Puedes usar Google Cloud para compilar un servicio escalable, eficiente y eficaz a fin de ofrecer recomendaciones de productos relevantes a los usuarios de una tienda en línea.
La competencia en los sitios de venta en línea nunca fue tan intensa como en el presente. Los clientes gastan más dinero en sus proveedores, pero invierten menos en los minoristas. El tamaño promedio de un solo carrito se redujo, en parte, debido a que la competencia está a solo un clic de distancia. Ofrecer recomendaciones relevantes a los clientes potenciales puede desempeñar una función importante con el objetivo de convertir compradores potenciales en compradores reales, así como para aumentar el tamaño promedio de los pedidos.
Después de leer esta solución, deberás ser capaz de configurar un entorno que admita un motor de recomendaciones básicas que puedas desarrollar y mejorar, según las necesidades de tu carga de trabajo específica. Ejecutar un motor de recomendaciones en Google Cloud te brinda flexibilidad y escalabilidad en las soluciones que deseas ejecutar.
En esta solución, verás cómo una empresa de alquileres de bienes raíces calcula las recomendaciones relevantes y se las presenta a los clientes que exploran un sitio web.
Situación
Samantha está buscando una casa para alquilar durante sus vacaciones. Tiene un perfil en un sitio web de alquileres de vacaciones y, anteriormente, alquiló y calificó varios paquetes de vacaciones. Sam está buscando recomendaciones basadas en sus preferencias y gustos. El sistema ya debería conocer los gustos de Sam. Al parecer, le gustan los alojamientos de tipo de house, según su página de calificaciones. El sistema debería recomendar algo similar.
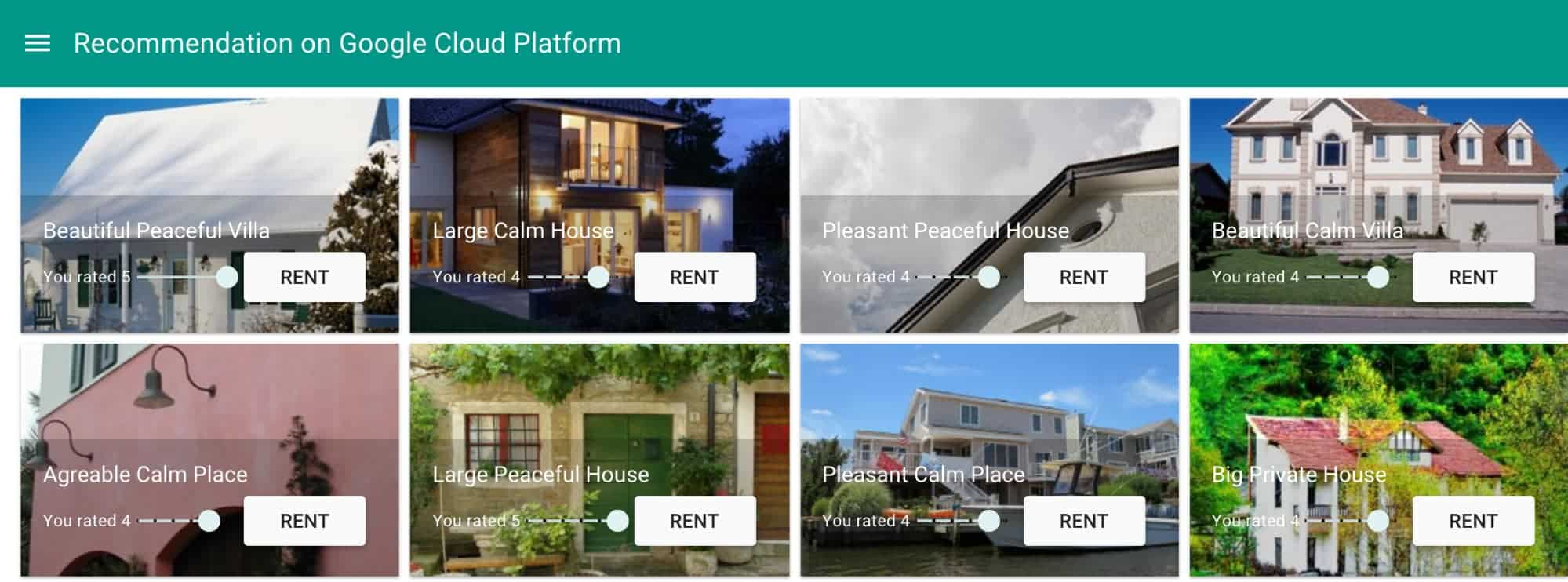
Descripción general de la solución
Para ofrecer recomendaciones, ya sea en tiempo real, mientras los clientes exploran, o más adelante por correo electrónico, es necesario que se cumplan determinadas condiciones. Al principio, cuando tienes poca información acerca de los gustos y las preferencias de tus usuarios, puedes basar las recomendaciones solo en los atributos de los elementos. Pero el sistema necesita obtener información de tus usuarios recopilando datos sobre sus gustos y preferencias. Con el tiempo, una vez que haya suficientes datos, puedes utilizar algoritmos de aprendizaje automático para realizar análisis útiles y entregar recomendaciones significativas. Las entradas de otros usuarios también pueden mejorar los resultados, lo que permite que el sistema reciba entrenamiento periódicamente. Esta solución se relaciona con un sistema de recomendaciones que cuenta con suficientes datos para beneficiarse de los algoritmos de aprendizaje automático.
Por lo general, un motor de recomendaciones procesa datos a través de las siguientes cuatro fases:

La arquitectura de ese sistema se puede representar mediante el siguiente diagrama:
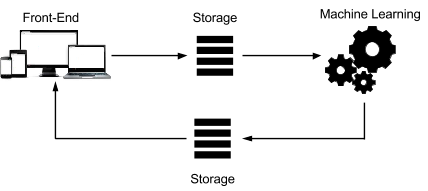
Cada paso se puede personalizar para cumplir con los requisitos. El sistema incluye las siguientes características:
Un frontend escalable que registra las interacciones del usuario para recopilar datos.
Almacenamiento permanente al que se puede acceder mediante una plataforma de aprendizaje automático. La carga de datos en este almacenamiento puede incluir varios pasos, como la importación, la exportación y la transformación de los datos.
Una plataforma de aprendizaje automático que puede analizar el contenido existente a fin de crear recomendaciones relevantes.
Almacenamiento que puede utilizar el frontend, en tiempo real o posteriormente, según los requisitos de puntualidad de las recomendaciones.
Elección de los componentes
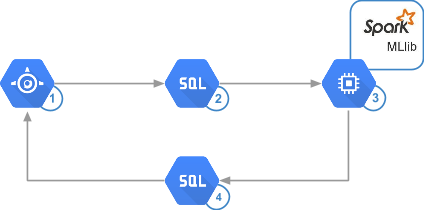
Para lograr un buen equilibrio entre velocidad, simplicidad, control de costos y precisión, esta solución usa App Engine, Cloud SQL y Apache Spark que se ejecuta en App Engine mediante Dataproc.
App Engine puede manejar varias decenas de miles de consultas por segundo sin necesitar una gran administración. Ya sea que estés creando el sitio web o guardando los datos en un almacenamiento backend, App Engine te permite escribir el código y, a continuación, implementarlo en un entorno de producción en cuestión de segundos.
Cloud SQL también ofrece una implementación simple. Cloud SQL puede escalar máquinas virtuales de 32 núcleos con una memoria RAM de hasta 208 GB, así como puede aumentar el almacenamiento según demanda a 10 TB con 30 IOPS por GB y miles de conexiones simultáneas. Estas especificaciones son suficientes en el ejemplo de esta solución, así como para muchos motores de recomendaciones reales. Cloud SQL también presenta la ventaja de que se puede acceder directamente desde Spark.
Spark ofrece un rendimiento superior al de una configuración típica de Hadoop, ya que puede ser de 10 a 100 veces más rápido. Con Spark MLlib, puedes analizar cientos de millones de clasificaciones en minutos, lo que aumenta la agilidad de las recomendaciones y permite que el administrador ejecute el algoritmo con mayor frecuencia. Spark aprovecha la memoria del procesamiento al máximo a fin de reducir las idas y vueltas al disco. También intenta minimizar la E/S. Esta solución usa Compute Engine para alojar la infraestructura de los análisis. Compute Engine ayuda a mantener el precio de los análisis lo más bajo posible mediante los precios por segundo a pedido.
El siguiente diagrama corresponde con el diagrama de arquitectura anterior, pero muestra la tecnología que se usa en cada paso:
Recopila los datos
Un motor de recomendaciones puede recopilar datos sobre los usuarios según el comportamiento implícito o la entrada explícita.
Los datos de comportamiento son fáciles de recopilar porque puedes conservar los registros de las actividades del usuario. La recopilación de estos datos también es sencilla porque no requiere que el usuario realice ninguna acción adicional, puesto que el usuario ya está usando la aplicación. La desventaja de este enfoque es que es más difícil de analizar. Por ejemplo, filtrar los registros interesantes de los menos interesantes puede ser muy complicado.
Los datos de entrada pueden ser más difíciles de recopilar porque los usuarios deben realizar acciones adicionales, como escribir una opinión. Hay muchos motivos por los cuales los usuarios no desean proporcionar estos datos. No obstante, cuando se trata de comprender las preferencias de los usuarios, estos resultados son bastante precisos.
Almacenamiento de datos
Cuantos más datos pongas a disposición de tus algoritmos, mejores serán las recomendaciones. Esto significa que cualquier proyecto de recomendaciones puede convertirse rápidamente en un proyecto de macrodatos.
Los tipos de datos que empleas para crear recomendaciones pueden ayudarte a decidir el tipo de almacenamiento que te conviene utilizar. Puede elegir una base de datos NoSQL, una base de datos SQL estándar o, incluso, algún tipo de almacenamiento de objetos. La viabilidad de cada una de estas opciones depende de si estás capturando las entradas o el comportamiento de los usuarios, así como ciertos factores, por ejemplo: la facilidad de implementación, la cantidad de datos que el almacenamiento puede administrar, la integración con el resto del entorno y la portabilidad.
Cuando se guardan los eventos o las calificaciones de los usuarios, una base de datos escalable y administrada minimiza la cantidad de tareas operativas necesarias y ayuda a enfocarse en la recomendación. Cloud SQL satisface ambas necesidades y facilita la carga de datos directamente desde Spark.
El siguiente código de ejemplo muestra los esquemas pertenecientes a las tablas de Cloud SQL.
La tabla Accommodation representa la propiedad de alquiler y la tabla Rating representa la calificación de un usuario con respecto a una propiedad en particular.
CREATE TABLE Accommodation
(
id varchar(255),
title varchar(255),
location varchar(255),
price int,
rooms int,
rating float,
type varchar(255),
PRIMARY KEY (ID)
);
CREATE TABLE Rating
(
userId varchar(255),
accoId varchar(255),
rating int,
PRIMARY KEY(accoId, userId),
FOREIGN KEY (accoId)
REFERENCES Accommodation(id)
);
Spark recibe datos de varias fuentes, como HDFS de Hadoop o Cloud Storage. Esta solución recibe los datos directamente desde Cloud SQL mediante el conector de la Conectividad a base de datos de Java (JDBC) de Spark. Debido a que los trabajos de Spark se ejecutan en paralelo, el conector debe estar disponible en todas las instancias de clústeres.
Análisis de datos
El diseño de la fase de análisis requiere comprender los requisitos de la aplicación. Estos requisitos incluyen las siguientes características:
La puntualidad de una recomendación. ¿Qué tan rápido la aplicación necesita presentar las recomendaciones?
El enfoque de filtrado de los datos. ¿La aplicación basará la recomendación solamente en los gustos del usuario, alternará los datos en función de lo que piensen los demás usuarios o se centrará en qué productos encajan de forma lógica?
Información sobre la puntualidad
El primer factor que debes considerar cuando analizas los datos es la velocidad con la que necesitas presentar las recomendaciones al usuario. Si deseas presentar recomendaciones de inmediato, como cuando el usuario está viendo un producto, necesitarás un tipo de análisis más ágil que, por ejemplo, enviar un correo electrónico al cliente que incluya recomendaciones en una fecha posterior.
Los sistemas en tiempo real pueden procesar datos a medida que se crean. Este tipo de sistema, por lo general, involucra herramientas que puedan procesar y analizar las transmisiones de eventos. Se requiere un sistema en tiempo real para brindar recomendaciones de forma inmediata.
El análisis de lotes requiere que proceses los datos de manera periódica. Este enfoque implica que se deben crear suficientes datos para que los análisis sean relevantes, como el volumen de ventas diario. Un sistema por lotes podría ser útil para enviar un correo electrónico en una fecha posterior.
El análisis casi en tiempo real te permite recopilar datos rápidamente a fin de actualizar las estadísticas en intervalos de pocos minutos o segundos. Un sistema en tiempo casi real puede ser útil para ofrecer recomendaciones durante la misma sesión de navegación.
Una recomendación podría corresponder a cualquiera de estas tres categorías de puntualidad; sin embargo, en el caso de una herramienta de ventas en línea, puedes considerar una opción intermedia entre el procesamiento casi en tiempo real y el procesamiento por lotes, según la cantidad de tráfico y de entrada del usuario que reciba la aplicación. La plataforma que ejecuta el análisis podría funcionar directamente desde una base de datos en la que se guardan esos datos, o en un archivo de volcado que se guarda en un almacenamiento continuo de forma periódica.
Filtrado de datos
Un componente central de la compilación de un motor de recomendaciones es el filtrado. Entre los enfoques más comunes, se incluyen los siguientes:
Basado en el contenido: un producto popular y recomendado tiene atributos similares a lo que el usuario ve o le gusta.
Clúster: los productos recomendados combinan bien juntos, independientemente de lo que hayan hecho otros usuarios.
Colaborativo: otros usuarios, a los cuales les gustan los mismos productos que el usuario ve o le llaman la atención, también se interesaron en un producto recomendado.
Si bien Google Cloud es compatible con cualquiera de estos enfoques, esta solución se centra en el filtrado colaborativo, que se implementa mediante el uso de Apache Spark. Para obtener más información sobre el filtrado basado en el contenido o el filtrado de clústeres, consulta el apéndice.
El filtrado colaborativo te ayuda a lograr que los atributos del producto sean abstractos, así como llevar a cabo predicciones basadas en los gustos del usuario. La salida de este filtrado se basa en el supuesto de que, probablemente, a dos usuarios diferentes que les gustaron los mismos productos en el pasado les interesarán esos productos en el presente.
Puedes representar datos sobre calificaciones o interacciones (por ejemplo, un conjunto de matrices) con productos y usuarios como dimensiones. El filtrado colaborativo intenta predecir las celdas faltantes en una matriz en el caso de un par usuario-producto determinado. Las dos matrices siguientes son similares, pero la segunda se deduce de la primera reemplazando las calificaciones existentes por el número uno y las calificaciones faltantes por el cero. La matriz resultante es una tabla de verdades en la cual un número representa una interacción de los usuarios con un producto.
| Matriz de calificación | Matriz de interacción |
|---|---|
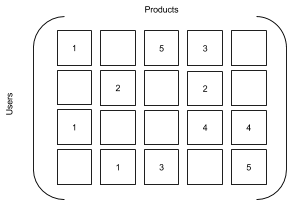 |
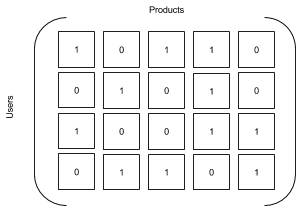 |
Hay dos enfoques distintos para emplear el filtrado colaborativo:
El filtrado basado en la memoria calcula las similitudes entre los productos o los usuarios.
El filtrado basado en modelos intenta aprender el patrón subyacente que dicta cómo los usuarios califican o interactúan con los elementos.
Esta solución usa el enfoque basado en modelos, en el cual los usuarios ya calificaron los elementos.
Todas las funciones analíticas que requiere esta solución están disponibles a través de PySpark, el cual proporciona una interfaz Python al lenguaje de programación Spark. Otras opciones están disponibles mediante el uso de Scala o Java. Consulta la documentación de Spark.
Entrenamiento de los modelos
Spark MLlib implementa el algoritmo de los mínimos cuadrados alternos (ALS) para entrenar los modelos. Utilizarás varias combinaciones de los siguientes parámetros para obtener la mejor concesión entre la varianza y el sesgo:
Clasificación: la cantidad de factores desconocidos que llevaron a un usuario a proporcionar una calificación. Entre estos factores, se incluyen la edad, el género o la ubicación. Cuanto más alta sea la clasificación, mejor será la recomendación; hasta cierto punto. Comienza en 5 y va subiendo en 5 hasta que la tasa de mejora de la recomendación comience a disminuir; la memoria y la CPU otorgan permiso. Es un enfoque adecuado.
Lambda: el parámetro de regularización que evita el sobreajuste y que está representado por una varianza alta y un sesgo bajo. La varianza representa la variación en las fluctuaciones de las predicciones en un punto dado y durante diversas ejecuciones, en comparación con el valor teórico correcto para ese punto. El sesgo representa a qué distancia están las predicciones generadas del valor verdadero que estás intentando predecir. El sobreajuste ocurre cuando el modelo funciona correctamente en los datos de entrenamiento que usan un ruido conocido, pero no funciona como se espera en los datos de prueba reales. Cuanto mayor sea la lambda, menor será el sobreajuste. No obstante, el sesgo será mayor. Los valores de 0.01, 1 y 10 son adecuados para realizar la prueba.
El siguiente diagrama muestra la relación entre la varianza y el sesgo. La diana representa el valor que el algoritmo está tratando de predecir.
Varianza frente a sesgo (lo mejor está en la parte superior izquierda) 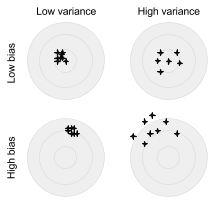
Iteración: la cantidad de veces que se ejecutará el entrenamiento. En este ejemplo, harás 5, 10 y 20 iteraciones para varias combinaciones de clasificación y lambda.
El siguiente código de ejemplo muestra cómo ejecutar un entrenamiento de modelos ALS en Spark.
from pyspark.mllib.recommendation import ALS
model = ALS.train(training, rank = 10, iterations = 5, lambda_=0.01)
Cómo encontrar el modelo correcto
El filtrado colaborativo que utiliza el algoritmo ALS se basa en tres conjuntos de datos diferentes:
Conjunto de entrenamiento: contiene datos con salida conocida. Este conjunto representa el aspecto que debe tener un resultado perfecto. En esta solución, se incluyen las calificaciones de los usuarios.
Conjunto de validación: contiene datos que ayudarán a ajustar el entrenamiento a fin de elegir la combinación correcta de parámetros, así como el modelo más adecuado.
Conjunto de prueba: contiene datos que se utilizarán para evaluar el rendimiento del modelo que haya recibido el mejor entrenamiento. Esto sería equivalente a ejecutar el análisis en un ejemplo del mundo real.
Para encontrar el mejor modelo, debes calcular el error de la raíz cuadrada de la media (RMSE) en función del modelo que se calculó, el conjunto de validación y el tamaño. Cuanto menor sea el RMSE, el modelo será de mejor calidad.
Entrega de las recomendaciones
Con el fin de que los resultados estén disponibles para el usuario con rapidez y de forma sencilla, debes cargarlos en una base de datos que se pueda consultar según demanda. Una vez más, Cloud SQL constituye una opción adecuada aquí. En Spark 1.4, puedes escribir los resultados de la predicción directamente en la base de datos de PySpark.
El esquema de la tabla Recommendation se ve de la siguiente manera:
CREATE TABLE Recommendation
(
userId varchar(255),
accoId varchar(255),
prediction float,
PRIMARY KEY(userId, accoId),
FOREIGN KEY (accoId)
REFERENCES Accommodation(id)
);
Explicación del código
En esta sección, se explica el código de entrenamiento de los modelos.
Obtén los datos desde Cloud SQL
El contexto de Spark SQL te permite conectarte con facilidad a una instancia de Cloud SQL a través del conector de JDBC. Los datos cargados están en formato DataFrame.
Convierte el DataFrame en RDD y crea conjuntos de datos diferentes
Spark utiliza un concepto llamado conjuntos de datos resilientes y distribuidos (RDD), que facilita el trabajo con elementos en paralelo. Los RDD son colecciones de solo lectura que se crean a partir del almacenamiento continuo. Se pueden procesar en la memoria, por lo que son adecuados para el procesamiento iterativo.
Recuerda que, a fin de obtener el mejor modelo para hacer tu predicción, debes dividir los conjuntos de datos en tres conjuntos diferentes. El siguiente código utiliza una función auxiliar que divide de manera aleatoria los valores no superpuestos en un porcentaje del 60/20/20:
Entrena modelos basados en varios parámetros
Recuerda que, si utilizas el método de ALS, el sistema deberá trabajar con los parámetros de clasificación, iteración y regularización para encontrar el modelo más adecuado. Las calificaciones existen, por lo que los resultados de la función train deben compararse con el conjunto de validación. Asegúrate de que los gustos del usuario también estén en el conjunto de entrenamiento.
Cálculo de las mejores predicciones para el usuario
Ahora que tienes un modelo capaz de proporcionar una predicción razonable, puedes usarlo para ver cuáles son los posibles intereses del usuario en función de los gustos y clasificaciones de otros con gustos similares. En este paso, puedes ver la asignación matricial que se describió antes.
Cómo guardar las mejores predicciones
Ahora que tienes una lista de todas las predicciones, puedes guardar las diez principales en Cloud SQL para que el sistema ofrezca algunas recomendaciones al usuario. Por ejemplo, un momento adecuado para usar estas predicciones podría ser cuando el usuario inicia sesión en el sitio.
Cómo ejecutar la solución
Para ejecutar esta solución, sigue en detalle las instrucciones de la página de GitHub. Si sigues las instrucciones sobre cómo llegar, deberías poder calcular y mostrar las recomendaciones para el usuario.
El código SQL final obtiene la recomendación principal de la base de datos y la muestra en la página de bienvenida de Samantha.
Cuando se ejecuta la consulta en la consola de Google Cloud o en un cliente MySQL, se muestra un resultado similar al siguiente ejemplo:
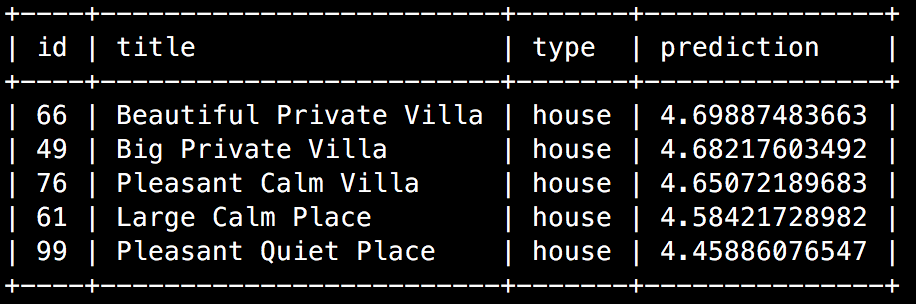
En el sitio web, la misma consulta puede mejorar la página de bienvenida y aumentar las posibilidades de que un visitante se convierta en cliente:
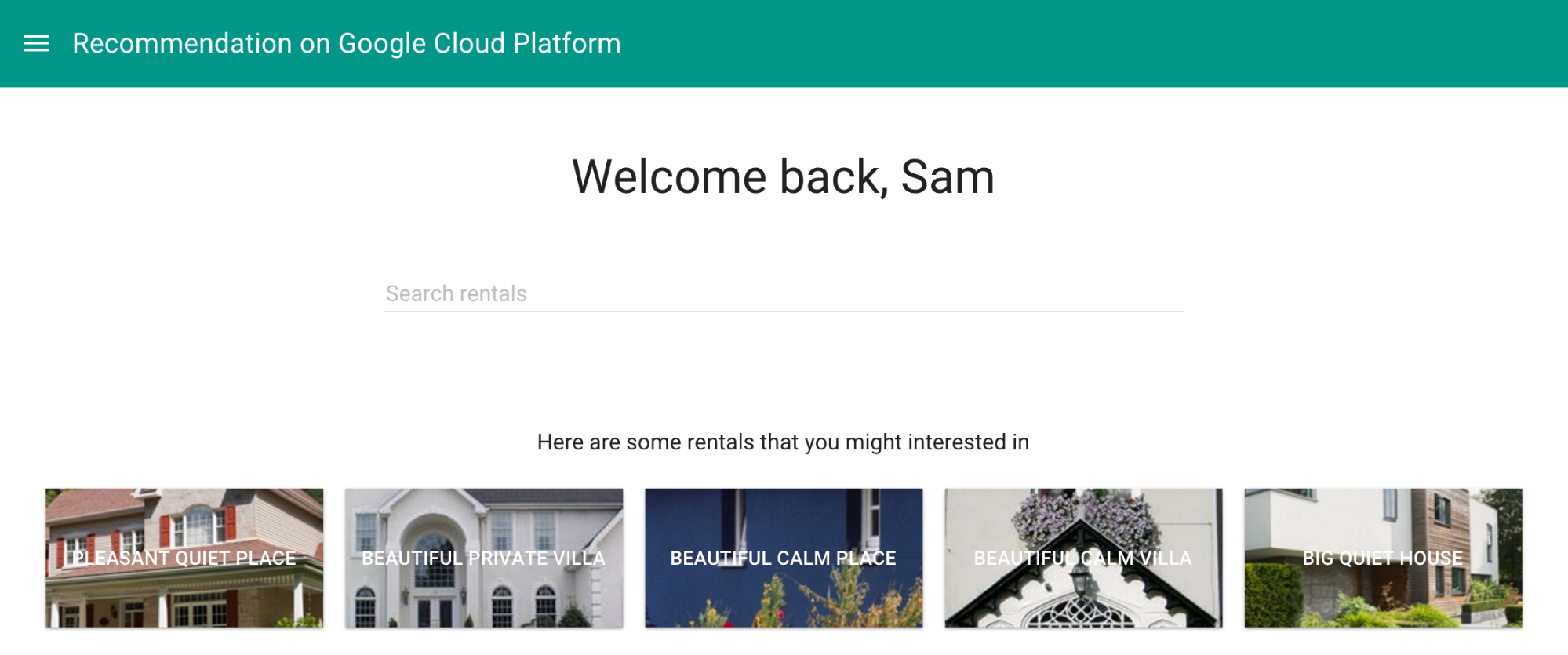
Esto se asemeja mucho a lo que le gusta a Sam según lo que el sistema ya sabía acerca de ella, como se explica en la descripción de la situación.
Instructivo
Puedes obtener el contenido completo del instructivo, incluidas las instrucciones de configuración y el código fuente, en GitHub.
Costos
En este instructivo, se usan los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Próximos pasos
- Explora arquitecturas de referencia, diagramas, instructivos y prácticas recomendadas sobre Google Cloud. Consulta nuestro Cloud Architecture Center.
- Aprende a usar los productos de Google Cloud para crear soluciones de extremo a extremo.
- Para obtener más información sobre la supervisión, consulta la documentación de Dataproc sobre los resultados o las interfaces web.
Apéndice
Filtrado cruzado
Si bien ya sabes cómo compilar una solución de filtrado colaborativo eficaz y escalable, cruzar los resultados con otros tipos de filtrado puede mejorar la recomendación. Recuerda los otros dos tipos principales de filtrado: basado en el contenido y agrupamiento en clústeres. Una combinación de estos enfoques puede producir una recomendación más adecuada para el usuario.
Filtrado basado en el contenido
El filtrado basado en el contenido funciona directamente con los atributos de los elementos y entiende sus similitudes, lo que facilita la creación de recomendaciones para los elementos que tienen atributos, pero cuentan con pocas calificaciones de los usuarios. A medida que la base de usuarios crece, este tipo de filtrado sigue siendo administrable, incluso con una gran cantidad de usuarios.
A fin de agregar un filtrado basado en el contenido, puedes usar las calificaciones anteriores de otros usuarios para los elementos del catálogo. En función de estas calificaciones, puedes encontrar los productos que sean más parecidos a los actuales.
Un método común para calcular la similitud entre dos productos consiste en usar la similitud coseno y hallar los vecinos más próximos:
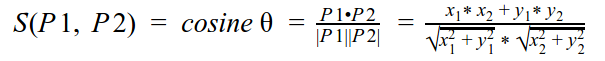
El resultado de similitud será entre 0 y 1. Mientras más cerca de 1, más similares son los productos.

Considera la siguiente matriz:
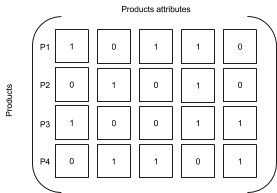
En esta matriz, la similitud entre P1 y P2 se puede calcular de la siguiente manera:
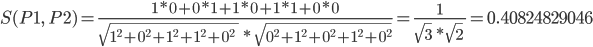
Puedes lograr un filtrado basado en el contenido mediante varias herramientas. Si deseas obtener más información, consulta las siguientes referencias:
Similitudes entre todos los pares en Twitter. La función
CosineSimilaritiesde Scala agregada a MLlib se puede ejecutar en el entorno de Spark.Mahout. Si deseas obtener acceso a más bibliotecas para complementar o reemplazar algún algoritmo de MLlib, puedes instalar Mahout en tu nodo controlador de Dataproc (instancia principal) mediante
sshpara conectarte a la instancia o mediante una acción de inicialización:sudo apt-get update sudo apt-get install mahout -y
Agrupamiento en clústeres
También es importante entender el contexto de navegación y qué es lo que el usuario está viendo en un momento en particular. La misma persona que explora en momentos diferentes podría estar interesada en dos productos completamente distintos; incluso, podría estar comprando un regalo para otra persona. Es fundamental entender qué elementos son similares a los que se muestran en la actualidad. El uso de agrupamiento en clústeres con el modelo K-means permite al sistema colocar elementos similares en depósitos, en función de los atributos principales.
Para esta solución, es probable que una persona que desea alquilar una casa en Londres, por ejemplo, no esté interesada en alquilar algún lugar en Auckland por el momento. Por lo tanto, el sistema debería filtrar esos casos cuando realiza una recomendación.
from pyspark.mllib.clustering import KMeans, KMeansModel
clusters = KMeans.train(parsedData, 2,
maxIterations=10,
runs=10,
initializationMode="random")
Vista de 360 grados
Puedes mejorar la recomendación aún más si tienes en cuenta otros datos del cliente, como los pedidos pasados, la asistencia y los atributos personales, por ejemplo: edad, ubicación o género. Estos atributos, que a menudo ya están disponibles en un sistema de administración de relaciones con el cliente (CRM) o planificación de recursos empresariales (ERP), ayudarán a reducir las opciones.
Si se piensa con detenimiento, no solo los datos internos del sistema influirán en el comportamiento y las elecciones de los usuarios; los factores externos también son importantes. En el caso práctico de alquiler de vacaciones, en relación con esta solución, conocer la calidad del aire podría ser importante para una familia joven. Por lo tanto, integrar un motor de recomendaciones compilado en Google Cloud con otra API, como Breezometer, podría brindar una ventaja competitiva.