
Managed Service para Apache Spark (antes Dataproc)
La nueva forma de usar Spark: más fácil, más rápido y más inteligente
Ejecuta cargas de trabajo de Apache Spark con Spark sin servidores ni operaciones o clústeres administrados. Acelera el desarrollo con flujos de trabajo de IA de agentes y mejora el rendimiento con Lightning Engine.
Los clientes nuevos obtienen $300 en créditos gratuitos para probar Managed Service for Apache Spark y otros productos de Google Cloud.
Spark es una marca comercial de The Apache Software Foundation.
Aspectos destacados del producto
Spark sin servidores ni operaciones o clústeres de Spark completamente administrados
Lightning Engine acelera el rendimiento de Spark hasta 4.9 veces en comparación con la ejecución de Spark de código abierto
Desarrollo y solución de problemas potenciados por IA con Gemini

Funciones
Rendimiento líder en la industria con Lightning Engine
Acelera las cargas de trabajo de ETL y SQL a gran escala hasta 4.9 veces más rápido que Apache Spark de código abierto sin realizar cambios en el código. Lightning Engine utiliza un motor de ejecución vectorizado nativo de C++, almacenamiento en caché inteligente y reorganización columnar optimizada. Combina esto con el ajuste automático inteligente de Spark para eliminar el impuesto de ajuste manual, optimizar la memoria y evitar errores OOM automáticamente.
* Las consultas se derivan del estándar TPC-DS y del estándar TPC-H
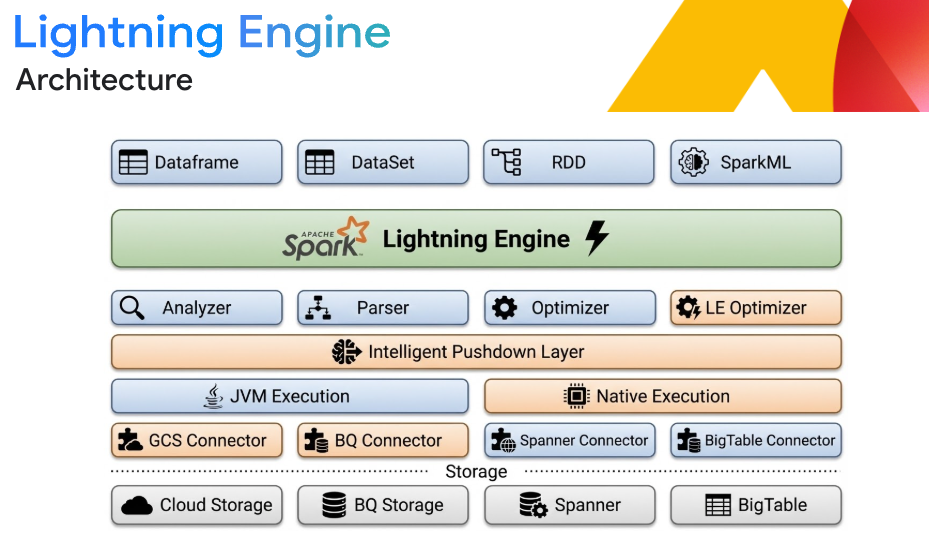
Interoperabilidad flexible de lakehouses
Crea una arquitectura de lakehouse abierta que garantice la independencia del motor. Procesa datos en formatos abiertos como Apache Iceberg directamente desde Google Cloud Storage. Obtén una integración perfecta con BigQuery y Knowledge Catalog (antes Dataplex) para un análisis y una administración unificados, lo que garantiza una verdadera interoperabilidad de múltiples motores sin capas de traducción.
Experiencia unificada para desarrolladores potenciada por IA
Elimina tu trabajo pendiente con agentes de datos que toman medidas, no solo responden preguntas. Acelera tu flujo de trabajo con Gemini integrado en la extensión de agente de VSCode para aumentar la productividad de las cargas de trabajo de Spark desde el desarrollo hasta la producción, o usa el IDE que prefieras. Automatiza el tratamiento de datos y la programación de PySpark con agentes de Data Cloud listos para usar, o bien usa Data Agent Kit para administrar conjuntos de datos y ejecutar consultas directamente desde tu IDE. Soluciona automáticamente los problemas de los trabajos de Spark rotos con Gemini Cloud Assist. Combina SQL y Spark en un solo notebook unificado centrado en la IA.
Listo para IA y AA empresariales
Crea y pon en funcionamiento todo tu ciclo de vida de aprendizaje automático. Acelera el entrenamiento de modelos y la inferencia con la compatibilidad de GPU, con la tecnología de NVIDIA RAPIDS y los entornos de ejecución de AA preconfigurados para PyTorch y XGBoost. Integrarse en el ecosistema de IA de Google Cloud para organizar MLOps de extremo a extremo y administrar recursos con la integración de Gemini Enterprise Agent Platform Model Registry.
Migraciones seguras, escalables y fluidas
Intégrate sin problemas con tu postura de seguridad usando IAM, los Controles del servicio de VPC y Kerberos. Migra fácilmente cargas de trabajo de Spark heredadas y en la nube con las plantillas y herramientas de Managed Service para Apache Spark. Realiza un lift-and-shift de las cargas de trabajo con compatibilidad para Spark 2.x hasta Spark 4.0 sin refactorización de código inmediata.
Eficiencia multiusuario y controles de FinOps
Maximiza la utilización de recursos y reduce los costos de inactividad. Implementa clústeres multiusuario de Spark que permitan que hasta 800 usuarios compartan recursos de procesamiento mientras se mantiene un estricto aislamiento de datos y entorno. Controla tu factura con capacidades de reducción de escala a cero, facturación por segundo y compatibilidad con VM Spot para cargas de trabajo flexibles.
Ecosistema abierto y flexible
Evita la dependencia de un solo proveedor. Si bien están optimizados para Apache Spark, nuestros clústeres administrados admiten más de 30 herramientas de código abierto, como Apache Hadoop, Flink y Trino. Se integra a la perfección con organizadores como Managed Service for Apache Airflow y se puede extender con Kubernetes y Docker para obtener la máxima flexibilidad.
Opciones de implementación
| Opciones de implementación | Elige entre el control detallado de los clústeres administrados o la simplicidad sin operaciones de una experiencia sin servidores para obtener la mejor opción para tu carga de trabajo. | ||
|---|---|---|---|
| Modo de implementación: | En qué consiste: | Es ideal para: | Paga por: |
Sin servidores | Trabajos de Spark como servicio. Spark administrado, infraestructura administrada. | Nuevas canalizaciones, análisis interactivos y cargas de trabajo con aumentos repentinos en las que se prefiere un modelo de cero operaciones y pago por trabajo. | Tiempo de ejecución del trabajo |
Clústeres | Clústeres de Spark como servicio. Spark administrado, tu infraestructura. | Migrar cargas de trabajo heredadas de Spark u OSS, ejecutar clústeres persistentes o requerir una personalización profunda de código abierto. | Tiempo de actividad del clúster |
Opciones de implementación
Elige entre el control detallado de los clústeres administrados o la simplicidad sin operaciones de una experiencia sin servidores para obtener la mejor opción para tu carga de trabajo.
Sin servidores
Trabajos de Spark como servicio.
Spark administrado, infraestructura administrada.
Nuevas canalizaciones, análisis interactivos y cargas de trabajo con aumentos repentinos en las que se prefiere un modelo de cero operaciones y pago por trabajo.
Tiempo de ejecución del trabajo
Clústeres
Clústeres de Spark como servicio.
Spark administrado, tu infraestructura.
Migrar cargas de trabajo heredadas de Spark u OSS, ejecutar clústeres persistentes o requerir una personalización profunda de código abierto.
Tiempo de actividad del clúster
Cómo funciona
Facilita Spark con clústeres administrados o sin servidores ni operaciones. Trabaja de forma más inteligente con Gemini en el IDE que elijas y usa la IA de agentes para acelerar el desarrollo de PySpark. Ejecuta trabajos más rápido con Lightning Engine, todo mientras mantienes una administración unificada en tu lakehouse abierto con Knowledge Catalog.
Facilita Spark con clústeres administrados o sin servidores ni operaciones. Trabaja de forma más inteligente con Gemini en el IDE que elijas y usa la IA de agentes para acelerar el desarrollo de PySpark. Ejecuta trabajos más rápido con Lightning Engine, todo mientras mantienes una administración unificada en tu lakehouse abierto con Knowledge Catalog.
Ingeniería de datos a gran escala
Canalizaciones de ETL automatizadas
Canalizaciones de ETL automatizadas
Crea canalizaciones de ETL de Spark sólidas y basadas en eventos que se escalen automáticamente a pedido. Aprovecha la ejecución sin servidores para cargas de trabajo con picos o clústeres administrados para trabajos persistentes. Usa plantillas de flujos de trabajo para automatizar tus trabajos de procesamiento de datos más importantes de nivel de producción de extremo a extremo.
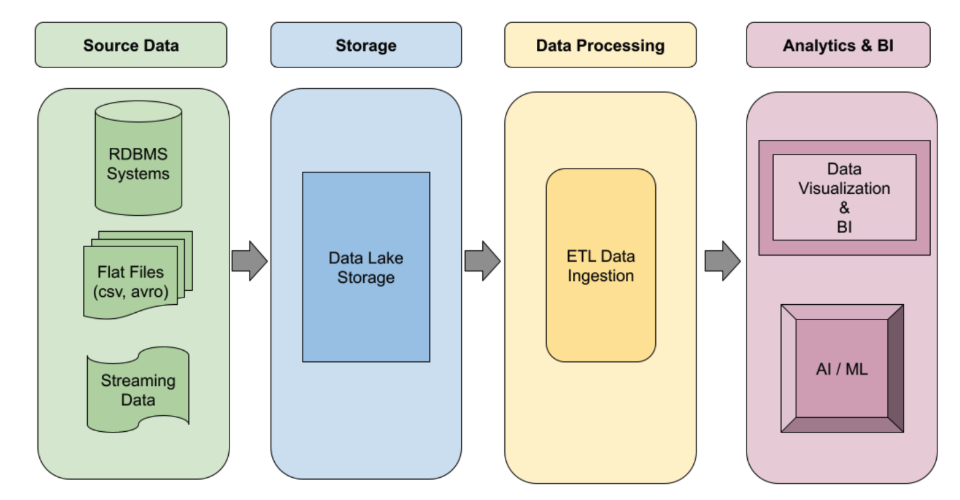


Instructivos, guías de inicio rápido y labs
Canalizaciones de ETL automatizadas
Canalizaciones de ETL automatizadas
Crea canalizaciones de ETL de Spark sólidas y basadas en eventos que se escalen automáticamente a pedido. Aprovecha la ejecución sin servidores para cargas de trabajo con picos o clústeres administrados para trabajos persistentes. Usa plantillas de flujos de trabajo para automatizar tus trabajos de procesamiento de datos más importantes de nivel de producción de extremo a extremo.
Ciencia de datos y aprendizaje automático
Ciencia de datos interactiva
Ciencia de datos interactiva
Permite a los científicos de datos explorar datos y realizar iteraciones en modelos de AA de Spark. Unifica SQL y Spark con Gemini usando la extensión de agente de VSCode o tu IDE preferido, pasando sin problemas de la exploración de datos a la creación de modelos con PySpark usando la ejecución sin servidores. Conecta GPUs con un solo comando.
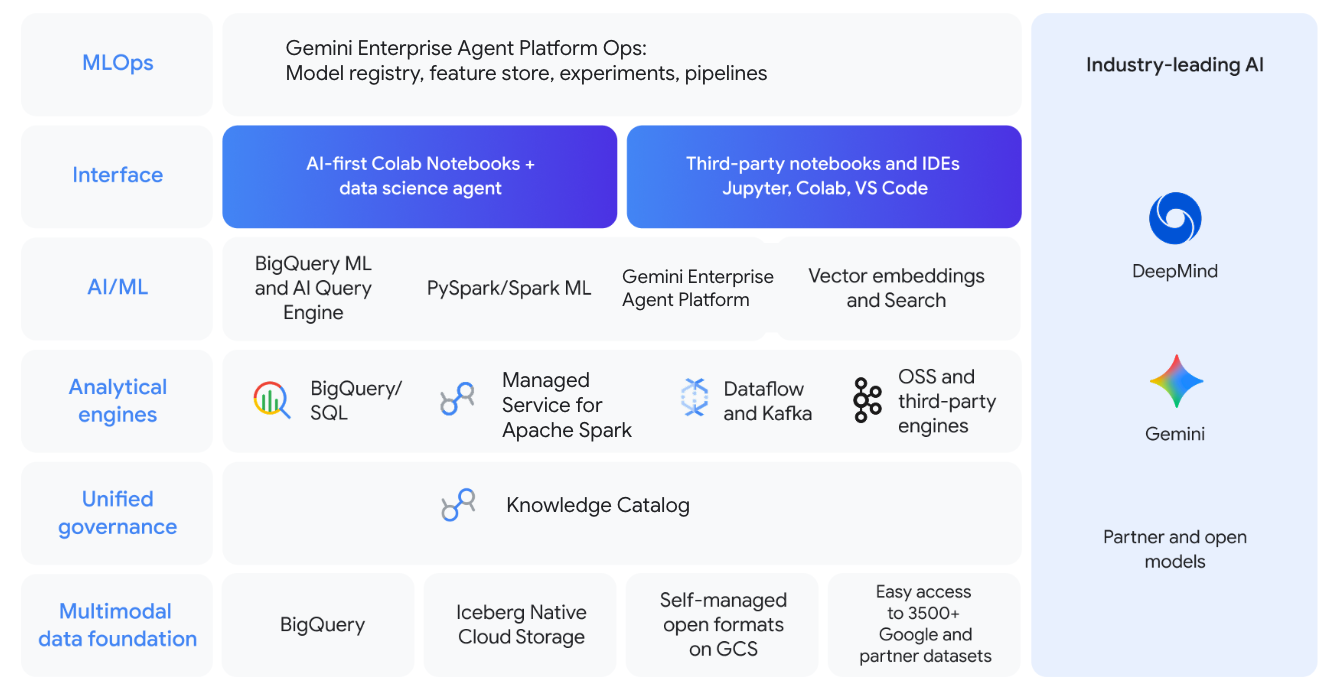


Instructivos, guías de inicio rápido y labs
Ciencia de datos interactiva
Ciencia de datos interactiva
Permite a los científicos de datos explorar datos y realizar iteraciones en modelos de AA de Spark. Unifica SQL y Spark con Gemini usando la extensión de agente de VSCode o tu IDE preferido, pasando sin problemas de la exploración de datos a la creación de modelos con PySpark usando la ejecución sin servidores. Conecta GPUs con un solo comando.
Modernización de lakehouse
Data lakehouse abierta
Data lakehouse abierta
Usa Managed Service para Apache Spark como el motor de procesamiento para tu data lakehouse moderno. Procesa datos en formatos abiertos como Apache Iceberg directamente desde tu data lake, lo que elimina los silos de datos. Integración con BigQuery y Lakehouse para Apache Iceberg para una plataforma de análisis unificada y de múltiples motores.
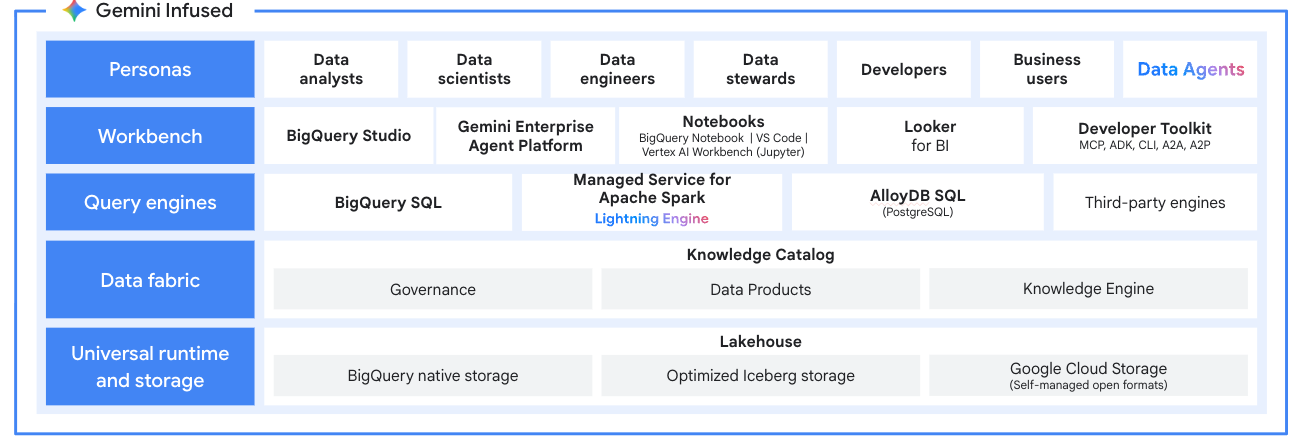

Instructivos, guías de inicio rápido y labs
Data lakehouse abierta
Data lakehouse abierta
Usa Managed Service para Apache Spark como el motor de procesamiento para tu data lakehouse moderno. Procesa datos en formatos abiertos como Apache Iceberg directamente desde tu data lake, lo que elimina los silos de datos. Integración con BigQuery y Lakehouse para Apache Iceberg para una plataforma de análisis unificada y de múltiples motores.
Precios
| Cómo funciona el precio de Managed Service para Apache Spark | El precio depende del modelo de implementación que elijas. Las plataformas sin servidores facturan por ejecución de trabajo, mientras que los clústeres facturan por la computación subyacente y el tiempo de actividad. | |
|---|---|---|
| Modo de implementación: | Qué pagas: | Cuánto pagas: |
Sin servidores | Paga solo por lo que usas. Se factura por segundo el procesamiento, las GPUs y el almacenamiento aleatorio. La reducción de escala a cero garantiza que nunca pagues por capacidad inactiva. | A partir de $0.06 por hora de DCU |
Nivel Premium y aceleradores: Accede a Lightning Engine para obtener un rendimiento hasta 4,9 veces más rápido o conecta GPUs NVIDIA para cargas de trabajo de IA/AA. | A partir de $0.089 por hora de DCU Nivel Premium sin servidores | |
Clústeres | Paga por el tiempo de actividad del clúster. Se factura por los recursos subyacentes de Compute Engine más una tarifa de administración fija. Aprovecha las VMs Spot y el escalamiento a cero para optimizar los costos. | A partir de $0.01 por hora de CPU virtual Cuota de administración |
Complemento Lightning Engine: Aporta un rendimiento innovador a tus clústeres. Experimenta una ejecución hasta 4.9 veces más rápida que Spark de código abierto. | A partir de $0.0025 por hora de CPU virtual | |
Obtén más información sobre los precios de Managed Service para Apache Spark. Ver todos los detalles de precios.
Cómo funciona el precio de Managed Service para Apache Spark
El precio depende del modelo de implementación que elijas. Las plataformas sin servidores facturan por ejecución de trabajo, mientras que los clústeres facturan por la computación subyacente y el tiempo de actividad.
Sin servidores
Paga solo por lo que usas. Se factura por segundo el procesamiento, las GPUs y el almacenamiento aleatorio. La reducción de escala a cero garantiza que nunca pagues por capacidad inactiva.
Starting at
$0.06 por hora de DCU
Nivel Premium y aceleradores:
Accede a Lightning Engine para obtener un rendimiento hasta 4,9 veces más rápido o conecta GPUs NVIDIA para cargas de trabajo de IA/AA.
Starting at
$0.089 por hora de DCU
Nivel Premium sin servidores
Clústeres
Paga por el tiempo de actividad del clúster. Se factura por los recursos subyacentes de Compute Engine más una tarifa de administración fija. Aprovecha las VMs Spot y el escalamiento a cero para optimizar los costos.
Starting at
$0.01 por hora de CPU virtual
Cuota de administración
Complemento Lightning Engine:
Aporta un rendimiento innovador a tus clústeres. Experimenta una ejecución hasta 4.9 veces más rápida que Spark de código abierto.
Starting at
$0.0025 por hora de CPU virtual
Obtén más información sobre los precios de Managed Service para Apache Spark. Ver todos los detalles de precios.
Caso empresarial
Historias de éxito de clientes

“Vimos que algunas de nuestras verificaciones de calidad pasaron de 11 horas a minutos”.
Michael Manos, director de Tecnología de Dun & Bradstreet
La migración a Google Cloud ayudó a Dun & Bradstreet a aumentar significativamente la velocidad de los flujos de datos, ya que reduce los procesos de verificación de calidad de horas a minutos y disminuye a la mitad el tiempo que se tarda en publicar nuevos datos. Esta sólida base de datos también permite a Dun & Bradstreet aprovechar todo el potencial del ecosistema de Google Cloud, incluidas las tecnologías de IA y datos de vanguardia.



La diferencia de Managed Service para Apache Spark
Productividad sin operaciones con opciones de implementación flexibles. Elige la ejecución sin servidores o clústeres completamente administrados para eliminar la sobrecarga de la infraestructura y el ajuste manual.
Desarrollo de IA de agentes. Acelera tu flujo de trabajo con Gemini integrado en la extensión de agente de VSCode o con el IDE que prefieras, junto con agentes de datos que automatizan la programación de PySpark, el tratamiento de datos y la solución de problemas de trabajos en un notebook unificado.
Rendimiento líder en la industria con la tecnología de Lightning Engine. Acelera tus cargas de trabajo de ETL y ciencia de datos más exigentes hasta 4.9 veces, lo que reduce significativamente tu costo total de propiedad.










Recursos adicionales:
Preguntas frecuentes
¿Qué pasó con Dataproc y Spark sin servidores?
Para simplificar tu experiencia, unificamos Dataproc y Google Cloud Serverless for Apache Spark en un solo producto: Managed Service para Apache Spark. Obtienes las mismas potentes capacidades, pero ahora simplemente eliges tu modelo de implementación preferido (sin servidores ni operaciones o clústeres completamente administrados) desde una sola interfaz unificada. Compara ambos modos de implementación con más detalle.
¿Cuándo debo elegir clústeres sin servidores en lugar de clústeres administrados?
Elige la opción sin servidores cuando quieras enfocarte puramente en el código con cero administración de la infraestructura, ideal para nuevas canalizaciones y análisis ad hoc. Elige clústeres administrados cuando necesites un control detallado, estés migrando cargas de trabajo heredadas, de Spark en la nube o de otros OSS, o requieras clústeres persistentes con diversas herramientas de código abierto.
¿Qué es Lightning Engine?
Lightning Engine es el motor de ejecución nativo y altamente optimizado de Google Cloud. Creado con bibliotecas de C++, optimiza cada capa, desde conectores de almacenamiento con alta capacidad de procesamiento hasta almacenamiento en caché inteligente. Ofrece un rendimiento hasta 4.9 veces mejor que Spark estándar y una relación precio-rendimiento 2 veces mejor que la principal alternativa de Spark de alta velocidad, ya que se integra sin problemas en tus implementaciones sin servidores o de clústeres sin cambios de código.
¿Debo instalar mis propias bibliotecas de AA como PyTorch?
No. Si ejecutas cargas de trabajo de IA o AA, puedes usar nuestros entornos de ejecución de AA preconfigurados. Estos entornos incluyen bibliotecas comunes como PyTorch, XGBoost y scikit-learn, además de controladores de GPU de NVIDIA optimizados, lo que elimina la necesidad de una configuración compleja.
¿Managed Service para Apache Spark es totalmente compatible con el código abierto?
Sí. Proporcionamos un entorno de Apache Spark compatible con el 100% del código abierto. Puedes ejecutar tu código de Spark existente sin modificaciones, lo que garantiza la portabilidad completa de la carga de trabajo y evita la dependencia de un proveedor.
¿Cómo ayuda la IA de Gemini con el desarrollo de Spark?
La IA de Gemini se puede incorporar directamente en el IDE que elijas para que actúe como tu copiloto de IA. Te ayuda a escribir y depurar código de PySpark más rápido, mientras que Gemini Cloud Assist proporciona análisis automatizados de causa raíz y recomendaciones para solucionar problemas de trabajos fallidos.
¿Puedo usar este servicio para crear un data lakehouse abierto?
Por supuesto. Managed Service para Apache Spark es un motor de procesamiento central para el lakehouse abierto de Google Cloud. Te permite procesar datos en formatos abiertos como Apache Iceberg directamente desde Cloud Storage, ya que se integra sin problemas con BigQuery y Knowledge Catalog para Apache Iceberg.
¿Cómo funcionan los niveles de precios estándar y premium?
Actualmente, los niveles estándar y premium solo se aplican a las implementaciones sin servidores. El estándar es ideal para el procesamiento por lotes y ETL de uso general y rentable. El nivel premium está diseñado para tus cargas de trabajo más exigentes, ya que desbloquea un aumento del rendimiento de 4.9 veces en comparación con Apache Spark de código abierto con Lightning Engine y proporciona acceso a capacidades de IA/AA aceleradas por GPU.


















