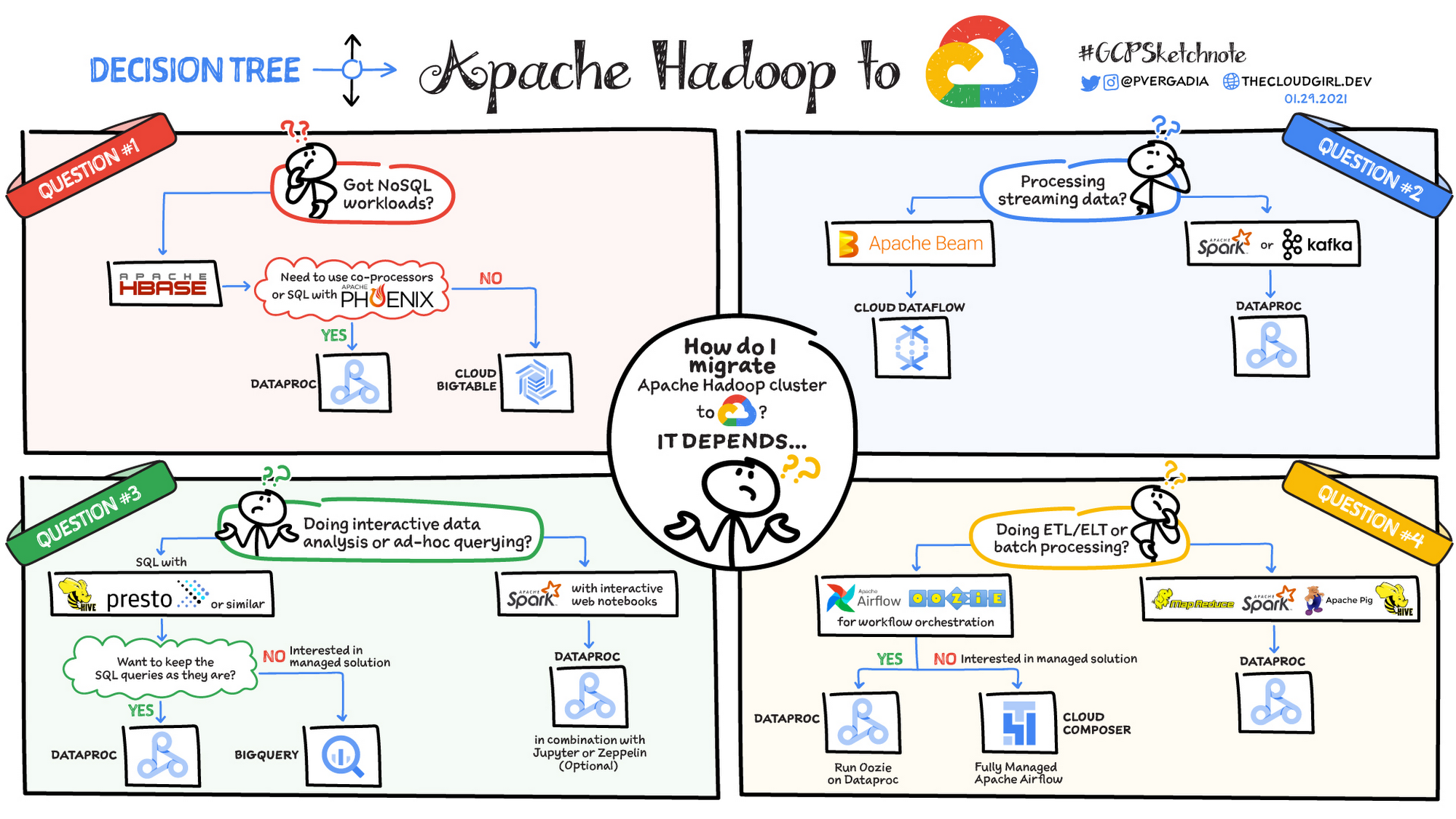
Migrating Apache Hadoop to Dataproc: A decision tree
Priyanka Vergadia
Staff Developer Advocate, Google Cloud
Are you using the Apache Hadoop ecosystem? Are you looking to simplify the management of resources while continuing to use your existing tools? If yes, then check out Dataproc. In this blog post, we will briefly cover Dataproc and then highlight four scenarios for migrating your Apache Hadoop workflows to Google Cloud.
What is Dataproc?
Dataproc is a managed Apache Spark and Apache Hadoop service that lets you take advantage of open-source data tools for batch processing, querying, streaming, and machine learning. If you are using the Apache Hadoop ecosystem and looking for an easier option to manage it then Dataproc is your answer. Dataproc automation helps you create clusters quickly, manage them easily, and save money by turning clusters off when you don’t need them. With less time and money spent on administration, you can focus on what matters the most—your DATA!
Key Dataproc Features
Dataproc installs a Hadoop cluster on demand, making it a simple, fast, and cost-effective way to gain insights. It simplifies the traditional cluster management activities and creates a cluster in seconds. Key Dataproc features include:
- Support for open source tools in the Hadoop and Spark ecosystem including 30+ OSS tools
- Customizable virtual machines that scale up and down as needed
- On-demand ephemeral clusters to save cost
- Tight integration with other Google Cloud analytics and security service.
How does Dataproc work?
To move your Hadoop/Spark jobs to Dataproc, simply copy your data into Google Cloud Storage, update your file paths from HDFS to GS and you are ready to go!
Watch this video for more:

Dataproc disaggregates storage and compute. Say an external application is sending logs that you want to analyze, and you store them in a data source. From Cloud Storage the data is used for processing by Dataproc, which then stores it back into Cloud Storage, BigQuery, or Bigtable. You could also use the data for analysis in a notebook and send logs to Cloud Monitoring and Cloud Logging.
Since storage is separate, for a long-lived cluster you could have one cluster per job. To save cost, however, you could also use ephemeral clusters that are grouped and selected by labels. And finally, you can also save costs by using just the right amount of memory, CPU, and disk to fit the needs of your application.
What are the migration scenarios to consider?
Here are four common scenarios that help you decide how to migrate a Hadoop cluster to Dataproc:
- Are you trying to migrate NoSQL workloads?
- Are you processing streaming data?
- Are you doing interactive data analysis or ad hoc querying?
- Are you doing ETL or batch processing?
Question 1: Do you have NoSQL workloads?
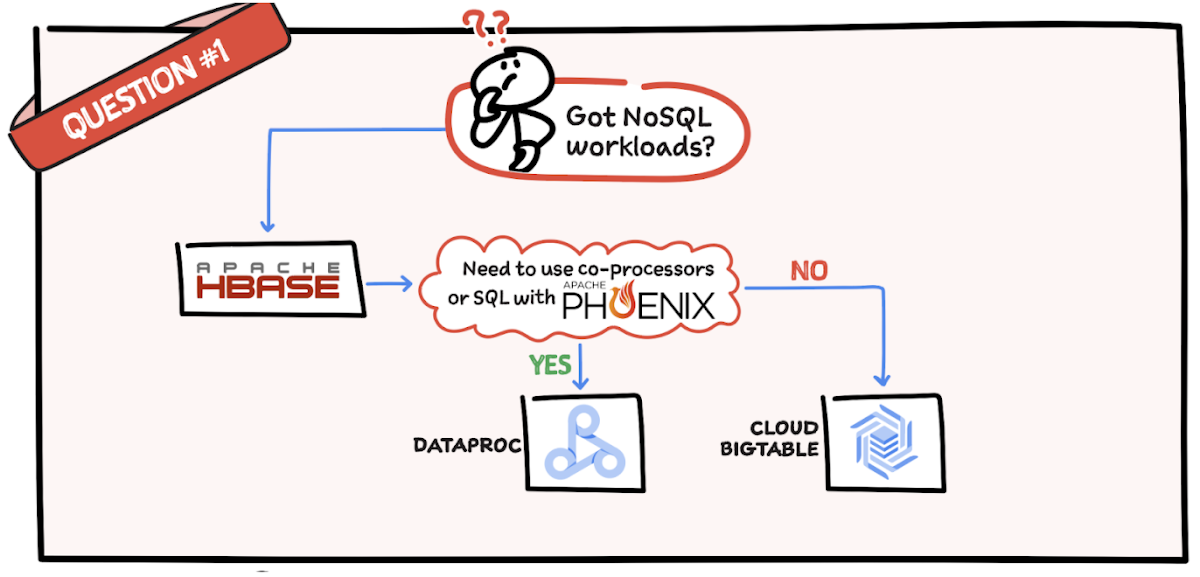
If you are using HBase then check if you need to use co-processors or SQL with Phoenix. If so, Dataproc is the best option. But if you don’t require a co-processor or SQL, then Bigtable is a good choice.
Question 2: Are you processing streaming data?
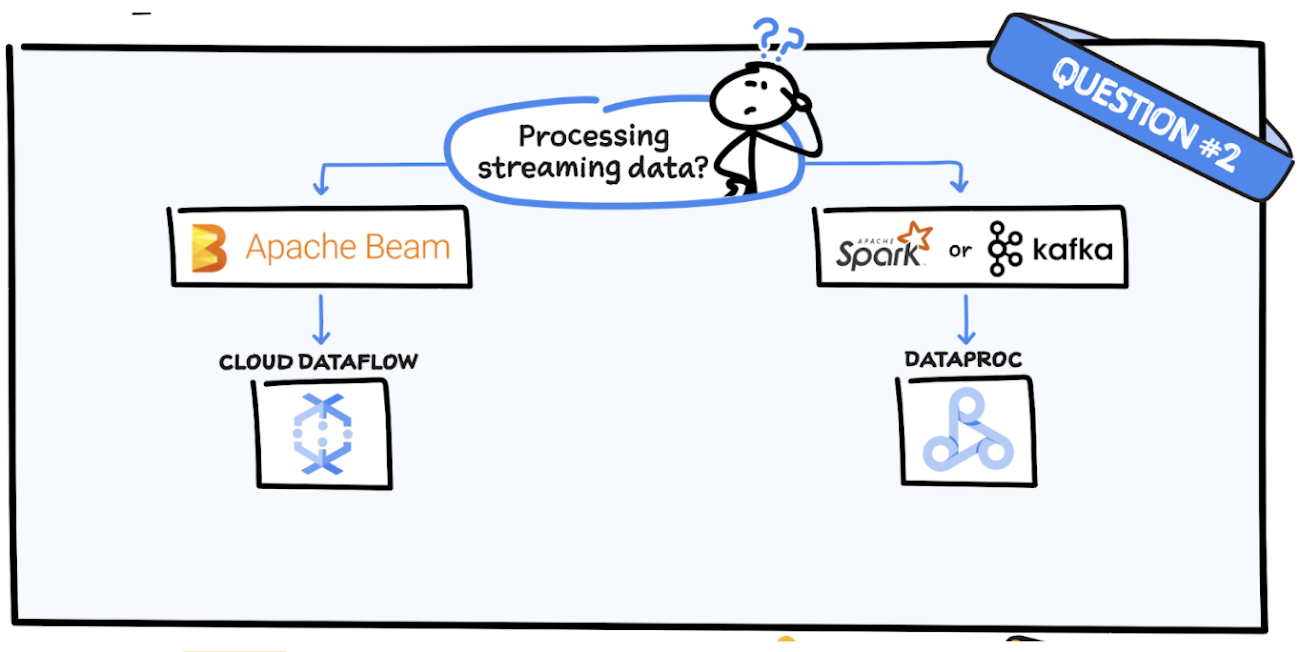
If you’re using Apache Beam it makes sense to use Dataflow because it is based on the Beam SDK. If you are using Spark or Kafka then Dataproc is a good option.
Question 3: Are you doing interactive data analysis or ad hoc querying?
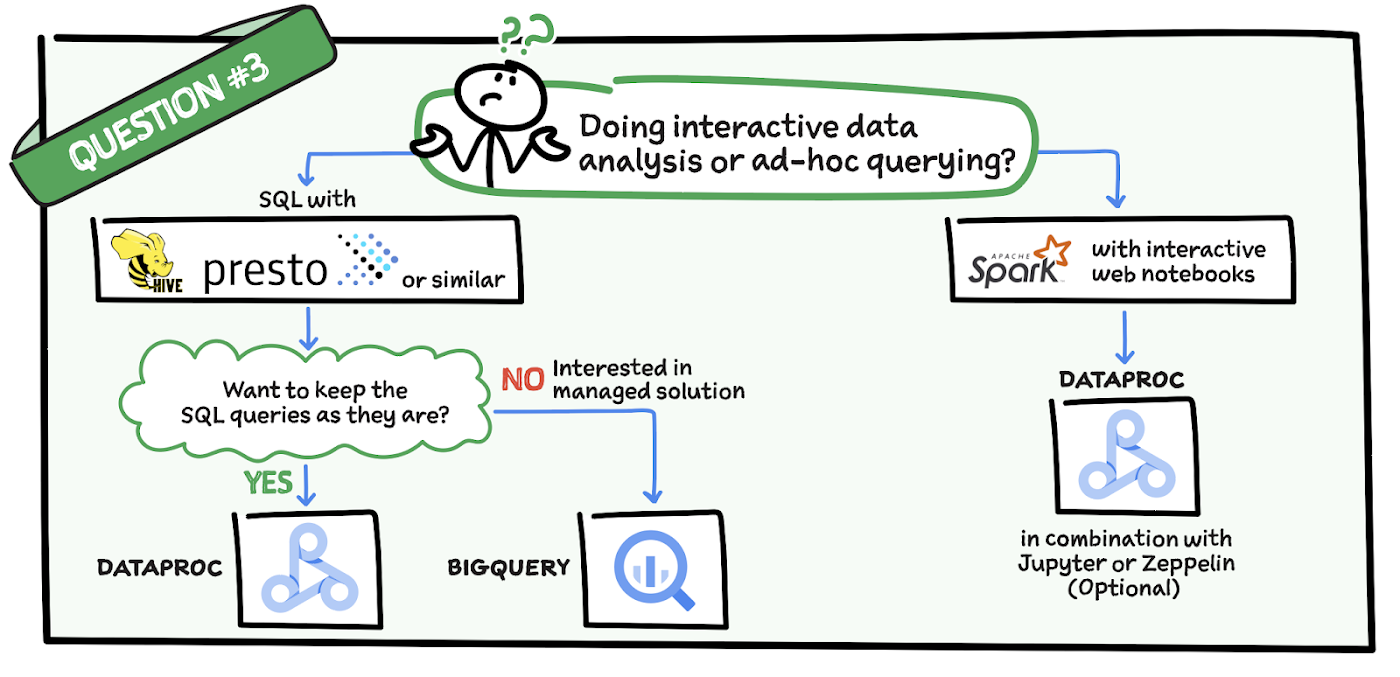
If you are doing interactive data analysis in Spark with interactive notebooks then Dataproc is great in combination with Jupyter Notebook or Zeppelin. If instead you are doing data analysis with SQL in Hive or Presto AND want to keep it that way then Dataproc is a good fit. But if you are interested in a managed solution for your interactive data analysis then you’ll want to look at BigQuery. It is a fully managed data analysis and warehousing solution.
Question 4: Are you doing ETL or batch processing?
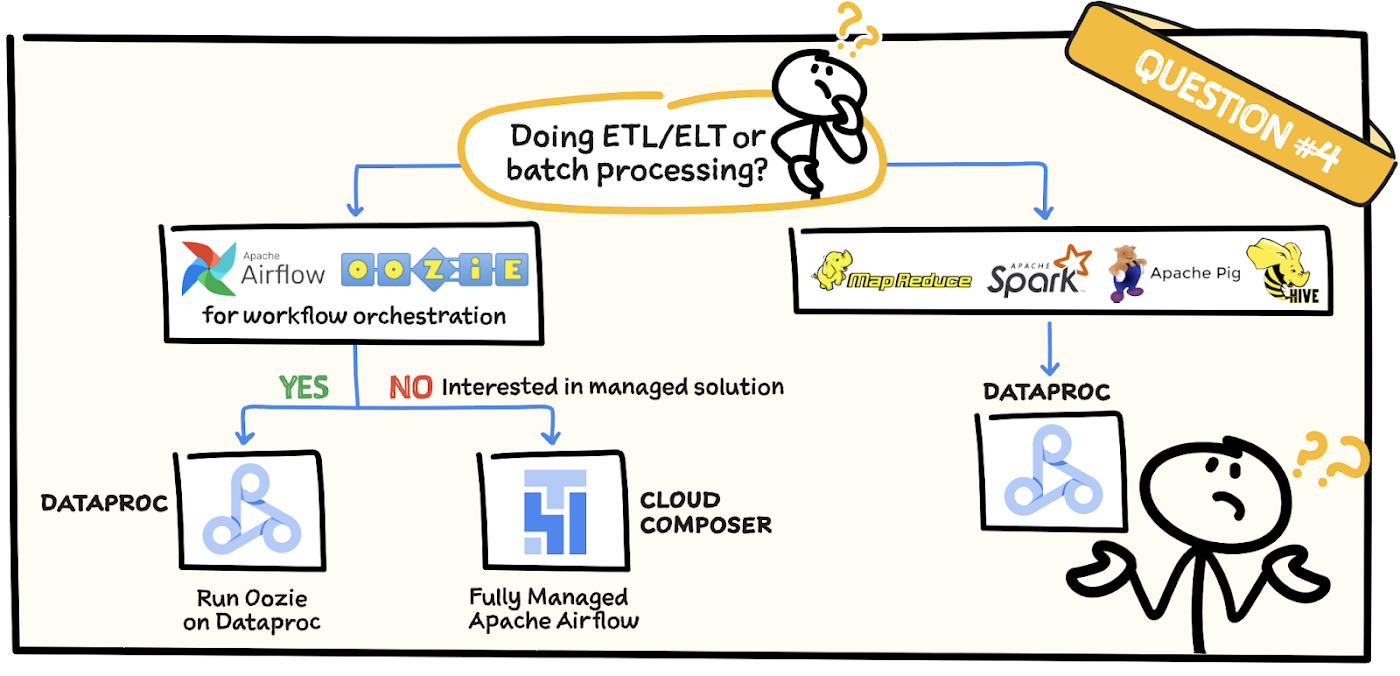
Use Dataproc if you are running ETL or batch processes using MapReduce, Pig, Spark, or Hive. If you’re using a workflow orchestration tool such as Apache Airflow or Oozie and want to keep the jobs as they are, then again Dataproc is great. However, if you prefer a managed solution then take a look at Cloud Composer, which is managed by Apache Airflow.
Conclusion
So there you have it—four different scenarios to plan the migration of your Apache Hadoop cluster to Google Cloud.
For more details, check out the Dataproc product page.
And, for more #GCPSketchnote and similar cloud content follow me on Twitter and Instagram @pvergadia and keep an eye out on thecloudgirl.dev.



