Combining the power of Apache Spark and AI Platform Notebooks with Dataproc Hub
Matthieu Mayran
Solutions Architect
Editor's note: February 7, 2025 – The approach described below has since shifted. Please refer to the documentation for the latest updates.
Apache Spark is commonly used by companies that want to explore large amounts of data and perform additional machine learning (ML)-related tasks at scale. Data scientists often need to examine these large datasets with the help of tools like Jupyter Notebooks, which plug into the scalable processing powerhouse that is Spark and also give them access to their favorite ML libraries. The new Dataproc Hub brings together interactive data research at scale and ML from within the same notebook environment (either from Dataproc or AI Platform) in a secure and centrally managed way.
With Google Cloud, you can use the following products to access notebooks:
- Dataproc is a Google Cloud-managed service for running Spark and Hadoop jobs, in addition to other open source software of the extended Hadoop ecosystem. Dataproc also provides notebooks as an Optional Component and is securely accessible through the Component Gateway. Check out the process for Jupyter notebooks.
- AI Platform Notebooks is a Google Cloud-managed service for JupyterLab environments that run on Deep Learning Compute Engine instances and is accessible through a secure URL provided by Google’s inverting proxy.
Although both of those products provide advanced features to set up notebooks, until now,
- Data scientists either needed to choose between Spark and their favorite ML libraries or had to spend time setting up their environments. This could prove cumbersome and often repetitive. That time could be spent exploring interesting data instead.
- Administrators could provide users with ready-to-use environments but had little means to customize the managed environments based on specific users or groups of users. This could lead to unwanted costs and security management overhead.
Data scientists have told us that they want the flexibility of running interactive Spark tasks at scale while still having access to the ML libraries that they need from within the same notebook and with minimum setup overhead.
Administrators have told us that they want to provide data scientists with an easy way to explore datasets interactively and at scale while still ensuring that the platform meets the costs and security constraints of their company.
We’re introducing Dataproc Hub, a control plane that addresses those needs. Dataproc Hub is built on core Google Cloud products (Cloud Storage, AI Platform Notebooks and Dataproc) and open-source software (JupyterHub, Jupyter and JupyterLab).
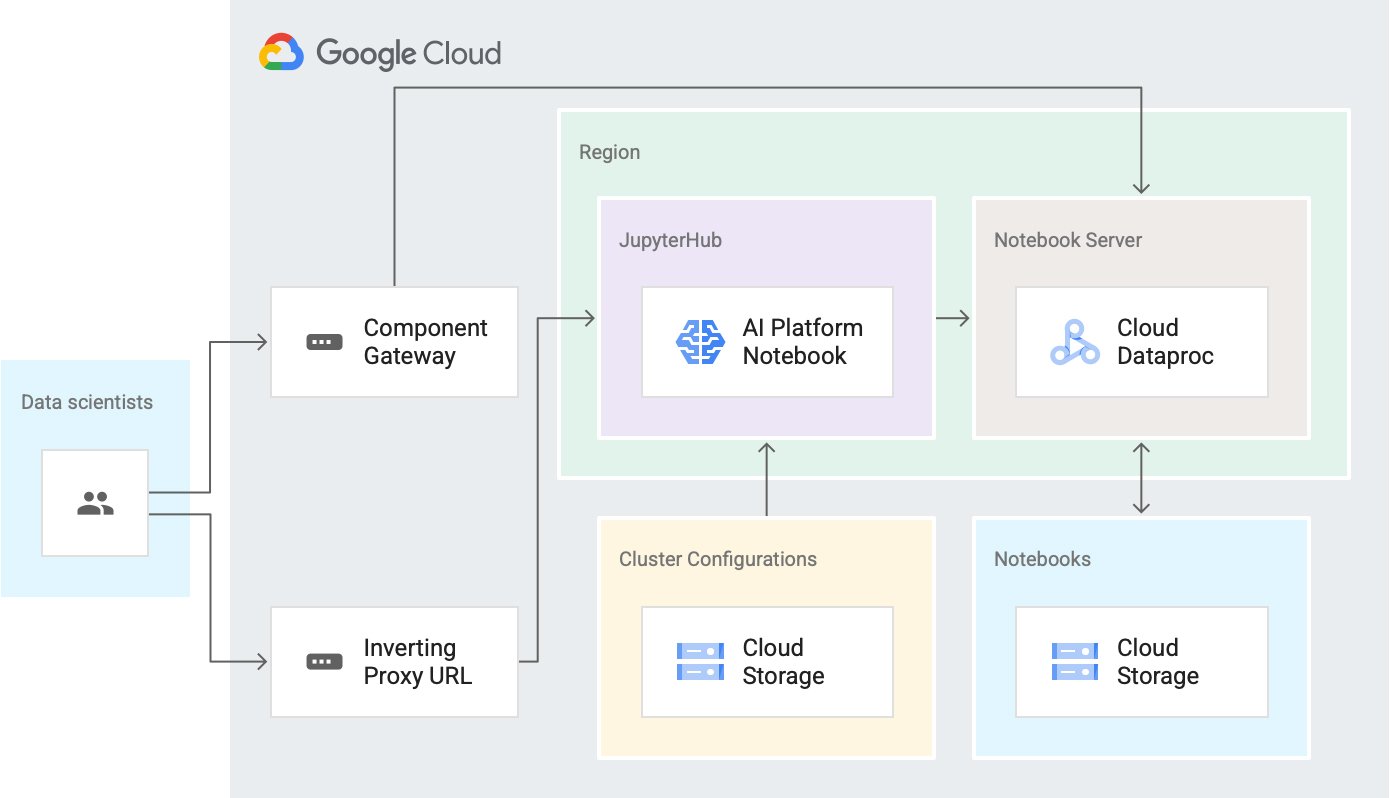
Click to enlarge
By combining those technologies, Dataproc Hub:
- Provides a way for data scientists to quickly select the Spark-based predefined environment that they need without having to understand all the possible configurations and required operations. Data scientists can combine this added simplicity with existing Dataproc advantages that include:
- Agility provided by ephemeral (short-lived or job-scoped, usually) clusters that can start in seconds so data scientists don’t have to wait for resources.
- Scalability: managed by autoscaling policies so scientists can run research on sample data and run tests at scale from within the same notebook.
- Durability: backed by Cloud Storage outside of the Dataproc cluster, which minimizes chances of losing precious work.
- Facilitates the administration of standardized environments to make it easier for both administrators and data scientists to transition to production. Administrators can combine this added security and consistency with existing Dataproc advantages that include:
- Flexibility: implemented by initialization actions that run additional scripts when starting a cluster to provide data scientists with the libraries that they need.
- Velocity: provided by custom images that minimize startup time through pre-install packages.
- Availability: supported by multiple master nodes.
Getting started with Dataproc Hub
To get started with Dataproc Hub today, using the default setup:
1. Go to the Dataproc UI
2. Click on the Notebooks menu in the left panel.
3. Click on NEW INSTANCE.
4. Choose Dataproc Hub from the Smart Analytics Frameworks menu.

5. Create the Dataproc Hub instance that meets your requirements and fits the needs of the group of users that will use it.
6. Wait for the instance creation to finish and click on the OPEN JUPYTERLAB link.

7. This should open a page that shows you a configuration form. If this is working, keep note of the URL of the page that you opened.
8. Share the URL with the group of data scientists that you created the Dataproc Hub instance for. Dataproc Hub identifies the data scientist when they access the secure endpoint and uses that identity to provide them with their own single-user environment.
Predefined configurations
As an administrator, you can add customization options for data scientists. For example, they can select a predefined working environment from a list of configurations that you curated. Cluster configurations are declarative YAML files that you define by following these steps:
- Manually create a reference cluster and export its configuration using the command
gcloud beta dataproc clusters exportCLUSTER - Store the YAML configuration files in a Cloud Storage bucket accessible by the identity of the instance that runs the Dataproc Hub interface.
- Repeat this for all the configurations that you want to create.
- Sets an environment variable with all the Cloud Storage URI of the relevant YAML files when creating the Dataproc Hub instance.
Note: If you provide configurations, a data scientist who accesses a Dataproc Hub endpoint for the first time will see the configuration form mentioned in Step 6 above. If they have a notebook environment running at the URL, Dataproc Hub will redirect them directly to their notebook.
For more details about setting up and using Dataproc Hub, check out the Dataproc Hub documentation.
Security overview
Cloud Identity and Access Management (Cloud IAM) is central to most Google Cloud products and provides two main features for our purposes here:
- Identity: defines who is trying to perform an action.
- Access: specifies whether an identity is allowed to perform an action.
To access the Dataproc Hub, users need the notebooks.instances.use permission.
In the current version of Dataproc Hub, all spawned clusters use the same customizable service account, set up by following these steps:
- An administrator provides a service account that will act as a common identity for all spawn Dataproc clusters. If not set, the default service account for Dataproc clusters is used.
- When a user spawns their notebook environment on Dataproc, the cluster starts with that identity. Users do not need the roles/iam.serviceAccountUser role on that service account because Dataproc Hub is the one spawning the cluster.
Next steps
- Get familiar with the Dataproc spawner to learn how to spawn notebook servers on Dataproc.
- Get familiar with the Dataproc Hub example code in Github to learn how to deploy and further customize the product to your requirements.
- Read the Dataproc Hub product documentation to learn how to quickly launch a Dataproc Hub instance.
- Use Dataproc custom images in order to minimize the cluster startup time. You can automate this step by using the image provided by the Cloud Builder community. You can then provide the image reference in your cluster configuration YAML files.

