このページは Apigee と Apigee ハイブリッドに適用されます。
Apigee Edge のドキュメントを表示する。

Operations Anomalies ダッシュボードで異常が見つかった場合は、API Monitoring ダッシュボードで詳しく調査できます。ダッシュボードには、最新の API データのグラフと表が表示されます。これにより、異常発生時に API で起きていたことについて具体性の高い情報を得ることができます。
次のセクションでは、ダッシュボードで異常を調査する方法を説明する例を紹介します。
例: 障害コードの異常
たとえば、Operations Anomalies ダッシュボードを表示している際に、次に示す異常が確認されたとします。

異常の詳細を表示するには、[Summary] 列の [Investigate] をクリックします。これにより、次に示すように API Monitoring Investigate ダッシュボードが表示されます。
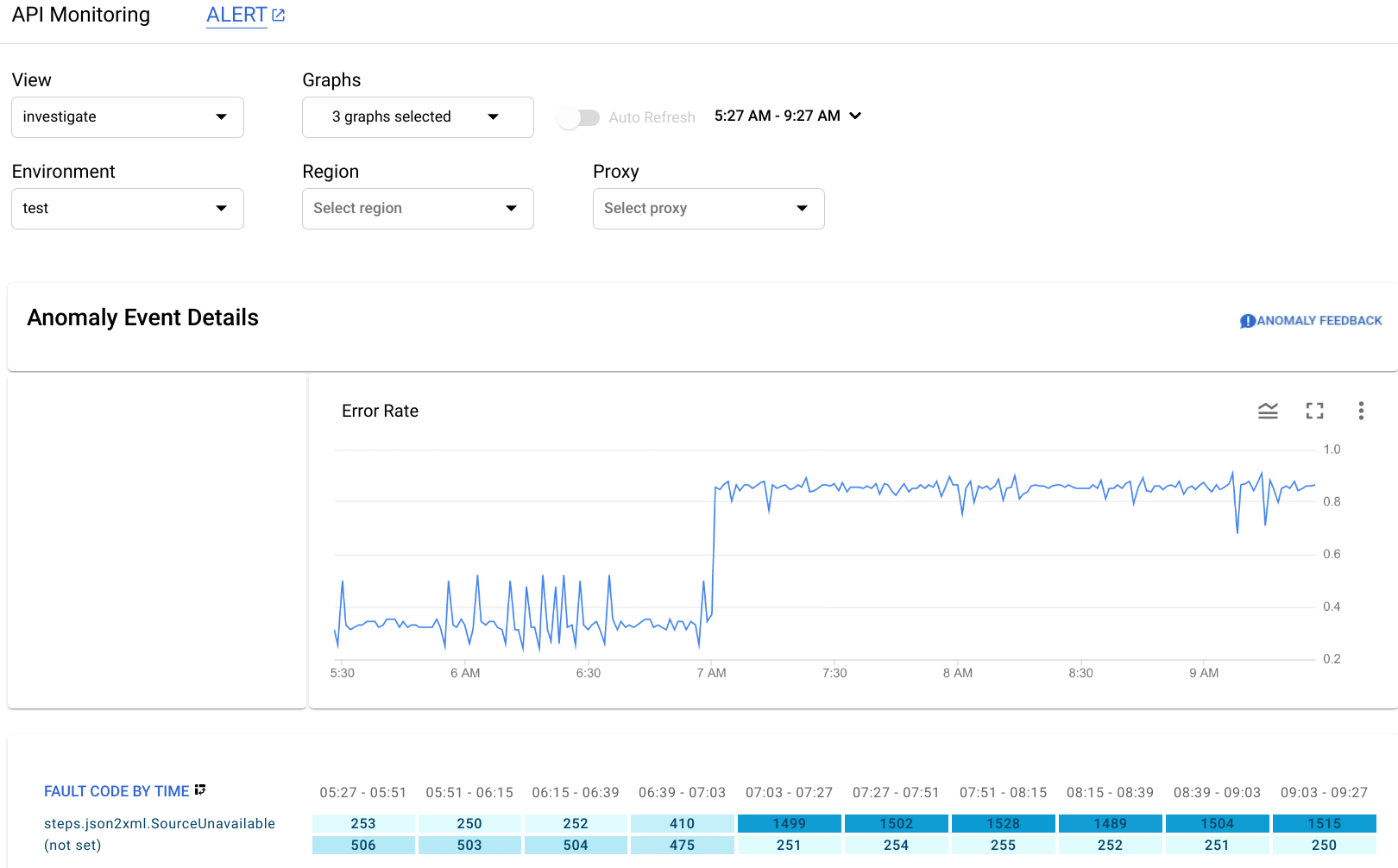
[Anomaly Event Details] ペインにエラー率のタイムラインが表示されます。グラフからは、午前 7 時を過ぎたころに異常が発生し、0.4 未満だったエラー率が 0.8 を超えたことがわかります。
タイムライン グラフのエラー率には、すべての障害コードのエラーが含まれます。さまざまな障害コードのエラーの内訳を確認するには、タイムラインの下に表示される [FAULT CODE BY TIME] グラフを調べます。
注: 現在、[FAULT CODE BY TIME] グラフが表示されていない場合は、[Graphs] メニューで [Fault Code] を選択して表示します。
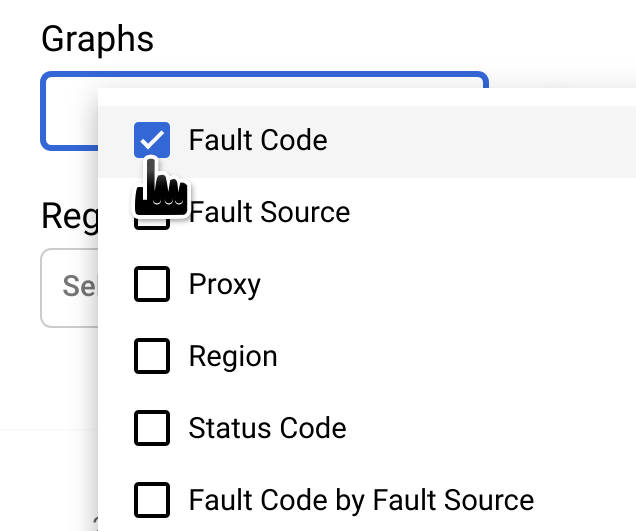
[FAULT CODE BY TIME] グラフの丸で囲った列は、異常があった時刻を含む時間間隔を表します。
注: グラフに表示されるデータと、異常が報告された時刻との間にわずかな差異が見られるのは正常な状態です。
![[FAULT CODE BY TIME] グラフの表示。](https://cloud.google.com/static/apigee/docs/aapi-ops/images/anomaly-investigate-dashboard-circle.png?hl=ja)
間隔 07:03 - 07:27 では、障害コード steps.json2xml.SourceUnavailable(JSON to XML ポリシー メッセージ ソースが利用できないと返されるエラーコード)を含むレスポンスが 1,499 件あったことがわかります。異常は、この障害コードにより引き起こされました。対照的に、それ以前の 4 つの間隔では、この障害コードを含むレスポンスは平均約 291 件でした。したがって、1,499 件に跳ね上がることは、間違いなく異例の出来事でした。
SourceUnavailable エラー メッセージの詳細については、JSON to XML ポリシーの実行時エラーの解決方法をご覧ください。
この時点で、異常の原因の調査を続ける方法には、次の 2 つがあります。
異常時の障害コードのデータを、[FAULT CODE BY TIME] グラフの異常が見られるセルをクリックしてドリルダウンできます。
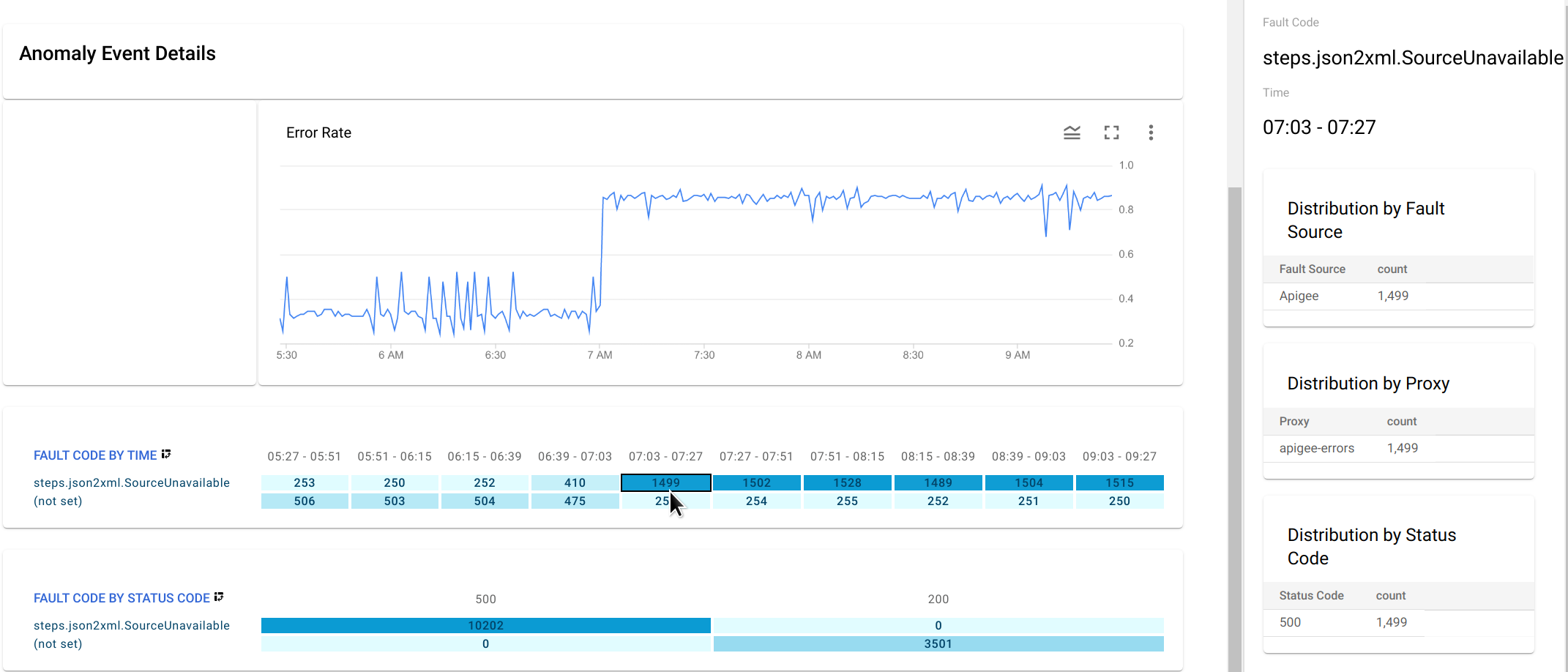
これによって、右側のペインに、障害ソース、プロキシ、ステータス コード別の
steps.json2xml.SourceUnavailableの分布テーブルが表示されます。この例では、すべての障害コードが同一の障害ソース、プロキシ、ステータス コードから発生しているため、テーブルには追加情報は表示されません。しかし、他の状況では、分布テーブルから異常が発生している場所と原因を特定できます。
- 異常のアラートを作成し、通知を設定します。これにより、今後同様のイベントが発生するたびに、AAPI Ops からメッセージが届きます。