このページは Apigee と Apigee ハイブリッドに適用されます。
Apigee Edge のドキュメントはこちらをご覧ください。

異常とは
異常とは、通常と異なる、または予期しない API データのパターンのことです。たとえば、次の API エラー率のグラフをご覧ください。
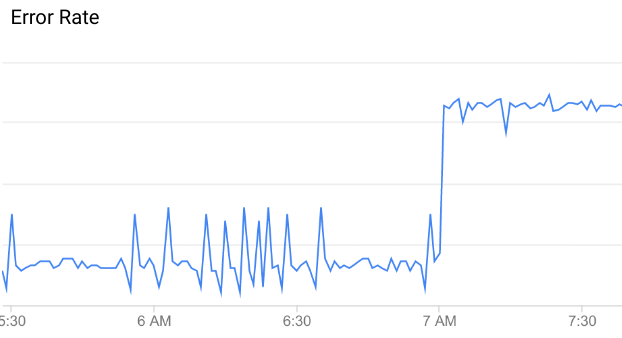
ご覧のように、午前 7 時前後にエラー率が急激に上昇しています。その時点までのデータと比較すると、この上昇は、異常として分類するのに十分なほど通常のパターンを逸脱していると言えます。
ただし、API データのすべての変化が異常にあたるわけではありません。その多くは単なる不規則変動です。たとえばエラー率に関しては、異常に至るまでに比較的小さな変動が見られる場合がありますが、そうした変動は真の異常と呼べるほど重大ではありません。
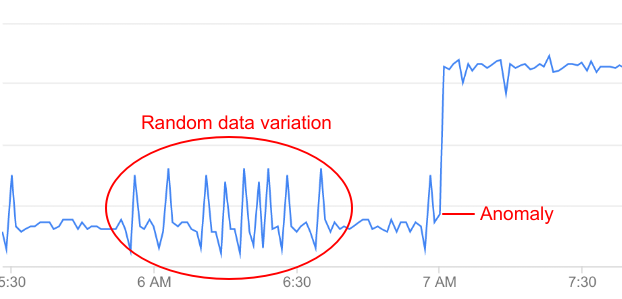
AAPI Ops は、API データを継続的にモニタリングし、統計的な分析を行い、真の異常をデータの不規則変動と区別します。
異常検出を使用しない場合は、各異常を独自に検出するためのしきい値を選択する必要があります(しきい値とは、異常をトリガーするために達する必要がある、エラー率などの一定の数値のことです)。また、最新のデータに基づいて、しきい値を最新の状態に保つ必要もあります。これに対して、AAPI-Ops では、最新のデータパターンに基づいて最適な異常しきい値が選択されます。
AAPI は、上記のような異常を検出すると、Anomaly Events ダッシュボードに異常の詳細を表示します。この時点で、API Monitoring ダッシュボードで異常値を調べ、必要に応じて適切な処置を講じることができます。また、同様のイベントが将来発生した場合にアラートを通知することもできます。
検出された異常には、次の情報が含まれます。
- プロキシのレイテンシや HTTP エラーコードなど、異常の原因となった指標。
- 異常の重大度。重大度は、モデルの信頼レベルに基づいて、軽微(slight)、中程度(moderate)、重大(severe)のいずれかになります。低い信頼度は、重大度が軽微であることを示し、信頼度が高い場合は、重大度が重大であることを示します。
異常の種類
Apigee では、次の種類の異常を自動的に検出します。
- 組織、環境、リージョン レベルでの HTTP 503 エラーの増加
- 組織、環境、リージョン レベルでの HTTP 504 エラーの増加
- 組織、環境、リージョン レベルでのすべての HTTP 4xx または 5xx エラーの増加
- 組織、環境、リージョン レベルでの、90 パーセンタイル(p90)に位置する合計レスポンス レイテンシの増加
異常検出の仕組み
異常検出には、次の段階を伴います。
モデルのトレーニング
異常検出では、過去の時系列データから API プロキシの動作のモデルをトレーニングします。モデルのトレーニングに、ユーザー側で行う操作は特にありません。過去 6 時間分の API データから、Apigee が自動的にモデルを作成してトレーニングします。したがって、異常をログに記録するには、API プロキシでモデルをトレーニングするための少なくとも 6 時間分のデータが Apigee に必要です。
トレーニングの目的は、モデルの精度を向上させることにあり、その効果は過去のデータでテストできます。モデルの精度をテストする最も簡単な方法は、偽陽性と偽陰性の合計を予測イベントの合計数で割って得られるエラー率を計算することです。
異常イベントのロギング
ランタイムでは、Apigee の異常検出は、API プロキシの現在の動作をモデルによって予測された動作と比較します。異常検出は次に、運用指標がいつ予測値を超えるかを特定の信頼度で判断します。たとえば、いつ 5xx エラーの割合がモデルで予測されたレートを超えるかなどです。
Apigee が異常を検出すると、自動的に Anomaly Events ダッシュボードにイベントが記録されます。ダッシュボードに表示されるイベントのリストには、検出されたすべての異常と、トリガーされたアラートが含まれます。