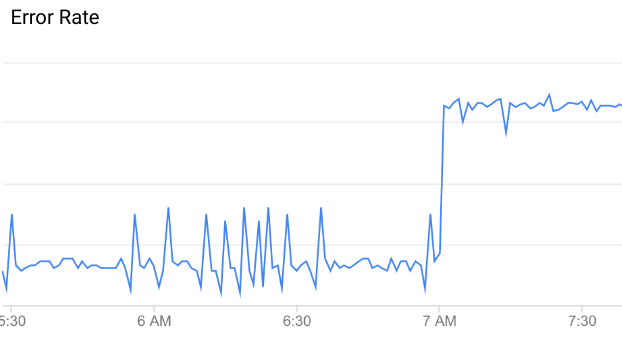
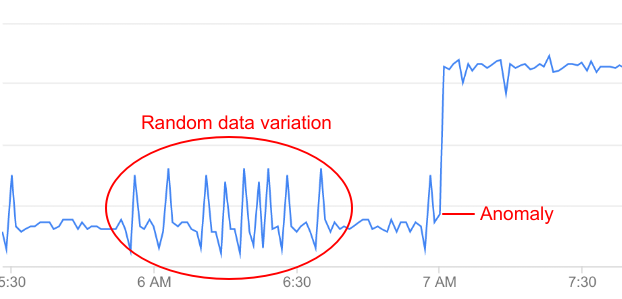
[[["わかりやすい","easyToUnderstand","thumb-up"],["問題の解決に役立った","solvedMyProblem","thumb-up"],["その他","otherUp","thumb-up"]],[["わかりにくい","hardToUnderstand","thumb-down"],["情報またはサンプルコードが不正確","incorrectInformationOrSampleCode","thumb-down"],["必要な情報 / サンプルがない","missingTheInformationSamplesINeed","thumb-down"],["翻訳に関する問題","translationIssue","thumb-down"],["その他","otherDown","thumb-down"]],["最終更新日 2025-08-18 UTC。"],[[["\u003cp\u003eThis content explains how Apigee and Apigee hybrid use anomaly detection to identify unusual API data patterns, distinguishing them from random fluctuations.\u003c/p\u003e\n"],["\u003cp\u003eAnomaly detection in Apigee involves training models from historical API data to establish expected behavior, and it automatically sets anomaly thresholds, unlike manual threshold setup.\u003c/p\u003e\n"],["\u003cp\u003eApigee detects increases in specific HTTP errors (503, 504, and all 4xx/5xx) and total response latency (90th percentile) at various levels (organization, environment, and region).\u003c/p\u003e\n"],["\u003cp\u003eWhen an anomaly is detected, Apigee logs the event, including details like the affected metric and severity level, in the Anomaly Events dashboard, where you can further investigate the issue.\u003c/p\u003e\n"]]],[],null,["*This page\napplies to **Apigee** and **Apigee hybrid**.*\n\n\n*View [Apigee Edge](https://docs.apigee.com/api-platform/get-started/what-apigee-edge) documentation.*\n\n| **Important:** \"Anomaly Detection\" describes the Advanced API Operations Anomaly Detection functionality, which is available in the Classic Apigee UI. This functionality is comparable to the \"Operations Anomalies\" functionality in [Apigee UI in Cloud console](https://console.cloud.google.com/apigee). Both are available at this time. See [Operations Anomalies overview](/apigee/docs/api-platform/analytics/operations-anomalies-overview) for information on the Operations Anomalies functionality.\n\nWhat is an anomaly?\n\nAn *anomaly* is an unusual or unexpected API data pattern. For example,\ntake a look at the graph of API error rate below:\n\nAs you can see, the error rate suddenly jumps up at around 7 AM. Compared\nto the data leading up to that time, this increase is unusual enough to be classified as an anomaly.\n\nHowever, not all variations in API data represent anomalies: most\nare simply random fluctuations. For example, you can see some relatively minor variations in\nerror rate leading up to the anomaly, but these are not significant enough to be called a true\nanomaly.\n\nAAPI Ops continually monitors API data and performs statistical analysis to distinguish true\nanomalies from random fluctuations in the data.\n\nWithout anomaly detection, you need to choose a *threshold* for detecting each\nanomaly yourself. (A threshold is a value that a quantity, such as error rate, must reach to trigger\nan anomaly.) You also need to keep the threshold values up to date, based on the latest data.\nBy contrast, AAPI-Ops chooses the best anomaly thresholds for you, based on recent\ndata patterns.\n\nWhen AAPI detects an anomaly like the one shown above, it displays the anomaly details in the\n[Anomaly Events dashboard](/apigee/docs/aapi-ops/anomaly-detect-ui).\nAt this point, you can investigate the anomaly in the API Monitoring dashboards and\ntake appropriate action if necessary. You can also\ncreate an alert to notify you if similar events occur in future.\n\nA detected anomaly includes the following information:\n\n- The metric that caused the anomaly, such as proxy latency or an HTTP error code.\n- The severity of the anomaly. The severity can be slight, moderate, or severe, based on its confidence level in the model. A low confidence level indicates that the severity is slight, while a high confidence level indicates that it is severe.\n\nAnomaly types\n\nApigee automatically detects the following types of anomalies:\n\n- Increase in HTTP 503 errors at the organization, environment, and region level\n- Increase in HTTP 504 errors at the organization, environment, and region level\n- Increase in all HTTP 4xx or 5xx errors at the organization, environment, and region level\n- Increase in the total response latency for the 90th percentile (p90) at the organization, environment, and region level\n\nHow anomaly detection works\n\nAnomaly detection involves the following stages:\n\n- [Train models](#train-models)\n- [Log anomaly events](#log-anomaly-events)\n\nTrain models\n\nAnomaly detection works by training a model of the behavior of your API proxies from historical\ntime-series data. There is no action required on your part to train the model. Apigee automatically\ncreates and trains models for you from the previous six hours of API data.\nTherefore, Apigee requires a minimum of six hours of data on an API proxy to train the model before\nit can log an anomaly.\n\nThe goal of training is to improve the accuracy of the model, which can then be tested\non historical data. The simplest\nway to test a model's accuracy is to calculate its *error rate*---the\nsum of false positives and false negatives, divided by the total number of predicted events.\n\nLog anomaly events\n\nAt runtime, Apigee anomaly detection compares the current behavior of your API proxies with the behavior\npredicted by the model. Anomaly detection can then determine, with a specific confidence level,\nwhen an operational metric is exceeding the predicted value. For example, when the rate of 5xx errors\nexceeds the rate predicted by the model.\n\nWhen Apigee detects an anomaly, it automatically logs the event in the\n[Anomaly Events\ndashboard](/apigee/docs/aapi-ops/anomaly-detect-ui). The list of events displayed in the dashboard includes all\ndetected anomalies, as well as triggered alerts."]]