このページは Apigee と Apigee ハイブリッドに適用されます。
Apigee Edge のドキュメントはこちらをご覧ください。

Operations Anomalies の概要
Operations Anomalies では、最近のデータパターンに基づいて、API の異常または予期しない API データパターンを特定します。たとえば、この API エラー率のグラフでは、午前 7 時前後にエラー率が急激に上昇しています。その時点までのデータと比較すると、この上昇は、異常として分類するのに十分なほど通常の傾向を逸脱しています。
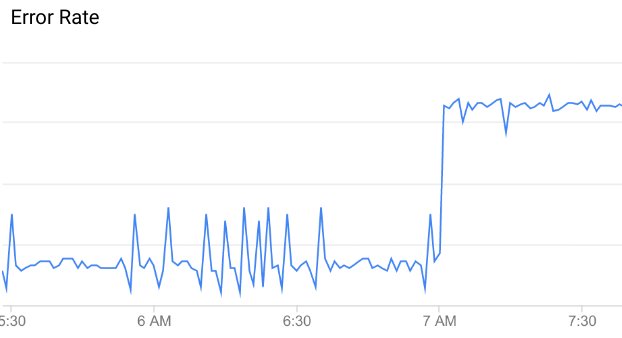
API データのすべての変化が異常にあたるわけではありません。多くは単なる不規則な変動です。たとえば、エラー率には異常の直前まで小さな変動が見られますが、それらは異常として分類するには十分な変動ではありません。
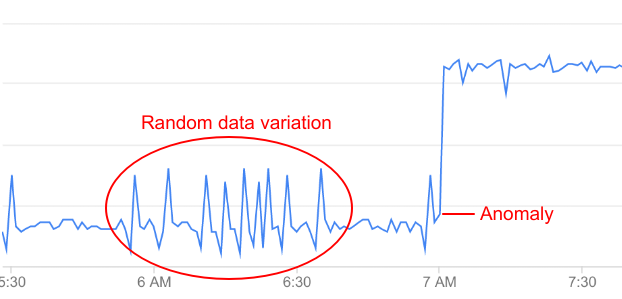
Operations Anomalies では、API データを継続的にモニタリングし、統計的な分析を行い、真の異常をデータの不規則変動と区別します。
Operations Anomalies では、次の種類の異常を自動的に検出します。
- 組織、環境、リージョン レベルでの HTTP 503 エラーの増加
- 組織、環境、リージョン レベルでの HTTP 504 エラーの増加
- 組織、環境、リージョン レベルでのすべての HTTP 4xx または 5xx エラーの増加
- 組織、環境、リージョン レベルでの、90 パーセンタイル(p90)に位置する合計レスポンス レイテンシの増加
検出された異常には、次の情報が含まれます。
- プロキシのレイテンシや HTTP エラーコードなど、異常の原因となった指標。
- 異常の重大度。重大度は、モデルの信頼レベルに基づいて、軽微(slight)、中程度(moderate)、重大(severe)のいずれかになります。低い信頼度は、重大度が軽微であることを示し、信頼度が高い場合は、重大度が重大であることを示します。
Operations Anomalies を使用するための前提条件
Operations Anomalies を使用するには:
- 組織で AAPI Ops アドオンを有効にする必要があります。組織で AAPI Ops を有効にするをご覧ください。
- Operations Anomalies のユーザーには、AAPI Ops に必要なロールが付与されていなければなりません。
- ダッシュボードで異常を調査するユーザーにも
roles/logging.viewerロールが必要です。
検出された Operations Anomalies を表示する
Operations Anomalies が異常を検出すると、Operations Anomalies ダッシュボードに異常の詳細が表示されます。API Monitoring ダッシュボードで異常値を調べ、必要に応じて適切な処置を講じることができます。また、同様のイベントが将来発生した場合にアラートを作成して通知することもできます。
Apigee UI の Operations Anomalies ダッシュボードは、検出されたオペレーションの異常に関する主要な情報ソースです。このダッシュボードには、最近の異常の一覧が表示されます。
Operations Anomalies ダッシュボードを開くには:
Google Cloud コンソールで、[アナリティクス] > [オペレーションの異常] ページに移動します。
- モニタリングする組織に切り替えます。
Operations Anomalies ダッシュボードが表示されます。
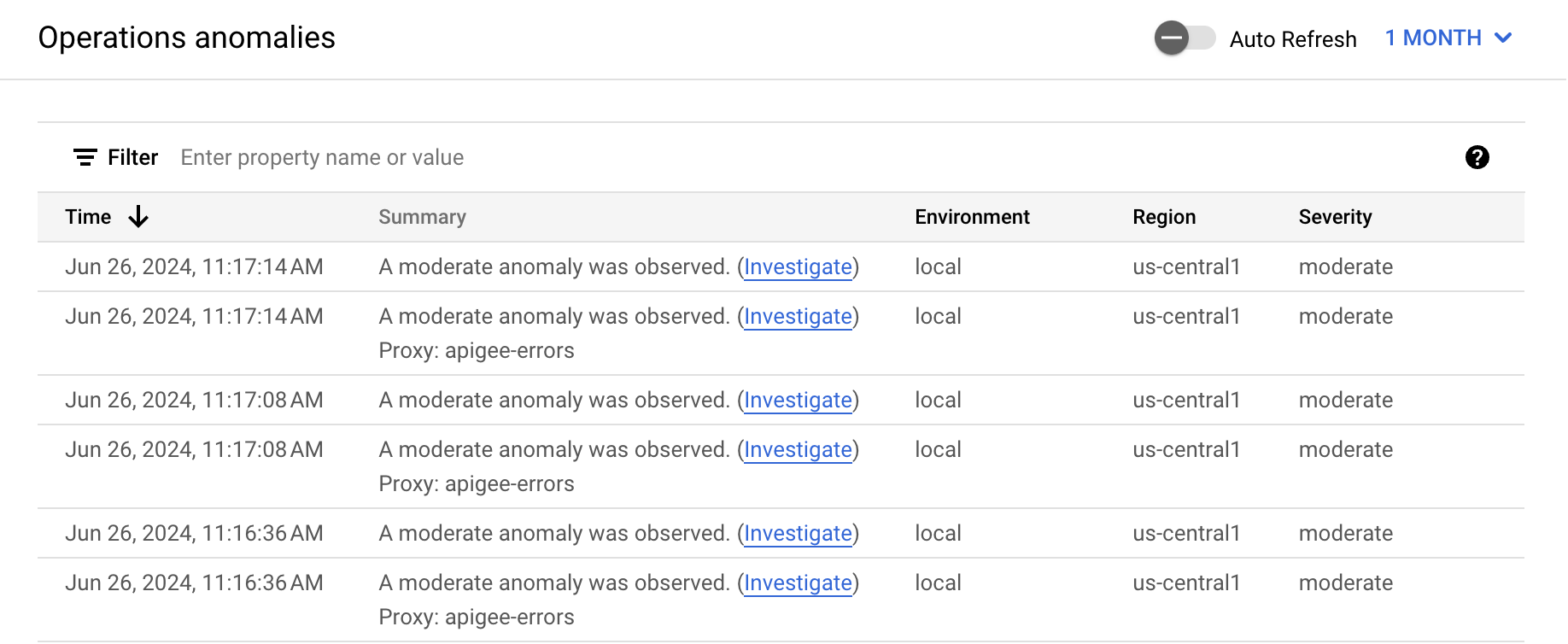
デフォルトでは、過去 1 時間に発生した異常がダッシュボードに表示されます。 この期間中に異常が検出されなかった場合、ダッシュボードには行が表示されません。ダッシュボードの右上にある時間範囲メニューから、より大きな時間範囲を選択できます。
テーブルの各行は検出された異常に対応し、次の情報が表示されます。
- 異常の発生日時。
- 異常の発生元となったプロキシや、異常をトリガーした障害コードなど、異常に関する簡単な概要。
- 異常が発生した環境。
- 異常が発生したリージョン。
- 異常イベントの重大度: 低、中、高。重大度は、イベントが偶然に発生する可能性の低さに関する統計的測定値(p 値)に基づいています(イベントが偶然に発生する可能性が低いほど、重大度が高くなります)。
API Monitoring ダッシュボードで異常を調査することもできます。このダッシュボードには、最新の API トラフィック データのさまざまなグラフが表示されます。
異常検出の仕組み
異常検出には、次の段階を伴います。
モデルのトレーニング
Operations Anomalies は、過去の時系列データから API プロキシの動作のモデルをトレーニングします。モデルのトレーニングに、ユーザー側で行う操作は特にありません。過去 6 時間分の API データから、Apigee が自動的にモデルを作成してトレーニングします。したがって、異常をログに記録するには、API プロキシでモデルをトレーニングするための少なくとも 6 時間分のデータが Apigee に必要です。
トレーニングの目的は、モデルの精度を向上させることにあり、その効果は過去のデータでテストできます。モデルの精度をテストする最も簡単な方法は、偽陽性と偽陰性の合計を予測イベントの合計数で割って得られるエラー率を計算することです。
異常イベントのロギング
ランタイムでは、Operations Anomalies は、API プロキシの現在の動作をモデルによって予測された動作と比較します。Operations Anomalies は、運用指標が予測値を超えた場合に、特定の信頼度のしきい値で判断できます。たとえば、いつ 5xx エラーの割合がモデルで予測されたレートを超えるかなどです。
Apigee が異常を検出すると、自動的に Operations Anomalies ダッシュボードにイベントが記録されます。ダッシュボードに表示されるイベントのリストには、検出されたすべての異常と、トリガーされたアラートが含まれます。