이 가이드에서는 Google Cloud에 고가용성(HA) SAP HANA 시스템을 배포하기 전에 알고 있어야 하는 옵션, 권장사항, 일반 개념을 간략하게 설명합니다.
이 가이드는 사용자가 SAP HANA 고가용성 시스템을 구현하는 데 일반적으로 필요한 개념과 방법을 이미 이해하고 있다고 가정하고 작성되었습니다. 따라서 이 가이드에서는 주로 Google Cloud에서 이러한 시스템을 구현하는 데 알아야 하는 정보를 중점적으로 설명합니다.
SAP HANA HA 시스템을 구현하는 데 필요한 일반적인 개념과 방법에 대한 상세 설명은 다음을 참조하세요.
- SAP 권장사항 문서 Linux에서 SAP NetWeaver 및 SAP HANA용 고가용성 구축
- SAP HANA 문서
이 계획 가이드에서는 SAP HANA의 HA만 다루고 애플리케이션 시스템의 HA는 다루지 않습니다. SAP NetWeaver의 HA에 대한 자세한 내용은 Google Cloud기반 SAP NetWeaver의 고가용성 계획 가이드를 참고하세요.
이 가이드는 SAP에서 제공하는 문서를 대체하지 않습니다.
Google Cloud기반 SAP HANA용 고가용성 옵션
SAP HANA의 고가용성 구성을 설계할 때 인프라 수준이나 소프트웨어 수준에서 장애를 처리할 수 있는 Google Cloud 및 SAP 기능의 조합을 사용할 수 있습니다. 다음 표에서는 고가용성을 제공하는 데 사용되는 SAP 및 Google Cloud 기능에 대해 설명합니다.
| 기능 | 설명 |
|---|---|
| Compute Engine 라이브 마이그레이션 |
Compute Engine은 기본 인프라의 상태를 모니터링하고 인프라 유지보수 이벤트 발생 시 인스턴스를 자동으로 마이그레이션합니다. 사용자가 개입할 필요가 없습니다. Compute Engine은 가능하면 마이그레이션이 진행되는 동안 인스턴스를 실행 상태로 유지합니다. 중요한 서비스 중단 상황이 발생할 경우 인스턴스가 중단된 후 다시 사용 가능해질 때까지 약간의 지연이 있을 수 있습니다. 멀티 호스트 시스템에서 배포 가이드에 사용된 `/hana/shared` 볼륨 같은 공유 볼륨은 마스터 호스트를 호스팅하는 VM에 연결된 영구 디스크이며 작업자 호스트에 NFS 마운트됩니다. 마스터 호스트의 라이브 마이그레이션 중에는 일시적으로 NFS 볼륨에 액세스할 없습니다. 마스터 호스트가 다시 시작되면 NFS 볼륨이 모든 호스트에서 다시 작동하고 정상 작동이 자동으로 다시 시작됩니다. 복구된 인스턴스는 인스턴스 ID, 비공개 IP 주소, 모든 인스턴스 메타데이터와 스토리지 등에서 원본 인스턴스와 동일합니다. 기본적으로 표준 인스턴스는 라이브 마이그레이션을 할 수 있도록 설정되어 있습니다. 이 설정을 변경하지 않는 것이 좋습니다. 자세한 내용은 라이브 마이그레이션을 참조하세요. |
| Compute Engine 자동 다시 시작 |
유지보수 이벤트가 있을 때 인스턴스가 종료되도록 설정되어 있거나 기본 하드웨어 문제로 인스턴스가 충돌하는 경우 Compute Engine이 인스턴스를 자동으로 다시 시작하도록 설정할 수 있습니다. 기본적으로 인스턴스는 자동으로 다시 시작되도록 설정되어 있습니다. 이 설정을 변경하지 않는 것이 좋습니다. |
| SAP HANA 서비스 자동 다시 시작 |
SAP HANA 서비스 자동 다시 시작은 SAP에서 제공하는 장애 조치 솔루션입니다. SAP HANA에는 다양한 활동을 위해 항상 실행되는 여러 서비스가 구성되어 있습니다. 소프트웨어 장애나 사용자 오류로 서비스 사용이 중지되면 SAP HANA 서비스 자동 다시 시작 워치독 기능이 해당 서비스를 자동으로 다시 시작합니다. 서비스가 다시 시작되면 모든 필요한 데이터가 다시 메모리에 로드되고 작동이 다시 시작됩니다. |
| SAP HANA 백업 |
SAP HANA 백업은 데이터베이스를 과거 특정 시점으로 재구성하는 데 사용할 수 있는 데이터베이스의 데이터 복사본을 만듭니다. Google Cloud에서 SAP HANA 백업을 사용하는 방법에 대한 자세한 내용은 SAP HANA 운영 가이드를 참고하세요. |
| SAP HANA 스토리지 복제 |
SAP HANA 스토리지 복제는 특정 하드웨어 파트너를 통해 스토리지 수준의 재해 복구 지원을 제공합니다. SAP HANA 스토리지 복제는 Google Cloud에서 지원되지 않습니다. 대신 Compute Engine 영구 디스크 스냅샷을 사용할 수 있습니다. 영구 디스크 스냅샷을 사용하여 Google Cloud에서 SAP HANA 시스템을 백업하는 방법에 대한 자세한 내용은 SAP HANA 운영 가이드를 참고하세요. |
| SAP HANA 호스트 자동 장애 조치 |
SAP HANA 호스트 자동 장애 조치는 수평 확장 시스템에 1개 이상의 대기 SAP HANA 호스트가 필요한 로컬 장애 복구 솔루션입니다. 기본 호스트 중 하나가 실패하면 호스트 자동 장애 조치에서 자동으로 대기 호스트를 온라인 상태로 만들고 실패한 호스트를 대기 호스트로 다시 시작합니다. 자세한 내용은 다음을 참고하세요. |
| SAP HANA 시스템 복제 |
SAP HANA 시스템 복제를 사용하면 고가용성 또는 재해 복구 상황 발생 시 기본 시스템에 사용할 1개 이상의 시스템을 구성할 수 있습니다. 성능 및 장애 조치 시간 측면에서 사용자의 요구사항을 충족하도록 복제를 조정할 수 있습니다. |
| SAP HANA 빠른 재시작 옵션(권장) |
SAP HANA 빠른 다시 시작은 SAP HANA가 종료되지만 운영체제는 계속 실행되는 경우 다시 시작하는 시간을 줄입니다. SAP HANA는 SAP HANA 영구 메모리 기능을 활용하여 SAP HANA 빠른 재시작 옵션 사용에 대한 자세한 내용은 고가용성 배포 가이드를 참조하세요. |
| SAP HANA HA/DR 제공업체 후크 (권장) |
SAP HANA HA/DR 제공업체 후크를 사용하면 SAP HANA가 특정 이벤트에 대한 알림을 Pacemaker 클러스터에 보낼 수 있으므로 장애 감지가 향상됩니다. SAP HANA HA/DR 제공업체 후크를 사용하려면 SAP HANA HA/DR 제공업체 후크 사용에 대한 자세한 내용은 고가용성 배포 가이드를 참조하세요. |
SAP HANA용 OS 기반 HA 클러스터( Google Cloud)
Linux 운영체제 클러스터링은 애플리케이션 상태에 대한 애플리케이션 및 게스트 인식을 제공하며 장애 발생 시 복구 작업을 자동화합니다.
비클라우드 환경에서 적용되는 고가용성 클러스터 원칙도 일반적으로 Google Cloud에서 적용되지만 펜싱 및 가상 IP 등이 구현되는 방법에는 차이가 있습니다.
Google Cloud기반 SAP HANA의 HA 클러스터에 Red Hat 또는 SUSE 고가용성 Linux 배포판을 사용할 수 있습니다.
SAP HANA용Google Cloud 에 HA 클러스터를 배포하고 수동으로 구성하는 방법에 대한 안내는 다음을 참고하세요.
- RHEL에서 HA 수직 확장 클러스터 수동 구성
- SLES에서 HA 클러스터 수동 구성:
Google Cloud에서 제공하는 자동 배포 옵션은 SAP HANA 고가용성 구성의 자동 배포 옵션을 참조하세요.
클러스터 리소스 에이전트
Red Hat과 SUSE 모두 Google Cloud의 리소스 에이전트에 Google Cloud Pacemaker 클러스터 소프트웨어의 고가용성 구현을 제공합니다. Google Cloud 의 리소스 에이전트는 펜싱, 경로 또는 별칭 IP로 구현된 VIP, 스토리지 작업을 관리합니다.
기본 OS 리소스 에이전트에 아직 포함되지 않은 업데이트를 제공하기 위해Google Cloud 는 SAP HA 클러스터를 위한 도우미 리소스 에이전트를 주기적으로 제공합니다. 이러한 도우미 리소스 에이전트가 필요한 경우Google Cloud 배포 절차에 에이전트를 다운로드하는 단계가 포함됩니다.
펜싱 에이전트
Google Cloud Compute Engine OS 클러스터링의 컨텍스트에서 펜싱은 STONITH 형식을 취하여 2노드 클러스터의 각 구성원에 다른 노드를 다시 시작할 수 있는 기능을 제공합니다.
Google Cloud 는 Linux 운영체제 기반 SAP 사용을 위해 두 개의 펜싱 에이전트를 제공합니다. 인증받은 Red Hat 및 SUSE Linux 배포판에 포함되는 fence_gce 에이전트와, fence_gce 에이전트를 포함하지 않으며 Linux 배포판에 사용하기 위해 다운로드할 수 있는 기존 gcpstonith 에이전트입니다. 가능한 경우 fence_gce 에이전트를 사용하는 것이 좋습니다.
펜싱 에이전트에 필요한 IAM 권한
펜싱 에이전트는 Compute Engine API에 재설정 호출을 수행하여 VM을 재부팅합니다. API 액세스 인증 및 승인을 위해 펜스 에이전트는 VM의 서비스 계정을 사용합니다. 펜스 에이전트에 사용되는 서비스 계정에는 다음 권한을 포함하는 역할이 부여되어야 합니다.
- compute.instances.get
- compute.instances.list
- compute.instances.reset
- compute.instances.start
- compute.instances.stop
- compute.zoneOperations.get
- logging.logEntries.create
- compute.zoneOperations.list
사전 정의된 Compute 인스턴스 관리자 역할에는 모든 필수 권한이 포함됩니다.
에이전트의 재부팅 권한 범위를 대상 노드로 제한하려면 리소스 기반 액세스를 구성할 수 있습니다. 자세한 내용은 리소스 기반 액세스 구성을 참조하세요.
가상 IP 주소
Google Cloud 기반 SAP 고가용성 클러스터는 가상 또는 유동 IP 주소(VIP)를 사용하여 장애 조치 시 네트워크 트래픽을 다른 호스트로 리디렉션합니다.
일반적인 비클라우드 배포는 Gratuitous 주소 결정 프로토콜(ARP) 요청을 사용하여 새 MAC 주소로의 VIP 이동 및 재할당을 알립니다.
Google Cloud에서는 Gratuitous ARP 요청을 사용하는 대신 HA 클러스터에서 VIP를 이동하고 재할당하는 여러 방법 중 하나를 사용합니다. 내부 TCP/UDP 부하 분산기를 사용하는 것이 좋지만 필요에 따라 경로 기반 VIP 구현 또는 별칭 IP 기반 VIP 구현을 사용할 수도 있습니다.
Google Cloud에서의 VIP 구현에 관한 자세한 내용은 Google Cloud에서의 가상 IP 구현을 참고하세요.
스토리지 및 복제
SAP HANA HA 클러스터 구성은 동기 SAP HANA 시스템 복제를 사용하여 기본 SAP HANA 데이터베이스와 보조 SAP HANA 데이터베이스를 동기화합니다. SAP HANA의 표준 OS 제공 리소스 에이전트는 장애 조치 중에 시스템 복제를 관리하고, 복제를 시작 및 중지하고, 복제 프로세스에서 활성 인스턴스 역할을 하는 인스턴스와 대기 인스턴스 역할을 하는 인스턴스를 전환할 수 있습니다.
공유 파일 스토리지가 필요한 경우 NFS 또는 SMB 기반 파일러가 필요한 기능을 제공할 수 있습니다.
고가용성 공유 스토리지 솔루션에 Filestore, Google Cloud NetApp Volumes의 Premium 또는 Extreme 서비스 수준 또는 서드 파티 파일 공유 솔루션을 사용할 수 있습니다. Filestore의 리전 서비스 등급(이전의 Enterprise)은 멀티 영역 배포에 사용될 수 있으며 Filestore의 Basic 등급은 단일 영역 배포에 사용될 수 있습니다.
Compute Engine 리전 영구 디스크는 영역 간에 동기식으로 복제된 블록 스토리지를 제공합니다. 리전 영구 디스크는 SAP HA 시스템의 데이터베이스 스토리지로 지원되지 않지만 NFS 파일 서버와 함께 사용할 수 있습니다.
Google Cloud의 스토리지 옵션에 관한 자세한 내용은 다음을 참고하세요.
Google Cloud의 HA 클러스터 구성 설정
Google Cloud 에서는 특정 클러스터 구성 매개변수의 기본값을 Google Cloud 환경의 SAP 시스템에 더 적합한 값으로 변경하는 것이 좋습니다. Google Cloud에서 제공하는 자동화 스크립트를 사용하는 경우 권장 값이 설정됩니다.
권장 값을 HA 클러스터의 Corosync 설정을 조정하기 위한 시작점으로 간주합니다. Google Cloud 환경의 시스템 및 워크로드에 오류 감지 및 장애 조치 트리거의 민감도가 적절한지 확인해야 합니다.
Corosync 구성 매개변수 값
Google Cloud는 SAP HANA용 HA 클러스터 구성 가이드에서 corosync.conf 구성 파일 totem 섹션의 여러 매개변수에 대한 권장 값을 제안합니다. 이 값은 Corosync 또는 Linux 배포자가 설정하는 기본값과 다릅니다.
totem 매개변수 및 값 변경의 영향이 나와 있습니다. Linux 배포판 간에 다를 수 있는 이러한 매개변수의 기본값은 Linux 배포판에 대한 문서를 참조하세요.
| 매개변수 | 권장 값 | 값 변경 영향 |
|---|---|---|
secauth |
off |
모든 totem 메시지의 인증과 암호화를 중지합니다. |
join |
60(ms) | 노드가 멤버십 프로토콜에서 join 메시지를 대기하는 시간을 늘립니다. |
max_messages |
20 | 토큰을 받은 후 노드가 전송할 수 있는 최대 메시지 수를 늘립니다. |
token |
20000(ms) |
노드가 토큰 손실을 선언하고 노드 장애를 가정하고 조치를 취하기 전에 노드가
또한 |
consensus |
해당 사항 없음 | 새로운 멤버십 구성을 시작하기 전에 합의에 도달할 때까지 기다리는 시간(밀리초)을 지정합니다.
이 매개변수를 생략하는 것이 좋습니다. consensus 값을 명시적으로 지정하는 경우 값이 24000 또는 1.2*token 중 더 큰 값이어야 합니다.
|
token_retransmits_before_loss_const |
10 | 수신자 노드가 실패하였음을 확인하고 조치를 취하기 전에 노드가 시도하는 토큰 재전송 횟수를 증가합니다. |
transport |
|
Corosync에서 사용되는 전송 메커니즘을 지정합니다. |
corosync.conf 파일 구성에 대한 상세 설명은 Linux 배포판의 구성 가이드를 참조하세요.
- RHEL: corosync.conf 기본 설정 수정
- SLES: Corosync 구성 파일 만들기
클러스터 리소스의 타임아웃 및 간격 설정
클러스터 리소스를 정의할 때 다양한 리소스 작업(op)에 interval 및 timeout 값을 초 단위로 설정합니다. 예를 들면 다음과 같습니다.
primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HA1_HDB00-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HA1" InstanceNumber="00" clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"
timeout 값은 다음 표에 설명된 대로 각 리소스 작업에 다른 방식으로 영향을 미칩니다.
| 리소스 작업 | 시간 초과 시 조치 |
|---|---|
monitor |
제한 시간을 초과하면 모니터링 상태가 일반적으로 실패로 보고되고 연결된 리소스가 실패한 상태로 간주됩니다. 클러스터가 장애 조치를 포함할 수 있는 복구 옵션을 시도합니다. 클러스터는 실패한 모니터링 작업을 다시 시도하지 않습니다. |
start |
제한 시간에 도달하기 전에 리소스가 시작에 실패한 경우 클러스터는 리소스 재시작을 시도합니다. 동작은 리소스와 연결된 실패 시 작업에 의해 지정됩니다. |
stop |
제한 시간에 도달하기 전에 리소스가 중지 작업에 응답하지 않으면 펜싱 이벤트가 트리거됩니다. |
다른 클러스터 구성 설정과 함께 클러스터 리소스의 interval 및 timeout 설정은 클러스터 소프트웨어가 오류를 감지하고 장애 조치를 트리거하는 속도에 영향을 줍니다.
Google Cloud 는 Compute Engine 라이브 마이그레이션 유지보수 이벤트를 위한 SAP HANA 계정용 클러스터 구성 가이드에서 timeout 및 interval 값을 제안합니다.
사용하는 timeout 및 interval 값과 관계없이 사용 중인 머신 유형과 시스템 사용률과 같은 기타 요인에 따라 실시간 마이그레이션 이벤트 기간이 약간 다를 수 있으므로 클러스터를 테스트할 때(특히 라이브 마이그레이션 테스트 중) 값을 평가해야 합니다.
펜싱 리소스 설정
Google Cloud는 SAP HANA용 HA 클러스터 구성 가이드에서 HA 클러스터의 펜싱 리소스를 구성할 때 여러 매개변수를 권장합니다. 권장되는 값은 Corosync 또는 Linux 배포자가 설정하는 기본값과 다릅니다.
다음 표에는 Google Cloud에서 권장하는 펜싱 매개변수와 권장 값, 매개변수 세부정보가 나와 있습니다. Linux 배포판 간에 다를 수 있는 매개변수의 기본값은 Linux 배포판에 대한 문서를 참조하세요.
| 매개변수 | 권장 값 | 세부정보 |
|---|---|---|
pcmk_reboot_timeout |
300(초) | 재부팅 작업에 사용할 제한 시간 값을 지정합니다.
|
pcmk_monitor_retries |
4 | 제한 시간 내에 monitor 명령어를 재시도할 최대 횟수를 지정합니다. |
pcmk_delay_max |
30(초) | 클러스터 노드가 동시에 펜싱되지 않도록 펜싱 작업에 무작위 지연을 지정합니다. 인스턴스 한 개에 무작위 지연이 할당되도록 하여 펜싱 경합을 방지하려면 2노드 HANA HA 클러스터(수직 확장)의 펜싱 리소스 중 하나에서 이 매개변수를 사용 설정해야 합니다. 수평 확장 HANA HA 클러스터에서는 사이트의 일부(기본 또는 보조)의 모든 노드에서 이 매개변수를 사용 설정해야 합니다. |
Google Cloud에서 HA 클러스터 테스트
클러스터가 구성되었고 클러스터와 SAP HANA 시스템이 테스트 환경에 배포된 후에는 클러스터를 테스트하여 HA 시스템이 올바르게 구성되었고 예상대로 작동하는지 확인해야 합니다.
장애 조치가 예상대로 작동하는지 확인하려면 다음 작업으로 다양한 장애 시나리오를 시뮬레이션합니다.
- VM 종료
- 커널 패닉 만들기
- 애플리케이션 종료
- 인스턴스 간 네트워크 중단
또한 기본 호스트에서 Compute Engine 라이브 마이그레이션 이벤트를 시뮬레이션하여 장애 조치를 트리거하지 않는지 확인합니다. Google Cloud CLI 명령어 gcloud compute instances
simulate-maintenance-event를 사용하여 유지보수 이벤트를 시뮬레이션할 수 있습니다.
로깅 및 모니터링
리소스 에이전트에는 분석을 위해 Google Cloud Observability에 로그를 전파하는 로깅 기능이 포함될 수 있습니다. 각 리소스 에이전트에는 로깅 옵션을 식별하는 구성 정보가 포함되어 있습니다. bash 구현의 경우 로깅 옵션은 gcloud logging입니다.
또한 Cloud Logging 에이전트를 설치하여 운영체제 프로세스에서 로그 출력을 캡처하고 리소스 사용률과 시스템 이벤트를 연관시킬 수 있습니다. Logging 에이전트는 Pacemaker 및 클러스터링 서비스의 로그 데이터를 포함하는 기본 시스템 로그를 캡처합니다. 자세한 내용은 Logging 에이전트 정보를 참조하세요.
Cloud Monitoring을 사용하여 서비스 엔드포인트의 가용성을 모니터링하는 서비스 점검을 구성하는 방법에 대한 상세 설명은 업타임 체크 관리를 참조하세요.
서비스 계정 및 HA 클러스터
클러스터 소프트웨어가 Google Cloud환경에서 수행할 수 있는 작업은 각 호스트 VM의 서비스 계정에 부여된 권한으로 보호됩니다. 보안 수준이 높은 환경에서는 호스트 VM의 서비스 계정에서 최소 권한 원칙을 준수하도록 권한을 제한할 수 있습니다.
서비스 계정 권한을 제한할 때 시스템이 Cloud Storage와 같은 Google Cloud 서비스와 상호작용할 수 있으므로 호스트 VM의 서비스 계정에 이러한 서비스 상호작용에 대한 권한을 포함해야 할 수 있습니다.
가장 제한적인 권한을 부여하려면 필요한 최소 권한이 있는 커스텀 역할을 만듭니다. 커스텀 역할에 대한 상세 설명은 커스텀 역할 만들기 및 관리를 참조하세요. 리소스 IAM 정책의 역할 결합에 조건을 추가하면 HA 클러스터의 VM 인스턴스와 같은 리소스의 특정 인스턴스로만 권한을 제한하는 방식으로 더 제한적인 권한을 부여할 수 있습니다.
시스템에 필요한 최소 권한은 시스템이 액세스하는Google Cloud 리소스와 시스템이 수행하는 작업에 따라 다릅니다. 따라서 HA 클러스터의 호스트 VM에 필요한 최소 권한을 결정하려면 호스트 VM의 시스템이 액세스하는 리소스와 이 시스템이 이 리소스로 수행하는 작업을 조사해야 합니다.
먼저 다음 목록은 일부 HA 클러스터 리소스와 리소스에 필요한 연결된 권한을 보여줍니다.
- 펜싱
- compute.instances.list
- compute.instances.get
- compute.instances.reset
- compute.instances.stop
- compute.instances.start
- logging.logEntries.create
- compute.zones.list
- 별칭 IP를 사용하여 구현된 VIP
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.instances.updateNetworkInterface
- compute.zoneOperations.get
- logging.logEntries.create
- 정적 경로를 사용하여 구현된 VIP
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.routes.get
- compute.routes.create
- compute.routes.delete
- compute.routes.update
- compute.routes.list
- compute.networks.updatePolicy
- compute.networks.get
- compute.globalOperations.get
- logging.logEntries.create
- 내부 부하 분산기를 사용하여 구현된 VIP
- 특정 권한이 필요하지 않습니다. 부하 분산기는 클러스터가 Google Cloud의 리소스와 상호작용하거나 리소스를 변경하지 않아도 되는 상태 확인 상태에서 작동합니다.
Google Cloud의 가상 IP 구현
고가용성 클러스터는 예기치 않은 장애가 발생하는 경우 또는 예정된 유지보수를 위해 유동 또는 가상 IP 주소(VIP)를 사용하여 클러스터 노드 간에 워크로드를 이동합니다. VIP의 IP 주소는 변경되지 않으므로 클라이언트 애플리케이션은 작업이 다른 노드에 의해 제공되고 있다는 것을 알지 못합니다.
VIP는 유동 IP 주소라고도 합니다.
Google Cloud에서 VIP는 온프레미스 설치 시와 약간 다른 방식으로 구현됩니다. 즉, 장애 조치가 발생하면 Gratuitous ARP 요청을 사용하여 변경사항을 알릴 수 없습니다. 대신 다음 방법 중 하나를 사용하여 SAP HA 클러스터의 VIP 주소를 구현할 수 있습니다.
- 내부 패스 스루 네트워크 부하 분산기 장애 조치 지원(권장).
- Google Cloud 정적 경로
- Google Cloud 별칭 IP 주소
내부 패스 스루 네트워크 부하 분산기 VIP 구현
일반적으로 부하 분산기는 여러 활성 시스템에 워크로드를 분산하고 어느 한 인스턴스에서의 처리 속도 저하나 장애로부터 보호하기 위해 애플리케이션의 여러 인스턴스에 사용자 트래픽을 분산합니다.
또한 내부 패스 스루 네트워크 부하 분산기는 Compute Engine 상태 점검과 함께 사용하여 장애를 감지하고 장애 조치를 트리거하고 OS 기반 HA 클러스터의 새로운 기본 SAP 시스템으로 트래픽을 다시 라우팅할 수 있는 장애 조치 지원을 제공합니다.
장애 조치 지원은 다음과 같은 다양한 이유로 권장되는 VIP 구현입니다.
- Compute Engine의 부하 분산은 99.99% 가용성 SLA를 제공합니다.
- 부하 분산은 예측 가능한 교차 영역 장애 조치 시간으로 영역 장애로부터 보호하는 다중 영역 고가용성 클러스터를 지원합니다.
- 부하 분산을 사용하면 장애 조치를 감지하고 트리거하는 데 필요한 시간이 일반적으로 장애 발생 후 몇 초 이내로 줄어듭니다. 전체 장애 조치 시간은 호스트, 데이터베이스 시스템, 애플리케이션 시스템 등이 포함될 수 있는 HA 시스템에 있는 각 구성요소의 장애 조치 시간에 따라 달라집니다.
- 부하 분산을 사용하면 클러스터 구성이 간소화되고 종속 항목이 줄어듭니다.
- 경로를 사용하는 VIP 구현과 달리 부하 분산에서는 자체 VPC 네트워크의 IP 범위를 사용하여 필요에 따라 IP 범위를 예약하고 구성할 수 있습니다.
- 예정된 유지보수 중단 시 부하 분산을 사용하여 트래픽을 보조 시스템으로 간단히 다시 라우팅할 수 있습니다.
VIP의 부하 분산기 구현에 대한 상태 확인을 만들 때 호스트 상태를 확인하기 위해 상태 확인이 검색하는 호스트 포트를 지정합니다. SAP HA 클러스터의 경우 다른 서비스와 충돌하지 않도록 비공개 범위인 49152~65535에서 대상 호스트 포트를 지정합니다. 호스트 VM에서 socat 유틸리티 또는 HAProxy와 같은 보조 도우미 서비스로 대상 포트를 구성합니다.
보조 대기 시스템이 온라인 상태로 유지되는 데이터베이스 클러스터의 경우 상태 점검 및 도우미 서비스는 부하 분산을 사용 설정하여 트래픽을 현재 클러스터의 기본 시스템 역할을 하는 온라인 시스템으로 전달합니다.
도우미 서비스와 포트 리디렉션을 사용하면 SAP 시스템에서 계획된 소프트웨어 유지보수를 위해 장애 조치를 트리거할 수 있습니다.
장애 조치 지원에 대한 자세한 내용은 내부 패스 스루 네트워크 부하 분산기에 대한 장애 조치 구성을 참조하세요.
부하 분산기 VIP 구현을 포함한 HA 클러스터를 배포하려면 다음을 참조하세요.
- Terraform: SAP HANA 고가용성 클러스터 구성 가이드
- RHEL에서 SAP HANA용 HA 클러스터 구성 가이드
- SLES 기반 SAP HANA용 HA 클러스터 구성 가이드
정적 경로 VIP 구현
정적 경로 구현도 영역 장애에 대한 보호를 제공하지만 VM이 상주하는 기존 VPC 서브넷의 IP 범위 밖에서 VIP를 사용해야 합니다. 따라서 VIP가 확장 네트워크의 외부 IP 주소와 충돌하지 않도록 해야 합니다.
호스트 프로젝트로 네트워크 구성을 분리하기 위한 공유 VPC 구성과 함께 정적 경로 구현을 사용하면 복잡해질 수 있습니다.
VIP에 정적 경로 구현을 사용하는 경우 네트워크 관리자에게 문의하여 정적 경로 구현에 적합한 IP 주소를 결정하세요.
별칭 IP VIP 구현
다중 영역 HA 배포에는 별칭 IP VIP 구현이 권장되지 않습니다. 영역에 장애가 발생할 경우 다른 영역의 노드로의 별칭 IP 재할당이 지연될 수 있기 때문입니다. 대신 장애 조치를 지원하는 내부 패스 스루 네트워크 부하 분산기를 사용하여 VIP를 구현하세요.
SAP HA 클러스터의 모든 노드를 같은 영역에 배포하는 경우 별칭 IP를 사용하여 HA 클러스터의 VIP를 구현할 수 있습니다.
VIP에 별칭 IP 구현을 사용하는 기존 다중 영역 SAP HA 클러스터가 있는 경우 VIP 주소 변경 없이 내부 패스 스루 네트워크 부하 분산기 구현으로 마이그레이션할 수 있습니다. 별칭 IP 주소와 내부 패스 스루 네트워크 부하 분산기 모두 VPC 네트워크의 IP 범위를 사용합니다.
다중 영역 HA 클러스터의 VIP 구현에는 별칭 IP 주소가 권장되지 않지만 SAP 배포에는 다른 사용 사례가 있습니다. 예를 들어 SAP Landscape Management에서 관리하는 것과 같은 유연한 SAP 배포를 위한 논리적 호스트 이름과 IP 할당을 제공하는 데 사용할 수 있습니다.
Google Cloud기반 VIP에 대한 일반적인 권장사항
Google Cloud기반 VIP에 대한 자세한 내용은 유동 IP 주소 관련 권장사항을 참조하세요.
Google Cloud에서 SAP HANA 호스트 자동 장애 조치
Google Cloud 는 SAP HANA에서 제공하는 로컬 장애 복구 솔루션인 SAP HANA 호스트 자동 장애 조치를 지원합니다. 호스트 자동 장애 조치 솔루션은 호스트가 실패할 경우 마스터 또는 작업자 호스트에서 작업을 인계하기 위해 예약된 하나 이상의 대기 호스트를 사용합니다. 대기 호스트는 어떤 데이터도 포함하지 않으며 어떤 작업도 처리하지 않습니다.
장애 조치가 완료되면 실패한 호스트는 대기 호스트로 다시 시작됩니다.
SAP는 Google Cloud의 수평 확장 시스템에서 최대 3개의 대기 호스트를 지원합니다. 대기 호스트는 SAP가Google Cloud의 수평 확장 시스템에서 지원하는 최대 16개의 활성 호스트에 포함되지 않습니다.
호스트 자동 장애 조치 솔루션에 대한 SAP의 자세한 내용은 호스트 자동 장애 조치를 참조하세요.
Google Cloud에서 SAP HANA 호스트 자동 장애 조치를 사용해야 하는 경우
SAP HANA 호스트 자동 장애 조치는 다음 항목에 대한 장애를 포함하여 SAP HANA 수평 확장 시스템의 단일 노드에 영향을 미치는 장애로부터 보호합니다.
- SAP HANA 인스턴스
- 호스트 운영체제
- 호스트 VM
Google Cloud의 호스트 VM 오류와 관련하여 자동 다시 시작(일반적으로 호스트 자동 장애 조치보다 SAP HANA 호스트 VM을 빠르게 복원) 및 라이브 마이그레이션은 계획되거나 계획되지 않은 VM 중단으로부터 보호합니다. 따라서 VM 보호를 위해 SAP HANA 호스트 자동 장애 조치 솔루션이 필요하지 않습니다.
SAP HANA 수평 확장 시스템의 모든 노드가 단일 영역에 배포되기 때문에 SAP HANA 호스트 자동 장애 조치는 영역 장애로부터 보호되지 않습니다.
SAP HANA 호스트 자동 장애 조치는 대기 노드의 메모리에 SAP HANA 데이터를 미리 로드하지 않으므로, 대기 노드가 넘겨받을 때 전체 노드 복구 시간은 주로 대기 노드의 메모리에 데이터가 로드되는 데 걸리는 시간으로 결정됩니다.
다음 시나리오에서 SAP HANA 호스트 자동 장애 조치를 사용하는 것이 좋습니다.
- Google Cloud에서 감지할 수 없는 SAP HANA 노드의 소프트웨어 또는 호스트 운영체제 오류
- Google Cloud용 SAP HANA를 최적화할 수 있을 때까지 온프레미스 SAP HANA 구성을 재현해야 하는 리프트 앤 시프트 마이그레이션
- 완전히 복제된 교차 영역의 고가용성 구성에 비용이 많이 들고 비즈니스가 다음 사항을 허용할 수 있는 경우
- 더 긴 노드 복구 시간(SAP HANA 데이터를 대기 노드의 메모리에 로드해야 하므로)
- 영역 장애의 위험
SAP HANA용 스토리지 관리자
/hana/data 및 /hana/log 볼륨은 마스터 및 작업자 호스트에만 마운트됩니다. 인계 작업이 수행되면 호스트 자동 장애 조치 솔루션은 SAP HANA Storage Connector API 및 SAP HANA용Google Cloud 스토리지 관리자 대기 노드를 사용하여 장애가 발생한 호스트에서 대기 호스트로 볼륨 마운트를 이동합니다.
Google Cloud에서는 SAP HANA 호스트 자동 장애 조치를 사용하는 SAP HANA 시스템에 SAP HANA용 스토리지 관리자가 필요합니다.
지원되는 SAP HANA용 스토리지 관리자 버전
SAP HANA용 스토리지 관리자 버전 2.0 이상이 지원됩니다. 2.0 이전의 모든 버전은 지원 중단되었으며 지원되지 않습니다. 이전 버전을 사용하는 경우 SAP HANA 시스템을 업데이트하여 최신 버전의 SAP HANA용 스토리지 관리자를 사용합니다. SAP HANA용 스토리지 관리자 업데이트를 참조하세요.
사용하는 버전이 지원 중단되었는지 확인하려면 gceStorageClient.py 파일을 엽니다.
기본 설치 디렉터리는 /hana/shared/gceStorageClient입니다.
버전 2.0부터 버전 번호는 다음 예시와 같이 gceStorageClient.py 파일 상단의 주석에 나열됩니다. 버전 번호가 없으면 SAP HANA용 스토리지 관리자의 지원 중단된 버전을 사용 중인 것입니다.
"""Google Cloud Storage Manager for SAP HANA Standby Nodes. The Storage Manager for SAP HANA implements the API from the SAP provided StorageConnectorClient to allow attaching and detaching of disks when running in Compute Engine. Build Date: Wed Jan 27 06:39:49 PST 2021 Version: 2.0.20210127.00-00 """
SAP HANA용 스토리지 관리자 설치
SAP HANA용 스토리지 관리자를 설치할 때 권장되는 방법은 자동 배포 방법을 사용하여 SAP HANA용 최신 스토리지 관리자가 포함된 수평 확장 SAP HANA 시스템을 배포하는 것입니다.
Google Cloud의 기존 SAP HANA 수평 확장 시스템에 SAP HANA 호스트 자동 장애 조치를 추가해야 하는 경우 권장되는 접근 방식은 비슷합니다. Google Cloud 에서 제공하는 Terraform 구성 파일을 사용하여 새 수평 확장 SAP HANA 시스템을 배포한 후 기존 시스템에서 새 시스템으로 데이터를 로드합니다. 데이터를 로드하려면 다운타임을 제한할 수 있는 표준 SAP HANA 백업 및 복원 프로시저 또는 SAP HANA 시스템 복제를 사용하면 됩니다. 시스템 복제에 대한 상세 설명은 SAP Note 2473002 - HANA 시스템 복제를 사용하여 수평 확장 시스템 마이그레이션을 참조하세요.
자동 배포 방법을 사용할 수 없는 경우 Google Cloud 컨설팅 서비스를 통해 찾을 수 있는 SAP 솔루션 컨설턴트에게 문의하여 스토리지 관리자 수동 설치에 대한 도움을 받으세요(SAP HANA용).
기존 또는 새 수평 확장 SAP HANA 시스템에 SAP HANA용 스토리지 관리자를 수동으로 설치하는 방법은 현재 문서화되지 않았습니다.
SAP HANA 호스트 자동 장애 조치의 자동 배포 옵션에 대한 자세한 내용은 SAP HANA 호스트 자동 장애 조치가 포함된 SAP HANA 수평 확장 시스템 자동 배포를 참조하세요.
SAP HANA용 스토리지 관리자 업데이트
먼저 설치 패키지를 다운로드한 다음 설치 스크립트를 실행하여 SAP HANA용 스토리지 관리자를 업데이트합니다. 그러면 SAP HANA /shared 드라이브의 SAP HANA 스토리지 관리자 실행 파일이 업데이트됩니다.
다음 절차는 SAP HANA용 스토리지 관리자 버전 2에만 해당됩니다. 2021년 2월 1일 이전에 다운로드한 SAP HANA용 스토리지 관리자 버전을 사용하는 경우 SAP HANA용 스토리지 관리자를 업데이트하기 전에 버전 2를 설치합니다.
SAP HANA용 스토리지 관리자를 업데이트하려면 다음을 따르세요.
현재 SAP HANA용 스토리지 관리자 버전을 확인합니다.
RHEL
sudo yum check-update google-sapgcestorageclient
SLES
sudo zypper list-updates -r google-sapgcestorageclient
업데이트가 있다면 업데이트를 설치합니다.
RHEL
sudo yum update google-sapgcestorageclient
SLES
sudo zypper update
업데이트된 SAP HANA용 스토리지 관리자는
/usr/sap/google-sapgcestorageclient/gceStorageClient.py에 설치됩니다.기존
gceStorageClient.py를 업데이트된gceStorageClient.py파일로 바꿉니다.기존
gceStorageClient.py파일이 기본 설치 위치인/hana/shared/gceStorageClient에 있는 경우 설치 스크립트를 사용하여 파일을 업데이트합니다.sudo /usr/sap/google-sapgcestorageclient/install.sh
기존
gceStorageClient.py파일이/hana/shared/gceStorageClient에 없으면 업데이트된 파일을 기존 파일과 동일한 위치에 복사하여 기존 파일을 바꿉니다.
global.ini 파일의 구성 매개변수
펜싱의 사용 설정 여부를 포함하여 SAP HANA용 스토리지 관리자의 특정 구성 매개변수는 SAP HANA global.ini 파일의 스토리지 섹션에 저장됩니다. Google Cloud 에서 제공하는 Terraform 구성 파일을 사용하여 호스트 자동 장애 조치 기능이 있는 SAP HANA 시스템을 배포하는 경우에는 배포 프로세스가 구성 매개변수를 global.ini 파일에 추가합니다.
다음 예시에서는 SAP HANA용 스토리지 관리자에 대해 생성된 global.ini의 내용을 보여줍니다.
[persistence] basepath_datavolumes = %BASEPATH_DATAVOLUMES% basepath_logvolumes = %BASEPATH_LOGVOLUMES% use_mountpoints = %USE_MOUNTPOINTS% basepath_shared = %BASEPATH_SHARED% [storage] ha_provider = gceStorageClient ha_provider_path = %STORAGE_CONNECTOR_PATH% # # Example configuration for 2+1 setup # # partition_1_*__pd = node-mnt00001 # partition_2_*__pd = node-mnt00002 # partition_3_*__pd = node-mnt00003 # partition_*_data__dev = /dev/hana/data # partition_*_log__dev = /dev/hana/log # partition_*_*__gcloudAccount = svc-acct-name@project-id. # partition_*_data__mountOptions = -t xfs -o logbsize=256k # partition_*_log__mountOptions = -t xfs -o logbsize=256k # partition_*_*__fencing = disabled [trace] ha_gcestorageclient = info
SAP HANA용 스토리지 관리자의 Sudo 액세스
SAP HANA 서비스 및 스토리지 관리를 위해 SAP HANA용 스토리지 관리자는 SID_LCadm 사용자 계정을 사용하고 특정 시스템 바이너리에 대한 sudo 액세스가 필요합니다.
SAP HANA에 호스트 자동 장애 조치를 배포하기 위해 Google Cloud 에서 제공하는 자동화 스크립트를 사용하는 경우 필요한 sudo 액세스가 자동으로 구성됩니다.
SAP HANA용 스토리지 관리자를 수동으로 설치할 경우 visudo 명령어를 사용해서 SID_LCadm 사용자 계정에 다음 필수 바이너리에 대한 sudo 액세스를 부여하도록 /etc/sudoers 파일을 수정합니다.
운영체제 탭을 클릭합니다.
RHEL
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof /usr/sbin/xfs_repair
SLES
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /sbin/xfs_repair /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof
다음 예시는 /etc/sudoers 파일의 항목을 보여줍니다. 이 예시에서는 연관된 SAP HANA 시스템의 시스템 ID가 SID_LC로 바뀝니다. 예시 항목은 호스트 자동 장애 조치로 수평 확장된 SAP HANA를 위해 Google Cloud 에서 제공하는 Terraform 구성으로 생성되었습니다.
Terraform 구성이 만드는 항목에는 더 이상 필요하지 않지만 하위 호환성을 위해 보존되는 바이너리가 포함됩니다. 이전 목록에 표시되는 바이너리만 포함하면 됩니다.
SID_LCadm ALL=NOPASSWD: /sbin/multipath,/sbin/multipathd,/etc/init.d/multipathd,/usr/bin/sg_persist,/bin/mount,/bin/umount,/bin/kill,/usr/bin/lsof,/usr/bin/systemctl,/usr/sbin/lsof,/usr/sbin/xfs_repair,/sbin/xfs_repair,/usr/bin/mkdir,/sbin/vgscan,/sbin/pvscan,/sbin/lvscan,/sbin/vgchange,/sbin/lvdisplay,/usr/bin/gcloud,/sbin/dmsetup
SAP HANA용 스토리지 관리자의 서비스 계정 구성
Google Cloud에서 SAP HANA 수평 확장 시스템의 호스트 자동 장애 조치를 사용 설정하려면 SAP HANA용 스토리지 관리자에 서비스 계정이 필요합니다. 전용 서비스 계정을 만들고 SAP HANA VM에서 작업을 실행하는 데 필요한 권한(예: 페일오버 중에 디스크 분리 및 연결)을 부여할 수 있습니다. 서비스 계정을 만드는 방법에 대한 자세한 내용은 서비스 계정 만들기를 참조하세요.
필수 IAM 권한
SAP HANA용 스토리지 관리자가 사용하는 서비스 계정의 경우 다음 IAM 권한이 포함된 역할을 부여해야 합니다.
gcloud compute instances reset명령어를 사용하여 VM 인스턴스를 재설정하려면compute.instances.reset권한을 부여합니다.gcloud compute disks describe명령어를 사용하여 Persistent Disk 또는 Hyperdisk 볼륨에 대한 정보를 가져오려면compute.disks.get권한을 부여합니다.gcloud compute instances attach-disk명령어를 사용하여 VM 인스턴스에 디스크를 연결하려면compute.instances.attachDisk권한을 부여합니다.gcloud compute instances detach-disk명령어를 사용하여 VM 인스턴스에서 디스크를 분리하려면compute.instances.detachDisk권한을 부여합니다.gcloud compute instances list명령어를 사용하여 VM 인스턴스를 나열하려면compute.instances.list권한을 부여합니다.gcloud compute disks list명령어를 사용하여 Persistent Disk 또는 Hyperdisk 볼륨을 나열하려면compute.disks.list권한을 부여합니다.
커스텀 역할이나 다른 사전 정의된 역할을 통해 필요한 권한을 부여할 수 있습니다.
또한 VM의 액세스 범위를 cloud-platform으로 설정하여 VM의 IAM 권한이 서비스 계정에 부여한 IAM 역할에 따라 완전히 결정되도록 합니다.
기본적으로 SAP HANA용 스토리지 관리자는 확장형 SAP HANA 시스템의 호스트에서 gcloud CLI가 사용할 권한이 있는 활성 서비스 계정 또는 사용자 계정을 사용합니다.
SAP HANA용 스토리지 관리자가 사용하는 활성 계정을 확인하려면 다음 명령어를 사용하세요.
gcloud auth list
이 명령어에 대한 자세한 내용은 gcloud auth list를 참고하세요.
SAP HANA용 스토리지 관리자가 사용하는 계정을 변경하려면 다음 단계를 따르세요.
수평 확장 SAP HANA 시스템의 각 호스트에서 서비스 계정을 사용할 수 있는지 확인합니다.
gcloud auth listglobal.ini파일에서[storage]섹션을 서비스 계정으로 업데이트합니다.[storage] ha_provider = gceStorageClient ... partition_*_*__gcloudAccount = SERVICE_ACCOUNTSERVICE_ACCOUNT을 SAP HANA의 스토리지 관리자가 사용하는 서비스 계정 이름(이메일 주소 형식)으로 바꿉니다. 이 서비스 계정은 SAP HANA용 스토리지 관리자에서gcloud명령어를 실행할 때 사용됩니다.
SAP HANA 호스트 자동 장애 조치용 NFS 스토리지
모든 호스트에서 /hana/shared 및 /hanabackup 볼륨을 공유하려면 호스트 자동 장애 조치가 포함된 SAP HANA 수평 확장 시스템에 Cloud Filestore 같은 NFS 솔루션이 필요합니다. NFS 솔루션을 직접 설정해야 합니다.
자동 배포 방법을 사용하는 경우 사용자는 배포 중 NFS 디렉터리를 마운트하기 위하여 배포 파일에 NFS 서버에 대한 정보를 제공하게 됩니다.
사용하는 NFS 볼륨은 비어 있어야 합니다. 모든 기존 파일은 배치 절차와 충돌할 수 있으며 파일 또는 폴더가 SAP 시스템 ID(SID)를 참조하는 경우에는 특히 그렇습니다. 배포 절차는 파일을 덮어쓸 수 있는지 여부를 결정할 수 없습니다.
배포 절차는 /hana/shared 및 /hanabackup 볼륨을 NFS 서버에 저장하고 대기 호스트를 포함한 모든 호스트에 NFS 서버를 마운트합니다. 그러면 마스터 호스트가 NFS 서버를 관리합니다.
SAP HANA용 Cloud Storage Backint 에이전트와 같은 백업 솔루션을 구현하는 경우에는 배포가 완료된 후 NFS 서버에서 /hanabackup 볼륨을 삭제할 수 있습니다.
Google Cloud에서 사용할 수 있는 공유 파일 솔루션에 대한 자세한 내용은 Google Cloud의 SAP용 파일 공유 솔루션을 참고하세요.
운영체제 지원
Google Cloud 는 다음 운영체제에서만 SAP HANA 호스트 자동 장애 조치를 지원합니다.
- RHEL for SAP 7.7 이상
- RHEL for SAP 8.1 이상
- RHEL for SAP 9.0 이상
-
RHEL for SAP 9.x에 SAP 소프트웨어를 설치하기 전에 호스트 머신, 특히
chkconfig및compat-openssl11에 추가 패키지를 설치해야 합니다. Compute Engine에서 제공하는 이미지를 사용하는 경우에는 이러한 패키지가 자동으로 설치됩니다. SAP의 자세한 내용은 SAP Note 3108316 - Red Hat Enterprise Linux 9.x: Installation and Configuration을 참조하세요.
-
RHEL for SAP 9.x에 SAP 소프트웨어를 설치하기 전에 호스트 머신, 특히
- SLES for SAP 12 SP5
- SLES for SAP 15 SP1 이상
Compute Engine에서 제공되는 공개 이미지를 확인하려면 이미지를 참조하세요.
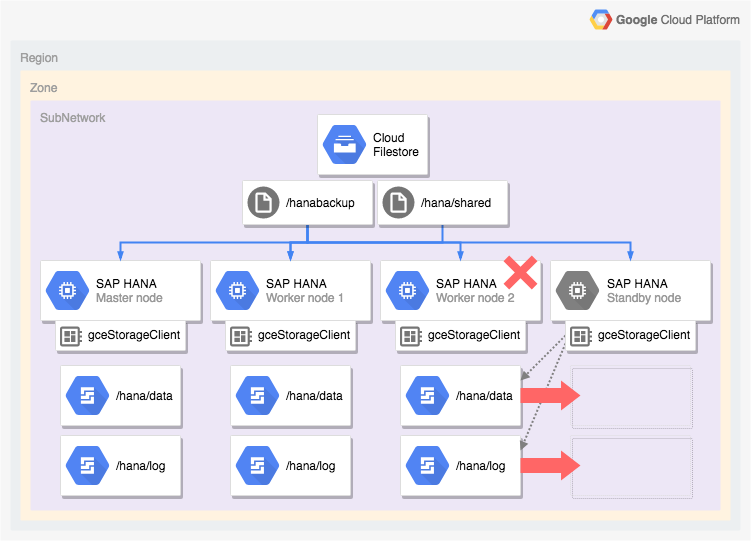
호스트 자동 장애 조치가 포함된 SAP HANA 시스템 아키텍처
다음 다이어그램은 SAP HANA 호스트 자동 장애 조치 기능이 포함된 Google Cloud 의 수평 확장 아키텍처를 보여줍니다. 다이어그램에서 SAP HANA의 스토리지 관리자는 실행 파일 이름 gceStorageClient로 표시됩니다.
다이어그램은 워커 노드 2 실패와 대기 노드의 인계를 보여줍니다.
SAP HANA용 스토리지 관리자는 SAP Storage Connector API(표시되지 않음)와 함께 작동하여 실패한 작업자 노드에서 /hana/data 및 /hana/logs 볼륨이 포함된 디스크를 분리한 후 대기 노드에 다시 마운트합니다. 그러면 이 노드는 실패한 노드가 대기 노드로 전환될 때까지 워커 노드 2가 됩니다.
SAP HANA 고가용성 구성의 자동 배포 옵션
Google Cloud 는 SAP HANA HA 시스템 배포를 자동화하는 데 사용할 수 있는 Terraform 구성을 제공합니다. 또는 SAP HANA HA 시스템을 수동으로 배포하고 구성할 수 있습니다.
Google Cloud 는 사용자가 완료하는 배포별 Terraform 구성 파일을 제공합니다. 표준 Terraform 명령어를 사용하여 현재 작업 디렉터리를 초기화하고 Google Cloud용 Terraform 제공업체 플러그인과 모듈 파일을 다운로드한 다음 구성을 적용하여 SAP HANA 시스템을 배포합니다.
이 자동 배포 방법은 SAP에서 완벽하게 지원하고 SAP 및Google Cloud의 권장사항을 준수하는 SAP HANA 시스템을 배포합니다.
SAP HANA용 Linux 고가용성 클러스터 자동 배포
SAP HANA의 경우 자동화된 배포 방법이 다음을 포함하는 성능에 최적화된 고가용성 Linux 클러스터를 배포합니다.
- 자동 장애 조치
- 자동으로 다시 시작
- 지정한 가상 IP 주소(VIP) 예약
- 가상 IP 주소(VIP)에서 HA 클러스터 노드로의 라우팅을 관리하는 내부 TCP/UDP 부하 분산에서 제공하는 장애 조치 지원
- Compute Engine 상태 확인이 클러스터의 VM 인스턴스를 모니터링할 수 있도록 허용하는 방화벽 규칙
- Pacemaker 고가용성 클러스터 리소스 관리자
- Google Cloud 펜싱 메커니즘
- SAP HANA 인스턴스별 필수 영구 디스크가 포함된 VM
- 단독 테넌트 노드(원하는 경우)
- 동기 복제 및 메모리 미리 로드를 위해 구성된 SAP HANA 인스턴스
Terraform을 사용하여 SAP HANA용 고가용성 클러스터 배포를 자동화하려면 다음을 참조하세요.
SAP HANA 호스트 자동 장애 조치가 포함된 SAP HANA 수평 확장 시스템 자동 배포
Terraform을 사용하여 대기 호스트가 있는 수평 확장 시스템 배포를 자동화할 수 있습니다. 자세한 내용은 Terraform: 호스트 자동 장애 조치가 포함된 SAP HANA 수평 확장 시스템 배포 가이드를 참고하세요.
SAP HANA 호스트 자동 장애 조치 기능이 포함된 SAP HANA 수평 확장 시스템의 경우 Google Cloud 에서 제공하는 Terraform 구성은 다음을 배포합니다.
- 마스터 SAP HANA 인스턴스 1개
- 작업자 호스트 1~15개
- 대기 호스트 1~3개
- SAP HANA 호스트별 VM 1개
- 마스터 및 작업자 호스트용 SSD 기반 영구 디스크 또는 Hyperdisk 볼륨
- SAP HANA 대기 노드용 Google Cloud 스토리지 관리자
모든 호스트에서 /hana/shared 및 /hanabackup 볼륨을 공유하려면 호스트 자동 장애 조치가 포함된 SAP HANA 수평 확장 시스템에 Cloud Filestore 같은 NFS 솔루션이 필요합니다. 그러면 Terraform은 배포 중에 NFS 디렉터리를 마운트할 수 있으며 사용자는 SAP HANA 시스템을 배포하기 전에 직접 NFS 솔루션을 설정해야 합니다.
인스턴스 만들기의 안내에 따라 Filestore NFS 서버 인스턴스를 빠르게 설정할 수 있습니다.
SAP HANA의 활성/활성(읽기 지원) 옵션
SAP HANA 2.0 SPS1부터 SAP HANA 시스템 복제 시나리오에 활성/활성(읽기 지원) 설정을 제공합니다. 활성/활성(읽기 지원)으로 구성된 복제 시스템에서 보조 시스템의 SQL 포트는 읽기 액세스를 위해 열려 있습니다. 읽기 집약 태스크에 보조 시스템을 사용하고 컴퓨팅 리소스 전반에서 워크로드를 더 효율적으로 분산하여 SAP HANA 데이터베이스의 전반적인 성능을 향상시킬 수 있습니다. 활성/활성(읽기 지원) 기능에 대한 자세한 내용은 SAP HANA 버전 및 SAP Note 1999880과 관련된 SAP HANA 관리 가이드를 참조하세요.
보조 시스템에서 읽기 액세스를 사용 설정하는 시스템 복제를 구성하려면 작업 모드 logreplay_readaccess를 사용해야 합니다. 그러나 이 작업 모드를 사용하려면 기본 및 보조 시스템에서 같은 SAP HANA 버전을 실행해야 합니다. 따라서 두 시스템 모두 같은 SAP HANA 버전을 실행할 때까지 순차적 업그레이드 중에 보조 시스템에 대한 읽기 전용 액세스를 사용할 수 없습니다.
활성/활성(읽기 지원) 보조 시스템에 연결하기 위해 SAP는 다음 옵션을 지원합니다.
- 보조 시스템에 대한 명시적 연결을 열어서 직접 연결합니다.
- 평가 시 보조 시스템으로 쿼리를 다시 라우팅하여 기본 시스템에서 SQL 문을 실행해 간접적으로 연결합니다.
다음 다이어그램에서는 애플리케이션이 Google Cloud에 배포된 Pacemaker 클러스터에서 직접 보조 시스템에 액세스하는 첫 번째 옵션을 보여줍니다. 추가 유동 또는 가상 IP 주소(VIP)는 SAP HANA Pacemaker 클러스터의 일부로 보조 시스템 역할을 하는 VM 인스턴스를 타겟팅하는 데 사용됩니다. VIP는 보조 시스템을 따르고 예기치 않은 장애가 발생하는 경우나 예정된 유지보수를 위해 읽기 워크로드를 클러스터 노드 간에 이동할 수 있습니다. 사용 가능한 VIP 구현 방법에 관한 자세한 내용은 Google Cloud의 가상 IP 구현을 참고하세요.

Pacemaker 클러스터에서 활성/활성(읽기 지원)으로 SAP HANA 시스템 복제를 구성하는 방법은 다음과 같습니다.
다음 단계
Google Cloud 및 SAP 둘 다 고가용성에 대한 자세한 정보를 제공합니다.
Google Cloud 고가용성에 대해 자세히 알아보기
Google Cloud에서 SAP HANA의 고가용성에 관한 자세한 내용은 SAP HANA 운영 가이드를 참고하세요.
다양한 장애 시나리오로부터 Google Cloud의 시스템을 보호하는 방법에 대한 일반적인 정보는 강력한 시스템 설계를 참고하세요.
SAP에서 제공하는 SAP HANA 고가용성 기능에 대한 추가 정보
SAP HANA 고가용성 기능에 대한 자세한 내용은 SAP에서 제공하는 다음 문서를 참조하세요.
- SAP HANA 고가용성
- SAP Note 2057595 - FAQ: SAP HANA 고가용성
- SAP HANA 2.0용 시스템 복제 수행 방법
- SAP HANA 시스템 복제용 네트워크 추천