Speech-to-Text
Google AI를 사용해 음성을 텍스트로 변환하기
사용하기 쉬운 API를 사용하여 오디오를 텍스트 스크립트로 변환하고 음성 인식을 애플리케이션에 통합하세요.
신규 고객에게는 최대 $300의 무료 크레딧도 제공되어 Speech-to-Text 및 기타 Google Cloud 제품을 사용해 볼 수 있습니다.
기능
고급 음성 AI
Speech-to-Text는 수백만 시간의 오디오 데이터와 수십억 개의 텍스트 문장으로 학습된 음성용 Google Cloud 파운데이션 모델인 Chirp 3을 활용할 수 있습니다. 이는 대량의 언어별 지도 데이터에 중점을 둔 기존 음성 인식 기술과 대조됩니다. 이러한 기법을 통해 더 많은 언어와 억양에 맞게 개선된 인식 및 스크립트 작성을 사용자에게 제공할 수 있습니다.
85개 이상의 언어 및 방언 지원
광범위한 언어 지원을 통해 전 세계적 사용자층에 맞게 빌드하세요. 짧거나 긴 오디오 데이터, 스트리밍 오디오 데이터를 스크립트로 작성할 수 있습니다. 또한 Speech-to-Text는 차세대 범용 음성 모델인 Chirp 3을 사용한 스크립트 작성으로 전 세계에서 더욱 정확하게 배포할 수 있도록 지원합니다.
Chirp 3: 스크립트 작성은 수백만 시간의 오디오와 100개 이상의 언어에 걸친 280억 개 문장에 대한 자체 지도 학습을 통해 빌드되었습니다.
음성 인식 스트리밍
API가 애플리케이션의 마이크로부터 스트리밍되거나 사전 녹음된 오디오 파일로부터 전송되는(인라인 또는 Cloud Storage 사용) 오디오 입력을 처리할 때 음성 인식 결과를 실시간으로 수신할 수 있습니다.
AI 기반 음성 인식 및 스크립트 작성
Speech-to-Text는 모델 적응을 사용하여 자주 사용하는 단어의 정확도를 개선하고, 스크립트 작성에 사용할 수 있는 어휘를 확장하며, 소음이 많은 오디오의 스트립트 작성을 개선합니다. 사용자는 모델 적응을 통해 Speech-to-Text가 추천될 수 있는 다른 옵션보다 특정 단어나 문구를 더 자주 인식하도록 맞춤설정할 수 있습니다. 예를 들어 Speech-to-Text가 'whether'보다 'weather'를 편향되게 스크립트를 작성하도록 할 수 있습니다.
즉시 사용 가능한 규제 및 보안 규정 준수
Speech-to-Text API v2는 기업 및 비즈니스 고객이 추가 보안 및 규제 요건을 즉시 충족할 수 있도록 지원합니다. 데이터 상주를 통해 싱가포르, 벨기에 등의 Google Cloud 리전을 활용하는 완전히 리전화된 서비스를 통해 스크립트 작성 모델을 호출할 수 있습니다. 리소스 생성 및 스크립트 작성을 위한 로그는 Google Cloud 콘솔에서 손쉽게 사용할 수 있습니다. 또한 Speech-to-Text API v2는 일괄 스크립트 작성은 물론 모든 리소스에 대한 고객 관리 암호화 키를 통해 엔터프라이즈급 암호화를 제공합니다.
멀티 채널 인식
Speech-to-Text는 멀티 채널 상황(예: 화상 회의)에서 개별 채널을 인식하고 순서에 맞게 스크립트에 주석을 달 수 있습니다.
강력한 소음 제거 기능
Speech-to-Text는 별도로 주변 소음을 제거할 필요 없이 다양한 환경의 소음이 있는 오디오를 처리할 수 있습니다.
분야별 모델
분야별 품질 요구사항에 따라 최적화된 학습된 모델 유형을 선택하여 음성 제어, 전화 통화, 동영상 스크립트 작성에 사용하세요. 예를 들어 Google의 향상된 전화 통화 모델은 8kHz 샘플링 레이트로 녹음된 전화 통화와 같이 전화에서 유래된 오디오에 맞게 조정되어 있습니다.
콘텐츠 필터링
욕설 필터는 오디오 데이터에서 부적절하거나 전문가답지 않은 콘텐츠를 감지하고 텍스트 결과에서 욕설 표현을 필터링합니다.
스크립트 작성 평가
자체 음성 데이터를 업로드하여 코딩 없이 스크립트를 작성하세요. 구성을 반복하여 품질을 평가할 수 있습니다.
자동 구두점(베타)
Speech-to-Text는 쉼표, 물음표, 마침표 등을 추가하여 스크립트 작성 시 구두점 정확하게 추가합니다.
화자 분할
대화 참여자의 각 발언에 대한 자동 예측을 수신하여 누가 어떤 발언을 했는지 알 수 있습니다.
API와 Agent Studio의 Speech-to-Text Chirp 모델 비교
| 제품 | 기본 개념 | 적합한 환경 | 주요 특징 |
|---|---|---|---|
Chirp 3: Agent Platform의 스크립트 작성 | 사용하기 쉬운 노 코드, 웹 기반 그래픽 사용자 인터페이스 | 오디오 파일을 빠르게 테스트하고, 신속하게 프로토타입을 제작하며, 오디오 스크립트를 만들고, 오디오 또는 녹음 파일을 웹브라우저에 직접 업로드할 수 있습니다. | -향상된 다국어 감지 및 스크립트 작성 -85개 이상의 언어 및 방언으로 스크립트 작성 지원 -화자 분할 및 모델 적응 지원 -자동 음성 인식, 오디오를 텍스트로 변환 -다국어 감지 및 스크립트 작성 |
Chirp 3: Speech-to-Text V2 API에서 스크립트 작성 | Google의 범용 Speech-to-Text 모델의 차세대 버전인 API로, 여러 언어의 데이터를 통합합니다. | 확장 가능한 엔터프라이즈급 애플리케이션 빌드 기존 소프트웨어에 손쉽게 통합되는 스크립트 작성 기능 | -향상된 다국어 감지 및 스크립트 작성 -85개 이상의 언어 및 방언으로 스크립트 작성 지원 -화자 분할 및 모델 적응 지원 -자동 음성 인식, 오디오를 텍스트로 변환 -다국어 감지 및 스크립트 작성 |
Chirp 3: Agent Platform의 스크립트 작성
사용하기 쉬운 노 코드, 웹 기반 그래픽 사용자 인터페이스
오디오 파일을 빠르게 테스트하고, 신속하게 프로토타입을 제작하며, 오디오 스크립트를 만들고, 오디오 또는 녹음 파일을 웹브라우저에 직접 업로드할 수 있습니다.
-향상된 다국어 감지 및 스크립트 작성
-85개 이상의 언어 및 방언으로 스크립트 작성 지원
-화자 분할 및 모델 적응 지원
-자동 음성 인식, 오디오를 텍스트로 변환
-다국어 감지 및 스크립트 작성
Chirp 3: Speech-to-Text V2 API에서 스크립트 작성
Google의 범용 Speech-to-Text 모델의 차세대 버전인 API로, 여러 언어의 데이터를 통합합니다.
확장 가능한 엔터프라이즈급 애플리케이션 빌드
기존 소프트웨어에 손쉽게 통합되는 스크립트 작성 기능
-향상된 다국어 감지 및 스크립트 작성
-85개 이상의 언어 및 방언으로 스크립트 작성 지원
-화자 분할 및 모델 적응 지원
-자동 음성 인식, 오디오를 텍스트로 변환
-다국어 감지 및 스크립트 작성
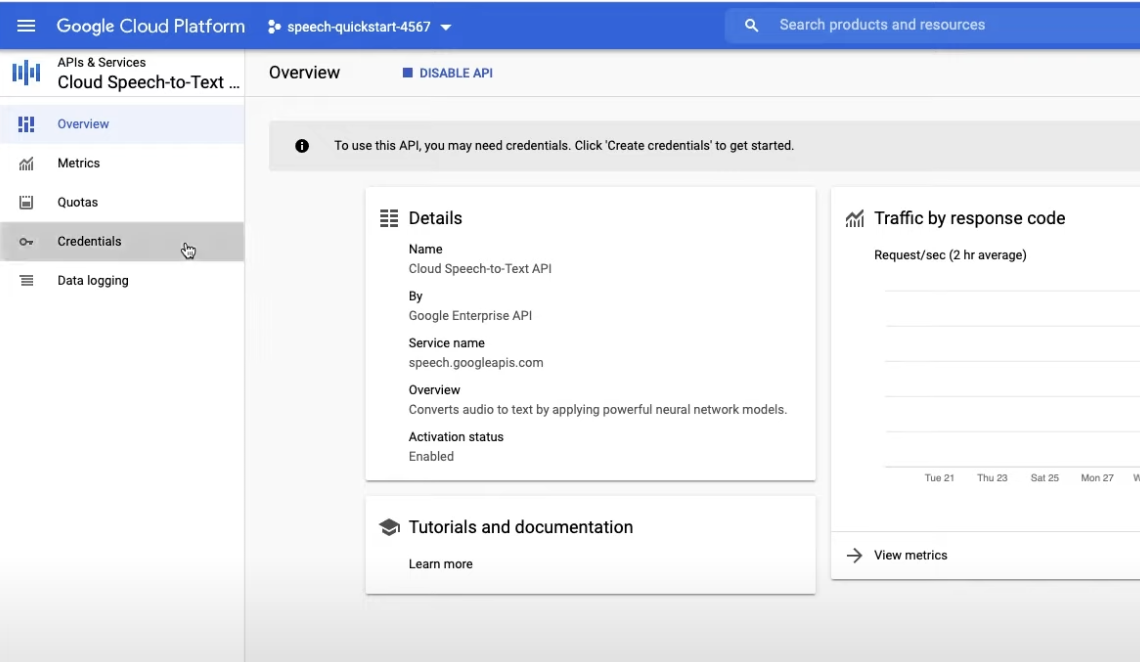
데모
Speech-to-Text API 테스트
파일 업로드 또는 마이크에 대고 말하여 오디오 스크립트를 빠르게 작성합니다.
오디오 스크립트 작성
오디오 스크립트 작성
오디오 스크립트 작성
튜토리얼, 빠른 시작, 실습
오디오 스크립트 작성
오디오 스크립트 작성
AI를 사용해 동영상에 자막 추가
AI를 사용해 동영상 자막 만들기
AI를 사용해 동영상 자막 만들기
오디오 및 동영상의 스크립트를 작성하여 자막을 포함할 수 있습니다. 기존 콘텐츠에 자막을 추가하거나 스트리밍 콘텐츠에 실시간으로 자막을 추가할 수 있습니다. Google의 Chirp 3: Transcription은 동영상 또는 화자가 여러 명인 콘텐츠의 색인을 생성하거나 자막을 제작하는 데 적합하며, YouTube 동영상 자막 제작에 사용하는 것과 유사한 머신러닝 기술을 사용합니다.
이 튜토리얼에서는 Google Cloud AI 서비스인 Speech-to-Text API와 Translation API를 사용해 동영상에 자막을 추가하고 다른 언어로 현지화된 자막을 제공하는 방법을 설명합니다.
튜토리얼, 빠른 시작, 실습
AI를 사용해 동영상 자막 만들기
AI를 사용해 동영상 자막 만들기
오디오 및 동영상의 스크립트를 작성하여 자막을 포함할 수 있습니다. 기존 콘텐츠에 자막을 추가하거나 스트리밍 콘텐츠에 실시간으로 자막을 추가할 수 있습니다. Google의 Chirp 3: Transcription은 동영상 또는 화자가 여러 명인 콘텐츠의 색인을 생성하거나 자막을 제작하는 데 적합하며, YouTube 동영상 자막 제작에 사용하는 것과 유사한 머신러닝 기술을 사용합니다.
이 튜토리얼에서는 Google Cloud AI 서비스인 Speech-to-Text API와 Translation API를 사용해 동영상에 자막을 추가하고 다른 언어로 현지화된 자막을 제공하는 방법을 설명합니다.
앱에 Speech-to-Text 추가
앱에 Speech-to-Text를 추가하는 방법
앱에 Speech-to-Text를 추가하는 방법
Google Cloud를 사용해 애플리케이션에서 Speech-to-Text를 빠르고 쉽게 사용 설정하는 방법을 알아보세요. 이 동영상에서는 광범위한 머신러닝 모델 경험 없어도 애플리케이션에 AI를 추가하는 방법을 다룹니다. 사전 학습된 Speech-to-Text API를 사용하면 애플리케이션에 AI를 빠르고 쉽게 적용할 수 있습니다.
튜토리얼, 빠른 시작, 실습
앱에 Speech-to-Text를 추가하는 방법
앱에 Speech-to-Text를 추가하는 방법
Google Cloud를 사용해 애플리케이션에서 Speech-to-Text를 빠르고 쉽게 사용 설정하는 방법을 알아보세요. 이 동영상에서는 광범위한 머신러닝 모델 경험 없어도 애플리케이션에 AI를 추가하는 방법을 다룹니다. 사전 학습된 Speech-to-Text API를 사용하면 애플리케이션에 AI를 빠르고 쉽게 적용할 수 있습니다.
오디오를 텍스트로 번역
Google Cloud API를 사용한 언어, 음성, 텍스트, 번역
Google Cloud API를 사용한 언어, 음성, 텍스트, 번역
이 과정에서는 Speech-to-Text API를 사용하여 오디오 파일을 텍스트 파일로 변환하고, Google Cloud Translation API로 번역하고, Natural Language API로 합성 음성을 만듭니다.
튜토리얼, 빠른 시작, 실습
Google Cloud API를 사용한 언어, 음성, 텍스트, 번역
Google Cloud API를 사용한 언어, 음성, 텍스트, 번역
이 과정에서는 Speech-to-Text API를 사용하여 오디오 파일을 텍스트 파일로 변환하고, Google Cloud Translation API로 번역하고, Natural Language API로 합성 음성을 만듭니다.
가격 책정
| Speech-to-Text 가격 책정 방식 | Speech-to-Text 가격은 API 버전, 채널, 일괄 처리 방식, 스토리지와 같은 추가 Google Cloud 서비스 비용을 기준으로 책정됩니다. | |
|---|---|---|
| API 버전 | 서비스 및 기능 | 가격 책정 |
Speech-to-Text V2 API | V2는 Chirp 3의 멀티 리전 및 단일 리전 배포를 위한 데이터 상주를 제공합니다. V2에는 감사 로깅과 고객 관리 암호화 키 지원이 포함되어 있습니다. | $0.016 /분 |
Speech-to-Text 가격 책정 세부정보를 확인하세요.
Speech-to-Text 가격 책정 방식
Speech-to-Text 가격은 API 버전, 채널, 일괄 처리 방식, 스토리지와 같은 추가 Google Cloud 서비스 비용을 기준으로 책정됩니다.
Speech-to-Text V2 API
V2는 Chirp 3의 멀티 리전 및 단일 리전 배포를 위한 데이터 상주를 제공합니다. V2에는 감사 로깅과 고객 관리 암호화 키 지원이 포함되어 있습니다.
$0.016
/분
Speech-to-Text 가격 책정 세부정보를 확인하세요.


















