Nestas instruções, mostramos como configurar uma solução para replicar dados de aplicativos SAP, como SAP S/4HANA ou SAP Business Suite, para o BigQuery usando o SAP Landscape Transformation (LT) Replication Server e o SAP Data Services (DS).
É possível usar a replicação de dados para fazer backup dos dados do SAP quase em tempo real ou para consolidar os dados dos sistemas SAP com dados de consumidores de outros sistemas no BigQuery, visando extrair insights de machine learning e da análise de dados em escala de petabytes.
As instruções destinam-se a administradores de sistemas SAP que tenham experiência básica de configuração em SAP Basis, SAP LT Replication Server, SAP DS e Google Cloud.
Arquitetura

O SAP LT Replication Server pode funcionar como provedor de dados para o SAP NetWeaver Operational Data Provisioning Framework (ODP). O SAP LT Replication Server recebe dados de sistemas SAP conectados e os armazena no framework ODP em uma fila delta operacional (ODQ, na sigla em inglês) do sistema SAP LT Replication Server. Assim, o SAP LT Replication Server também funciona como destino das próprias configurações. O framework ODP disponibiliza os dados como objetos ODP correspondentes às tabelas do sistema de origem.
O framework ODP é compatível com cenários de extração e replicação para vários aplicativos SAP de destino, conhecidos como assinantes. Os assinantes recuperam os dados da fila delta para processamento extra.
Os dados são replicados assim que um assinante os solicita de uma origem por meio de um contexto ODP. Vários assinantes podem usar a mesma ODQ como origem.
O SAP LT Replication Server utiliza o suporte à captura de dados alterados (CDC, na sigla em inglês) do SAP Data Services 4.2 SP1 ou posterior, que inclui provisionamento de dados em tempo real e recursos delta para todas as tabelas de origem.
No diagrama a seguir, veja o fluxo de dados pelos sistemas:
- Os aplicativos SAP atualizam os dados no sistema de origem.
- O SAP LT Replication Server replica as alterações de dados e armazena os dados na fila delta operacional.
- Sendo assinante da fila delta operacional, o SAP DS pesquisa periodicamente a fila em busca de alterações nos dados.
- O SAP DS recupera os dados da fila delta, transforma-os para serem compatíveis com o formato do BigQuery e inicia o job de carga que os move para o BigQuery.
- Os dados ficam disponíveis no BigQuery para análise.
Neste cenário, o sistema de origem SAP, o SAP LT Replication Server e o SAP Data Services podem ser executados dentro ou fora do Google Cloud. Para mais informações da SAP, consulte Provisionamento de dados operacionais em tempo real com o SAP Landscape Transformation Replication Server.

Componentes principais da solução
Os componentes a seguir são necessários para replicar dados de aplicativos SAP para o BigQuery usando o SAP Landscape Transformation Replication Server e o SAP Data Services:
| Componente | Versões exigidas | Observações |
|---|---|---|
| Pilha do servidor de aplicativos SAP | Qualquer sistema SAP baseado em ABAP que comece com R/3 4.6C SAP_Basis (requisito mínimo):
|
Neste guia, o servidor de aplicativos e o servidor de banco de dados são chamados coletivamente de sistema de origem, mesmo que estejam em execução em máquinas diferentes. Defina o usuário RFC com a autorização apropriada Opcional: defina espaço de tabela separado para tabelas de registro |
| Sistema de banco de dados (DB, na sigla em inglês) | Qualquer versão de banco de dados que conste como compatível da matriz de disponibilidade do produto (PAM, na sigla em inglês) do SAP, sujeita às restrições da pilha do SAP NetWeaver apresentadas na PAM. Consulte service.sap.com/pam. | |
| Sistema operacional (SO) | Qualquer versão de SO que conste como compatível da PAM do SAP, sujeita a quaisquer restrições da pilha do SAP NetWeaver apresentadas na PAM. Consulte service.sap.com/pam. | |
| SAP Data Migration Server (DMIS) | DMIS:
|
|
| SAP Landscape Transformation Replication Server | SAP LT Replication Server 2.0 ou posterior | Requer uma conexão RFC com o sistema de origem. O dimensionamento do sistema SAP LT Replication Server depende muito do volume de dados armazenados na ODQ e dos períodos de retenção planejados. |
| SAP Data Services | SAP Data Services 4.2 SP1 ou posterior | |
| BigQuery | N/A |
Custos
O BigQuery é um componente faturável Google Cloud .
Use a Calculadora de preços para gerar uma estimativa de custo com base no uso previsto.
Pré-requisitos
Nestas instruções, presume-se que o servidor de aplicativos SAP, o servidor de banco de dados, o SAP LT Replication Server e o SAP Data Services já estejam instalados e configurados para operação normal.
Para usar o BigQuery, você precisa de um projeto do Google Cloud.
Configurar um projeto do Google Cloud em Google Cloud
Você precisa ativar a API BigQuery e, se ainda não tiver criado um projeto doGoogle Cloud , precisará fazer isso também.
Criar Google Cloud projeto
Acesse o console Google Cloud e inscreva-se, percorrendo o assistente de configuração.
Ao lado do logotipo Google Cloud no canto superior esquerdo, clique no menu suspenso e selecione Criar projeto.
Dê um nome ao projeto e clique em Criar.
Após a criação do projeto (uma notificação é exibida no canto superior direito), atualize a página.
Ativar APIs
Ative a API BigQuery:
Ativar o acesso particular às Google Cloud APIs
Para cargas de trabalho da SAP em execução fora de Google Cloud, depois de estabelecer uma conexão de rede com Google Cloud, é necessário ativar o acesso particular às APIs Google Cloud .
Para mais informações, consulte Opções de acesso privado do Google para serviços.
Criar uma conta de serviço
A conta de serviço (especificamente o arquivo de chave) é usada para autenticar o SAP DS no BigQuery. Você usa o arquivo de chave mais tarde ao criar o armazenamento de dados de destino.
No console Google Cloud , acesse a página Contas de serviço.
Selecionar o projeto Google Cloud .
Clique em Criar conta de serviço.
Insira um Nome de conta de serviço.
Clique em Criar e continuar.
Na lista Selecionar um papel, escolha BigQuery > Editor de dados do BigQuery.
Clique em Adicionar outro papel.
Na lista Selecionar um papel, escolha BigQuery > Usuário de jobs do BigQuery.
Clique em Continuar.
Conceda aos outros usuários acesso à conta de serviço, conforme adequado.
Clique em Concluído.
Na página Contas de serviço no Google Cloud console, clique no endereço de e-mail da conta de serviço que você acabou de criar.
No nome da conta de serviço, clique na guia Chaves.
Clique no menu suspenso Adicionar chave e selecione Criar nova chave.
Certifique-se de que o tipo de chave JSON esteja especificado.
Clique em Criar.
Salve o arquivo de chave baixado automaticamente em local seguro.
Como configurar a replicação entre aplicativos SAP e o BigQuery
A configuração dessa solução inclui as etapas gerais a seguir:
- configuração do SAP LT Replication Server;
- configuração do SAP Data Services;
- criação do fluxo de dados entre o SAP Data Services e o BigQuery.
Configuração do SAP Landscape Transformation Replication Server
Nas etapas a seguir, configuramos o SAP LT Replication Server para funcionar como provedor dentro do framework de provisionamento de dados operacional e criar uma fila delta operacional. Nessa configuração, o SAP LT Replication Server usa a replicação baseada em gatilho para copiar os dados do sistema SAP de origem para as tabelas na fila delta. O SAP Data Services funciona como assinante no framework ODP, recuperando os dados da fila delta, para depois transformá-los e carregá-los no BigQuery.
Configurar a fila delta operacional (ODQ)
- No SAP LT Replication Server, use a transação
SM59para criar um destino RFC para o sistema de aplicativos SAP usado como origem de dados. - No SAP LT Replication Server, use a transação
LTRCpara criar uma configuração. Na configuração, defina a origem e o destino do SAP LT Replication Server. O destino da transferência de dados que usa ODP é o próprio SAP LT Replication Server.- Para especificar a origem, insira o destino RFC do sistema de aplicativos SAP a ser usado como origem de dados.
- Para especificar o destino:
- Insira NONE como conexão RFC.
- Escolha ODQ Replication Scenario para comunicação RFC. Usando esse cenário, especifique que os dados são transferidos usando a infraestrutura de provisionamento de dados operacionais com filas delta operacionais.
- Atribua um alias de fila.
O alias de fila é usado no SAP Data Services para a configuração de contexto ODP da origem de dados.
Configuração do SAP Data Services
Criar um projeto de serviços de dados
- Abra o aplicativo SAP Data Services Designer.
- Acesse File > New > Project.
- Especifique um nome no campo Project name.
- Em Data Services Repository, selecione seu repositório de serviços de dados.
- Clique em Finish. Seu projeto aparece no Project Explorer à esquerda.
O SAP Data Services se conecta aos sistemas de origem para coletar metadados e, em seguida, ao agente do SAP Replication Server para recuperar a configuração e alterar dados.
Criar um armazenamento de dados de origem
Nas etapas a seguir, criamos uma conexão com o SAP LT Replication Server e adicionamos as tabelas de dados ao nó do armazenamento de dados relevante na biblioteca de objetos do Designer.
Para usar o SAP LT Replication Server com o SAP Data Services, é preciso conectar o SAP Data Services à fila delta operacional correta no ODP. Para isso, conecte um armazenamento de dados à infraestrutura do ODP.
- Abra o aplicativo SAP Data Services Designer.
- No Project Explorer, clique com o botão direito do mouse no nome do projeto do SAP Data Services.
- Selecione New > Datastore.
- Preencha o campo Datastore Name. Por exemplo, DS_SLT.
- No campo Datastore type, selecione SAP Applications.
- No campo Application server name, forneça o nome da instância do SAP LT Replication Server.
- Especifique as credenciais de acesso do SAP LT Replication Server.
- Abra a guia Advanced.
- Em Contexto ODP, digite SLT~ALIAS, em que ALIAS é o alias de fila especificado em Configurar a fila delta operacional (ODQ).
- Clique em OK.
O novo armazenamento de dados aparece na guia Datastore na biblioteca de objetos local no Designer.
Criar o armazenamento de dados de destino
Nestas etapas, criamos um armazenamento de dados do BigQuery que usa a conta de serviço criada anteriormente na seção Criar uma conta de serviço. Com a conta de serviço, o SAP Data Services pode acessar o BigQuery com segurança.
Para mais informações, consulte Receber o e-mail da sua conta de serviço do Google e Receber um arquivo de chave privada da conta de serviço do Google na documentação do SAP Data Services.
- Abra o aplicativo SAP Data Services Designer.
- No Project Explorer, clique com o botão direito do mouse no nome do projeto do SAP Data Services.
- Selecione New > Datastore.
- Preencha o campo Name. Por exemplo, BQ_DS.
- Clique em Next.
- No campo Datastore type, selecione Google BigQuery.
- A opção Web Service URL é exibida. O software preenche automaticamente a opção com o URL padrão do serviço da Web do BigQuery.
- Selecione Advanced.
- Conclua as opções avançadas com base nas descrições de opções do armazenamento de dados para o BigQuery na documentação do SAP Data Services.
- Clique em OK.
O novo armazenamento de dados aparece na guia Datastore na biblioteca de objetos locais do Designer.
Importar os objetos ODP de origem para replicação
Nestas etapas, importamos objetos ODP do armazenamento de dados de origem para as cargas inicial e delta e os disponibilizamos no SAP Data Services.
- Abra o aplicativo SAP Data Services Designer.
- No Project Explorer, expanda o armazenamento de dados de origem para a carga de replicação.
- Selecione a opção External Metadata na parte superior do painel direito. A lista de nós com tabelas e objetos ODP disponíveis é exibida.
- Clique no nó de objetos ODP para recuperar a lista de objetos ODP disponíveis. A lista pode levar muito tempo para ser exibida.
- Clique no botão Search.
- Na caixa de diálogo, selecione External data no menu Look in e ODP object no menu Object type.
- Na caixa de diálogo "Search", selecione os critérios de pesquisa para filtrar a lista de objetos ODP de origem.
- Selecione o objeto ODP a importar da lista.
- Clique com o botão direito do mouse e selecione a opção Import.
- Preencha o campo Name of Consumer.
- Preencha o campo Name of project.
- Selecione a opção Changed-data capture (CDC) em Extraction mode.
- Clique em Importar. Isso inicia a importação do objeto ODP para o Data Services. O objeto ODP agora está disponível na biblioteca de objetos no nó DS_SLT.
Para mais informações, consulte Como importar metadados de origem ODP na documentação do SAP Data Services.
Criar um arquivo de esquema
Nestas etapas, criamos um fluxo de dados no SAP Data Services para gerar um arquivo de esquema que reflete a estrutura das tabelas de origem. Posteriormente, você usará o arquivo de esquema para criar uma tabela do BigQuery.
O esquema garante que o fluxo de dados do carregador do BigQuery preencha a nova tabela do BigQuery.
Criar um fluxo de dados
- Abra o aplicativo SAP Data Services Designer.
- No Project Explorer, clique com o botão direito do mouse no nome do projeto do SAP Data Services.
- Selecione Project.
- Preencha o campo Name. Por exemplo, DF_BQ.
- Clique em Finish.
Atualizar a biblioteca de objetos
- Clique com o botão direito do mouse no armazenamento de dados de origem para a carga inicial no Project Explorer e selecione a opção Refresh Object Library. Isso atualiza a lista de tabelas de banco de dados da origem de dados que se pode usar no fluxo de dados.
Criar seu fluxo de dados
- Crie seu fluxo de dados arrastando e soltando as tabelas de origem no espaço de trabalho do fluxo de dados e escolhendo Import as Source quando solicitado.
- Na guia Transforms da biblioteca de objetos, arraste uma transformação XML_Map do nó Platform para o fluxo de dados e escolha a opção Batch Load quando solicitado.
- Conecte todas as tabelas de origem no espaço de trabalho à transformação XML Map.
- Abra a transformação de XML Map e preencha as seções de esquema de entrada e saída com base nos dados incluídos na tabela do BigQuery.
- Clique com o botão direito do mouse no nó XML_Map na coluna Schema Out e selecione Generate Google BigQuery Schema no menu suspenso.
- Insira um nome e um local para o esquema.
- Clique em Salvar.
- No Project Explorer, clique com o botão direito do mouse no fluxo de dados e selecione Remove.
O SAP Data Services gera um arquivo de esquema com a extensão de arquivo .json.
Criar as tabelas do BigQuery
Você precisa criar tabelas no conjunto de dados do BigQuery no Google Cloud para as cargas inicial e delta. Use os esquemas criados no SAP Data Services para criar as tabelas.
A tabela de carga inicial é usada para a replicação inicial de todo o conjunto de dados de origem. A tabela de carga delta é usada para a replicação das alterações no conjunto de dados de origem que ocorrem após a carga inicial. As tabelas são baseadas no esquema que você gerou na etapa anterior. A tabela das cargas delta inclui um outro campo de carimbo de data/hora que identifica o horário de cada carga delta.
Criar uma tabela do BigQuery para a carga inicial
Nestas etapas, criamos uma tabela para a carga inicial no conjunto de dados do BigQuery.
- Acesse seu projeto Google Cloud no console Google Cloud .
- Selecione BigQuery.
- Clique no conjunto de dados relevante.
- Clique em Criar tabela.
- Insira um nome para a tabela. Por exemplo, BQ_INIT_LOAD.
- Em Esquema, ative a opção Editar como texto.
- Defina o esquema da nova tabela no BigQuery copiando e colando o conteúdo do arquivo de esquema que você criou em Criar um arquivo de esquema.
- Clique em Criar tabela.
Criar uma tabela do BigQuery para as cargas delta
Nestas etapas, criamos uma tabela para as cargas delta do conjunto de dados do BigQuery.
- Acesse seu projeto Google Cloud no console Google Cloud .
- Selecione BigQuery.
- Clique no conjunto de dados relevante.
- Clique em Criar tabela.
- Insira o nome da tabela. Por exemplo, BQ_DELTA_LOAD.
- Em Esquema, defina a configuração para ativar o modo Editar como texto.
- Defina o esquema da nova tabela no BigQuery copiando e colando o conteúdo do arquivo de esquema que você criou em Criar um arquivo de esquema.
Na lista JSON no arquivo de esquema, imediatamente antes da definição do campo DI_SEQUENCE_NUMBER, adicione a definição de campo DL_TIMESTAMP a seguir. Este campo armazena o carimbo de data/hora de cada execução de carga delta:
{ "name": "DL_TIMESTAMP", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "Delta load timestamp" },Clique em Criar tabela.
Configurar o fluxo de dados entre o SAP Data Services e o BigQuery
Para configurar o fluxo de dados, você precisa importar as tabelas do BigQuery para o SAP Data Services como metadados externos e criar o job de replicação e o fluxo de dados do carregador do BigQuery.
Importar as tabelas do BigQuery
Nestas etapas, importamos as tabelas do BigQuery que você criou na etapa anterior e as disponibilizamos no SAP Data Services.
- Na biblioteca de objetos do SAP Data Services Designer, abra o armazenamento de dados do BigQuery criado anteriormente.
- Na parte superior do painel direito, selecione External Metadata. As tabelas do BigQuery que você criou aparecem.
- Clique com o botão direito do mouse no nome da tabela do BigQuery aplicável e selecione Import.
- A importação da tabela selecionada para o SAP Data Services é iniciada. A tabela agora está disponível na biblioteca de objetos no nó de armazenamento de dados de destino.
Criar um job de replicação e o fluxo de dados do carregador do BigQuery
Nestas etapas, criamos um job de replicação e o fluxo de dados no SAP Data Services. Eles são usados para carregar os dados do SAP LT Replication Server na tabela do BigQuery.
O fluxo de dados consiste em duas partes. A primeira executa a carga inicial de dados dos objetos ODP de origem para a tabela do BigQuery e a segunda ativa as cargas delta subsequentes.
Criar uma variável global
Para que o job de replicação possa determinar se é necessário executar uma carga inicial ou delta, você precisa criar uma variável global para rastrear o tipo da carga na lógica do fluxo de dados.
- No menu do aplicativo SAP Data Services Designer, acesse Tools > Variables.
- Clique com o botão direito do mouse em Global Variables e selecione Insert.
- Clique com o botão direito do mouse na variável Name e selecione Properties.
- Insira $INITLOAD na variável Name.
- Em Data Type, selecione Int.
- Insira 0 no campo Value.
- Clique em OK.
Criar o job de replicação
- No Project Explorer, clique com o botão direito do mouse no nome do projeto.
- Selecione New > Batch Job.
- Preencha o campo Name. Por exemplo, JOB_SRS_DS_BQ_REPLICATION.
- Clique em Finish.
Criar lógica de fluxo de dados para a carga inicial
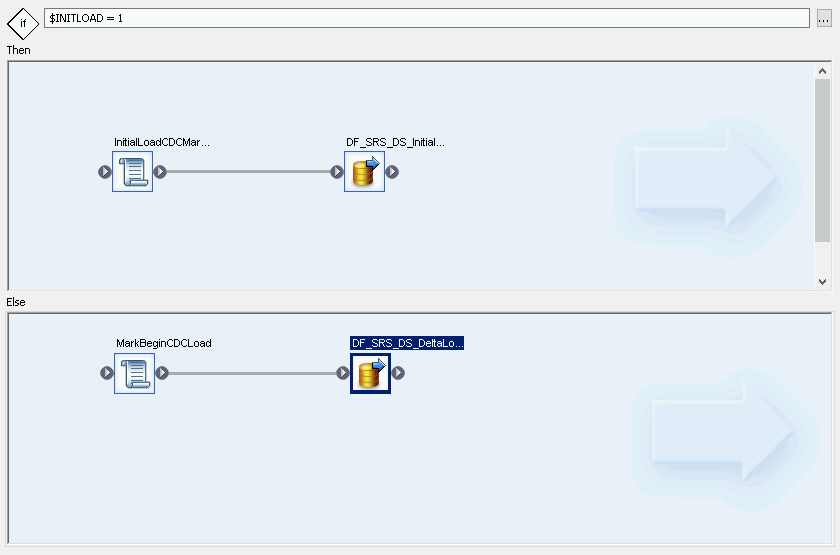
Criar uma condicional
- Clique com o botão direito do mouse em Job Name e selecione a opção Add New > Conditional.
- Clique com o botão direito do mouse no ícone de condicional e selecione Rename.
Altere o nome para InitialOrDelta.

Abra o editor de condicional clicando duas vezes no ícone de condicional.
No campo If statement, insira $INITLOAD = 1, que define a condição para executar a carga inicial.
Clique com o botão direito no painel Then e selecione Add New > Script.
Clique com o botão direito do mouse no ícone Script e selecione Rename.
Altere o nome. Por exemplo, nestas instruções, usamos InitialLoadCDCMarker.
Clique duas vezes no ícone Script para abrir o editor de funções.
Insira
print('Beginning Initial Load');Insira
begin_initial_load();
Clique no ícone "Back" na barra de ferramentas do aplicativo para sair do editor de funções.
Criar um fluxo de dados para a carga inicial
- Clique com o botão direito do mouse no painel Then e selecione Add New > Data Flow.
- Renomeie o fluxo de dados. Por exemplo, DF_SRS_DS_InitialLoad.
- Conecte o InitialLoadCDCMarker ao DF_SRS_DS_InitialLoad clicando no ícone de saída de conexão de InitialLoadCDCMarker e arrastando a linha de conexão para o ícone de entrada de DF_SRS_DS_InitialLoad.
- Clique duas vezes no fluxo de dados DF_SRS_DS_InitialLoad.
Importar e conectar o fluxo de dados aos objetos do armazenamento de dados de origem
- No armazenamento de dados, arraste e solte os objetos ODP de origem no espaço de trabalho do fluxo de dados. Nestas instruções, o armazenamento de dados é DS_SLT. O nome de seu armazenamento de dados pode ser diferente.
- Arraste a transformação Query do nó Platform na guia Transforms da biblioteca de objetos para o fluxo de dados.
Clique duas vezes nos objetos ODP e, na guia Source, defina a opção Initial Load como Yes.
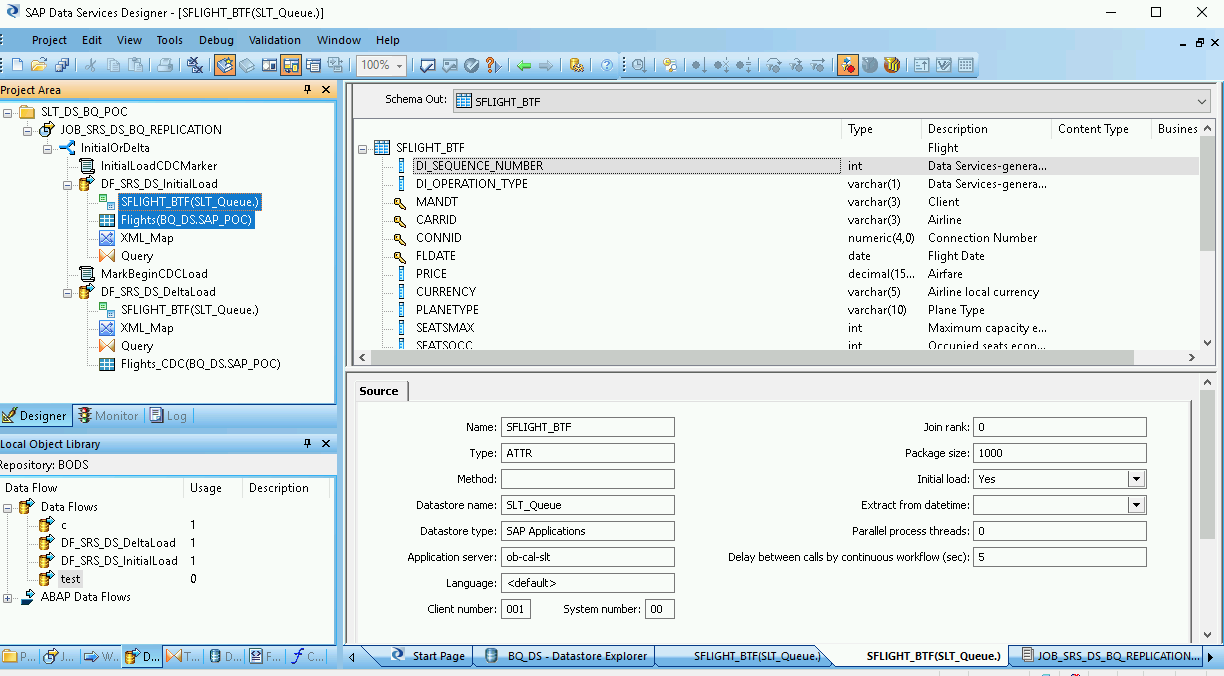
Conecte todos os objetos ODP de origem no espaço de trabalho à transformação Query.
Clique duas vezes na transformação Query.
Selecione todos os campos da tabela em Schema In à esquerda e arraste-os para Schema Out à direita.
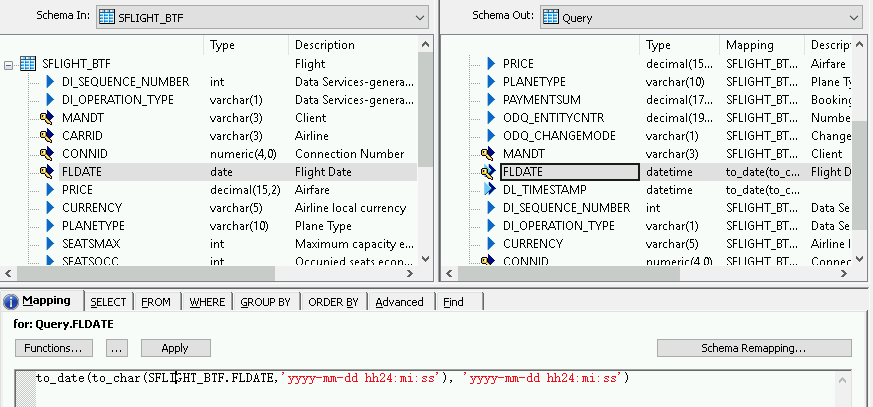
Para adicionar uma função de conversão a um campo de data e hora:
- Selecione o campo de data e hora na lista Schema Out à direita.
- Selecione a guia Mapping abaixo das listas de esquema.
Substitua o nome do campo pela função a seguir:
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')Em que FIELDNAME é o nome do campo selecionado.
Clique no ícone "Back" na barra de ferramentas do aplicativo para voltar ao fluxo de dados.
Importar e conectar o fluxo de dados aos objetos do armazenamento de dados de destino
- No armazenamento de dados na biblioteca de objetos, arraste a tabela importada do BigQuery para a carga inicial no fluxo de dados. Nestas instruções, o armazenamento de dados usa o nome BQ_DS. O nome de seu armazenamento de dados pode ser diferente.
- No nó Platform na guia Transforms da biblioteca de objetos, arraste uma transformação XML_Map para o fluxo de dados.
- Selecione Batch mode na caixa de diálogo.
- Conecte a transformação Query à transformação XML_Map.
Conecte a transformação XML_Map à tabela importada do BigQuery.
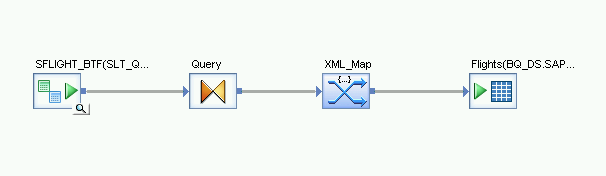
Abra a transformação XML_Map e preencha as seções do esquema de entrada e saída com base nos dados incluídos na tabela do BigQuery.
Clique duas vezes na tabela do BigQuery no espaço de trabalho para abri-la e concluir as opções na guia Target, conforme indicado na tabela a seguir:
| Opção | Descrição |
|---|---|
| Make Port | Especifique No, que é o padrão. Ao especificar Yes, você transforma um arquivo de origem ou de destino em uma porta de fluxo de dados incorporada. |
| Mode | Especifique Truncate para a carga inicial, que substitui todos os registros atuais na tabela do BigQuery pelos dados carregados pelo SAP Data Services. Truncate é o padrão. |
| Number of loaders | Especifique um número inteiro positivo para definir o número de carregadores (linhas de execução) a serem usados para processamento. O padrão é 4.
Cada carregador inicia um job de carga retomável no BigQuery. É possível especificar qualquer número de carregadores. Para saber como determinar um número adequado de carregadores, consulte a documentação da SAP, incluindo: |
| Maximum failed records per loader | Especifique 0 ou um número inteiro positivo para definir o número máximo de registros que podem falhar por job de carga antes que o BigQuery pare de carregar registros. O padrão é zero (0). |
- Clique no ícone "Validate" na barra de ferramentas superior.
- Clique no ícone "Back" na barra de ferramentas do aplicativo para retornar ao editor de condicional.
Criar um fluxo de dados para a carga delta
Você precisa criar um fluxo de dados para replicar os registros de captura de dados alterados que se acumulam após a carga inicial.
Criar um fluxo delta de condicional
- Clique duas vezes na condicional InitialOrDelta.
- Clique com o botão direito do mouse na seção Else e selecione Add New. Script.
- Renomeie o script. Por exemplo, MarkBeginCDCLoad.
- Clique duas vezes no ícone "Script" para abrir o editor de funções.
Insira print('Beginning Delta Load');

Clique no ícone "Back" na barra de ferramentas do aplicativo para voltar ao editor de condicional.
Criar o fluxo de dados para a carga delta
- No editor de condicional, clique com o botão direito do mouse e selecione Add New > Data Flow.
- Renomeie o fluxo de dados. Por exemplo, DF_SRS_DS_DeltaLoad.
- Conecte MarkBeginCDCLoad a DF_SRS_DS_DeltaLoad, conforme mostrado no diagrama.
Clique duas vezes no fluxo de dados DF_SRS_DS_DeltaLoad.
Importar e conectar o fluxo de dados aos objetos do armazenamento de dados de origem
- Arraste e solte os objetos ODP de origem do armazenamento de dados no espaço de trabalho do fluxo de dados. Nestas instruções, o armazenamento de dados usa o nome DS_SLT. O nome de seu armazenamento de dados pode ser diferente.
- No nó Platform na guia Transforms da biblioteca de objetos, arraste a transformação Query para o fluxo de dados.
- Clique duas vezes nos objetos ODP e, na guia Source, defina a opção Initial Load como No.
- Conecte todos os objetos ODP de origem no espaço de trabalho à transformação Query.
- Clique duas vezes na transformação Query.
- Selecione todos os campos da tabela na lista "Schema" à esquerda e arraste-os para a lista "Schema" à direita
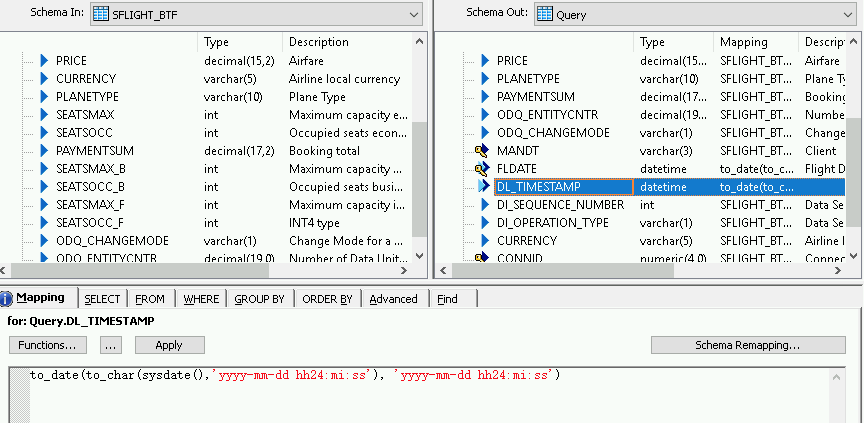
Ativar o carimbo de data/hora das cargas delta
Nas etapas a seguir, o SAP Data Services pode registrar automaticamente o carimbo de data/hora de cada execução de carga delta em um campo na tabela de carga delta.
- Clique com o botão direito do mouse no nó Query no painel "Schema Out" à direita.
- Selecione New Output Column.
- Insira DL_TIMESTAMP em Name.
- Selecione data e hora em Data type.
- Clique em OK.
- Clique no campo DL_TIMESTAMP recém-criado.
- Acesse a guia Mapping abaixo.
Insira a função a seguir:
- to_date(to_char(sysdate(),'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
Importar e conectar o fluxo de dados aos objetos do armazenamento de dados de destino
- No armazenamento de dados na biblioteca de objetos, arraste a tabela importada do BigQuery da carga delta para o espaço de trabalho do fluxo de dados após a transformação XML_Map. Nestas instruções, usamos o nome de exemplo de armazenamento de dados BQ_DS. O nome de seu armazenamento de dados pode ser diferente.
- No nó Platform na guia Transforms da biblioteca de objetos, arraste uma transformação XML_Map para o fluxo de dados.
- Conecte a transformação Query à transformação XML_Map.
Conecte a transformação XML_Map à tabela importada do BigQuery.
Abra a transformação XML_Map e conclua as seções do esquema de entrada e saída com base nos dados incluídos na tabela do BigQuery.
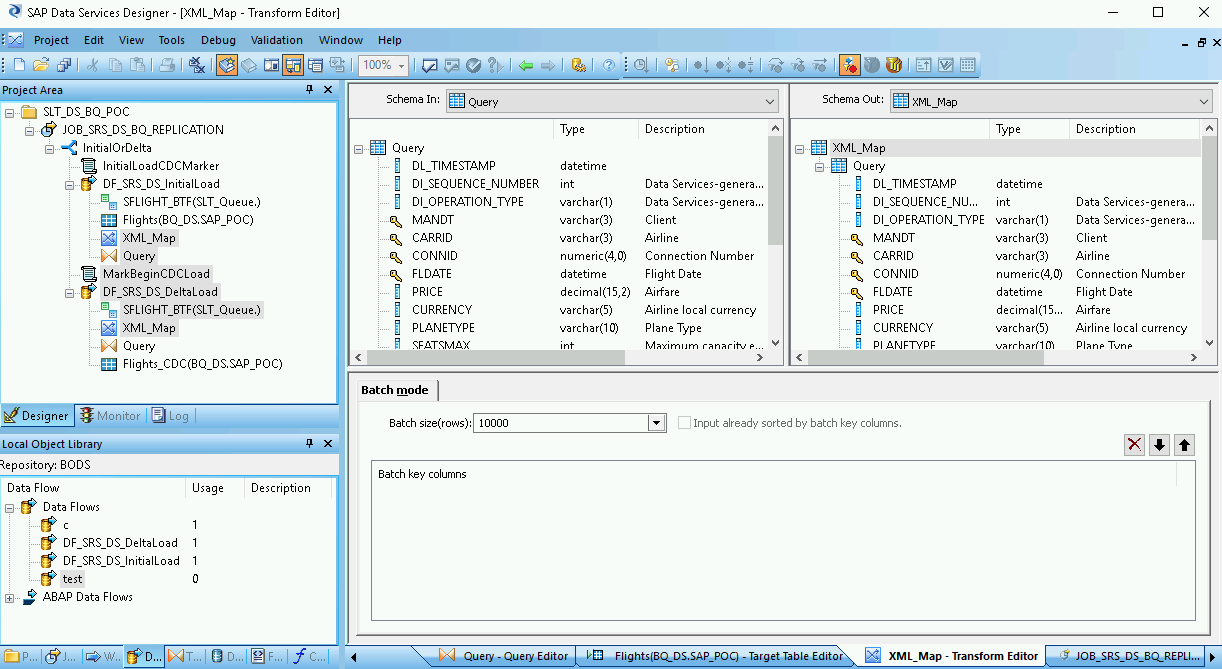
Clique duas vezes na tabela do BigQuery no espaço de trabalho para abri-la e concluir as opções na guia Target com base nas descrições a seguir:
| Opção | Descrição |
|---|---|
| Make Port | Especifique No, que é o padrão. Ao especificar Yes, você transforma um arquivo de origem ou de destino em uma porta de fluxo de dados incorporada. |
| Mode | Especifique Append para as cargas delta, que mantém os registros atuais na tabela do BigQuery quando novos registros são carregados do SAP Data Services. |
| Number of loaders | Especifique um número inteiro positivo para definir o número de carregadores (linhas de execução) a serem usados para processamento.
Cada carregador inicia um job de carga retomável no BigQuery. É possível especificar qualquer número de carregadores. Geralmente, as cargas delta precisam de menos carregadores que a carga inicial. Para saber como determinar um número adequado de carregadores, consulte a documentação da SAP, incluindo: |
| Maximum failed records per loader | Especifique 0 ou um número inteiro positivo para definir o número máximo de registros que podem falhar por job de carga antes que o BigQuery pare de carregar registros. O padrão é zero (0). |
- Clique no ícone "Validate" na barra de ferramentas superior.
- Clique no ícone "Back" na barra de ferramentas do aplicativo para voltar ao editor de condicional.
Como carregar os dados no BigQuery
As etapas para uma carga inicial e uma carga delta são semelhantes. Para cada uma delas, inicie o job de replicação e execute o fluxo de dados no SAP Data Services para carregar os dados do SAP LT Replication Server no BigQuery. Uma diferença importante entre os dois procedimentos de carga é o valor da variável global $INITLOAD. Para uma carga inicial, é preciso definir INITLOAD como 1. Para uma carga delta, $INITLOAD precisa ser 0.
Executar uma carga inicial
Quando você executa uma carga inicial, todos os dados no conjunto de dados de origem são replicados para a tabela de destino do BigQuery que está conectada ao fluxo de dados de carga inicial. Todos os dados na tabela de destino são substituídos.
- No SAP Data Services Designer, abra o Project Explorer.
- Clique com o botão direito do mouse no nome do job de replicação e selecione Execute. Uma caixa de diálogo é exibida.
- Na caixa de diálogo, acesse a guia Global Variable e altere o valor de
$INITLOADpara 1 para que a carga inicial seja executada primeiro. - Clique em OK. O processo de carregamento é iniciado e as mensagens de depuração começam a aparecer no registro do SAP Data Services. Os dados são carregados na tabela que você criou no BigQuery para cargas iniciais. Nestas instruções, o nome da tabela de carga inicial é BQ_INIT_LOAD. O nome de sua tabela pode ser diferente.
- Para conferir se o carregamento foi concluído, acesse o console Google Cloud e abra o conjunto de dados do BigQuery que contém a tabela. Se os dados ainda estiverem sendo carregados, a mensagem "Carregando" vai aparecer ao lado do nome da tabela.
Após o carregamento, os dados estarão prontos para processamento no BigQuery.
Deste ponto, todas as alterações na tabela de origem serão registradas na fila delta do SAP LT Replication Server. Para carregar os dados da fila delta no BigQuery, execute um job de carga delta.
Executar uma carga delta
Quando você executa uma carga delta, somente as alterações que ocorreram no conjunto de dados de origem desde a última carga são replicadas na tabela de destino do BigQuery conectada ao fluxo de dados da carga delta.
- Clique com o botão direito do mouse no nome do job e selecione Execute.
- Clique em OK. O processo de carregamento é iniciado e as mensagens de depuração começam a aparecer no registro do SAP Data Services. Os dados são carregados na tabela que você criou no BigQuery para as cargas delta. Nestas instruções, o nome da tabela de carga delta é BQ_DELTA_LOAD. O nome de sua tabela pode ser diferente.
- Para conferir se o carregamento foi concluído, acesse o console Google Cloud e abra o conjunto de dados do BigQuery que contém a tabela. Se os dados ainda estiverem sendo carregados, a mensagem "Carregando" vai aparecer ao lado do nome da tabela.
- Após o carregamento, os dados estarão prontos para processamento no BigQuery.
Para rastrear as alterações nos dados de origem, o SAP LT Replication Server registra a ordem das operações de dados alterados na coluna DI_SEQUENCE_NUMBER e o tipo de operação de dados alterados na coluna DI_OPERATION_TYPE (D=delete, U=update, I=insert). O SAP LT Replication Server armazena os dados nas colunas das tabelas de fila delta, de onde são replicados para o BigQuery.
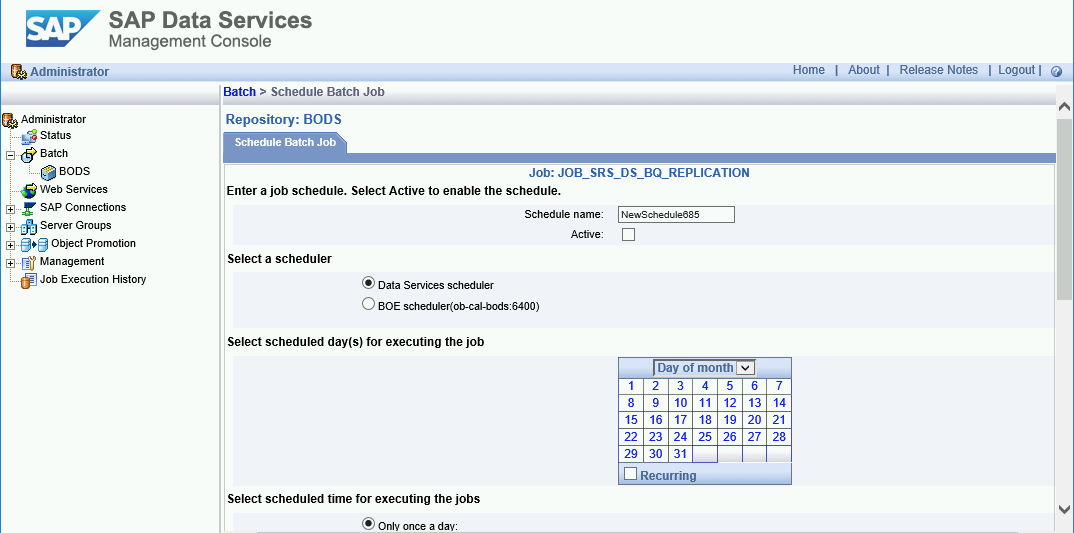
Como programar cargas delta
É possível programar um job de carga delta para ser executado em intervalos regulares usando o SAP Data Services Management Console.
- Abra o aplicativo SAP Data Services Management Console.
- Clique em Administrator.
- Expanda o nó Batch na árvore de menus à esquerda.
- Clique no nome do repositório do SAP Data Services.
- Clique na guia Batch Job Configuration.
- Clique em Add Schedule.
- Preencha o Schedule name.
- Marque Active.
- Na seção Select scheduled time for executing the jobs, especifique a frequência da execução da carga delta.
- Importante: Google Cloud limita o número de jobs de carregamento do BigQuery que podem ser executados em um dia. Certifique-se de que sua programação não exceda o limite, que não pode ser aumentado. Para mais informações sobre o limite de jobs de carregamento do BigQuery, consulte Cotas e limites na documentação do BigQuery.
- Expanda Global Variables e verifique se $INITLOAD está definida como 0.
- Clique em Apply.
A seguir
Consulte e analise dados replicados no BigQuery.
Para mais informações sobre consultas, veja:
- Visão geral da consulta de dados do BigQuery na documentação do BigQuery.
Para algumas ideias sobre como consolidar dados de cargas inicial e delta no BigQuery em grande escala, consulte:
- Solução Como realizar mutações em grande escala no BigQuery disponível no Google Cloud blog.
- Linguagem de manipulação de dados na documentação do BigQuery.
Confira arquiteturas de referência, diagramas, tutoriais e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.