이 안내에서는 SAP Landscape Transformation(LT) Replication Server와 SAP Data Services(DS)를 사용하여 SAP S/4HANA 또는 SAP Business Suite와 같은 SAP 애플리케이션에서 BigQuery로 데이터를 복제하는 솔루션을 설정하는 방법을 설명합니다.
데이터 복제를 사용하면 SAP 데이터를 거의 실시간으로 백업할 수 있으며 SAP 시스템의 데이터를 BigQuery에 있는 다른 시스템의 소비자 데이터와 통합하여 머신러닝으로부터 유용한 정보를 얻거나 페타바이트급 규모의 데이터 분석을 수행할 수 있습니다.
이 안내는 SAP Basis, SAP LT Replication Server, SAP DS, Google Cloud구성에 대한 기본 경험이 있는 SAP 시스템 관리자를 대상으로 합니다.
아키텍처

SAP LT Replication Server는 SAP NetWeaver Operational Data Provisioning Framework(ODP)의 데이터 제공자 역할을 수행할 수 있습니다. SAP LT Replication Server는 연결된 SAP 시스템에서 데이터를 수신하여 SAP LT Replication Server 시스템의 Operational Delta Queue(ODQ)에 ODP 프레임워크로 저장합니다. 따라서 SAP LT Replication Server 자체가 SAP LT Replication Server 구성의 대상으로 작동할 수도 있습니다. ODP 프레임워크는 소스 시스템 테이블에 해당하는 데이터를 ODP 객체로 사용할 수 있도록 해줍니다.
ODP 프레임워크는 구독자라고 하는 다양한 대상 SAP 애플리케이션에 추출 및 복제 시나리오를 지원합니다. 구독자는 델타 큐에서 데이터를 검색하여 추가 처리합니다.
구독자가 ODP 컨텍스트를 통해 데이터 소스에서 데이터를 요청하자마자 데이터가 복제됩니다. 여러 구독자가 동일한 ODQ를 소스로 사용할 수 있습니다.
SAP LT Replication Server는 SAP Data Services 4.2 SP1 이상의 변경된 데이터 캡처(CDC) 지원을 활용합니다. 여기에는 모든 소스 테이블에의 실시간 데이터 프로비저닝 및 델타 기능이 포함됩니다.
다음 다이어그램에서는 시스템을 통한 데이터 흐름을 보여줍니다.
- SAP 애플리케이션이 소스 시스템의 데이터를 업데이트합니다.
- SAP LT Replication Server가 데이터 변경사항을 복제하고 이 데이터를 운영 델타 큐에 저장합니다.
- SAP DS는 운영 델타 큐의 구독자이며 정기적으로 큐를 폴링해 데이터 변경사항을 확인합니다.
- SAP DS는 델타 큐에서 데이터를 검색하고, BigQuery 형식과 호환되도록 데이터를 변환하며, 데이터를 BigQuery로 이동하는 로드 작업을 시작합니다.
- 데이터는 BigQuery에서 분석용으로 사용될 수 있습니다.
이 시나리오에서 SAP 소스 시스템, SAP LT Replication Server, SAP Data Services는 Google Cloud에서 또는 Google Cloud외부에서 실행될 수 있습니다. SAP에서 제공하는 자세한 내용은 SAP Landscape Transformation Replication Server를 사용한 실시간 운영 데이터 프로비저닝을 참고하세요.

핵심 솔루션 구성요소
SAP Landscape Transformation Replication Server와 SAP Data Services를 사용하여 SAP 애플리케이션에서 BigQuery로 데이터를 복제하려면 다음 구성요소가 필요합니다.
| 구성요소 | 필요 버전 | 참고 |
|---|---|---|
| SAP 애플리케이션 서버 스택 | R/3 4.6C 이상의 모든 ABAP 기반 SAP 시스템 SAP_Basis(최소 요구사항):
|
이 가이드에서는 애플리케이션 서버와 데이터베이스 서버를 통칭하여 소스 시스템이라 하며, 이는 이들 서버가 서로 다른 머신에서 실행 중인 경우에도 마찬가지입니다. 적절한 승인으로 RFC 사용자 정의 선택사항: 테이블 로깅을 위한 별도의 테이블 공간 정의 |
| 데이터베이스(DB) 시스템 | SAP Product Availability Matrix(PAM)에 나와 있는 SAP NetWeaver 스택 제한사항이 적용되며 PAM에서 지원되는 것으로 나와 있는 모든 DB 버전. service.sap.com/pam을 참조하세요. | |
| 운영체제(OS) | PAM에 나와 있는 SAP NetWeaver 스택 제한사항이 적용되며 SAP PAM에서 지원되는 것으로 나와 있는 모든 OS 버전. service.sap.com/pam을 참조하세요. | |
| SAP Data Migration Server(DMIS) | DMIS:
|
|
| SAP Landscape Transformation Replication Server | SAP LT Replication Server 2.0 이상 | 소스 시스템에 RFC 연결이 필요합니다. SAP LT Replication Server 시스템의 크기 조정은 ODQ에 저장된 데이터 양과 계획된 보관 기간에 따라 크게 달라집니다. |
| SAP Data Services | SAP Data Services 4.2 SP1 이상 | |
| BigQuery | 해당 사항 없음 |
비용
BigQuery는 청구 가능한 Google Cloud 구성요소입니다.
가격 계산기를 사용하면 예상 사용량을 기준으로 예상 비용을 산출할 수 있습니다.
기본 요건
이 안내에서는 SAP 애플리케이션 서버, 데이터베이스 서버, SAP LT Replication Server, SAP Data Services가 이미 정상적으로 작동할 수 있도록 설치 및 구성되어 있다고 가정합니다.
BigQuery를 사용하려면 먼저 Google Cloud프로젝트가 필요합니다.
Google Cloud에서 Google Cloud 프로젝트 설정
BigQuery API를 사용 설정해야 하며,Google Cloud 프로젝트를 아직 만들지 않았으면 지금 만들어야 합니다.
Google Cloud 프로젝트 만들기
Google Cloud 콘솔로 이동하고 로그인하여 설정 마법사를 진행합니다.
왼쪽 상단의 Google Cloud 로고 옆에 있는 드롭다운을 클릭하고 프로젝트 만들기를 선택합니다.
프로젝트 이름을 지정하고 만들기를 클릭합니다.
프로젝트가 생성되면(오른쪽 상단에 알림 표시) 페이지를 새로고칩니다.
API 사용 설정
BigQuery API를 사용 설정합니다.
Google Cloud API에 대한 비공개 액세스 사용 설정
Google Cloud외부에서 실행되는 SAP 워크로드의 경우 Google Cloud에 네트워크 연결을 설정한 후 Google Cloud API에 대한 비공개 액세스를 사용 설정해야 합니다.
자세한 내용은 서비스의 비공개 Google 액세스 옵션을 참고하세요.
서비스 계정 만들기
서비스 계정(특히 키 파일)은 SAP DS를 BigQuery에 인증하는 데 사용됩니다. 키 파일은 나중에 대상 Datastore를 만들 때 사용됩니다.
Google Cloud 콘솔에서 서비스 계정 페이지로 이동합니다.
Google Cloud 프로젝트를 선택합니다.
서비스 계정 만들기를 클릭합니다.
서비스 계정 이름을 입력합니다.
만들고 계속하기를 클릭합니다.
역할 선택 목록에서 BigQuery > BigQuery 데이터 편집자를 선택합니다.
다른 역할 추가를 클릭합니다.
역할 선택 목록에서 BigQuery > BigQuery 작업 사용자를 선택합니다.
계속을 클릭합니다.
필요에 따라 다른 사용자에게 서비스 계정에 대한 액세스 권한을 부여합니다.
완료를 클릭합니다.
Google Cloud 콘솔의 서비스 계정 페이지에서 방금 만든 서비스 계정의 이메일 주소를 클릭합니다.
서비스 계정 이름에서 키 탭을 클릭합니다.
키 추가 드롭다운 메뉴를 클릭한 후 새 키 만들기를 선택합니다.
JSON 키 유형이 지정되었는지 확인합니다.
만들기를 클릭합니다.
자동으로 다운로드된 키 파일을 안전한 위치에 저장합니다.
SAP 애플리케이션과 BigQuery 간 복제 구성
이 솔루션 구성에는 다음과 같은 상위 수준 단계가 포함되어 있습니다.
- SAP LT Replication Server 구성
- SAP Data Services 구성
- SAP Data Services와 BigQuery 간의 데이터 흐름 만들기
SAP Landscape Transformation Replication Server 구성
다음 단계에서는 SAP LT Replication Server가 운영 데이터 프로비저닝 프레임워크 내에서 제공자 역할을 수행하고 운영 델타 큐를 만들도록 구성합니다. 이 구성에서 SAP LT Replication Server는 트리거 기반 복제를 사용하여 소스 SAP 시스템의 데이터를 델타 큐의 테이블로 복사합니다. ODP 프레임워크에서 구독자 역할을 수행하는 SAP Data Services는 델타 큐에서 데이터를 검색하여 변환한 후 BigQuery에 로드합니다.
운영 델타 큐(ODQ) 구성
- SAP LT Replication Server에서 트랜잭션
SM59를 사용하여 데이터 소스로 SAP 애플리케이션 시스템용 RFC 대상을 만듭니다. - SAP LT Replication Server에서 트랜잭션
LTRC를 사용하여 구성을 만듭니다. 구성에서 SAP LT Replication Server의 소스 및 대상을 정의합니다. ODP를 사용한 데이터 전송 대상은 SAP LT Replication Server입니다.- 소스를 지정하려면 데이터 소스로 사용할 SAP 애플리케이션 시스템의 RFC 대상을 입력합니다.
- 대상을 지정하려면 다음 안내를 따르세요.
- RFC 연결로 NONE(없음)을 입력합니다.
- RFC 통신에 사용할 ODQ 복제 시나리오를 선택합니다. 이 시나리오를 통해 운영 데이터 프로비저닝 인프라를 운영 델타 큐와 함께 사용하여 데이터가 전송되도록 지정합니다.
- 큐 별칭을 지정합니다.
큐 별칭은 SAP Data Services에서 데이터 소스 ODP 컨텍스트 설정에 사용됩니다.
SAP 데이터 서비스 구성
데이터 서비스 프로젝트 만들기
- SAP Data Services Designer 애플리케이션을 엽니다.
- 파일 > 새로 만들기 > 프로젝트로 이동합니다.
- 프로젝트 이름 필드에 이름을 지정합니다.
- 데이터 서비스 저장소에서 데이터 서비스 저장소를 선택합니다.
- 마침을 클릭합니다. 프로젝트가 왼쪽의 프로젝트 탐색기에 나타납니다.
SAP Data Services는 소스 시스템에 연결하여 메타데이터를 수집한 후 SAP Replication Server 에이전트에 연결하여 구성을 검색하고 데이터를 변경합니다.
소스 Datastore 만들기
다음 단계에서는 SAP LT Replication Server에 연결하고 Designer 객체 라이브러리의 해당 Datastore 노드에 데이터 테이블을 추가합니다.
SAP Data Services와 함께 SAP LT Replication Server를 사용하려면 Datastore를 ODP 인프라에 연결하여 SAP DataServices를 ODP의 올바른 운영 델타 큐에 연결해야 합니다.
- SAP Data Services Designer 애플리케이션을 엽니다.
- 프로젝트 탐색기에서 SAP Data Services 프로젝트 이름을 마우스 오른쪽 버튼으로 클릭합니다.
- 새로 만들기 > Datastore를 선택합니다.
- Datastore 이름을 입력합니다. 예를 들면 DS_SLT입니다.
- Datastore type(Datastore 유형) 필드에서 SAP Applications(SAP 애플리케이션)을 선택합니다.
- 애플리케이션 서버 이름 필드에 SAP LT Replication Server의 인스턴스 이름을 지정합니다.
- SAP LT Replication Server 액세스 사용자 인증 정보를 지정합니다.
- 고급 탭을 엽니다.
- ODP 컨텍스트에 SLT~ALIAS를 입력합니다. 여기서 ALIAS는 운영 델타 큐(ODQ) 구성에서 지정한 큐 별칭입니다.
- 확인을 클릭합니다.
새 Datastore가 Designer에 있는 로컬 객체 라이브러리의 Datastore 탭에 나타납니다.
대상 Datastore 만들기
이 단계에서는 이전 서비스 계정 만들기 섹션에서 만든 서비스 계정을 사용하는 BigQuery 데이터 스토어를 만듭니다. SAP Data Services는 서비스 계정을 통해 BigQuery에 안전하게 액세스할 수 있습니다.
자세한 내용은 SAP 데이터 서비스 문서의 Google 서비스 계정 이메일 가져오기 및 Google 서비스 계정 개인 키 파일 가져오기를 참조하세요.
- SAP Data Services Designer 애플리케이션을 엽니다.
- 프로젝트 탐색기에서 SAP Data Services 프로젝트 이름을 마우스 오른쪽 버튼으로 클릭합니다.
- 새로 만들기 > Datastore를 선택합니다.
- 이름 필드를 입력합니다. 예를 들면 BQ_DS입니다.
- 다음을 클릭합니다.
- Datastore type(Datastore 유형) 필드에서 Google BigQuery를 선택합니다.
- 웹 서비스 URL 옵션이 나타납니다. 옵션은 소프트웨어에서 기본 BigQuery 웹 서비스 URL로 자동 완성됩니다.
- 고급을 선택합니다.
- SAP Data Services 문서의 BigQuery용 데이터 스토어 옵션 설명을 따라 고급 옵션을 완료합니다.
- 확인을 클릭합니다.
새 Datastore가 Designer에 있는 로컬 객체 라이브러리의 Datastore 탭에 나타납니다.
복제할 소스 ODP 객체 가져오기
이 단계에서는 초기 로드 및 델타 로드의 소스 Datastore에서 ODP 객체를 가져와 SAP Data Services에서 사용할 수 있도록 만듭니다.
- SAP Data Services Designer 애플리케이션을 엽니다.
- 프로젝트 탐색기에서 복제 로드의 소스 Datastore를 펼칩니다.
- 오른쪽 패널 상단에서 외부 메타데이터 옵션을 선택합니다. 사용 가능한 테이블 및 ODP 객체가 포함된 노드 목록이 나타납니다.
- ODP 객체 노드를 클릭하여 사용 가능한 ODP 객체 목록을 검색합니다. 목록을 표시하는 데 시간이 오래 걸릴 수 있습니다.
- 검색 버튼을 클릭합니다.
- 대화상자의 Look in(찾는 위치) 메뉴에서 External data(외부 데이터)를 선택하고 Object type(객체 유형) 메뉴에서 ODP object(ODP 객체)를 선택합니다.
- 검색 대화상자에서 검색 기준을 선택하여 소스 ODP 객체 목록을 필터링합니다.
- 목록에서 가져올 ODP 객체를 선택합니다.
- 마우스 오른쪽 버튼을 클릭하고 가져오기 옵션을 선택합니다.
- 소비자 이름을 입력합니다.
- 프로젝트 이름을 입력합니다.
- Extraction mode(추출 모드)에서 Changed-data capture (CDC)(변경된 데이터 캡처(CDC)) 옵션을 선택합니다.
- 가져오기를 클릭합니다. 그러면 ODP 객체를 Data Services로 가져오기 시작합니다. 이제 ODP 객체를 객체 라이브러리의 DS_SLT 노드 아래에서 사용할 수 있습니다.
자세한 내용은 SAP Data Services 문서의 Importing ODP source metadata를 참조하세요.
스키마 파일 만들기
이 단계에서는 SAP Data Services에서 데이터 흐름을 만들어 소스 테이블의 구조가 반영된 스키마 파일을 생성합니다. 나중에 이 스키마 파일을 사용하여 BigQuery 테이블을 만들 수 있습니다.
스키마는 BigQuery 로더 데이터 흐름이 새 BigQuery 테이블을 채우도록 합니다.
데이터 흐름 만들기
- SAP Data Services Designer 애플리케이션을 엽니다.
- 프로젝트 탐색기에서 SAP Data Services 프로젝트 이름을 마우스 오른쪽 버튼으로 클릭합니다.
- 프로젝트 > 새로 만들기 > 데이터 흐름을 선택합니다.
- 이름 필드를 입력합니다. 예를 들면 DF_BQ입니다.
- 마침을 클릭합니다.
객체 라이브러리 새로고침
- 프로젝트 탐색기에서 초기 로드용 소스 Datastore를 마우스 오른쪽 버튼으로 클릭하고 객체 라이브러리 새로고침 옵션을 선택합니다. 그러면 데이터 흐름에 사용할 수 있는 데이터 소스 데이터베이스 테이블 목록이 업데이트됩니다.
데이터 흐름 빌드
- 소스 테이블을 데이터 흐름 작업공간으로 드래그하여 드롭하고 메시지가 표시되면 소스로 가져오기를 선택하여 데이터 흐름을 빌드합니다.
- 객체 라이브러리의 Transforms(변환) 탭에서 Platform(플랫폼) 노드 i의 XML_Map transform(XML_Map 변환)을 데이터 흐름으로 드래그하고 메시지가 표시되면 Batch Load(일괄 로드) 옵션을 선택합니다.
- 작업공간의 모든 소스 테이블을 XML 맵 변환에 연결합니다.
- XML 맵 변환을 열고 BigQuery 테이블에 포함될 데이터에 따라 입력 및 출력 스키마 섹션을 완료합니다.
- Schema Out(스키마 출력) 열에서 XML_Map 노드를 마우스 오른쪽 버튼으로 클릭하고 드롭다운 메뉴에서 Generate Google BigQuery Schema(Google BigQuery 스키마 생성)를 선택합니다.
- 스키마의 이름과 위치를 입력합니다.
- 저장을 클릭합니다.
- 프로젝트 탐색기에서 데이터 흐름을 마우스 오른쪽 버튼으로 클릭하고 삭제를 선택합니다.
SAP Data Services가 파일 확장자가 .json인 스키마 파일을 생성합니다.
BigQuery 테이블 만들기
초기 로드와 델타 로드 모두에서Google Cloud 의 BigQuery 데이터 세트에 테이블을 만들어야 합니다. SAP Data Services에서 만든 스키마를 사용하여 테이블을 만듭니다.
초기 로드용 테이블은 전체 소스 데이터 세트의 초기 복제에 사용됩니다. 델타 로드용 테이블은 초기 로드 이후에 발생하는 소스 데이터 세트의 변경사항을 복제하는 데 사용됩니다. 테이블은 이전 단계에서 생성한 스키마를 기반으로 합니다. 델타 로드용 테이블에는 각 델타 로드의 시간을 식별하는 추가 타임스탬프 필드가 포함됩니다.
초기 로드용 BigQuery 테이블 만들기
이 단계에서는 BigQuery 데이터 세트에 초기 로드용 테이블을 만듭니다.
- Google Cloud 콘솔에서 Google Cloud 프로젝트에 액세스합니다.
- BigQuery를 선택합니다.
- 해당 데이터 세트를 클릭합니다.
- 테이블 만들기를 클릭합니다.
- 테이블 이름을 입력합니다. 예를 들면 BQ_INIT_LOAD입니다.
- 스키마 아래에서 설정을 전환하여 텍스트로 편집 모드를 사용 설정합니다.
- 스키마 파일 만들기에서 만든 스키마 파일의 콘텐츠를 복사하고 붙여넣어 BigQuery에서 새 테이블의 스키마를 설정합니다.
- 테이블 만들기를 클릭합니다.
델타 로드용 BigQuery 테이블 만들기
이 단계에서는 BigQuery 데이터 세트의 델타 로드용 테이블을 만듭니다.
- Google Cloud 콘솔에서 Google Cloud 프로젝트에 액세스합니다.
- BigQuery를 선택합니다.
- 해당 데이터 세트를 클릭합니다.
- 테이블 만들기를 클릭합니다.
- 테이블 이름을 입력합니다. 예를 들면 BQ_DELTA_LOAD입니다.
- 스키마 아래에서 설정을 전환하여 텍스트로 편집 모드를 사용 설정합니다.
- 스키마 파일 만들기에서 만든 스키마 파일의 콘텐츠를 복사하고 붙여넣어 BigQuery에서 새 테이블의 스키마를 설정합니다.
스키마 파일의 JSON 목록에서 DI_SEQUENCE_NUMBER 필드의 필드 정의 바로 앞에 다음 DL_TIMESTAMP 필드 정의를 추가합니다. 이 필드는 각 델타 로드 실행의 타임스탬프를 저장합니다.
{ "name": "DL_TIMESTAMP", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "Delta load timestamp" },테이블 만들기를 클릭합니다.
SAP Data Services와 BigQuery 간 데이터 흐름 설정
데이터 흐름을 설정하려면 BigQuery 테이블을 외부 메타데이터로 SAP Data Services에 가져오고 복제 작업 및 BigQuery 로더 데이터 흐름을 만들어야 합니다.
BigQuery 테이블 가져오기
이 단계에서는 이전 단계에서 만든 BigQuery 테이블을 가져와 SAP Data Services에서 사용할 수 있도록 만듭니다.
- SAP Data Services Designer 객체 라이브러리에서 이전에 만든 BigQuery Datastore를 엽니다.
- 오른쪽 패널 상단에서 외부 메타데이터를 선택합니다. 만든 BigQuery 테이블이 나타납니다.
- 해당 BigQuery 테이블 이름을 마우스 오른쪽 버튼으로 클릭하고 가져오기를 선택합니다.
- 선택한 테이블을 SAP Data Services로 가져오기 시작합니다. 이제 테이블을 객체 라이브러리의 대상 Datastore 노드 아래에서 사용할 수 있습니다.
복제 작업 및 BigQuery 로더 데이터 흐름 만들기
이 단계에서는 복제 작업과 SAP LT Replication Server에서 BigQuery 테이블로 데이터를 로드하는 데 사용되는 데이터 흐름을 SAP Data Services에서 만듭니다.
데이터 흐름은 두 부분으로 구성됩니다. 첫 번째 부분은 소스 ODP 객체에서 BigQuery 테이블로의 초기 데이터 로드를 실행하고, 두 번째 부분은 이후의 델타 로드를 사용 설정합니다.
전역 변수 만들기
복제 작업에서 초기 로드를 실행할지 또는 델타 로드를 실행할지 결정할 수 있도록 데이터 흐름 로직에서 로드 유형을 추적할 전역 변수를 만들어야 합니다.
- SAP Data Services Designer 애플리케이션 메뉴에서 Tools(도구) > Variables(변수)로 이동합니다.
- Global Variables(전역 변수)를 마우스 오른쪽 버튼으로 클릭하고 Insert(삽입)를 선택합니다.
- 변수 Name(이름)을 마우스 오른쪽 버튼으로 클릭하고 Properties(특성)를 선택합니다.
- 변수 이름에 $INITLOAD를 입력합니다.
- Data Type(데이터 유형)에서 Int를 선택합니다.
- 값 필드에 0을 입력합니다.
- 확인을 클릭합니다.
복제 작업 만들기
- 프로젝트 탐색기에서 프로젝트 이름을 마우스 오른쪽 버튼으로 클릭합니다.
- New(새로 만들기) > Batch Job(일괄 작업)을 선택합니다.
- Name(이름) 필드를 입력합니다. 예를 들면 JOB_SRS_DS_BQ_REPLICATION입니다.
- 마침을 클릭합니다.
초기 로드용 데이터 흐름 로직 만들기
조건부 만들기
- Job Name(작업 이름)을 마우스 오른쪽 버튼으로 클릭하고 Add New(새로 추가) > Conditional(조건부) 옵션을 선택합니다.
- 조건부 아이콘을 마우스 오른쪽 버튼으로 클릭하고 이름 바꾸기를 선택합니다.
이름을 InitialOrDelta로 변경합니다.

조건부 아이콘을 더블클릭하여 조건부 편집기를 엽니다.
If 문 필드에 $INITLOAD = 1을 입력하여 초기 로드를 실행할 조건을 설정합니다.
Then 창에서 마우스 오른쪽 버튼을 클릭하고 Add New(새로 추가) > Script(스크립트)를 선택합니다.
Script(스크립트) 아이콘을 마우스 오른쪽 버튼으로 클릭하고 Rename(이름 바꾸기)을 선택합니다.
이름을 변경합니다. 예를 들어 이 안내에서는 InitialLoadCDCMarker를 사용합니다.
Script(스크립트) 아이콘을 더블클릭하여 함수 편집기를 엽니다.
print('Beginning Initial Load');입력begin_initial_load();입력
애플리케이션 툴바에서 뒤로 아이콘을 클릭하여 Function Editor(함수 편집기)를 종료합니다.
초기 로드용 데이터 흐름 만들기
- Then 창에서 마우스 오른쪽 버튼을 클릭하고 Add New(새로 추가) > Data Flow(데이터 흐름)를 선택합니다.
- 데이터 흐름 이름을 바꿉니다. 예를 들면 DF_SRS_DS_InitialLoad입니다.
- InitialLoadCDCMarker의 연결 출력 아이콘을 클릭한 후 연결선을 DF_SRS_DS_InitialLoad의 입력 아이콘으로 드래그하여 InitialLoadCDCMarker와 DF_SRS_DS_InitialLoad를 연결합니다.
- DF_SRS_DS_InitialLoad 데이터 흐름을 더블클릭합니다.
데이터 흐름을 가져온 후 소스 Datastore 객체와 연결
- Datastore에서 소스 ODP 객체를 데이터 흐름 작업공간으로 드래그하여 드롭합니다. 이 안내에서 Datastore 이름은 DS_SLT입니다. Datastore 이름은 다를 수 있습니다.
- 객체 라이브러리의 Transforms(변환) 탭에 있는 Platform(플랫폼) 노드에서 Query transform(쿼리 변환)을 데이터 흐름으로 드래그합니다.
ODP 객체를 더블클릭하고 Source(소스) 탭에서 Initial Load(초기 로드) 옵션을 Yes(예)로 설정합니다.
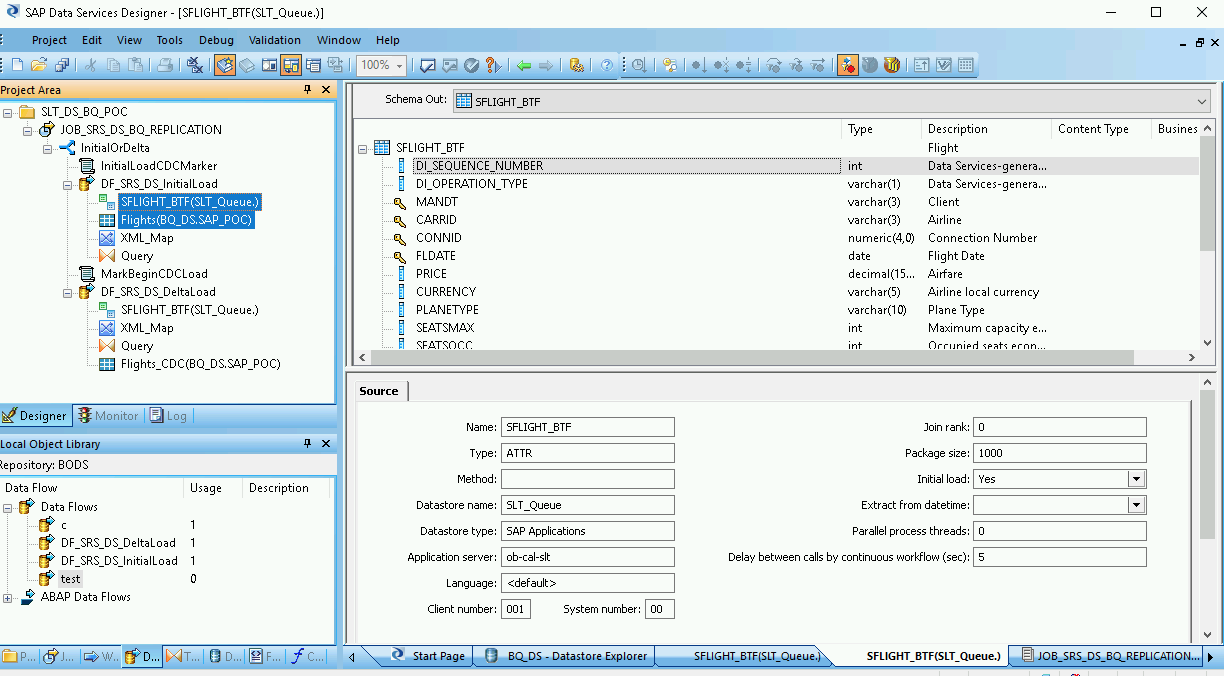
작업공간의 모든 소스 ODP 객체를 Query transform(쿼리 변환)에 연결합니다.
쿼리 변환을 더블클릭합니다.
왼쪽의 Schema In(스키마 입력) 아래에 있는 모든 테이블 필드를 선택하고 오른쪽의 Schema Out(스키마 출력)으로 드래그합니다.
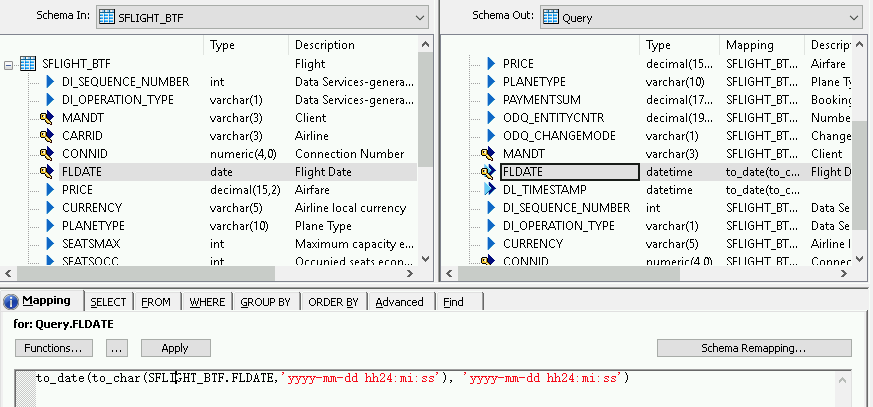
날짜/시간 필드에 변환 함수를 추가하려면 다음 안내를 따르세요.
- 오른쪽의 스키마 출력 목록에서 날짜/시간 필드를 선택합니다.
- 스키마 목록 아래에서 매핑 탭을 선택합니다.
필드 이름을 다음 함수로 바꿉니다.
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')여기서 FIELDNAME은 선택한 필드의 이름입니다.
애플리케이션 툴바에서 뒤로 아이콘을 클릭하여 데이터 흐름으로 돌아갑니다.
데이터 흐름을 가져온 후 대상 Datastore 객체와 연결
- 객체 라이브러리의 Datastore에서 초기 로드용으로 가져온 BigQuery 테이블을 데이터 흐름으로 드래그합니다. 이 안내에서 Datastore 이름은 BQ_DS입니다. Datastore 이름은 다를 수 있습니다.
- 객체 라이브러리의 Transforms(변환) 탭에 있는 Platform(플랫폼) 노드에서 XML_Map 변환을 데이터 흐름으로 드래그합니다.
- 대화상자에서 일괄 처리 모드를 선택합니다.
- Query(쿼리) 변환을 XML_Map 변환에 연결합니다.
XML_Map 변환을 가져온 BigQuery 테이블에 연결합니다.
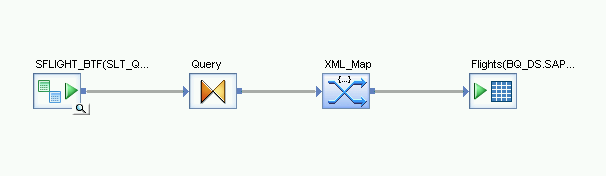
XML_Map 변환을 열고 BigQuery 테이블에 포함할 데이터에 따라 입력 및 출력 스키마 섹션을 완료합니다.
작업공간에서 BigQuery 테이블을 더블클릭하여 열고 대상 탭의 옵션을 다음 표와 같이 완료합니다.
| 옵션 | 설명 |
|---|---|
| 포트 만들기 | 기본값인 No(아니요)를 지정합니다. Yes(예)를 지정하면 소스 또는 대상 파일이 삽입된 데이터 흐름 포트가 됩니다. |
| 모드 | 초기 로드에 자르기를 지정합니다. 이렇게 하면 BigQuery 테이블의 기존 레코드가 SAP Data Services에서 로드된 데이터로 바뀝니다. Truncate(자르기)가 기본값입니다. |
| 로더 수 | 처리에 사용할 로더(스레드)의 수를 설정하는 양의 정수를 지정합니다. 기본값은 4입니다.
각 로더는 BigQuery에서 재개 가능한 로드 작업 한 개를 시작합니다. 로더 수를 제한 없이 지정할 수 있습니다. 적절한 로더 수를 결정하는 데 도움이 필요하면 다음을 포함한 SAP 문서를 참조하세요. |
| 로더당 최대 오류 레코드 수 | 0 또는 양의 정수를 지정하여 BigQuery가 레코드 로드를 중지하기 전에 로드 작업마다 실패할 수 있는 최대 레코드 수를 설정합니다. 기본값은 0입니다. |
- 상단 툴바에서 검사기 아이콘을 클릭합니다.
- 애플리케이션 툴바에서 뒤로 아이콘을 클릭하여 조건부 편집기로 돌아갑니다.
델타 로드용 데이터 흐름 만들기
초기 로드 후 누적된 변경 데이터 캡처 레코드를 복제하는 데이터 흐름을 만들어야 합니다.
조건부 델타 흐름을 만들려면 다음 안내를 따르세요.
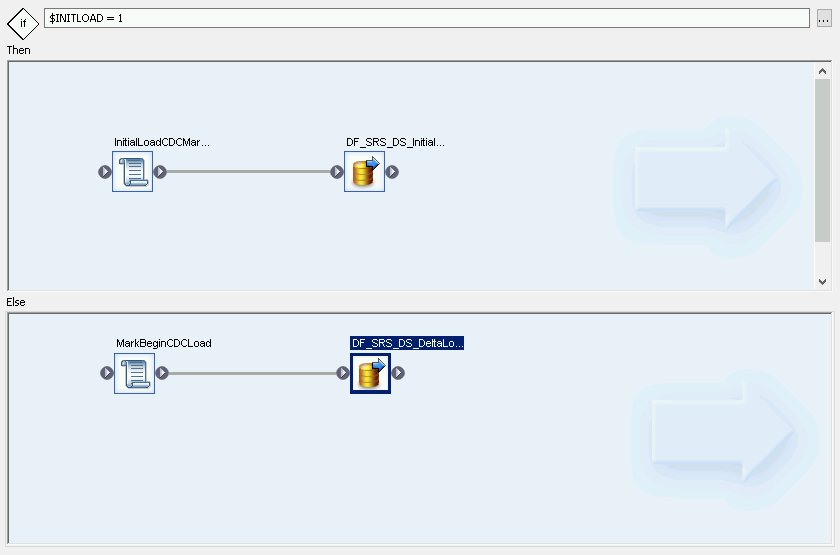
- InitialOrDelta 조건부를 더블클릭합니다.
- Else 섹션을 마우스 오른쪽 버튼으로 클릭하고 Add New(새로 추가) > Script(스크립트)를 선택합니다.
- 스크립트 이름을 바꿉니다. 예를 들면 MarkBeginCDCLoad입니다.
- 스크립트 아이콘을 더블클릭하여 함수 편집기를 엽니다.
print('Beginning Delta Load')를 입력합니다.

애플리케이션 툴바에서 뒤로 아이콘을 클릭하여 Conditional(조건부) 편집기로 돌아갑니다.
델타 로드용 데이터 흐름 만들기
- 조건부 편집기에서 마우스 오른쪽 버튼을 클릭하고 Add New(새로 추가) > Data Flow(데이터 흐름)를 선택합니다.
- 데이터 흐름 이름을 바꿉니다. 예를 들면 DF_SRS_DS_DeltaLoad입니다.
- 다음 다이어그램과 같이 MarkBeginCDCLoad를 DF_SRS_DS_DeltaLoad와 연결합니다.
DF_SRS_DS_DeltaLoad 데이터 흐름을 더블클릭합니다.
데이터 흐름을 가져온 후 소스 Datastore 객체와 연결
- Datastore에서 데이터 흐름 작업공간으로 소스 ODP 객체를 드래그하여 드롭합니다. 이 안내에서 Datastore 이름은 DS_SLT입니다. Datastore 이름은 다를 수 있습니다.
- 객체 라이브러리의 Transforms(변환) 탭에 있는 Platform(플랫폼) 노드에서 Query(쿼리) 변환을 데이터 흐름으로 드래그합니다.
- ODP 객체를 더블클릭하고 Source(소스) 탭에서 Initial Load(초기 로드) 옵션을 No(아니요)로 설정합니다.
- 작업공간의 모든 소스 ODP 객체를 쿼리 변환에 연결합니다.
- 쿼리 변환을 더블클릭합니다.
- 왼쪽의 스키마 입력 목록에 있는 모든 테이블 필드를 선택하고 오른쪽의 스키마 출력 목록으로 드래그합니다.
델타 로드에 타임스탬프 사용 설정
다음 단계에서는 SAP Data Services가 델타 로드 테이블의 필드에 각 델타 로드 실행 타임스탬프를 자동으로 기록하도록 사용 설정합니다.
- 오른쪽의 스키마 출력 창에서 쿼리 노드를 마우스 오른쪽 버튼으로 클릭합니다.
- 새 출력 열을 선택합니다.
- 이름에 DL_TIMESTAMP를 입력합니다.
- 데이터 유형에서 날짜/시간을 선택합니다.
- 확인을 클릭합니다.
- 새로 만든 DL_TIMESTAMP 필드를 클릭합니다.
- 아래의 매핑 탭으로 이동합니다.
다음 함수를 입력합니다.
- to_date(to_char(sysdate(),'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
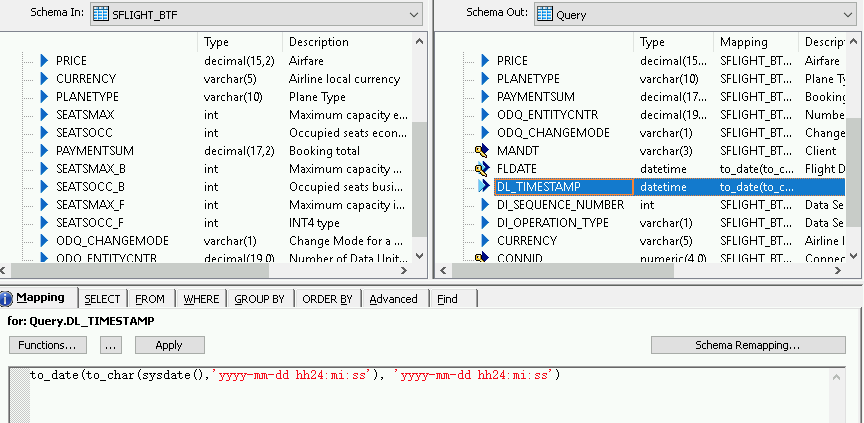
데이터 흐름을 가져온 후 대상 Datastore 객체에 연결
- 객체 라이브러리의 Datastore에서 delta load(델타 로드)용으로 가져온 BigQuery 테이블을 XML_Map 변환 후 데이터 흐름 작업공간으로 드래그합니다. 이 안내에서는 Datastore 이름 BQ_DS를 사용합니다. Datastore 이름은 다를 수 있습니다.
- 객체 라이브러리의 Transforms(변환) 탭에 있는 Platform(플랫폼) 노드에서 XML_Map 변환을 데이터 흐름으로 드래그합니다.
- Query(쿼리) 변환을 XML_Map 변환에 연결합니다.
XML_Map 변환을 가져온 BigQuery 테이블에 연결합니다.
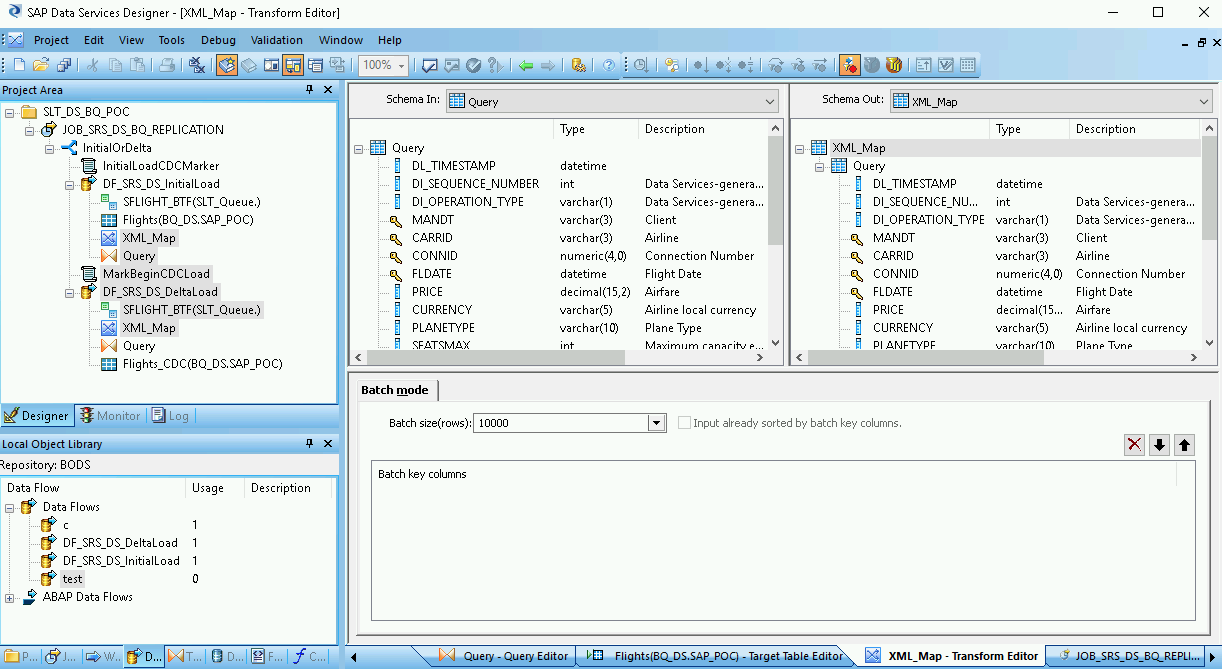
XML_Map 변환을 열고 BigQuery 테이블에 포함할 데이터에 따라 입력 및 출력 스키마 섹션을 완료합니다.
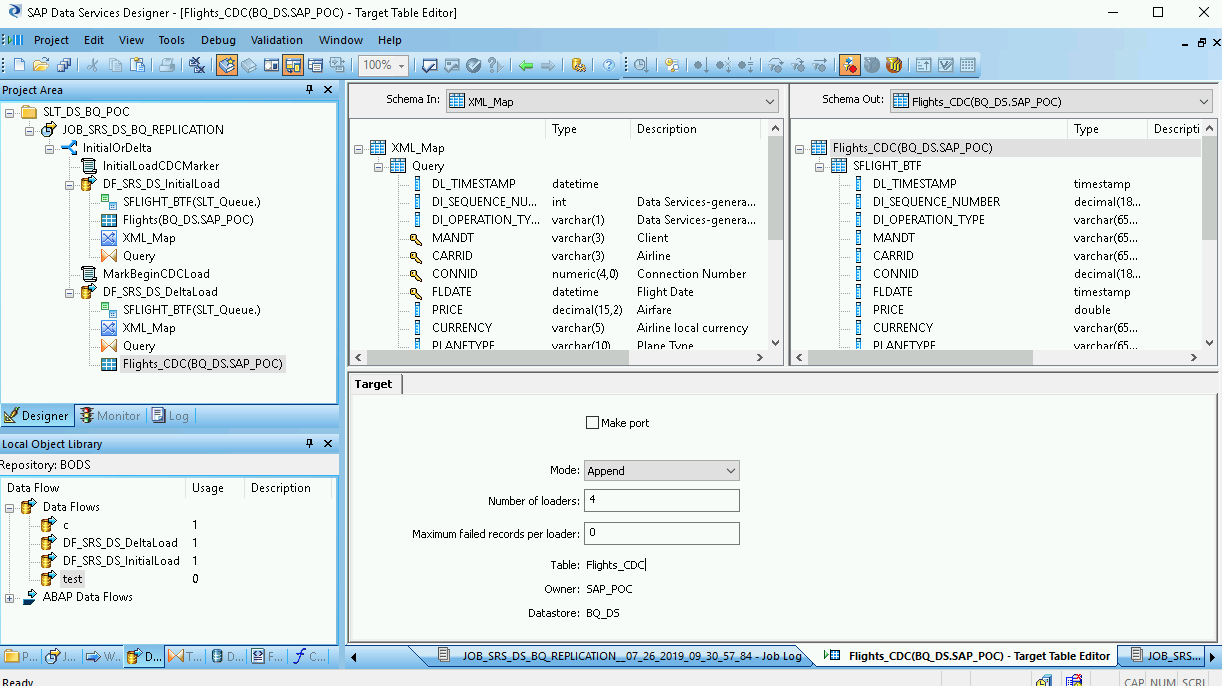
작업공간에서 BigQuery 테이블을 더블클릭하여 열고 다음 설명을 따라 Target(대상) 탭의 옵션을 완료합니다.
| 옵션 | 설명 |
|---|---|
| 포트 만들기 | 기본값인 No(아니요)를 지정합니다. Yes(예)를 지정하면 소스 또는 대상 파일이 삽입된 데이터 흐름 포트가 됩니다. |
| 모드 | 델타 로드에 추가를 지정합니다. 이렇게 하면 SAP Data Services에서 새 레코드가 로드될 때 BigQuery 테이블의 기존 레코드가 유지됩니다. |
| Number of loaders(로더 수) | 처리에 사용할 로더(스레드)의 수를 설정하는 양의 정수를 지정합니다.
각 로더는 BigQuery에서 재개 가능한 로드 작업 한 개를 시작합니다. 로더 수를 제한 없이 지정할 수 있습니다. 일반적으로 델타 로드에는 초기 로드보다 적은 수의 로더가 필요합니다. 적절한 로더 수를 결정하는 데 도움이 필요하면 다음을 포함한 SAP 문서를 참조하세요. |
| 로더당 최대 오류 레코드 수 | 0 또는 양의 정수를 지정하여 BigQuery가 레코드 로드를 중지하기 전에 로드 작업마다 실패할 수 있는 최대 레코드 수를 설정합니다. 기본값은 0입니다. |
- 상단 툴바에서 검사기 아이콘을 클릭합니다.
- 애플리케이션 툴바에서 뒤로 아이콘을 클릭하여 Conditional(조건부) 편집기로 돌아갑니다.
BigQuery에 데이터 로드
초기 로드와 델타 로드의 단계는 서로 비슷합니다. 두 로드 모두에서 복제 작업을 시작하고 SAP Data Services에서 데이터 흐름을 실행하여 SAP LT Replication Server에서 BigQuery로 데이터를 로드합니다. 두 로드 절차의 중요한 차이점은 $INITLOAD 전역 변수 값입니다. 초기 로드에서는 $INITLOAD를 1로 설정해야 합니다. 델타 로드의 경우 $INITLOAD가 0이어야 합니다.
초기 로드 실행
초기 로드를 실행하면 소스 데이터 세트의 모든 데이터가 초기 로드 데이터 흐름에 연결된 대상 BigQuery 테이블에 복제됩니다. 대상 테이블의 모든 데이터를 덮어씁니다.
- SAP Data Services Designer에서 프로젝트 탐색기를 엽니다.
- 복제 작업 이름을 마우스 오른쪽 버튼으로 클릭하고 실행을 선택합니다. 대화상자가 표시됩니다.
- 대화상자에서 전역 변수 탭으로 이동한 후
$INITLOAD값을 1로 변경하여 초기 로드가 먼저 실행되도록 합니다. - 확인을 클릭합니다. 로드 프로세스가 시작되고 디버그 메시지가 SAP Data Services 로그에 표시되기 시작합니다. 데이터가 BigQuery에서 초기 로드용으로 만든 테이블로 로드됩니다. 이 안내에서 초기 로드 테이블 이름은 BQ_INIT_LOAD입니다. 테이블 이름은 다를 수 있습니다.
- 로드가 완료되었는지 확인하려면 Google Cloud 콘솔로 이동하여 테이블이 포함된 BigQuery 데이터 세트를 엽니다. 데이터가 계속 로드 중이면 테이블 이름 옆에 '로드 중'이 표시됩니다.
로드가 끝나면 데이터를 BigQuery에서 처리할 수 있습니다.
이 시점부터 소스 테이블의 모든 변경사항이 SAP LT Replication Server 델타 큐에 기록됩니다. 델타 큐에서 BigQuery로 데이터를 로드하려면 델타 로드 작업을 실행합니다.
델타 로드 실행
델타 로드를 실행하면 마지막 로드 이후에 소스 데이터 세트에서 발생한 변경사항만 델타 로드 데이터 흐름에 연결된 대상 BigQuery 테이블에 복제됩니다.
- 작업 이름을 마우스 오른쪽 버튼으로 클릭하고 Execute(실행)를 선택합니다.
- 확인을 클릭합니다. 로드 프로세스가 시작되고 SAP Data Services 로그에 디버그 메시지가 나타납니다. 데이터가 BigQuery에서 델타 로드용으로 만든 테이블에 로드됩니다. 이 안내에서 델타 로드 테이블 이름은 BQ_DELTA_LOAD입니다. 테이블 이름은 다를 수 있습니다.
- 로드가 완료되었는지 확인하려면 Google Cloud 콘솔로 이동하여 테이블이 포함된 BigQuery 데이터 세트를 엽니다. 데이터가 계속 로드 중이면 테이블 이름 옆에 '로드 중'이 표시됩니다.
- 로드가 끝나면 데이터를 BigQuery에서 처리할 수 있습니다.
소스 데이터 변경사항을 추적하려면 SAP LT Replication Server는 DI_SEQUENCE_NUMBER 열에 변경된 데이터 작업 순서를 기록하고 DI_OPERATION_TYPE 열에 변경된 데이터 작업 유형(D=삭제, U=업데이트, I=삽입)을 기록합니다. SAP LT Replication Server는 델타 큐 테이블의 열에 데이터를 저장하고, 데이터는 이 테이블에서 BigQuery로 복제됩니다.
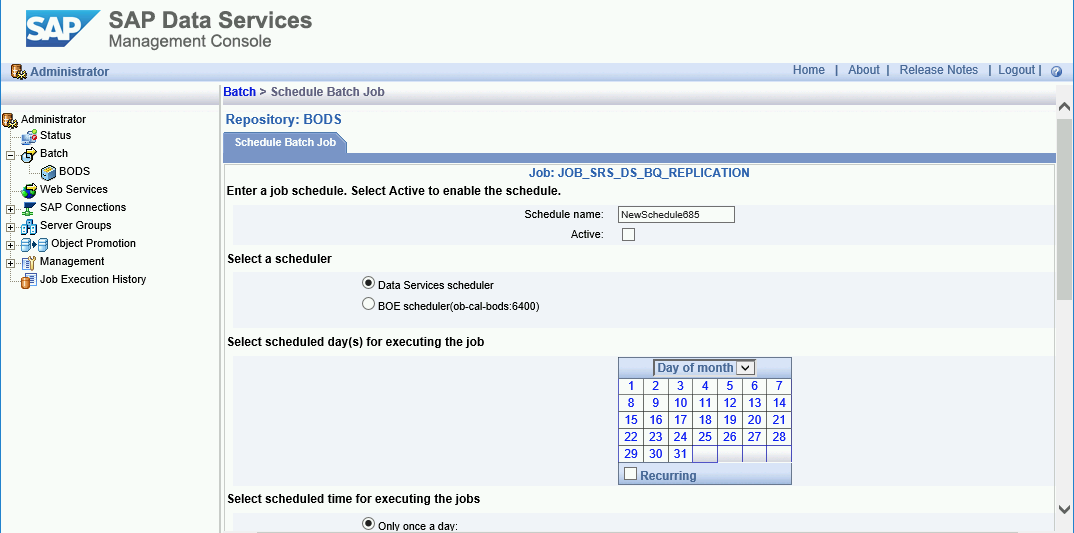
델타 로드 예약
SAP Data Services Management Console을 사용하여 정기적으로 델타 로드 작업이 실행되도록 예약할 수 있습니다.
- SAP Data Services Management Console 애플리케이션을 엽니다.
- 관리자를 클릭합니다.
- 왼쪽의 메뉴 트리에서 일괄 처리 노드를 펼칩니다.
- SAP Data Services 저장소 이름을 클릭합니다.
- 일괄 처리 작업 구성 탭을 클릭합니다.
- 일정 추가를 클릭합니다.
- 예약 이름을 입력합니다.
- 활성을 선택합니다.
- Select scheduled time for executing the jobs(작업을 실행할 예약 시간 선택) 섹션에서 델타 로드 실행 빈도를 지정합니다.
- 중요: Google Cloud 는 하루에 실행할 수 있는 BigQuery 로드 작업 수를 제한합니다. 일정이 한도를 초과하지 않아야 하며, 한도를 늘릴 수 없습니다. BigQuery 로드 작업 제한에 대한 자세한 내용은 BigQuery 문서의 할당량 및 한도를 참고하세요.
- 전역 변수를 펼치고 $INITLOAD가 0으로 설정되어 있는지 확인합니다.
- 적용을 클릭합니다.
다음 단계
BigQuery에서 복제된 데이터를 쿼리하고 분석합니다.
쿼리에 대한 자세한 내용은 다음을 참조하세요.
- BigQuery 문서의 BigQuery 데이터 쿼리 개요
BigQuery에서 초기 로드 및 델타 로드 데이터의 대규모 통합 방법에 대한 자세한 내용은 다음을 참조하세요.
- Google Cloud 블로그에 제공된 BigQuery에서 대규모 변형 수행 솔루션
- BigQuery 문서의 DML
Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기 Cloud 아키텍처 센터 살펴보기