Dokumen ini adalah seri pertama yang menunjukkan cara memantau model machine learning (ML) yang di-deploy ke AI Platform Prediction untuk mendeteksi kemiringan data dan penyimpangan data. Panduan ini menjelaskan hal-hal berikut:
- Cara menyalurkan model Keras dengan TensorFlow 2.3 menggunakan AI Platform Prediction.
- Cara mengonfigurasi model Keras untuk mencatat permintaan (instance) dan respons (prediksi) online ke BigQuery.
Seri ini ditujukan untuk data scientist dan engineer MLOps yang ingin mempertahankan performa model ML mereka dalam produksi dengan memantau perubahan data penayangan dari waktu ke waktu. Anda dianggap memiliki pengalaman dengan Google Cloud, TensorFlow, dan dengan Jupyter notebooks.
Rangkaian ini terdiri dari panduan berikut:
- Mencatat permintaan penyaluran menggunakan AI Platform Prediction (dokumen ini)
- Menganalisis log di BigQuery
- Menganalisis diferensiasi server pelatihan dengan Validasi Data TensorFlow
- Mengotomatiskan deteksi diferensiasi performa server pelatihan
- Mengidentifikasi diferensiasi performa pelatihan dan penyajian dengan deteksi kebaruan
Ringkasan pemantauan model ML
Saat Anda men-deploy model ML dalam produksi untuk melayani kasus penggunaan bisnis, penting untuk memverifikasi secara rutin dan proaktif bahwa performa model tidak menurun. Untuk membantu memastikan performa yang akurat, tugas memantau kualitas dan performa model dalam produksi hadir sebagai salah satu elemen terpenting dari MLOps.
Karena model tidak beroperasi di lingkungan statis, performa model ML dapat menurun seiring waktu. Karena properti data input berubah seiring waktu, data mulai menyimpang dari data yang digunakan untuk melatih dan mengevaluasi model.
Misalnya, modifikasi pada pipeline pemrosesan data upstream dapat mengubah representasi fitur dan domain fitur yang diharapkan oleh model tersebut. Input mungkin menyertakan satu atau beberapa hal berikut:
- Perubahan satuan ukuran dari meter ke kilometer
- Pengantar kosakata baru ke fitur kategoris
- Perubahan pada jenis data dari beberapa fitur.
Diferensiasi antara data pelatihan dan data penayangan dapat menyebabkan penurunan performa prediktif suatu model.
Untuk mempertahankan performa model dalam produksi, Anda perlu mengambil data penyajian dan menentukan bagaimana model Anda merespons prediksi yang ditayangkan. Pengambilan data membantu Anda melakukan hal berikut:
- Menganalisis bagaimana data telah berubah dari waktu ke waktu.
- Mendeteksi diferensiasi yang mungkin muncul dalam data.
- Memberi tahu Anda bahwa model perlu diperbarui atau dilatih ulang dengan data baru untuk menangkap pola yang muncul.
Prediksi AI Platform untuk pemantauan ML
AI Platform Prediction adalah layanan yang skalabel dan terkelola sepenuhnya untuk men-deploy model ML yang melayani prediksi online. Dokumen dalam seri ini menunjukkan cara menggunakan AI Platform Prediction untuk mengaktifkan logging permintaan-respons (Beta). Proses ini mencatat sampel permintaan dan respons prediksi online ke tabel BigQuery dalam format mentah (JSON).
Arsitektur yang Anda buat ditampilkan dalam diagram berikut.

Dalam arsitektur ini, instance mentah dan data prediksi disimpan di BigQuery Anda dapat mengurai data ini, menghitung statistik deskriptif, dan memvisualisasikan diferensiasi data serta penyimpangan data. Tugas-tugas ini dijelaskan secara lebih mendetail di bagian berikutnya dalam seri ini.
Set data untuk seri
Untuk skenario yang dijelaskan dalam seri ini, Anda menggunakan set data Covertype dari UCI Machine Learning Repository. Set data ini mencakup informasi tentang jenis pohon (tutup hutan) di beberapa area hutan belantara di negara bagian Colorado. Ini adalah set data klasifikasi, yang tugasnya memprediksi jenis tutup hutan hanya dari variabel kartografi. Dataset tersebut memiliki karakteristik berikut:
- Set data ini memiliki 581.012 instance, dengan pemisahan pelatihan mencakup 431.010 instance.
- Set data memiliki 12 fitur input. 10 adalah numerik dan 2 bersifat kategoris.
- Class target memiliki 7 label. Rentangnya adalah 0 hingga 6.
Set data diproses sebelumnya, dibagi, dan diupload ke bucket publik
Cloud Storage (gs://workshop-datasets/covertype). Anda menggunakan dataset yang telah
diproses sebelumnya untuk tugas-tugas dalam rangkaian ini. Untuk mengetahui informasi selengkapnya tentang set data, lihat
file README
Set Data Covertype
GitHub.
Tujuan
- Buka instance notebook yang dikelola pengguna Vertex AI Workbench dan buat clone repositori GitHub yang berisi notebook Jupyter.
- Jalankan notebook untuk melakukan tugas berikut:
- Melatih model.
- Mengekspor model.
- Men-deploy model.
- Aktifkan logging ke BigQuery.
- Menguji model.
Biaya
Dalam dokumen ini, Anda menggunakan komponen Google Cloud yang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Sebelum memulai
- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
-
Di konsol Google Cloud, pada halaman pemilih project, pilih atau buat project Google Cloud.
-
Pastikan penagihan telah diaktifkan untuk project Google Cloud Anda.
Notebook Jupyter untuk skenario ini
Tugas untuk pemantauan ML dalam seri ini digabungkan ke dalam notebook Jupyter yang ada di repositori GitHub. Untuk melakukan tugas, buka notebook lalu menyetujui sel kode di notebook secara berurutan.
Dalam panduan pertama ini, Anda menggunakan notebook Jupyter untuk melakukan tugas berikut:
- Melatih dan mengevaluasi model klasifikasi Keras.
- Ekspor model Keras sebagai SavedModel dan upload ke Cloud Storage.
- Men-deploy model yang diekspor ke AI Platform Prediction.
- Mengaktifkan logging respons permintaan ke versi model pada AI Platform Prediction.
- Menguji API model untuk prediksi online.
- Verifikasi instance dan prediksi yang dicatat.
Membuka JupyterLab dan notebook
Untuk mengerjakan tugas pada skenario ini, Anda perlu membuka lingkungan JupyterLab dan membuka notebook.
Di Konsol Google Cloud, buka halaman Notebooks.
Pada tab Notebook yang dikelola pengguna, pilih notebook, lalu klik Buka Jupyterlab. Lingkungan JupyterLab akan terbuka di browser Anda.
Untuk meluncurkan tab terminal, pilih File > New > Launcher.
Klik ikon Terminal pada tab Launcher.
Di terminal, clone repositori GitHub
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.gitSetelah perintah selesai, Anda akan melihat folder
mlops-on-gcpdi file browser.
Mengonfigurasi setelan notebook
Di bagian ini, Anda akan menetapkan variabel di notebook dengan nilai yang spesifik untuk konteks, dan menyiapkan lingkungan Python untuk menjalankan kode untuk skenario tersebut.
- Di file browser, buka file
mlops-on-gcp, lalu buka direktoriskew-detection. - Buka notebook
01-covertype-training-serving.ipynb. - Di notebook, di bagian Setup, jalankan sel Install packages and Dependency untuk menginstal paket Python yang diperlukan dan mengonfigurasi variabel lingkungan.
Di sel pertama di bagian Configure Google Cloud environment settings, tetapkan variabel berikut, lalu jalankan sel:
PROJECT: ID project Google Cloud tempat model Prediction AI Platform akan di-deploy, dan tempat set data BigQuery untuk data permintaan-respons akan dicatat dalam log.BUCKET: Nama bucket Cloud Storage tempat SavedModel akan diupload untuk di-deploy ke AI Platform Prediction. Pastikan nama tersebut unik secara global.REGION: region di mana model Prediksi AI Platform akan di-deploy. Pilih wilayah yang secara geografis dekat dengan Anda.
Jalankan sel yang tersisa di bagian Setelan untuk menyelesaikan konfigurasi lingkungan:
- Mengautentikasi akun Google Cloud
- Mengimpor library
- Menentukan konstanta
- Membuat ruang kerja lokal
Setelah menyelesaikan langkah-langkah ini, Anda siap menyiapkan data, melatih dan mengevaluasi model, mengekspor model yang akan digunakan, dan men-deploy model tersebut ke AI Platform. Setelah selesai melakukan tugas-tugas tersebut, Anda menyiapkan set data untuk logging BigQuery.
Semua tugas ini dikodekan di notebook. Untuk melakukan tugas, jalankan urutan sel di notebook, seperti yang Anda lakukan dengan notebook Jupyter.
Bagian berikut menyoroti bagian-bagian penting dari proses tersebut serta menjelaskan aspek desain dan kode.
Melatih model
Anda menjalankan tugas di Bagian 2 dari notebook untuk membuat dan melatih model.
Kode di notebook menggunakan daftar
feature columns
untuk mewakili fitur input. Kode menggunakan variabel berikut:
numeric_columnuntuk fitur numerik.categorical_column_with_vocabulary_listuntuk fitur kategoris.embedding_columnuntuk menggabungkan setiap kolom fitur kategoris, dengandimensionkolom embedding ditetapkan ke 1 ditambah akar kuadrat dari kosakata ukuran fitur kategoris.
Cuplikan berikut menunjukkan kolom fitur yang dibuat:
EmbeddingColumn(categorical_column=VocabularyListCategoricalColumn(key='Soil_Type', vocabulary_list=('2702', '2703', '2704', ...), dtype=tf.string, default_value=-1, num_oov_buckets=0), dimension=7, combiner='mean', max_norm=None, trainable=True)
EmbeddingColumn(categorical_column=VocabularyListCategoricalColumn(key='Wilderness_Area', vocabulary_list=('Cache', 'Commanche', 'Neota', 'Rawah'), dtype=tf.string, default_value=-1, num_oov_buckets=0), dimension=3, combiner='mean', max_norm=None, trainable=True)
NumericColumn(key='Aspect', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='Elevation', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='Hillshade_3pm', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='Hillshade_9am', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='Hillshade_Noon', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='Horizontal_Distance_To_Fire_Points', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='Horizontal_Distance_To_Hydrology', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='Horizontal_Distance_To_Roadways', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='Slope', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
NumericColumn(key='Vertical_Distance_To_Hydrology', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)
Di notebook, model klasifikasi Keras dibuat menggunakan metode
tf.keras.Sequential,
seperti yang ditunjukkan dalam cuplikan kode berikut:
def create_model(params):
feature_columns = create_feature_columns()
layers = []
layers.append(tf.keras.layers.DenseFeatures(feature_columns))
for units in params.hidden_units:
layers.append(tf.keras.layers.Dense(units=units, activation='relu'))
layers.append(tf.keras.layers.BatchNormalization())
layers.append(tf.keras.layers.Dropout(rate=params.dropout))
layers.append(tf.keras.layers.Dense(units=NUM_CLASSES, activation='softmax'))
model = tf.keras.Sequential(layers=layers, name='classifier')
adam_optimzer = tf.keras.optimizers.Adam(learning_rate=params.learning_rate)
model.compile(
optimizer=adam_optimzer,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
loss_weights=None,
sample_weight_mode=None,
weighted_metrics=None,
)
return model
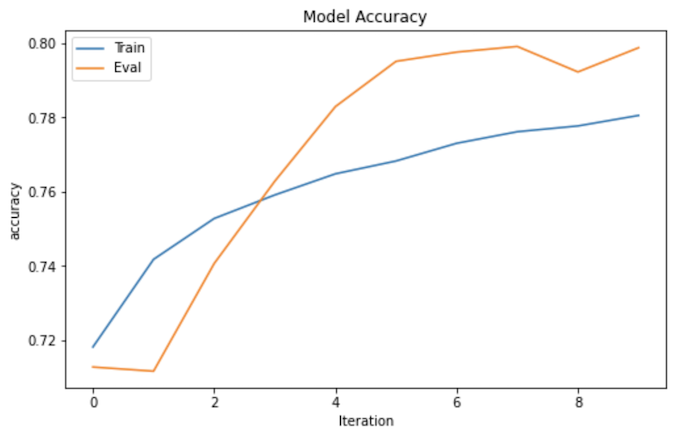
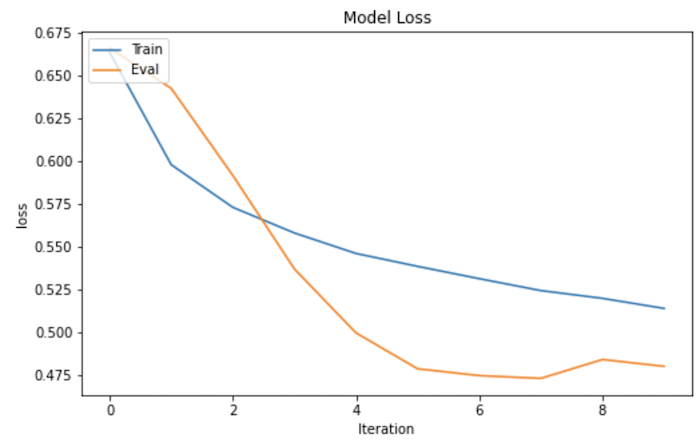
Saat Anda melatih model menggunakan setelan parameter default di notebook, model tersebut akan mencapai nilai akurasi dan kerugian yang mirip dengan yang ditunjukkan dalam grafik berikut. Sumbu X menunjukkan jumlah epoch, dan sumbu Y menunjukkan akurasi dan kerugian.
Mengekspor model
Anda menjalankan tugas di bagian 3 notebook untuk mengekspor model yang akan ditayangkan. Setelah mengekspor dan memeriksa SavedModel Anda, Anda dapat menguploadnya ke bucket Cloud Storage.
Sebelum mengekspor model sebagai SavedModel yang dikonfigurasi untuk menerima fitur mentah
untuk penyaluran, Anda perlu membuat kamus feature_spec. Kamus ini
menentukan antarmuka (input) untuk fungsi penayangan. Cuplikan
berikut dari notebook menunjukkan kamus:
feature_spec = {}
for feature_name in FEATURE_NAMES:
if feature_name in CATEGORICAL_FEATURES_WITH_VOCABULARY:
feature_spec[feature_name] = tf.io.FixedLenFeature(
shape=[None], dtype=tf.string)
else:
feature_spec[feature_name] = tf.io.FixedLenFeature(
shape=[None], dtype=tf.float32)
Cuplikan berikut menunjukkan kamus feature_spec yang dibuat:
Soil_Type: FixedLenFeature(shape=[None], dtype=tf.string, default_value=None) Wilderness_Area: FixedLenFeature(shape=[None], dtype=tf.string, default_value=None) Aspect: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None) Elevation: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None) Hillshade_3pm: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None) Hillshade_9am: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None) Hillshade_Noon: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None) Horizontal_Distance_To_Fire_Points: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None) Horizontal_Distance_To_Hydrology: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None) Horizontal_Distance_To_Roadways: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None) Slope: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None) Vertical_Distance_To_Hydrology: FixedLenFeature(shape=[None], dtype=tf.float32, default_value=None)
Kode notebook kemudian menentukan fungsi make_features_serving_fn, yang
mengambil objek model dan menampilkan fungsi serve_features_fn. Fungsi
serve_features_fn, yang akan digunakan sebagai fungsi penerima yang menyalurkan
model, menerima kamus features dan menampilkan kamus yang memiliki
item berikut:
predicted_label, termasuk label class yang diprediksi oleh model.confidence, termasuk probabilitas label class yang diprediksi.probabilities, termasuk probabilitas semua label class.
Format output ini kompatibel dengan evaluasi berkelanjutan AI Platform. Untuk mengetahui informasi tentang tugas klasifikasi umum, lihat cara memformat contoh input dan prediksi output.
Cuplikan berikut menunjukkan fungsi make_features_serving_fn yang
ditentukan di notebook.
LABEL_KEY = 'predicted_label'
SCORE_KEY = 'confidence'
PROBABILITIES_KEY = 'probabilities'
SIGNATURE_NAME = 'serving_default'
...
def make_features_serving_fn(model):
@tf.function
def serve_features_fn(features):
probabilities = model(features)
labels = tf.constant(TARGET_FEATURE_LABELS, dtype=tf.string)
predicted_class_indices = tf.argmax(probabilities, axis=1)
predicted_class_label = tf.gather(
params=labels, indices=predicted_class_indices)
prediction_confidence = tf.reduce_max(probabilities, axis=1)
return {
LABEL_KEY: predicted_class_label,
SCORE_KEY:prediction_confidence,
PROBABILITIES_KEY: probabilities}
return serve_features_fn
Setelah menjalankan sel untuk melatih model, Anda harus mengekspor model ke format
SavedModel. Untuk melakukannya, Anda memerlukan kamus signatures yang menggunakan
fungsi make_features_serving_fn dan kamus feature_spec. Daftar
berikut menunjukkan kode untuk kedua tugas tersebut.
SIGNATURE_NAME = 'serving_default'
features_input_signature = {
feature: tf.TensorSpec(shape=spec.shape, dtype=spec.dtype, name=feature)
for feature, spec in feature_spec.items()}
...
signatures = {
SIGNATURE_NAME: make_features_serving_fn(model).get_concrete_function(
features_input_signature)}
model.save(MODEL_DIR, save_format='tf', signatures=signatures)
Saat mengekspor model, Anda dapat memeriksa tanda tangan SavedModel (input dan
output) menggunakan alat command line saved_model_cli, yang menghasilkan
output berikut:
The given SavedModel SignatureDef contains the following input(s):
inputs['Aspect'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Aspect:0
inputs['Elevation'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Elevation:0
inputs['Hillshade_3pm'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Hillshade_3pm:0
inputs['Hillshade_9am'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Hillshade_9am:0
inputs['Hillshade_Noon'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Hillshade_Noon:0
inputs['Horizontal_Distance_To_Fire_Points'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Horizontal_Distance_To_Fire_Points:0
inputs['Horizontal_Distance_To_Hydrology'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Horizontal_Distance_To_Hydrology:0
inputs['Horizontal_Distance_To_Roadways'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Horizontal_Distance_To_Roadways:0
inputs['Slope'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Slope:0
inputs['Soil_Type'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_Soil_Type:0
inputs['Vertical_Distance_To_Hydrology'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: serving_default_Vertical_Distance_To_Hydrology:0
inputs['Wilderness_Area'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_Wilderness_Area:0
The given SavedModel SignatureDef contains the following output(s):
outputs['confidence'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall_24:0
outputs['predicted_label'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall_24:1
outputs['probabilities'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 7)
name: StatefulPartitionedCall_24:2
Method name is: tensorflow/serving/predict
Men-deploy model ke AI Platform Prediction
Anda menjalankan sel di bagian 4 dari notebook untuk men-deploy model. Setelah mengupload SavedModel ke lokasi Cloud Storage, Anda akan men-deploy model ke AI Platform Prediction sebagai REST API. Jalankan kode untuk membuat model, seperti yang ditunjukkan dalam cuplikan kode berikut:
!gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT} \
--regions {REGION}
Anda kemudian membuat versi model dengan menggunakan perintah berikut:
!gcloud ai-platform versions create {VERSION_NAME} \
--model={MODEL_NAME} \
--origin=gs://{BUCKET}/models/{MODEL_NAME} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--project={PROJECT}
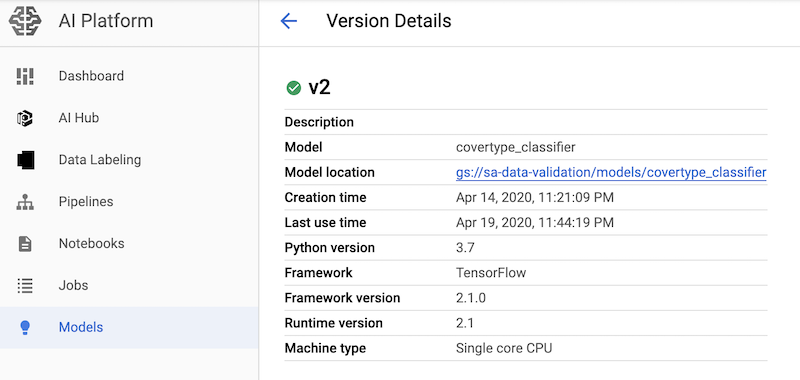
Setelah versi model dibuat, Anda dapat melihatnya di Google Cloud Console di bagian AI Platform > Model. Saat memilih model di konsol, Anda akan melihat versi model yang Anda buat. Untuk melihat detail tentang versi, Anda dapat mengklik versi model.
Gambar berikut menunjukkan detail versi yang ditampilkan di konsol.
Mengaktifkan logging respons permintaan ke BigQuery
Anda menjalankan sel di bagian 5 notebook untuk mengaktifkan logging ke BigQuery. Hal ini termasuk menyiapkan tabel BigQuery.
Secara default, layanan prediksi Prediction AI Platform tidak memberikan informasi tentang permintaan yang dicatat ke dalam log karena log dikenai biaya. Online prediksi yang melibatkan tingkat kueri per detik (QPS) yang tinggi dapat menghasilkan sejumlah besar log, yang tunduk pada harga BigQuery. Oleh karena itu, Anda harus mengaktifkan logging secara eksplisit.
Sebelum mengaktifkan logging respons permintaan ke BigQuery, Anda harus membuat tabel BigQuery yang memiliki format yang diterima layanan logging permintaan-respons.
Cuplikan berikut menampilkan kode di notebook yang Anda jalankan untuk membuat skema tabel BigQuery menyimpan log.
import json
table_schema_json = [
{"name":"model", "type": "STRING", "mode": "REQUIRED"},
{"name":"model_version", "type": "STRING", "mode":"REQUIRED"},
{"name":"time", "type": "TIMESTAMP", "mode": "REQUIRED"},
{"name":"raw_data", "type": "STRING", "mode": "REQUIRED"},
{"name":"raw_prediction", "type": "STRING", "mode": "NULLABLE"},
{"name":"groundtruth", "type": "STRING", "mode": "NULLABLE"}]
json.dump(table_schema_json, open('table_schema.json', 'w'))
Cuplikan berikut menunjukkan perintah BigQuery yang Anda jalankan untuk membuat tabel.
TIME_PARTITION_EXPERIATION = int(60 * 60 * 24 * 7)
!bq mk --table \
--project_id={PROJECT_ID} \
--time_partitioning_field=time \
--time_partitioning_type=DAY \
--time_partitioning_expiration={TIME_PARTITION_EXPERIATION} \
{PROJECT}:{BQ_DATASET_NAME}.{BQ_TABLE_NAME} \
'table_schema.json'
Untuk mengaktifkan logging permintaan-respons, gunakan metode
projects.models.versions.patch
dari versi model yang sudah ada. Anda harus menetapkan nilai samplingPercentage dan
bigqueryTableName dalam kamus requestLoggingConfig, seperti
yang ditunjukkan dalam cuplikan kode berikut:
sampling_percentage = 1.0
bq_full_table_name = '{}.{}.{}'.format(PROJECT, BQ_DATASET_NAME, BQ_TABLE_NAME)
service = googleapiclient.discovery.build('ml', 'v1')
name = 'projects/{}/models/{}/versions/{}'.format(PROJECT, MODEL_NAME, VERSION_NAME)
logging_config = {
"requestLoggingConfig":{
"samplingPercentage": sampling_percentage,
"bigqueryTableName": bq_full_table_name
}
}
service.projects().models().versions().patch(
name=name,
body=logging_config,
updateMask="requestLoggingConfig"
).execute()
Saat menjalankan kode ini, Anda akan melihat output yang mirip dengan berikut ini:
{'metadata': {'@type': 'type.googleapis.com/google.cloud.ml.v1.OperationMetadata',
'createTime': '2020-04-24T23:59:38Z',
'modelName': 'projects/[YOUR_GOOGLE_PROJECT]/models/covertype_classifier',
'operationType': 'UPDATE_VERSION',
'version': {'createTime': '2020-04-14T21:21:09Z',
'deploymentUri': 'gs://<[YOUR_CLOUD_STORAGE_BUCKET]/models/covertype_classifier',
'etag': 'TnlXt8cIbVs=',
'framework': 'TENSORFLOW',
'machineType': 'mls1-c1-m2',
'name': 'projects/[YOUR_GOOGLE_PROJECT]/models/covertype_classifier/versions/v2',
'pythonVersion': '3.7',
'requestLoggingConfig': {'bigqueryTableName': '[YOUR_GOOGLE_PROJECT].data_validation.covertype_classifier_logs',
'samplingPercentage': 1},
'runtimeVersion': '2.1',
'state': 'READY'}},
'name': 'projects/[YOUR_GOOGLE_PROJECT]/operations/update_covertype_classifier_v2_1587772778240'}
Menguji API model serta instance dan prediksi yang dicatat
Agar Anda dapat menguji API model, notebook ini menyertakan kode untuk mengimplementasikan
metode caip_predict. Metode ini memanggil model yang di-deploy ke
AI Platform Prediction sebagai API, yang meneruskan instance data tertentu. Cuplikan
berikut menunjukkan kode di notebook yang melakukan tugas ini.
import googleapiclient.discovery
service = googleapiclient.discovery.build('ml', 'v1')
name = 'projects/{}/models/{}/versions/{}'.format(PROJECT, MODEL_NAME, VERSION_NAME)
print("Service name: {}".format(name))
def caip_predict(instances):
request_body={
'signature_name': SIGNATURE_NAME,
'instances': instances}
response = service.projects().predict(
name=name,
body=request_body).execute()
if 'error' in response:
raise RuntimeError(response['error'])
probability_list = [output[MODEL_OUTPUT_KEY] for output in response['predictions']]
classes = [FEATURE_LABELS[int(np.argmax(probabilities))] for probabilities in probability_list]
return classes
Untuk memanggil API menggunakan sample instance, Anda menjalankan kode berikut. Kode
ini memanggil API 10 kali, dengan meneruskan kamus instances setiap waktu.
instances = [
{
'Soil_Type': ['7202'],
'Wilderness_Area': ['Commanche'],
'Aspect': [61],
'Elevation': [3091],
'Hillshade_3pm': [129],
'Hillshade_9am': [227],
'Hillshade_Noon': [223],
'Horizontal_Distance_To_Fire_Points': [2868],
'Horizontal_Distance_To_Hydrology': [134],
'Horizontal_Distance_To_Roadways': [0],
'Slope': [8],
'Vertical_Distance_To_Hydrology': [10],
}
]
...
import time
for i in range(10):
caip_predict(instances)
print('.', end='')
time.sleep(0.1)
Untuk mengkueri permintaan dan respons yang dicatat ke dalam log dari konsol, Anda dapat menggunakan konsol BigQuery, seperti yang ditunjukkan pada screenshot berikut:
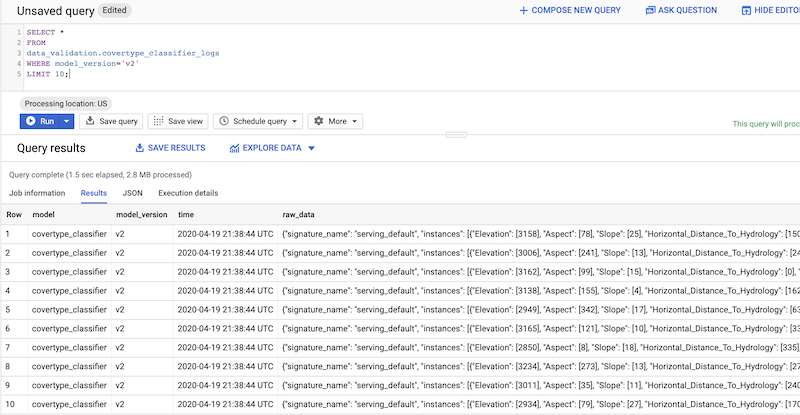
Seperti yang Anda lihat, instance (permintaan) dan prediksinya (respons) ditangkap dalam tabel BigQuery, tetapi dalam bentuk mentah yaitu dalam format JSON. Oleh karena itu, fitur dan probabilitas yang diprediksi harus diurai sebelum dapat dianalisis untuk menemukan diferensiasi. Panduan berikutnya dalam seri ini membahas cara melakukannya.
Pembersihan
Jika Anda berencana untuk melanjutkan sisa seri ini, pertahankan resource yang telah Anda buat. Jika tidak, hapus project yang berisi resource, atau simpan project dan hapus resource individual.
Menghapus project
- Di konsol Google Cloud, buka halaman Manage resource.
- Pada daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
Langkah selanjutnya
- Baca panduan Menganalisis log Prediksi AI Platform di BigQuery.
- Baca panduan Menganalisis kecenderungan penayangan pelatihan di Prediksi AI Platform dengan Validasi Data TensorFlow.
- Baca panduan Mengotomatiskan deteksi diferensiasi performa pelatihan dan penayangan di AI Platform Prediction.
- Pelajari MLOps, continuous delivery, dan pipeline otomatisasi di machine learning.
- Pelajari arsitektur untuk MLOps menggunakan TFX, Kubeflow Pipelines, dan Cloud Build.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.