Ces instructions vous expliquent comment configurer une solution permettant de répliquer les données d'une application SAP, telle que SAP S/4HANA ou SAP Business Suite, vers BigQuery à l'aide de SAP Landscape Transformation (LT) Replication Server et de SAP Data Services (DS).
La réplication de données vous permet de sauvegarder quasiment en temps réel les données des systèmes SAP ou de les regrouper dans BigQuery avec des données client issues d'autres systèmes afin d'obtenir des insights grâce au machine learning et à l'analyse de données à l'échelle du pétaoctet.
Ces instructions s'adressent aux administrateurs de systèmes SAP qui savent configurer SAP Basis, SAP LT Replication Server, SAP DS et Google Cloud.
Architecture

SAP LT Replication Server peut agir en tant que fournisseur de données pour NetWeaver, le framework de provisionnement de données opérationnelles (Operational Data Provisioning, ODP) de SAP. SAP LT Replication Server reçoit les données des systèmes SAP connectés et les stocke dans le framework ODP, dans une file d'attente ODQ (Operational Delta Queue) du système SAP LT Replication Server. De cette façon, SAP LT Replication Server joue également le rôle de cible des configurations SAP LT Replication Server. Le framework ODP rend les données disponibles en tant qu'objets ODP correspondant aux tables du système source.
Il accepte des scénarios d'extraction et de réplication pour diverses applications SAP cibles, appelées abonnés. Les abonnés récupèrent les données de la file d'attente delta en vue d'un traitement ultérieur.
Ces données sont ensuite répliquées dès qu'un abonné les demande à une source de données via un contexte ODP. Plusieurs abonnés peuvent utiliser la même URL comme source.
SAP LT Replication Server exploite la compatibilité de la capture de données modifiées (Changed Data Capture, CDC) de SAP Data Services 4.2 SP1 ou une version ultérieure, qui inclut des fonctionnalités de provisionnement des données en temps réel et delta pour toutes les tables sources.
Le schéma suivant représente le flux des données d'un système à l'autre :
- Les applications SAP mettent à jour les données dans le système source.
- SAP LT Replication Server réplique les données modifiées et les stocke dans la file d'attente delta opérationnelle.
- SAP DS est un abonné à la file d'attente opérationnelle delta qui l'interroge régulièrement pour rechercher les modifications de données.
- SAP DS récupère les données de la file d'attente delta, les transforme pour les rendre compatibles avec le format BigQuery et lance la tâche de chargement qui les déplace vers BigQuery.
- Ces données sont ensuite disponibles dans BigQuery pour l'analyse.
Dans ce scénario, le système source SAP, SAP LT Replication Server et SAP Data Services peuvent être exécutés sur ou hors de Google Cloud. Pour en savoir plus, consultez la page Provisionnement des données opérationnelles en temps réel avec SAP Landscape Transformation Replication Server.

Composants principaux de la solution
Les composants suivants sont requis pour répliquer les données des applications SAP et les déplacer vers BigQuery à l'aide de SAP Landscape Transformation Replication Server et de SAP Data Services :
| Composant | Versions requises | Remarques |
|---|---|---|
| Pile du serveur de l'application SAP | Tout système SAP basé sur ABAP à partir de la version R/3 4.6C SAP_Base (exigence minimale) :
|
Dans ce guide, le serveur d'application et le serveur de base de données sont collectivement désignés par l'appellation système source, même s'ils s'exécutent sur des machines différentes. Définir l'utilisateur RFC avec l'autorisation appropriée Facultatif : définir un espace de table distinct pour les tables de journalisation |
| Système de base de données | Toute version de base de données répertoriée comme compatible dans la matrice de disponibilité des produits SAP (Product Availability Matrix, PAM), sous réserve des restrictions de la pile SAP NetWeaver identifiées dans la matrice. Consulter la page service.sap.com/pam. | |
| Système d'exploitation | Toute version de système d'exploitation répertoriée comme compatible dans la matrice de disponibilité des produits SAP, sous réserve des restrictions de la pile SAP NetWeaver identifiées dans la matrice. Consulter la page service.sap.com/pam. | |
| SAP Data Migration Server (DMIS) | DMIS :
|
|
| SAP Landscape Transformation Replication Server | SAP LT Replication Server 2.0 ou une version ultérieure | Nécessite une connexion RFC au système source. Le dimensionnement du système SAP LT Replication Server dépend fortement de la quantité de données stockées dans la file d'attente ODQ et des durées de conservation planifiées. |
| SAP Data Services | SAP Data Services version 4.2 SP1 ou ultérieure | |
| BigQuery | N/A |
Coûts
BigQuery est un composant Google Cloud facturable.
Utilisez le Simulateur de coût pour générer une estimation des coûts en fonction de votre utilisation prévue.
Prérequis
Dans ces instructions, nous partons du principe que le serveur d'applications SAP, le serveur de base de données, le système SAP LT Replication Server et l'outil SAP Data Services sont déjà installés et configurés pour un fonctionnement normal.
Avant de pouvoir utiliser BigQuery, vous devez disposer d'un projet Google Cloud.
Configurer un projet Google Cloud dans Google Cloud
Vous devez activer l'API BigQuery et créer un projetGoogle Cloud , si ce n'est pas déjà fait.
Créer un projet Google Cloud
Accédez à la console Google Cloud , puis inscrivez-vous en suivant la procédure de l'assistant de configuration.
À côté du logo Google Cloud en haut à gauche, cliquez sur le menu déroulant, puis sélectionnez Créer un projet.
Attribuez un nom à votre projet, puis cliquez sur Créer.
Une fois le projet créé (une notification s'affiche en haut à droite), actualisez la page.
Activer des API
Activez l'API BigQuery :
Activer l'accès privé aux API Google Cloud
Pour les charges de travail SAP exécutées en dehors de Google Cloud, après avoir établi une connexion réseau à Google Cloud, vous devez activer l'accès privé aux API Google Cloud .
Pour en savoir plus, consultez la section Options d'accès privé à Google pour les services.
Créer un compte de service
Le compte de service (plus précisément son fichier de clé) permet d'authentifier SAP DS dans BigQuery. Vous utiliserez le fichier de clé ultérieurement lors de la création du datastore cible.
Dans la console Google Cloud , accédez à la page Comptes de service.
Sélectionnez votre projet Google Cloud .
Cliquez sur Créer un compte de service.
Saisissez un nom de compte de service.
Cliquez sur Create and continue (Créer et continuer).
Dans la liste Sélectionner un rôle, sélectionnez BigQuery > Éditeur de données BigQuery.
Cliquez sur Ajouter un autre rôle.
Dans la liste Sélectionner un rôle, choisissez BigQuery > Utilisateur de tâche BigQuery.
Cliquez sur Continuer.
Le cas échéant, accordez aux autres utilisateurs l'accès au compte de service.
Cliquez sur OK.
Sur la page Comptes de service de la console Google Cloud , cliquez sur l'adresse e-mail du compte de service que vous venez de créer.
Sous le nom du compte de service, cliquez sur l'onglet Clés.
Cliquez sur le menu déroulant Ajouter une clé, puis sélectionnez Créer une clé.
Assurez-vous que le type de clé JSON est spécifié.
Cliquez sur Créer.
Enregistrez le fichier de clé téléchargé automatiquement dans un emplacement sécurisé.
Configurer la réplication entre les applications SAP et BigQuery
Pour configurer cette solution, voici les étapes majeures à suivre :
- Configurer SAP LT Replication Server
- Configurer SAP Data Services
- Créer un flux de données entre SAP Data Services et BigQuery
Configurer SAP Landscape Transformation Replication Server
Les étapes suivantes permettent de configurer SAP LT Replication Server pour qu'il agisse en tant que fournisseur au sein du framework de provisionnement des données opérationnelles, et de créer une file d'attente delta opérationnelle. Dans cette configuration, SAP LT Replication Server utilise la réplication basée sur des déclencheurs pour copier les données du système SAP source dans les tables de la file d'attente delta. L'outil SAP Data Services, agissant en tant qu'abonné dans le framework ODP, récupère les données de la file d'attente delta, les transforme et les charge dans BigQuery.
Configurer la file d'attente delta opérationnelle (ODQ)
- Dans SAP LT Replication Server, utilisez la transaction
SM59afin de créer une destination RFC pour le système d'application SAP qui est la source de données. - Dans SAP LT Replication Server, utilisez la transaction
LTRCpour créer une configuration. Dans la configuration, définissez la source et la cible du système SAP LT Replication Server. La cible du transfert de données à l'aide de la fonctionnalité ODP est le système SAP LT Replication Server lui-même.- Pour spécifier la source, saisissez la destination RFC du système d'application SAP à utiliser comme source de données.
- Pour spécifier la cible, procédez comme suit :
- Saisissez NONE (Aucune) comme connexion RFC.
- Sélectionnez ODQ Replication Scenario (Scénario de réplication ODQ) pour la communication RFC. Si vous utilisez ce scénario, indiquez que le transfert de données s'effectue à l'aide de l'infrastructure de provisionnement des données opérationnelles et des files d'attente delta opérationnelles.
- Attribuez un alias de file d'attente.
L'alias de file d'attente s'utilise dans SAP Data Services pour paramétrer le contexte ODP de la source de données.
Configuration de SAP Data Services
Créer un projet de services de données
- Ouvrez l'application SAP Data Services Designer.
- Accédez à File > New > Project (Fichier > Nouveau > Projet).
- Saisissez un nom dans le champ Project name (Nom du projet).
- Dans Data Services Repository (Dépôt Data Services), sélectionnez votre dépôt de services de données.
- Cliquez sur Terminer. Votre projet s'affiche dans l'explorateur de projets à gauche.
SAP Data Services se connecte aux systèmes sources pour collecter les métadonnées, puis à l'agent SAP Replication Server pour récupérer la configuration et modifier les données.
Créer un datastore source
Les étapes suivantes permettent de créer une connexion à SAP LT Replication Server et d'ajouter les tables de données au nœud du datastore applicable dans la bibliothèque d'objets Designer.
Pour utiliser SAP LT Replication Server avec SAP Data Services, vous devez associer SAP Data Services à la file d'attente delta opérationnelle appropriée dans ODP en associant un datastore à l'infrastructure ODP.
- Ouvrez l'application SAP Data Services Designer.
- Dans l'explorateur de projets, effectuez un clic droit sur le nom de votre projet SAP Data Services.
- Sélectionnez New > Datastore (Nouveau > Datastore).
- Renseignez le champ Datastore Name (Nom du datastore). Par exemple, "DS_SLT".
- Dans le champ Datastore type (Type de datastore), sélectionnez SAP Applications (Applications SAP).
- Dans le champ Application server name (Nom du serveur d'applications), indiquez le nom de l'instance SAP LT Replication Server.
- Spécifiez les identifiants d'accès à SAP LT Replication Server.
- Ouvrez l'onglet Advanced (Avancé).
- Dans le champ ODP Context (Contexte ODP), saisissez SLT~ALIAS, où ALIAS correspond à l'alias de la file d'attente que vous avez spécifié dans lors de la configuration de la file d'attente delta opérationnelle (ODQ).
- Cliquez sur OK.
Le nouveau datastore s'affiche dans l'onglet Datastore de la bibliothèque d'objets locaux Designer.
Créer le datastore cible
Ces étapes permettent de créer un datastore BigQuery qui utilise le compte de service créé précédemment dans la section Créer un compte de service. Le compte de service permet à SAP Data Services d'accéder à BigQuery de manière sécurisée.
Pour en savoir plus, consultez les pages Obtain your Google service account email (Obtenir l'adresse e-mail d'un compte de service Google) et Obtain a Google service account private key file (Obtenir le fichier de clé privée d'un compte de service Google) de la documentation SAP Data Services.
- Ouvrez l'application SAP Data Services Designer.
- Dans l'explorateur de projets, effectuez un clic droit sur le nom de votre projet SAP Data Services.
- Sélectionnez New > Datastore (Nouveau > Datastore).
- Renseignez le champ Name (Nom). Par exemple, "BQ_DS".
- Cliquez sur Suivant.
- Dans le champ Datastore type (Type de datastore), sélectionnez Google BigQuery.
- L'option Web Service URL (URL du service Web) s'affiche. Le logiciel saisit automatiquement l'URL du service Web BigQuery par défaut dans cette option.
- Choisissez Avancée.
- Renseignez les options avancées en fonction des descriptions d'options du datastore pour BigQuery décrites dans la documentation SAP Data Services.
- Cliquez sur OK.
Le nouveau datastore s'affiche dans l'onglet Datastore de la bibliothèque d'objets locaux Designer.
Importer le ou les objets ODP sources pour la réplication
Ces étapes permettent d'importer des objets ODP à partir du datastore source afin d'exécuter des chargements initiaux et delta, et de rendre ces objets disponibles dans SAP Data Services.
- Ouvrez l'application SAP Data Services Designer.
- Dans l'explorateur de projets, développez le datastore source pour le chargement des données à répliquer.
- Sélectionnez l'option External Metadata (Métadonnées externes) dans la partie supérieure du panneau de droite. La liste des nœuds avec les tables et objets ODP disponibles s'affiche.
- Cliquez sur le nœud des objets ODP pour récupérer la liste d'objets ODP disponibles. L'affichage de la liste peut prendre un certain temps.
- Cliquez sur le bouton Search (Rechercher).
- Dans la boîte de dialogue, sélectionnez External data (Données externes) dans le menu Look in (Rechercher dans) puis ODP Object (Objet ODP) dans le menu Object type (Type d'objet).
- Dans la boîte de dialogue "Search" (Rechercher), sélectionnez les critères de recherche permettant de filtrer la liste des objets ODP sources.
- Dans la liste, sélectionnez l'objet ODP à importer.
- Effectuez un clic droit, puis sélectionnez l'option Import (Importer).
- Renseignez le champ Name of Consumer (Nom du client).
- Renseignez le champ Name of project (Nom du projet).
- Sélectionnez l'option Changed-data capture (CDC) (Capture de données modifiées) dans Extraction mode (Mode d'extraction).
- Cliquez sur Importer. Cette action démarre l'importation de l'objet ODP dans Data Services. L'objet ODP est désormais disponible dans la bibliothèque d'objets sous le nœud DS_SLT.
Pour en savoir plus, consultez la page Importing ODP source metadata (Importer les métadonnées de la source ODP) dans la documentation SAP Data Services.
Créer un fichier de schéma
Ces étapes permettent de créer un flux de données dans SAP Data Services afin de générer un fichier de schéma qui reflète la structure des tables sources. Vous allez ensuite créer une table BigQuery à l'aide de ce fichier.
Le schéma garantit que le flux de données du chargeur BigQuery remplit correctement la nouvelle table BigQuery.
Créer un flux de données
- Ouvrez l'application SAP Data Services Designer.
- Dans l'explorateur de projets, effectuez un clic droit sur le nom de votre projet SAP Data Services.
- Sélectionnez Project > Nouveau > DataFlow (Projet > Nouveau > Flux de données).
- Renseignez le champ Name (Nom). Par exemple, "DF_BQ".
- Cliquez sur Finish (Terminer).
Actualiser la bibliothèque d'objets
- Effectuez un clic droit sur le datastore source pour le chargement initial dans l'explorateur de projets, puis sélectionnez l'option Refresh Object Library (Actualiser la bibliothèque d'objets). Cette action met à jour la liste des tables de base de données source que vous pouvez utiliser dans votre flux de données.
Créer votre flux de données
- Créez votre flux de données en faisant glisser les tables sources vers l'espace de travail du flux de données et en sélectionnant Import as Source (Importer en tant que source) lorsque vous y êtes invité.
- Dans l'onglet Transformations (Transformations) de la bibliothèque d'objets, faites glisser une transformation XML_Map du nœud Platform vers le flux de données, puis sélectionnez Batch load (Chargement par lot) lorsque vous y êtes invité.
- Associez toutes les tables sources de l'espace de travail à la transformation XML Map.
- Ouvrez la transformation XML Map, puis complétez les sections des schémas d'entrée et de sortie en fonction des données incluses dans la table BigQuery.
- Effectuez un clic droit sur le nœud XML_Map dans la colonne Schema Out (Schéma de sortie), puis sélectionnez Generate Google BigQuery Schema (Générer le schéma Google BigQuery) dans le menu déroulant.
- Indiquez un nom et un emplacement pour le schéma.
- Cliquez sur Enregistrer.
- Dans l'explorateur de données, effectuez un clic droit sur le flux de données, puis sélectionnez Remove (Supprimer).
SAP Data Services génère un fichier de schéma portant l'extension .json.
Créer les tables BigQuery
Dans votre ensemble de données BigQuery surGoogle Cloud , vous devez créer des tables pour le chargement initial et pour les chargements delta. Pour cela, vous devez vous servir des schémas que vous avez créés dans SAP Data Services.
La table dédiée au chargement initial sert à la réplication initiale de tout l'ensemble de données source. La table dédiée aux chargements delta sert à la réplication des modifications de l'ensemble de données source qui se produisent après le chargement initial. Ces tables se basent sur le schéma que vous avez généré à l'étape précédente. La table dédiée aux chargements delta inclut un champ d'horodatage supplémentaire qui indique l'heure de chaque chargement delta.
Créer une table BigQuery dédiée au chargement initial
Ces étapes permettent de créer une table dédiée au chargement initial dans votre ensemble de données BigQuery.
- Accédez à votre projet Google Cloud dans la console Google Cloud .
- Sélectionnez BigQuery.
- Cliquez sur l'ensemble de données concerné.
- Cliquez sur Créer une table.
- Saisissez un nom de table. Par exemple, "BQ_INIT_LOAD".
- Sous Schéma, activez le mode Modifier sous forme de texte.
- Définissez le schéma de la nouvelle table dans BigQuery en copiant et en collant le contenu du fichier créé à l'étape Créer un fichier de schéma.
- Cliquez sur Create table.
Créer une table BigQuery dédiée aux chargements delta
Ces étapes permettent de créer une table dédiée aux chargements delta de votre ensemble de données BigQuery.
- Accédez à votre projet Google Cloud dans la console Google Cloud .
- Sélectionnez BigQuery.
- Cliquez sur l'ensemble de données concerné.
- Cliquez sur Créer une table.
- Saisissez le nom de la table. Par exemple, "BQ_DELTA_LOAD".
- Sous Schéma, activez l'option Modifier sous forme de texte.
- Définissez le schéma de la nouvelle table dans BigQuery en copiant et en collant le contenu du fichier créé à l'étape Créer un fichier de schéma.
Dans la liste JSON du fichier de schéma, juste avant la définition du champ DL_SEQUENCE_NUMBER, ajoutez la définition du champ DL_TIMESTAMP suivante. Ce champ stocke l'horodatage de chaque chargement delta exécuté :
{ "name": "DL_TIMESTAMP", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "Delta load timestamp" },Cliquez sur Create table.
Configurer le flux de données entre SAP Data Services et BigQuery
Pour configurer le flux de données, vous devez importer les tables BigQuery dans SAP Data Services en tant que métadonnées externes, puis créer la tâche de réplication et le flux de données du chargeur BigQuery.
Importer les tables BigQuery
Ces étapes permettent d'importer les tables BigQuery que vous avez créées à l'étape précédente et de les rendre disponibles dans SAP Data Services.
- Dans la bibliothèque d'objets SAP Data Services Designer, ouvrez le datastore BigQuery que vous avez créé précédemment.
- Dans la partie supérieure du panneau de droite, sélectionnez External Metadata (Métadonnées externes). Les tables BigQuery que vous avez créées s'affichent.
- Effectuez un clic droit sur le nom de la table BigQuery de votre choix, puis sélectionnez Import (Importer).
- L'importation de la table sélectionnée dans SAP Data Services commence. La table est désormais disponible dans la bibliothèque d'objets sous le nœud du datastore cible.
Créer une tâche de réplication et le flux de données du chargeur BigQuery
Ces étapes permettent de créer une tâche de réplication ainsi que le flux de données dans SAP Data Services qui servira à charger les données SAP LT Replication Server dans la table BigQuery.
Le flux de données comprend deux parties. La première exécute le chargement initial des données depuis le ou les objets ODP sources dans la table BigQuery, tandis que la seconde active les chargements delta ultérieurs.
Créer une variable globale
Pour que la tâche de réplication puisse déterminer si vous souhaitez exécuter un chargement initial ou un chargement delta, vous devez créer une variable globale permettant de suivre le type de chargement dans la logique du flux de données.
- Dans le menu de l'application SAP Data Services Designer, accédez à Tools (Outils) > Variables (Variables).
- Effectuez un clic droit sur Global Variables (Variables globales), puis sélectionnez Insert (Insérer).
- Effectuez un clic droit sur le Nom de la variable, puis sélectionnez Properties (Propriétés).
- Saisissez "$ INITLOAD" dans le Nom de la variable.
- Dans Data Type (Type de données), sélectionnez Int.
- Saisissez 0 dans le champ Value (Valeur).
- Cliquez sur OK.
Créer la tâche de réplication
- Dans l'explorateur de projets, effectuez un clic droit sur le nom de votre projet.
- Sélectionnez New (Nouvelle tâche) puis Batch Job (Tâche par lot).
- Renseignez le champ Name (Nom). Par exemple, "JOB_SRS_DS_BQ_REPLICATION".
- Cliquez sur Terminer.
Créer une logique de flux de données pour le chargement initial
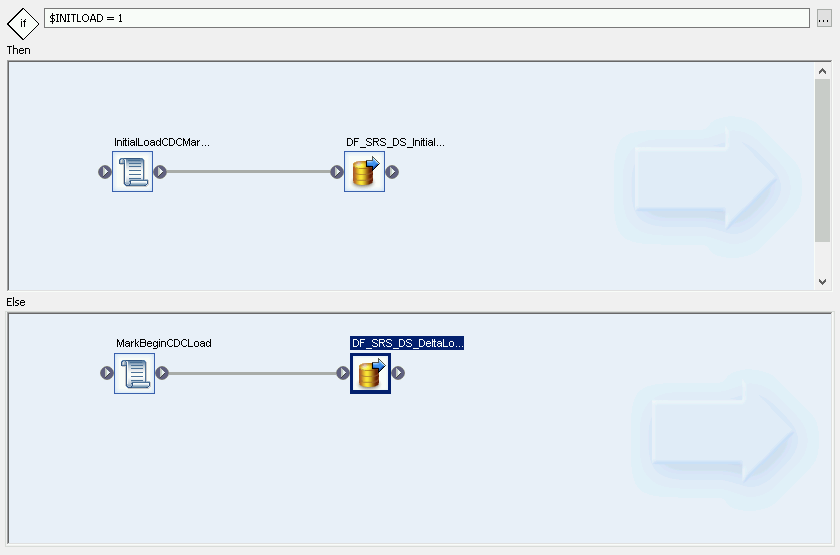
Créer une instruction conditionnelle
- Effectuez un clic droit sur Job Name (Nom de la tâche), puis sélectionnez l'option Add New (Ajouter) > Conditional (Instruction conditionnelle).
- Effectuez un clic droit sur l'icône d'instruction conditionnelle, puis sélectionnez Rename (Renommer).
Remplacez le nom par InitialOrDelta.

Ouvrez l'éditeur d'instruction conditionnelle en double-cliquant sur l'icône correspondante.
Dans le champ If instruction (Instruction If), saisissez "$INITLOAD = 1", qui définit la condition d'exécution du chargement initial.
Effectuez un clic droit dans le volet Then (Alors), puis sélectionnez Add (Ajouter) > Script (Script).
Effectuez un clic droit sur l'icône de Script, puis sélectionnez Rename (Renommer).
Modifiez le nom. Par exemple, ces instructions utilisent "InitialLoadCDCMarker".
Double-cliquez sur l'icône de Script pour ouvrir l'éditeur de fonction.
Saisissez
print('Beginning Initial Load');.Saisissez
begin_initial_load();.
Cliquez sur l'icône de retour dans la barre d'outils de l'application pour quitter l'éditeur de fonction.
Créer un flux de données pour le chargement initial
- Effectuez un clic droit dans le volet Then (Alors), puis sélectionnez Add New (Ajouter) > Data Flow (Flux de données).
- Renommez le flux de données. Par exemple, "DF_SRS_DS_InitialLoad".
- Associez "InitialLoadCDCMarker" au flux "DF_SRS_DS_InitialLoad" en cliquant sur l'icône d'association de sortie à "InitialLoadCDCMarker", puis faites glisser la ligne d'association vers l'icône d'entrée du flux "DF_SRS_DS_InitialLoad".
- Double-cliquez sur le flux de données "DD_SRS_DS_InitialLoad".
Importer le flux de données et l'associer aux objets du datastore source
- Depuis le datastore, faites glisser le ou les objets ODP sources vers l'espace de travail du flux de données. Dans ces instructions, le datastore est nommé "DS_SLT". Le nom de votre datastore peut être différent.
- Faites glisser Query transform (Transformation de requête) depuis le nœud Platform (Plate-forme) situé dans l'onglet Transforms (Transformations) de la bibliothèque d'objets vers le flux de données.
Double-cliquez sur le ou les objets ODP et, dans l'onglet Source, définissez l'option Initial Load (Chargement initial) sur Yes (Oui).
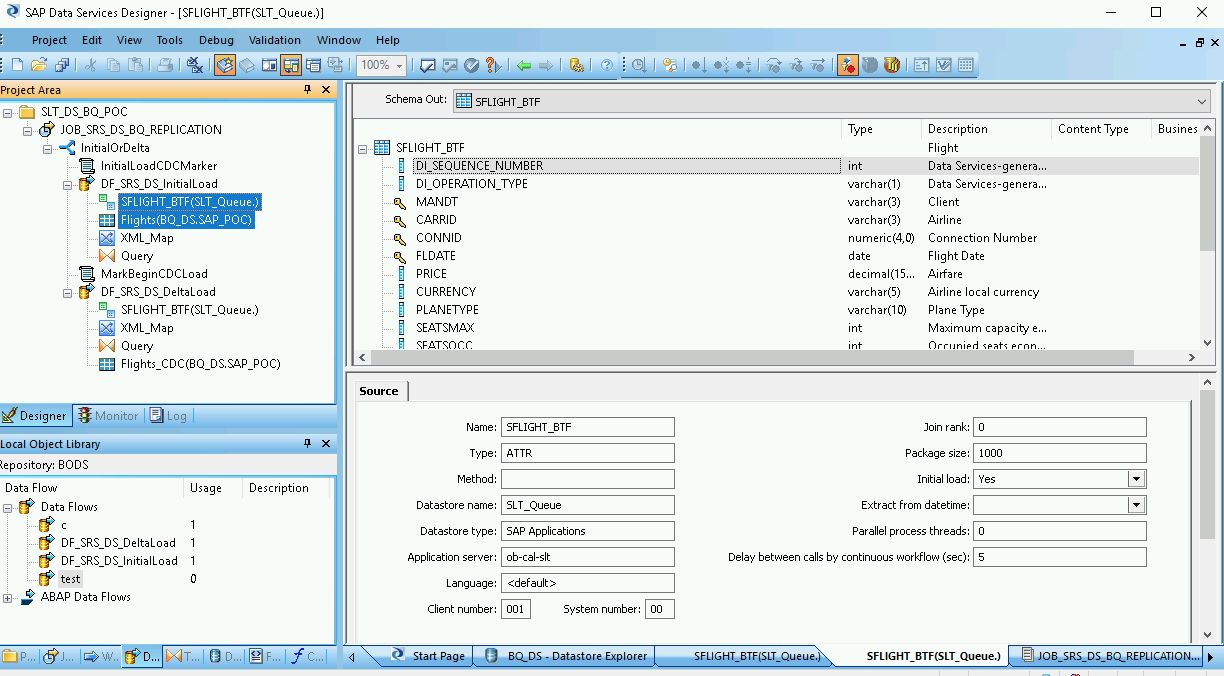
Associez tous les objets ODP sources de l'espace de travail à la transformation de requête.
Double-cliquez sur Query transform (Transformation de requête).
Sélectionnez tous les champs de la table sous Schema In (Schéma d'entrée) à gauche, puis faites-les glisser vers Schema Out (Schéma de sortie) à droite.
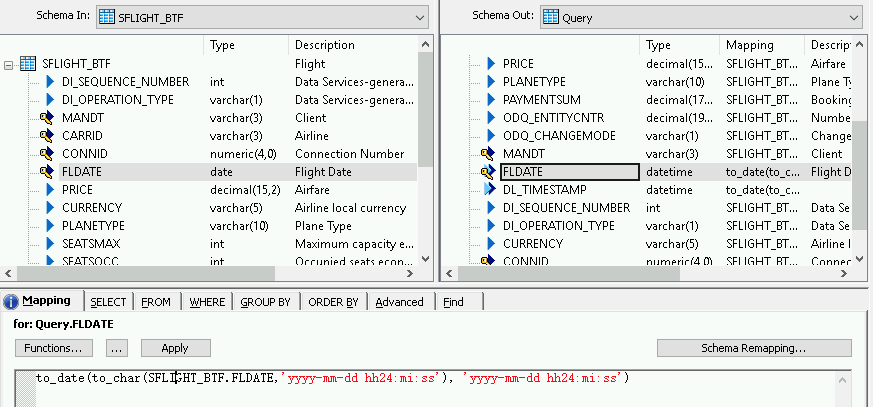
Pour ajouter une fonction de conversion à un champ date/heure, procédez comme suit :
- Sélectionnez le champ date/heure dans la liste Schema Out (Schéma désactivé) à droite.
- Sélectionnez l'onglet Mapping (Mappage) sous les listes de schémas.
Remplacez le nom du champ par la fonction suivante :
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')Où FIELDNAME est le nom du champ sélectionné.
Dans la barre d'outils de l'application, cliquez sur l'icône de retour pour revenir au flux de données.
Importer le flux de données et l'associer aux objets du datastore cible
- Dans le datastore de la bibliothèque d'objets, faites glisser la table BigQuery importée pour le chargement initial vers le flux de données. Dans ces instructions, le datastore est nommé "BQ_DS". Le nom de votre datastore peut être différent.
- Dans le nœud Platform (Plate-forme) de l'onglet Transforms (Transformations) de la bibliothèque d'objets, faites glisser une transformation XML_Map sur le flux de données.
- Dans la boîte de dialogue, sélectionnez le mode Batch (Par lot).
- Associez la transformation Query (Requête) à la transformation XML_Map.
Associez la transformation XML_Map à la table BigQuery importée.
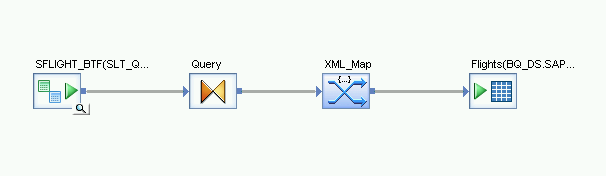
Ouvrez la transformation XML_Map, puis complétez les sections des schémas d'entrée et de sortie en fonction des données incluses dans la table BigQuery.
Dans l'espace de travail, double-cliquez sur la table BigQuery pour l'ouvrir, puis remplissez les options de l'onglet Target (Cible) comme indiqué dans le tableau suivant :
| Option | Description |
|---|---|
| Port de création | Spécifiez No (Non), qui est la valeur par défaut. Spécifier Yes (Oui) permet de transformer un fichier source ou cible en port de flux de données intégré. |
| Mode | Définissez le paramètre Troncate (Tronquer) pour le chargement initial. Il remplace tous les enregistrements existants de la table BigQuery par les données chargées par SAP Data Services. Truncate (Tronquer) est la valeur par défaut. |
| Nombre de chargeurs | Spécifiez un entier positif pour définir le nombre de chargeurs (threads) à utiliser pour le traitement. La valeur par défaut est 4.
Chaque chargeur lance une tâche de chargement avec reprise dans BigQuery. Vous pouvez spécifier autant de chargeurs que vous le souhaitez. Pour déterminer le nombre approprié de chargeurs, consultez la documentation SAP, y compris les pages suivantes : |
| Nombre maximal d'échecs d'enregistrements par chargeur | Indiquez zéro ou un entier positif pour définir le nombre maximal d'enregistrements pouvant échouer par tâche de chargement avant que BigQuery arrête le chargement des enregistrements. La valeur par défaut est zéro (0). |
- Cliquez sur l'icône de validation dans la barre d'outils supérieure.
- Cliquez sur l'icône de retour dans la barre d'outils de l'application pour revenir à l'éditeur d'instruction conditionnelle.
Créer un flux de données pour le chargement delta
Pour répliquer les enregistrements de capture de données modifiées qui s'accumulent après le chargement initial, vous devez créer un flux de données.
Pour créer un flux delta conditionnel, procédez comme suit :
- Double-cliquez sur l'instruction conditionnelle InitialOrDelta.
- Effectuez un clic droit dans la section Else (Sinon) et sélectionnez Add New (Ajouter) > Script (Script).
- Renommez le script. Par exemple, "MarkBeginCDCLoad".
- Double-cliquez sur l'icône de script pour ouvrir l'éditeur de fonction.
Saisissez l'instruction d'impression ("Début du chargement delta").

Cliquez sur l'icône de retour dans la barre d'outils de l'application pour revenir à l'éditeur d'instruction conditionnelle.
Créer le flux de données pour le chargement delta
- Dans l'éditeur d'instruction conditionnelle, effectuez un clic droit et sélectionnez Add (Ajouter) > Dataflow (Flux de données).
- Renommez le flux de données. Par exemple, "DF_SRS_DS_DeltaLoad".
- Associez MarkBeginCDCLoad au flux DF_SRS_DS_DeltaLoad, comme indiqué dans le schéma suivant.
Double-cliquez sur le flux de données DF_SRS_DS_DeltaLoad.
Importer le flux de données et l'associer aux objets du datastore source
- Faites glisser le ou les objets ODP sources du datastore vers l'espace de travail du flux de données. Dans ces instructions, le datastore est nommé "DS_SLT". Le nom de votre datastore peut être différent.
- Dans le nœud Platform (Plate-forme) de l'onglet Transforms (Transformations) de la bibliothèque d'objets, faites glisser la transformation Query (Requête) vers le flux de données.
- Double-cliquez sur le ou les objets ODP, puis définissez l'option Initial Load (Chargement initial) sur No (Non) dans l'onglet Source.
- Associez tous les objets ODP sources de l'espace de travail à la transformation Query (Requête).
- Double-cliquez sur Query transform (Transformation de requête).
- Sélectionnez tous les champs de table dans la liste "Schema In" (Schéma d'entrée) à gauche et faites-les glisser vers la liste "Schema Out" (Schéma de sortie) à droite.
Activer l'horodatage pour les chargements delta
Les étapes suivantes permettent à SAP Data Services d'enregistrer automatiquement l'horodatage de chaque chargement delta exécuté dans un champ de la table dédiée aux chargements delta.
- Dans le volet "Schema Out" (Schéma de sortie) à droite, effectuez un clic droit sur le nœud Query (Requête).
- Sélectionnez New Output Column (Nouvelle colonne de sortie).
- Dans le champ Name (Nom), saisissez DL_TIMESTAMP.
- Dans Data type (Type de données), sélectionnez "datetime" (date/heure).
- Cliquez sur OK.
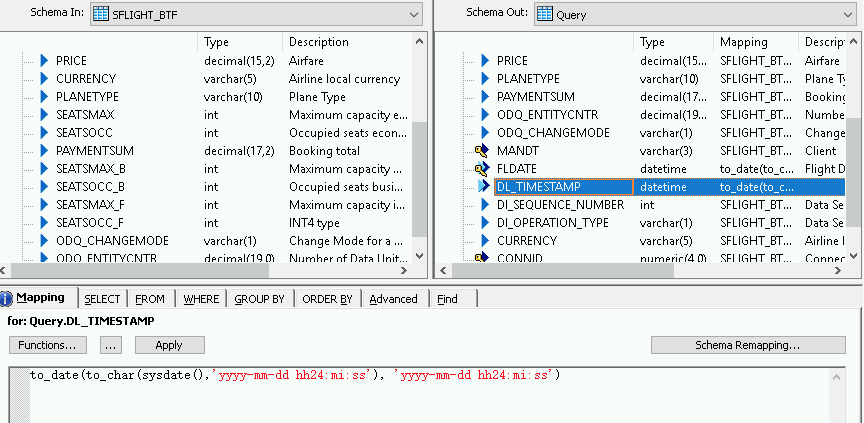
- Cliquez sur le champ DL_TIMESTAMP que vous venez de créer.
- Accédez à l'onglet Mapping (Mappage) ci-dessous.
Saisissez la fonction suivante :
- to_date(to_char(sysdate(),'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
Importer le flux de données et l'associer aux objets du datastore cible
- Dans le datastore de la bibliothèque d'objets, faites glisser la table BigQuery importée pour le chargement delta vers l'espace de travail du flux de données après la transformation XML_Map. Dans ces instructions, le datastore est nommé BQ_DS. Le nom de votre datastore peut être différent.
- Dans le nœud Platform (Plate-forme) de l'onglet Transforms (Transformations) de la bibliothèque d'objets, faites glisser une transformation XML_Map vers le flux de données.
- Associez la transformation Query (Requête) à la transformation XML_Map.
Associez la transformation XML_Map à la table BigQuery importée.
Ouvrez la transformation XML_Map, puis complétez les sections des schémas d'entrée et de sortie en fonction des données incluses dans la table BigQuery.
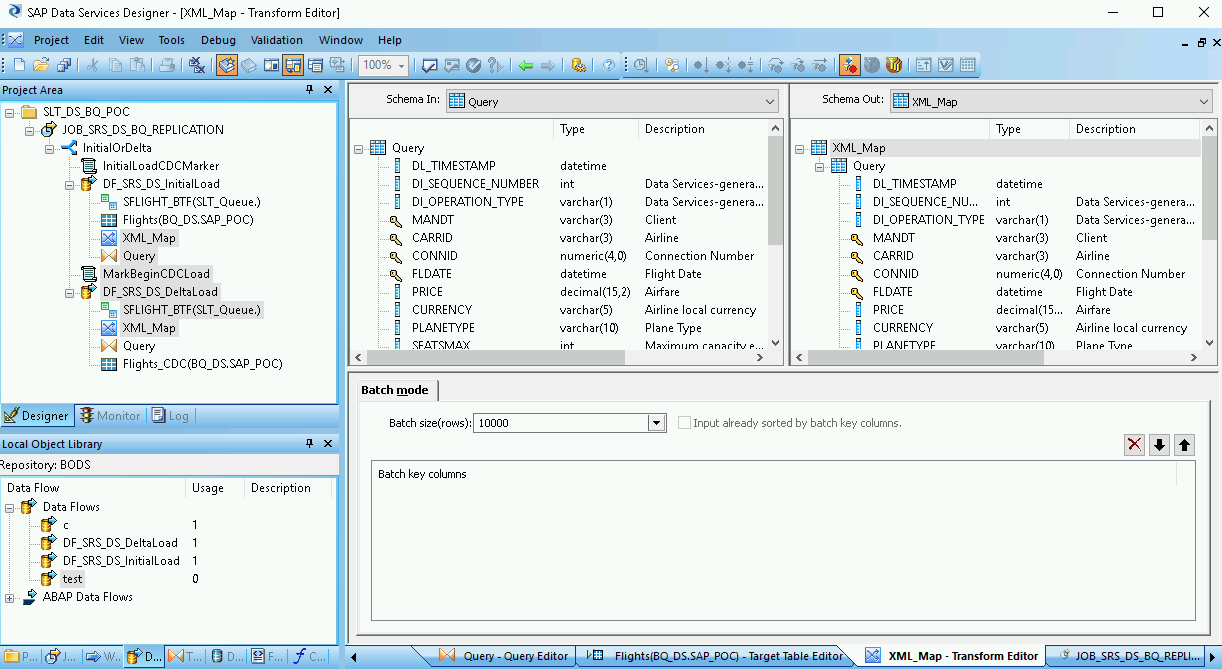
Dans l'espace de travail, double-cliquez sur la table BigQuery pour l'ouvrir et définissez les options de l'onglet Target (Cible) en fonction des descriptions suivantes :
| Option | Description |
|---|---|
| Port de création | Spécifiez No (Non), qui est la valeur par défaut. Spécifier Yes (Oui) permet de transformer un fichier source ou cible en port de flux de données intégré. |
| Mode | Spécifiez le paramètre Append (Ajouter) pour les chargements delta, afin de conserver les enregistrements existants dans la table BigQuery lorsque de nouveaux enregistrements sont chargés à partir de SAP Data Services. |
| Nombre de chargeurs | Spécifiez un entier positif pour définir le nombre de chargeurs (threads) à utiliser pour le traitement.
Chaque chargeur lance une tâche de chargement avec reprise dans BigQuery. Vous pouvez spécifier autant de chargeurs que vous le souhaitez. En règle générale, les chargements delta nécessitent moins de chargeurs que le chargement initial. Pour déterminer le nombre approprié de chargeurs, consultez la documentation SAP, y compris les pages suivantes : |
| Nombre maximal d'échecs d'enregistrements par chargeur | Indiquez zéro ou un entier positif pour définir le nombre maximal d'enregistrements pouvant échouer par tâche de chargement avant que BigQuery arrête le chargement des enregistrements. La valeur par défaut est zéro (0). |
- Cliquez sur l'icône de validation dans la barre d'outils supérieure.
- Cliquez sur l'icône de retour dans la barre d'outils de l'application pour revenir à l'éditeur d'instruction conditionnelle.

Charger les données dans BigQuery
Les étapes permettant d'effectuer un chargement initial et un chargement delta sont similaires. Pour chacun de ces chargements, vous démarrez la tâche de réplication, puis vous exécutez le flux de données dans SAP Data Services pour charger les données SAP LT Replication Server dans BigQuery. La différence majeure entre les deux procédures de chargement consiste à définir la valeur de la variable globale $INITLOAD différemment. Pour un chargement initial, définissez $INITLOAD sur 1. Pour un chargement delta, définissez $ INITLOAD sur 0.
Exécuter un chargement initial
Lorsque vous exécutez un chargement initial, toutes les données de l'ensemble de données source sont répliquées dans la table BigQuery cible associée au flux de données du chargement initial. Toutes les données de la table cible sont écrasées.
- Dans SAP Data Services Designer, ouvrez l'explorateur de projets.
- Effectuez un clic droit sur le nom de la tâche de réplication, puis cliquez sur Execute (Exécuter). Une boîte de dialogue s'affiche.
- Dans la boîte de dialogue, accédez à l'onglet Global Variable (Variable globale) et remplacez la valeur de
$INITLOADpar 1, de sorte que le chargement initial s'exécute en premier. - Cliquez sur OK. Le processus de chargement démarre et les messages de débogage s'affichent dans le journal SAP Data Services. Les données sont chargées dans la table que vous avez créée dans BigQuery pour les chargements initiaux. Dans ces instructions, la table de chargement initial est nommée "BQ_INIT_LOAD". Le nom de votre table peut être différent.
- Pour savoir si le chargement est terminé, accédez à la console Google Cloud et ouvrez l'ensemble de données BigQuery qui contient la table. Si le chargement des données est toujours en cours, la mention Loading (Chargement) s'affiche à côté du nom de la table.
Une fois le chargement terminé, les données sont prêtes à être traitées dans BigQuery.
À partir de ce moment, toutes les modifications de la table source sont enregistrées dans la file d'attente delta du système SAP Replication Server. Pour charger les données de la file d'attente delta dans BigQuery, vous devez exécuter une tâche de chargement delta.
Exécuter un chargement delta
Lorsque vous exécutez un chargement delta, seules les modifications apportées à l'ensemble de données source depuis le dernier chargement sont répliquées dans la table BigQuery cible associée au flux de données de chargement delta.
- Effectuez un clic droit sur le nom de la tâche, puis sélectionnez Execute (Exécuter).
- Cliquez sur OK. Le processus de chargement démarre et les messages de débogage s'affichent dans le journal SAP Data Services. Les données sont chargées dans la table dédiée aux chargements delta que vous avez créée dans BigQuery. Dans ces instructions, la table de chargement delta est nommée "BQ_DELTA_LOAD". Le nom de votre table peut être différent.
- Pour savoir si le chargement est terminé, accédez à la console Google Cloud et ouvrez l'ensemble de données BigQuery qui contient la table. Si le chargement des données est toujours en cours, la mention Loading (Chargement) s'affiche à côté du nom de la table.
- Une fois le chargement terminé, les données sont prêtes à être traitées dans BigQuery.
Pour effectuer le suivi des modifications apportées aux données sources, SAP LT Replication Server enregistre l'ordre des opérations de modification des données dans la colonne ID_SEQUENCE_NUMBER et le type d'opération de modification (suppression, mise à jour, insertion) dans la colonne ID_OPÉRATION (D=delete, U=update, I=insert). SAP LT Replication Server stocke les données dans les colonnes des tables de la file d'attente delta, puis les réplique dans BigQuery à partir de ces tables.
Planifier des chargements delta
Vous pouvez planifier l'exécution des tâches de chargement delta à intervalles réguliers à l'aide de la console de gestion de SAP Data Services.
- Ouvrez l'application SAP Data Services Management Console.
- Cliquez sur Administrator (Administrateur).
- Dans l'arborescence de menu située à gauche, développez le nœud Batch (Par lot).
- Cliquez sur le nom de votre dépôt SAP Data Services.
- Cliquez sur l'onglet Batch Job Configuration (Configuration de la tâche par lot).
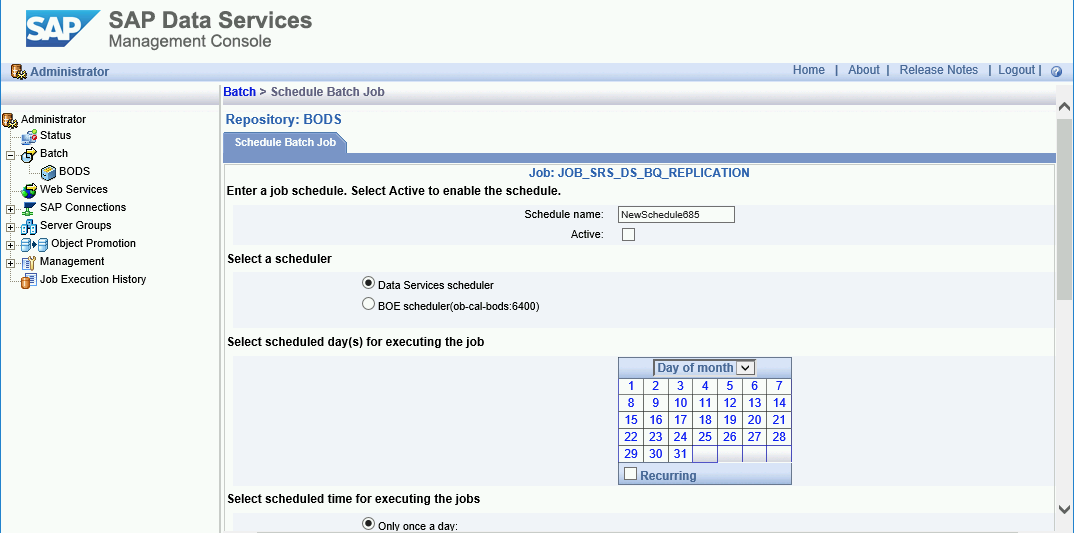
- Cliquez sur Add Schedule (Ajouter un programme).
- Renseignez le champ Schedule name (Nom du programme).
- Cochez la case Active.
- Dans la section Select scheduled time for executing the jobs (Sélectionner l'heure programmée pour l'exécution des tâches), spécifiez la fréquence d'exécution du chargement différé.
- Important: Google Cloud limite le nombre de tâches de chargement BigQuery que vous pouvez exécuter par jour. Assurez-vous que votre programme ne dépasse pas la limite, car celle-ci ne peut pas être augmentée. Pour en savoir plus sur la limite applicable aux tâches de chargement BigQuery, consultez la page Quotas et limites de la documentation BigQuery.
- Développez Global Variables (Variables globales) et vérifiez si $INITLOAD est défini sur 0.
- Cliquez sur Apply (Appliquer).
Étapes suivantes
Interrogez et analysez les données répliquées dans BigQuery.
Pour en savoir plus sur les requêtes, consultez la page suivante :
- Présentation des requêtes de données dans BigQuery dans la documentation BigQuery
Pour savoir comment regrouper à grande échelle les données de chargement initial et delta dans BigQuery, consultez les pages suivantes :
- Effectuer des mutations à grande échelle dans BigQuery : solution disponible sur le Google Cloud blog.
- Langage de manipulation de données : dans la documentation BigQuery.
Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.