En este artículo se explica cómo migrar una base de datos de los sistemas de procesamiento transaccionales en línea (OLTP) desde MySQL a Cloud Spanner.
Restricciones de migración
Spanner utiliza ciertos conceptos de forma diferente a otras herramientas de administración de bases de datos empresariales, por lo que es posible que debas ajustar la arquitectura de tu aplicación para sacar el máximo partido de sus funciones. Además, es posible que tengas que complementar Spanner con otros servicios de Google Cloud para satisfacer tus necesidades.
Activadores y procedimientos almacenados
Spanner no admite la ejecución de código de usuario a nivel de base de datos, por lo que, como parte de la migración, la lógica empresarial implementada por los procesos y procesos almacenados a nivel de base de datos debe trasladarse a la aplicación.
Secuencias
Spanner no implementa un generador de secuencias y, tal y como se explica a continuación, usar números en aumento monolitos, ya que las claves principales son un patrón que se usa en Spanner. Un mecanismo alternativo para generar una clave principal única es usar un UID único.
Si necesitas secuencias por motivos externos, debes implementarlas en la capa de aplicación.
Controles de acceso
Spanner solo admite controles de acceso a nivel de base de datos mediante los permisos y permisos de acceso de gestión de identidades y accesos. Hay roles predefinidos que pueden conceder acceso de lectura y escritura o de solo lectura a la base de datos. Si necesitas permisos pormenorizados, debes implementarlos en la capa de aplicación. En una situación normal, solo la aplicación debe poder leer y escribir en la base de datos.
Si necesitas exponer tu base de datos a los usuarios para que utilicen los informes y quieres usar permisos de seguridad pormenorizados (por ejemplo, permisos de tabla o de vista), te recomendamos que exportes la base de datos a BigQuery.
Restricciones de validación de datos
Spanner admite un conjunto limitado de restricciones de validación de datos en la capa de la base de datos. Si necesitas restricciones de datos más complejas, debes implementarlas en la capa de aplicación.
En la siguiente tabla se explican los tipos de restricciones que se suelen encontrar en las bases de datos MySQL y cómo se implementan con Spanner.
| Restricción | Implementación con Spanner |
|---|---|
| No es nulo | Restricción de columnas NOT NULL |
| Identificador único | Secondaryndice secundario con restricción de UNIQUE |
Foreign key (para tablas normales) |
Consulta Crear y gestionar relaciones de claves externas. |
Acciones ON DELETE/ON UPDATE de clave externa |
Solo es posible en tablas intercaladas. de lo contrario, implementada en la capa de la aplicación |
Comprobaciones de valores y validación mediante restricciones de CHECK |
Consulta la sección Crear y gestionar restricciones de comprobaciones. |
| Comprobaciones de valores y validación mediante activadores | Implementado en la capa de aplicación |
Columnas generadas
Spanner admite columnas generadas, por las que el valor de columna siempre se generará mediante una función proporcionada como parte de la definición de la tabla. Al igual que en MySQL, las columnas generadas no se pueden definir de forma explícita en un valor proporcionado en una declaración de DML.
Las columnas generadas se definen como parte de la definición de la columna durante una declaración CREATE TABLE o ALTER TABLE en el lenguaje de definición de datos (DDL). La palabra clave AS va seguida de una función SQL válida y del sufijo obligatorio STORED. La palabra clave STORED forma parte de la especificación SQL ANSI SQL e indica que los resultados de la función se almacenarán junto con otras columnas de la tabla.
La función SQL, la expresión de generación, puede incluir cualquier expresión, función y operador deterministas y se puede usar en índices secundarios o usarse como valores extranjeros.
Consulta más información sobre cómo gestionar este tipo de columnas en el artículo Crear y gestionar columnas generadas.
Tipos de datos admitidos
MySQL y Spanner admiten diferentes conjuntos de tipos de datos. En la siguiente tabla se enumeran los tipos de datos de MySQL y su equivalente en Spanner. Para obtener definiciones detalladas de cada tipo de datos de Spanner, consulta Tipos de datos.
Es posible que debas transformar tus datos tal como se describe en la columna Notas para que los datos de MySQL se adapten a tu base de datos de Spanner. Por ejemplo, puedes almacenar un objeto BLOB grande como objeto en un segmento de Cloud Storage en lugar de en la base de datos, y luego almacenar la referencia de URI al objeto de Cloud Storage en la base de datos como un objeto STRING.
| Tipo de datos de MySQL | Equivalente en Spanner | Notas |
|---|---|---|
INTEGER, INT, BIGINT de MEDIUMINT de SMALLINT |
INT64 |
|
TINYINT, BOOL, BOOLEAN |
BOOL, INT64 |
Los valores TINYINT(1) se usan para representar los valores booleanos "true" (no cero) o "false" (0). |
FLOAT, DOUBLE |
FLOAT64 |
|
DECIMAL, NUMERIC |
NUMERIC, STRING
|
En MySQL,los tipos de datos NUMERIC y DECIMAL admiten hasta 65 dígitos de precisión y escala, tal como se define en la declaración de la columna.
El tipo de datos NUMERIC de Spanner admite hasta 38 dígitos de precisión y 9 dígitos decimales de escala.Si necesitas una mayor precisión, consulta la página sobre cómo almacenar datos numéricos de precisión arbitrarios para ver mecanismos alternativos. |
BIT |
BYTES |
|
DATE |
DATE |
Tanto Spanner como MySQL utilizan el formato yyyy-mm-dd para las fechas, por lo que no es necesario hacer nada. Se proporcionan funciones de SQL para convertir fechas en una cadena con formato. |
DATETIME, TIMESTAMP |
TIMESTAMP |
Spanner almacena tiempo independientemente de la zona horaria. Si necesitas almacenar una zona horaria, debes usar una columna STRING distinta.
Las funciones de SQL se proporcionan para convertir marcas de tiempo en una cadena con formato según las zonas horarias. |
CHAR, VARCHAR |
STRING |
Nota: Spanner usa cadenas Unicode en toda la interfaz. VARCHAR admite una longitud máxima de 65.535 bytes, mientras que Spanner admite un máximo de 2.621.440 caracteres. |
BINARY, VARBINARY, BLOB, TINYBLOB |
BYTES |
Los objetos pequeños (menos de 10 MiB) se pueden almacenar como BYTES. Usa productos de Google Cloud alternativos como Cloud Storage para almacenar objetos más grandes |
TEXT, TINYTEXT, ENUM |
STRING
|
Los valores TEXT pequeños (menos de 10 MiB) se pueden almacenar como STRING. Te recomendamos usar ofertas de Google Cloud alternativas, como Cloud Storage, para admitir valores TEXT más grandes. |
ENUM |
STRING |
La validación de valores de ENUM debe realizarse en la aplicación. |
SET |
ARRAY<STRING> |
La validación de valores de elemento SET debe realizarse en la aplicación. |
LONGBLOB, MEDIUMBLOB |
BYTES o STRING que incluyen el URI del objeto.
|
Los objetos pequeños (menos de 10 MiB) se pueden almacenar como BYTES.
Te recomendamos que utilices otros servicios de Google Cloud, como Cloud Storage, para almacenar objetos más grandes. |
LONGTEXT, MEDIUMTEXT |
STRING (con los datos o el URI a un objeto externo)
|
Los objetos pequeños (menos de 2.621.440 caracteres) se pueden almacenar como STRING. Usa soluciones alternativas de Google Cloud, como Cloud Storage, para almacenar objetos más grandes |
JSON |
STRING (con los datos o el URI a un objeto externo)
|
Las cadenas JSON pequeñas (de menos de 2.621.440 caracteres) se pueden almacenar como STRING. Te recomendamos que utilices otros servicios de Google Cloud, como Cloud Storage, para almacenar objetos más grandes. |
GEOMETRY, POINT, LINESTRING, POLYGON, MULTIPOINT, MULTIPOLYGON y GEOMETRYCOLLECTION |
Spanner no admite tipos de datos geoespaciales. Debes almacenar estos datos utilizando tipos de datos estándar e implementar cualquier lógica de búsqueda o filtrado en la capa de la aplicación. |
Proceso de migración
Una cronología general del proceso de migración sería la siguiente:
- Convierte el esquema y el modelo de datos.
- Traduce cualquier consulta de SQL.
- Migra tu aplicación para que use Spanner además de MySQL.
- Exporta datos en bloque de MySQL e impórtalos en Spanner mediante Dataflow.
- Mantén la coherencia entre ambas bases de datos durante la migración.
- Migra tu aplicación desde MySQL.
Convertir la base de datos y el esquema
Convierte el esquema que ya tienes en un esquema de Spanner para almacenar tus datos. Para facilitar las modificaciones de las aplicaciones, asegúrate de que el esquema convertido coincida con el esquema MySQL de la forma más precisa posible. Sin embargo, debido a las diferencias en las funciones, puede que sea necesario hacer algunos cambios.
Al seguir las prácticas recomendadas en el diseño de esquemas, podrás aumentar el rendimiento y reducir los puntos activos de tu base de datos de Spanner.
Claves principales
Todas las tablas que deban almacenar más de una fila deben tener una clave principal que conste de una o más columnas de la tabla. La clave principal de la tabla identifica de forma unívoca cada fila de una tabla y, dado que las filas de la tabla están ordenadas por clave principal, la tabla en sí como índice principal.
Lo mejor es no designar columnas que aumenten o disminuyan de forma monótona como la primera parte de la clave principal (ejemplos incluyen secuencias o marcas de tiempo), ya que pueden provocar puntos calientes provocados por inserciones que se envíen al final de {101 }tu espacio de claves. Un punto de actividad es la concentración de operaciones en un solo nodo, lo que reduce el rendimiento de escritura a la capacidad del nodo en lugar de beneficiarse del balanceo de carga, todas las escrituras entre los nodos del Nosotros.
Usa las siguientes técnicas para generar valores de claves principales únicos y reducir el riesgo de puntos de actividad:
- Cambiar el orden de las claves para que la columna que contiene el valor de forma monótona creciente o decreciente no sea la primera parte clave.
- Cifrar la clave única y distribuir las escrituras en fragmentos lógicos. Para ello, crea una columna que contenga el hash de la clave única y, a continuación, utiliza la columna de hash (o la columna de hash y el juntas) como clave principal. De este modo, se evitan los puntos de actividad porque las filas nuevas se distribuyen de manera más uniforme en el espacio clave.
- Utiliza un identificador único universal (UUID), tal como se define en RFC 41122 como clave principal. Recomendamos el uso de la versión 4 de UUID, ya que utiliza valores aleatorios en la secuencia de bits.
- Valores secuenciales de doble byte para distribuir bits de orden alto de números posteriores aproximadamente igual que el espacio entero.
Tras designar la clave principal de la tabla, no podrás cambiarla después sin eliminarla ni volver a crearla. Para obtener más información sobre cómo diseñar tu clave principal, consulta el artículo sobre el esquema y el modelo de datos de las claves principales.
A continuación se muestra un ejemplo de declaración DDL para crear una tabla de base de datos de pistas musicales:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE,
) PRIMARY KEY(SingerId);
Intercalar tablas
Spanner dispone de una función que permite definir dos tablas como una relación de tipo principal y secundaria. Esta función intercala las filas de datos secundarios junto a la fila superior del almacenamiento, estableciendo previamente la tabla previamente y mejora la eficiencia de la recuperación de datos cuando se consultan ambos elementos.
La clave principal de la tabla secundaria debe empezar por las columnas de la clave principal de la tabla superior. Desde la perspectiva de la fila secundaria, la clave principal de la fila superior se denomina clave externa. Puede definir hasta 6 niveles de relaciones de elementos superiores y secundarios.
Puedes definir acciones en eliminación en tablas secundarias para determinar qué ocurre cuando se elimina la fila superior: se eliminan todas las filas secundarias o se elimina la fila superior. bloqueadas mientras hay filas secundarias.
Este es un ejemplo de cómo crear una tabla Albums intercalada en la tabla superior Singers definida anteriormente:
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
Crear índices secundarios
También puedes crear índices secundarios para indexar datos dentro de la tabla fuera de la clave principal. Spanner implementa índices secundarios de la misma manera que las tablas, por lo que los valores de columna que se usen como claves de índice tendrán las mismas restricciones que las claves principales de las tablas. Esto significa que los índices tienen las mismas garantías de coherencia que las tablas de Spanner.
Las búsquedas de valores mediante índices secundarios son efectivamente igual que una consulta con una combinación de tabla. Puedes mejorar el rendimiento de las consultas con los índices si copias los valores de columna de la tabla original en el índice secundario con la cláusula STORING, lo que la convierte en un índice de cubierta en tu teléfono Android.
El optimizador de consultas de Spanner solo utiliza un índice secundario de forma automática cuando el índice almacena todas las columnas que se están consultando (una consulta cubierta). Para forzar el uso de un índice al consultar columnas en la tabla original, debes usar una directiva FORCE INDEX en la declaración SQL, por ejemplo:
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
Los índices se pueden usar para aplicar valores únicos en una columna de tabla, definiendo un índice UNIQUE en esa columna. El índice impedirá que se añadan valores duplicados.
A continuación se incluye una declaración de DDL de ejemplo para crear un índice secundario para la tabla Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Si creas más índices después de cargar los datos, puede que el proceso tarde un poco. Te recomendamos que limites la frecuencia a la que los añadas a una media de tres al día. Más información sobre cómo crear índices secundarios Para obtener más información sobre las limitaciones de la creación de índices, consulta la página sobre actualizaciones de esquemas.
Traducir consultas de SQL
Spanner utiliza el dialecto ANSI de 2011 con extensiones y dispone de muchas funciones y operadores para traducir y agregar datos. en tu teléfono Android. Las consultas SQL que usen un dictado, una función y un tipo específicos de MySQL deben convertirse para ser compatibles con Spanner.
Aunque Spanner no admite datos estructurados como definiciones de columna, puedes utilizarlos en consultas SQL mediante los tipos ARRAY<> y STRUCT<>. Por ejemplo, puedes escribir una consulta que devuelva todos los álbumes de un artista usando ARRAY de STRUCT (siendo los datos preunidos). Para obtener más información, consulta la sección Subconsultas de la documentación.
Se pueden crear consultas de SQL con la interfaz de consulta de Spanner en la consola de Cloud para ejecutarlas. En general, las consultas que realizan análisis completos de tablas en tablas grandes son muy caras y se deben utilizar de manera comparativa. Para obtener más información sobre la optimización de las consultas SQL, consulta la documentación de prácticas recomendadas de SQL.
Migra tu aplicación para usar Spanner
Spanner proporciona un conjunto deBibliotecas de cliente para varios idiomas, así como la capacidad de leer y escribir datos con las llamadas de la API específicas de Spanner, así como el uso deConsultas SQL y Lenguaje de modificación de datos (DML). Es posible que el uso de llamadas a la API sea más rápido en el caso de algunas consultas, como la presencia directa de filas por clave, ya que no es necesario traducir la declaración SQL.
También puedes usar el controlador de conectividad de bases de datos (JDBC) de Java para conectarte a Spanner mediante las herramientas y la infraestructura de las que no dispones de integración nativa.
Como parte del proceso de migración, las funciones que no están disponibles en Spanner deben implementarse en la aplicación. Por ejemplo, un activador para verificar los valores de los datos y actualizar una tabla relacionada se debe implementar en la aplicación mediante una transacción de lectura y escritura para leer la fila disponible, verificar la restricción y, a continuación, escribir la filas actualizadas en ambas tablas.
Spanner ofrece transacciones de lectura y escritura y de solo lectura, lo que garantiza la coherencia externa de los datos. Además, se pueden aplicar límites de marca de tiempo a las transacciones de lectura, que es donde se lee una versión coherente de los datos:
- a la hora exacta del pasado (hace hasta una hora).
- en el futuro (donde la lectura se bloqueará hasta esa fecha).
- con una cantidad de tiempo limitado, que devuelve una vista coherente hasta un momento en el pasado sin que sea necesario comprobar que los datos posteriores estén disponibles en otra réplica. lo que puede dar lugar a beneficios de rendimiento y, a su vez, puede perder datos.
Transferir los datos de MySQL a Spanner
Para transferir tus datos de MySQL a Spanner, debes exportar tu base de datos de MySQL a un formato de archivo portátil (por ejemplo, XML) y luego importar esos datos a Spanner con Dataflow.
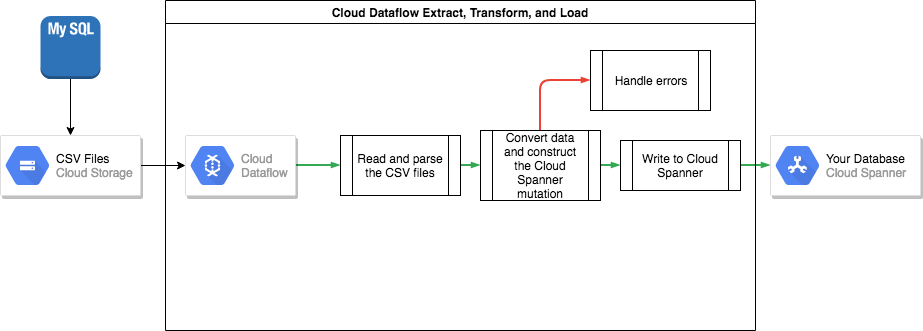
Exportar datos en bloque desde MySQL
La herramienta mysqldump incluida con MySQL puede exportar toda la base de datos a archivos XML bien formados.
También puedes usar la instrucción SQL SELECT ... INTO OUTFILE para crear archivos CSV para cada tabla. Sin embargo, este enfoque tiene la desventaja de que solo se puede exportar una tabla a la vez, lo que significa que debes pausar tu aplicación o extraer la base de datos para que la base de datos siga en un estado coherente. Exportar.
Después de exportar estos archivos de datos, se recomienda subirlos a un segmento de Cloud Storage para que se puedan importar.
Importación en bloque en Spanner
Como los esquemas de bases de datos probablemente difieren entre MySQL y Spanner, es posible que debas convertir algunas conversiones de datos en el proceso de importación. La forma más sencilla de hacer estas conversiones de datos e importarlos a Spanner es mediante Dataflow. Dataflow es el servicio de extracción, transformación y carga distribuida (ETL) de Google Cloud. Ofrece una plataforma para ejecutar flujos de procesamiento de datos escritos con el SDK de Apache Beam para leer y procesar grandes cantidades de datos en paralelo en varias máquinas.
El SDK de Apache Beam requiere que crees un sencillo programa Java para configurar las operaciones de lectura, transformación y escritura. Existen conectores de Beam para Cloud Storage y Spanner, por lo que el único código que debes escribir es el de transformación de datos.
Para obtener un ejemplo de un flujo de procesamiento sencillo que leer desde archivos CSV y escribir en Spanner, consulta el repositorio de código de ejemplo.
Si utilizas tablas intercaladas de elementos superiores en el esquema de Spanner, ten cuidado en el proceso de importación que la fila superior se crea antes de la fila secundaria. El código del flujo de procesamiento de importación de Spanner procesa esta función importando primero los datos de las tablas de nivel raíz y, a continuación, todas las tablas secundarias de nivel 1 y, a continuación, las tablas secundarias de nivel 2, y así sucesivamente.
Puedes utilizar el flujo de procesamiento de importación de Spanner directamente para importar datos en bloque, pero este método requiere que los datos existan en los archivos Avro mediante el esquema correcto.
Mantener la coherencia entre ambas bases de datos
Muchas aplicaciones tienen requisitos de disponibilidad, por lo que es imposible mantener la aplicación offline durante el tiempo necesario para exportar e importar los datos. Por tanto, mientras transfieres tus datos a Spanner, la aplicación sigue modificando la base de datos actual. Por lo tanto, es necesario duplicar las actualizaciones en la base de datos de Spanner mientras se ejecuta la aplicación.
Hay varios métodos para mantener tus dos bases de datos sincronizadas, como cambiar la captura de datos e implementar actualizaciones simultáneas en la aplicación.
Cambiar captura de datos
MySQL no tiene una utilidad nativa de captura de datos (CDC). Sin embargo, hay varios proyectos de código abierto que pueden recibir binlogs de MySQL y convertirlos en un CDC. Por ejemplo, el daemon de Maxwell puede ofrecer una emisión de CDC para tu base de datos.
Puedes escribir en la aplicación una aplicación que se suscriba a este flujo y aplique las mismas modificaciones (después de la conversión de datos, por supuesto) a tu base de datos de Spanner.
Actualizaciones simultáneas a ambas bases de datos desde la aplicación
Un método alternativo consiste en modificar tu aplicación para realizar escrituras en ambas bases de datos. Una base de datos (inicialmente MySQL) se consideraría la fuente de un thof y, después de cada escritura de base de datos, toda la fila se lee, se convierte y se escribe en la base de datos de Spanner. De esta manera, la aplicación sobrescribe las filas de Spanner de forma constante con los datos más recientes.
Cuando tengas la certeza de que todos tus datos se han transferido correctamente, puedes cambiar la fuente de veracidad a la base de datos de Spanner. Este mecanismo permite proporcionar una ruta de restauración si se detectan problemas al cambiar a Spanner.
Verificar la coherencia de los datos
A medida que los flujos de datos se integran en la base de datos de Spanner, puedes ejecutar periódicamente una comparación entre los datos de dicho servicio y los datos de MySQL para asegurarte de que son coherentes. Para validar la coherencia, consulta las dos fuentes de datos y compara los resultados.
También puedes usar Dataflow para hacer una comparación detallada en grandes conjuntos de datos con la transformación de unión. Esta transformación toma dos conjuntos de datos clave y relaciona los valores por clave. Los valores que se comparan se pueden comparar por igualdad. Puedes llevar a cabo esta verificación periódicamente hasta que el nivel de coherencia coincida con los requisitos de tu empresa.
Cambia a Spanner como la fuente de la información original
Cuando confíes en la migración de datos, puedes cambiar la aplicación para que use Spanner como la fuente de datos reales. Si sigues escribiendo cambios en la base de datos MySQL, la base de datos MySQL se mantiene actualizada y, si surge algún problema, se consigue una ruta de restauración.
Por último, puedes inhabilitar y eliminar el código de actualización de la base de datos MySQL y desactivar la base de datos MySQL obsoleta.
Exportar e importar bases de datos de Spanner
Si quieres, puedes exportar tus tablas de Spanner a un segmento de Cloud Storage mediante una plantilla de Dataflow. La carpeta resultante contiene un conjunto de archivos Avro y archivos de manifiesto JSON que contienen las tablas exportadas. Estos archivos pueden servir para varios fines, entre los que se incluyen los siguientes:
- Crear una copia de seguridad de la base de datos para cumplir con las políticas de retención de datos o recuperación tras fallos.
- Importar el archivo Avro en otras ofertas de Google Cloud como BigQuery.
Para obtener más información sobre el proceso de exportación e importación, consulta los artículos Exportar bases de datos e Importar bases de datos.
Siguientes pasos
- Infórmate sobre cómo optimizar tu esquema de Spanner.
- Descubre cómo usar Dataflow en situaciones más complejas.
- Aprende a elegir el mejor servicio de almacenamiento en Google Cloud para tu aplicación.
- Consulta otras guías prácticas de Spanner.
- Explora arquitecturas de referencia, diagramas, tutoriales y prácticas recomendadas sobre Google Cloud. Echa un vistazo a Cloud Architecture.