Las tecnologías de almacenamiento de Google impulsan algunas de las aplicaciones más grandes del mundo. Sin embargo, el escalamiento no siempre es un resultado automático del uso de estos sistemas. Los diseñadores deben pensar con cuidado en cómo modelar sus datos para asegurarse de que su aplicación pueda escalar y funcionar a medida que crece en varias dimensiones.
Spanner es una base de datos distribuida, y para usarla de manera eficaz es necesario pensar de manera diferente en el diseño del esquema y los patrones de acceso que con las bases de datos tradicionales. Por naturaleza, los sistemas distribuidos obligan a los diseñadores a pensar en los datos y en la localidad del procesamiento.
Spanner admite consultas y transacciones de SQL con la capacidad de escalar horizontalmente. A menudo, se necesita un diseño cuidadoso para obtener todos los beneficios de Spanner. En este documento, se analizan algunas de las ideas clave que te ayudarán a garantizar que tu aplicación pueda escalar a niveles arbitrarios y maximizar su rendimiento. Dos herramientas en particular tienen un gran impacto en la escalabilidad: intercalación y definición de claves.
Diseño de la tabla
Las filas de una tabla de Spanner se organizan de manera lexicográfica por PRIMARY
KEY. En teoría, las claves se ordenan según la concatenación de las columnas en el orden en que se declaran en la cláusula PRIMARY KEY. Aquí se muestran todas las propiedades estándar de la localidad:
- El análisis de la tabla en orden lexicográfico es eficiente.
- Las filas que estén lo suficientemente cerca se almacenarán en los mismos bloques de disco y se leerán y almacenarán en caché.
Spanner replica tus datos en varias zonas para determinar su disponibilidad y escalamiento. Cada zona contiene una réplica completa de tus datos. Cuando aprovisionas un nodo de instancia de Spanner, debes especificar su capacidad de procesamiento. La capacidad de procesamiento es la cantidad de recursos de procesamiento asignados a tu instancia en cada una de estas zonas. Si bien cada réplica es un conjunto completo de tus datos, los datos dentro de una réplica se dividen entre los recursos de procesamiento de esa zona.
Los datos dentro de cada réplica de Spanner se organizan en dos niveles de jerarquía física: divisiones de base de datos y, luego, bloques. Las divisiones contienen rangos contiguos de filas y son la unidad que usa Spanner para distribuir tu base de datos entre los recursos de procesamiento. Con el tiempo, las divisiones se separan en partes más pequeñas, se combinan o se mueven a otros nodos en tu instancia para aumentar el paralelismo y permitir que tu aplicación escale. Las operaciones que abarcan divisiones son más costosas que las operaciones equivalentes que no lo hacen, debido al aumento de la comunicación. Esto es así incluso si el mismo nodo entrega esas divisiones.
Existen dos tipos de tablas en Spanner: tablas raíz (a veces denominadas tablas de nivel superior) y tablas intercaladas. Las tablas intercaladas se definen con la especificación de otra tabla como su superior, lo que provoca que las filas de la tabla intercalada se agrupen con la fila superior. Las tablas raíz no tienen un superior, y cada fila de una tabla raíz define una nueva fila de nivel superior o fila raíz. Las filas intercaladas con esta fila raíz se llaman filas secundarias, y la colección de una fila raíz más todos sus descendientes se denomina árbol de filas. Debe existir una fila superior para que puedas insertar filas secundarias. La fila superior puede ya existir en la base de datos o puede insertarse antes de la inserción de las filas secundarias en la misma transacción.
Spanner divide particiones de manera automática cuando lo considera necesario debido al tamaño o la carga. Para preservar la localidad de los datos, Spanner prefiere agregar límites de división lo más cerca posible de las tablas raíz, de modo que cualquier árbol de filas determinado se pueda mantener en una sola división. Esto significa que las operaciones dentro de un árbol de filas tienden a ser más eficientes porque es poco probable que requieran comunicación con otras divisiones.
Sin embargo, si hay un hotspot en una fila secundaria, Spanner intentará agregar límites de división a las tablas intercaladas para aislar esa fila del hotspot, junto con todas las filas secundarias debajo de ella.
Elegir qué tablas deben ser raíces es una decisión importante para diseñar tu aplicación con el fin de que escale. Las raíces suelen ser Usuarios, Cuentas, Proyectos y similares, y sus tablas secundarias contienen la mayoría de los demás datos sobre la entidad en cuestión.
Recomendaciones:
- Usa un prefijo de clave común para las filas relacionadas en la misma tabla con el fin de mejorar la localidad.
- Intercala datos relacionados en otra tabla cuando tenga sentido.
Compensaciones de la localidad
Si los datos se escriben o se leen con frecuencia, eso puede beneficiar tanto la latencia como la capacidad de procesamiento para agruparlos mediante la selección cuidadosa de las claves primarias y el intercalado. Esto se debe a que existe un costo fijo para comunicarse con cualquier servidor o bloque de disco, así que ¿por qué no aprovechar todos los beneficios posibles? Además, a medida que te comuniques con más servidores, mayor será la probabilidad de que encuentres un servidor ocupado temporalmente, lo que aumentará la latencia de cola. Por último, las transacciones que abarcan divisiones, aunque son automáticas y transparentes en Spanner, tienen un costo de CPU y una latencia ligeramente más altos debido a la naturaleza distribuida de la confirmación en dos fases.
Por otro lado, si los datos están relacionados, pero no se accede a ellos con frecuencia, considera hacer un esfuerzo por separarlos. Esto tiene el mayor beneficio cuando los datos a los que se accede con poca frecuencia son grandes. Por ejemplo, muchas bases de datos almacenan grandes datos binarios fuera de banda de los datos de fila primarios, con referencias solo a los datos intercalados de gran tamaño.
Ten en cuenta que es inevitable que exista algún nivel de confirmación de dos fases y operaciones de datos no locales en una base de datos distribuida. No te preocupes demasiado por obtener una historia de localidad perfecta para cada operación. Enfócate en obtener la localidad deseada para las entidades raíz más importantes y los patrones de acceso más comunes, y permite que se realicen operaciones distribuidas sensibles al rendimiento o menos frecuentes cuando sea necesario. La confirmación en dos fases y las lecturas distribuidas ayudan a simplificar los esquemas y facilitar el trabajo del programador: en todos los casos prácticos, excepto en los críticos, es mejor permitirlas.
Recomendaciones:
- Organiza tus datos en jerarquías de modo que los datos leídos o escritos juntos estén cerca.
- Considera almacenar columnas grandes en tablas no intercaladas si se accede a ellas con menos frecuencia.
Opciones de índice
Los índices secundarios te permiten buscar filas con rapidez según valores distintos de la clave primaria. Spanner admite índices intercalados y no intercalados. Los índices no intercalados son los predeterminados y el tipo más analógico a lo que se admite en un RDBMS tradicional. No aplican ninguna restricción sobre las columnas que se indexan y, si bien son potentes, no siempre son la mejor opción. Los índices intercalados se deben definir en columnas que comparten un prefijo con la tabla superior y permiten un mayor control de la localidad.
Spanner almacena los datos de índice de la misma manera que las tablas, con una fila por cada entrada de índice. Muchas de las consideraciones de diseño de las tablas también se aplican a los índices. Los índices no intercalados almacenan datos en tablas raíz. Debido a que las tablas raíz se pueden dividir entre cualquier fila raíz, esto garantiza que los índices no intercalados puedan escalar a un tamaño arbitrario y, también, ignorar los puntos clave para casi cualquier carga de trabajo. Lamentablemente, también significa que las entradas del índice no suelen tener las mismas divisiones que los datos principales. Esto crea trabajo adicional y latencia para cualquier proceso de escritura, y agrega divisiones adicionales con el fin de consultar en el momento de la lectura.
Por el contrario, los índices intercalados almacenan datos en tablas intercaladas. Son adecuadas cuando buscas dentro del dominio de una sola entidad. Los índices intercalados obligan a los datos y las entradas de índice a permanecer en el mismo árbol de filas, lo que hace que las uniones entre ellos sean mucho más eficaces. Ejemplos de usos de un índice intercalado:
- Acceder a tus fotos por varios órdenes de clasificación, como fecha de publicación, fecha de la última modificación, título, álbum, etcétera
- Encontrar todas las publicaciones que tienen un conjunto específico de etiquetas
- Encontrar mis pedidos de compras anteriores que contenían un artículo específico
Recomendaciones:
- Usa índices no intercalados cuando necesites encontrar filas desde cualquier parte de tu base de datos.
- Prefiere los índices intercalados cada vez que tus búsquedas tengan el alcance de una sola entidad.
Cláusula de índice STORING
Los índices secundarios te permiten buscar filas por atributos que no sean la clave primaria. Si todos los datos solicitados se encuentran en el índice, se pueden consultar por sí solos sin necesidad de leer el registro principal. Esto puede ahorrar recursos importantes, ya que no es necesario realizar ninguna unión.
Lamentablemente, las claves de índice están limitadas a 16 en número y 8 KiB en tamaño agregado, lo que restringe lo que se puede colocar en ellas. Para compensar estas limitaciones, Spanner tiene la capacidad de almacenar datos adicionales en cualquier índice mediante la cláusula STORING. STORING una columna en un índice da como resultado la duplicación de sus valores, y se almacena una copia en el índice. Puedes pensar en un índice con STORING como una vista materializada de una sola tabla simple (en este momento, las vistas no se admiten de forma nativa en Spanner).
Otra aplicación útil de STORING es como parte de un índice NULL_FILTERED.
Esto te permite definir qué es efectivamente una vista materializada de un subconjunto disperso de una tabla que puedes escanear de manera eficiente. Por ejemplo, puedes crear un índice en la columna is_unread de un buzón para poder mostrar la vista de mensajes no leídos en un solo análisis de tabla, pero sin pagar una copia completa de cada buzón.
Recomendaciones:
- Haz un uso prudente de
STORINGpara compensar el rendimiento del tiempo de lectura con el tamaño de almacenamiento y el rendimiento del tiempo de escritura. - Usa
NULL_FILTEREDpara controlar los costos de almacenamiento de los índices dispersos.
Antipatrones
Antipatrón: orden de la marca de tiempo
Muchos diseñadores de esquemas tienden a definir una tabla raíz que se ordena por marca de tiempo y se actualiza cada vez que se escribe en ella. Lamentablemente, esta es una de las tareas menos escalables que puedes hacer. El motivo es que este diseño genera un enorme punto de actividad al final de la tabla que no se puede mitigar con facilidad. A medida que aumentan las tasas de escritura, también lo hacen las RPC en una sola división, al igual que los eventos de contención de bloqueo y otros problemas. A menudo, este tipo de problemas no aparecen en pruebas de carga pequeñas y, en su lugar, aparecen después de que la aplicación ha estado en producción durante algún tiempo. Para entonces, ya es demasiado tarde.
Si tu aplicación debe incluir un registro ordenado por marca de tiempo, considera si la posibilidad de convertir el registro en local. Para ello, puedes intercalarlo en una de tus otras tablas raíz. Esto tiene el beneficio de distribuir el punto de actividad entre muchas raíces. Sin embargo, debes tener cuidado de que cada raíz distinta tenga una tasa de escritura lo suficientemente baja.
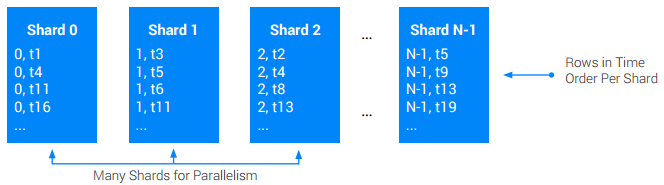
Si necesitas una tabla ordenada por marca de tiempo global (raíz cruzada) y necesitas admitir tasas de escritura más altas que las permitidas por un nodo único, usa fragmentación a nivel de la aplicación. Fragmentar una tabla significa dividirla en una cantidad N de divisiones aproximadamente iguales llamadas Shards. Por lo general, esto se hace agregando un prefijo en la clave primaria original con una columna ShardId adicional que contiene valores de números enteros entre [0, N). La ShardId para una escritura determinada suele seleccionarse de forma aleatoria o mediante la codificación hash de una parte de la clave base. Por lo general, se prefiere usar hash, ya que se puede usar para garantizar que todos los registros de un tipo determinado entren al mismo Shard, lo que mejora el rendimiento de la recuperación. En cualquier caso, el objetivo es garantizar que, con el tiempo, las escrituras se distribuyan en todos los Shards por igual.
Este enfoque a veces significa que las lecturas deben analizar todos los Shards para reconstruir el orden total original de las escrituras.
Recomendaciones:
- Evita índices y tablas ordenados por marca de tiempo de alta tasa de escritura a toda costa.
- Usa alguna técnica para extender puntos de actividad, ya sea con intercalado en otra tabla o con fragmentación.
Antipatrón: secuencias
A los desarrolladores de aplicaciones les encanta usar secuencias de bases de datos (o autoincremento) para generar claves primarias. Desafortunadamente, este hábito de los días de RDBMS (llamados claves sustitutas) es casi tan dañino como el antipatrón de orden por marca de tiempo descrito antes. El motivo es que las secuencias de bases de datos tienden a emitir valores de manera casi monótona, a lo largo del tiempo, para producir valores que se agrupan cerca unos de otros. Normalmente, esto produce puntos de actividad cuando se usan como claves primarias, especialmente para las filas raíz.
Al contrario de la sabiduría convencional de RDBMS, te recomendamos que uses atributos del mundo real para las claves primarias cuando tenga sentido. Este es particularmente el caso si el atributo nunca va a cambiar.
Si deseas generar claves primarias únicas numéricas, intenta que los bits de orden superior de los números subsiguientes se distribuyan aproximadamente igual en todo el espacio numérico. Un truco consiste en generar números secuenciales con medios convencionales y, luego, revertir los bits para obtener un valor final. Como alternativa, puedes buscar en un generador UUID, pero ten cuidado: no todas las funciones UUID se crean de la misma manera y algunas almacenan la marca de tiempo en bits de orden superior, lo que elimina por completo el beneficio. Asegúrate de que el generador de UUID seleccione bits de orden superior de manera pseudoaleatoria.
Recomendaciones:
- Evita usar valores de secuencia incrementales como claves primarias. En cambio, revierte los bits de un valor de secuencia o usa un UUID cuidadosamente seleccionado.
- Usa valores del mundo real para las claves primarias en lugar de las claves sustitutas.