本頁內容適用於 Apigee 和 Apigee Hybrid。
查看
Apigee Edge 說明文件。

什麼是異常狀況?
異常狀況是指非比尋常或出乎意料的 API 資料模式。舉例來說,請參閱下方的 API 錯誤率圖表:
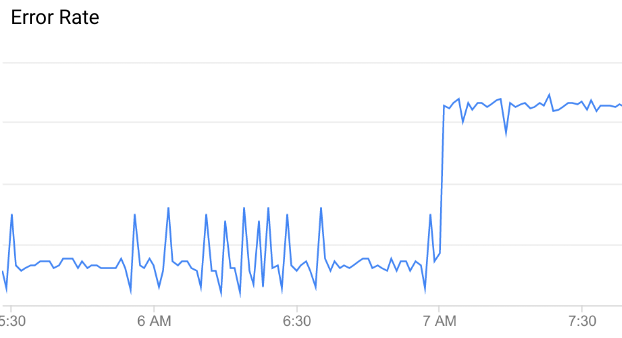
如您所見,錯誤率在早上 7 點左右突然大幅上升。與該時間之前的資料相比,這項增幅異常,因此可歸類為異常。
不過,API 資料中的所有變化都不代表異常,大多數只是隨機波動。舉例來說,您可能會發現異常狀況發生前,錯誤率出現一些相對較小的變化,但這些變化不夠顯著,因此不能稱為真正的異常狀況。
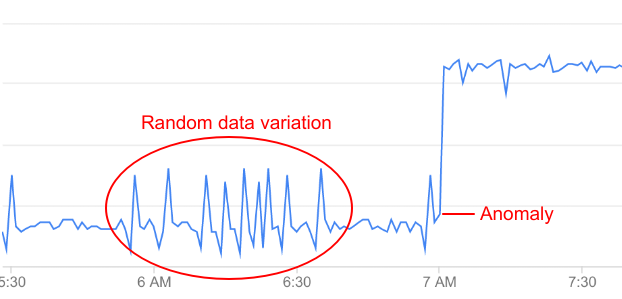
API Ops 會持續監控 API 資料並執行統計分析,從資料中的隨機波動區分出真正的異常狀況。
如果不使用異常偵測功能,您必須自行選擇偵測每項異常狀況的門檻。(門檻是數量值,例如錯誤率,必須達到這個值才會觸發異常狀況)。此外,您也需要根據最新資料更新門檻值。 相較之下,AAPI-Ops 會根據近期資料模式,為您選擇最佳異常狀況門檻。
當 AAPI 偵測到上述異常狀況時,會將異常狀況詳細資料顯示在異常事件資訊主頁中。 此時,您可以在 API 監控資訊主頁中調查異常狀況,並視需要採取適當行動。您也可以建立快訊,在日後發生類似事件時收到通知。
偵測到的異常狀況包含下列資訊:
- 導致異常的指標,例如 Proxy 延遲或 HTTP 錯誤代碼。
- 異常狀況的嚴重程度。嚴重程度可能為輕微、中等或嚴重,具體情況取決於模型的可信度。如果信心水準較低,代表嚴重程度較輕微;如果信心水準較高,代表嚴重程度較嚴重。
異常狀況類型
Apigee 會自動偵測下列類型的異常狀況:
- 機構、環境和區域層級的 HTTP 503 錯誤增加
- 機構、環境和區域層級的 HTTP 504 錯誤增加
- 機構、環境和區域層級的所有 HTTP 4xx 或 5xx 錯誤增加
- 機構、環境和區域層級的第 90 百分位數 (p90) 回應延遲總時間增加
異常偵測功能的運作方式
異常偵測包含下列階段:
訓練模型
異常偵測功能會使用歷來時間序列資料,訓練 API Proxy 行為模型。您無須採取任何行動來訓練模型。Apigee 會自動根據前六小時的 API 資料建立及訓練模型。因此,Apigee 必須先取得 API Proxy 至少六小時的資料,才能訓練模型並記錄異常狀況。
訓練的目的是提高模型準確度,然後以歷來資料測試模型。如要測試模型準確率,最簡單的方法是計算錯誤率,也就是將正向誤判和負向誤判加總,然後除以預測事件總數。
記錄異常事件
在執行階段,Apigee 異常偵測功能會比較 API Proxy 的目前行為與模型預測的行為。異常偵測功能隨後會以特定信賴水準,判斷作業指標何時會超出預測值。舉例來說,當 5xx 錯誤率超過模型預測的錯誤率時。
Apigee 偵測到異常狀況時,會自動將事件記錄在「異常事件」資訊主頁中。資訊主頁顯示的事件清單包含所有偵測到的異常狀況,以及觸發的快訊。