本页面适用于 Apigee 和 Apigee Hybrid。
查看 Apigee Edge 文档。

什么是异常值?
异常值是一种异常或意外的 API 数据模式。例如,请看下面的 API 错误率图表:
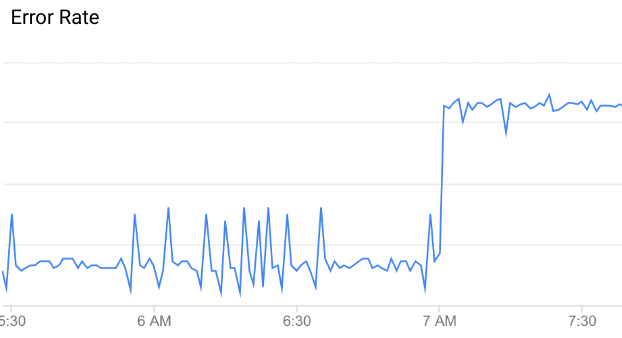
如图所示,错误率在上午 7 点左右突然升高。与该时间之前的数据相比,这一增长幅度足以归类为异常值。
但是,并非 API 数据的所有变化都表示异常值,大多数变化仅仅是随机波动。例如,您可以看到导致异常值的错误率存在一些相对较小的变化,但这些变化并不够显著,不足以称为真正的异常值。
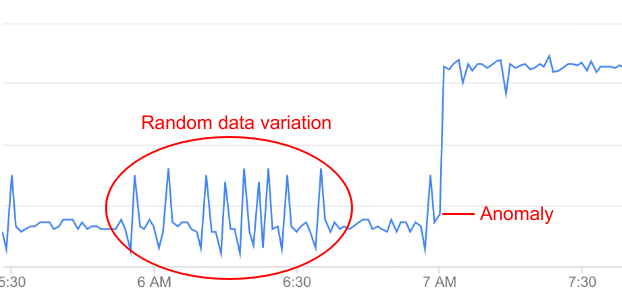
AAPI Ops 会持续监控 API 数据并执行统计分析,以区分真正的异常值和数据的随机波动。
如果没有异常值检测,您需要选择一个阈值以自行检测每个异常值。(阈值是触发异常值时某个数量(例如错误率)必须达到的值。)您还需要根据最新数据使阈值保持最新。相比之下,AAPI-Ops 会根据最近的数据模式为您选择最佳异常值阈值。
当 AAPI 检测到如上所示的异常值时,会在异常值事件信息中心中显示异常值的详细信息。此时,您可以在 API Monitoring 信息中心中调查异常值,并根据需要采取适当的措施。您还可以创建提醒,以便在今后发生类似事件时收到通知。
检测到的异常值包括以下信息:
- 导致异常值的指标,例如代理延迟时间或 HTTP 错误代码。
- 异常值的严重程度。根据模型中的置信度,严重程度可以是轻微、中等或严重。较低的置信度表示严重程度轻微,而较高的置信度则表示严重。
异常值类型
Apigee 会自动检测以下类型的异常值:
- 组织、环境和区域级别的 HTTP 503 错误增加
- 组织、环境和区域级别的 HTTP 504 错误增加
- 组织、环境和区域层级的所有 HTTP 4xx 或 5xx 错误增加
- 组织、环境和区域级的第 90 百分位 (p90) 的总响应延迟时间增加
异常值检测的工作原理
异常检测涉及以下阶段:
训练模型
异常值检测的工作原理是训练 API 代理根据历史时间序列数据的行为而构建的模型。您无需执行任何操作即可训练模型。Apigee 会根据过去六个小时的 API 数据自动为您创建并训练模型。因此,Apigee 要求至少有 6 个小时的 API 代理数据来训练模型,然后才能记录异常值。
训练的目标是提高模型的准确性,然后使用历史数据对模型进行测试。测试模型准确率的最简单方法是计算其错误率,即假正例和假负例的总和除以预测事件总数。
记录异常值事件
在运行时,Apigee 异常值检测功能会将 API 代理的当前行为与模型预测的行为进行比较。然后,在特定的置信度下,异常值检测可以确定操作指标超出预测值的情况。例如,当 5xx 错误率超过模型预测的概率。
如果 Apigee 检测到异常值,它会自动在异常值事件信息中心中记录该事件。信息中心中显示的事件列表包括所有检测到的异常值以及触发的提醒。