이 문서에서는 Dataproc으로 Apache Spark 작업을 마이그레이션하는 방법을 설명합니다. 이 문서는 빅데이터 엔지니어와 설계자를 위해 마련되었으며 마이그레이션 관련 고려사항, 준비, 작업 마이그레이션, 관리와 같은 주제를 다룹니다.
개요
온프레미스 환경에서 Google Cloud로 Apache Spark 워크로드를 이동하려면 Dataproc을 사용하여 Apache Spark/Apache Hadoop 클러스터를 실행하는 것이 좋습니다. Dataproc은 Google Cloud가 제공하는 완전 관리형, 완전 지원형 서비스입니다. 스토리지를 분리하고 컴퓨팅을 수행하여 비용을 관리하고 워크로드를 유연하게 확장하는 데 도움이 됩니다.
관리형 Hadoop 환경이 사용자의 요구사항에 부합하지 않을 경우 Google Kubernetes Engine(GKE)에서 Spark를 실행하거나 Compute Engine에서 가상 머신을 대여하여 직접 Hadoop 또는 Spark 클러스터를 실행할 수도 있습니다. 그러나 Dataproc 사용 이외의 옵션은 자체 관리형이며 커뮤니티만 지원한다는 점을 고려하세요.
마이그레이션 계획
온프레미스로 Spark 작업을 실행하는 것과 Compute Engine에서 Dataproc 또는 Hadoop 클러스터로 Spark 작업을 실행하는 것에는 많은 차이가 있습니다. 워크로드를 주의 깊게 살펴보고 마이그레이션을 준비하는 것이 중요합니다. 이 섹션에서는 Spark 작업을 마이그레이션하기 전에 고려해야 할 사항과 준비해야 할 사항에 대해 설명합니다.
작업 유형 식별 및 클러스터 계획
이 섹션에서 설명된 대로 3가지 유형의 Spark 작업 부하가 있습니다.
정기적으로 예약된 일괄 작업
정기적으로 예약된 일괄 작업에는 일일 또는 시간별 ETL과 같은 사용 사례 또는 Spark ML을 사용한 머신러닝 학습을 위한 파이프라인이 포함됩니다. 이 경우 각 일괄 워크로드의 클러스터를 만든 다음 작업이 완료된 후 클러스터를 삭제하는 것이 좋습니다. 각 워크로드의 구성을 개별적으로 조정할 수 있으므로 클러스터를 유연하게 구성할 수 있습니다. Dataproc 클러스터 비용은 처음 1분이 지난 후 1초 단위로 청구되기 때문에 비용 효율적이며, 클러스터에 라벨을 지정할 수 있습니다. 자세한 내용은 Dataproc 가격 책정 페이지를 참조하세요.
워크플로 템플릿 또는 다음 단계를 따라 일괄 작업을 구현할 수 있습니다.
클러스터를 만들고 클러스터가 생성될 때까지 기다립니다. API 호출 또는 gcloud 명령어를 사용하여 클러스터가 생성되었는지 여부를 모니터링할 수 있습니다. 전용 Cloud Dataproc 클러스터에서 작업을 실행하는 경우 동적 할당 및 외부 셔플 서비스를 해제하는 것이 도움이 될 수 있습니다. 다음
gcloud명령어는 Dataproc 클러스터를 만들 때 제공되는 Spark 구성 속성을 보여줍니다.dataproc clusters create ... \ --properties 'spark:spark.dynamicAllocation.enabled=false,spark:spark.shuffle.service.enabled=false,spark.executor.instances=10000'클러스터에 작업을 제출합니다. API 호출 또는 gcloud 명령어를 사용하여 작업 상태를 모니터링할 수 있습니다. 예를 들면 다음과 같습니다.
jobId=$(gcloud --quiet dataproc jobs submit pyspark \ --async \ --format='value(reference.jobId)' \ --cluster $clusterName \ --region global \ gs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py) gcloud dataproc jobs describe $jobId \ --region=global \ --format='value(status.state)'작업이 실행된 후 API 호출 또는 gcloud 명령어를 사용하여 클러스터를 삭제합니다.
스트리밍 작업
스트리밍 작업의 경우 장기 실행 Dataproc 클러스터를 만들고 고가용성 모드에서 실행되도록 클러스터를 구성해야 합니다. 이 경우 선점형 VM을 사용하지 않는 것이 좋습니다.
사용자가 제출한 임시 또는 양방향 작업 부하
임시 워크로드의 예로는 낮에 쿼리를 작성하거나 분석 작업을 실행하는 사용자가 포함될 수 있습니다.
이 경우 고가용성 모드에서 클러스터를 실행해야 하는지 여부, 선점형 VM을 사용할지 여부, 클러스터 액세스를 관리하는 방법을 결정해야 합니다. 예를 들어 밤 또는 주말에 클러스터가 필요하지 않은 경우 클러스터 생성 및 종료를 예약할 수 있으며 일정에 따라 확장 또는 축소를 이행할 수 있습니다.
데이터 소스 및 종속 항목 식별
각 작업에는 작업에서 필요한 데이터 소스와 같은 고유한 종속 항목이 있으며 회사의 다른 팀이 사용자의 작업 결과에 영향을 받을 수 있습니다. 따라서 모든 종속 항목을 식별하고 다음을 위한 절차가 포함된 마이그레이션 계획을 세워야 합니다.
모든 데이터 소스를 Google Cloud에 단계별로 마이그레이션합니다. 처음에는 Google Cloud에 있는 데이터 소스를 미러링하여 두 장소에 데이터 소스를 보유하고 있는 것이 유용합니다.
해당 데이터 소스가 마이그레이션되는 즉시 Spark 워크로드를 Google Cloud에 작업별로 마이그레이션합니다. 데이터와 마찬가지로 어떤 시점에서는 두 개의 워크로드가 기존 환경과 Google Cloud에서 동시에 실행될 수 있습니다.
Spark 워크로드의 출력에 의존하는 다른 워크로드를 마이그레이션합니다. 또는 출력을 초기 환경으로 다시 복제할 수도 있습니다.
종속된 모든 팀에 더 이상 작업이 필요 없는지 확인한 다음 기존 환경의 Spark 작업을 종료합니다.
스토리지 옵션 선택
Dataproc 클러스터에서 사용할 수 있는 2가지 스토리지 옵션이 있습니다. 모든 데이터를 Cloud Storage에 저장하거나 클러스터 작업자를 통해 로컬 디스크 또는 영구 디스크를 사용할 수 있습니다. 어떤 옵션이 적합한지는 작업의 성격에 따라 다릅니다.
Cloud Storage와 HDFS 비교
Dataproc 클러스터의 각 노드에 Cloud Storage 커넥터가 설치되어 있습니다. 기본적으로 커넥터는 /usr/lib/hadoop/lib 아래에 설치됩니다. 이 커넥터는 Hadoop FileSystem 인터페이스를 구현하고 Cloud Storage를 HDFS와 호환 가능하게 설정합니다.
Cloud Storage는 바이너리 대형 객체(BLOB) 스토리지 시스템이므로 커넥터는 객체의 이름에 따라 디렉터리를 에뮬레이션합니다. hdfs:// 프리픽스 대신 gs:// 프리픽스를 사용하여 데이터에 액세스할 수 있습니다.
Cloud Storage 커넥터는 일반적으로 맞춤설정이 필요하지 않습니다. 그러나 변경이 필요한 경우 커넥터 구성 안내를 따릅니다. 구성 키의 전체 목록도 사용할 수 있습니다.
다음과 같은 경우 Cloud Storage가 적합합니다.
- ORC, Parquet, Avro 또는 다른 형식의 데이터가 다른 클러스터 또는 작업에서 사용되며 클러스터가 종료되는 경우 데이터 지속성이 필요합니다.
- 높은 처리량이 필요하며 데이터가 128MB보다 큰 파일로 저장됩니다.
- 데이터의 영역(zone) 간 내구성이 필요합니다.
- 데이터 가용성이 뛰어나야 합니다. 예를 들어 HDFS NameNode를 단일 장애점으로서 제거하려 합니다.
다음과 같은 경우 로컬 HDFS 저장소가 적합합니다.
- 작업에 많은 메타데이터 작업이 필요합니다. 예를 들어 수천 개의 파티션과 디렉토리가 있고 각 파일의 크기는 비교적 작은 편입니다.
- HDFS 데이터를 자주 수정하거나 디렉터리의 이름을 변경합니다. (Cloud Storage 객체는 변경할 수 없습니다. 따라서 디렉터리의 이름을 변경하는 것은 모든 객체를 새로운 키로 복사한 다음 삭제해야 하기 때문에 비용이 많이 드는 작업입니다.)
- HDFS 파일에서 추가 작업을 많이 사용합니다.
과중한 I/O를 포함하는 작업 부하가 있습니다. 예를 들어 다음과 같이 파티션을 나눈 쓰기가 많이 있습니다.
spark.read().write.partitionBy(...).parquet("gs://")지연 시간에 특히 민감한 I/O 워크로드가 있습니다. 예를 들어 스토리지 작업당 한 자릿수의 밀리초 지연 시간이 필요합니다.
일반적으로 Cloud Storage는 빅데이터 파이프라인의 초기 및 최종 데이터 소스로 사용하는 것이 좋습니다. 예를 들어 워크플로에 5개의 Spark 작업이 연속으로 포함된 경우 첫번째 작업은 Cloud Storage에서 초기 데이터를 검색한 다음 HDFS에 셔플 데이터와 중간 작업 출력을 씁니다. 최종 Spark 작업은 그 결과를 Cloud Storage에 씁니다.
스토리지 크기 조정
Cloud Storage와 함께 Dataproc을 사용하면 HDFS 대신 데이터를 저장함으로써 디스크 요구사항을 줄이고 비용을 절감할 수 있습니다. Cloud Storage에 데이터를 저장하고 로컬 HDFS에 저장하지 않는 경우 클러스터에 더 작은 디스크를 사용할 수 있습니다. 클러스터를 완전한 주문형으로 만들면 앞에서 설명한 바와 같이 스토리지를 분리하고 컴퓨팅을 수행할 수 있어 비용을 크게 절감할 수 있습니다.
모든 데이터를 Cloud Storage에 저장하더라도 Dataproc 클러스터는 제어 및 복구 파일을 저장하거나 로그를 집계하는 것과 같은 특정 작업에 HDFS가 필요합니다. 또한 무작위 섞기를 위한 로컬 디스크 공간도 필요합니다. 로컬 HDFS를 많이 사용하지 않는 경우 작업자당 디스크 크기를 줄일 수 있습니다.
다음은 로컬 HDFS의 크기를 조정하는 몇 가지 옵션입니다.
- 마스터 및 작업자의 기본 영구 디스크 크기를 줄여 로컬 HDFS의 총 크기를 줄입니다. 기본 영구 디스크에는 부팅 볼륨과 시스템 라이브러리도 포함되므로 최소 100GB를 할당하세요.
- 작업자의 기본 영구 디스크 크기를 늘려 로컬 HDFS의 총 크기를 늘립니다. 이 옵션은 신중하게 고려하세요. SSD로 Cloud Storage 또는 로컬 HDFS를 사용하는 것과 비교하면 표준 영구 디스크로 HDFS를 사용하여 성능이 개선되는 워크로드는 거의 없습니다.
- 각 작업자에 최대 8개의 SSD(각 375GB)를 연결하고 해당 디스크를 HDFS용으로 사용합니다. 이는 HDFS를 I/O 중심의 워크로드에 사용하려 하거나 한 자릿수의 밀리초 지연 시간이 필요한 경우 적합한 옵션입니다. 이 디스크를 지원하려면 작업자에 충분한 CPU 및 메모리가 있는 머신 유형을 사용해야 합니다.
- 마스터 및 작업자의 영구 디스크 SSD(PD-SSD)를 기본 디스크로 사용합니다.
Dataproc 액세스
Compute Engine에서 Dataproc 또는 Hadoop에 액세스하는 것은 온프레미스 클러스터에 액세스하는 것과 다릅니다. 보안 설정 및 네트워크 액세스 옵션을 확인해야 합니다.
네트워킹
Dataproc 클러스터의 모든 VM 인스턴스에는 서로 간의 내부 네트워킹이 필요하며 열린 UDP, TCP, ICMP 포트가 필요합니다. 기본 네트워크 구성 또는 VPC 네트워크를 사용하여 Dataproc 클러스터에 대한 외부 IP 주소의 액세스를 허용할 수 있습니다. Dataproc 클러스터는 사용하는 모든 네트워크 옵션에서 모든 Google Cloud 서비스(Cloud Storage 버킷, API 등)에 대한 네트워킹 액세스 권한을 가집니다. 온프레미스 리소스를 오가는 네트워킹 액세스를 허용하려면 VPC 네트워크 구성을 선택하고 적절한 방화벽 규칙을 설정하세요. 자세한 내용은 Dataproc 클러스터 네트워크 구성 가이드 및 아래의 YARN 액세스 섹션을 참조하세요.
ID 및 액세스 관리
네트워크 액세스 외에도 Dataproc 클러스터에는 리소스 액세스 권한이 필요합니다. 예를 들어 Cloud Storage 버킷에 데이터를 쓰려면 Dataproc 클러스터에 버킷에 대한 쓰기 액세스가 있어야 합니다. 역할을 사용하여 액세스를 설정할 수 있습니다. Spark 코드를 스캔하여 코드에 필요한 모든 Dataproc 이외의 리소스를 찾아 클러스터의 서비스 계정에 올바른 역할을 부여합니다. 또한 클러스터, 작업, 운영, 워크플로 템플릿을 만드는 사용자에게 적절한 권한이 있는지 확인합니다.
자세한 내용과 권장사항은 IAM 문서를 참조하세요.
Spark 및 기타 라이브러리 종속 항목 확인
Spark 버전과 다른 라이브러리 버전을 공식 Dataproc 버전 목록과 비교하여 아직 제공되지 않는 라이브러리를 찾습니다. Dataproc에서 공식적으로 지원하는 Spark 버전을 사용하는 것이 좋습니다.
라이브러리를 추가해야 하는 경우 다음을 수행할 수 있습니다.
- Dataproc 클러스터의 커스텀 이미지를 만듭니다.
- 클러스터의 Cloud Storage에 초기화 스크립트를 만듭니다. 초기화 스크립트를 사용하여 추가 종속 항목을 설치하거나 바이너리를 복사하는 등의 작업을 할 수 있습니다.
- 자바 또는 Scala 코드를 다시 컴파일하고 Gradle, Maven, Sbt 또는 다른 도구를 사용하여 기본 배포에 포함되지 않은 모든 추가 종속 항목을 'fat jar'로 패키지화합니다.
Dataproc 클러스터 크기 조정
온프레미스 또는 클라우드의 모든 클러스터 구성에서 클러스터 크기는 Spark 작업 성능에 중요한 역할을 합니다. 리소스가 부족한 Spark 작업은 특히 실행 메모리가 충분하지 않은 경우 느려지거나 실패할 수 있습니다. Hadoop 클러스터의 크기를 조정할 때 고려해야 할 사항은 Hadoop 이전 가이드의 클러스터 크기 조정 섹션을 참조하세요.
다음 섹션에서는 클러스터의 크기를 조정하는 몇 가지 옵션에 대해 설명합니다.
현재 Spark 작업의 구성 가져오기
현재 Spark 작업이 어떻게 구성되어 있는지 살펴보고 Dataproc 클러스터가 충분히 큰지 확인합니다. 공유 클러스터에서 여러 Dataproc 클러스터로 이동하는 경우(각 일괄 워크로드마다 하나씩) 각 애플리케이션의 YARN 구성을 확인하여 필요한 실행자 수, 실행자당 CPU 수, 총 실행자 메모리를 파악합니다. 온프레미스 클러스터에 YARN 큐가 설정된 경우 어떤 작업이 각 큐의 리소스를 공유하는지 확인하고 병목 현상을 파악합니다. 이전을 하면 온프레미스 클러스터에 있을 수 있는 리소스 제한을 삭제할 수 있습니다.
머신 유형 및 디스크 옵션 선택
워크로드의 요구사항에 따라 VM의 수와 유형을 선택합니다. 로컬 HDFS를 스토리지로 사용하기로 결정했다면 VM의 디스크 유형과 크기가 적절한지 확인합니다. 계산에 드라이버 프로그램의 리소스 요구사항을 포함하는 것을 잊지 마세요.
각 VM에는 vCPU당 2Gbps의 네트워킹 이그레스 한도가 있습니다. 영구 디스크 또는 영구 SSD에 쓰는 경우 이 한도에 포함되므로 vCPU 수가 매우 적은 VM이 디스크에 데이터를 쓸 때 한도의 적용을 받을 수 있습니다. 이는 Spark가 디스크에 셔플 데이터를 쓰고 실행자 간에 네트워크를 통해 셔플 데이터를 이동하는 셔플 단계에서 발생할 수 있습니다. 최대 쓰기 성능에 도달하려면 영구 디스크에는 2개 이상의 vCPU가 필요하고 영구 SSD에는 4개의 vCPU가 필요합니다. 이 최소 사양은 VM 간 통신과 같은 트래픽을 고려하지 않습니다. 또한 각 디스크의 크기는 최대 성능에 영향을 미칩니다.
선택한 구성은 Dataproc 클러스터의 비용에 영향을 미칩니다. Dataproc 가격은 각 VM 및 다른 Google Cloud 리소스의 Compute Engine 인스턴스당 가격에 추가로 부과됩니다. 자세한 내용을 보고 Google Cloud 가격 계산기를 사용하여 비용을 예상하려면 Dataproc 가격 책정 페이지를 참조하세요.
성능 벤치마킹 및 최적화
작업 이전 단계를 완료했다면 온프레미스 클러스터에서 Spark 워크로드를 실행 중지하기 전에 Spark 작업을 벤치마킹하고 최적화를 고려하세요. 최적의 구성이 아닌 경우 클러스터의 크기를 조절할 수 있습니다.
Spark 자동 확장을 위한 서버리스 Dataproc
서버리스 Dataproc를 사용하여 자체 클러스터를 프로비저닝 및 관리하지 않고 Spark 워크로드를 실행합니다. 워크로드 매개변수를 지정한 후 워크로드를 Dataproc 서버리스 서비스에 제출합니다. 이 서비스는 관리되는 컴퓨팅 인프라에서 워크로드를 실행하여 필요에 따라 리소스를 자동 확장합니다. Dataproc 서버리스 요금은 워크로드가 실행될 때만 적용됩니다.
이전 수행
이 섹션에서는 데이터 이전, 작업 코드 변경, 작업 실행 방법 변경에 대해 다룹니다.
데이터 마이그레이션
Dataproc 클러스터에서 Spark 작업을 실행하기 전에 데이터를 Google Cloud로 마이그레이션해야 합니다. 자세한 내용은 데이터 마이그레이션 가이드를 참조하세요.
Spark 코드 마이그레이션
Dataproc으로 마이그레이션을 계획하고 필요한 데이터 소스를 이동했다면 작업 코드를 마이그레이션할 수 있습니다. 두 클러스터의 Spark 버전 간에 차이가 없고 로컬 HDFS 대신 Cloud Storage에 데이터를 저장하려면 모든 HDFS 파일 경로의 프리픽스를 hdfs://에서 gs://로 변경하기만 하면 됩니다.
다른 Spark 버전을 사용하는 경우 Spark 출시 노트를 참조하여 두 버전을 비교한 후 그에 따라 Spark 코드를 적용합니다.
Dataproc 클러스터 또는 HDFS 폴더와 연결된 Cloud Storage 버킷으로 Spark 애플리케이션용 jar 파일을 복사할 수 있습니다. 다음 섹션에서는 Spark 작업을 실행하기 위해 사용할 수 있는 옵션을 설명합니다.
워크플로 템플릿을 사용하기로 결정한 경우 추가하려는 각 Spark 작업을 개별적으로 테스트하는 것이 좋습니다. 그런 다음 템플릿의 최종 테스트 실행을 진행하여 템플릿의 워크플로가 올바른지(누락된 업스트림 작업이 없는지, 출력이 올바른 위치에 저장되어 있는지 등) 확인합니다.
작업 실행
다음과 같은 방법으로 Spark 작업을 실행할 수 있습니다.
다음
gcloud명령어를 사용합니다.gcloud dataproc jobs submit [COMMAND]
각 항목의 의미는 다음과 같습니다.
[COMMAND]는spark,pyspark또는spark-sql입니다.--properties옵션을 사용하여 Spark 속성을 설정할 수 있습니다. 자세한 내용은 이 명령어 관련 문서를 참조하세요.작업을 Cloud Dataproc으로 마이그레이션하기 전에 사용했던 것과 동일한 프로세스를 사용합니다. 온프레미스에서 Dataproc 클러스터에 액세스할 수 있어야 하며 동일한 구성을 사용해야 합니다.
Cloud Composer를 사용합니다. 환경(관리형 Apache Airflow 서버)을 만들고 여러 Spark 작업을 DAG 워크플로에 정의한 다음 전체 워크플로를 실행할 수 있습니다.
자세한 내용은 작업 제출 가이드를 참조하세요.
마이그레이션 후 작업 관리
Spark 작업을 Google Cloud로 이동한 후에는 Google Cloud에서 제공하는 도구와 메커니즘을 사용하여 작업을 관리하는 것이 중요합니다. 이 섹션에서는 로깅, 모니터링, 클러스터 액세스, 클러스터 확장, 작업 최적화에 대해 다룹니다.
로깅 및 성능 모니터링 사용
Google Cloud에서 Cloud Logging 및 Cloud Monitoring을 사용하여 로그를 보고 맞춤설정하거나 작업과 리소스를 모니터링할 수 있습니다.
Spark 작업 실패의 원인을 찾아내는 가장 좋은 방법은 Spark 실행자가 생성한 드라이버 출력과 로그를 살펴보는 것입니다.
Google Cloud 콘솔 또는 gcloud 명령어를 사용하여 드라이버 프로그램 출력을 검색할 수 있습니다. 출력은 Dataproc 클러스터의 Cloud Storage 버킷에도 저장됩니다. 자세한 내용은 Dataproc 문서의 작업 드라이버 출력 섹션을 참조하세요.
다른 모든 로그는 클러스터 머신 내의 다른 파일에 있습니다. 실행자 탭의 Spark 앱 웹 UI(또는 프로그램 종료 후 History Server)에서 각 컨테이너의 로그를 볼 수 있습니다. 각 로그를 보려면 각 Spark 컨테이너를 찾아보아야 합니다. 애플리케이션 코드로 로그를 쓰거나 stdout또는 stderr로 출력하는 경우 로그는 stdout 또는 stderr의 리디렉션으로 저장됩니다.
Dataproc 클러스터에서 YARN은 기본적으로 이러한 모든 로그를 수집하도록 구성되어 있으며 Cloud Logging에서 확인할 수 있습니다. Cloud Logging은 모든 로그를 통합하여 간결하게 보여주므로 오류를 찾기 위해 컨테이너 로그를 살펴보느라 시간을 낭비하지 않아도 됩니다.
다음 그림은 Google Cloud 콘솔의 Cloud Logging 페이지를 보여줍니다. 선택기 메뉴에서 클러스터 이름을 선택하여 Dataproc 클러스터의 모든 로그를 볼 수 있습니다. 시간 범위 선택기에서 기간을 확장하는 것을 잊지 마세요.
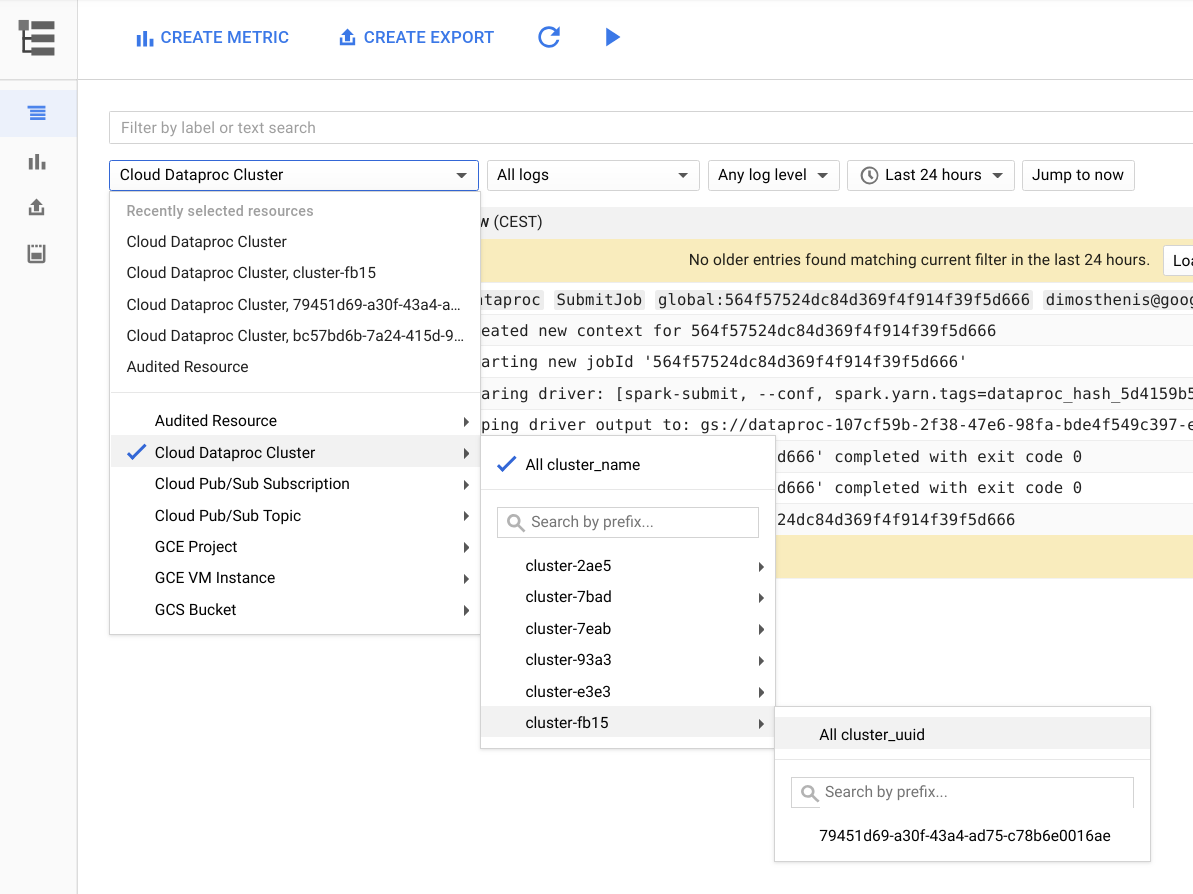
해당 ID로 필터링하여 Spark 애플리케이션에서 로그를 가져올 수 있습니다. 드라이버 출력에서는 애플리케이션 ID를 가져올 수 있습니다.
라벨 만들고 사용하기
로그를 더 빨리 찾으려면 각 클러스터 또는 각 Dataproc 작업에 고유한 라벨을 만들어 사용할 수 있습니다. 예를 들어 env 키와 exploration 값으로 라벨을 만들고 데이터 탐색 작업에 사용할 수 있습니다. 이렇게 하면 Cloud Logging에서 label:env:exploration으로 필터링하여 생성된 모든 탐색 작업의 로그를 가져올 수 있습니다.
이 필터는 이 작업의 모든 로그를 반환하지 않으며 리소스 생성 로그만 반환합니다.
로그 수준 설정
다음 gcloud 명령어를 사용하여 드라이버 로그 수준을 설정할 수 있습니다.
gcloud dataproc jobs submit hadoop --driver-log-levels
Spark 환경설정에서 나머지 애플리케이션의 로그 수준을 설정합니다. 예를 들면 다음과 같습니다.
spark.sparkContext.setLogLevel("DEBUG")
작업 모니터링
Cloud Monitoring은 클러스터의 CPU, 디스크, 네트워크 사용량, YARN 리소스를 모니터링할 수 있습니다. 커스텀 대시보드를 만들어 이러한 측정항목 및 기타 측정항목의 최신 차트를 얻을 수 있습니다. Dataproc은 Compute Engine을 기반으로 실행됩니다. 차트에서 CPU 사용량, 디스크 I/O 또는 네트워킹 측정항목을 시각화하려면 리소스 유형으로 Compute Engine VM 인스턴스를 선택한 다음 클러스터 이름으로 필터링해야 합니다. 다음 다이어그램은 출력의 예를 보여줍니다.
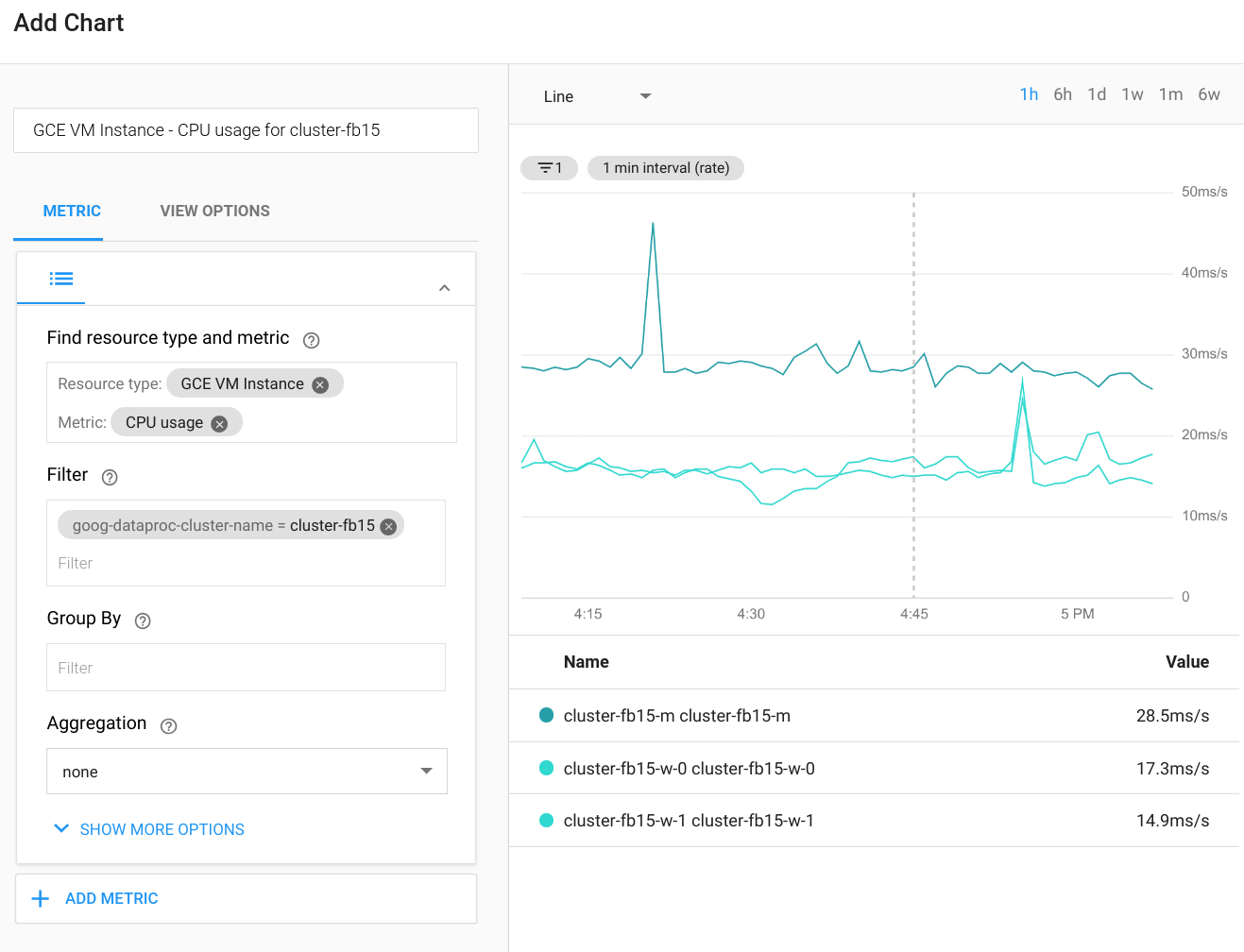
Spark 쿼리, 작업, 단계 또는 태스크의 측정항목을 보려면 Spark 애플리케이션의 웹 UI에 연결합니다. 다음 섹션에서는 이를 수행하는 방법을 설명합니다. 커스텀 측정항목을 만드는 방법에 대한 자세한 내용은 에이전트의 커스텀 측정항목 가이드를 참조하세요.
YARN 액세스
SSH 터널을 설정하면 Dataproc 클러스터 외부에서 YARN 리소스 관리자 웹 인터페이스에 액세스할 수 있습니다. 로컬 포트 전달 대신 간단한 SOCKS 프록시를 사용하는 것이 좋습니다. 이렇게 하면 웹 인터페이스를 통한 탐색이 더 쉬워집니다.
다음 URL은 YARN 액세스에 유용합니다.
YARN 리소스 관리자:
http://[MASTER_HOST_NAME]:8088Spark 기록 서버:
http://[MASTER_HOST_NAME]:18080
Dataproc 클러스터에 내부 IP 주소만 있는 경우 VPN 연결 또는 배스천 호스트를 통해 연결할 수 있습니다. 자세한 내용은 내부 전용 VM의 연결 옵션 선택을 참조하세요.
Dataproc 클러스터 확장 및 크기 조절
기본 또는 보조(선점형) 작업자의 수를 늘리거나 줄여 Dataproc 클러스터를 확장할 수 있습니다. Dataproc은 단계적 해제도 지원합니다.
Spark에서의 축소 작업은 다양한 요인의 영향을 받습니다. 다음 사항을 고려하세요.
ExternalShuffleService는 사용하지 않는 것이 좋습니다. 클러스터를 주기적으로 축소하는 경우에는 더욱 그러합니다. 무작위 섞기는 컴퓨팅 단계가 실행된 후 작업자의 로컬 디스크에 쓰인 결과를 사용하기 때문에 컴퓨팅 리소스가 더 이상 소비되지 않아도 노드를 삭제할 수 없습니다.Spark는 메모리에 있는 데이터(RDD 및 데이터 세트 모두)를 캐시에 저장하며 캐싱에 사용된 실행자는 절대 종료되지 않습니다. 결과적으로 작업자가 캐싱에 사용된 경우 단계적으로 해제되지 않습니다. 작업자를 강제로 삭제하면 캐시된 데이터가 손실되므로 전체 성능에 영향을 미칩니다.
Spark Streaming은 기본적으로 동적 할당이 사용 중지되어 있으며 이 동작을 설정하는 구성 키는 문서화되지 않습니다. Spark 문제 스레드에서 동적 할당 동작에 대한 토론에 참여할 수 있습니다. Spark Streaming 또는 Spark Structured Streaming을 사용하는 경우 앞서 작업 유형 식별 및 클러스터 계획에서 설명한 대로 동적 할당을 명시적으로 사용 중지해야 합니다.
일반적으로 일괄 또는 스트리밍 워크로드를 실행하는 경우 Dataproc 클러스터를 축소하지 않는 것이 좋습니다.
성능 최적화
이 섹션에서는 Spark 작업을 실행하는 동안 성능을 향상시키고 비용을 절감하는 방법에 대해 설명합니다.
Cloud Storage 파일 크기 관리
최적의 성능을 위해서는 Cloud Storage의 데이터를 128MB에서 1GB 크기의 파일로 분할합니다. 작은 파일을 많이 사용하면 병목 현상이 생길 수 있습니다. 작은 파일이 많은 경우 파일을 로컬 HDFS로 복사하여 처리한 다음 결과를 다시 복사하는 것이 좋습니다.
SSD 디스크로 전환
무작위 섞기 작업 또는 파티션을 나눈 쓰기가 많은 경우 SSD로 전환하면 성능이 향상됩니다.
같은 영역에 VM 배치
네트워킹 비용을 절감하고 성능을 향상시키려면 Cloud Dataproc 클러스터에 사용하는 Cloud Storage 버킷과 동일한 리전 위치를 사용합니다.
기본적으로 전역 또는 리전 Dataproc 엔드포인트를 사용하는 경우 클러스터가 생성될 때 클러스터의 VM은 같은 영역(또는 충분한 용량이 확보된 같은 리전의 다른 영역)에 배치됩니다. 클러스터를 만들 때 영역을 지정할 수도 있습니다.
선점형 VM 사용
Dataproc 클러스터는 선점형 VM 인스턴스를 작업자로 사용할 수 있습니다. 이렇게 하면 중요하지 않은 워크로드에 대한 시간당 컴퓨팅 비용이 일반 인스턴스를 사용하는 것보다 낮아집니다. 그러나 선점형 VM을 사용할 때에는 다음과 같은 몇 가지 요소를 고려해야 합니다.
- 선점형 VM은 HDFS 저장소로 사용할 수 없습니다.
- 기본적으로 선점형 VM은 부팅 디스크 사이즈가 작게 만들어지므로 무작위 섞기가 많은 워크로드를 실행하는 경우 이 구성을 재정의해야 할 수 있습니다. 자세한 내용은 Dataproc 문서의 선점형 VM에 대한 페이지를 참조하세요.
- 총 작업자의 절반 이상을 선점형으로 설정하는 것은 권장하지 않습니다.
선점형 VM을 사용하는 경우 VM의 가용성이 떨어질 수 있으므로 작업 실패에 더 잘 대처할 수 있도록 클러스터 구성을 조정하는 것이 좋습니다. 예를 들어 YARN 구성에서 다음과 같이 설정합니다.
yarn.resourcemanager.am.max-attempts mapreduce.map.maxattempts mapreduce.reduce.maxattempts spark.task.maxFailures spark.stage.maxConsecutiveAttempts
클러스터에서 선점형 VM을 쉽게 추가하거나 삭제할 수 있습니다. 자세한 내용은 선점형 VM을 참조하세요.
다음 단계
- 온프레미스 Hadoop 인프라를 Google Cloud로 마이그레이션하는 방법 가이드를 참조하세요.
- Dataproc 작업 수명의 설명을 확인하세요.
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항을 살펴보세요. Cloud 아키텍처 센터 살펴보기