In a traditional enterprise application, requests from clients are executed within a database transaction. Generally, all of the data that you need to complete a request is stored in a single database that has ACID properties (the term ACID stands for atomicity, consistency, isolation, and durability). Therefore, you can guarantee consistency by using the transactional features of the relational database system. When something goes wrong during the transaction, the database system can automatically roll back and retry the transaction. This document describes how to design transactional workflows by using Cloud Run, Pub/Sub, Workflows, and Firestore in Datastore mode (Datastore). It's intended for application developers who want to design transactional workflows in a microservices based application.
This document is part of a series that has the following parts:
- Transactional workflows in microservices architecture on Google Cloud (this document).
- Deploying an example application of transactional workflows in microservices architecture: A tutorial that shows you how to deploy and use an example application which uses the architecture that this document describes.
End-to-end transactions in microservices
In microservices architectures, an end-to-end transaction might span multiple services. Each service might provide a specific capability and have its own independent database, as shown in the following diagram.

As shown in the preceding image, a client accesses multiple microservices through a gateway. Because of this client access arrangement, you can't rely on the transactional features of a single database to help your database system to recover from failures and guarantee consistency. Instead, we recommend that you implement a transactional workflow in your microservices architecture.
This document describes two patterns that you can use to implement a transactional workflow in a microservices architecture. The patterns are as follows:
- Choreography-based saga
- Synchronous orchestration
Example application
To help demonstrate the workflow, this document uses a simple example
application, which can handle order transactions for a shopping website. The
application manages customers and orders. Customers have a credit limit and the
application must confirm that a new order will not exceed the customer's credit
limit. As shown in the following diagram, the transactional workflow runs across
the following microservices: theOrder service and theCustomer service.

The workflow is as follows:
- A client submits an order request that specifies a customer ID and a number of items.
- The
Orderservice assigns an order ID, and stores the order information in the database. The status of the order is marked aspending. - The
Customerservice increases the customer's credit usage stored in the database according to the number of ordered items. (For example, an increase of 100 credits for a single item.) - If the total credit usage is lower than or equal to the predefined
limit, the order is accepted and the
Orderservice changes the status of the order in the database toaccepted. - If the total credit usage is higher than the predefined limit, the
Orderservice changes the status of the order torejected. In this case, the credit usage is not increased.
The Order service
The Order service manages the status of an order. It generates and stores an
order record in the Order database for each client request. The record
consists of the following columns:
Order_id: The ID of the order. This ID is generated by theOrderservice.Customer_id: The customer ID.Number: The quantity of items in the order.Status: The status of an order.
The Customer service
The Customer service manages customer credits. It generates and stores a
customer record to the Customer database for each client request. The record
consists of the following columns:
Customer_id: The ID of the customer, which is generated by theCustomerservice.Credit: The number of credits the customer consumes. It increases when the customer orders items.Limit: The customer's individual credit limit. An order will be rejected when the customer's credit is over the set limit.
Choreography-based saga
This section describes how you implement a choreography-based saga microservices pattern in a transactional workflow.
Architecture overview
In a choreography-based saga microservices pattern, microservices work as an autonomous-distributed system. When a service changes the status of its own entity, it publishes an event to notify other services of updates. The notification event triggers other services to act. In this way, multiple services work together to complete a transactional process. The communication between microservices is asynchronous. When a service publishes an event, no information is sent to the publishing service to confirm the services that receive the event, or when they receive it.
The following image shows an example choreography-based saga microservices pattern.

The example architecture shown in the preceding image is as follows:
- Cloud Run acts as a runtime of microservices.
- Pub/Sub acts as a messaging service to deliver events between microservices.
- Datastore provides a database of each service.
You use Datastore to store events before publishing them. As explained in the event publishing process, the microservices store events instead of publishing them immediately.
The Order and Customer services store events in the event database at first.
Then, the stored events are published periodically using
Cloud Scheduler.
Cloud Scheduler
invokes the event-publisher service, which publishes events. This flow of events
is shown in the following image:

Transactional workflow
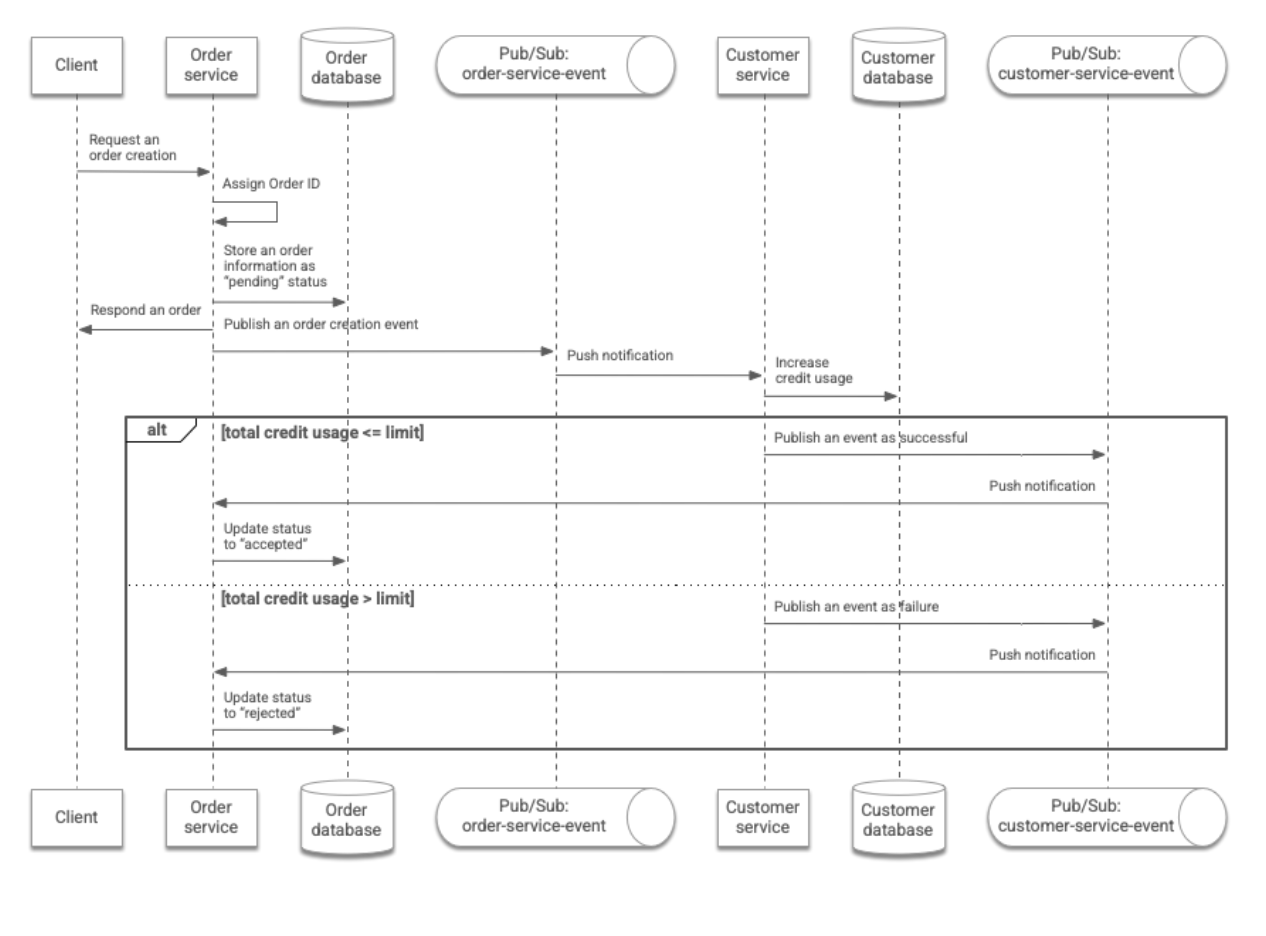
In a transactional workflow, two services communicate with each other through events. In this architecture, the customer's order is processed as follows:
- The client submits an order request that specifies the customer's ID
and the number of items they have ordered. The request is sent to the
Orderservice through a REST API. - The
Orderservice assigns an ID to the order, and stores the order information in theOrderdatabase. The status of the order is marked aspending. TheOrderservice returns the order information to the client, and publishes an event which includes the order information to the following Pub/Sub topic:order-service-event. - The
Customerservice receives the event through a push notification. It increases the customer's credit usage which is stored in theCustomerdatabase according to the number of ordered items. - If the total credit usage is lower than or equal to the predefined
limit, the
Customerservice publishes an event which states that the credit increase has succeeded. Alternatively, it publishes an event which states that the credit increase has failed. In this case, the credit usage is not increased. - The
Orderservice receives the event through a push notification. It changes the order status toacceptedorrejectedaccordingly. The client can track the status of the order using the order ID returned fromOrderservice.
The following diagram summarizes this workflow:
The event publishing process
When a microservice modifies its own data in the database and publishes an event to notify the database, these two operations must be conducted in an atomic way. For example, if the microservice fails after modifying data without publishing an event, the transactional process stops. In this case, the data can potentially be left in an inconsistent state across the multiple microservices that are involved in the transaction. To avoid this issue, in the example application used in this document, the microservices write event data in the backend database instead of directly publishing the events to Pub/Sub.
Data is modified and the associated event data is written in an atomic way, using the transactional feature of the backend database. This pattern, which is shown in the following image, is commonly called application events or "transactional outbox".

As shown in the preceding image, initially, the published column in the event
data is marked as False. Then, the event-publisher service periodically
scans the database and publishes events where the published column is False.
After successfully publishing an event, the event-publisher service changes
the published column to True.
As shown in the following image, both the Order database and the Event
database in the same namespace can be updated atomically by
Datastore transactions.

If the event-publisher service fails after publishing an event without changing the
published column, the service publishes the same event again after it
recovers. Because the republication of the event causes a duplicate event, the
microservices that receive the event must check for potential duplication and
handle it accordingly. This approach helps to guarantee the idempotence of the
event handling.
The following image shows how an example application deals with duplication of events.
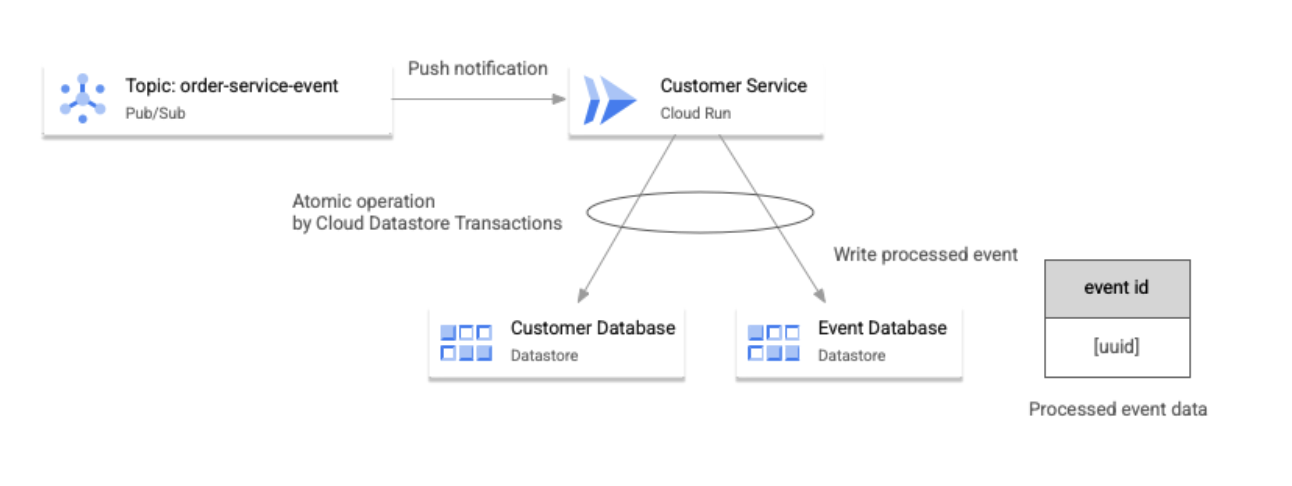
As shown in the preceding diagram, the application handles duplicate events with the following workflow:
- Each microservice updates its respective backend database based on the business logic triggered by an event, and writes the event ID to its database.
- These two writes are conducted in an atomic way using the transactional feature that the backend databases use.
- If the services receive a duplicate event, it's detected when the services look up the event ID in their databases.
Handling duplicate events is a common practice when receiving events from Pub/Sub, because there is a small chance that Pub/Sub can cause duplicate message delivery.
Expand the architecture
In the example application, before you process a message, you can use
Datastore to check if it's duplicated. This approach means that
the service which consumes the messages (Customer Service, in this case) is
idempotent. This approach is commonly called the
"idempotent consumer"
pattern. Some frameworks implement this pattern as a built-in feature—for
example,
Eventuate.
However, accessing the database every time you process a message can cause performance issues. One solution is to utilize a database that has good performance and scalability—for example, Redis.
Synchronous orchestration
This section describes how you implement a synchronous orchestration microservices pattern in a transactional workflow.
Architecture overview
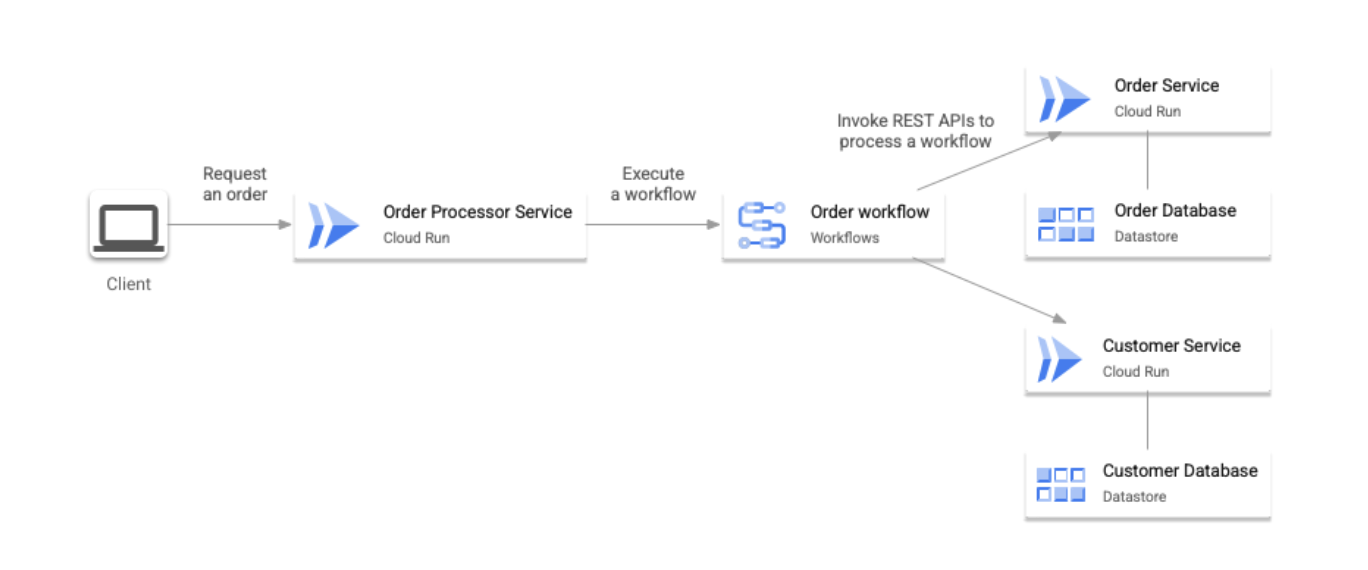
In this pattern, a single orchestrator controls the execution flow of a transaction. The communication between microservices and the orchestrator is done synchronously through REST APIs.
In the example architecture described in this document, Cloud Run is used as a runtime of microservices and Datastore is used as a backend database for each service. In addition, Workflows is used as an orchestrator. This pattern is shown in the following image:
Transactional workflow
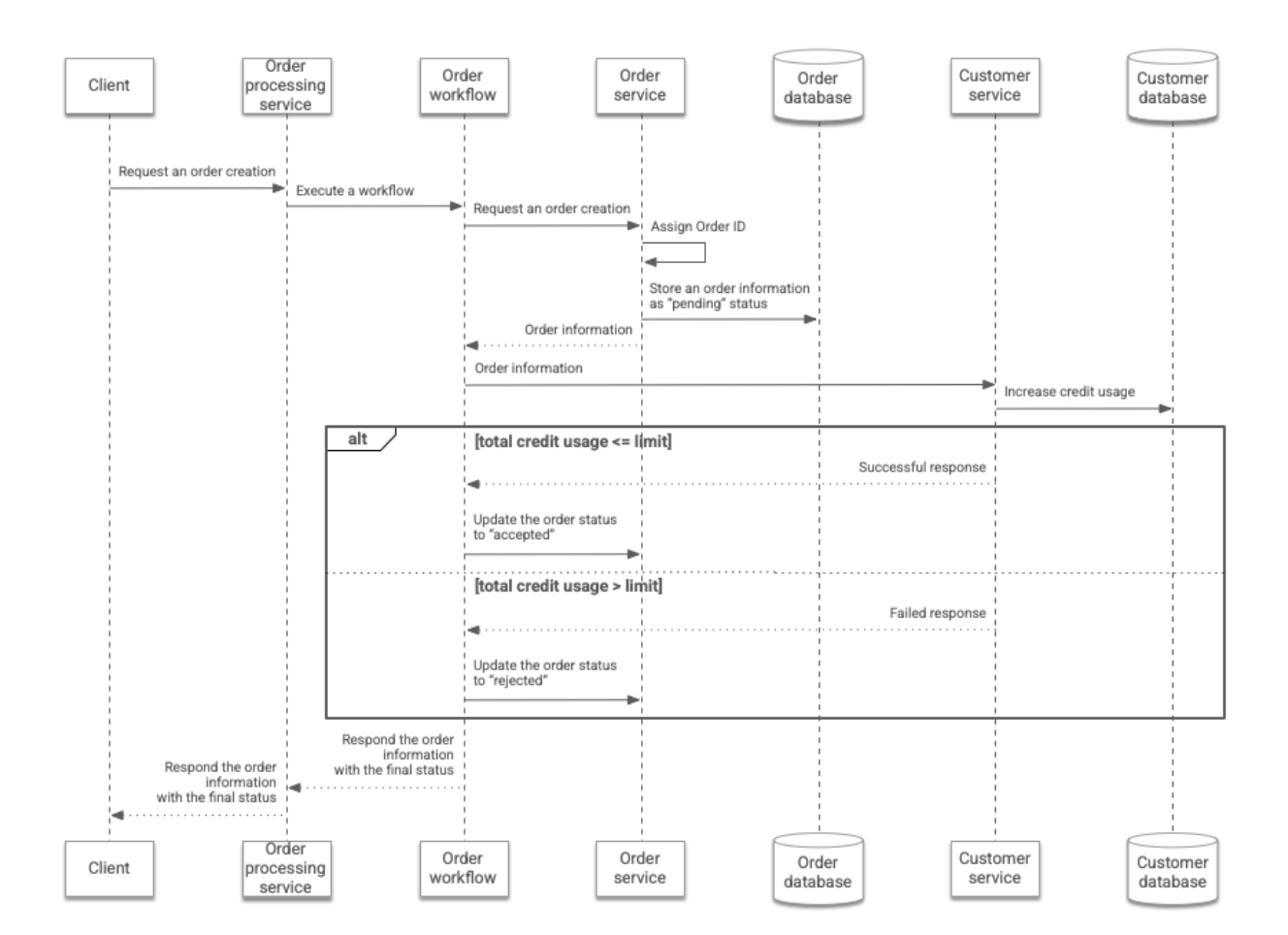
In the architecture for a synchronous workflow, a customer's order is processed as follows:
- The client submits an order request which specifies the ID of a
customer and the number of items that the customer has ordered. The
request is sent to the
Order processorservice through the REST API. - The
Order processorservice executes a workflow where the customer ID and the number of items is passed to Workflows. - The workflow calls the
Orderservice's REST API and passes on the customer ID and the number of items that the customer has ordered. Then, theOrderservice assigns an order ID to the customer's order, and stores the order information in theOrderdatabase. The status of the order is marked aspending. TheOrderservice returns the order information to the workflow. - The workflow calls the
Customerservice's REST API and passes on the customer ID and the number of items that the customer has ordered. Then, theCustomerservice increases the customer's credit usage stored in theCustomerdatabase according to the number of ordered items. - If the total credit usage is lower than or equal to the predefined
limit, the
Customerservice returns data which explains that the credit increase has succeeded. Alternatively, it returns data which explains that the credit increase has failed. In this case, the credit usage is not increased. - The workflow calls the
Orderservice REST API to change the order status toacceptedorrejected, as appropriate. Finally, it returns the order information in the final status update to theOrder processorservice. Then, theOrder processorservice returns that information to the client.
This workflow is summarized in the following diagram:
Advantages and disadvantages
When you consider whether to implement a choreography-based saga or synchronous orchestration, the best choice for your organization is always the pattern which is most suitable for its needs. However, in general, because of the simplicity of its design, synchronous orchestration is often the first choice for many enterprises.
The following table summarizes the advantages and disadvantages of the choreography-based saga and synchronous orchestration patterns that are described in this document.
Advantages |
Disadvantages |
|
|---|---|---|
Choreography-based saga |
Loose coupling: Each service publishes events to Datastore when there is a change in its own data. No information is sent to any other services. This approach makes each service more independent, and there's a lower chance of the need to modify services when you introduce new services to the workflow. |
Complex dependency: The implementation of the whole workflow is distributed among services. As a result, it can be complex to understand the workflow. This approach might accidentally introduce complexity into future design changes and troubleshooting. |
Synchronous orchestration |
Simple dependency: A single orchestrator controls the whole execution flow of a transaction. As a result, it's simpler to understand how the transaction flow works. This pattern simplifies the modification of workflow and troubleshooting. |
Risk of tight coupling: The central orchestrator depends on all of the services that make up the transactional workflow. As a result, when you modify one of these services or add new services to the workflow, you might need to modify the orchestrator accordingly. The extra effort required can outweigh the benefit of being able to modify and add services more independently to microservices architecture compared to monolithic systems. |
What's next
- Learn more about microservices architectures
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.