Google Cloud fournit l'infrastructure évolutive dont vous avez besoin pour gérer des opérations d'analyse de journaux importantes et diverses. Ce tutoriel montre comment utiliser Google Cloud pour créer des pipelines d'analyse, qui traitent les entrées de journal provenant de plusieurs sources. Vous combinerez les données de journalisation d'une manière qui vous aidera à extraire des informations significatives et à conserver les enseignements tirés de ces données, que vous pourrez ensuite exploiter pour des analyses, des examens complémentaires et créer des rapports.
Présentation
À mesure que votre application se complexifie, il devient plus difficile de recueillir des informations utiles à partir des données capturées dans vos journaux. Ces derniers proviennent d'un nombre croissant de sources. Il peut donc être difficile de les rassembler et de les interroger pour en tirer des enseignements. La création, l'exploitation et la maintenance de votre propre infrastructure dédiée à l'analyse de données de journalisation à grande échelle peuvent nécessiter une vaste expertise dans la gestion de systèmes et d'espaces de stockage distribués. Ce type d'infrastructure dédiée représente souvent un investissement ponctuel résultant en une capacité fixe, ce qui rend difficile toute évolution de l'infrastructure initiale. Ces limitations peuvent avoir un impact sur votre entreprise, car elles ralentissent la génération d'informations significatives et exploitables à partir de vos données.
Cette solution vous montre comment dépasser ces limitations en utilisant les produits Google Cloud, comme illustré dans le diagramme suivant.

Ici, un ensemble d'exemples de microservices est exécuté sur Google Kubernetes Engine (GKE) pour mettre en œuvre un site Web. Cloud Logging collecte les journaux en provenance de ces services, puis les enregistre dans des buckets Cloud Storage. Dataflow traite ensuite les journaux en extrayant les métadonnées et en calculant les agrégations de base. Le pipeline Dataflow est conçu pour traiter quotidiennement les éléments de journal afin de générer des métriques agrégées pour les temps de réponse des serveurs, en fonction des journaux de chaque jour. Enfin, le résultat de Dataflow est chargé dans des tables BigQuery, où les données peuvent être analysées pour fournir des informations décisionnelles. Cette solution explique également comment modifier le pipeline pour qu'il s'exécute en mode flux continu afin d'offrir un traitement asynchrone à faible temps de latence.
Ce tutoriel fournit un exemple de pipeline Dataflow, un exemple d'application Web, des informations de configuration, ainsi que toutes les étapes requises pour exécuter l'exemple.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- GKE pour le déploiement de microservices
- Cloud Logging pour la réception et l'exportation des journaux
- Cloud Storage pour le stockage des journaux exportés en mode de traitement par lot
- Pub/Sub pour la diffusion en continu des journaux exportés en streaming
- Dataflow pour le traitement des données de journal
- BigQuery pour le stockage des résultats du traitement et l'utilisation de requêtes enrichies sur ces résultats
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, Cloud Storage, Pub/Sub, Dataflow, GKE and Logging APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the BigQuery, Cloud Storage, Pub/Sub, Dataflow, GKE and Logging APIs.
Configurer votre environnement
Dans ce tutoriel, vous utilisez Cloud Shell pour saisir des commandes. Cloud Shell vous donne accès à l'interface de ligne de commande dans la console Google Cloud. En outre, il intègre Google Cloud CLI ainsi que d'autres outils dont vous pourrez avoir besoin pour le développement dans Google Cloud. Cloud Shell apparaît sous la forme d'une fenêtre en bas de la console Google Cloud. L'initialisation peut prendre quelques minutes, mais la fenêtre apparaît immédiatement.
Pour configurer votre environnement et cloner le dépôt git utilisé dans ce tutoriel à l'aide de Cloud Shell, procédez comme suit :
Dans Google Cloud Console, ouvrez Cloud Shell.
Assurez-vous que vous travaillez dans le projet que vous avez créé. Remplacez
[YOUR_PROJECT_ID]par votre projet Google Cloud nouvellement créé.gcloud config set project [YOUR_PROJECT_ID]Définissez la zone de calcul par défaut. Pour les besoins de ce tutoriel, il s'agit de
us-east1. Si vous effectuez un déploiement dans un environnement de production, déployez dans la région de votre choix.export REGION=us-east1 gcloud config set compute/region $REGION
Cloner l'exemple de dépôt
Clonez le dépôt contenant les scripts et la logique d'application utilisés dans ce tutoriel.
git clone https://github.com/GoogleCloudPlatform/processing-logs-using-dataflow.git cd processing-logs-using-dataflow/services
Configurer les variables d'environnement
# name your bucket
export PROJECT_ID=[YOUR_PROJECT_ID]
# name your GKE cluster
export CLUSTER_NAME=cluster-processing-logs-using-dataflow
# name the bucket for this tutorial
export BUCKET_NAME=${PROJECT_ID}-processing-logs-using-dataflow
# name the logging sink for this tutorial
export SINK_NAME=sink-processing-logs-using-dataflow
# name the logging sink for this tutorial
export DATASET_NAME=processing_logs_using_dataflow
Déployer l'exemple d'application sur un nouveau cluster Google Kubernetes Engine
# create the cluster and deploy sample services
./cluster.sh $PROJECT_ID $CLUSTER_NAME up
À propos de l'exemple de déploiement d'application
L'exemple de déploiement modélise une application d'achat. Dans cet exemple, les utilisateurs peuvent consulter la page d'accueil d'un site d'e-commerce, rechercher des produits individuels, puis essayer de les localiser dans les magasins physiques les plus proches. L'application se compose de trois microservices : HomeService, BrowseService et LocateService. Chaque service est disponible à partir d'un point de terminaison d'API dans un espace de noms partagé. Les utilisateurs accèdent aux services en ajoutant /home, /browse et /locate à l'URL de base.
L'application est configurée de manière à consigner les requêtes HTTP entrantes dans stdout.
Utilisation de Google Kubernetes Engine avec Cloud Logging
Dans cet exemple, les microservices s'exécutent dans un cluster Kubernetes Engine, c'est-à-dire un groupe d'instances (ou nœuds) Compute Engine qui fonctionnent sous Kubernetes. Par défaut, GKE configure chaque nœud de manière à fournir un certain nombre de services, y compris la surveillance, la vérification de l'état et la journalisation centralisée. La solution présentée ici s'appuie sur la compatibilité intégrée avec Logging pour envoyer les journaux de chaque microservice vers Cloud Storage. Une solution alternative pour les applications qui consignent des informations dans des fichiers (que nous n'aborderons pas dans cette solution) consiste à configurer la journalisation au niveau du cluster avec Kubernetes.
Chaque microservice s'exécute sur un pod individuel du cluster. Chaque pod s'exécute sur un nœud et est exposé comme point de terminaison HTTP unique à l'aide des services GKE.
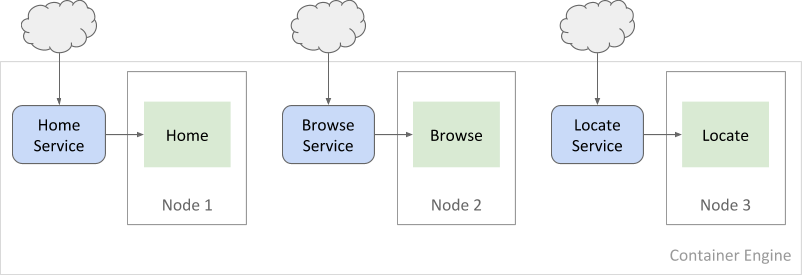
Chaque nœud du cluster exécute un agent Cloud Logging qui capture les messages de journalisation. Une fois que les journaux sont disponibles dans Logging, un script les achemine automatiquement vers un bucket Cloud Storage grâce à l'intégration de Logging dans gcloud CLI.
Vous pouvez également configurer l'exportation des journaux vers Cloud Storage à l'aide de l'explorateur de journaux. La solution présentée ici utilise gcloud CLI, car celle-ci est requise pour exporter plusieurs journaux.
Lorsque vous utilisez Cloud Storage comme destination pour l'exportation de journaux, les entrées de journal de type LogEntry sont enregistrées par lot toutes les heures dans des fichiers JSON individuels. Ces entrées Logging structurées incluent des métadonnées supplémentaires qui spécifient quand a été créé chaque message de journal, quelle ressource ou instance l'a généré, quel est son niveau de gravité, etc. Dans l'exemple suivant d'une entrée Logging, dans l'élément structPayload.log, vous pouvez voir le message de journal d'origine généré par le microservice :
{
"insertId": "ugjuig3j77zdi",
"labels": {
"compute.googleapis.com/resource_name": "fluentd-gcp-v3.2.0-9q4tr",
"container.googleapis.com/namespace_name": "default",
"container.googleapis.com/pod_name": "browse-service-rm7v9",
"container.googleapis.com/stream": "stdout"
},
"logName": "projects/processing-logs-at-scale/logs/browse-service",
"receiveTimestamp": "2019-03-09T00:33:30.489218596Z",
"resource": {
"labels": {
"cluster_name": "cluster-processing-logs-using-dataflow",
"container_name": "browse-service",
"instance_id": "640697565266753757",
"namespace_id": "default",
"pod_id": "browse-service-rm7v9",
"project_id": "processing-logs-at-scale",
"zone": "us-east1-d"
},
"type": "container"
},
"severity": "INFO",
"textPayload": "[GIN] 2019/03/09 - 00:33:23 | 200 | 190.726µs | 10.142.0.6 | GET /browse/product/1\n",
"timestamp": "2019-03-09T00:33:23.743466177Z"
}
Configurer la journalisation
Une fois le cluster opérationnel et les services déployés, vous pouvez configurer la journalisation pour l'application.
Tout d'abord, obtenez les identifiants du cluster, car le kubectl est utilisé pour obtenir les noms de services afin de configurer les récepteurs d'exportation Cloud Logging.
gcloud container clusters get-credentials $CLUSTER_NAME --region $REGION
Dans le dépôt de code, services/logging.sh configure les composants requis pour le traitement par lot ou par flux. Le script accepte les paramètres suivants :
logging.sh [YOUR_PROJECT_ID] [BUCKET_NAME] [streaming|batch] [up|down]
Pour les besoins de ce tutoriel, démarrez la journalisation en mode de traitement par lot :
./logging.sh $PROJECT_ID $BUCKET_NAME batch up
Les étapes suivantes illustrent les commandes exécutées pour le mode de traitement par lot :
Créez un bucket Cloud Storage.
gsutil -q mb gs://[BUCKET_NAME]Autorisez Cloud Logging à accéder au bucket.
gsutil -q acl ch -g cloud-logs@google.com:O gs://[BUCKET_NAME]Pour chaque microservice, configurez les exportations Cloud Logging à l'aide d'un récepteur.
gcloud logging sinks create [SINK_NAME] \ storage.googleapis.com/[BUCKET_NAME] \ --log-filter="kubernetes.home_service..." --project=[YOUR_PROJECT_ID]
Mettre à jour les autorisations de la destination
Les autorisations de la destination (ici, votre bucket Cloud Storage) ne sont pas modifiées lorsque vous créez un récepteur. Vous devez modifier les paramètres d'autorisation du bucket Cloud Storage pour accorder une autorisation en écriture au récepteur.
Pour mettre à jour les autorisations du bucket Cloud Storage :
Identifiez l'identité du rédacteur de votre récepteur :
Accédez à la page Routeur de journaux :
Accéder à la page du Routeur de journaux
La page Routeur de journaux contient un résumé de vos récepteurs, y compris l'identité du rédacteur de récepteur.
IMPORTANT : Pour chacun de vos trois récepteurs, vous devez accorder des autorisations sur le bucket Cloud Storage à une adresse e-mail de compte de service distincte.
Depuis la console Google Cloud, cliquez sur Stockage > Navigateur :
Pour afficher la vue détaillée, cliquez sur le nom de votre bucket.
Sélectionnez Autorisations, puis cliquez sur Ajouter des entités principales.
Définissez le Rôle sur
Storage Object Creatoret saisissez l'identité du rédacteur du récepteur.
Pour en savoir plus, consultez la section Autorisations des destinations.
Vous pouvez vérifier les chemins des objets journaux à l'aide de la commande suivante :
gsutil ls gs://$BUCKET_NAME | grep service
Lorsque le résultat contient les trois entrées, vous pouvez continuer la procédure et exécuter le pipeline de données :
gs://$BUCKET_NAME/browse-service/ gs://$BUCKET_NAME/home-service/ gs://$BUCKET_NAME/locate-service/
Créer l'ensemble de données BigQuery
bq mk $DATASET_NAME
Générer une charge sur les services d'application
Installer les utilitaires du serveur HTTP Apache
Vous allez utiliser l'outil d'analyse comparative (ab) du serveur HTTP Apache pour générer la charge sur les services.
sudo apt-get update
sudo apt-get install -y apache2-utils
Le script shell load.sh génère une charge sur les microservices en demandant des réponses à HomeService, BrowseService et LocateService.
Un ensemble de charge se compose d'une requête envoyée au service "home" ainsi que de 20 requêtes adressées aux services "browse" et "locate".
L'option suivante génère 1 000 ensembles de charge (avec la simultanéité définie sur 3 requêtes simultanées)
cd ../services
./load.sh 1000 3
Laissez la commande s'exécuter pendant quelques minutes pour créer un nombre suffisant de journaux.
Démarrer le pipeline Dataflow
Lorsqu'une quantité de trafic suffisante a atteint les services, vous pouvez démarrer le pipeline Dataflow.
Dans le cadre de ce tutoriel, le pipeline Dataflow est exécuté en mode de traitement par lot. Le script shell pipeline.sh démarre manuellement le pipeline.
cd ../dataflow
./pipeline.sh $PROJECT_ID $DATASET_NAME $BUCKET_NAME run
Comprendre le pipeline Dataflow
Dataflow peut être utilisé pour une grande variété de tâches de traitement de données. Le SDK Dataflow fournit un modèle de données unifié pouvant représenter un ensemble de données de toute taille, y compris un ensemble illimité ou infini provenant d'une source de données mise à jour en continu. Il est adapté au traitement des données de journalisation utilisées dans cette solution. Le service géré Dataflow peut exécuter des tâches par lot et en flux continu. Cela signifie que vous pouvez utiliser une même base de code pour le traitement asynchrone ou synchrone de données en temps réel sur la base d'événements.
Le SDK Dataflow fournit des représentations de données simples via une classe de collection spécialisée appelée PCollection.
Il fournit également des transformations de données intégrées et personnalisées via la classe PTransform. Dans Dataflow, les transformations représentent la logique de traitement d'un pipeline. Elles peuvent être utilisées pour réaliser un large éventail d'opérations de traitement telles que la fusion de données, le calcul de valeurs mathématiques, le filtrage des données de sortie ou la conversion des données d'un format à un autre. Pour plus d'informations sur les pipelines, les PCollections, les transformations, et les sources et récepteurs d'E/S, consultez la page Modèle de programmation de Dataflow.
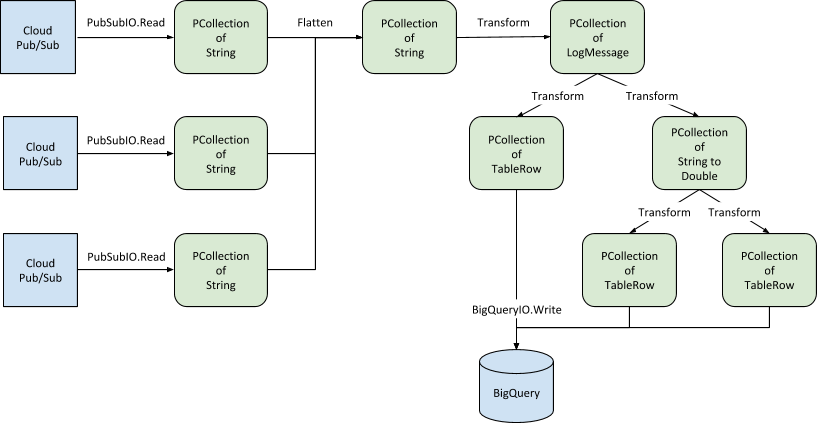
Le diagramme suivant illustre les opérations de pipeline pour les données de journalisation enregistrées dans Cloud Storage :
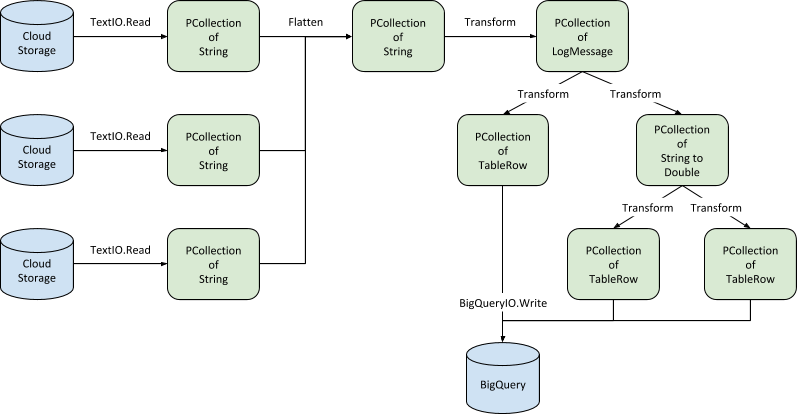
Bien que le diagramme puisse paraître complexe, Dataflow facilite la construction et l'utilisation du pipeline. Les sections suivantes décrivent les opérations spécifiques à chaque étape du pipeline.
Recevoir les données
Le pipeline commence par absorber les entrées en provenance des buckets Cloud Storage qui hébergent les journaux des trois microservices. Chaque collection de journaux devient une PCollection d'éléments String, où chaque élément correspond à un seul objet LogEntry. Dans l'extrait de code suivant, homeLogs, browseLogs et locateLogs sont de type PCollection<String>:
Pour faire face aux défis posés par la mise à jour continue d'un ensemble de données, le SDK Dataflow utilise une technique appelée fenêtrage.
Il s'agit de subdiviser logiquement les données d'une PCollection en fonction de l'horodatage de ses éléments individuels. Comme la source est de type TextIO, tous les objets sont initialement lus dans une seule fenêtre globale, ce qui correspond au comportement par défaut.
Collecter les données dans des objets
L'étape suivante fusionne les PCollections des microservices individuels en une seule PCollection grâce à l'opération Flatten.
Cette opération est utile, car chaque PCollection source contient le même type de données et utilise la même stratégie de fenêtrage globale. Bien que les sources et la structure de chaque journal soient identiques dans cette solution, vous pouvez étendre cette approche aux cas où les sources et les structures diffèrent.
Une fois la PCollection unique créée, vous pouvez traiter les éléments String individuels au moyen d'une transformation personnalisée qui réalise plusieurs étapes de traitement sur l'entrée de journal. Ces étapes sont illustrées dans le diagramme suivant :

- Désérialisez la chaîne JSON en un objet Java
LogEntryCloud Logging. - Extrayez l'horodatage à partir des métadonnées
LogEntry. - Extrayez les champs individuels suivants du message de journalisation à l'aide d'expressions régulières :
timestamp,responseTime,httpStatusCode,httpMethod, adresse IPsourceet point de terminaisondestination. Utilisez ces champs pour créer un objet personnaliséLogMessagehorodaté. - Renvoyez les objets
LogMessagedans une nouvellePCollection.
Le code suivant réalise ces étapes :
Agréger les données par jour
Rappelez-vous que l'objectif est de traiter les éléments quotidiennement pour générer des métriques agrégées basées sur les journaux produits chaque jour. Pour réaliser cette agrégation, il faut une fonction de fenêtrage, qui subdivise les données par jour, ce que permet l'horodatage de chaque LogMessage de la PCollection. Une fois que Dataflow a partitionné la PCollection suivant les limites quotidiennes, les opérations prenant en charge les PCollections fenêtrées respectent ce schéma de fenêtrage.
Avec une PCollection unique et fenêtrée, vous pouvez désormais calculer des métriques quotidiennes agrégées à partir de l'ensemble des données de journalisation (trois sources et plusieurs journées), en exécutant une seule tâche Dataflow.
Pour commencer, une transformation prend en entrée les objets LogMessage et renvoie une PCollection de paires clé-valeur, qui utilise les points de terminaison de destination comme clés, auxquelles sont associées les valeurs correspondant aux temps de réponse, comme illustré dans le diagramme suivant.
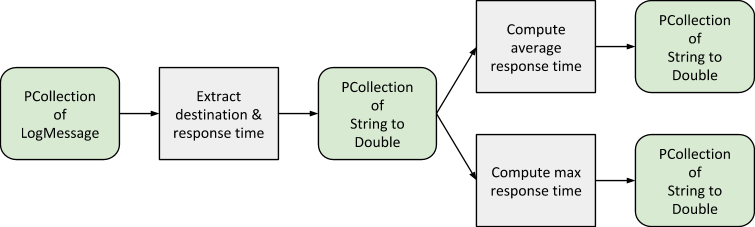
À l'aide de cette PCollection, vous pouvez calculer deux mesures agrégées : le temps de réponse maximal par destination et le temps de réponse moyen par destination. Comme la PCollection est toujours partitionnée par jour, le résultat de chaque calcul représente donc les données de journalisation d'une seule journée. Cela signifie que vous obtiendrez deux PCollections finales : l'une contenant le temps de réponse maximal par destination et par jour, l'autre contenant le temps de réponse moyen par destination et par jour.
Charger les données dans BigQuery
La dernière étape du pipeline consiste à envoyer les PCollections obtenues à BigQuery pour les analyses en aval et l'entreposage des données.
Tout d'abord, le pipeline transforme la PCollection contenant les objets LogMessage pour l'ensemble des sources de journalisation en une collection d'objets BigQuery TableRow.
Cette étape est nécessaire pour bénéficier des capacités intégrées de Cloud Dataflow à utiliser BigQuery en tant que récepteur pour un pipeline.
Les tables BigQuery nécessitent des schémas définis. Pour cette solution, les schémas sont définis dans LogAnalyticsPipelineOptions.java en utilisant une annotation de valeur par défaut. Par exemple, le schéma de la table hébergeant les temps de réponse maximaux est défini comme suit :
Une opération sur les PCollections contenant les valeurs de temps de réponse agrégées les convertit en PCollections d'objets TableRow, en appliquant les schémas appropriés et en créant, si nécessaire, les tables requises.
Cette solution ajoute systématiquement les nouvelles données aux données existantes. C'est un choix pertinent, car ce pipeline s'exécute périodiquement pour analyser les nouvelles données de journalisation. Cependant, il est possible de tronquer les données existantes de la table ou de n'écrire dans la table que si celle-ci est vide, si ces options ont davantage de sens dans le scénario qui vous intéresse.
Interroger les données depuis BigQuery
La console BigQuery vous permet d'exécuter des requêtes sur les données de sortie et de vous connecter à des outils de veille stratégique tiers, tels que Tableau et QlikView, pour y effectuer des analyses supplémentaires.
Dans la console Google Cloud, ouvrez BigQuery.
Cliquez sur le projet
processing-logs-at-scale, puis cliquez sur l'ensemble de donnéesprocessing_logs_using_dataflow.Sélectionnez
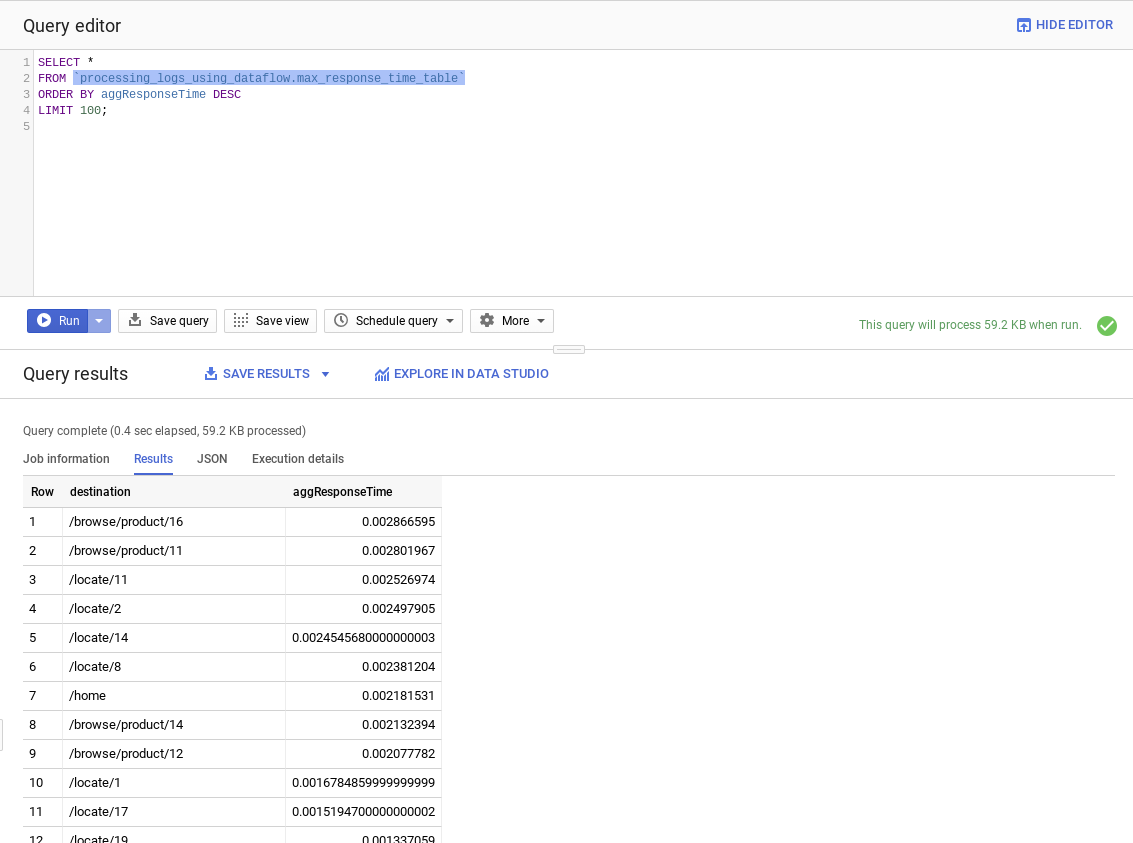
all_logs_table, puis, dans le volet des données, sélectionnez Prévisualiser pour afficher un échantillon des données de la table all logs.Dans Query editor (éditeur de requête), saisissez la requête suivante :
SELECT * FROM `processing_logs_using_dataflow.max_response_time_table` ORDER BY aggResponseTime DESC LIMIT 100;Pour exécuter la requête, cliquez sur Run (Exécuter).
Utiliser un pipeline en flux continu
L'exemple permet d'exécuter le pipeline aussi bien en mode de traitement par lot qu'en flux continu. Il suffit de quelques étapes pour passer d'un mode à l'autre. Tout d'abord, la configuration de Cloud Logging exporte les informations de journalisation vers Pub/Sub au lieu de Cloud Storage. L'étape suivante consiste à modifier les sources d'entrée du pipeline Dataflow de Storage en abonnements à des sujets Pub/Sub. Chaque source d'entrée nécessite son propre abonnement.
Vous pouvez voir quelles commandes du SDK sont utilisées dans logging.sh.
Les PCollections créées à partir de données d'entrée provenant de Pub/Sub utilisent une fenêtre globale illimitée. Cependant, les entrées individuelles incluent déjà des horodatages. Cela signifie qu'il n'est pas nécessaire d'extraire les données d'horodatage de l'objet Cloud Logging LogEntry ; vous pouvez plutôt extraire les horodatages de journal pour créer les objets LogMessage personnalisés.

Le reste du pipeline est inchangé, y compris les opérations de fusion, de transformation, d'agrégation et de sortie en aval.
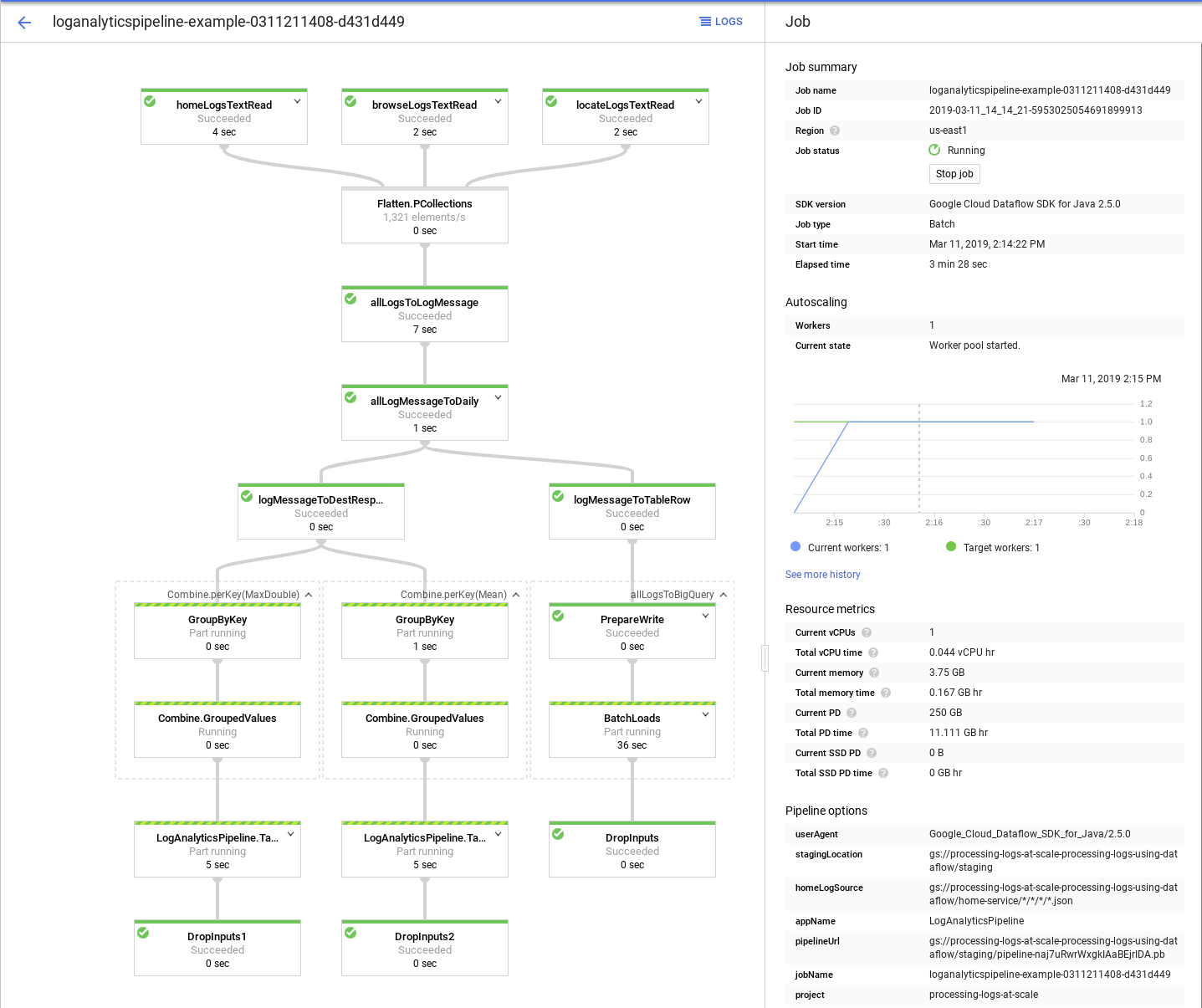
Surveiller le pipeline
Lorsque vous exécutez la tâche Dataflow, vous pouvez utiliser la console Google Cloud pour surveiller la progression et afficher des informations sur chaque étape du pipeline.
L'image suivante montre la console Google Cloud lors de l'exécution d'un exemple de pipeline :
Nettoyer
Supprimer le projet
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Supprimer tous les composants
Assurez-vous que les variables d'environnement conservent toujours les valeurs utilisées lors de la configuration.
Supprimez l'ensemble de données BigQuery :
bq rm $DATASET_NAMEDésactivez les exportations ((logging_name)). Cette étape supprime les exportations et le bucket Cloud Storage spécifié :
cd ../services ./logging.sh $PROJECT_ID $BUCKET_NAME batch downSupprimez le cluster Compute Engine utilisé pour exécuter les exemples d'applications Web :
/cluster.sh $PROJECT_ID $CLUSTER_NAME down
Étendre la solution
Le pipeline et l'ensemble des opérations décrites dans cette solution peuvent être étendus de différentes manières. Les extensions les plus évidentes consistent à effectuer des agrégations supplémentaires sur les données LogMessage. Par exemple, si la sortie du journal inclut des informations de session ou d'utilisateur anonymisées, vous pouvez créer des agrégations autour de l'activité utilisateur. Vous pouvez également utiliser la transformation ApproximateQuantiles pour générer une distribution des temps de réponse.
Étape suivante
- Examinez l'exemple de code dans le dépôt Traiter des journaux à grande échelle à l'aide de Cloud Dataflow sur GitHub.
- Découvrez d'autres solutions d'analyse de journaux.
- Explorez des architectures de référence, des schémas, des tutoriels et des bonnes pratiques concernant Google Cloud. Consultez notre Centre d'architecture cloud.