이 가이드에서는 Cloud Functions를 사용하여 Cloud Storage 버킷에서 BigQuery로 새 객체를 스트리밍하는 방법을 보여 줍니다. Cloud Functions는 프로비저닝, 관리, 업데이트, 패치를 위해 서버 없이 자동 확장, 고가용성, 내결함성을 제공하는 Google Cloud의 이벤트 기반 서버리스 컴퓨팅 플랫폼입니다. Cloud Functions를 통한 스트림 데이터를 사용하면 다른 Google Cloud 서비스를 연결 및 확장하고 앱이 실행될 때만 비용을 지불할 수 있습니다.
이 문서는 Cloud Storage에 추가된 파일에 대해 실시간에 가까운 분석을 실행해야 하는 데이터 분석가, 개발자 또는 운영자를 대상으로 합니다. 이 문서에서는 사용자가 Linux, Cloud Storage, BigQuery에 익숙하다고 가정합니다.
아키텍처
다음 아키텍처 다이어그램은 이 가이드의 스트리밍 파이프라인의 전체 흐름과 모든 구성요소를 보여줍니다. 이 파이프라인에서는 JSON 파일을 Cloud Storage에 업로드해야 하며, 다른 파일 형식을 지원하려면 코드를 약간 변경해야 합니다. 이 문서에서 다른 파일 형식의 수집을 설명하지 않습니다.

앞의 다이어그램에서 파이프라인은 다음과 같은 단계로 구성됩니다.
- JSON 파일은
FILES_SOURCECloud Storage 버킷에 업로드됩니다. - 이 이벤트는
streamingCloud 함수를 트리거합니다. - 데이터가 파싱되어 BigQuery에 삽입됩니다.
- 수집 상태는 Firestore 및 Cloud Logging에 로깅됩니다.
- 메시지가 다음 Pub/Sub 주제 중 하나에 게시됩니다.
streaming_success_topicstreaming_error_topic
- 결과에 따라 Cloud Functions는 JSON 파일을
FILES_SOURCE버킷에서 다음 버킷 중 하나로 이동합니다.FILES_ERRORFILES_SUCCESS
목표
- JSON 파일을 저장할 Cloud Storage 버킷을 만듭니다.
- 데이터를 스트리밍할 BigQuery 데이터 세트와 테이블을 만듭니다.
- 파일이 버킷에 추가될 때마다 트리거하도록 Cloud 함수를 구성합니다.
- Pub/Sub 주제를 설정합니다.
- 함수 출력을 처리할 추가 함수를 구성합니다.
- 스트리밍 파이프라인을 테스트합니다.
- 예기치 않은 동작을 알리도록 Cloud Monitoring을 구성합니다.
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
- Cloud Storage
- Cloud Functions
- Firestore
- BigQuery
- Logging
- Monitoring
- Container Registry
- Cloud Build
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Functions and Cloud Build APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Functions and Cloud Build APIs.
- Google Cloud 콘솔에서 Monitoring으로 이동합니다.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
환경 설정
이 가이드에서는 Cloud Shell을 사용하여 명령어를 입력합니다. Cloud Shell은 Google Cloud 콘솔의 명령줄에 대한 액세스를 제공하며 Google Cloud 개발에 필요한 Cloud CLI와 기타 도구를 포함합니다. Cloud Shell은 Google Cloud 콘솔 하단에 창으로 표시됩니다. 초기화되는 데 몇 분 정도 걸릴 수 있지만 창은 즉시 표시됩니다.
Cloud Shell을 사용하여 환경을 설정하고 이 가이드에서 사용된 git 저장소를 클론하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 Cloud Shell을 엽니다.
방금 만든 프로젝트에서 작업하고 있는지 확인합니다.
[YOUR_PROJECT_ID]를 새로 만든 Google Cloud 프로젝트로 대체합니다.gcloud config set project [YOUR_PROJECT_ID]기본 컴퓨팅 영역을 설정합니다. 이 튜토리얼의 목적에 따라 이 영역은
us-east1입니다. 프로덕션 환경에 배포하는 경우, 선택한 리전에 배포합니다.REGION=us-east1이 가이드에서 사용된 함수가 있는 저장소를 클론합니다.
git clone https://github.com/GoogleCloudPlatform/solutions-gcs-bq-streaming-functions-python cd solutions-gcs-bq-streaming-functions-python
스트리밍 소스 및 대상 싱크 만들기
콘텐츠를 BigQuery로 스트리밍하려면 FILES_SOURCE Cloud Storage 버킷이 있어야 하고 BigQuery에 대상 테이블이 있어야 합니다.
Cloud Storage 버킷 만들기
이 가이드에서 제공하는 스트리밍 파이프라인의 소스를 나타내는 Cloud Storage 버킷을 만듭니다. 이 버킷의 기본 목표는 BigQuery로 스트리밍되는 JSON 파일을 임시로 저장하는 것입니다.
FILES_SOURCECloud Storage 버킷을 만듭니다. 여기서FILES_SOURCE는 고유한 이름이 있는 환경 변수로 설정됩니다.FILES_SOURCE=${DEVSHELL_PROJECT_ID}-files-source-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FILES_SOURCE}
BigQuery 테이블 만들기
이 섹션에서는 파일의 콘텐츠 대상으로 사용되는 BigQuery 테이블을 만듭니다. BigQuery를 사용하면 테이블에 데이터 로드 시 또는 새 테이블 생성 시 테이블의 스키마를 지정할 수 있습니다. 이 섹션에서는 테이블을 만들고 동시에 스키마를 지정합니다.
BigQuery 데이터 세트와 테이블을 만듭니다.
schema.json파일에 정의된 스키마는FILES_SOURCE버킷에서 오는 파일의 스키마와 일치해야 합니다.bq mk mydataset bq mk mydataset.mytable schema.json테이블이 생성되었는지 확인합니다.
bq ls --format=pretty mydataset출력은 다음과 같습니다.
+---------+-------+--------+-------------------+ | tableId | Type | Labels | Time Partitioning | +---------+-------+--------+-------------------+ | mytable | TABLE | | | +---------+-------+--------+-------------------+
BigQuery에 데이터 스트리밍
소스 및 대상 싱크를 만들었습니다. 이제 Cloud Storage에서 BigQuery로 데이터를 스트리밍하는 Cloud 함수를 만듭니다.
스트리밍 Cloud 함수 설정
스트리밍 기능은 FILES_SOURCE 버킷에 추가된 새 파일을 리슨한 후 다음을 수행하는 프로세스를 트리거합니다.
- 파일을 파싱하고 파일 유효성을 검사합니다.
- 중복 여부를 검사합니다.
- 파일 콘텐츠를 BigQuery에 삽입합니다.
- Firestore 및 Logging에서 수집 상태를 로깅합니다.
- Pub/Sub의 오류 또는 성공 주제 중 하나로 메시지를 게시합니다.
함수 배포 단계는 다음과 같습니다.
Cloud Storage 버킷을 만들어 배포하는 동안 함수를 스테이징합니다. 여기서
FUNCTIONS_BUCKET은 고유한 이름이 있는 환경 변수로 설정됩니다.FUNCTIONS_BUCKET=${DEVSHELL_PROJECT_ID}-functions-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FUNCTIONS_BUCKET}streaming함수를 배포합니다. 구현 코드는./functions/streaming폴더에 있습니다. 완료되는 데 몇 분 정도 걸릴 수 있습니다.gcloud functions deploy streaming --region=${REGION} \ --source=./functions/streaming --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-bucket=${FILES_SOURCE}이 코드는 Python으로 작성된 Cloud 함수를 배포하며, 이름은
streaming입니다. 파일이FILES_SOURCE버킷에 추가될 때마다 트리거됩니다.함수가 배포되었는지 확인합니다.
gcloud functions describe streaming --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"출력은 다음과 같습니다.
┌────────────────┬────────┬────────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├────────────────┼────────┼────────────────────────────────┤ │ streaming │ ACTIVE │ google.storage.object.finalize │ └────────────────┴────────┴────────────────────────────────┘
오류 경로를 처리하기 위해
streaming_error_topic이라는 Pub/Sub 주제를 프로비저닝합니다.STREAMING_ERROR_TOPIC=streaming_error_topic gcloud pubsub topics create ${STREAMING_ERROR_TOPIC}성공 경로를 처리하기 위해
streaming_success_topic이라는 Pub/Sub 주제를 프로비저닝합니다.STREAMING_SUCCESS_TOPIC=streaming_success_topic gcloud pubsub topics create ${STREAMING_SUCCESS_TOPIC}
Firestore 데이터베이스 설정
데이터가 BigQuery로 스트리밍되는 동안 각 파일 수집과 관련된 상황을 이해하는 것이 중요합니다. 예를 들어, 부적절하게 가져온 파일이 있다고 가정합니다. 이 경우, 문제의 근본 원인을 파악하고 해결하여 파이프라인이 끝날 때 손상된 데이터와 부정확한 보고서가 생성되지 않도록 해야 합니다. 이전 섹션에서 배포된 streaming 함수는 Firestore 문서에 파일 수집 상태를 저장합니다. 따라서 모든 문제 해결을 위해 최근 오류를 쿼리할 수 있습니다.
Firestore 인스턴스를 만들려면 다음 단계를 따르세요.
Google Cloud Console에서 Firestore로 이동합니다.
Cloud Firestore 모드 선택 창에서 기본 모드 선택을 클릭합니다.
위치 선택 목록에서 nam5(미국)를 선택한 후 데이터베이스 만들기를 클릭합니다. Firestore 초기화가 완료될 때까지 기다립니다. 이 작업은 일반적으로 몇 분 정도 걸립니다.
스트리밍 오류 처리
streaming_error_topic에 게시된 메시지를 리슨하는 또 다른 Cloud 함수를 배포하여 오류 파일을 처리하는 경로를 프로비저닝합니다. 프로덕션 환경에서 이러한 오류를 처리하는 방법은 비즈니스 요구사항에 따라 달라집니다.
이 가이드에서는 문제 해결이 용이하도록 문제가 있는 파일을 다른 Cloud Storage 버킷으로 이동합니다.
문제가 있는 파일을 저장할 Cloud Storage 버킷을 만듭니다.
FILES_ERROR는 오류 파일을 저장하는 버킷의 고유한 이름이 있는 환경 변수로 설정됩니다.FILES_ERROR=${DEVSHELL_PROJECT_ID}-files-error-$(date +%s) gsutil mb -c regional -l ${REGION} gs://${FILES_ERROR}오류 처리를 위해
streaming_error함수를 배포합니다. 이 작업은 몇 분 정도 걸릴 수 있습니다.gcloud functions deploy streaming_error --region=${REGION} \ --source=./functions/move_file \ --entry-point=move_file --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-topic=${STREAMING_ERROR_TOPIC} \ --set-env-vars SOURCE_BUCKET=${FILES_SOURCE},DESTINATION_BUCKET=${FILES_ERROR}이 명령어는
streaming함수를 배포하기 위한 명령어와 비슷합니다. 가장 큰 차이점은 이 명령어에서는 함수가 주제에 게시된 메시지에 의해 트리거되고 환경 변수 두 개(즉, 파일이 복사되는 소스인SOURCE_BUCKET변수와 파일이 복사되는 대상인DESTINATION_BUCKET변수)를 받아들인다는 점입니다.streaming_error함수가 생성되었는지 확인합니다.gcloud functions describe streaming_error --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"출력은 다음과 같습니다.
┌─────────────┬────────┬─────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├─────────────┼────────┼─────────────────────────────┤ │ move_file │ ACTIVE │ google.pubsub.topic.publish │ └─────────────┴────────┴─────────────────────────────┘
성공적인 스트리밍 처리
streaming_success_topic에 게시된 메시지를 리슨하는 세 번째 Cloud 함수를 배포하여 성공 파일을 처리하는 경로를 프로비저닝합니다. 이 가이드에서 성공적으로 수집된 파일은 Coldline Cloud Storage 버킷에 보관됩니다.
Coldline Cloud Storage 버킷을 만듭니다.
FILES_SUCCESS는 성공 파일을 저장하는 버킷의 고유한 이름이 있는 환경 변수로 설정됩니다.FILES_SUCCESS=${DEVSHELL_PROJECT_ID}-files-success-$(date +%s) gsutil mb -c coldline -l ${REGION} gs://${FILES_SUCCESS}성공 처리를 위해
streaming_success함수를 배포합니다. 이 작업은 몇 분 정도 걸릴 수 있습니다.gcloud functions deploy streaming_success --region=${REGION} \ --source=./functions/move_file \ --entry-point=move_file --runtime=python37 \ --stage-bucket=${FUNCTIONS_BUCKET} \ --trigger-topic=${STREAMING_SUCCESS_TOPIC} \ --set-env-vars SOURCE_BUCKET=${FILES_SOURCE},DESTINATION_BUCKET=${FILES_SUCCESS}함수가 생성되었는지 확인합니다.
gcloud functions describe streaming_success --region=${REGION} \ --format="table[box](entryPoint, status, eventTrigger.eventType)"출력은 다음과 같습니다.
┌─────────────┬────────┬─────────────────────────────┐ │ ENTRY_POINT │ STATUS │ EVENT_TYPE │ ├─────────────┼────────┼─────────────────────────────┤ │ move_file │ ACTIVE │ google.pubsub.topic.publish │ └─────────────┴────────┴─────────────────────────────┘
스트리밍 파이프라인 테스트
이 시점에서 스트리밍 파이프라인 생성이 완료되었습니다. 이제는 서로 다른 경로를 테스트할 차례입니다. 먼저 새 파일의 수집, 중복 파일의 수집, 문제가 있는 파일의 수집을 차례대로 테스트합니다.
새 파일 수집
새 파일의 수집을 테스트하려면 업로드하는 파일이 전체 파이프라인을 성공적으로 통과해야 합니다. 모든 것이 올바르게 작동하는지 확인하기 위해서는 모든 스토리지 항목인 BigQuery, Firestore, Cloud Storage 버킷을 확인해야 합니다.
data.json파일을FILES_SOURCE버킷에 업로드합니다.gsutil cp test_files/data.json gs://${FILES_SOURCE}출력은 다음과 같습니다.
Operation completed over 1 objects/312.0 B.
BigQuery로 데이터를 쿼리합니다.
bq query 'select first_name, last_name, dob from mydataset.mytable'이 명령어는
data.json파일의 콘텐츠를 출력합니다.+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
Google Cloud 콘솔에서 Firestore 페이지로 이동합니다.
/ > streaming_files > data.json 문서로 이동하여 success: true 필드가 있는지 확인합니다.
streaming함수는 파일 상태를 streaming_files라는 컬렉션에 저장하고 파일 이름을 문서 ID로 사용합니다.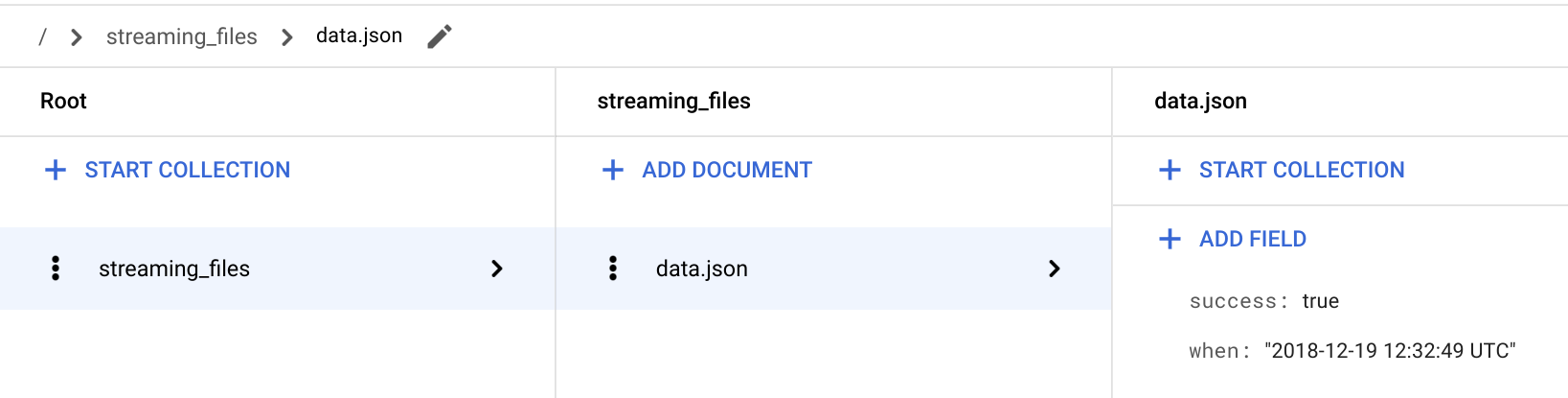
Cloud Shell로 돌아갑니다.
수집된 파일이
streaming_success함수에 의해FILES_SOURCE버킷에서 삭제되었는지 확인합니다.gsutil ls -l gs://${FILES_SOURCE}/data.json파일이
FILES_SOURCE에 더 이상 존재하지 않기 때문에 출력은CommandException입니다.수집된 파일이 현재
FILES_SUCCESS버킷에 있는지 확인합니다.gsutil ls -l gs://${FILES_SUCCESS}/data.json출력은 다음과 같습니다.
TOTAL: 1 objects, 312 bytes.
기존에 처리된 파일 수집
파일 이름은 Firestore에서 문서 ID로 사용됩니다. 따라서 지정된 파일이 처리되었는지 여부를 streaming 함수에서 쉽게 쿼리할 수 있습니다.
파일이 이전에 성공적으로 수집된 경우에 새로 파일을 추가하려 하면 BigQuery에서 정보를 복제하여 부정확한 보고서가 생성되므로 무시됩니다.
이 섹션에서는 중복 파일이 FILES_SOURCE 버킷에 업로드되는 경우에 파이프라인이 예상대로 작동하는지 확인합니다.
동일한
data.json파일을FILES_SOURCE버킷에 다시 업로드합니다.gsutil cp test_files/data.json gs://${FILES_SOURCE}출력은 다음과 같습니다.
Operation completed over 1 objects/312.0 B.
BigQuery를 쿼리하면 이전과 동일한 결과가 반환됩니다. 하지만 이는 파이프라인에서 파일을 처리했지만 파일이 이전에 수집되었으므로, 파일 콘텐츠가 BigQuery에 삽입되지 않았다는 의미입니다.
bq query 'select first_name, last_name, dob from mydataset.mytable'출력은 다음과 같습니다.
+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
Google Cloud 콘솔에서 Firestore 페이지로 이동합니다.
/ > streaming_files > data.json 문서에서 새로운
**duplication_attempts**필드가 추가되었는지 확인합니다.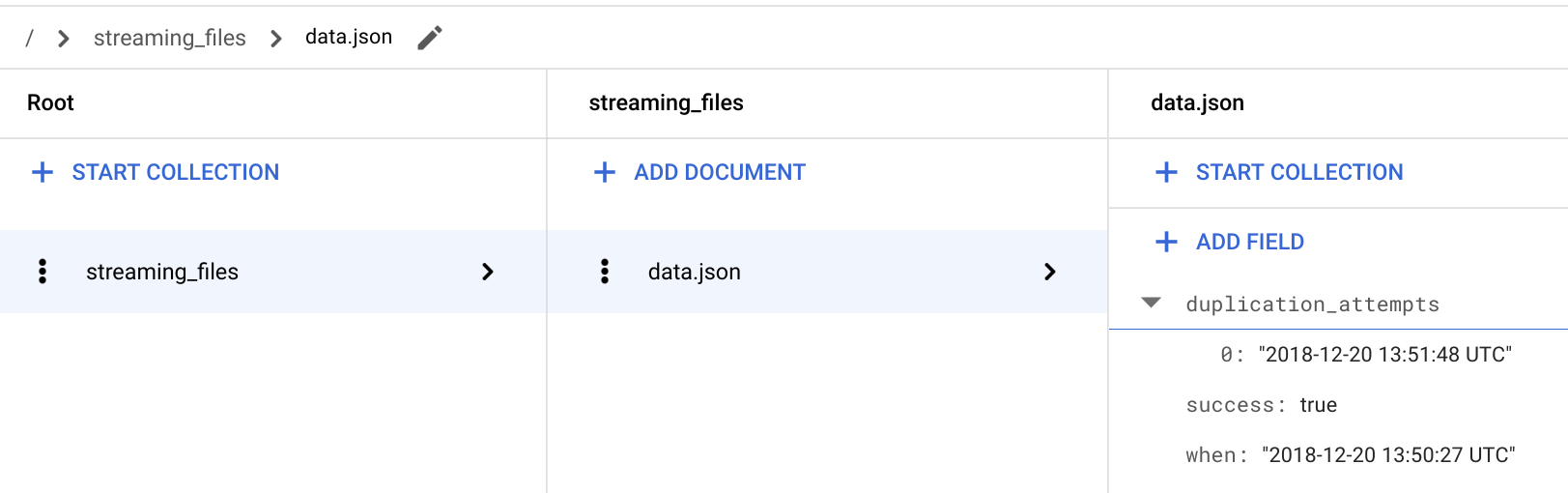
이전에 성공적으로 처리된 것과 동일한 이름으로 파일이
FILES_SOURCE버킷에 추가될 때마다 파일 내용이 무시되고 새로운 중복 시도가 Firestore의**duplication_attempts**필드에 추가됩니다.Cloud Shell로 돌아갑니다.
중복된 파일이 여전히
FILES_SOURCE버킷에 있는지 확인합니다.gsutil ls -l gs://${FILES_SOURCE}/data.json출력은 다음과 같습니다.
TOTAL: 1 objects, 312 bytes.
복제 시나리오에서
streaming함수는 예기치 않은 동작을 Logging에 로깅하고, 수집을 무시하고, 파일을 나중에 분석할 수 있도록FILES_SOURCE버킷에 남겨 둡니다.
오류가 있는 파일 수집
스트리밍 파이프라인이 작동 중이고 복제본이 BigQuery에 수집되지 않음을 확인했습니다. 이제는 오류 경로를 확인할 차례입니다.
data_error.json을FILES_SOURCE버킷에 업로드합니다.gsutil cp test_files/data_error.json gs://${FILES_SOURCE}출력은 다음과 같습니다.
Operation completed over 1 objects/311.0 B.
BigQuery를 쿼리하면 이전과 동일한 결과가 반환됩니다. 이는 파이프라인에서 파일을 처리했지만 콘텐츠가 필요한 스키마를 준수하지 않아 BigQuery에 삽입되지 않았다는 의미입니다.
bq query 'select first_name, last_name, dob from mydataset.mytable'출력은 다음과 같습니다.
+------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | +------------+-----------+------------+
Google Cloud 콘솔에서 Firestore 페이지로 이동합니다.
/ > streaming_files > data_error.json 문서에서 success: false 필드가 추가되었는지 확인합니다.
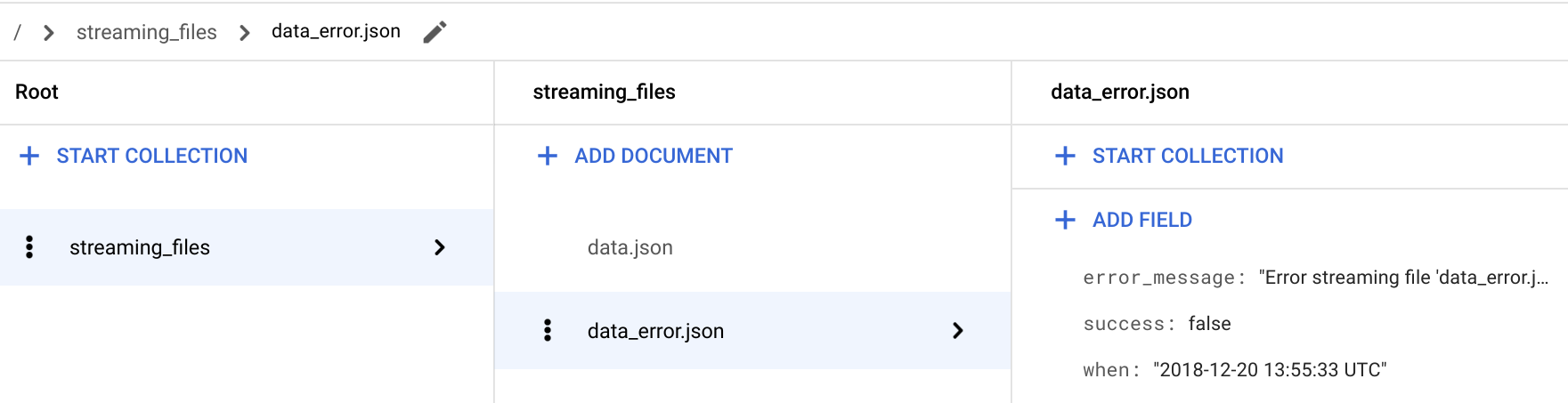
오류가 있는 파일의 경우
streaming함수는error_message필드도 저장하며, 이 필드는 파일이 수집되지 않은 이유에 대한 자세한 정보를 제공합니다.Cloud Shell로 돌아갑니다.
파일이
streaming_error함수에 의해FILES_SOURCE버킷에서 삭제되었는지 확인합니다.gsutil ls -l gs://${FILES_SOURCE}/data_error.json파일이
FILES_SOURCE에 더 이상 존재하지 않기 때문에 출력은CommandException입니다.파일이 예상대로
FILES_ERROR버킷에 있는지 확인합니다.gsutil ls -l gs://${FILES_ERROR}/data_error.json출력은 다음과 같습니다.
TOTAL: 1 objects, 311 bytes.
데이터 수집 문제 찾기 및 해결
Firestore의 streaming_files 컬렉션에 대해 쿼리를 실행하면 문제를 신속하게 진단하고 해결할 수 있습니다. 이 섹션에서는 Firestore용 표준 Python API를 사용하여 모든 오류 파일을 필터링합니다.
사용자 환경에서 쿼리 결과를 확인하려면 다음 단계를 따르세요.
firestore폴더에 가상 환경을 만듭니다.pip install virtualenv virtualenv firestore source firestore/bin/activate가상 환경에 Python Firestore 모듈을 설치합니다.
pip install google-cloud-firestore기존 파이프라인 문제를 시각화합니다.
python firestore/show_streaming_errors.pyshow_streaming_errors.py파일에는 Firestore 쿼리와 결과를 반복하고 출력 형식을 지정하는 데 필요한 상용구가 포함되어 있습니다. 위의 명령어를 실행하면 다음과 비슷한 출력이 표시됩니다.+-----------------+-------------------------+----------------------------------------------------------------------------------+ | File Name | When | Error Message | +-----------------+-------------------------+----------------------------------------------------------------------------------+ | data_error.json | 2019-01-22 11:31:58 UTC | Error streaming file 'data_error.json'. Cause: Traceback (most recent call las.. | +-----------------+-------------------------+----------------------------------------------------------------------------------+
분석을 마치면 가상 환경을 중지합니다.
deactivate문제가 있는 파일을 찾아 해결한 후에는 해당 파일을 같은 파일 이름으로
FILES_SOURCE버킷에 다시 업로드합니다. 이러한 과정을 통해 파일이 전체 스트리밍 파이프라인을 통과하여 콘텐츠가 BigQuery에 삽입되게 됩니다.
예기치 않은 동작 알림
프로덕션 환경에서는 모니터링하고 예기치 않은 일이 발생할 때마다 알리는 것이 중요합니다. 여러 Logging 기능 중 하나는 커스텀 측정항목입니다. 커스텀 측정항목을 사용하면 측정항목이 지정된 기준을 충족할 때 자신과 팀에게 알리도록 알림 정책을 만들 수 있습니다.
이 섹션에서는 파일 수집이 실패할 때마다 이메일 알림을 보내도록 Monitoring을 구성합니다. 실패한 수집을 식별하기 위해 다음 구성에서는 기본 Python logging.error(..) 메시지를 사용합니다.
Google Cloud 콘솔에서 로그 기반 측정항목 페이지로 이동합니다.
측정항목 만들기를 클릭합니다.
필터 목록에서 고급 필터로 변환을 선택합니다.
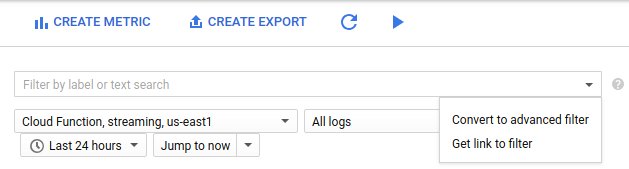
고급 필터에서 다음 구성을 붙여넣습니다.
resource.type="cloud_function" resource.labels.function_name="streaming" resource.labels.region="us-east1" "Error streaming file "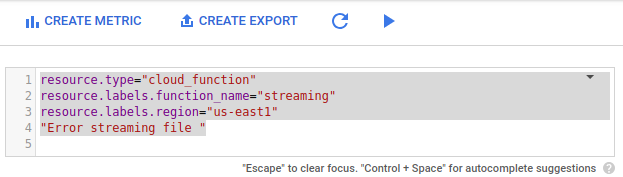
측정항목 편집기 에서 다음 필드를 입력한 후 측정항목 만들기를 클릭합니다.
- 이름 필드에
streaming-error를 입력합니다. - 라벨 섹션에서
payload_error를 이름 필드에 입력합니다. - 라벨 유형 목록에서 문자열을 선택합니다.
- 필드 이름 목록에서 textPayload를 선택합니다.
- 추출 정규 표현식 필드에
(Error streaming file '.*'.)을 입력합니다. 유형 목록에서 카운터를 선택합니다.
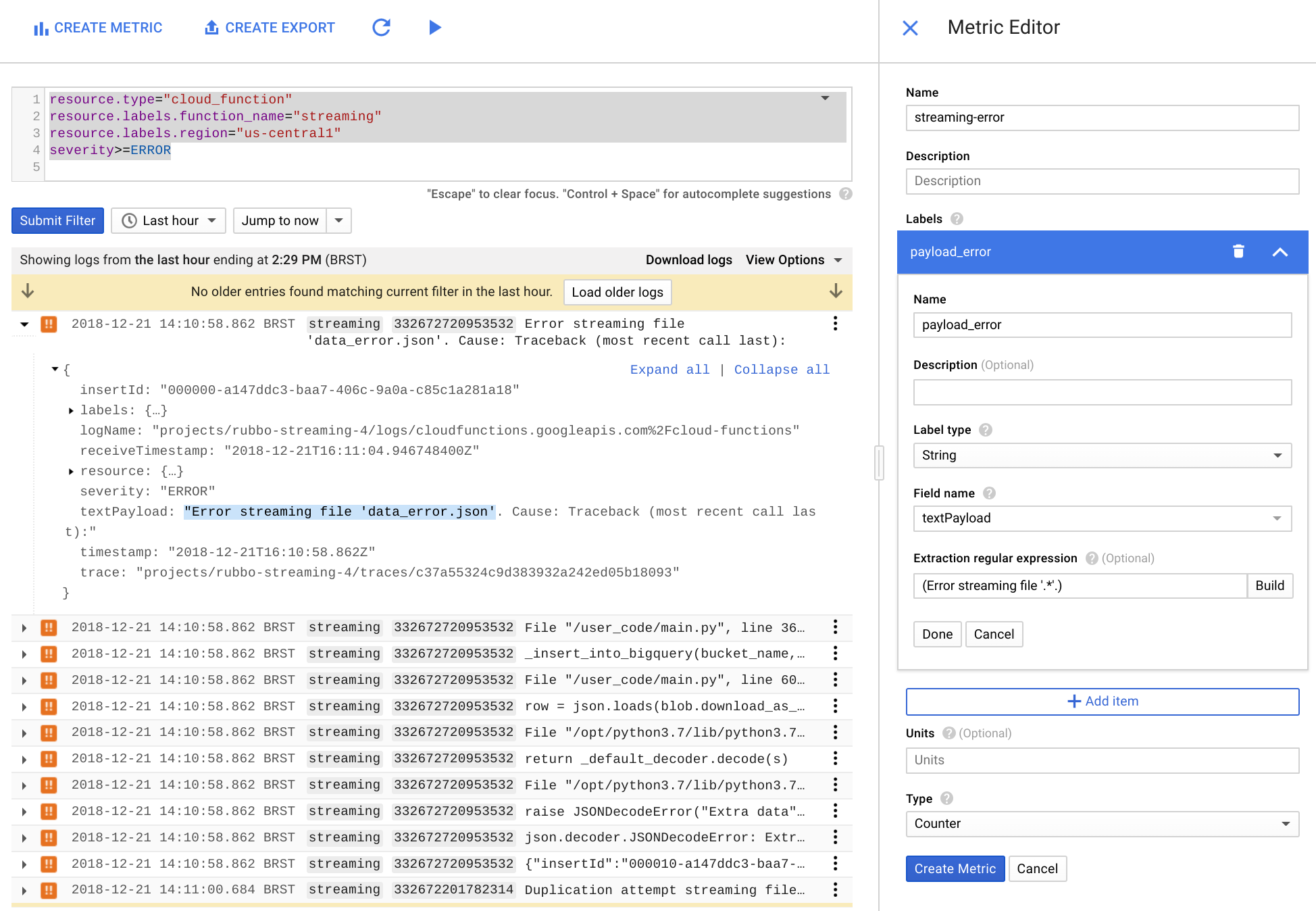
- 이름 필드에
Google Cloud Console에서 Monitoring으로 이동하거나 다음 버튼을 사용합니다.
Monitoring 탐색창에서 notifications 알림을 선택한 후 정책 만들기를 선택합니다.
이 정책 이름 지정 필드에
streaming-error-alert를 입력합니다.조건 추가를 클릭합니다.
- 제목 필드에
streaming-error-condition을 입력합니다. - 측정항목 필드에
logging/user/streaming-error를 입력합니다. - 다음 조건의 경우 트리거 목록에서 시계열 위반을 선택합니다.
- 조건 목록에서 초과 시를 선택합니다.
- 임곗값 필드에
0을 입력합니다. - 시간 목록에서 1분을 선택합니다.
- 제목 필드에
알림 채널 유형 목록에서 이메일을 선택하고 이메일 주소를 입력한 후 알림 채널 추가를 클릭합니다.
(선택사항) 문서를 클릭하고 알림 메시지에 포함할 정보를 추가합니다.
저장을 클릭합니다.
알림 정책을 저장한 후 Monitoring은 streaming 함수 오류 로그를 모니터링하고 1분 간격으로 스트리밍 오류가 발생할 때마다 이메일 알림을 보냅니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
프로젝트 삭제
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- 이벤트 및 트리거를 검토하여 Google Cloud에서 서버리스 함수를 트리거하는 다른 방법 알아보기
- 알림 페이지에 방문하여 이 가이드에 정의된 알림 정책 개선 방법 알아보기
- Firestore 문서를 참조하여 이 전역 스케일의 NoSQL 데이터베이스 알아보기
- BigQuery 할당량 및 제한 페이지를 방문하여 프로덕션 환경에서 이 솔루션 구현 시 스트리밍 삽입 제한 이해하기
- Cloud Functions 할당량 및 제한 페이지를 방문하여 배포된 함수가 처리할 수 있는 최대 크기 이해하기
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 가이드, 권장사항 살펴보기 Cloud 아키텍처 센터 살펴보세요.