이 문서에서는 확장 가능한 TensorFlow 추론 시스템 배포에서 만든 TensorFlow 추론 시스템의 성능을 측정하는 방법을 설명합니다. 또한 매개변수 조정을 적용해서 시스템 처리량을 향상시키는 방법을 보여줍니다.
배포는 확장 가능한 TensorFlow 추론 시스템에 설명된 참조 아키텍처를 기반으로 합니다.
이 시리즈는 TensorFlow 및 TensorRT를 포함하여 Google Kubernetes Engine 및 머신러닝(ML) 프레임워크에 익숙한 개발자를 대상으로 합니다.
이 문서에서는 특정 시스템의 성능 데이터를 제공하지 않습니다. 대신 성능 측정 프로세스의 일반 안내를 제공합니다. 초당 총 요청 수(RPS) 및 응답 시간(밀리초)과 같이 표시되는 성능 측정항목은 학습된 모델, 소프트웨어 버전, 사용되는 하드웨어 구성에 따라 달라집니다.
아키텍처
TensorFlow 추론 시스템의 아키텍처 개요는 확장 가능한 TensorFlow 추론 시스템을 참조하세요.
목표
- 성능 목표와 측정항목 정의
- 기준 성능 측정
- 그래프 최적화 수행
- FP16 변환 측정
- INT8 양자화 측정
- 인스턴스 수 조정
비용
배포 관련 비용에 대한 자세한 내용은 비용을 참조하세요.
이 문서에 설명된 태스크를 완료했으면 만든 리소스를 삭제하여 청구가 계속되는 것을 방지할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
확장 가능한 TensorFlow 추론 시스템 배포의 단계를 완료했는지 확인합니다.
이 문서에서는 다음 도구를 사용합니다.
- 작업 환경 만들기에서 준비한 작업 인스턴스의 SSH 터미널
- Prometheus 및 Grafana로 모니터링 서버 배포에서 준비한 Grafana 대시보드
- 부하 테스트 도구 배포에서 준비한 Locust 콘솔
디렉터리 설정
Google Cloud 콘솔에서 Compute Engine > VM 인스턴스로 이동합니다.
사용자가 만든
working-vm인스턴스가 표시됩니다.인스턴스의 터미널 콘솔을 열려면 SSH를 클릭합니다.
SSH 터미널에서 현재 디렉터리를
client하위 디렉터리로 설정합니다.cd $HOME/gke-tensorflow-inference-system-tutorial/client이 문서에서는 이 디렉터리의 모든 명령어를 실행합니다.
성능 목표 정의
추론 시스템 성능을 측정하는 경우 시스템 사용 사례에 따라 성능 목표와 적절한 성능 측정항목을 정의해야 합니다. 이 문서에서는 시연 목적으로 다음과 같은 성능 목표를 사용합니다.
- 요청의 95% 이상이 100밀리초 이내에 응답을 수신합니다.
- 초당 요청 수(RPS)로 표시되는 총 처리량은 이전 목표에 영향을 주지 않고 증가합니다.
이러한 가정을 사용하여 서로 다른 최적화를 통해 다음 ResNet-50 모델의 처리량을 측정하고 늘립니다. 클라이언트가 추론 요청을 보낼 때 이 표의 모델 이름을 사용하여 모델을 지정합니다.
| 모델 이름 | 최적화 |
|---|---|
original |
원본 모델(TF-TRT를 사용한 최적화 없음) |
tftrt_fp32 |
그래프 최적화 (배치 크기: 64, 인스턴스 그룹: 1) |
tftrt_fp16 |
그래프 최적화 외에 FP16으로 변환 (배치 크기: 64, 인스턴스 그룹: 1) |
tftrt_int8 |
그래프 최적화 외에 INT8을 사용한 양자화 (배치 크기: 64, 인스턴스 그룹: 1) |
tftrt_int8_bs16_count4 |
그래프 최적화 외에 INT8을 사용한 양자화 (배치 크기: 16, 인스턴스 그룹: 4) |
기준 성능 측정
먼저 TF-TRT를 기준으로 사용하여 최적화되지 않은 원본 모델의 성능을 측정합니다. 성능 향상을 정량적으로 평가하기 위해 다른 모델의 성능을 원본과 비교합니다. Locust를 배포하는 경우 이미 원본 모델에 대한 요청을 보내도록 구성되었습니다.
부하 테스트 도구 배포에서 준비한 Locust 콘솔을 엽니다.
클라이언트 수(슬레이브라고 함)가 10인지 확인합니다.
수가 10 미만이면 클라이언트는 계속 시작됩니다. 이 경우 10이 될 때까지 몇 분 정도 기다립니다.
성능을 측정합니다.
- 시뮬레이션할 사용자 수 필드에
3000을 입력합니다. - 해치 비율 필드에
5를 입력합니다. - 3,000에 도달할 때까지 시뮬레이션 사용 횟수를 초당 5회씩 늘리려면 생성 시작을 클릭합니다.
- 시뮬레이션할 사용자 수 필드에
차트를 클릭합니다.
그래프에 성능 결과가 표시됩니다. 초당 총 요청 수 값이 선형적으로 증가하고 응답 시간(밀리초) 값이 그에 따라 증가합니다.
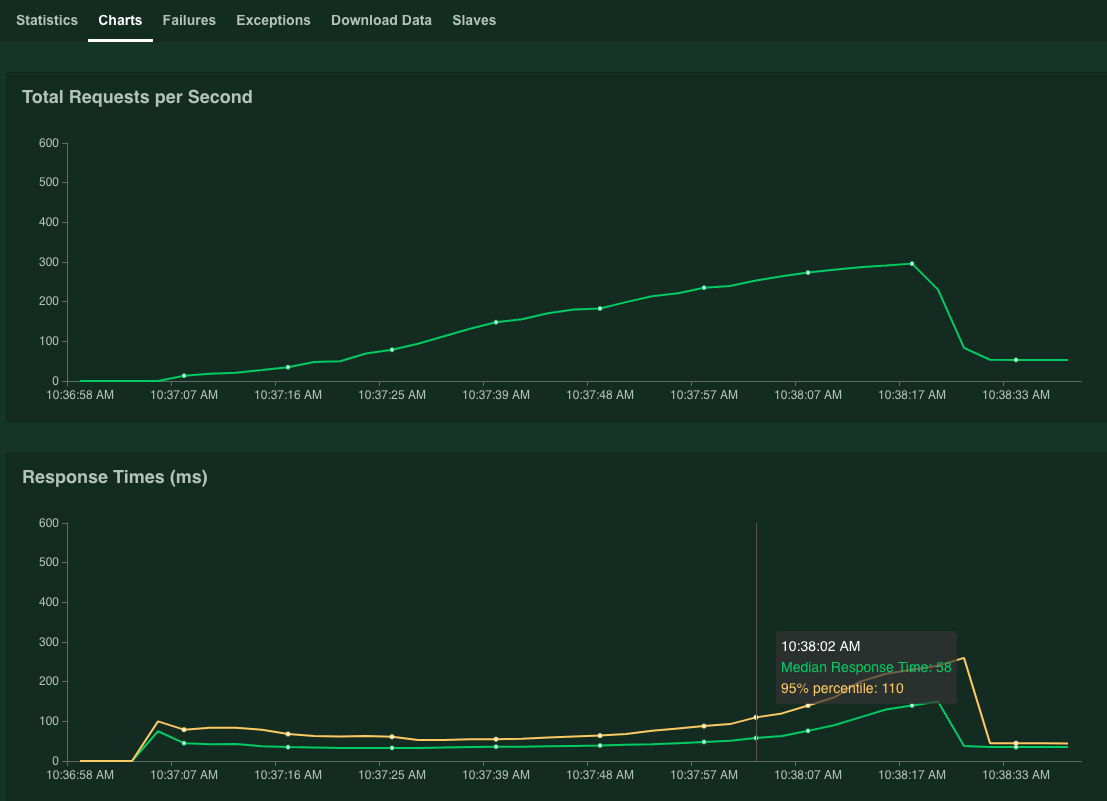
95% percentile of Response Times(응답 시간의 95% 백분위수) 값이 100ms를 초과하면 Stop(중지)을 클릭하여 시뮬레이션을 중지합니다.
그래프 위로 포인터를 가져가면 응답 시간의 95% 백분위수 값이 100ms를 초과한 시점에 해당하는 초당 요청 수를 확인할 수 있습니다.
예를 들어 다음 스크린샷에서 초당 요청 수는 253.1입니다.
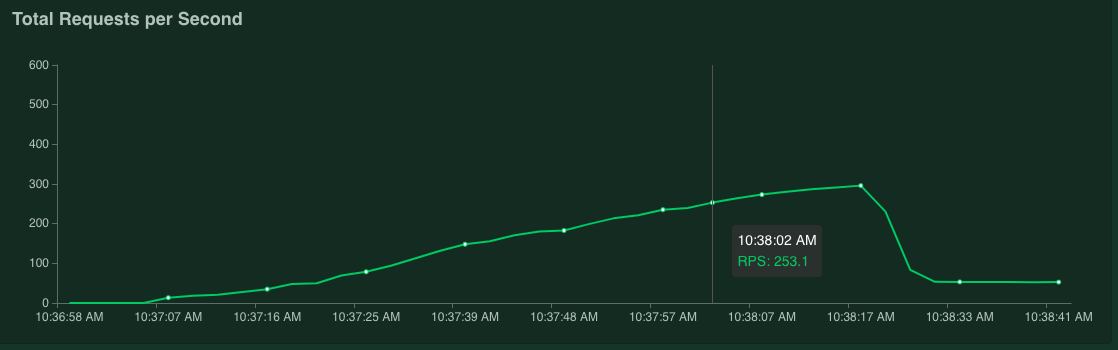
이 측정은 변동을 고려하여 여러 번 반복하고 평균을 반영하는 것이 좋습니다.
SSH 터미널에서 Locust를 재시작합니다.
kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust측정을 반복하려면 이 절차를 반복합니다.
그래프 최적화
이 섹션에서는 그래프 최적화를 위해 TF-TRT를 사용해서 최적화된 tftrt_fp32 모델의 성능을 측정합니다. 이는 대부분의 NVIDIA GPU 카드와 호환되는 일반적인 최적화입니다.
SSH 터미널에서 부하 테스트 도구를 재시작합니다.
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp32 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustconfigmap리소스는 모델을tftrt_fp32로 지정합니다.Triton 서버를 다시 시작합니다.
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1서버 프로세스가 준비될 때까지 몇 분 정도 기다립니다.
서버 상태를 확인합니다.
kubectl get pods출력은 다음과 비슷합니다. 여기서
READY열은 서버 상태를 표시합니다.NAME READY STATUS RESTARTS AGE inference-server-74b85c8c84-r5xhm 1/1 Running 0 46sREADY열의1/1값은 서버가 준비되었음을 나타냅니다.성능을 측정합니다.
- 시뮬레이션할 사용자 수 필드에
3000을 입력합니다. - 해치 비율 필드에
5를 입력합니다. - 3,000에 도달할 때까지 시뮬레이션 사용 횟수를 초당 5회씩 늘리려면 생성 시작을 클릭합니다.
그래프는 TF-TRT 그래프 최적화의 성능 개선을 보여줍니다.
예를 들어 그래프에는 초당 요청 수가 이제 381이고 응답 시간 중앙값은 59밀리초로 표시될 수 있습니다.
- 시뮬레이션할 사용자 수 필드에
FP16으로 변환
이 섹션에서는 그래프 최적화와 FP16 변환에 TF-TRT를 사용하여 최적화된 tftrt_fp16 모델의 성능을 측정합니다. 이는 NVIDIA T4에서 사용할 수 있는 최적화입니다.
SSH 터미널에서 부하 테스트 도구를 재시작합니다.
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp16 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustTriton 서버를 다시 시작합니다.
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1서버 프로세스가 준비될 때까지 몇 분 정도 기다립니다.
성능을 측정합니다.
- 시뮬레이션할 사용자 수 필드에
3000을 입력합니다. - 해치 비율 필드에
5를 입력합니다. - 3,000에 도달할 때까지 시뮬레이션 사용 횟수를 초당 5회씩 늘리려면 생성 시작을 클릭합니다.
그래프는 TF-TRT 그래프 최적화 외에도 FP16 변환의 성능 개선을 보여줍니다.
예를 들어 그래프에서 초당 요청 수가 1072.5이고 응답 시간 중앙값이 63밀리초로 표시될 수 있습니다.
- 시뮬레이션할 사용자 수 필드에
INT8을 사용한 양자화
이 섹션에서는 그래프 최적화와 INT8 양자화에 TF-TRT를 사용하여 최적화된 tftrt_int8 모델의 성능을 측정합니다. 이 최적화를 NVIDIA T4에서 사용할 수 있습니다.
SSH 터미널에서 부하 테스트 도구를 재시작합니다.
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustTriton 서버를 다시 시작합니다.
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1서버 프로세스가 준비될 때까지 몇 분 정도 기다립니다.
성능을 측정합니다.
- 시뮬레이션할 사용자 수 필드에
3000을 입력합니다. - 해치 비율 필드에
5를 입력합니다. - 3,000에 도달할 때까지 시뮬레이션 사용 횟수를 초당 5회씩 늘리려면 생성 시작을 클릭합니다.
그래프에 성능 결과가 표시됩니다.
예를 들어 그래프에서 초당 요청 수가 1085.4이고 응답 시간 중앙값이 32밀리초로 표시될 수 있습니다.
이 예시에서 결과는 FP16 변환과 비교할 때 성능이 크게 증가하지 않았습니다. 이론적으로 NVIDIA T4 GPU는 FP16 변환 모델보다 더 빠르게 INT8 양자화 모델을 처리할 수 있습니다. 이 경우 GPU 성능 이외의 병목 현상이 발생할 수 있습니다. Grafana 대시보드의 GPU 사용률 데이터에서 이를 확인할 수 있습니다. 예를 들어 사용률이 40%보다 작으면 모델이 GPU 성능을 완전히 사용할 수 없음을 의미합니다.
다음 섹션에서 볼 수 있듯이 인스턴스 그룹 수를 늘려 이러한 병목 현상을 완화할 수 있습니다. 예를 들어 인스턴스 그룹 수를 1에서 4로 늘리고 배치 크기를 64에서 16으로 줄입니다. 이 방식은 단일 GPU에서 처리되는 총 요청 수를 64로 유지합니다.
- 시뮬레이션할 사용자 수 필드에
인스턴스 수 조정
이 섹션에서는 tftrt_int8_bs16_count4 모델의 성능을 측정합니다. 이 모델은 tftrt_int8와 구조가 동일하지만 INT8로 양자화에 설명된 것처럼 배치 크기와 인스턴스 그룹 수를 변경합니다.
SSH 터미널에서 Locust를 재시작합니다.
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8_bs16_count4 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust kubectl scale deployment/locust-slave --replicas=20 -n locust이 명령어에서는
configmap리소스를 사용하여 모델을tftrt_int8_bs16_count4로 지정합니다. 또한 Locust 클라이언트 Pod 수를 늘려 모델의 성능 제한을 측정할 수 있는 충분한 워크로드를 생성합니다.Triton 서버를 다시 시작합니다.
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1서버 프로세스가 준비될 때까지 몇 분 정도 기다립니다.
성능을 측정합니다.
- 시뮬레이션할 사용자 수 필드에
3000을 입력합니다. - 해치 비율 필드에
15를 입력합니다. 이 모델에서는 해치 비율이5로 설정된 경우 성능 한도에 도달하는 데 오랜 시간이 걸릴 수 있습니다. - 3,000에 도달할 때까지 시뮬레이션 사용 횟수를 초당 5회씩 늘리려면 생성 시작을 클릭합니다.
그래프에 성능 결과가 표시됩니다.
예를 들어 그래프에서 초당 요청 수가 2236.6이고 응답 시간 중앙값이 38밀리초로 표시될 수 있습니다.
인스턴스 수를 조정하면 초당 요청 수를 거의 두 배로 늘릴 수 있습니다. GPU 사용률이 Grafana 대시보드에서 증가한 것을 확인할 수 있습니다(예: 사용률 75% 증가).
- 시뮬레이션할 사용자 수 필드에
성능 및 여러 노드
노드 여러 개로 확장할 경우 단일 포드의 성능을 측정합니다. 추론 프로세스는 공유 없는 방식으로 여러 Pod에서 독립적으로 실행되므로 총 처리량이 Pod 수에 따라 선형적으로 확장된다고 가정할 수 있습니다. 이러한 가정은 클라이언트와 추론 서버 사이의 네트워크 대역폭과 같은 병목 현상이 없는 한 적용됩니다.
하지만 추론 요청이 여러 추론 서버에 어떻게 균형을 이루는지 이해하는 것이 중요합니다. Triton은 gRPC 프로토콜을 사용하여 클라이언트와 서버 간의 TCP 연결을 설정합니다. Triton은 추론 요청 여러 개를 보내기 위해 설정된 연결을 재사용하므로 단일 클라이언트의 요청은 항상 동일한 서버로 전송됩니다. 서버 여러 개에 대한 요청을 배포하려면 클라이언트 여러 개를 사용해야 합니다.
삭제
이 시리즈에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 프로젝트를 삭제하면 됩니다.
프로젝트 삭제
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- 예측을 위한 컴퓨팅 리소스 구성 방법 알아보기
- Google Kubernetes Engine(GKE) 자세히 알아보기
- Cloud Load Balancing 알아보기
- 그 밖의 참조 아키텍처, 다이어그램, 튜토리얼, 권장사항을 알아보려면 클라우드 아키텍처 센터를 확인하세요.