O OpenCensus é um projeto gratuito e de código aberto com bibliotecas que:
- Fornecer suporte independente de fornecedor para a coleta de dados de métricas e traces em vários idiomas.
- É possível exportar os dados coletados para vários aplicativos de back-end, incluindo o Cloud Monitoring, usando exportadores.
Embora o Cloud Monitoring forneça uma API compatível com a definição e a coleta de métricas definidas pelo usuário, ele é uma API reservada de baixo nível. O OpenCensus oferece uma API que segue o estilo da comunidade de linguagem, além de um exportador que envia os dados de métricas para o Cloud Monitoring por meio da API Monitoring.
O OpenCensus também tem um bom suporte para o rastreamento de aplicativos. Veja OpenCensus Tracing (em inglês) para ter uma visão geral. O Cloud Trace recomenda o uso do OpenCensus para instrumentação de rastreamento. Para coletar dados de métricas e traces dos seus serviços, é possível usar uma única distribuição de bibliotecas. Para informações sobre como usar o OpenCensus com Cloud Trace, consulte Bibliotecas de cliente para o Trace.
Antes de começar
Para usar o Cloud Monitoring, você precisa ter um projeto do Google Cloud com faturamento ativado. Se necessário, faça o seguinte:
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
- Verifique se a API Monitoring está ativada. Para ver detalhes, leia Como ativar a API Monitoring.
Seu projeto do Google Cloud precisa autenticar o aplicativo de aplicativos executados fora do Google Cloud. Normalmente, você configura a autenticação criando uma conta de serviço para o projeto e uma variável de ambiente.
Para aplicativos executados em uma instância do Amazon Elastic Compute Cloud (Amazon EC2), crie a conta de serviço para o projeto do conector da AWS da instância.
Para informações sobre como criar uma conta de serviço, consulte Primeiros passos na autenticação.
Instale o OpenCensus
Para usar as métricas coletadas pelo OpenCensus no seu projeto do Google Cloud, é preciso disponibilizar as bibliotecas de métricas do OpenCensus e o exportador do Stackdriver para o aplicativo. O exportador do Stackdriver exporta as métricas que o OpenCensus coleta para seu projeto do Google Cloud. É possível usar o Cloud Monitoring para criar gráficos ou monitorar essas métricas.
Go
Para autenticar no Monitoring, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
O uso do OpenCensus requer o Go versão 1.11 ou mais recente. As dependências são tratadas automaticamente para você.Java
Para autenticar no Monitoring, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Para o Maven, adicione o seguinte ao elementodependencies no seu
arquivo pom.xml:
Node.js
Para autenticar no Monitoring, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
- Antes de instalar as bibliotecas do núcleo e do exportador do OpenCensus, prepare seu ambiente para o desenvolvimento do Node.js.
- A maneira mais fácil de instalar o OpenCensus é com o npm:
npm install @opencensus/core npm install @opencensus/exporter-stackdriver
- Coloque as instruções
requiremostradas abaixo na parte superior do script principal ou do ponto de entrada do seu aplicativo, antes de qualquer outro código:
Python
Para autenticar no Monitoring, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Instale as bibliotecas do núcleo do OpenCensus e do exportador do Stackdriver usando o seguinte comando:pip install -r opencensus/requirements.txt
O arquivo requirements.txt está no repositório do GitHub para essas amostras,
python-docs-samples.
Gravar métricas definidas pelo usuário com o OpenCensus
Instrumentar seu código para usar o OpenCensus para métricas envolve três etapas:
- Importar as estatísticas do OpenCensus e os pacotes exportadores do OpenCensus Stackdriver.
- Inicialize o exportador do Stackdriver.
- Use a API OpenCensus para instrumentar seu código.
O exemplo a seguir é um programa mínimo que grava dados de métricas usando o OpenCensus. O programa executa um loop e coleta as medidas de latência e, quando o loop termina, exporta as estatísticas para o Cloud Monitoring e é encerrado:
Go
Para autenticar no Monitoring, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Java
Para autenticar no Monitoring, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para autenticar no Monitoring, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para autenticar no Monitoring, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
O programa cria uma visualização do OpenCensus chamada task_latency_distribution. Essa string se torna parte do nome da métrica quando é exportada para o Cloud Monitoring. Consulte Como recuperar descritores de métrica para ver como a visualização do OpenCensus é notada como um descritor de métrica do Cloud Monitoring.
Portanto, use o nome da visualização como uma string de pesquisa ao selecionar uma métrica para o gráfico.
-
No painel de navegação do console do Google Cloud, selecione Monitoramento e leaderboard Metrics Explorer:
- No elemento Métrica, expanda o menu Selecionar uma métrica,
digite
OpenCensus/task_latency_distributionna barra de filtro e use os submenus para selecionar um tipo de recurso e métrica específicos:- No menu Recursos ativos, selecione o recurso monitorado. Se você executar o programa em um ambiente local, selecione Global.
- No menu Categorias de métricas ativas, selecione Personalizado.
- No menu Métricas ativas, selecione Distribuição de latência da tarefa.
- Clique em Aplicar.
A captura de tela a seguir mostra a série temporal coletada depois de executar o programa em um ambiente local:
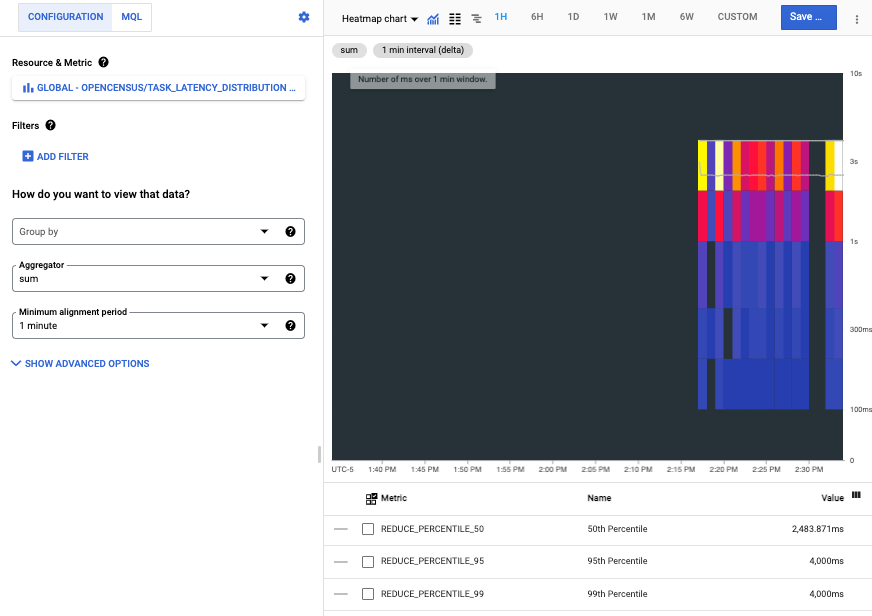
Cada barra no mapa de calor representa uma execução do programa, e os componentes coloridos de cada barra representam os buckets na distribuição de latência.
Ler métricas do OpenCensus no Cloud Monitoring
Você usa métricas definidas pelo usuário, incluindo aquelas escritas pelo OpenCensus, como métricas integradas. É possível criar gráficos, definir alertas, ler e monitorar os alertas.
Esta seção mostra como usar o APIs Explorer para ler dados de métricas. Para informações sobre como ler dados de métricas usando a API Cloud Monitoring ou bibliotecas de cliente, consulte os seguintes documentos:
- Listar tipos de métricas e recursos explica como listar e examinar os tipos de recursos e de métricas no sistema.
- O artigo Recuperar dados de séries temporais explica como recuperar dados de série temporal de métricas usando a API Monitoring.
Por exemplo, a captura de tela mostrada na seção anterior é do Metrics Explorer. Ao usar ferramentas de gráfico, recomendamos que você use o nome da visualização do OpenCensus para filtrar a lista de métricas. Para mais informações, consulte Selecionar métricas ao usar o Metrics Explorer.
Recuperar descritores de métrica
Para recuperar os dados da métrica usando diretamente a API Monitoring, é preciso conhecer os nomes do Cloud Monitoring para os quais as métricas do OpenCensus foram exportadas. É possível determinar esses nomes
recuperando os descritores de métrica que o exportador cria e, em seguida,
analisando o campo type. Para ver mais detalhes sobre os descritores de métrica, consulte MetricDescriptor.
Para visualizar os descritores de métrica criados para as métricas exportadas, faça o seguinte:
- Acesse a página de referência de
metricDescriptors.list. No widget Testar esta API na página de referência, preencha os seguintes campos:
Digite o nome do seu projeto no campo
name. Use a seguinte estrutura de nomeprojects/PROJECT_ID. Este documento usa um projeto com o IDa-gcp-project.Insira um filtro no campo
filter. Há muitos descritores de métrica em um projeto. A filtragem permite eliminar esses descritores que não são de interesse.Por exemplo, como o nome da visualização do OpenCensus se torna parte do nome da métrica, é possível adicionar um filtro como este:
metric.type=has_substring("task_latency_distribution")A chave
metric.typeé um campo em um tipo incorporado em uma série temporal. ConsulteTimeSeriespara ver detalhes.Clique em Executar.
O exemplo seguinte mostra o descritor de métrica retornado:
{
"metricDescriptors": [
{
"name": "projects/a-gcp-project/metricDescriptors/custom.googleapis.com/opencensus/task_latency_distribution",
"labels": [
{
"key": "opencensus_task",
"description": "Opencensus task identifier"
}
],
"metricKind": "CUMULATIVE",
"valueType": "DISTRIBUTION",
"unit": "ms",
"description": "The distribution of the task latencies",
"displayName": "OpenCensus/task_latency_distribution",
"type": "custom.googleapis.com/opencensus/task_latency_distribution"
}
]
}
Essa linha no descritor de métrica informa o nome do tipo de métrica no Cloud Monitoring:
"type": "custom.googleapis.com/opencensus/task_latency_distribution"
Agora você tem as informações necessárias para recuperar manualmente os dados associados ao tipo de métrica. O valor do campo type também é
mostrado no console do Google Cloud quando você cria um gráfico com a métrica.
Recuperar dados de métricas
Para recuperar manualmente os dados da série temporal de um tipo de métrica, faça o seguinte:
- Acesse a página de referência do
timeSeries.list. No widget Testar esta API na página de referência, preencha os seguintes campos:
- Digite o nome do seu projeto no campo
name. Use a seguinte estrutura de nomeprojects/PROJECT_ID. No campo
filter, digite o seguinte valor:metric.type="custom.googleapis.com/opencensus/task_latency_distribution"Insira valores para os campos
interval.startTimeeinterval.endTime. Esses valores precisam ser inseridos como um carimbo de data/hora, por exemplo,2018-10-11T15:48:38-04:00. Verifique se o valorstartTimeé anterior ao valorendTime.Clique em Execute.
- Digite o nome do seu projeto no campo
A seguir, é mostrado o resultado de uma dessas recuperações:
{
"timeSeries": [
{
"metric": {
"labels": {
"opencensus_task": "java-3424@docbuild"
},
"type": "custom.googleapis.com/opencensus/task_latency_distribution"
},
"resource": {
"type": "gce_instance",
"labels": {
"instance_id": "2455918024984027105",
"zone": "us-east1-b",
"project_id": "a-gcp-project"
}
},
"metricKind": "CUMULATIVE",
"valueType": "DISTRIBUTION",
"points": [
{
"interval": {
"startTime": "2019-04-04T17:49:34.163Z",
"endTime": "2019-04-04T17:50:42.917Z"
},
"value": {
"distributionValue": {
"count": "100",
"mean": 2610.11,
"sumOfSquaredDeviation": 206029821.78999996,
"bucketOptions": {
"explicitBuckets": {
"bounds": [
0,
100,
200,
400,
1000,
2000,
4000
]
}
},
"bucketCounts": [
"0",
"0",
"1",
"6",
"13",
"15",
"44",
"21"
]
}
}
}
]
},
[ ... data from additional program runs deleted ...]
]
}
Os dados das métricas retornados incluem o seguinte:
- informações sobre o recurso monitorado do qual os dados foram coletados.
O OpenCensus detecta automaticamente os recursos monitorados
gce_instance,k8s_containereaws_ec2_instance. Esses dados são provenientes de um programa executado em uma instância do Compute Engine. Para ver informações sobre como usar outros recursos monitorados, leia Set monitored resource for exporter (em inglês); - a descrição do tipo de métrica e o tipo dos valores;
- os pontos de dados reais coletados no intervalo de tempo solicitado.
Como o Monitoring representa as métricas do OpenCensus
O uso direto da API Cloud Monitoring para métricas definidas pelo usuário é compatível. O uso está descrito em Criar métricas definidas pelo usuário com a API. Na verdade, o exportador do OpenCensus para o Cloud Monitoring usa essa API. Nesta seção, fornecemos algumas informações sobre como o Cloud Monitoring representa as métricas escritas pelo OpenCensus.
As construções usadas pela API OpenCensus diferem das usadas pelo Cloud Monitoring, assim como parte da terminologia. Enquanto o Cloud Monitoring se refere a “métricas”, o OpenCensus às vezes se refere a “estatísticas”. Por exemplo, o componente do OpenCensus que envia dados de métrica para o Cloud Monitoring é chamado “exportador de estatísticas do Stackdriver”.
Para ter uma visão geral do modelo do OpenCensus para métricas, consulte Métricas do OpenCensus.
Os modelos de dados para as estatísticas do OpenCensus e as métricas do Cloud Monitoring não se enquadram em um mapeamento 1:1 puro. Muitos dos mesmos conceitos existem em cada um deles, mas não são diretamente intercambiáveis.
Uma visualização do OpenCensus é análoga ao
MetricDescriptorna API Monitoring. Uma visualização descreve como coletar e agregar medições individuais. As tags são incluídas em todas as medições registradas.Uma tag do OpenCensus é um par de chave-valor. Uma tag do OpenCensus geralmente corresponde a
LabelDescriptorna API Monitoring. As tags permitem capturar informações contextuais que você pode usar para filtrar e agrupar métricas.Uma medida do OpenCensus descreve os dados da métrica a serem registrados. Uma agregação do OpenCensus é uma função aplicada aos dados usados para resumi-los. Essas funções são usadas na exportação para determinar o
MetricKind, oValueTypee a unidade informada no descritor de métrica do Cloud Monitoring.Uma medição do OpenCensus é um ponto de dados coletado. As medições precisam ser agregadas em visualizações. Caso contrário, as medições individuais serão descartadas. Uma medida do OpenCensus é análoga a
Pointna API Monitoring. Quando as medidas são agregadas nas visualizações, os dados agregados são armazenados como dados de exibição, de maneira análoga a umTimeSeriesna API Monitoring.
A seguir
O OpenCensus apresenta a documentação de referência oficial para sua API de métricas e para o exportador do Stackdriver. A tabela a seguir apresenta links para esses documentos de referência:
Idioma Documentação de referência de APIs Documentação do exportador Guia de início rápido Go API Go Stats and Trace Exporters (em inglês) Métricas Java API Java Stats Exporter (em inglês) Métricas NodeJS API NodeJS Stats Exporter (em inglês) Métricas Python API Python Stats Exporter (em inglês) Métricas