このチュートリアルでは、Striim を使用して、Oracle® Database Enterprise Edition 18c 以降を、オンプレミス環境またはクラウド環境から Google Cloud 上の Cloud SQL for PostgreSQL インスタンスへ移行します。このチュートリアルでは、Oracle の HR サンプル スキーマのテーブルを使用します。
このチュートリアルは、Striim を使用して Oracle データベースを Cloud SQL for PostgreSQL に移行または複製することを予定しているエンタープライズ データベース アーキテクト、データベース エンジニア、データオーナーを対象としています。このチュートリアルの読者は、Striim を使用してパイプラインを構築する方法の基本を理解している必要があります。また、Striim ウェブ UI、Striim の主なコンセプト、Striim の Flow Designer を使用してアプリケーションを作成する方法についても一定の知識を持っている必要があります。
Striim は、Google Cloud データベース移行の技術パートナーです。Striim では、ドラッグ&ドロップ インターフェースを使用して、データベース間の継続的なデータ移動を設定することにより、オンライン移行を簡素化します。Google Cloud への移行については、Striim が提供する、抽出、変換、読み込み(ETL)のための、非干渉型のストリーミング プラットフォームによって、効率的なデプロイと、単純な反復処理が実現されます。このチュートリアルでは、移行パイプラインを構築するために、全体を通して Striim の Flow Designer を使用します。
データベース移行に関する知識が不足している場合は、こちらの Cloud Next '19 でのテックトークをご覧ください。
アーキテクチャ
Striim を使用したデータベース移行は、2 つのステージから成るシーケンシャルなデータ移動により実現されます。
- ステージ 1: Oracle データベースの初期レプリケーション(1 回限り)。
- ステージ 2: 変更データ キャプチャ(CDC)を使用した継続的なレプリケーション。ステージ 1 以降にソース データベース システム上で commit されたすべての変更に対して実施します。
次の図では、基本的なデプロイ アーキテクチャを示します。

このアーキテクチャでは、Compute Engine インスタンス上で Striim アプリケーションが実行される必要があります。このアプリケーションは、オンプレミスまたはクラウドでホストされている Oracle データベースに接続し、Google Cloud 上の Cloud SQL for PostgreSQL インスタンスにデータを書き込みます。
Striim インスタンスと Cloud SQL インスタンス間のネットワークや接続で発生する問題を防止するには、両方のインスタンスに同じネットワークを使用します。Striim を Google Cloud Marketplace から Compute Engine インスタンスにデプロイするか、高可用性が必要な場合は、Striim をクラスタとしてデプロイできます。
このチュートリアルでは、Cloud Marketplace からデプロイします。
Striim を Cloud Marketplace からデプロイすることの利点は、組み込みアダプタを使用してさまざまなデータベースおよびデータソースに接続できることです。アダプタは、Striim のインタラクティブなドラッグ&ドロップ インターフェースである Flow Designer を使用して接続でき、それによって非巡回グラフが形成されます。このグラフは、Striim パイプラインまたは Striim アプリケーションとも呼ばれます。
このチュートリアルの移行のユースケースでは、次に挙げる 3 つの Striim アダプタを使用します。
- Database Reader: 初期読み込みのステージで Oracle ソース データベースからデータを読み取ります。
- Oracle Reader: 継続的なデータ レプリケーションのステージで、Oracle ソース データベースから LogMiner を使用してデータを読み取ります。
- Database Writer: 初期読み込みと継続的なデータ レプリケーションで Cloud SQL for PostgreSQL データベースにデータを書き込みます。
目標
移行やレプリケーションのソース データベースとして、Oracle データベースを準備します。
移行やレプリケーションのターゲット データベースとして、Cloud SQL for PostgreSQL データベースを準備します。
Striim をインストールして実行するための前提事項を実現します。
Oracle データベースのスキーマを PostgreSQL 内の対応するスキーマに変換します。
Oracle データベースから Cloud SQL for PostgreSQL への初期読み込みを行います。
Oracle データベースから Cloud SQL for PostgreSQL への継続的なレプリケーションを設定します。
費用
このドキュメントでは、Google Cloud の次の課金対象のコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
Cloud Marketplace の Striim ソリューションには、期間限定の無料トライアル ライセンスが用意されています。トライアル期間が終了すると、使用料金は Google Cloud アカウントに請求されます。オンプレミス デプロイ用と Compute Engine 仮想マシン(VM)内の Striim ライセンスは、Striim から直接取得することもできます。また、Google Cloud 外での Oracle データベースの実行に関連する費用が発生する場合もあります。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
-
Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
このガイドは、次のものが揃っていることを前提としています。
- 移行する Oracle Database Enterprise Edition 18c 以降(Linux x86-64 用)。
- Striim をインストールした CentOS が実行されている Compute Engine。Striim は、Google Cloud Marketplace ソリューションを介してデプロイできます。
Oracle データベースの準備
以降のセクションでは、Oracle データベースに接続し Striim で移行するために必要となる構成の変更について説明します。構成の詳細については、Oracle の基本的な構成タスクをご覧ください。
Oracle CDC のソースを選択する
Oracle CDC ソースには、さまざまなものがありますが、このチュートリアルでは LogMiner を使用します。代わりとなる選択肢については、他の Oracle CDC ソースをご覧ください。
Oracle Database Enterprise Edition 18c 以降を準備する
Oracle データベースを準備するには、Striim のドキュメント ページの手順に沿って次の操作を行います。
- Striim の
archivelogを有効にします。 - Striim の追加ログデータを有効にします。
- Striim の主キーのロギングを有効にします。
Striim の LogMiner 権限がある Oracle ユーザーを作成します。
CDB とプラガブル データベース(PDB)のどちらを移行するかにかかわらず、この手順で操作するには、コンテナ データベース(CDB)に接続する必要があります。SQL*Plus をインストールして使用し、Oracle データベースを操作することをおすすめします。
Striim の
quiescemarkerテーブルを作成します。Striim の CDC 用 Oracle Reader アダプタには、アプリケーションの静止時にメタデータを保存するテーブルが必要です。このチュートリアルのように CDC のソースとして LogMiner を使用する場合は、QUIESCEMARKER テーブルが必要です。テーブルを作成する手順を行う際には、CDB に接続されている必要があります。
Oracle データベースと Striim インスタンス間のネットワーク接続を確立します。
デフォルトでは、Oracle リスナーのポートは
1521です。Striim インスタンスの IP アドレスから Oracle リスナーのポートに接続でき、接続をブロックするファイアウォール ルールが存在しないことを確認します。Oracle リスナーが構成されているポートは、$ORACLE_HOME/network/admin/tnsnames.oraファイルに存在します。Oracle データベースのシステム変更番号(SCN)をメモします。
SCN は、データベースに加えられた変更を参照するために使用する内部のタイムスタンプです。
Oracle データベースで、最も古い SCN を取得します。
SELECT MIN(start_scn) FROM gv$transaction;この番号を書き留めます。これは、後述する継続的なレプリケーション パイプラインの手順で必要になります。
Striim インスタンスの準備
Striim がサポートするオペレーティング システムについては、システム要件をご覧ください。LogMiner で Oracle Reader を使用するには、Striim インスタンスの Java クラスパスに Oracle JDBC ドライバを配置します。Oracle Reader アダプタを実行する各 Striim サーバーで次の手順を行います。
- Oracle アカウントにログインして、ローカルマシンに
ojdbc8.jarファイルをダウンロードします。- Oracle アカウントをお持ちでない場合は、アカウントを作成します。
ojdbc8.jarファイルのダウンロード リンクをクリックします。- ライセンス条項に同意する場合は、[I reviewed and accept the Oracle License Agreement] をクリックしてファイルをダウンロードします。
Cloud Shell で Cloud Storage バケットを作成し、そこに
.jarファイルをアップロードします。gsutil mb -b on -l REGION gs://BUCKET_NAME gsutil cp PATH/ojdbc8.jar gs://BUCKET_NAME次のように置き換えます。
- REGION: Cloud Storage バケットを作成するリージョン
- BUCKET_NAME:
ojdbc8.jarファイルを保存する Cloud Storage バケットの名前 - PATH:
ojdbc8.jarファイルのダウンロード先のパス
ローカルマシンにファイルを保存した後は、
.jarファイルを Cloud Storage バケットにアップロードすることをおすすめします。これにより、そのファイルを任意のインスタンスにダウンロードできるようになります。Striim インスタンスで SSH セッションを開始し、
.jarファイルを Striim インスタンスにダウンロードして、/opt/striim/libディレクトリに配置します。sudo su - striim gsutil cp gs://BUCKET_NAME/ojdbc8.jar /opt/striim/libojdbc8.jarファイルに適切なファイル権限が付与されていることを確認します。sudo ls -l /opt/striim/lib/ojdbc8.jar出力では、次のように表示されます。
-rwxrwx--- striim striim(省略可)
.jarファイルに前述の権限が付与されていない場合は、適切な権限を設定します。sudo chmod 770 /opt/striim/lib/ojdbc8.jar sudo chown striim /opt/striim/lib/ojdbc8.jar sudo chgrp striim /opt/striim/lib/ojdbc8.jarStriim を停止して再起動します。
構成を変更(前述の権限の変更など)した後は、Striim を再起動する必要があります。
CentOS 7 の Linux ディストリビューションを使用している場合は、次のコマンドで Striim を停止します。
sudo systemctl stop striim-node sudo systemctl stop striim-dbmsCentOS 7 の Linux ディストリビューションを使用している場合は、次のコマンドで Striim を起動します。
sudo systemctl start striim-dbms sudo systemctl start striim-node
別のオペレーティング システムで Striim を停止および再起動する方法については、Striim の起動と停止をご覧ください。
Striim インスタンスに psql クライアントをインストールします。
このクライアントは、後ほどこのチュートリアルの中で使用して、Cloud SQL インスタンスに接続し、スキーマを作成します。
Cloud SQL for PostgreSQL スキーマの準備
表形式データをあるデータベースから別のデータベースにコピーまたは継続的に複製する場合、通常、Striim では、ターゲット データベースが正しいスキーマに対応するテーブルを含んでいる必要があります。Google Cloud には、スキーマを準備するユーティリティはありませんが、Striim のスキーマ変換ユーティリティか、ora2pg のようなオープンソース ユーティリティを使用できます。
初期読み込み中は外部キーを保持する
初期読み込みのフェーズでは、外部キーの取り扱いに注意してください。外部キーは、リレーショナル データベース内のテーブル間の関係を確立します。ターゲット データベースに順序を気にせずに外部キーを作成または挿入すると、2 つのテーブル間の関係を破壊することがあります。2 つのデータベース間の整合性が損なわれると、エラーが発生する可能性があります。したがって、このセクションに後述するように、すべての外部キー宣言を別々のファイルに出力することが重要です。
CDC パイプラインでの継続的なレプリケーションの間、ソース データベース イベントは、発生した順にターゲット データベースに伝えられます。外部キーがソースで正しく保持されると、外部キー オペレーションによってソースからターゲット データベースに同じ順序で複製されます。
一方、初期読み込みのパイプラインは、デフォルトではアルファベット順にテーブルを読み込みます。初期読み込みの前に外部キーを無効にしなければ、外部キー違反エラーが発生します。初期読み込み時にソース データベース テーブルから Cloud SQL for PostgreSQL のターゲット テーブルへデータを複製するには、テーブルの外部キー制約を無効にする必要があります。そうしない場合、レプリケーション プロセス中に制約違反が発生する可能性があります。
2021 年 6 月の時点で、Cloud SQL for PostgreSQL では、外部キー制約を無効にする構成オプションがサポートされていません。
外部キー制約に対処するには、次のようにします。
- スキーマをエクスポートするとき、すべての外部キー宣言を別のファイルに出力します。
- 外部キー制約を含めずに Cloud SQL for PostgreSQL データベースにテーブル スキーマを作成します。
- 初期のデータ レプリケーションを実施します。
- テーブルに外部キー制約を適用します。
- 継続的なレプリケーション パイプラインを作成します。
このチュートリアルでは、スキーマ変換の 2 つの選択肢を用意しており、以下のセクションで説明します。
Striim スキーマ変換ユーティリティを使用してスキーマを変換する
データをターゲット スキーマと統合してソース Oracle データベースを反映したテーブルを作成するために、Striim スキーマ変換ユーティリティを使用して Cloud SQL for PostgreSQL を準備します。
Striim スキーマ変換ツールは、次のソース オブジェクトを同等のターゲット オブジェクトに変換します。
- テーブル
- 主キー
- データ型
- UNIQUE 制約
NOT NULL制約- 外部キー
Striim スキーマ変換ユーティリティを使用すると、同等のターゲット スキーマをターゲット データベースに作成するために、ソース データベースを分析して DDL スクリプトを生成できます。
スキーマは、生成した DDL スクリプトを使用して、ターゲット データベースに手動で作成することをおすすめします。それには、テーブルの一部を選択してスキーマをエクスポートした後、そのスキーマをターゲットの Cloud SQL for PostgreSQL データベースにインポートするのが最も簡単です。
次の例では、Striim スキーマ変換ユーティリティを使用してスキーマをインポートすることで、ターゲット Cloud SQL for PostgreSQL データベースで初期読み込みの準備を行う方法を示します。
Striim インスタンスに SSH で接続します。
/opt/striimディレクトリに移動します。cd /opt/striimすべての引数を一覧表示します。
bin/schemaConversionUtility.sh --helpユースケースに合うフラグを指定して、スキーマ変換ユーティリティを実行します。
bin/schemaConversionUtility.sh \ -s=oracle \ -d=SOURCE_DATABASE_CONNECTION_URL \ -u=SOURCE_DATABASE_USERNAME \ -p=SOURCE_DATABASE_PASSWORD \ -b=SOURCE_TABLES_TO_CONVERT \ -t=postgres \ -f=false次のように置き換えます。
- SOURCE_DATABASE_CONNECTION_URL: Oracle データベースの接続 URL(例:
"jdbc:oracle:thin:@12.123.123.12:1521/APPSPDB.WORLD"または"jdbc:oracle:thin:@12.123.123.12:1521:XE") - SOURCE_DATABASE_USERNAME: Oracle データベースへの接続に使用する Oracle ユーザー名
- SOURCE_DATABASE_PASSWORD: Oracle データベースへの接続に使用する Oracle パスワード
- SOURCE_TABLES_TO_CONVERT: スキーマの変換に使用されるソース データベースのテーブル名
-f=false引数は、必ず使用してください。この引数により、外部キー宣言が別のファイルにエクスポートされます。出力フォルダには、次のファイルの一部または全部が含まれます。これらのファイルの詳細については、Striim スキーマ変換ユーティリティのドキュメントをご覧ください。
出力ファイル名 説明 converted_tables.sql強制変換が必要ないすべての変換済みテーブルを含みます。 converted_tables_with_striim_intelligence.sql強制的に変換されたすべての変換済みテーブルを含みます。 conversion_failed_tables.sql変換を試みたもののマッピングが取得されなかったテーブルを含みます。 converted_foreignkey.sqlすべての外部キー制約宣言を含みます。 conversion_failed_foreignkey.sql失敗した外部キー変換すべてを含みます。 conversion_report.txtスキーマ変換の詳細なレポートを含みます。 このチュートリアルでは、
converted_tables.sqlファイルを使用して、外部キー制約を付けずに、Cloud SQL for PostgreSQL データベースに同等のテーブルを作成します。初期レプリケーションの後、converted_foreignkey.sqlファイルを使用して外部キー制約を適用します。- SOURCE_DATABASE_CONNECTION_URL: Oracle データベースの接続 URL(例:
Ora2Pg を使用してスキーマを変換する
Oracle のテーブル スキーマを同等の PostgreSQL スキーマに変換するためのもう 1 つの選択肢は、Ora2Pg ユーティリティです。このユーティリティは、別の Google Cloud VM にインストールできます。
Ora2Pg ユーティリティは、Oracle スキーマを変換し、PostgreSQL データベースに同等のテーブルを作成するために必要な DDL ステートメントをエクスポートします。これらの DDL ステートメントは、output.sql という名前の出力ファイルにエクスポートされます。
スキーマのエクスポートの際、Ora2Pg 構成ファイルで次のフラグを使用して、すべての外部キー宣言を別のファイルにエクスポートして保存します。
FILE_PER_FKEYS 1
デフォルトでは、外部キーはメイン出力ファイル(output.sql)にエクスポートされます。FILE_PER_FKEYS フラグを有効(1)にすると、外部キーは FKEYS_output.sql という名前の別のファイルにエクスポートされます。
このチュートリアルでは、output.sql ファイルを使用して、外部キー制約を付けずに、Cloud SQL for PostgreSQL データベースに同等のテーブルを作成します。初期レプリケーションの後、FKEY_output.sql ファイルを使用して外部キー制約を適用します。
Cloud SQL for PostgreSQL インスタンスの準備
Striim で Cloud SQL for PostgreSQL インスタンスにデータを書き込めるようにするには、Cloud SQL インスタンスを作成する必要があります。また、Striim が書き込むデータベース テーブルとスキーマを作成する必要もあります。
Cloud Shell で、Cloud SQL for PostgreSQL のインスタンスを作成します。プライベート IP アドレスを使用するように Cloud SQL を構成することをおすすめします。このアドレスは、
--networkパラメータを使用して構成します。$INSTANCE_NAME=INSTANCE_NAME gcloud beta sql instances create INSTANCE_NAME \ --database-version=POSTGRES_12 \ --network=NETWORK \ --cpu=NUMBER_CPUS \ --memory=MEMORY_SIZE \ --region=REGION次のように置き換えます。
- INSTANCE_NAME: インスタンス名
- NETWORK: このインスタンスに使用する VPC ネットワークの名前
- NUMBER_CPUS: インスタンスの vCPU の数
- MEMORY_SIZE: インスタンスのメモリ容量。たとえば、「3072MiB」や「9GiB」とします。単位を指定しないと、GiB が使用されます。
- REGION: Cloud Storage バケットを作成したリージョン。
Cloud SQL インスタンスで、ユーザー名とパスワードを作成します。
CLOUD_SQL_USERNAME=CLOUD_SQL_USERNAME gcloud sql users create $CLOUD_SQL_USERNAME \ --instance=$INSTANCE_NAME \ --password=CLOUD_SQL_PASSWORD次のように置き換えます。
- CLOUD_SQL_USERNAME: Cloud SQL インスタンスのユーザー名
- CLOUD_SQL_PASSWORD: Cloud SQL ユーザー名に対するパスワード
このユーザーには、PostgreSQL テーブルのオーナー権限が付与されます。Striim では、Cloud SQL for PostgreSQL データベースへの接続にも、このユーザーの認証情報を使用します。
スキーマの変換ステップの中でエクスポートされるスキーマ ファイルには、次の例のように、ユーザーに所有権を付与する DDL ステートメントが含まれている場合があります。
CREATE SCHEMA <SCHEMA_NAME>; ALTER SCHEMA <SCHEMA_NAME> OWNER TO <USER>;
SCHEMA_NAMEをCLOUD_SQL_SCHEMAに、USERを上記で作成したCLOUD_SQL_USERNAMEに置き換えることが必要な場合があります。PostgreSQL データベースを作成します。
CLOUD_SQL_DATABASE_NAME=CLOUD_SQL_DATABASE_NAME gcloud sql databases create $CLOUD_SQL_DATABASE_NAME \ --instance=$INSTANCE_NAME次のように置き換えます。
- CLOUD_SQL_DATABASE_NAME: PostgreSQL データベース名
Striim インスタンスからアクセスできるように Cloud SQL for PostgreSQL データベースを構成します。接続性オプションは、パブリック IP アドレスかプライベート IP アドレスのどちらを使用して Cloud SQL インスタンスを構成したかによって決まります。
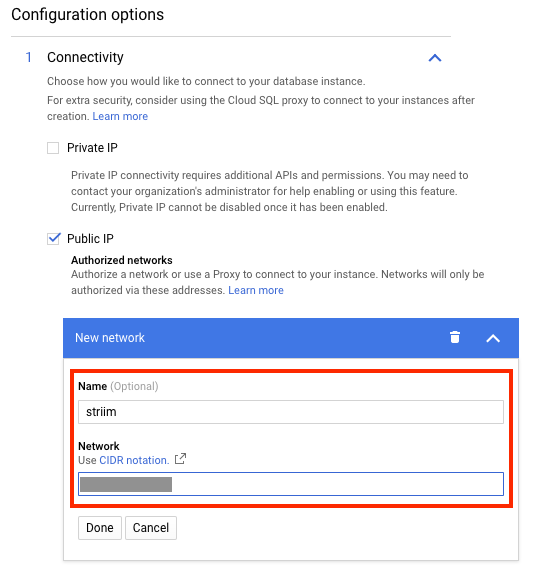
パブリック IP アドレスを構成した場合は、Striim のインスタンス IP アドレスを承認済みアドレスとして Cloud SQL インスタンスに追加します。次のスクリーンショットでは、Google Cloud コンソールから追加する方法を示します。
プライベート IP アドレスを構成した場合、使用可能な接続方法は、Cloud SQL インスタンスと Striim インスタンスが同じ VPC ネットワーク上にあるかどうかによって異なります。
Striim インスタンスが Cloud SQL インスタンスと同じ VPC ネットワーク上にある場合、Striim インスタンスは Cloud SQL インスタンスと接続を確立できます。
次のスクリーンショットは、Cloud SQL インスタンスがデフォルトの VPC ネットワークに関連付けられていることを示しています。Striim インスタンスがデフォルトの VPC ネットワークにも作成されている場合は、Cloud SQL インスタンスにプライベート IP アドレスで接続できます。
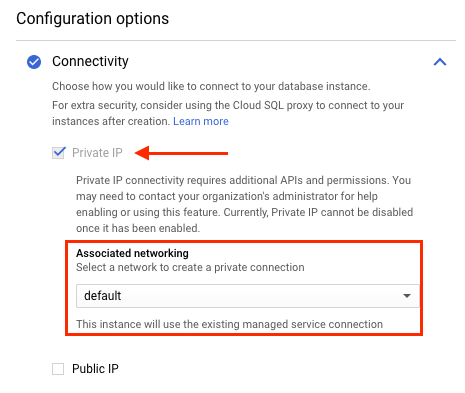
Striim インスタンスが Cloud SQL インスタンスとは異なる VPC ネットワーク上にある場合は、Striim インスタンスの VPC ネットワークでプライベート サービス アクセスを構成します。
Cloud SQL for PostgreSQL データベースに外部キー制約のないテーブル スキーマを作成します。
スキーマの変換ステップの中で
output.sqlをエクスポートするには、output.sqlファイルを使用してスキーマを作成します。スキーマの変換ステップの中で
converted_tables.sqlをエクスポートするには、converted_tables.sqlファイルを使用してスキーマを作成します。どちらのスクリプトも、対象の Cloud SQL for PostgreSQL インスタンスに接続できる任意の PostgreSQL クライアントを使用して実行できます。とはいえ、Striim インスタンスに前の手順でインストールした PostgreSQL クライアントを使用することをおすすめします。
スキーマを作成します。
psql -h HOSTNAME -p CLOUD_SQL_PORT -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -f PATH_TO_MAIN_SQL_FILE次のように置き換えます。
- HOSTNAME: Cloud SQL インスタンスの IP アドレス。
- CLOUD_SQL_PORT: 接続先の Cloud SQL インスタンスのポート。デフォルトでは
5432です。 - PATH_TO_MAIN_SQL_FILE: Striim インスタンスのメイン スクリプトへのパス。
次に例を示します。
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
テーブルが作成されたことを確認します。
Cloud SQL for PostgreSQL データベースに接続します。
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMEこのデータベース内のテーブルを一覧表示します。
\dtこの出力は、前の手順で作成したテーブル スキーマの変換スクリプトによって作成されたテーブルのリストです。
Cloud SQL for PostgreSQL データベースにチェックポイント テーブルを作成します。
Cloud SQL for PostgreSQL データベースに接続します。
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMEテーブルを作成します。
CREATE TABLE chkpoint ( id character varying(100) primary key, sourceposition bytea, pendingddl numeric(1), ddl text);Striim では、継続的なレプリケーション プロセスでチェックポイントを保持するために、このテーブルが必要です。
Cloud SQL for PostgreSQL データベースへの Oracle データベースの読み込み
このセクションでは、1 回だけ行う Oracle データベースの Cloud SQL for PostgreSQL データベースへの初期レプリケーションについて説明します。
Striim から Oracle への接続を確立する
Google Cloud での Striim の実行のガイダンスに従います。初期読み込みの場合は、Striim Database Reader アダプタを使用して Striim から Oracle に接続します。Striim の CDC ウィザードも使用できます。
Striim Database Reader アダプタで、[Sources] に移動し、リストから「Database」を検索して選択します。
[Database] ウィンドウで、次のプロパティを設定します。
- Name: この移行パイプラインのコンポーネントを識別します。
- Adapter:
DatabaseReader Connection URL: Oracle データベースに接続するための一意の文字列を入力します。
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT:SIDまたは
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT/PDB_OR_CDB_SERVICE_NAME次のように置き換えます。
- ORACLE_PORT: Oracle データベースのポート(デフォルトは
1521) - SID: Oracle データベースの SID
- PDB_OR_CDB_SERVICE_NAME: Oracle PDB または CDB サービス名。テーブルが PDB にある場合は、
PDB_SERVICE_NAMEを使用します。CDB にある場合は、CDB_SERVICE_NAMEを使用します。
ポート名とサービス名は、Oracle インスタンスの
$ORACLE_HOME/network/admin/tnsnames.oraに配置されているtnsnames.oraファイルにあります。- ORACLE_PORT: Oracle データベースのポート(デフォルトは
Username と Password: 前もって実施した手順で作成した Oracle ユーザー(
c##striimユーザー)を使用します。Striim では、このユーザー名とパスワードを使用して Oracle データベースに接続し、テーブルを読み取ります。Tables: Oracle の場合、Database Reader には、複製するテーブル名のリストも必要です。このプロパティは、[Show optional properties] の下の [Tables] フィールドで指定します。このプロパティの形式は、次のとおりです。
ORACLE_SCHEMA.ORACLE_TABLE_NAME次のように置き換えます。
- ORACLE_SCHEMA: Oracle スキーマ名
- ORACLE_TABLE_NAME: そのスキーマ内の Oracle テーブル名
複数のテーブルや実体化したビューをセミコロンで区切ったリストとして指定するか、次のワイルドカードで指定することもできます。
%: 任意の文字列_: 任意の 1 文字たとえば、「
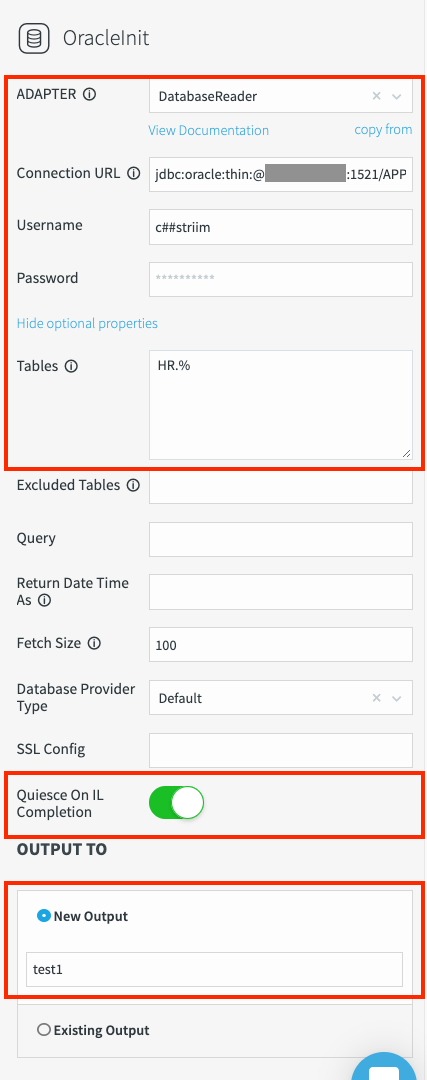
HR.%」は、HR スキーマ内のすべてのテーブルを読み取ります。少なくとも 1 つのテーブルが、ワイルドカードと一致する必要があります。一致するテーブルがない場合、Database Reader は、次のエラーで失敗します。Could not find tables specified in the databaseQuiesce On IL Completion: 初期読み込みが完了したら、パイプラインを一時停止するために、このフィールドを右にスライドして緑色に切り替えます。
Output To: このアダプタの出力先に名前を付けます。特殊文字やスペースを含まない文字列を使用します(大文字と小文字は区別されます)。
[保存] をクリックします。アダプタのプロパティは、次のように表示されます。
接続をテストする
Striim から Oracle に接続できたため、接続をテストします。
[Created] プルダウン リストをクリックして、Striim の Oracle データベースへの接続性をテストします。
[Deploy App] をクリックします。
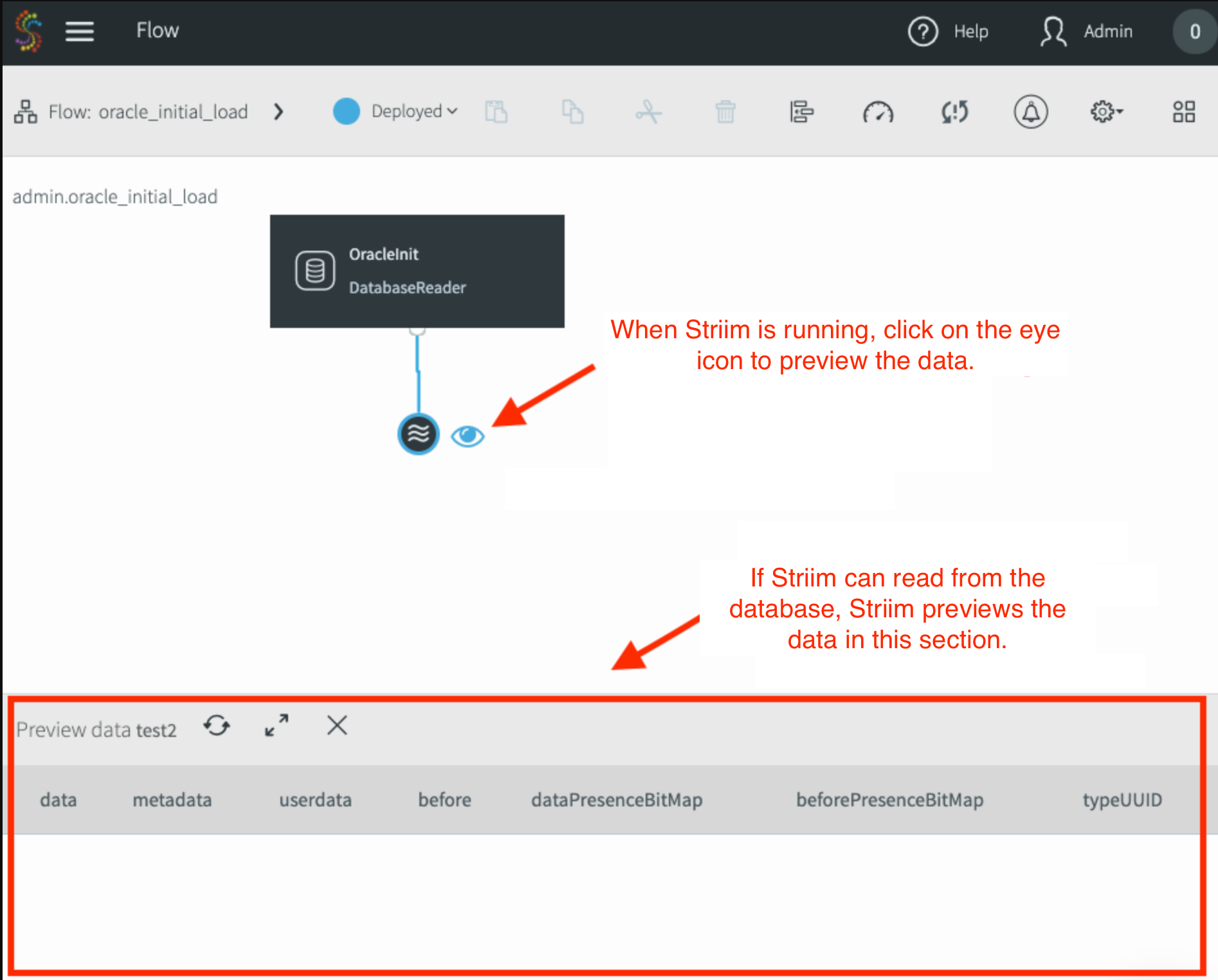
このアダプタの出力を選択し、[Preview] をクリックして Striim がソースからデータを読み取る際にリアルタイムでデータが表示されるようにします。
[Deployed] プルダウン リストをクリックし、[Start App] をクリックします。
(省略可)[Deployed] プルダウン リストをクリックし、[Undeploy App] をクリックして発生したエラーを修正します。
(省略可)すべてのエラーが修正されたら [Resume App] をクリックして、アプリを再起動します。
デフォルトのデプロイ グループをクリックします。
[Validate table mappings] オプションがオンに切り替わっていることを確認し、[Deploy] をクリックします。
プレビュー データ ペインとパイプラインのステータスが [Quiesced] に変わります。
チュートリアルのこの時点で、問題なく Striim から Oracle データベースへの接続を確立して、内部のデータを読み取れることが確認できました。
Cloud SQL for PostgreSQL データベースをターゲットとして追加する
この移行では、Cloud SQL for PostgreSQL インスタンスにデータを書き込みます。Striim では、移行に使用できる、Database Writer という一般的なデータベース書き込みアダプタが用意されています。
- Striim Flow Designer で、[Targets] に移動し、リストから [Cloud SQL Postgres] を選択します。
- Database Writer をパイプラインにドラッグします。
次のプロパティ値を設定します。
Adapter:
DatabaseWriterConnection URL: Cloud SQL インスタンスへの接続を確立するための一意の文字列を入力します。
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecified次のように置き換えます。
- CLOUD_SQL_IP_ADDRESS: Cloud SQL インスタンスの IP アドレス。
次に例を示します。
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedUsername と Password: 前の手順で作成した Cloud SQL のユーザー名とパスワードを入力します。
Tables: Oracle データベースのテーブル名から Cloud SQL テーブル名へのマッピングを作成します。どの Oracle データベース テーブルが、どの Cloud SQL テーブルに書き込まれるかを指定します。このマッピングでは、次の形式を使用します。
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAME次のように置き換えます。
- CLOUD_SQL_SCHEMA: PostgreSQL のスキーマ名
- CLOUD_SQL_TABLE_NAME: PostgreSQL のテーブル名
複数のテーブルをマッピングするには、[Tables] フィールドにワイルドカード記号(%)を使用します。たとえば、次のように記述します。
HR.%,hr.%次のスクリーンショットでは、Database Writer の必須フィールドを示します。
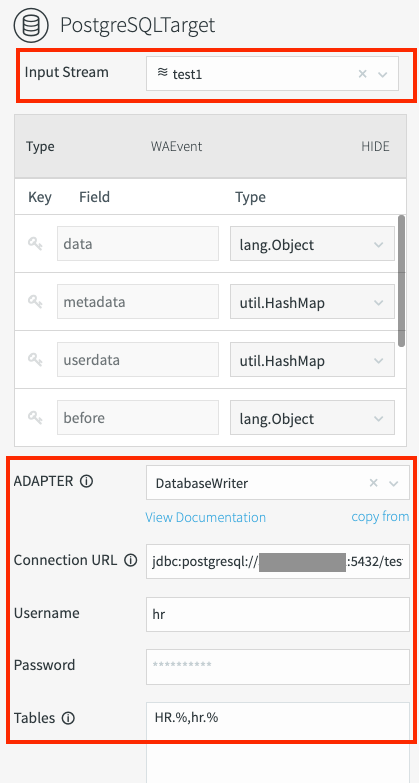
移行パイプラインをデプロイする
移行パイプラインの準備ができたら、Striim Flow Designer から移行パイプラインをデプロイしてアプリケーションを起動します。複製されているデータをリアルタイムでプレビューすることもできます。モニター レポートを使用して、レプリケーションの進行状況を追跡します。進捗状況を追跡するには、[Application Progress] アイコンを選択します。
![[Application Progress] アイコンをクリックすると、データベース レプリケーションの進捗状況を確認できます。](https://cloud.google.com/static/architecture/images/mod-to-cloudsql-for-postgresql-using-striim-07.png?authuser=0&hl=ja)
Striim Flow Designer で、移行パイプラインをデプロイします。[Created] プルダウン リストをクリックし、[Deploy App] をクリックします。初期読み込みが完了すると、パイプラインのステータスは
Quiescedに変わります。[Undeploy the app] をクリックして、デプロイをロールバックします。
行数を数えて、データ読み込みが成功したことを確認します。
SELECT COUNT(*) FROM <TARGET CLOUD SQL TABLE>;ゼロ以外の出力が表示されます。ゼロの場合は、データ読み込みが失敗しています。
Oracle データベースから Cloud SQL for PostgreSQL への初期データ読み込みはアトミックです。データ読み込みは、全体が成功するか失敗するかのいずれかです。初期読み込みが失敗した場合は、データを再度読み込む必要があります。
Cloud SQL for PostgreSQL テーブルで外部キー制約を有効にする
初期読み込みが完了したら、ターゲット テーブルで外部キー制約を有効にします。スキーマの変換で作成した外部キー宣言があるファイル(FKEY_output.sql または converted_foreignkey.sql)を使用します。
Striim で、SSH セッションを開始します。
テーブルに外部キー制約を作成します。
psql -h HOSTNAME -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -p CLOUD_SQL_PORT -f PATH_TO_FOREIGN_KEY_FILE次のように置き換えます。
- CLOUD_SQL_USERNAME: Cloud SQL for PostgreSQL のユーザー名
PATH_TO_FOREIGN_KEY_FILE: Striim インスタンス上の外部キー制約を含むスクリプトへのパス
次に例を示します。
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
Oracle データベースを Cloud SQL for PostgreSQL に継続的に複製する
初期データの読み込みが完了したら、別のパイプラインを作成して、Oracle データベースへの変更を複製します。このパイプラインは、実行されている限り、参照元データベースとターゲット データベースの同期状態も保持します。
Striim から Oracle への接続を確立する
継続的なレプリケーションを行うため、Striim の Oracle Reader アダプタを使用して、Striim から Oracle データベースに接続します。この Striim アダプタでは、Oracle から CDC データを読み取ることができます。
- Striim Oracle リーダー アダプタで [Sources] に移動します。
「Oracle」を検索し、表示されるリストから [Oracle CDC] を選択します。
次のプロパティ値を設定します。
Connection URL:
HOSTNAME:ORACLE_PORT/SIDまたは
HOSTNAME:ORACLE_PORT/CDB_SERVICE_NAME次のように置き換えます。
- CDB_SERVICE_NAME: Oracle の CDB サービス名
接続 URL は、Oracle データベースへの接続に使用される一意の文字列です。初期読み込みに使用される Database Reader アダプタとは異なり、データベース テーブルが PDB にあるか CDB にあるかにかかわらず、CDB サービス名を使用します。
例:
12.123.123.12:1521/ORCLCDB.WORLD。Username / Password: 前の手順で作成した Oracle ユーザー名(
c##striimユーザー)を使用します。この Oracle ユーザーには、テーブルを読み取るための権限が必要です。
Tables: 複製するテーブル名のリストも必要です。名前は、テーブルが CDB にあるか PDB にあるかによって、次の形式で指定します。
CDB テーブルの場合:
ORACLE_SCHEMA.ORACLE_TABLE_NAMEPDB テーブルの場合:
PDB_NAME.ORACLE_SCHEMA.ORACLE_TABLE_NAME次のように置き換えます。
- PDB_NAME: Oracle の PDB 名
このコマンドは、CDB または PDB のテーブルを複製します。
PDB_NAMEは、Oracle インスタンスの$ORACLE_HOME/network/admin/tnsnames.oraにあるファイルtnsnames.oraにあります。PDB_NAMEとPDB_SERVICE_NAMEは異なります。PDB_SERVICE_NAMEは、前のセクションで使用しました。tnsnames.oraファイルを表示して、PDB 名を取得します。sudo su - oracle // Login as oracle user cat ORACLE_HOME/network/admin/tnsnames.oratnsnames.oraファイル内のPDB_NAME(APPSPDB)の例を次に示します。APPSPDB = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP) (HOST = orainst) (PORT = 1521)) ) (CONNECT_DATA = (SERVICE NAME = APPSPDB.WORLD) ) )複数のテーブルと実体化されたビューをリストとして指定するには、テーブル名やビュー名をセミコロンかワイルドカードで区切ります。少なくとも 1 つのテーブルがワイルドカードと一致する必要があります。一致するテーブルがない場合、Oracle Reader は
Could not find tables specified in the databaseエラーで失敗します。Start SCN: 継続的なパイプラインの場合は、Oracle データベースの SCN を指定する必要があります。Striim では、全トランザクションの複製を開始するために必要です。SCN 値は、前に生成したものを入力します。
PDB と CDB のサポート: CDB または PDB を使用できます。[Show optional properties] を展開して、スイッチを右に切り替えます。
Quiesce マーカー テーブル: 前に作成したテーブル名を使用します。
次のスクリーンショットでは、Oracle Reader アダプタの必須項目の概要を示します。
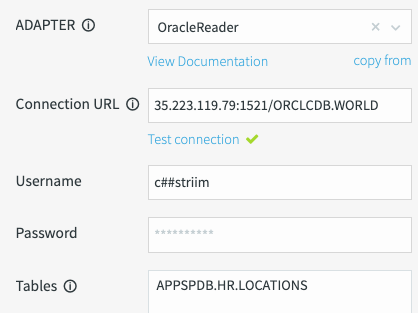
接続のテスト: [Test connection] をクリックします。データベース接続をテストするには、接続 URL、ユーザー名、パスワードが必要です。Striim が正常に接続を確立すると、緑色のチェックマークが表示されます。
Striim の Oracle データベース テーブルを読み取る機能をテストします。
- Oracle Reader アダプタで [Deploy app] を選択します。
- デフォルトのデプロイ グループを選択します。
- [デプロイ] をクリックします。
このアダプタではウェーブ(出力)アイコンをクリックします。表示されている目のアイコン(プレビュー)は、Striim が参照元からデータを読み取る際、リアルタイムでプレビューするために使用します。
[Deployed] プルダウンの [Start App] をクリックします。
エラーが発生した場合は、同じプルダウンから [Undeploy App] を選択し、エラーを修正します。エラーを修正したら、[Resume App] をクリックしてアプリケーションを再起動します。
パイプラインが開始されると、パイプライン ステータスが Running に更新されます。ソーステーブルに対する新しい変更は、プレビュー ウィンドウに表示されます。Oracle Reader アダプタは CDC を使用するため、プレビュー データ ペインに表示されるテーブルの変更は、アプリケーションの起動後に発生した変更に限られます。
![[Data Preview] タブには、ソーステーブルの新しい変更がリアルタイムで表示されます。](https://cloud.google.com/static/architecture/images/mod-to-cloudsql-for-postgresql-using-striim-10.png?authuser=0&hl=ja)
Oracle から CDC データを読み取る機能を確認する
アダプタが新しい変更を読み取れるかどうかをテストするには、次の手順を行います。
- SQL ステートメントを使用して、Oracle のソーステーブルに新しいトランザクションを挿入します。
- 新しいトランザクションが Oracle Reader アダプタの [Preview data] タブに表示されることを確認します。
- アプリケーションを停止して、[Undeploy] をクリックします。これで、次の手順に進むことができます。
この時点では、ターゲット アダプタはパイプラインに追加されていません。ターゲット アダプタを追加しないと、データはコピーされません。次のセクションでは、ターゲット アダプタを追加します。
Cloud SQL for PostgreSQL データベースをターゲットとして追加する
Cloud SQL for PostgreSQL データベースにデータを書き込むには、Database Writer アダプタをパイプラインに追加する必要があります。継続的なレプリケーション パイプラインでは、初期読み込みパイプラインで使用したものと同じアダプタを使用します。
- Striim Flow Designer で、[Targets] に移動し、リストから [Cloud SQL Postgres] を選択します。
- Database Writer をパイプラインにドラッグします。
次のプロパティ値を設定します。
Adapter:
DatabaseWriter.Connection URL: Cloud SQL インスタンスへの接続を確立するために入力した接続 URL を入力します。
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecified次に例を示します。
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedUsername と Password: 前の手順で作成した Cloud SQL のユーザー名とパスワードを入力します。
Tables: Oracle データベースのテーブル名から Cloud SQL テーブル名へのマッピングを作成します。どの Oracle データベース テーブルが、どの Cloud SQL テーブルに書き込まれるかを指定します。このマッピングでは、次の形式を使用します。
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAME複数のテーブルをマッピングするには、[Tables] フィールドにワイルドカード記号(%)を使用します。次に例を示します。
HR.%,hr.%上に示したプロパティに加えて、継続的なレプリケーション パイプラインでは、次のプロパティも設定する必要があります。
[Show optional properties] をクリックします。
[Ignorable Exception Code] フィールドには、次の値を選択します。
23505,NO_OP_UPDATE,NO_OP_DELETE過去の時点から CDC パイプラインを開始しているため、重複が発生している可能性があります。Striim では、前述の無視できる例外コードのプロパティを使用して、ターゲットで重複除去を行います。例外コードの詳細は以下の表に記載されています。
例外コード 詳細 23505主キーの値が重複しており、一意の制約に違反しています。 NO_OP_UPDATEターゲットの行を更新できませんでした(多くの場合、対応する主キーが存在しないことが原因です)。 NO_OP_DELETEターゲットの行を削除できませんでした(多くの場合、対応する主キーが存在しないことが原因です)。 [Check Point Table] フィールドに「
chkpoint」と入力します。Striim は、このテーブルを使用して、継続的レプリケーション パイプラインでのチェックポイントに関連付けられたメタデータを保存します。
復元と暗号化を有効にする
CDC パイプラインをデプロイする前に、復元を有効にすることを強くおすすめします。復元を有効にすると、Striim アプリケーションや VM が停止した場合に、Striim が処理を続行できるようになります。このステップは、1 回限りの処理のセマンティクスを実現するためにも有効です。こうしたセマンティクスでは、ソース データベースで最後に確認された読み取りチェックポイントと、ターゲット データベースで最後に確認された書き込みチェックポイントが追跡されます。アプリケーションや VM に障害が発生した場合、Striim では、2 つのチェックポイントと合わせて、データの消失や重複がないことを確認します。初期読み込みアプリケーションに復元は適用されません。
復元を有効にする
- Striim Flow Designer で [Configuration] アイコンをクリックしてから、[App Settings] を選択します。
- [Recovery Interval] をクリックします。
- 「
5」と入力し、プルダウン リストから [Second] を選択します。 - [enable encryption] をクリックします。Striim によって、Striim サーバー間、または転送エージェントから Striim サーバーにデータを移動するすべてのストリームが暗号化されます。
暗号化を有効にする
- Striim Flow Designer で、[Configuration] アイコンをクリックして [App Settings] を選択し、[Encryption] のチェックボックスをオンにします。
Striim の復元方法の詳細については、Striim のウェブサイトをご覧ください。
ロギングの例外を有効にする
継続的レプリケーション パイプラインをデプロイする前に、Striim で例外ストアを有効にすることをおすすめします。CDC アプリケーションの一部として、初期読み込みアプリケーションによって書き込まれた重複が存在する可能性があります。Striim アプリケーションは、こうしたエラーを無視し、ストア(確認および処理用)に書き込み、処理を続けます。
- Striim Flow Designer で、[Exceptions] アイコンを選択します。このアイコンは、2 つの曲線の矢印の間に感嘆符が入った形をしています。
- [オンにする] をクリックします。
パイプラインをデプロイする
パイプラインの準備が完了したら、デプロイしてアプリケーションを起動できます。複製されているデータをリアルタイムでプレビューし、モニター レポートを表示することもできます。継続的レプリケーションがパイプラインで正常に開始されると、パイプラインのステータスは Running に変わります。
- Oracle Reader アダプタで [Deploy app] を選択します。
- デフォルトのデプロイ グループを選択します。
- [デプロイ] をクリックします。
Oracle テーブルと Cloud SQL テーブルの同期を継続している限り、パイプラインの実行も継続できます。
以上でチュートリアルは終了です。他の Oracle CDC ソースについては、次のセクションで説明します。
他の Oracle CDC ソース
LogMiner に加え、Striim のアダプタでは、XStream か Oracle Golden Gate のトレイル ファイルから Oracle データベースを読み取ることができます。
XStream から読み取るには、Striim の Oracle Reader アダプタを使用します。XStream はパフォーマンスが優れているかもしれませんが、Golden Gate ライセンスが必要です。また、Oracle Database 11.2.0.4 でのみサポートされています。
Golden Gate トレイル ファイルを読み取るには、Striim の GG Trail Reader アダプタを使用します。
次の表では、LogMiner と XStream の違いを示します。
| Oracle データベース CDC の機能 |
LogMiner での サポート |
XStream Out での サポート |
|---|---|---|
データ定義言語(DDL)、ROLLBACK、コミットされていないトランザクションの読み取り |
○ | × |
DATA() 関数と BEFORE() 関数の使用 |
○ | × |
QUIESCE の使用(コンソール コマンドを参照) |
○ | × |
| CDC イベントの受信 | Oracle Reader の FetchSize プロパティで定義されているとおりにバッチでイベントを受信する |
変更データイベントを継続的に受信 |
| サポートされていない型を含むテーブルからの読み取り | テーブルは読み取らない | サポートされている型の列を読み取る |
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- Striim のドキュメント Oracle から Google Cloud PostgreSQL への移行ガイドを確認する。
- Oracle データベースから Cloud SQL PostgreSQL への移行に関する動画を確認する。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。
Oracle、Java、MySQL は、Oracle およびその関連会社の登録商標です。他の名前は、それぞれの所有者の商標である可能性があります。