This guide provides an overview of the options, recommendations, and general concepts that you need to know before you deploy a high-availability (HA) SAP HANA system on Google Cloud.
This guide assumes that you already have an understanding of the concepts and practices that are generally required to implement an SAP HANA high-availability system. Therefore, the guide focuses primarily on what you need to know to implement such a system on Google Cloud.
If you need to know more about the general concepts and practices that are required to implement an SAP HANA HA system, see:
- The SAP best practices document Building High Availability for SAP NetWeaver and SAP HANA on Linux
- The SAP HANA documentation
This planning guide focuses solely on HA for SAP HANA and does not cover HA for application systems. For information about HA for SAP NetWeaver, see the High-availability planning guide for SAP NetWeaver on Google Cloud.
This guide does not replace any documentation that is provided by SAP.
High-availability options for SAP HANA on Google Cloud
You can use a combination of Google Cloud and SAP features in the design of a high-availability configuration for SAP HANA that can handle failures at both the infrastructure or software levels. The following table describes SAP and Google Cloud features that are used to provide high availability.
| Feature | Description |
|---|---|
| Compute Engine live migration |
Compute Engine monitors the state of the underlying infrastructure and automatically migrates your instance away from an infrastructure maintenance event. No user intervention is required. Compute Engine keeps your instance running during the migration if possible. In the case of major outages, there might be a slight delay between when the instance goes down and when it is available. In multi-host systems, shared volumes, such as the `/hana/shared` volume used in the deployment guide, are persistent disks attached to the VM that hosts the master host, and are NFS-mounted to the worker hosts. The NFS volume is inaccessible for up to a few seconds in the event of the master host's live migration. When the master host has restarted, the NFS volume functions again on all hosts, and normal operation resumes automatically. A recovered instance is identical to the original instance, including the instance ID, private IP address, and all instance metadata and storage. By default, standard instances are set to live migrate. We recommend not changing this setting. For more information, see Live migrate. |
| Compute Engine automatic restart |
If your instance is set to terminate when there is a maintenance event, or if your instance crashes because of an underlying hardware issue, you can set up Compute Engine to automatically restart the instance. By default, instances are set to automatically restart. We recommend not changing this setting. |
| SAP HANA Service Auto-Restart |
SAP HANA Service Auto-Restart is a fault recovery solution provided by SAP. SAP HANA has many configured services running all the time for various activities. When any of these services is disabled due to a software failure or human error, the SAP HANA service auto-restart watchdog function restarts it automatically. When the service is restarted, it loads all the necessary data back into memory and resumes its operation. |
| SAP HANA Backups |
SAP HANA backups create copies of data from your database that can be used to reconstruct the database to a point in time. For more information about using SAP HANA backups on Google Cloud, see the SAP HANA operations guide. |
| SAP HANA Storage Replication |
SAP HANA storage replication provides storage-level disaster recovery support through certain hardware partners. SAP HANA storage replication isn't supported on Google Cloud. You can consider using Compute Engine persistent disk snapshots instead. For more information about using persistent disk snapshots to back up SAP HANA systems on Google Cloud, see the SAP HANA operations guide. |
| SAP HANA Host Auto-Failover |
SAP HANA host auto-failover is a local fault recovery solution that requires one or more standby SAP HANA hosts in a scale-out system. If one of the main hosts fail, host auto-failover automatically brings the standby host online and restarts the failed host as a standby host. For more information, see: |
| SAP HANA System Replication |
SAP HANA system replication allows you to configure one or more systems to take over for your primary system in high-availability or disaster recovery scenarios. You can tune replication to meet your needs in terms of performance and failover time. |
| SAP HANA Fast Restart option (Recommended) |
SAP HANA Fast Restart reduces restart time in the event that SAP HANA
terminates, but the operating system remains running. SAP HANA reduces
the restart time by leveraging the SAP HANA persistent memory
functionality to preserve MAIN data fragments of column store tables
in DRAM that is mapped to the For more information about using the SAP HANA Fast Restart option, see the high availability deployment guides: |
SAP HANA HA/DR provider hooks (Recommended) |
SAP HANA HA/DR provider hooks allow SAP HANA to send out notifications
for certain events to the Pacemaker cluster thereby improving
failure detection. The SAP HANA HA/DR provider hooks require
For more information about using the SAP HANA HA/DR provider hooks, see the high availability deployment guides: |
OS-native HA clusters for SAP HANA on Google Cloud
Linux operating system clustering provides application and guest awareness for your application state and automates recovery actions in case of failure.
Although the high-availability cluster principles that apply in non-cloud environments generally apply on Google Cloud, there are differences in how some things, such as fencing and virtual IPs, are implemented.
You can use either Red Hat or SUSE high-availability Linux distributions for your HA cluster for SAP HANA on Google Cloud.
For instructions for deploying and manually configuring an HA cluster on Google Cloud for SAP HANA, see:
- Manual HA scale-up cluster configuration on RHEL
- Manual HA cluster configuration on SLES:
For the automated deployment options that are provided by Google Cloud, see Automated deployment options for SAP HANA high-availability configurations.
Cluster resource agents
Both Red Hat and SUSE provide resource agents for Google Cloud with their high-availability implementations of the Pacemaker cluster software. The resource agents for Google Cloud manage fencing, VIPs that are implemented with either routes or alias IPs, and storage actions.
To deliver updates that are not yet included in the base OS resource agents, Google Cloud periodically provides companion resource agents for HA clusters for SAP. When these companion resource agents are required, the Google Cloud deployment procedures include a step for downloading them.
Fencing agents
Fencing, in the context of Google Cloud Compute Engine OS clustering, takes the form of STONITH, which provides each member in a two node cluster with the ability to restart the other node.
Google Cloud provides two fencing agents for use with SAP on Linux
operating systems, the fence_gce agent that is included in certified Red Hat
and SUSE Linux distributions, and the legacy gcpstonith agent, which you can
also download for use with Linux distributions that do not include the
fence_gce agent. We recommend that you use the fence_gce agent, if
available.
Required IAM permissions for fencing agents
The fencing agents reboot VMs by making a reset call to the Compute Engine API. For authentication and authorization to access the API, the fence agents use the service account of the VM. The service account that a fence agent uses must be granted a role that includes the following permissions:
- compute.instances.get
- compute.instances.list
- compute.instances.reset
- compute.instances.start
- compute.instances.stop
- compute.zoneOperations.get
- logging.logEntries.create
- compute.zoneOperations.list
The predefined Compute Instance Admin role contains all of the required permissions.
To limit the scope of the reboot permission of the agent to the target node, you can configure resource-based access. For more information see, Configuring resource-based access.
Virtual IP address
High-availability clusters for SAP on Google Cloud use a virtual, or floating, IP address (VIP) to redirect network traffic from one host to another in the event of a failover.
Typical non-cloud deployments use a gratuitous Address Resolution Protocol (ARP) request to announce the movement and reallocation of a VIP to a new MAC address.
On Google Cloud, instead of using gratuitous ARP requests, you use one of several different methods to move and reallocate a VIP in an HA cluster. The recommended method is to use an internal TCP/UDP load balancer, but, depending on your needs, you can also use route-based VIP implementation or an alias-IP-based VIP implementation.
For more information about VIP implementation on Google Cloud, see Virtual IP implementation on Google Cloud.
Storage and replication
An SAP HANA HA cluster configuration uses synchronous SAP HANA System Replication to keep the primary and secondary SAP HANA databases in sync. The standard OS-provided resource agents for SAP HANA manage System Replication during a failover, starting and stopping the replication, and switching which instances are serving as the active and the standby instances in the replication process.
If you need shared file storage, NFS- or SMB-based filers can provide the required functionality.
For a high-availability shared storage solution you can use Filestore, the Premium or Extreme service level of Google Cloud NetApp Volumes, or a third-party file-sharing solution. The Regional service tier (formerly Enterprise) of Filestore can be used for multi-zone deployments and the Basic tier of Filestore can be used for single-zone deployments.
Compute Engine regional persistent disks offer synchronously replicated block storage across zones. Although regional persistent disks are not supported for database storage in SAP HA systems, you can use them with NFS file servers.
For more information about storage options on Google Cloud, see:
Configuration settings for HA clusters on Google Cloud
Google Cloud recommends changing the default values of certain cluster configuration parameters to values that are better suited for SAP systems in the Google Cloud environment. If you use the automation scripts that are provided by Google Cloud, the recommended values are set for you.
Consider the recommended values as a starting point for tuning the Corosync settings in your HA cluster. You need to confirm that the sensitivity of failure detection and failover triggering are appropriate for your systems and workloads in the Google Cloud environment.
Corosync configuration parameter values
In the HA cluster configuration guides for SAP HANA, Google Cloud
recommends values for several parameters
in the totem section of the corosync.conf configuration file that are
different than the default values that are set by Corosync or your Linux
distributor.
totem parameters for which Google Cloud
recommends values, along with the impact of changing the values. For the default values
of these parameters, which can differ between Linux distributions, see the documentation
for your Linux distribution.
| Parameter | Recommended value | Impact of changing the value |
|---|---|---|
secauth |
off |
Disables authentication and encryption of all totem messages. |
join |
60 (ms) | Increases how long the node waits for join messages
in the membership protocol. |
max_messages |
20 | Increases the maximum number of messages that might be sent by the node after receiving the token. |
token |
20000 (ms) |
Increases how long the node waits for a
Increasing the value of the
The value of the |
consensus |
N/A | Specifies, in milliseconds, how long to wait for consensus to be achieved before starting a new round of membership configuration.
We recommend that you omit this parameter. When the consensus,
then make sure that the value is 24000 or
1.2*token, whichever is greater.
|
token_retransmits_before_loss_const |
10 | Increases the number of token retransmits that the node attempts before it concludes that the recipient node has failed and takes action. |
transport |
|
Specifies the transport mechanism used by corosync. |
For more information about configuring the corosync.conf file, see
the configuration guide for your Linux distribution:
Time out and interval settings for cluster resources
When you define a cluster resource, you set interval
and timeout values, in seconds, for various resource operations (op).
For example:
primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations \$id="rsc_sap2_HA1_HDB00-operations" \ op monitor interval="10" timeout="600" \ op start interval="0" timeout="600" \ op stop interval="0" timeout="300" \ params SID="HA1" InstanceNumber="00" clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta is-managed="true" clone-node-max="1" target-role="Started" interleave="true"
The timeout values affect each of the resource operations differently, as
explained in the following table.
| Resource operation | Timeout action |
|---|---|
monitor |
If the timeout is exceeded, the monitoring status typically reports as failed, and the associated resource is considered in a failed state. The cluster attempts recovery options, which can include a failover. The cluster does not retry a failed monitoring operation. |
start |
If a resource fails to start before its timeout is reached, the cluster attempts to restart the resource. The behavior is dictated by the on-fail action that is associated with a resource. |
stop |
If a resource does not respond to a stop operation before the timeout is reached, this triggers a fencing event. |
Along with other cluster configuration settings, the interval and timeout
settings of the cluster resources affect how quickly the cluster software
detects a failure and triggers a failover.
The timeout and interval values that are suggested by Google Cloud in
the cluster configuration guides for SAP HANA account for Compute Engine
Live Migration
maintenance events.
Regardless of which timeout and interval values you use, you need to
evaluate the values when you test your cluster, particularly during live
migration testing, because the length of live migration events can vary slightly
depending on the machine type you are using and other factors, such as system
utilization.
Fencing resource settings
In the HA cluster configuration guides for SAP HANA, Google Cloud recommends several parameters while configuring the fencing resources of the HA cluster. The values recommended are different than the default values that are set by Corosync or your Linux distributor.
The following table shows the fencing parameters that Google Cloud recommends along with the recommended values and the details of the parameters. For the default values of the parameters, which can differ between Linux distributions, see the documentation for your Linux distribution.
| Parameter | Recommended value | Details |
|---|---|---|
pcmk_reboot_timeout |
300 (seconds) | Specifies the value of the timeout to use for reboot actions.
The
|
pcmk_monitor_retries |
4 | Specifies the maximum number of times to retry the
monitor command within the timeout period. |
pcmk_delay_max |
30 (seconds) | Specifies a random delay to fencing actions to prevent the cluster nodes from fencing each other at the same time. To avoid a fencing race by ensuring that only one instance is assigned a random delay, this parameter should only be enabled on one of the fencing resources in a two node HANA HA cluster (scale-up). On a scale-out HANA HA cluster, this parameter should be enabled on all nodes that are part of a site (either primary or secondary) |
Testing your HA cluster on Google Cloud
After your cluster is configured and the cluster and SAP HANA systems are deployed in your test environment, you need to test the cluster to confirm that the HA system is configured correctly and functioning as expected.
To confirm failover is working as expected, simulate various failure scenarios with the following actions:
- Shut down the VM
- Create a kernel panic
- Shut down the application
- Interrupt the network between the instances
Also, simulate a Compute Engine live migration event on the primary
host to confirm that it does not trigger a failover. You can simulate a
maintenance event by using the Google Cloud CLI command gcloud compute instances
simulate-maintenance-event.
Logging and monitoring
Resource agents can include logging capabilities that propagate logs to
Google Cloud Observability for analysis. Each resource agent includes configuration
information that identifies any logging options. In the case of bash
implementations, the logging option is gcloud logging.
You can also install the Cloud Logging agent to capture log output from operating system processes and correlate resource utilization with system events. The Logging agent captures default system logs, which include log data from Pacemaker and the clustering services. For more information, see About the Logging agent.
For information about using Cloud Monitoring to configure service checks that monitor the availability of service endpoints, see Managing uptime checks.
Service accounts and HA clusters
The actions that the cluster software can take in the Google Cloud environment are secured by the permissions that are granted to the service account of each host VM. For high-security environments, you can limit the permissions in the service accounts of your host VMs to conform to the principle of least privilege.
When limiting the service account permissions, keep in mind that your system might interact with Google Cloud services, such as Cloud Storage, so you might need to include permissions for those service interactions in the service account of the host VM.
For the most restrictive permissions, create a custom role with the minimum required permissions. For information about custom roles, see Creating and managing custom roles. You can further restrict permissions by limiting them to only specific instances of a resource, such as the VM instances in your HA cluster, by adding conditions in the role bindings of a resource's IAM policy.
The minimum permissions that your systems need depends on the Google Cloud resources that your systems access and the actions that your systems perform. Consequently, determining the minimum required permissions for the host VMs in your HA cluster might require you to investigate exactly which resources the systems on the host VM access and the actions that those systems perform with those resources.
As a starting point, the following list shows some HA cluster resources and the associated permissions that they require:
- Fencing
- compute.instances.list
- compute.instances.get
- compute.instances.reset
- compute.instances.stop
- compute.instances.start
- logging.logEntries.create
- compute.zones.list
- VIP implemented by using an alias IP
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.instances.updateNetworkInterface
- compute.zoneOperations.get
- logging.logEntries.create
- VIP implemented by using static routes
- compute.instances.list
- compute.instances.get
- compute.zones.list
- logging.logEntries.create
- compute.routes.get
- compute.routes.create
- compute.routes.delete
- compute.routes.update
- compute.routes.list
- compute.networks.updatePolicy
- compute.networks.get
- compute.globalOperations.get
- logging.logEntries.create
- VIP implemented by using an internal load balancer
- No specific permissions required - the load balancer operates on health check statuses that does not require the cluster to interact with or change resources in Google Cloud
Virtual IP implementation on Google Cloud
A high-availability cluster uses a floating or virtual IP address (VIP) to move its workload from one cluster node to another in the event of an unexpected failure or for scheduled maintenance. The IP address of the VIP doesn't change, so client applications are unaware that the work is being served by a different node.
A VIP is also referred to as a floating IP address.
On Google Cloud, VIPs are implemented slightly differently than they are in on-premises installations, in that when a failover occurs, gratuitous ARP requests cannot be used to announce the change. Instead, you can implement a VIP address for an SAP HA cluster by using one of the following methods:
- Internal passthrough Network Load Balancer failover support (recommended).
- Google Cloud static routes.
- Google Cloud alias IP addresses.
Internal passthrough Network Load Balancer VIP implementations
A load balancer typically distributes user traffic across multiple instances of your applications, both to distribute the workload across multiple active systems and to protect against a processing slowdown or failure on any one instance.
The internal passthrough Network Load Balancer also provides failover support that you can use with Compute Engine health checks to detect failures, trigger failover, and reroute traffic to a new primary SAP system in an OS-native HA cluster.
Failover support is the recommended VIP implementation for a variety of reasons, including:
- Load balancing on Compute Engine offers a 99.99% availability SLA.
- Load balancing supports multi-zone high-availability clusters, which protects against zone failures with predictable cross-zone failover times.
- Using load balancing reduces the time required to detect and trigger a failover, usually within seconds of the failure. Overall failover times are dependent on the failover times of each of the components in the HA system, which can include the hosts, database systems, application systems, and more.
- Using load balancing simplifies cluster configuration and reduces dependencies.
- Unlike a VIP implementation that uses routes, with load balancing, you can use IP ranges from your own VPC network, allowing you to reserve and configure them as needed.
- Load balancing can easily be used to reroute traffic to a secondary system for planned maintenance outages.
When you create a health check for a load balancer implementation of a VIP, you specify the host port that the health check probes to determine the health of the host. For an SAP HA cluster, specify a target host port that is in the private range, 49152-65535, to avoid clashing with other services. On the host VM, configure the target port with a secondary helper service, such as the socat utility or HAProxy.
For database clusters in which the secondary, standby system remains online, the health check and helper service enables load balancing to direct traffic to the online system that is currently serving as the primary system in the cluster.
Using the helper service and port redirection, you can trigger a failover for planned software maintenance on your SAP systems.
For more information about failover support, see Configuring failover for internal passthrough Network Load Balancers.
To deploy an HA cluster with a load-balancer VIP implementation, see:
- Terraform: SAP HANA high-availability cluster configuration guide
- HA cluster configuration guide for SAP HANA on RHEL
- HA cluster configuration guide for SAP HANA on SLES
Static route VIP implementations
The static route implementation also provides protection against zone failures, but requires you to use a VIP outside of the IP ranges of your existing VPC subnets where the VMs reside. Consequently, you also need to make sure that the VIP does not conflict with any external IP addresses in your extended network.
Static route implementations can also introduce complexity when used with shared VPC configurations, which are intended to segregate network configuration to a host project.
If you use a static route implementation for your VIP, consult with your network administrator to determine a suitable IP address for a static route implementation.
Alias IP VIP implementations
Alias IP VIP implementations are not recommended for multi-zone HA deployments because, if a zone fails, the reallocation of the alias IP to a node in a different zone can be delayed. Implement your VIP with an internal passthrough Network Load Balancer with failover support instead.
If you are deploying all nodes of your SAP HA cluster in the same zone, you can use an alias IP to implement a VIP for the HA cluster.
If you have existing multi-zone SAP HA clusters that use an alias IP implementation for the VIP, you can migrate to an internal passthrough Network Load Balancer implementation without changing your VIP address. Both alias IP addresses and internal passthrough Network Load Balancers use IP ranges from your VPC network.
While alias IP addresses are not recommended for VIP implementations in multi-zone HA clusters, they have other use cases in SAP deployments. For example, they can be used to provide a logical host name and IP assignments for flexible SAP deployments, such as those managed by SAP Landscape Management.
General best practices for VIPs on Google Cloud
For more information about VIPs on Google Cloud, see Best Practices for Floating IP Addresses.
SAP HANA host auto-failover on Google Cloud
Google Cloud supports SAP HANA host auto-failover, the local fault-recovery solution provided by SAP HANA. The host auto-failover solution uses one or more standby hosts that are kept in reserve to take over work from the master or a worker host in the event of a host failure. The standby hosts do not contain any data or process any work.
After a failover completes, the failed host is restarted as a standby host.
SAP supports up to three standby hosts in scale-out systems on Google Cloud. The standby hosts do not count against the maximum of 16 active hosts that SAP supports in scale-out systems on Google Cloud.
For more information from SAP about the host auto-failover solution, see Host Auto-Failover.
When to use SAP HANA host auto-failover on Google Cloud
SAP HANA host auto-failover protects against failures that affect a single node in an SAP HANA scale-out system, including failures of:
- The SAP HANA instance
- The host operating system
- The host VM
Regarding failures of the host VM, on Google Cloud, automatic restart, which typically restores the SAP HANA host VM faster than host auto-failover, and live migration together protect against both planned and unplanned VM outages. So for VM protection, SAP HANA host auto-failover solution is not necessary.
SAP HANA host auto-failover does not protect against zonal failures, because all the nodes of an SAP HANA scale-out system are deployed in a single zone.
SAP HANA host auto-failover does not preload SAP HANA data into the memory of standby nodes, so when a standby node takes over, the overall node recovery time is mainly determined by how long it takes to load the data into the memory of the standby node.
Consider using SAP HANA host auto-failover for the following scenarios:
- Failures in the software or host operating system of an SAP HANA node that might not be detected by Google Cloud.
- Lift and shift migrations, in which you need to reproduce your on-premises SAP HANA configuration until you can optimize SAP HANA for Google Cloud.
- When a fully-replicated, cross-zone, high-availability configuration is
cost prohibitive and your business can tolerate:
- A longer node recovery time due to the need to load SAP HANA data into the memory of a standby node.
- The risk of zonal failure.
The storage manager for SAP HANA
The /hana/data and /hana/log volumes are mounted on the master and
worker hosts only. When a takeover occurs, the host auto-failover solution
uses the SAP HANA Storage Connector API and the
Google Cloud storage manager for SAP HANA standby nodes to move the volume mounts from
the failed host to the standby host.
On Google Cloud, the storage manager for SAP HANA is required for SAP HANA systems that use SAP HANA host auto-failover.
Supported versions of the storage manager for SAP HANA
Versions 2.0 and later of the storage manager for SAP HANA are supported. All versions earlier than 2.0 are deprecated and not supported. If you are using an earlier version, then update your SAP HANA system to use the latest version of the storage manager for SAP HANA. See Updating the storage manager for SAP HANA.
To determine if your version is deprecated, open the gceStorageClient.py file.
The default installation directory is /hana/shared/gceStorageClient.
Starting with version 2.0, the version number is listed in the comments at
the top of the gceStorageClient.py file, as shown in the following example. If
the version number is missing, then you are looking at a deprecated version
of the storage manager for SAP HANA.
"""Google Cloud Storage Manager for SAP HANA Standby Nodes. The Storage Manager for SAP HANA implements the API from the SAP provided StorageConnectorClient to allow attaching and detaching of disks when running in Compute Engine. Build Date: Wed Jan 27 06:39:49 PST 2021 Version: 2.0.20210127.00-00 """
Installing the storage manager for SAP HANA
The recommended method for installing the storage manager for SAP HANA is to use an automated deployment method to deploy a scale-out SAP HANA system that includes the latest storage manager for SAP HANA.
If you need to add SAP HANA host auto-failover to an existing SAP HANA scale-out system on Google Cloud, then the recommended approach is similar: use the Terraform configuration file provided by Google Cloud to deploy a new scale-out SAP HANA system and then load the data into the new system from the existing system. To load the data, you can use either standard SAP HANA backup and restore procedures or SAP HANA system replication, which can limit downtime. For more information about system replication, see SAP Note 2473002 - Using HANA system replication to migrate scale out system.
If you cannot use an automated deployment method, then consider contacting an SAP solution consultant, such as can be found through Google Cloud Consulting services, for help manually installing the storage manager for SAP HANA.
The manual installation of the storage manager for SAP HANA into either an existing or new scale-out SAP HANA system is not currently documented.
For more information about the automated deployment options for SAP HANA host auto-failover, see Automated deployment of SAP HANA scale-out systems with SAP HANA host auto-failover.
Updating the storage manager for SAP HANA
You update the storage manager for SAP HANA by first downloading the installation
package and then running an installation script, which updates the
storage manager for SAP HANA executable in the SAP HANA /shared drive.
The following procedure is only for version 2 of the storage manager for SAP HANA. If you are using a version of the storage manager for SAP HANA that was downloaded before February 1, 2021, install version 2 before attempting to update the storage manager for SAP HANA.
To update the storage manager for SAP HANA:
Check the version of your current storage manager for SAP HANA:
RHEL
sudo yum check-update google-sapgcestorageclient
SLES
sudo zypper list-updates -r google-sapgcestorageclient
If an update exists, install the update:
RHEL
sudo yum update google-sapgcestorageclient
SLES
sudo zypper update
The updated storage manager for SAP HANA is installed in
/usr/sap/google-sapgcestorageclient/gceStorageClient.py.Replace the existing
gceStorageClient.pywith the updatedgceStorageClient.pyfile:If your existing
gceStorageClient.pyfile is in/hana/shared/gceStorageClient, the default installation location, use the installation script to update the file:sudo /usr/sap/google-sapgcestorageclient/install.sh
If your existing
gceStorageClient.pyfile is not in/hana/shared/gceStorageClient, copy the updated file into the same location as your existing file, replacing the existing file.
Configuration parameters in the global.ini file
Certain configuration parameters for the storage manager for SAP HANA,
including whether fencing is enabled or disabled, are stored in the
storage section of the SAP HANA global.ini file. When you use the Terraform
configuration file that is
provided by Google Cloud to deploy an SAP HANA
system with the host auto-failover function, the deployment process adds the
configuration parameters to the global.ini file for you.
The following example shows the contents of a global.ini that is created
for the storage manager for SAP HANA:
[persistence] basepath_datavolumes = %BASEPATH_DATAVOLUMES% basepath_logvolumes = %BASEPATH_LOGVOLUMES% use_mountpoints = %USE_MOUNTPOINTS% basepath_shared = %BASEPATH_SHARED% [storage] ha_provider = gceStorageClient ha_provider_path = %STORAGE_CONNECTOR_PATH% # # Example configuration for 2+1 setup # # partition_1_*__pd = node-mnt00001 # partition_2_*__pd = node-mnt00002 # partition_3_*__pd = node-mnt00003 # partition_*_data__dev = /dev/hana/data # partition_*_log__dev = /dev/hana/log # partition_*_*__gcloudAccount = svc-acct-name@project-id.iam.gserviceaccount.com # partition_*_data__mountOptions = -t xfs -o logbsize=256k # partition_*_log__mountOptions = -t xfs -o logbsize=256k # partition_*_*__fencing = disabled [trace] ha_gcestorageclient = info
Sudo access for the storage manager for SAP HANA
To manage SAP HANA services and storage, the
storage manager for SAP HANA uses the SID_LCadm
user account and requires sudo access to certain system
binaries.
If you use the automation scripts that Google Cloud provides to deploy SAP HANA with host auto-failover, the required sudo access is configured for you.
If you manually install the storage manager for SAP HANA, use the
visudo command to edit the /etc/sudoers file to give the
SID_LCadm user account sudo access to the following
required binaries.
Click the tab for your operating system:
RHEL
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof /usr/sbin/xfs_repair
SLES
/bin/kill /bin/mount /bin/umount /sbin/dmsetup /sbin/lvdisplay /sbin/lvscan /sbin/pvscan /sbin/vgchange /sbin/vgscan /sbin/xfs_repair /usr/bin/gcloud /usr/bin/lsof /usr/bin/mkdir /usr/bin/sg_persist /usr/bin/systemctl /usr/sbin/lsof
The following example shows an entry in the /etc/sudoers file. In the
example, the system ID for the associated SAP HANA system is replaced with
SID_LC. The example entry was created by the
Terraform configuration that is provided by Google Cloud for SAP HANA scale-out
with host auto-failover.
The entry that the Terraform configuration creates
includes binaries that are no longer required, but that are retained for
backward compatibility. You need to include only those binaries that
appear in the preceding list.
SID_LCadm ALL=NOPASSWD: /sbin/multipath,/sbin/multipathd,/etc/init.d/multipathd,/usr/bin/sg_persist,/bin/mount,/bin/umount,/bin/kill,/usr/bin/lsof,/usr/bin/systemctl,/usr/sbin/lsof,/usr/sbin/xfs_repair,/sbin/xfs_repair,/usr/bin/mkdir,/sbin/vgscan,/sbin/pvscan,/sbin/lvscan,/sbin/vgchange,/sbin/lvdisplay,/usr/bin/gcloud,/sbin/dmsetup
Configuring service account for the storage manager for SAP HANA
To enable host auto-failover for your SAP HANA scale-out system on Google Cloud, the storage manager for SAP HANA requires a service account. You can create a dedicated service account and grant it the required permissions to perform actions on your SAP HANA VMs, such as detaching and attaching disks during a failover. For information about how to create a service account, see Create a service account.
Required IAM permissions
For the service account used by the storage manager for SAP HANA, you must grant a role that includes the following IAM permissions:
To reset a VM instance by using the
gcloud compute instances resetcommand, grant thecompute.instances.resetpermission.To get information about a Persistent Disk or Hyperdisk volume by using the
gcloud compute disks describecommand, grant thecompute.disks.getpermission.To attach a disk to a VM instance by using the
gcloud compute instances attach-diskcommand, grant thecompute.instances.attachDiskpermission.To detach a disk from a VM instance by using the
gcloud compute instances detach-diskcommand, grant thecompute.instances.detachDiskpermission.To list VM instances by using the
gcloud compute instances listcommand, grant thecompute.instances.listpermission.To list the Persistent Disk or Hyperdisk volumes by using the
gcloud compute disks listcommand, grant thecompute.disks.listpermission.
You can grant the required permissions through custom roles or other predefined roles.
Also, set the VM's access scope to cloud-platform so that the
IAM permissions of the VM are completely determined
by the IAM roles that you grant to the service account.
By default the storage manager for SAP HANA uses the active service account or user account that the gcloud CLI is authorized to use on the hosts in the scale-out SAP HANA system.
To check the active account used by the storage manager for SAP HANA, use the following command:
gcloud auth list
For information about this command, see gcloud auth list.
To change the account that is used by the storage manager for SAP HANA, perform the following steps:
Make sure that the service account is available on each of the hosts in the scale-out SAP HANA system:
gcloud auth listIn the
global.inifile, update the[storage]section with the service account:[storage] ha_provider = gceStorageClient ... partition_*_*__gcloudAccount = SERVICE_ACCOUNTReplace
SERVICE_ACCOUNTwith the name of the service account, in email address format, that is used by the storage manager for SAP HANA. This service account is used when issuing anygcloudcommands from the storage manager for SAP HANA.
NFS storage for SAP HANA host auto-failover
An SAP HANA scale-out system with host auto-failover requires an NFS solution,
such as Filestore, to share the /hana/shared and /hanabackup
volumes between all hosts. You must set up the NFS solution yourself.
When you use an automated deployment method, you provide information about the NFS server in the deployment file, to mount the NFS directories during deployment.
The NFS volume that you use must be empty. Any existing files can conflict with the deployment process, particularly if the files or folders reference the SAP system ID (SID). The deployment process cannot determine whether the files can be overwritten.
The deployment process stores the /hana/shared and /hanabackup
volumes on the NFS server and mounts the NFS server on all hosts, including
the standby hosts. The master host then manages the NFS server.
If you are implementing a backup solution, such as the Cloud Storage Backint agent for SAP HANA, you can
remove the /hanabackup volume from the NFS server after the deployment is complete.
For more information about the available shared file solutions that are available on Google Cloud, see File sharing solutions for SAP on Google Cloud.
Operating system support
Google Cloud supports SAP HANA host auto-failover on only the following operating systems:
- RHEL for SAP 7.7 or later
- RHEL for SAP 8.1 or later
- RHEL for SAP 9.0 or later
-
Before you install any SAP software on RHEL for SAP 9.x, additional packages must be installed on
your host machines, especially
chkconfigandcompat-openssl11. If you use an image provided by Compute Engine, then these packages are automatically installed for you. For more information from SAP, see SAP Note 3108316 - Red Hat Enterprise Linux 9.x: Installation and Configuration .
-
Before you install any SAP software on RHEL for SAP 9.x, additional packages must be installed on
your host machines, especially
- SLES for SAP 12 SP5
- SLES for SAP 15 SP1 or later
To see the public images that are available from Compute Engine, see Images.
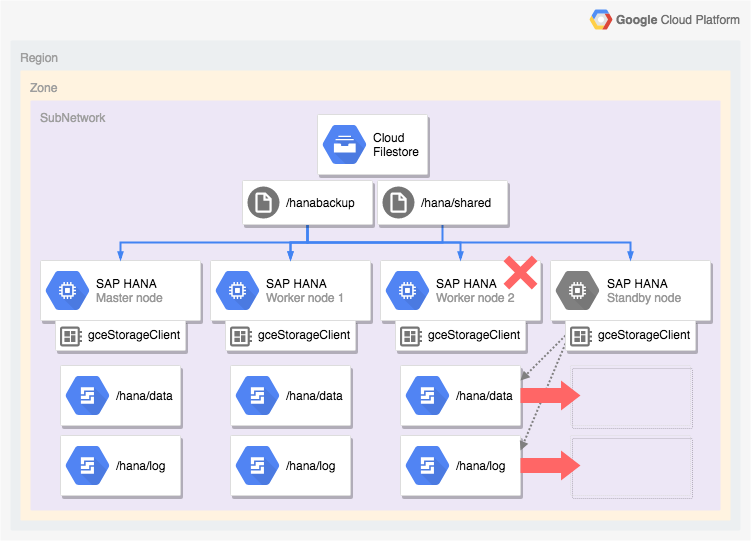
Architecture of an SAP HANA system with host auto-failover
The following diagram shows a scale-out architecture on Google Cloud that
includes the SAP HANA host auto-failover feature. In the diagram,
the storage manager for SAP HANA is represented by the name of
its executable, gceStorageClient.
The diagram shows worker node 2 failing and the standby node taking over.
The storage manager for SAP HANA works with the SAP Storage Connector
API (not shown) to detach the disks
that contain the /hana/data and /hana/logs volumes from the failed
worker node and to remount them on the standby node, which then becomes worker
node 2 while the failed node becomes the standby node.
Automated deployment options for SAP HANA high-availability configurations
Google Cloud provides Terraform configurations that you can use to automate the deployment of SAP HANA HA systems or you can deploy and configure your SAP HANA HA systems manually.
Google Cloud provides deployment-specific Terraform configuration files that you complete. You use the standard Terraform commands to initialize your current working directory and download the Terraform provider plugin and module files for Google Cloud, and apply the configuration to deploy an SAP HANA system.
This automated deployment method deploys an SAP HANA system for you that is fully supported by SAP and that adheres to the best practices of both SAP and Google Cloud.
Automated deployment of Linux high-availability clusters for SAP HANA
For SAP HANA, the automated deployment method deploys a performance-optimized, high-availability Linux cluster that includes:
- Automatic failover.
- Automatic restart.
- A reservation of the virtual IP address (VIP) that you specify.
- Failover support provided by internal TCP/UDP load balancing, which manages routing from the virtual IP address (VIP) to the nodes of the HA cluster.
- A firewall rule that allows Compute Engine health checks to monitor the VM instances in the cluster.
- The Pacemaker high-availability cluster resource manager.
- A Google Cloud fencing mechanism.
- A VM with the required persistent disks for each SAP HANA instance.
- Optionally, a sole-tenant node.
- SAP HANA instances configured for synchronous replication and memory preload.
To use Terraform to automate the deployment of a high-availability cluster for SAP HANA, see:
- Terraform: SAP HANA scale-up high-availability cluster configuration guide.
- Terraform: SAP HANA scale-out high-availability cluster configuration guide.
Automated deployment of SAP HANA scale-out systems with SAP HANA host auto-failover
You can use Terraform to automate the deployment of a scale-out system with standby hosts. For more information, see Terraform: SAP HANA scale-out system with host auto-failover deployment guide.
For an SAP HANA scale-out system that includes the SAP HANA host auto-failover feature, the Terraform configuration provided by Google Cloud deploys the following:
- One master SAP HANA instance
- 1 to 15 worker hosts
- 1 to 3 standby hosts
- A VM for each SAP HANA host
- SSD-based Persistent Disk or Hyperdisk volumes for the master and worker hosts
- The Google Cloud storage manager for SAP HANA standby nodes
An SAP HANA scale-out system with host auto-failover requires an NFS solution,
such as Filestore, to share the
/hana/shared and /hanabackup volumes between all hosts. So that Terraform
can mount the NFS directories during
deployment, you must set up the NFS solution yourself before you deploy the SAP
HANA system.
You can set up Filestore NFS server instances quickly by following the instructions at Creating Instances.
Active/Active (Read Enabled) option for SAP HANA
Starting with SAP HANA 2.0 SPS1, SAP provides the Active/Active (Read Enabled) setup for SAP HANA System Replication scenarios. In a replication system that is configured for Active/Active (Read Enabled), the SQL ports on the secondary system are open for read access. This makes it possible for you to use the secondary system for read-intense tasks and to have a better balance of workloads across compute resources, improving the overall performance of your SAP HANA database. For more information about the Active/Active (Read Enabled) feature, see the SAP HANA Administration Guide specific to your SAP HANA version and SAP Note 1999880.
To configure a system replication that enables read access on your secondary system, you need to use the operation mode logreplay_readaccess. However, to use this operation mode, your primary and secondary systems must run the same SAP HANA version. Consequently, read-only access to the secondary system is not possible during a rolling upgrade until both systems run the same SAP HANA version.
To connect to an Active/Active (read enabled) secondary system, SAP supports the following options:
- Connect directly by opening an explicit connection to the secondary system.
- Connect indirectly by executing an SQL statement on the primary system with a hint, which on evaluation reroutes the query to the secondary system.
The following diagram shows the first option, where applications access the secondary system directly in a Pacemaker cluster deployed in Google Cloud. An additional floating or virtual IP address (VIP) is used to target the VM instance that is serving as the secondary system as part of the SAP HANA Pacemaker cluster. The VIP follows the secondary system and can move its read workload from one cluster node to another in the event of an unexpected failure or for scheduled maintenance. For information about the available VIP implementation methods, see Virtual IP implementation on Google Cloud.

For instructions to configure SAP HANA system replication with Active/Active (read enabled) in a Pacemaker cluster:
- Configure HANA Active/Active (Read Enabled) in a SUSE Pacemaker cluster
- Configure HANA Active/Active (Read Enabled) in a Red Hat Pacemaker cluster
What's next
Both Google Cloud and SAP provide more information about high availability.
More information from Google Cloud about high availability
For more information about high-availability for SAP HANA on Google Cloud, see SAP HANA Operations Guide.
For general information about protecting systems on Google Cloud against various failure scenarios, see Designing robust systems.
More information from SAP about SAP HANA high-availability features
For more information from SAP about SAP HANA high-availability features, refer to the following documents:
- High Availability for SAP HANA
- SAP Note 2057595 - FAQ: SAP HANA High Availability
- How To Perform System Replication for SAP HANA 2.0
- Network Recommendations for SAP HANA System Replication