Dataproc と Google Cloud には、データを保護するためのさまざまな機能があります。このガイドでは、Hadoop のセキュリティの仕組みと Google Cloud への移行方法について説明し、Google Cloud へのデプロイ時にセキュリティを設計する方法のガイダンスを提供します。
概要
オンプレミス Hadoop デプロイメントの一般的なセキュリティ モデルとその仕組みは、クラウドのセキュリティ モデルとその仕組みとは異なります。Hadoop のセキュリティを理解することで、Google Cloud へのデプロイ時にセキュリティをより適切に設計できます。
Google Cloud に Hadoop をデプロイするには、Google が管理するクラスタ(Dataproc)としてデプロイする方法と、ユーザー管理クラスタ(Compute Engine での Hadoop)としてデプロイする方法の 2 種類があります。このガイドの内容と技術的なガイダンスのほとんどは、両方のデプロイ方法に適用されます。このガイドでは、両方のデプロイメントに適用されるコンセプトと手順を指すときに Dataproc / Hadoop という用語を使います。このガイドでは、Dataproc へのデプロイが Compute Engine 上の Hadoop へのデプロイと異なるいくつかのケースを説明します。
一般的なオンプレミス Hadoop のセキュリティ
次の図は、一般的なオンプレミス Hadoop インフラストラクチャとその保護方法を示しています。Hadoop 基本コンポーネント間のやり取りと、Hadoop 基本コンポーネントとユーザー管理システム間のやり取りに注意してください。
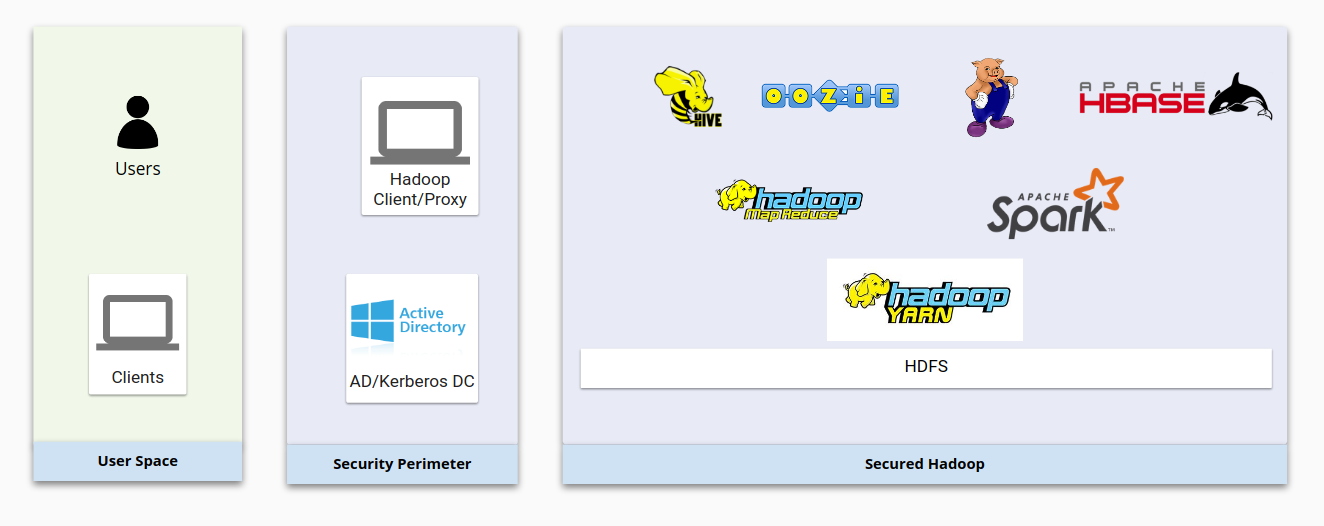
全体的に、Hadoop のセキュリティは以下の 4 つの要素に基づいています。
- 認証は、LDAP または Active Directory と統合された Kerberos によって実現します。
- 承認は、HDFS と、ユーザーに Hadoop リソースへの適切なアクセス権があることを確認するセキュリティ製品(Apache Sentry、Apache Ranger など)によって実現します。
- 暗号化は、ネットワーク暗号化と HDFS 暗号化によって実現します。この 2 つの暗号化により、データは転送時と保管時の両方で保護されます。
- 監査は、ベンダー提供製品(Cloudera Navigator など)によって実現します。
ユーザー アカウントの観点から、Hadoop には ID の管理とデーモンの実行のためのユーザーおよびグループに関する独自の構造があります。たとえば、Hadoop の HDFS デーモンと YARN デーモンは、それぞれ Unix ユーザー hdfs と yarn として実行されます。詳細については、セキュアモードの Hadoop をご覧ください。
Hadoop ユーザーは通常、Linux システム ユーザーまたは Active Directory / LDAP ユーザーからマッピングされます。Active Directory のユーザーとグループは、Centrify や RedHat SSSD などのツールによって同期されます。
Hadoop オンプレミス認証
セキュアなシステムでは、ユーザーとサービスがシステムに対し身元を証明する必要があります。Hadoop セキュアモードでは、認証に Kerberos が使用されます。ほとんどの Hadoop コンポーネントは、認証に Kerberos を使用するように設計されています。Kerberos は通常、エンタープライズ認証システム(Active Directory や LDAP に準拠するシステムなど)内に実装されています。
Kerberos プリンシパル
Kerberos のユーザーはプリンシパルと呼ばれます。Hadoop デプロイメントには、ユーザー プリンシパルとサービス プリンシパルがあります。通常、ユーザー プリンシパルは Active Directory またはその他のユーザー管理システムからキー配布センター(KDC)に同期されます。1 つのユーザー プリンシパルは 1 人のユーザーを表します。サービス プリンシパルは、サーバーごとのサービスに固有であるため、各サーバーの各サービスには、サービスを表す独自のプリンシパルが 1 つあります。
keytab ファイル
keytab ファイルには、Kerberos プリンシパルとそのキーが含まれています。ユーザーとサービスは keytab を使用することで、インタラクティブ ツールを使用せず、またパスワードを入力せずに Hadoop サービスに対して認証できます。Hadoop により、各ノードのサービスごとにサービス プリンシパルが作成されます。これらのプリンシパルは、Hadoop ノードの keytab ファイルに格納されます。
SPNEGO
ウェブブラウザを使用して Kerberos クラスタにアクセスする場合、ブラウザが Kerberos キーを渡す方法を認識している必要があります。このために、ウェブ アプリケーションで Kerberos を使用できるようにする Simple and Protected GSS-API Negotiation Mechanism(SPNEGO)が使用されます。
統合
ユーザー認証だけでなく、サービス認証のためにも Hadoop は Kerberos と統合します。ノード上の Hadoop サービスには、認証に使用される独自の Kerberos プリンシパルがあります。通常、サービスの keytab ファイルはサーバーに格納されており、この keytab ファイルにはランダムなパスワードが含まれています。
人間であるユーザーは、サービスを操作するには kinit コマンド、Centrify、SSSD のいずれかを使って Kerberos チケットを取得する必要があります。
Hadoop オンプレミス: 承認
ID の検証後、承認システムによりユーザーまたはサービスのアクセス権のタイプが確認されます。Hadoop では、承認機能を提供するため Apache Sentry や Apache Ranger などのオープンソース プロジェクトが使用されています。
Apache Sentry と Apache Ranger
Apache Sentry と Apache Ranger は、Hadoop クラスタで使用される一般的な承認メカニズムです。Sentry または Ranger が ID へのアクセスを承認または拒否したときの動作を指定するため、Hadoop のコンポーネントは専用の Sentry または Ranger のプラグインを実装します。Sentry と Ranger は、Kerberos、LDAP、AD などの認証システムに依存しています。Hadoop のグループ マッピング メカニズムにより、Sentry または Ranger は、Hadoop エコシステムのその他のコンポーネントが認識するものと同じグループ マッピングを認識します。
HDFS の権限と ACL
HDFS は、POSIX に似た権限システムとアクセス制御リスト(ACL)を使用して、ユーザーがファイルにアクセスできるかどうかを判別します。各ファイルとディレクトリは、オーナーとグループに関連付けられています。この構造には、スーパーユーザーが所有するルートフォルダがあります。構造のレベルによって、暗号化、所有権、権限、拡張 ACL(facl)は異なります。
次の図に示すように、権限は通常、グループのアクセスニーズに基づいて特定のグループにディレクトリ レベルで付与されます。アクセス パターンは異なる役割として識別され、Active Directory のグループにマッピングされます。一般に、1 つのデータセットに含まれるオブジェクトは、特定グループの権限が設定されているレイヤで、データカテゴリごとに異なるディレクトリに保存されています。
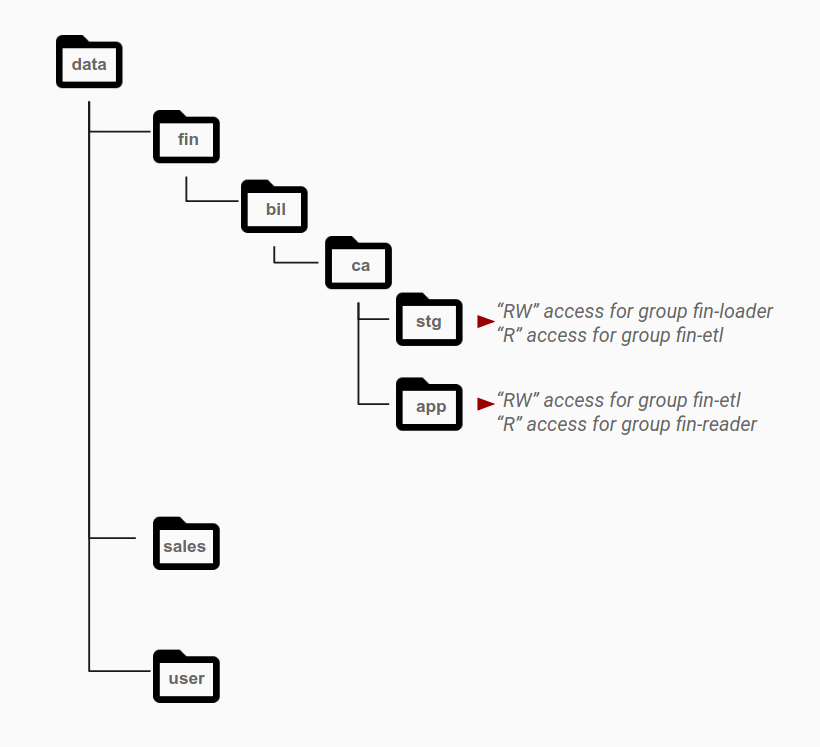
たとえば、stg ディレクトリは財務データのステージング領域です。stg フォルダには、fin-loader グループに対する読み書き権限があります。このステージング領域で、ETL パイプラインを表す別のアプリケーション アカウント グループ fin-etl には、このディレクトリへの読み取り専用アクセス権があります。ETL パイプラインはデータを処理し、そのデータを app ディレクトリに提供用に保存します。このアクセス パターンを有効にするために、app ディレクトリは fin-etl グループ(ETL データの書き込みに使用される ID)に対して読み書きアクセス権を持ち、処理結果のデータを消費する fin-reader グループに対しては読み取り専用アクセス権を持ちます。
Hadoop オンプレミス: 暗号化
Hadoop では、保存データと転送中のデータを暗号化できます。保存データを暗号化するには、Java ベースの鍵暗号化またはベンダー提供の暗号化ソリューションを使用して HDFS を暗号化できます。HDFS では暗号化ゾーンがサポートされているため、異なるファイルの暗号化に異なる鍵を利用できます。各暗号化ゾーンには、ゾーンの作成時に指定される 1 つの暗号化ゾーン鍵が関連付けられています。
暗号化ゾーン内の各ファイルには、固有のデータ暗号鍵(DEK)があります。HDFS は DEK を直接処理することはありません。代わりに、HDFS は暗号化されたデータ暗号鍵(EDEK)のみを処理します。クライアントは EDEK を復号し、後続の DEK を使用してデータを読み書きします。HDFS データノードは、暗号化バイトのストリームを参照するだけです。
Hadoop ノード間のデータ転送は、Transport Layer Security(TLS)を使用して暗号化できます。TLS により、Hadoop の 2 つのコンポーネント間の通信に暗号化と認証が実装されます。通常、Hadoop はコンポーネント間の TLS に内部 CA 署名証明書を使用します。
Hadoop オンプレミス: 監査
監査は、セキュリティにおいて重要な部分です。監査では疑わしいアクティビティを特定でき、またリソースにアクセスしたユーザーを記録できます。通常、Hadoop での監査トレースなどのデータ管理の目的で、Cloudera Navigator やその他のサードパーティのツールが使用されます。これらのツールは、Hadoop データストア内のデータと、そのデータに対して実行される計算を可視化し、これらのデータと計算を制御します。データ監査では、システム内のすべてのアクティビティの完全で不変なレコードを取得できます。
Google Cloud での Hadoop
従来のオンプレミス Hadoop 環境では、Hadoop セキュリティの 4 つの要素(認証、承認、暗号化、監査)が統合され、異なるコンポーネントによって処理されます。Google Cloud では、Dataproc と Compute Engine 上の Hadoop の両方の外部にあるさまざまな Google Cloud コンポーネントにより処理されます。
ウェブベースのインターフェースである Google Cloud コンソールを使用して Google Cloud リソースを管理できます。また、Google Cloud CLI を使用することもできます。コマンドラインの操作に慣れている場合は、このツールの方が使いやすく、迅速に作業できることがあります。gcloud コマンドを実行するには、ローカルのパソコンに gcloud CLI をインストールするか、Cloud Shell のインスタンスを使用します。
Hadoop Google Cloud 認証
Google Cloud には、サービス アカウントとユーザー アカウントという 2 種類の Google ID があります。ほとんどの Google API では、Google ID による認証が必要です。一部の Google Cloud APIs は、認証なしで(API キーを使用して)動作しますが、すべての API でサービス アカウント認証を使用することをおすすめします。
サービス アカウントは秘密鍵を使用して ID を確立します。ユーザー アカウントは OAUTH 2.0 プロトコルを使用してエンドユーザーを認証します。詳細については、認証の概要をご覧ください。
Hadoop Google Cloud 認可
Google Cloud では、認証された ID が一連のリソースに対してどのような権限を持つかを複数の方法で指定できます。
IAM
Google Cloud の Identity and Access Management(IAM)では、どのユーザー(プリンシパル)に、どのリソースに対するどのようなアクセス権(ロール)を付与するのかを定義して、アクセス制御を管理できます。
IAM を使用すると、Google Cloud リソースへのアクセス権を付与し、その他のリソースへの不正なアクセスを防ぐことができます。IAM では最小権限のセキュリティ原則を導入して、リソースに対する必要なアクセス権のみを付与できます。
サービス アカウント
サービス アカウントは、個々のエンドユーザーではなく、アプリケーションや仮想マシン(VM)に属している特別な種類の Google アカウントです。アプリケーションは、サービス アカウントの認証情報を使用して、他の Cloud API に対して自身を認証できます。また管理者は、各インスタンスに割り当てられているサービス アカウントに基づいてインスタンスとの間のトラフィックを許可または拒否するファイアウォール ルールを作成できます。
Dataproc クラスタは、Compute Engine VM 上に構築されています。Dataproc クラスタの作成時にカスタム サービス アカウントを割り当てると、そのサービス アカウントはクラスタ内のすべての VM に割り当てられます。これにより、クラスタによる Google Cloud リソースに対するきめ細かいアクセス制御が実現します。サービス アカウントを指定しないと、Dataproc VM は Google が管理するデフォルトの Compute Engine サービス アカウントを使用します。このアカウントには、広範なプロジェクト編集者役割がデフォルトで設定されており、さまざまな権限が付与されます。本番環境で Dataproc クラスタを作成する場合は、デフォルトのサービス アカウントを使用しないことをおすすめします。
サービス アカウントの権限
カスタム サービス アカウントを Dataproc / Hadoop クラスタに割り当てる場合、対象のサービス アカウントのアクセスレベルは、クラスタの VM インスタンスに付与されているアクセス スコープとサービス アカウントに付与されている IAM ロールの組み合わせによって決定されます。カスタム サービス アカウントを使用してインスタンスを設定するには、アクセス スコープと IAM ロールの両方を構成する必要があります。基本的に、これらのメカニズムは次のように相互作用します。
- アクセス スコープは、インスタンスに付与されているアクセス権を承認します。
- IAM は、インスタンスが使用するサービス アカウントに付与されているロールにアクセス権を制限します。
- アクセス スコープと IAM ロールの組み合わせに共通する権限が、インスタンスの最終的な権限になります。
Google Cloud コンソールで Dataproc クラスタまたは Compute Engine インスタンスを作成する際、インスタンスのアクセス スコープを選択します。
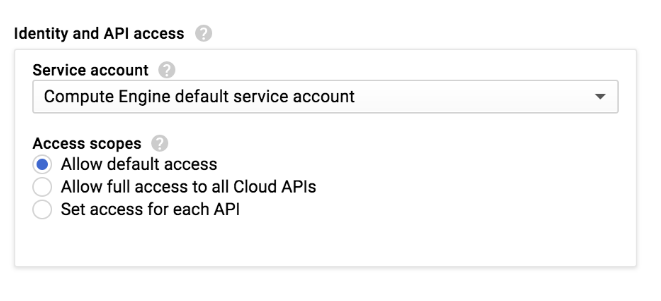
Dataproc クラスタまたは Compute Engine インスタンスでは、[デフォルトのアクセス権を許可] 設定で使用可能な一連のアクセス スコープが定義されています。
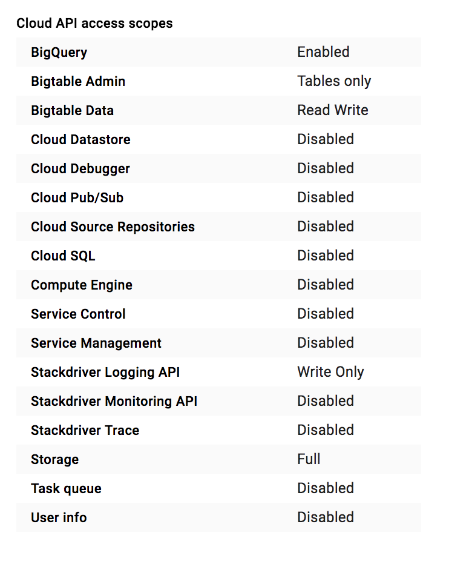
多数のアクセス スコープから選択できます。新しい VM インスタンスまたはクラスタを作成するときは、コンソールで [すべての Cloud APIs に完全アクセス権を許可] を設定するか、Google Cloud CLI を使用している場合は https://www.googleapis.com/auth/cloud-platform アクセス スコープを設定することをおすすめします。これらのスコープは、すべての Google Cloud サービスへのアクセスを許可します。スコープを設定したら、IAM ロールをクラスタのサービス アカウントに割り当てて、そのアクセス権を制限することをおすすめします。
アカウントでは、Google Cloud のアクセス スコープにかかわらず、これらのロールのスコープ外のアクションは実行できません。詳細については、サービス アカウント権限のドキュメントをご覧ください。
IAM と Apache Sentry および Apache Ranger の比較
IAM は、Apache Sentry と Apache Ranger に似た役割を果たします。IAM はロールを使用してアクセス権を定義します。他の Google Cloud コンポーネントへのアクセスはこれらのロールで定義されており、サービス アカウントに関連付けられます。つまり、同じサービス アカウントを使用するすべてのインスタンスには、他の Google Cloud リソースに対する同じアクセス権が付与されることになります。また、これらのインスタンスにアクセスできるユーザーにも、これらの Google Cloud リソースに対し、サービス アカウントと同じアクセス権が付与されます。
Dataproc クラスタと Compute Engine インスタンスには、Google のユーザーとグループを Linux のユーザーとグループにマッピングするメカニズムがありません。ただし、Linux ユーザーとグループを作成することはできます。Dataproc クラスタ内部または Compute Engine VM 内部では、HDFS の権限と、Hadoop のユーザーおよびグループのマッピングは引き続き機能します。このマッピングを使用して、HDFS へのアクセスを制限し、YARN キューを使用してリソース割り当てを適用できます。
Dataproc クラスタまたは Compute Engine VM 上のアプリケーションが Cloud Storage や BigQuery などの外部リソースにアクセスする必要がある場合、これらのアプリケーションは、クラスタ内の VM に割り当てられているサービス アカウントの ID として認証されます。さらに IAM を使用して、アプリケーションで必要とされる最小レベルのアクセス権をクラスタのカスタム サービス アカウントに付与します。
Cloud Storage の権限
Dataproc は、ストレージ システムとして Cloud Storage を使用します。Dataproc はローカル HDFS システムも提供しますが、Dataproc クラスタが削除されると HDFS は使用できなくなります。アプリケーションが HDFS に厳密に依存していない場合は、Cloud Storage を使用して Google Cloud を最大限に活用することをおすすめします。
Cloud Storage にはストレージ階層はありません。ディレクトリ構造は、ファイル システムの構造をシミュレートします。また、POSIX のような権限もありません。IAM ユーザー アカウントとサービス アカウントによるアカウント制御は、バケットレベルで設定できます。権限が Linux ユーザーに基づいて強制的に適用されることはありません。
Hadoop Google Cloud 暗号化
いくつかの例外を除いて、Google Cloud サービスはさまざまな暗号化方式を使用して、お客様のコンテンツを保管時も転送時も暗号化します。暗号化は自動で行われるため、お客様による操作は必要ありません。
たとえば、永続ディスクに保存される新規データは 256 ビット高度暗号化標準(AES-256)で暗号化され、各暗号鍵自体も定期的にローテーションされる一連のルート(マスター)鍵によって暗号化されます。Google Cloud が使用する暗号化や鍵管理ポリシー、暗号ライブラリ、ルート オブ トラストは、Gmail や Google の自社データを含む多くの Google の本番環境サービスでも採用されています。
ほとんどのオンプレミス Hadoop 実装とは異なり、暗号化は Google Cloud のデフォルト機能であるため、独自の暗号鍵を使用する場合以外は、暗号化の実装は不要です。Google Cloud には、顧客管理の暗号鍵ソリューションと顧客指定の暗号鍵ソリューションもあります。必要に応じて、暗号鍵を各自で管理したり、オンプレミスに保管したりできます。
詳細については、保存データの暗号化と転送データの暗号化をご覧ください。
Hadoop Google Cloud 監査
Cloud Audit Logs は、プロジェクトおよび組織ごとに数種類のログを保持できます。Google Cloud サービスによって、これらのログに監査ログエントリが書き込まれ、Google Cloud プロジェクト内で誰が、何を、どこで、いつ行ったかを調べるのに役立ちます。
監査ログおよび監査ログを書き込むサービスについて詳しくは、Cloud Audit Logs のドキュメントをご覧ください。
移行プロセス
Google Cloud で Hadoop を安全かつ効率的に運用するために、このセクションで説明する手順に従ってください。
このセクションでは、Google Cloud 環境をすでに設定していることを前提としています。これには、Google Workspace でのユーザーとグループの作成も含まれます。これらのユーザーとグループは、手動で管理されるか、または Active Directory と同期されます。すべての構成が完了しているため、ユーザー認証の観点において、Google Cloud は完全に機能しています。
ID の管理者を決定する
Google のほとんどのお客様は、Cloud Identity で ID を管理しています。しかし、Google Cloud ID とは別に企業 ID を管理しているお客様もいます。その場合、クラウド リソースへのエンドユーザー アクセスは POSIX および SSH の権限により決定します。
独立した ID システムを使用している場合は、最初に Google Cloud のサービス アカウントキーを作成してダウンロードします。次に、オンプレミス POSIX および SSH セキュリティ モデルを Google Cloud モデルと連携するため、ダウンロードしたサービス アカウント キーファイルに対し適切な POSIX 形式のアクセス権限を付与します。オンプレミスの ID に対し、これらのキーファイルへのアクセスを許可または拒否します。
前述の作業を行うと、各自の ID 管理システムによって監査機能が管理されます。監査証跡を提供するには、エッジノードでのユーザー ログインの SSH ログ(サービス アカウント キーファイルが保持されているログ)を使用するか、またはサービス アカウントの認証情報をユーザーから取得する厳密で明示的なキーストア メカニズムを選択できます。後者の場合、「サービス アカウントの権限借用」はキーストア レイヤで監査ログに記録されます。
1 つのデータ プロジェクトと複数のデータ プロジェクトのどちらを使用するかを決定する
組織に大量のデータがある場合、データは複数の Cloud Storage バケットに分割されます。また、これらのデータバケットをプロジェクト間で分散する方法についても検討する必要があります。Google Cloud を使用し始めたときには少量のデータから始め、ワークロードとアプリケーションの移動に伴い、移動データを増加したくなるかもしれません。
すべてのデータバケットを 1 つのプロジェクトに配置すると便利なように見えますが、必ずしも適切な方法とは限りません。データへのアクセスを管理するには、バケット用のフラットなディレクトリ構造と IAM 役割を使用します。そのため、バケットの数の増加に伴い、管理が難しくなることがあります。
別の方法として、各組織に専用のプロジェクトを複数作成し(財務部門向けのプロジェクト、法務グループ向けのプロジェクトなど)、それらのプロジェクトにデータを格納する方法があります。この場合、各グループはグループ独自の権限を個別に管理します。
データ処理中に、アドホック バケットにアクセスするか、またはアドホック バケットを作成する必要がある場合があります。この処理は、信頼境界間で分割されることがあります(データ サイエンティストが、自分が所有していないプロセスによって生成されるデータにアクセスする場合など)。
次の図に、1 つのデータ プロジェクトと複数のデータ プロジェクトでの Cloud Storage データの一般的な編成を示します。
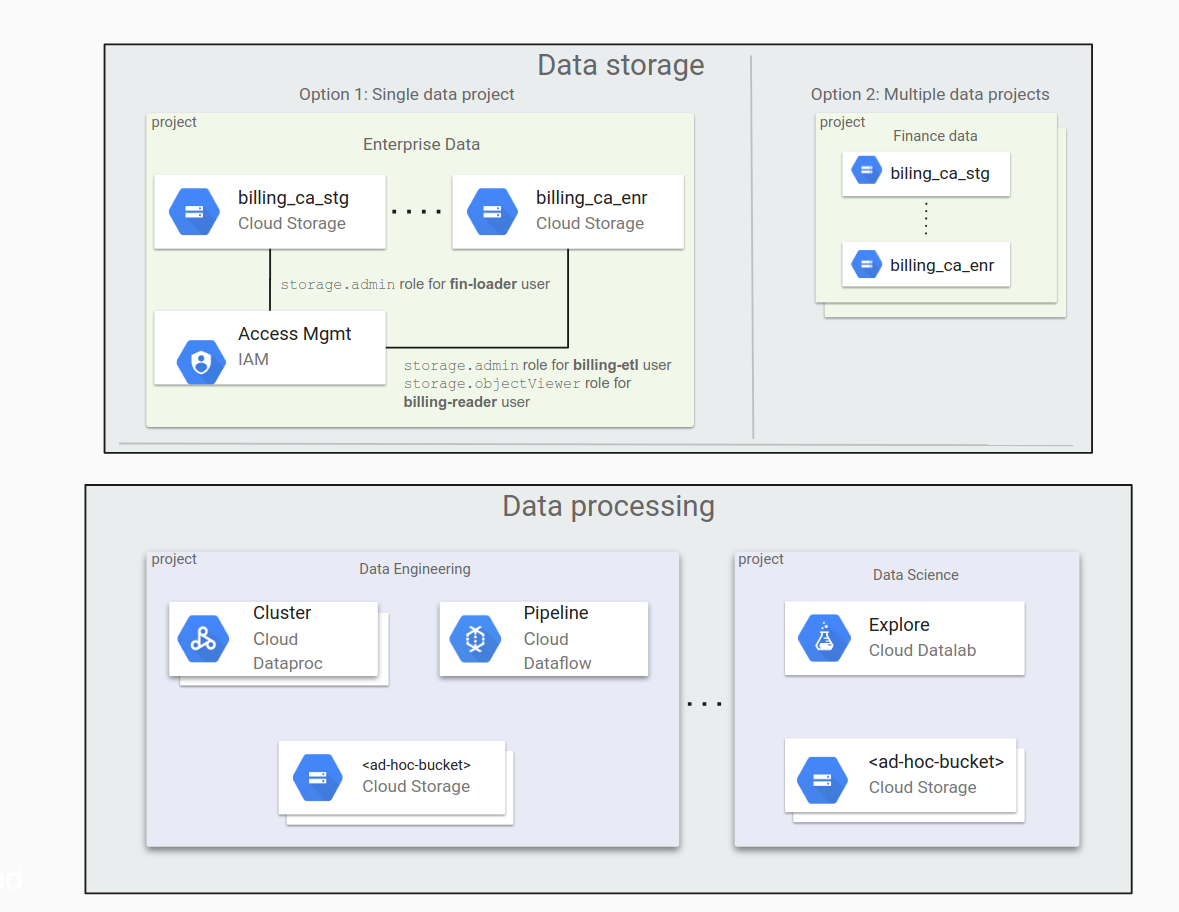
組織にとって最適な方法を決定する際に検討すべき重要な点を以下に示します。
単独のデータ プロジェクト:
- バケットの数が少ない場合は、すべてのバケットを容易に管理できます。
- ほとんどの場合、権限の付与は管理グループのメンバーにより行われます。
複数のデータ プロジェクト:
- 管理上の責任をプロジェクト オーナーに容易に委任できます。
- この方法は、組織で複数の異なる権限付与プロセスを使用している場合に便利です。たとえば、マーケティング部門のプロジェクトと法務部門のプロジェクトでは、権限付与のプロセスが異なる場合があります。
アプリケーションを特定してサービス アカウントを作成する
Dataproc / Hadoop クラスタがその他の Google Cloud リソース(Cloud Storage など)を操作する場合は、Dataproc / Hadoop で実行されるすべてのアプリケーションと、これらのアプリケーションに必要なアクセス権限を特定する必要があります。たとえば、カリフォルニア州の財務データを financial-ca バケットに取り込む ETL ジョブがあるとします。この ETL ジョブには、バケットへの読み書きアクセス権限が必要です。Hadoop を使用するアプリケーションを特定したら、各アプリケーションのサービス アカウントを作成できます。
このアクセス権は、Dataproc クラスタ内または Compute Engine 上の Hadoop 内の Linux ユーザーには影響しないことに注意してください。
サービス アカウントの詳細については、サービス アカウントの作成と管理をご覧ください。
サービス アカウントに権限を付与する
各アプリケーションに、異なる Cloud Storage バケットへのどのようなアクセス権限が必要であるかが判明している場合は、該当するアプリケーション サービス アカウントにこれらの権限を設定できます。アプリケーションがその他の Google Cloud コンポーネント(BigQuery や Bigtable など)にアクセスする必要がある場合は、サービス アカウントを使用してこれらのコンポーネントへの権限を付与できます。
たとえば、カリフォルニア州のマーケティング データとセールスデータをまとめて運用レポートを生成できるようにするには、ETL アプリケーションとして operation-ca-etl を指定し、財務部門のデータバケットにレポートを書き込むための権限を付与します。次に、marketing-report-ca アプリケーションと sales-report-ca アプリケーションに、それぞれの部門への読み書きアクセス権限を設定します。次の図はこの設定を示しています。
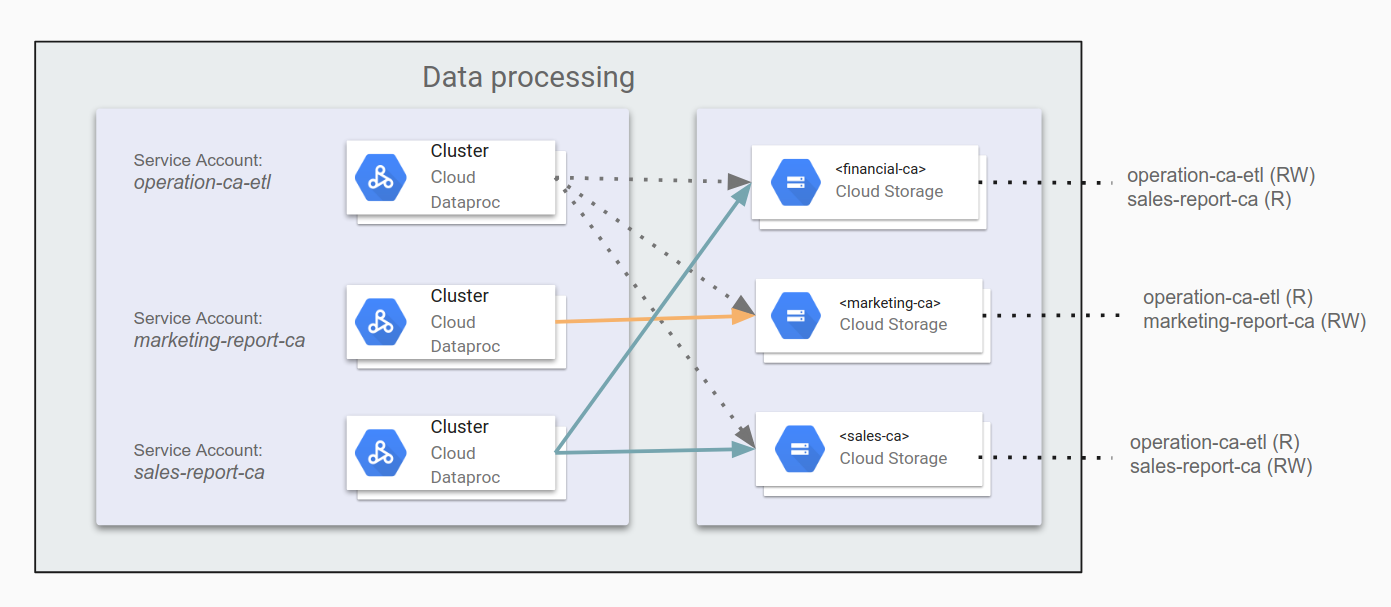
最小権限の原則に従う必要があります。この原則では、1 つ以上のタスクを実行するために必要な最小権限だけを、各ユーザー アカウントまたはサービス アカウントに付与することが規定されています。Google Cloud のデフォルトの権限は、使いやすく、設定時間を短縮できるように最適化されています。セキュリティとコンプライアンスの審査に合格できる Hadoop インフラストラクチャを構築するには、制限の厳しい権限を設計する必要があります。早期の時点で取り組み、戦略を文書化することで、安全な準拠パイプラインを提供でき、またセキュリティ チームとコンプライアンス チームによるアーキテクチャの審査の際に役立ちます。
クラスタを作成する
アクセス権を計画して構成したら、作成したサービス アカウントを使用して Dataproc クラスタまたは Compute Engine 上の Hadoop を作成できます。各クラスタは、サービス アカウントに付与されている権限に基づいてその他の Google Cloud コンポーネントにアクセスできます。Google Cloud にアクセスするための正しいアクセス スコープを指定してから、サービス アカウントへのアクセス権を使用して調整してください。アクセスの問題が発生した場合(特に Compute Engine 上の Hadoop の場合)、これらの権限を必ず確認してください。
特定のサービス アカウントで Dataproc クラスタを作成するには、次の gcloud コマンドを使用します。
gcloud dataproc clusters create [CLUSTER_NAME] \
--service-account=[SERVICE_ACCOUNT_NAME]@[PROJECT+_ID].iam.gserviceaccount.comn \
--scopes=scope[, ...]
以下の理由から、デフォルトの Compute Engine サービス アカウントは使用しないことをおすすめします。
- 複数のクラスタと Compute Engine VM でデフォルトの Compute Engine サービス アカウントが使用されている場合、監査が困難になります。
- デフォルトの Compute Engine サービス アカウントのプロジェクト設定が変わる可能性があります。つまり、クラスタが必要としている以上の権限が存在する場合があります。
- デフォルトの Compute Engine サービス アカウントを変更すると、クラスタや、クラスタ内で実行されているアプリケーションに意図しない影響が及ぶことや、それらが機能しなくなることがあります。
クラスタ別に IAM の権限を設定することを検討する
1 つのプロジェクトに多数のクラスタを配置すると、それらのクラスタの管理が容易になりますが、クラスタへのアクセスを保護する点ではこれは最善の方法ではない可能性があります。たとえば、プロジェクト A にクラスタ 1 と 2 がある場合、一部のユーザーにクラスタ 1 で作業する適切な権限があるが、クラスタ 2 での権限が多すぎることがあります。さらに問題なのは、クラスタ 2 がこのプロジェクトに含まれているというだけの理由で、クラスタ 2 にアクセスすべきではない場合にクラスタ 2 へのアクセス権が付与されることがあります。
次の図に示すように、プロジェクトに多数のクラスタが含まれていると、それらのクラスタへのアクセスが複雑になる可能性があります。
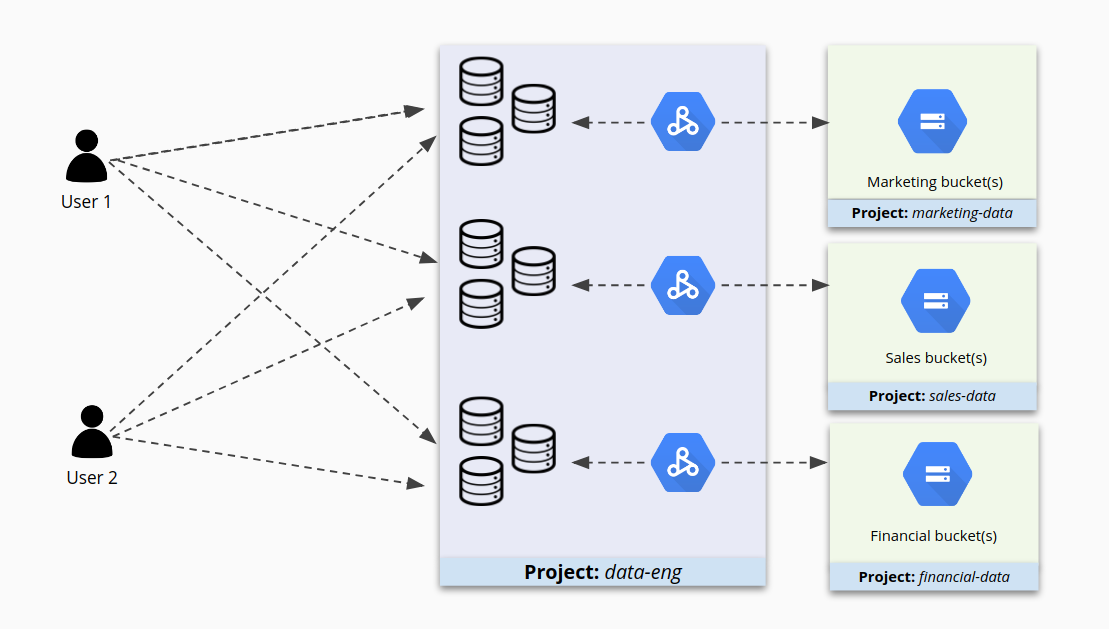
代わりに類似するクラスタを小さなプロジェクトにまとめ、IAM をクラスタごとに個別に構成すると、アクセスを細かく制御できます。これで、ユーザーは各自に必要なクラスタにアクセスでき、それ以外のクラスタへのアクセスが制限されます。
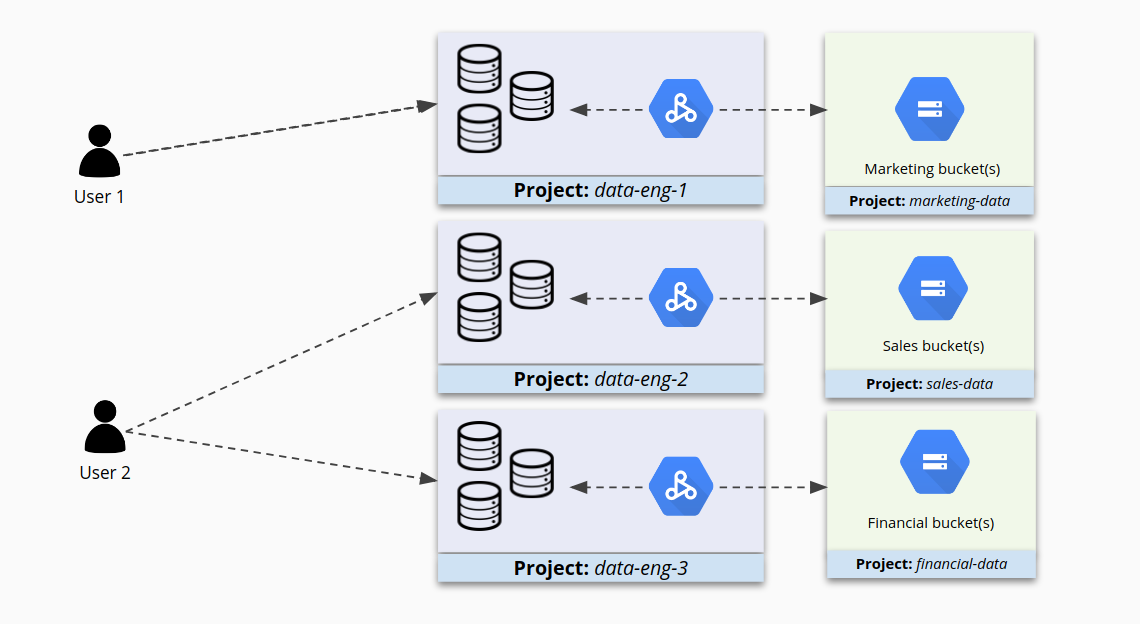
クラスタへのアクセスを制限する
サービス アカウントを使用してアクセス権を設定すると、Dataproc / Hadoop と他の Google Cloud コンポーネントとの間のやり取りが保護されます。ただし、Dataproc / Hadoop にアクセスできるユーザーを完全に制御するわけではありません。たとえば、Dataproc / Hadoop クラスタノードの IP アドレスを持つクラスタ内のユーザーは(場合に応じて)SSH を使用して接続し、またジョブを送信できます。オンプレミス環境では、システム管理者は通常、Hadoop クラスタへのアクセスを制限するため、サブネット、ファイアウォール ルール、Linux 認証、その他の戦略を利用しています。
Compute Engine で Dataproc / Hadoop を実行する際には、Google Workspace または Google Cloud 認証のレベルでアクセスを制限するさまざまな方法があります。ただし、このガイドでは Google Cloud コンポーネント レベルでのアクセスを中心に説明しています。
OS ログインを使用した SSH ログインの制限
オンプレミス環境では、ユーザーの Hadoop ノードへの接続を制限するために、境界アクセス制御、Linux レベルの SSH アクセス、sudoer ファイルを設定する必要があります。
Google Cloud では、次の手順に沿って、Compute Engine インスタンス接続に対するユーザーレベルの SSH 制限を構成できます。
- プロジェクトまたは個々のインスタンスで OS ログイン機能を有効にします。
- ご自身と他のプリンシパルに必要な IAM のロールを付与します。
- 必要に応じて、ご自身とその他のプリンシパルのユーザー アカウントにカスタム SSH 認証鍵を追加します。別の方法として、Compute Engine による SSH 認証鍵の自動生成も利用できます。その場合は、インスタンスに接続するときに SSH 認証鍵が生成されます。
プロジェクト内の 1 つ以上のインスタンスで OS Login を有効化すると、それらのインスタンスはプロジェクトまたは組織内で必要な IAM ロールが割り当てられたユーザー アカウントからの接続のみを受け入れます。
たとえば、以下の手順でインスタンスへのアクセス権をユーザーに付与できます。
ユーザーに必要なインスタンス アクセスの役割を付与します。必要な役割は以下のとおりです。
iam.serviceAccountUserロール次のログインロールのいずれか
compute.osLoginロール(管理者の権限は付与されない)compute.osAdminLoginロール(管理者の権限が付与される)
組織外の Google ID にインスタンスへのアクセスを許可する場合は、組織の管理者が組織レベルでそれらの外部 ID に
compute.osLoginExternalUserロールを付与します。また、プロジェクト レベルまたは組織レベルでcompute.osLoginまたはcompute.osAdminLoginのいずれかのロールを外部 ID に付与する必要もあります。
必要な役割を構成したら、Compute Engine のツールを使用してインスタンスに接続します。Compute Engine によって自動的に SSH 認証鍵が生成されてユーザー アカウントに関連付けられます。
OS Login 機能の詳細については、OS Login を使用してインスタンス アクセスを管理するをご覧ください。
ファイアウォール ルールを使用したネットワーク アクセスの制限
Google Cloud では、サービス アカウントを使用して上り(内向き)トラフィックまたは下り(外向き)トラフィックをフィルタリングするファイアウォール ルールも作成できます。この方法は、以下の状況で特に効果的です。
- さまざまなユーザーやアプリケーションが Hadoop にアクセスする必要がある場合。つまり、IP に基づくルールの作成が困難な場合。
- エフェメラル Hadoop クラスタまたはクライアント VM を実行しており、IP アドレスが頻繁に変更される場合。
ファイアウォール ルールをサービス アカウントと組み合わせて使用すると、特定のサービス アカウントだけを許可するように、特定の Cloud Dataproc / Hadoop クラスタへのアクセスを設定できます。これにより、そのサービス アカウントとして実行されている VM だけが、指定されたレベルでクラスタにアクセスできます。
以下に、サービス アカウントを使用してアクセスを制限するプロセスの図を示します。dataproc-app-1、dataproc-1、dataproc-2、app-1-client はすべてサービス アカウントです。ファイアウォール ルールにより、dataproc-app-1 に対し dataproc-1 と dataproc-2 へのアクセスが許可され、app-1-client を使用するクライアントに対し dataproc-1 へのアクセスが許可されます。ストレージ側では、Cloud Storage へのアクセスと権限は、ファイアウォール ルールではなく、サービス アカウントへの Cloud Storage の権限によって制限されます。
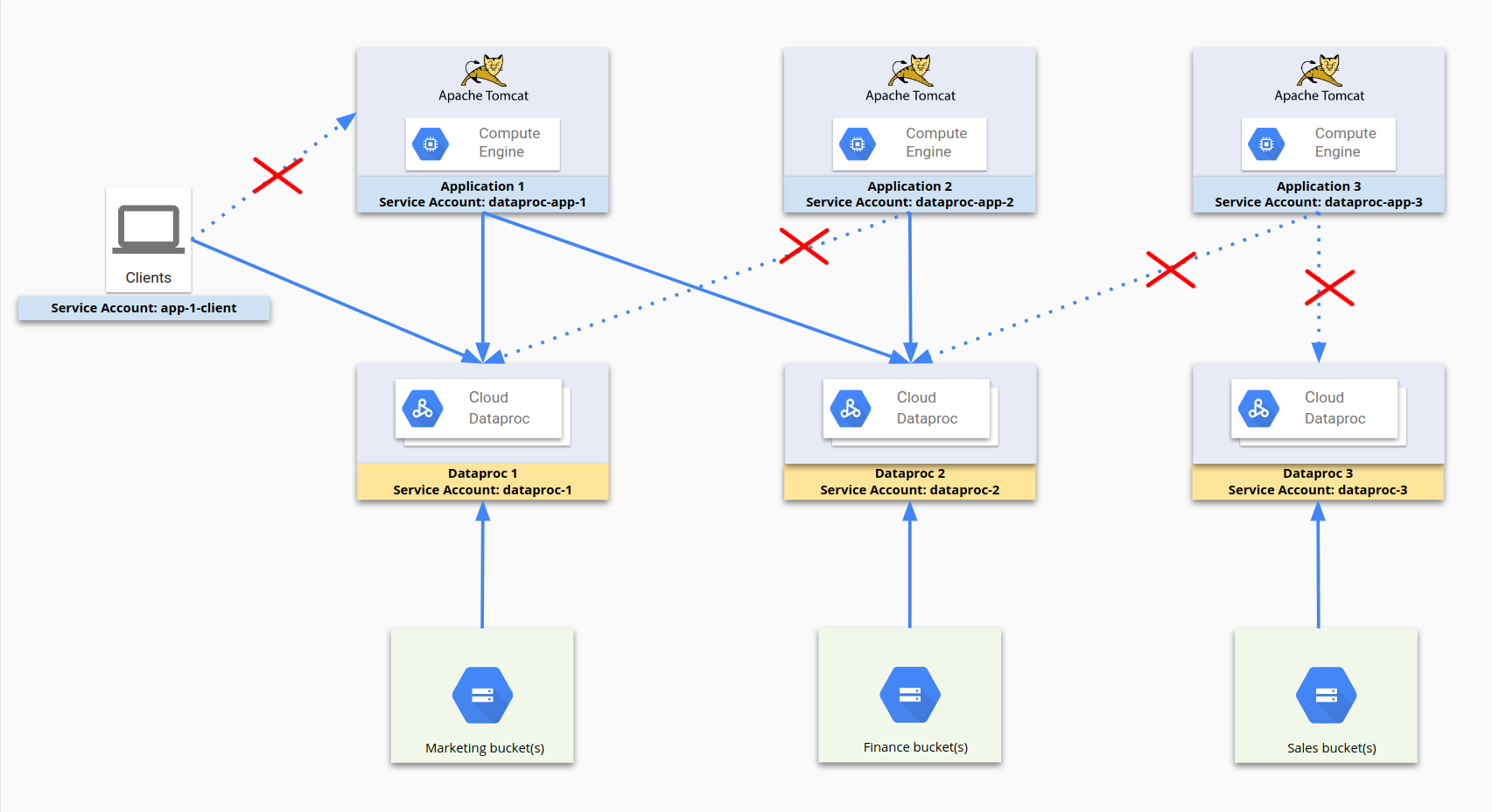
この構成では、次のファイアウォール ルールが設定されています。
| ルール名 | 設定 |
|---|---|
dp1 |
ターゲット: dataproc-1送信元: [IP 範囲] 送信元 SA: dataproc-app-1Allow [ポート] |
dp2 |
ターゲット: dataproc-2送信元: [IP 範囲] 送信元 SA: dataproc-app-2Allow [ポート] |
dp2-2 |
ターゲット: dataproc-2送信元: [IP 範囲] 送信元 SA: dataproc-app-1Allow [ポート] |
app-1-client |
ターゲット: dataproc-1送信元: [IP 範囲] 送信元 SA: app-1-clientAllow [ポート] |
ファイアウォール ルールとサービス アカウントの使用方法の詳細は、サービス アカウントによる送信元とターゲットのフィルタリングをご覧ください。
誤って開いているファイアウォール ポートがないかどうかを確認する
クラスタで稼働するウェブベースのユーザー インターフェースを公開するうえで、適切なファイアウォール ルールを設定することも重要です。これらのインターフェースに接続するファイアウォール ポートが、インターネットに対して開いていないことを確認します。オープンポートと不適切に構成されたファイアウォール ルールが原因で、不正なユーザーが任意のコードを実行できる可能性があります。
たとえば Apache Hadoop YARN は、YARN ウェブ インターフェースと同じポートを共有する REST API を提供します。デフォルトでは、YARN ウェブ インターフェースにアクセスできるユーザーは、アプリケーションを作成し、ジョブを送信できるほか、Cloud Storage 操作を実行できることもあります。
Dataproc ネットワーク構成を確認し、SSH トンネルを作成して、クラスタのコントローラとの安全な接続を確立してください。ファイアウォール ルールとサービス アカウントの使用方法の詳細については、サービス アカウントによる送信元とターゲットのフィルタリングをご覧ください。
マルチテナント クラスタについて
一般に、異なるアプリケーションには個別の Dataproc / Hadoop クラスタを実行することがベストプラクティスです。ただし、マルチテナント クラスタを使用する必要があり、セキュリティ要件を遵守する必要がある場合は、Dataproc / Hadoop クラスタ内に Linux ユーザーとグループを作成し、YARN キューを使用して承認とリソース割り当てを行うことができます。Google ユーザーと Linux ユーザー間には直接のマッピングがないため、ユーザーが自分で認証機能を実装する必要があります。クラスタで Kerberos を有効にすると、クラスタのスコープ内で認証レベルが強化されます。
場合によっては、データ サインティストのグループなどのユーザーが Hadoop クラスタを使用してデータを検出し、モデルを構築することがあります。このような状況では、データへの同じアクセス権を共有するユーザーをグループ化して、専用の Dataproc / Hadoop クラスタを 1 つ作成することをおすすめします。これにより、データへのアクセス権が設定されているグループにユーザーを追加できます。クラスタ リソースは、Linux ユーザーに基づいて割り当てることもできます。