このドキュメントは、Google Cloud の障害復旧(DR)について説明するシリーズの一部です。このパートでは、Google Cloud を使用してワークロードを設計し、クラウド インフラストラクチャの障害から復旧するブロックを構築するプロセスについて説明します。
シリーズは次のパートで構成されています。
- 障害復旧計画ガイド
- 障害復旧の構成要素
- データの障害復旧シナリオ
- アプリケーションの障害復旧シナリオ
- 地域制限があるワークロードの障害復旧の設計
- 障害復旧のユースケース: 地域制限のあるデータ分析アプリケーション
- クラウド インフラストラクチャの停止に対する障害復旧の設計(このドキュメント)
はじめに
ワークロードをパブリック クラウドに移行する場合は、オンプレミスで復元力の高いシステムを構築したときの知識や経験から離れ、Google Cloud などのクラウド プロバイダのハイパースケーリング インフラストラクチャの理解を深める必要があります。この記事では、RTO(リカバリ時間目標)や RPO(リカバリポイント目標)など、障害復旧に関する業界標準のコンセプトと Google Cloud インフラストラクチャの対応について説明します。
このドキュメントのガイダンスは、極めて優れたサービス可用性を実現する Google の重要な原則の 1 つ(障害に対する計画)に基づいています。Google Cloud は極めて信頼性の高いサービスを提供しますが、自然災害、ケーブル切断など、予測できないインフラストラクチャ障害でサービスが停止する可能性があります。サービス停止に対する計画を立てることで、Google Cloud プロダクトで「組み込み」の DR メカニズムを使用し、これらの予期しないイベントに対して耐障害性を備えたアプリケーションを作成できます。
障害復旧は包括的なトピックで、インフラストラクチャの障害だけでなく、ソフトウェアのバグやデータの破損なども含まれます。この記事では、DR 計画の一つである、クラウド インフラストラクチャの停止に耐障害性のあるアプリケーションを設計する方法に焦点を当てています。この記事の内容は以下のとおりです。
- Google Cloud インフラストラクチャ、Google Cloud の停止時として障害イベントを表す方法、停止の頻度と範囲を最小限に抑える Google Cloud の設計方法。
- アーキテクチャ計画ガイド。目的とする信頼性に基づいてアプリケーションを分類、設計するためのフレームワークを提供します。
- アプリケーションで使用可能な組み込み DR 機能を提供する Google Cloud プロダクトのリスト。
一般的な DR 計画の詳細と、オンプレミスの DR 戦略の一部として Google Cloud を使用する方法については、障害復旧計画ガイドをご覧ください。また、高可用性は障害復旧のコンセプトと密接に関連していますが、このドキュメントでは説明しません。高可用性の設計の詳細については、Google Cloud アーキテクチャ フレームワークをご覧ください。
用語に関する注意: この記事では、プロダクトに継続してアクセスし、使用できる状況を表す言葉として「可用性」という用語を使用しています。また、可用性だけでなく、耐久性や正確性という属性を含めた意味で「信頼性」という用語を使用しています。
Google Cloud で復元力を高める設計方法
Google データセンター
従来型のデータセンターでは、個々のコンポーネントの可用性を最大限に高める必要があります。クラウドでは、Google などの運用企業が仮想化テクノロジーを使用して多数のコンポーネントにサービスを分散させ、従来のコンポーネントを超える信頼性を提供しています。信頼性を考える基準が変わり、オンプレミスで問題になっていたことを心配する必要はありません。冷却装置や電源装置などの故障モードではなく、Google Cloud プロダクトとその信頼性の指標を評価し、計画を立てます。これらの指標には、基盤となるインフラストラクチャ全体の停止リスクが反映されています。これにより、インフラストラクチャの管理ではなく、アプリケーションの設計、デプロイ、運用に集中できます。
Google では、最新のデータセンターの構築と運営に関する豊富な経験に基づいて、高い可用性目標を満たすインフラストラクチャを設計しています。Google は、データセンター設計における世界的なリーダーとして位置づけられています。電源から冷却、ネットワークまで、それぞれのデータセンターの技術に対し、独自の冗長性と緩和策を実現しています(FMEA プランなど)。Google のデータセンターは、さまざまなリスクをバランスよく考慮し、Google Cloud プロダクトに期待されるレベルの可用性を一貫して提供できるように構築されています。Google では、この経験に基づき、物理アーキテクチャと論理システム アーキテクチャ全体の可用性をモデル化し、データセンターの設計が期待どおり機能していることを確認しています。Google のエンジニアは、お客様の期待に応えるため、運用に多大な時間を費やしています。実際に測定された可用性は設計目標を大きく上回っています。
Google Cloud では、こうしたデータセンターのリスク対策をユーザー向けのプロダクトに組み込まれているので、データセンターの設計と運用を気にせず、Google Cloud のリージョンとゾーンの設計に重点を置くことができます。
リージョンとゾーン
Google Cloud プロダクトは、非常に多くのリージョンとゾーンにまたがって提供されています。リージョンとは、3 つ以上のゾーンから構成された物理的に独立した地理的なエリアです。ゾーンは、物理インフラストラクチャと論理インフラストラクチャの点で、それぞれ高い独立性を保つリージョン内にある物理的なコンピューティング リソースのグループを表します。同じリージョン内の他のゾーンと高帯域幅で低レイテンシのネットワークで接続されています。たとえば、日本の asia-northeast1 リージョンには 3 つのゾーン(asia-northeast1-a、asia-northeast1-b、asia-northeast1-c)があります。
Google Cloud プロダクトは、ゾーンリソース、リージョン リソース、マルチリージョン リソースに分類されます。
ゾーンリソースは、単一のゾーン内にホストされています。ゾーンでサービスが中断すると、そのゾーンのすべてのリソースが影響を受けます。たとえば、Compute Engine インスタンスは指定された単一ゾーンで実行されます。ハードウェア障害によってそのゾーンのサービスが中断した場合、復旧するまでその Compute Engine インスタンスを使用することはできません。
リージョン リソースは、リージョン内の複数のゾーンに重複してデプロイされます。そのため、リージョン リソースはゾーンリソースに比べて信頼性が高くなります。
マルチリージョン リソースは、リージョン内とリージョン間で分散されています。通常、マルチリージョン リソースはリージョン リソースよりも信頼性が高くなりますが、このレベルでは可用性、パフォーマンス、リソースの効率性を最適化する必要があります。そのためには、使用するマルチリージョン プロダクトのトレードオフを理解することが重要です。それぞれのトレードオフについては、このドキュメントの後半で説明します。
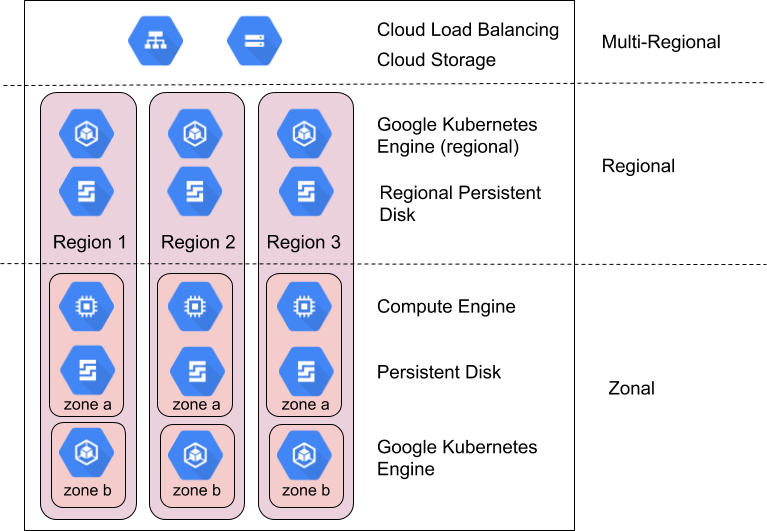
ゾーンとリージョンによる信頼性の実現
Google SRE は、世界中のコンピューティング インフラストラクチャをシームレスに実現するさまざまな手法や技術を通じて、Gmail や Google 検索のような信頼性の高いグローバル ユーザー プロダクトの管理とスケーリングを行っています。たとえば、グローバル ロード バランシングを使用して、使用不能なロケーションからトラフィックをリダイレクトし、世界中のさまざまな場所で複数のレプリカを実行しています。また、ロケーション間でデータの複製を行っています。Google Cloud のお客様には、Cloud Load Balancing、Google Kubernetes Engine(GKE)、Spanner などのプロダクトにより、これらの機能を提供しています。
Google Cloud では、ゾーンとリージョンに対して以下の可用性レベルを提供するプロダクトを設計しています。
| リソース | 例 | 可用性の設計目標 | 暗黙のダウンタイム |
|---|---|---|---|
| ゾーン | Compute Engine、Persistent Disk | 99.9% | 8.75 時間/年 |
| リージョン | リージョンの Cloud Storage、複製された Persistent Disk、リージョンの GKE | 99.99% | 52 分/年 |
Google Cloud の可用性の設計目標と適切なダウンタイム レベルを比較し、適切な Google Cloud リソースを選択してください。従来の設計では、コンポーネントの可用性を向上させてアプリケーションの可用性を向上させることに重点を置いていますが、クラウドモデルの場合は、目標を達成するためにコンポーネントを構成することに重点を置く必要があります。Google Cloud の多くのプロダクトで、この方法を使用しています。たとえば、Spanner は 99.999% の可用性を提供するため、複数のリージョンを構成するマルチリージョン データベースを提供します。
構成は重要です。これがないと、アプリケーションの可用性は、使用する Google Cloud プロダクトの可用性を超えることができません。実際に、アプリケーションで障害が発生しない限り、基盤となる Google Cloud プロダクトよりも可用性は低くなります。このセクションの残りの部分では、ゾーン プロダクトとリージョン プロダクトの構成を使用して、単一のゾーンまたはリージョンで提供される可用性よりもアプリケーションの可用性を高める方法を説明します。次のセクションでは、これらの原則をアプリケーションに適用するための実践的なガイドを紹介します。
ゾーン停止のスコープに対する計画
インフラストラクチャに障害が発生すると、通常は単一のゾーンでサービスが中断します。リージョン内では、ゾーンは他のゾーンとの連動障害のリスクを最小限に抑えるように設計されています。また、あるゾーンでサービスが中断しても、同じリージョン内の別のゾーンのサービスに影響することはありません。ゾーンをスコープとする停止が発生しても、ゾーン全体が使用できなくなるわけではありません。これは単にインシデントの境界を定義しているだけです。ゾーンが停止しても、そのゾーンの特定のリソースに影響が及ばないこともあります。
これはまれなことですが、1 つのリージョン内のあるポイントが停止し、結果的に複数のゾーンが停止することがあります。2 つ以上のゾーンでサービスが停止した場合は、以下のようにリージョン停止のスコープが適用されます。
リージョン リソースは、複数のゾーンの構成からサービスを提供することで、ゾーン停止に対する耐障害性を備えるように設計されています。リージョン リソースをバックアップするゾーンのいずれかでサービスが中断した場合、別のゾーンからリソースが利用できるようになります。詳細については、付録にあるプロダクトの機能説明をご覧ください。
Google Cloud から提供されるゾーンリソースは Compute Engine 仮想マシン(VM)と Persistent Disk だけです。ゾーンリソースを使用する場合は、複数のゾーンに配置されたゾーンリソース間のフェイルオーバーとリカバリを設計、構築、テストし、独自のリソース構成を使用する必要があります。以下のような戦略を実施します。
- ヘルスチェックでゾーンの問題が検出されたときに、Cloud Load Balancing を使用して、トラフィックを別のゾーンの仮想マシンに迅速にルーティングします。
- Compute Engine インスタンス テンプレートまたはマネージド インスタンス グループを使用して、複数のゾーンで同じ VM インスタンスを実行し、スケーリングします。
- リージョン Persistent Disk を使用して、データをリージョン内の別のゾーンに同期的に複製します。詳細については、リージョン PD を使用した高可用性オプションをご覧ください。
リージョン停止のスコープに対する計画
リージョン停止とは、単一リージョン内の複数のゾーンに影響するサービスの中断です。これは大規模な停止ですが、発生する頻度は低く、自然災害や大規模なインフラストラクチャの障害が原因となります。
99.99% の可用性を提供するように設計されたリージョン プロダクトの場合、許容されるダウンタイムは年間で 1 時間程度になります。したがって、重要なアプリケーションでこのような停止期間が許容できない場合は、マルチリージョンの DR 計画を用意する必要があります。
マルチリージョン リソースは、複数のリージョンからサービスを提供することで、リージョンの停止に対する耐障害性を備えるように設計されています。前述のように、マルチリージョン プロダクトではレイテンシ、整合性、コストがトレードオフになります。最も一般的なトレードオフは、データのレプリケーションを同期で行うのか、非同期で行うのかです。非同期レプリケーションの場合、レイテンシは低くなりますが、停止時にデータが損失するリスクは高くなります。付録にあるプロダクト機能の説明で詳細を確認してください。
リージョン リソースを使用し、リージョンの停止に対する耐障害性を維持するには、複数のリージョンに存在するリージョン リソース間でフェイルオーバーと復元を設計、構築、テストし、独自のリソース構成を使用する必要があります。前述のゾーン戦略は複数のリージョン間にも適用できます。次のことを検討してください。
- リージョン リソースは、Cloud Storage などのマルチリージョン ストレージ オプション、GKE Enterprise などのハイブリッド クラウド オプションを使用して、データをセカンダリ リージョンに複製する必要があります。
- リージョン停止の対策を作成したら、それを定期的にテストします。単一リージョンに対する耐障害性だけでは、現実的な状況に対応することはできません。
Google Cloud の耐障害性と可用性のアプローチ
Google Cloud は定期的な評価で可用性の設計目標を達成していますが、このパフォーマンスが設計可能な最小の可用性になるわけではありません。アプリケーションに期待する信頼性を上回るように Google Cloud のプロダクトを選択する必要があります。たとえば、アプリケーションのダウンタイムと Google Cloud のダウンタイムを考慮することで、求めている結果を実現できます。
適切に設計されたシステムであれば、「ゾーンまたはリージョンが 1 分、5 分、10 分、30 分間停止した場合どうなるか」という質問に的確に回答できるはずです。この質問には、次のように多層的に答える必要があります。
- 停止中にユーザーはどのような影響を受けるかのか。
- 停止が発生していることを、どのように検知するのか。
- 停止した場合、アプリケーションはどうなるのか。
- 停止した場合、データはどうなるのか。
- 依存関係のある他のアプリケーションにはどのような影響があるのか。
- 復旧後に復元するには、どうすればよいのか。誰が行うのか。
- 停止をどのタイミングで、いつまでに通知するのか。
Google Cloud でアプリケーションの障害復旧を設計するための設定ガイド
ここまでのセクションでは、Google がクラウド インフラストラクチャを構築している方法と、ゾーンとリージョンの停止に対処するいくつかの方法について説明しました。
このセクションでは、目的の信頼性に基づいてアプリケーションに構成の原則を適用するためのフレームワークを作成します。
RTO や RPO などの障害復旧目標をターゲットとする Google Cloud の顧客アプリケーションは、RTO / RPO の対象となるビジネス クリティカルなオペレーションが、サービスのオペレーションの継続的な処理を担うデータプレーン コンポーネントにのみ依存するように設計する必要があります。つまり、こうしたビジネス クリティカルなオペレーションは、構成の状態を管理し、コントロール プレーンとデータプレーンへの構成を push する管理プレーン オペレーションに依存してはなりません。
たとえば、ビジネス クリティカルなオペレーションの RTO を達成しようとしている Google Cloud のお客様は、VM で作成された API や IAM 権限の更新に依存すべきではありません。
ステップ 1: 既存の要件を収集する
最初のステップは、アプリケーションの可用性の要件を定義することです。ほとんどの企業では、この領域について設計上のガイダンスが存在しています。内部で開発している場合もあれば、規制や法的要件に基づいて作成している場合もあるでしょう。この設計上のガイダンスは通常、リカバリ時間目標(RTO)とリカバリ ポイント目標(RPO)の 2 つの主要な指標に基づいて作成されます。ビジネス上の用語では、RTO は「障害が発生してから稼働状態に戻るまでどのくらいの時間がかかるか」を意味します。RPO は「障害発生時に失われるデータの許容量」を意味します。

大規模な組織では、コンポーネントの障害から地震に至るまで、さまざまな障害イベントに対して RTO と RPO の要件を定義してきました。これは、プランナーがソフトウェアとハードウェア スタック全体を通して RTO / RPO の要件をマッピングする必要があるオンプレミス環境では意味のあることです。しかし、クラウド環境ではプロバイダがこのような処理を行うため、これほど細かい要件を定義する必要はありません。根本的な原因を明確に記述せず、損失のスコープ(ゾーン全体またはリージョン全体)だけで RTO と RPO の要件を定義できます。Google Cloud の場合、ゾーンの停止、リージョンの停止、複数のリージョンの停止(この状況が起きることはまずありませんが)の 3 つのシナリオで要件をまとめます。
すべてのアプリケーションが同じ重要性を持つわけではないので、アプリケーションを重要性の階層で分類し、それに特定の RTO / RPO 要件を適用します。つまり、RTO / RPO とアプリケーションの重要性を定義することにより、次の質問に答えることで特定のアプリケーションの設計を効率的に進めることができます。
- アプリケーションを同じリージョン内の複数のゾーンで実行する必要があるか。あるいは、複数のリージョンの複数のゾーンで実行する必要があるか。
- アプリケーションで使用できる Google Cloud プロダクトはどれか。
以下に、要件をまとめる際の例を示します。
Example Organization Co におけるアプリケーションの重要性ごとの RTO と RPO:
| アプリケーションの重要性 | アプリの割合 | アプリの例 | ゾーンの停止 | リージョンの停止 |
|---|---|---|---|---|
| 階層 1 (最も重要性が高い) |
5% | グローバルまたは外部ユーザー向けのアプリケーション(リアルタイムの決済システム、e コマースのショーウィンドウなど)。 | RTO ゼロ RPO ゼロ |
RTO ゼロ RPO ゼロ |
| 階層 2 | 35% | 標準的なリージョン アプリケーション、または重要な内部アプリケーション(CRM、ERP など)。 | RTO 15 分 RPO 15 分 |
RTO 1 時間 RPO 1 時間 |
| 階層 3 (最も重要性が低い) |
60% | 標準的なチームまたは部門用のアプリケーション(バックオフィス、休暇の申請、出張、会計、HR など)。 | RTO 1 時間 RPO 1 時間 |
RTO 12 時間 RPO 12 時間 |
ステップ 2: 利用可能なプロダクトと機能をマッピングする
次に、アプリケーションが使用する Google Cloud プロダクトの耐障害性を把握します。ほとんどの企業は、関連するプロダクトの情報を確認し、その機能と耐障害性の要件のギャップを埋めるためにアーキテクチャを変更する方法についてガイダンスを追加しています。このセクションでは、一般的な領域と、この領域におけるデータまたはアプリケーションの制限に関する推奨事項について説明します。
前述のように、Google の DR 対応プロダクトはリージョンとゾーンという 2 種類の停止スコープに対応しています。部分的な停止は、DR の完全停止と同じ方法で計画する必要があります。これにより、各シナリオのデフォルトに適したプロダクトの最初のリストをまとめることができます。
Google Cloud プロダクトの全般的な機能
(特定のプロダクト機能については、付録を参照)
| すべての Google Cloud プロダクト | ゾーン間の自動レプリケーションが可能なリージョン Google Cloud プロダクト | リージョン間の自動レプリケーション機能を備えたマルチリージョンまたはグローバル Google Cloud プロダクト | |
|---|---|---|---|
| ゾーン内のコンポーネントの障害 | 対象* | 対象 | 対象 |
| ゾーンの停止 | 対象外 | 対象 | 対象 |
| リージョンの停止 | 対象外 | 対象外 | 対象 |
* プロダクトのドキュメントに記載されている特別なケースを除き、すべての Google Cloud プロダクトはコンポーネントの障害に耐障害性を備えています。これは、プロダクトがメモリやソリッド ステート ディスク(SSD)などの特殊ハードウェアへの直接アクセスまたは静的マッピングを提供する標準的なシナリオになります。
RPO によるプロダクトの選択
ほとんどのクラウド環境で、サービスのアーキテクチャについて考慮すべき最も重要な点はデータの整合性です。アプリケーションの中には RPO 要件をゼロにするもの、つまり、停止時のデータ損失をゼロにしなければならないものがあります。この要件を満たすには、データを別のゾーンまたはリージョンに同期的に複製する必要があります。同期レプリケーションにはコストとレイテンシのトレードオフがあります。Google Cloud プロダクトの多くはゾーン間で同期レプリケーションを行いますが、リージョン間でのみ行うプロダクトもあります。このコストと複雑さのトレードオフは、アプリケーション内のデータの種類によって RPO 値が変わることがまずないことを意味します。
RPO がゼロより大きいデータの場合は、アプリケーションで非同期レプリケーションを利用できます。非同期レプリケーションは、失われたデータの再作成が簡単な場合や、必要に応じて確実なソースから復元できる場合に使用します。また、ゾーンとリージョンで想定される停止時間を考慮してデータの損失量が許容範囲であれば、合理的な選択になる場合もあります。また、一時的な停止であれば、影響を受けるロケーションに書き込まれたデータが他のロケーションにまだ複製されていなくても、復旧後にデータが利用可能になることもあります。これは、データを完全に損失するリスクが、停止時にデータアクセスが失われるリスクよりも低いことを意味します。
重要なアクション: RPO をゼロに設定する必要があるかどうかを判断します。その場合は、データのサブセットを対象にできるかどうかを判断します。これにより、DR 対応サービスの範囲が大幅に広がります。Google Cloud で RPO ゼロを達成するには、アプリケーションで主にリージョン プロダクトを使用する必要があります。これらのプロダクトの場合、デフォルトでゾーンスケールに対する耐障害性は提供されますが、リージョン スケールの停止に対する耐障害性は提供されません。
RTO によるプロダクトの選択
クラウド コンピューティングの主な利点の 1 つは、インフラストラクチャをオンデマンドでデプロイできることですが、瞬時にデプロイできるわけではありません。アプリケーションの RTO 値は、アプリケーションで使用する Google Cloud プロダクトの RTO と、エンジニアまたは SRE が VM またはアプリケーション コンポーネントの再起動で行うアクションの両方を考慮して調整する必要があります。RTO を分単位で設定した場合、人手を介さずに障害から自動的に回復するか、フェイルオーバー用のボタンを押すなど、最小限の手順でアプリケーションを復元できるようにアプリケーションを設計する必要があります。これまで、このようなシステムの構築には多大なコストがかかり、複雑な設計を行う必要がありましたが、ロードバランサやインスタンス グループなどの Google Cloud プロダクトでは、こうした設計をはるかにシンプルかつ簡単に行うことができます。したがって、ほとんどのアプリケーションでは、自動フェイルオーバーとリカバリを検討する必要があります。リージョン間でこのようなホット フェイルオーバーを行うシステムの設計は複雑で、コストがかかるものですが、クリティカル サービスのわずかな部分でこの機能が保証されます。
ほとんどのアプリケーションの RTO は 1 時間から 1 日です。これにより、障害シナリオでワーム フェイルオーバーが可能になります。たとえば、アプリケーションの一部のコンポーネント(データベースなど)は常時スタンバイ モードで実行し、残りのコンポーネント(ウェブサーバーなど)は実際の障害が発生したときにスケールアウトされるようにします。このようなアプリケーションでは、スケールアウト イベントの自動化を検討する必要があります。RTO が 1 日であるサービスは重要性が最も低く、多くの場合、バックアップから復元するか、最初から作り直すことができます。
重要なアクション: リージョン フェイルオーバーで RTO をゼロに設定する必要があるかどうかを判断します。その場合は、データのサブセットを対象にできるかどうかを判断します。これにより、サービスの実行と維持にかかるコストが変わります。
ステップ 3: 独自のリファレンス アーキテクチャとガイドを作成する
最後の推奨ステップは、障害復旧に関するアプローチを標準化するため、会社固有のアーキテクチャ パターンを構築することです。Google Cloud を利用している大半の企業は、個々のビジネス レジリエンスの期待値を Google Cloud の 2 つの停止シナリオに合わせるため、開発チーム用のガイドを作成しています。これにより、重要性のレベルに適した DR 対応プロダクトを簡単に分類できます。
プロダクト ガイドラインの作成
前述の RTO / RPO の例をもう一度見てください。仮説に基づいて、それぞれの重要性の層においてデフォルトで許可されるプロダクトが設定されています。特定のプロダクトが適切でないことが判明した時点で、ゾーン間またはリージョン間の同期を可能にする独自のレプリケーション / フェイルオーバー メカニズムを追加できますが、この記事の範囲を超えるため、その方法については説明しません。これらの表には、各プロダクトの詳細を確認できるリンクも記載されています。ゾーンやリージョンの停止を管理する際に利用できる機能を確認してください。
Example Organization Co のサンプル アーキテクチャ パターン - ゾーンの停止に対する耐障害性
| Google Cloud プロダクト | プロダクトが Example Organization のゾーン停止要件を満たしているか(適切なプロダクト構成を含む) | ||
|---|---|---|---|
| 階層 1 | 階層 2 | 階層 3 | |
| Compute Engine | × | いいえ | × |
| データフロー | × | いいえ | × |
| BigQuery | × | いいえ | ○ |
| GKE | ○ | はい | ○ |
| Cloud Storage | ○ | はい | ○ |
| Cloud SQL | × | ○ | ○ |
| Spanner | ○ | はい | ○ |
| Cloud Load Balancing | ○ | はい | ○ |
この表は、前述の仮定の階層に基づくサンプルです。
Example Organization Co のサンプル アーキテクチャ パターン - リージョンの停止に対する耐障害性
| Google Cloud プロダクト | プロダクトが Example Organization のリージョン停止要件を満たしているか(適切なプロダクト構成を含む) | ||
|---|---|---|---|
| 階層 1 | 階層 2 | 階層 3 | |
| Compute Engine | ○ | はい | ○ |
| Dataflow | × | いいえ | × |
| BigQuery | × | いいえ | ○ |
| GKE | ○ | はい | ○ |
| Cloud Storage | × | いいえ | × |
| Cloud SQL | × | ○ | ○ |
| Spanner | ○ | はい | ○ |
| Cloud Load Balancing | ○ | はい | ○ |
この表は、前述の仮定の階層に基づくサンプルです。
これらのプロダクトがどのように使用されるのかを説明するため、以降のセクションでは、アプリケーションに仮定した重要性レベルごとにリファレンス アーキテクチャを示します。これらは、アーキテクチャ上の重要な決定を説明するためのもので、ソリューションの全体的な設計を説明するものではありません。
階層 3 アーキテクチャの例
| アプリケーションの重要性 | ゾーンの停止 | リージョンの停止 |
|---|---|---|
| 階層 3 (最も低い重要性) |
RTO 12 時間 RPO 24 時間 |
RTO 28 日 RPO 24 時間 |
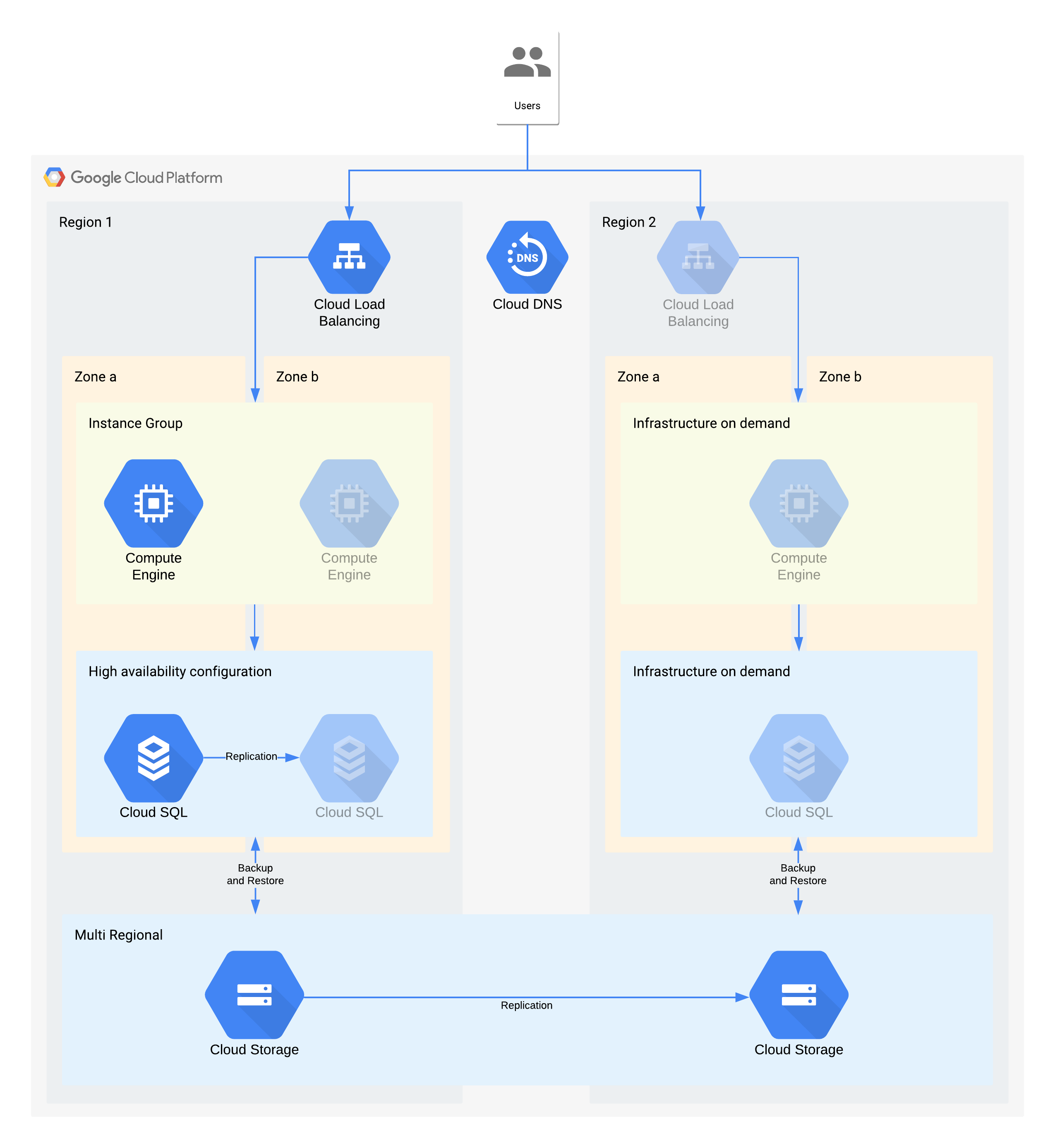
(グレー表示されたアイコンは、復元を有効にするインフラストラクチャを示しています)
このアーキテクチャは、従来のクライアント / サーバー型のアプリケーションを表しています。内部ユーザーは、コンピューティング インスタンス上で動作するアプリケーションに接続しています。このインスタンスは永続ストレージとしてデータベースを使用しています。
このアーキテクチャは必要以上の RTO と RPO 値をサポートしていることに注意してください。ただし、コストが増加する可能性がある場合や、信頼性が低くなる可能性がある場合は、人手による操作の削減をさらに検討する必要があります。たとえば、夜間のバックアップからデータベースを復元した場合、24 時間の RPO に対応できますが、このような作業にはデータベース管理者などの熟練したスタッフが必要になります。しかし、このようなスタッフを割り当てられるとは限りません。特に、複数のサービスが同時に影響を受けている場合はなおさらです。Google Cloud のオンデマンド インフラストラクチャでは、コスト増大のトレードオフを気にすることなく、こうした機能を構築できます。このアーキテクチャの場合、ゾーンの停止に手動によるバックアップと復元を行うのではなく、Cloud SQL HA を使用することにします。
ゾーン停止に対するアーキテクチャ上の重要な決定 - RTO 12 時間と RPO 24 時間
- 内部ロードバランサは、ユーザーにスケーラブルなアクセス ポイントを提供するために使用され、別のゾーンへの自動フェイルオーバーを可能にします。RTO は 12 時間ですが、IP アドレスや DNS の更新を手動で行う場合は、想定以上に時間がかかる場合があります。
- リージョンのマネージド インスタンス グループは複数のゾーンから構成されていますが、リソースは最小限になっています。これにより、コストが最適化されます。また、仮想マシンをバックアップ ゾーンに迅速にスケールアウトできます。
- Cloud SQL の高可用性構成により、別のゾーンへの自動フェイルオーバーを実現しています。Compute Engine 仮想マシンと比べると、データベースの再作成と復元は非常に困難な作業となります。
リージョン停止に対するアーキテクチャ上の重要な決定 - RTO 28 日と RPO 24 時間
- ロードバランサは、リージョンが停止した場合にのみ、リージョン 2 に構築されます。リージョン 2 のインフラストラクチャはリージョン停止時にのみ利用可能なため、Cloud DNS を使用して、オーケストレートされたリージョン フェイルオーバーを手動で行えるようにしています。
- 新しいマネージド インスタンス グループは、リージョンが停止した場合にのみ構築されます。これによりコストが最適化されます。ほとんどのリージョンの停止は短時間になり、呼び出される可能性はほとんどなくなります。わかりやすくするため、この図には再デプロイに必要な関連ツールや Compute Engine イメージのコピーは含まれていません。
- 新しい Cloud SQL インスタンスが再作成され、データがバックアップから復元されます。ここでも 1 つのリージョンが長期間停止するリスクは極めて低いため、コスト最適化のトレードオフになります。
- これらのバックアップを保存するために、マルチリージョンの Cloud Storage が使用されます。これにより、RTO と RPO 内でのゾーンとリージョンの自動復元が可能となります。
階層 2 アーキテクチャの例
| アプリケーションの重要性 | ゾーンの停止 | リージョンの停止 |
|---|---|---|
| 階層 2 | RTO 4 時間 RPO ゼロ |
RTO 24 時間 RPO 4 時間 |
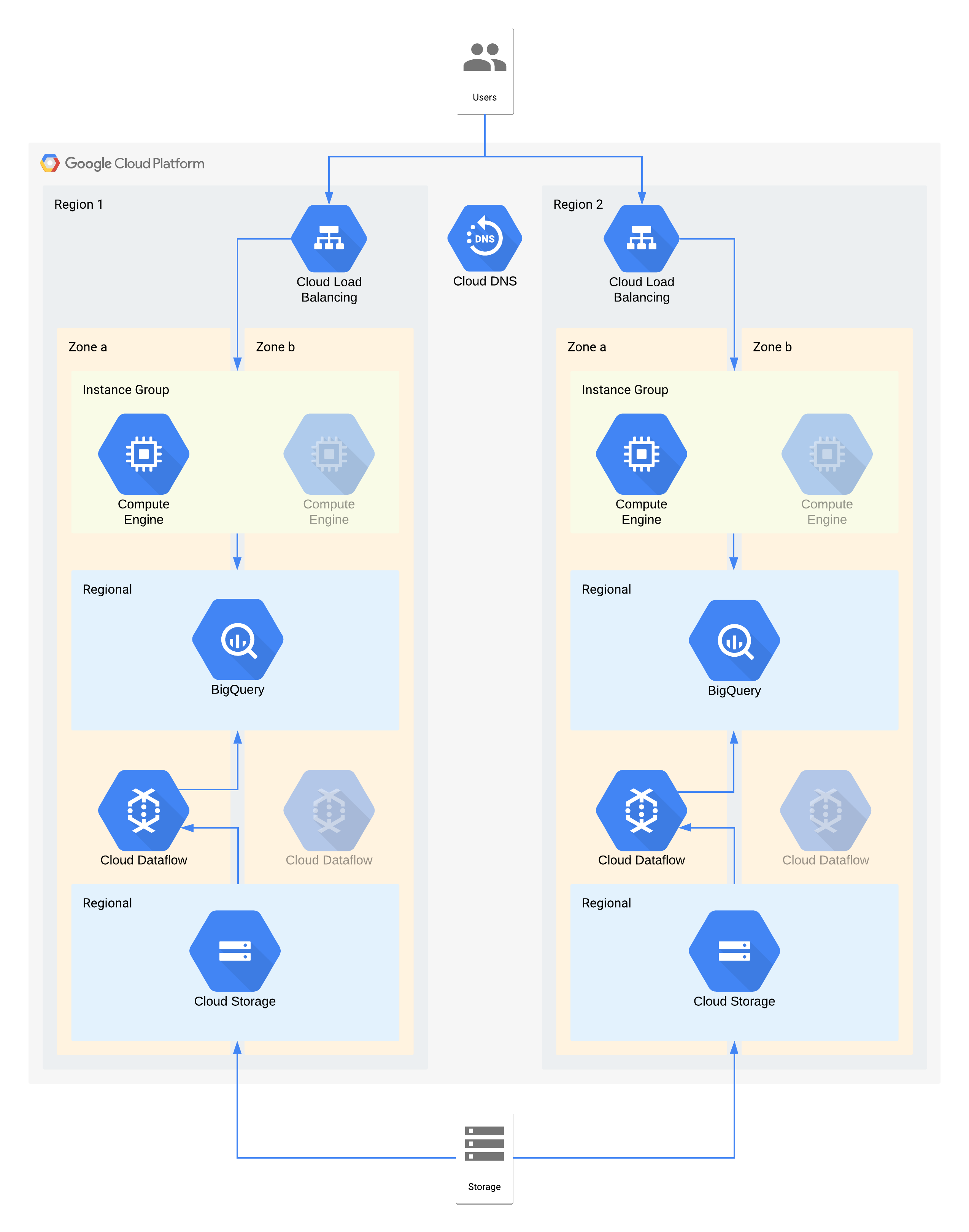
このアーキテクチャは、内部ユーザーがコンピューティング インスタンスの可視化レイヤに接続し、データの取り込み / 変換レイヤがバックエンド データ ウェアハウスにデータを送信するデータ ウェアハウスを表しています。
このアーキテクチャの個々のコンポーネントは、この階層に必要な RPO に直接対応していません。ただし、これらのコンポーネントを組み合わせて使用することで、全体的なサービスが RPO を満たすことになります。この場合、Dataflow はゾーン プロダクトであるため、高可用性設計の推奨事項に従ってサービス停止中のデータ損失を防いでください。ただし、Cloud Storage レイヤはこのデータの確実なソースであり、RPO はゼロです。その結果、ゾーン a が停止した場合、ゾーン b を使用して失われたデータを BigQuery に再度取り込むことが可能です。
ゾーン停止に対するアーキテクチャ上の重要な決定 - RTO 4 時間と RPO ゼロ
- ロードバランサは、ユーザーにスケーラブルなアクセス ポイントを提供するために使用され、別のゾーンへの自動フェイルオーバーを可能にします。RTO は 4 時間ですが、IP アドレスや DNS の更新を手動で行う場合は、想定以上に時間がかかる場合があります。
- データ可視化のコンピューティング レイヤのリージョン マネージド インスタンス グループは複数のゾーンから構成されていますが、リソースは最小限になっています。これにより、コストが最適化されます。また、仮想マシンを迅速にスケールアウトできます。
- リージョン Cloud Storage は、データの最初の取り込みのステージング レイヤとして使用され、ゾーンの自動復元を可能にします。
- Dataflow は、Cloud Storage からデータを抽出し、変換して、BigQuery にデータを読み込ませるために使用します。これはステートレス プロセスのため、ゾーンが停止しても別のゾーンで再開できます。
- BigQuery は、データ可視化のフロントエンド向けのデータ ウェアハウス バックエンドを実現します。ゾーンが停止した場合、失われたデータは Cloud Storage から取り込まれます。
リージョン停止に対するアーキテクチャ上の重要な決定 - RTO 24 時間と RPO 4 時間
- 各リージョンのロードバランサは、ユーザーにスケーラブルなアクセス ポイントを提供するために使用されます。リージョン 2 のインフラストラクチャはリージョン停止時にのみ利用可能なため、Cloud DNS を使用して、オーケストレートされたリージョン フェイルオーバーを手動で行えるようにしています。
- データ可視化のコンピューティング レイヤのリージョン マネージド インスタンス グループは複数のゾーンから構成されていますが、リソースは最小限になっています。ロードバランサが再構成されるまではアクセスできません。再構成後は手動による操作は不要です。
- リージョンの Cloud Storage は、データの最初の取り込みでステージング レイヤとして使用されます。RPO の要件を満たすため、両方のリージョンで同時に読み込まれます。
- Dataflow は、Cloud Storage からデータを抽出し、変換して、BigQuery にデータを読み込ませるために使用します。リージョンが停止した場合、BigQuery に Cloud Storage から最新データが提供されます。
- BigQuery は、データ ウェアハウスのバックエンドを実現します。通常のオペレーションでは、これは断続的に更新されます。リージョンが停止した場合、Dataflow 経由で Cloud Storage から最新のデータが取り込まれます。
階層 1 アーキテクチャの例
| アプリケーションの重要性 | ゾーンの停止 | リージョンの停止 |
|---|---|---|
| 階層 1 (最重要) |
RTO ゼロ RPO ゼロ |
RTO 4 時間 RPO 1 時間 |
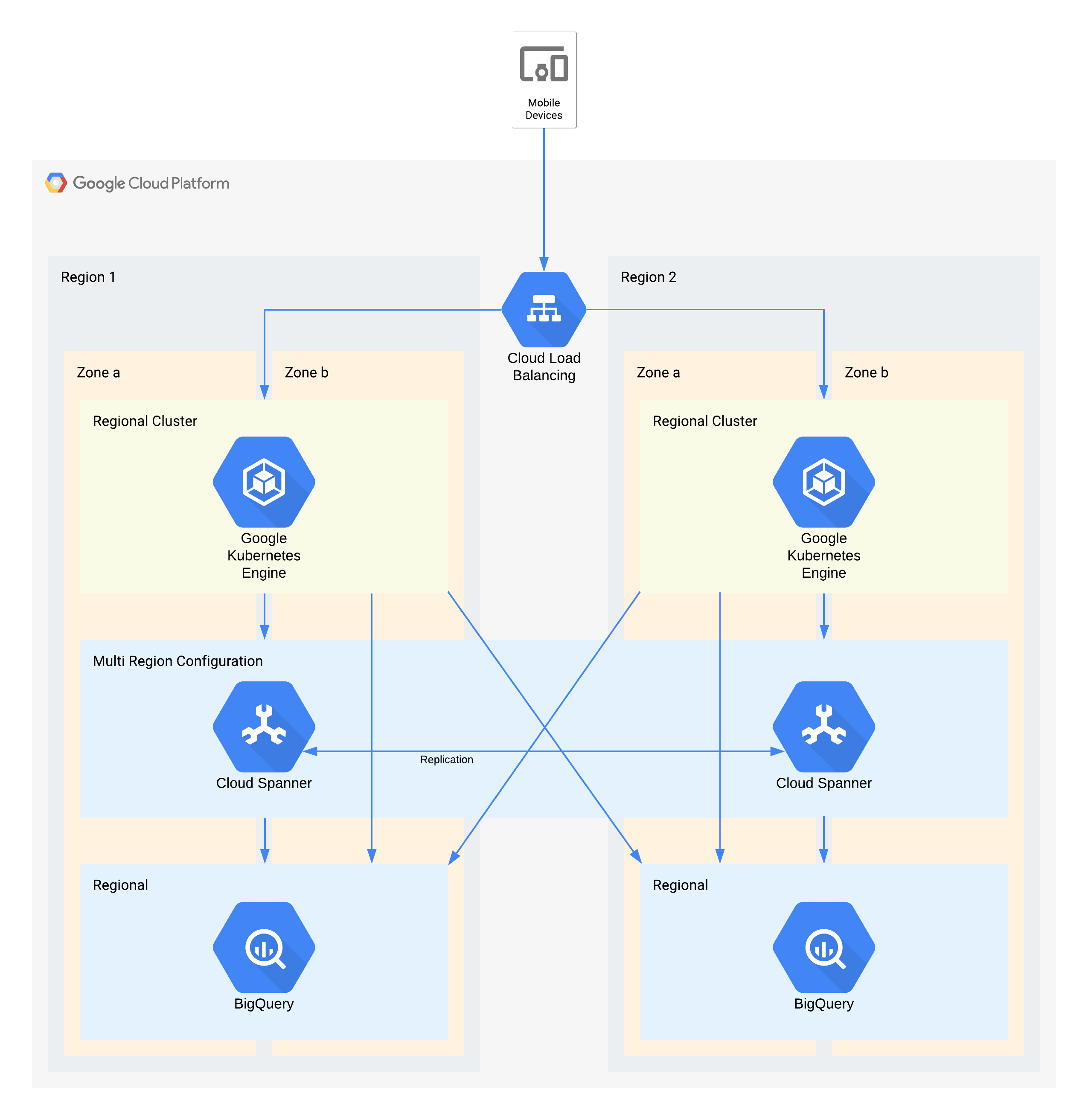
このアーキテクチャは、外部ユーザーが GKE 上の一連のマイクロサービスに接続するモバイルアプリのバックエンド インフラストラクチャを表します。Spanner はリアルタイム データ用のバックエンド データ ストレージ レイヤを提供します。履歴データが各リージョンの BigQuery データレイクにストリーミングされます。
このアーキテクチャの個々のコンポーネントは、この階層に必要な RPO に直接対応していませんが、これらのコンポーネントを併用することで、サービス全体で RPO を満たします。この場合、BigQuery が分析クエリに使用されています。各リージョンは Spanner から同時にフィードされます。
ゾーン停止に対するアーキテクチャ上の重要な決定 - RTO ゼロと RPO ゼロ
- ロードバランサは、ユーザーにスケーラブルなアクセス ポイントを提供するために使用され、別のゾーンへの自動フェイルオーバーを可能にします。
- リージョンの GKE クラスタは、複数のゾーンにまたがるアプリケーション レイヤで使用されます。これにより、各リージョン内で RTO がゼロになります。
- マルチリージョンの Spanner は、データ永続性レイヤとして使用され、ゾーンデータの自動復元とトランザクションの整合性を実現します。
- BigQuery は、アプリケーションの分析機能を提供します。各リージョンは Spanner から独立してデータをフィードし、アプリケーションから独立してアクセスされます。
リージョン停止に対するアーキテクチャ上の重要な決定 - RTO 4 時間と RPO 1 時間
- 内部ロードバランサは、ユーザーにスケーラブルなアクセス ポイントを提供するために使用され、別のリージョンへの自動フェイルオーバーを可能にします。
- リージョンの GKE クラスタは、複数のゾーンにまたがるアプリケーション レイヤで使用されます。リージョンが停止した場合、処理する負荷が増加するのに合わせて別のリージョンのクラスタが自動的にスケーリングされます。
- マルチリージョンの Spanner はデータ永続性レイヤとして使用され、リージョン データの自動復元とトランザクションの整合性を実現します。これは、クロスリージョンの RPO を 1 時間にするうえで重要なコンポーネントとなります。
- BigQuery は、アプリケーションの分析機能を提供します。各リージョンは Spanner から独立してデータをフィードし、アプリケーションから独立してアクセスされます。このアーキテクチャで BigQuery のコンポーネントを補完することで、アプリケーション全体の要件を達成できます。
付録: プロダクト リファレンス
このセクションでは、お客様のアプリケーションで最もよく利用され、DR 要件の実現に簡単に利用できる Google Cloud プロダクトのアーキテクチャと DR 機能について説明します。
共通のテーマ
多くの Google Cloud プロダクトは、リージョンまたはマルチリージョン構成を提供しています。リージョン プロダクトはゾーンの停止に対する耐障害性を備えています。また、マルチリージョン プロダクトとグローバル プロダクトはリージョンの停止に対して耐障害性を備えています。これは、停止中のアプリケーションの中断が最小限に抑えられることを意味します。Google では、上記のアーキテクチャの説明と同じく、一般的なアーキテクチャ アプローチによってこの結果を実現しています。
- 冗長デプロイ: アプリケーションのバックエンドとデータ ストレージは、リージョン内の複数のゾーンにデプロイされています。さらに、マルチリージョン ロケーションの場合は、複数のリージョンにデプロイされます。
データ レプリケーション: プロダクトは、冗長なロケーション間で同期レプリケーションまたは非同期レプリケーションのいずれかを使用します。
同期レプリケーションでは、アプリケーションが API 呼び出しを行い、プロダクトがデータの作成または変更を行ったときに、プロダクトが複数のロケーションでデータを完了した場合にのみ、成功のレスポンスが返されます。同期レプリケーションを使用している場合、Google Cloud インフラストラクチャが停止してもデータにアクセスできなくなることはありません。すべてのデータが使用可能なバックエンド ロケーションのいずれかに存在しているためです。
この方法では、データの保護は最大限になりますが、レイテンシとパフォーマンスの点でトレードオフがあります。同期レプリケーションを使用するマルチリージョン プロダクトでは、このトレードオフが最大になります。通常、レイテンシが追加し、10 ミリ秒または 100 ミリ秒単位で遅延が発生します。
非同期レプリケーションでは、アプリケーションが API 呼び出しを行い、プロダクトがデータを作成または変更したときに、プロダクトが 1 つのロケーションで書き込みを完了すると、成功のレスポンスが返されます。書き込みリクエストの後に、プロダクトは別のロケーションにデータを複製します。
この方法では、同期レプリケーションよりも API のレイテンシが短くなり、スループットが向上しますが、データの保護という点では弱くなります。レプリケーションが完了する前にデータの書き込み先のロケーションで障害が発生すると、そのロケーションが復旧するまで、データにはアクセスできなくなります。
負荷分散による停止の対応: Google Cloud では、ソフトウェア負荷分散を使用して、適切なアプリケーション バックエンドにリクエストをルーティングしています。DNS のロード バランシングなどの場合と異なり、この方法ではシステム停止に対応するまでの時間が短くなります。Google Cloud のロケーションが停止すると、ロードバランサは、そのロケーションにデプロイしたバックエンドが「異常な状態」になったことを瞬時に検出し、すべてのリクエストを別の場所にあるバックエンドに転送します。これにより、ロケーションが停止している間でも、プロダクトはアプリケーションのリクエスト処理を続行できます。ロケーションが復旧すると、ロードバランサはそのロケーションにあるプロダクト バックエンドの可用性を確認し、トラフィックの送信を再開します。
Access Context Manager
Access Context Manager によって、企業はリクエスト属性で定義されたポリシーに対応するアクセスレベルを構成できます。ポリシーはリージョン内でミラーリングされます。
ゾーンの停止の場合、使用できないゾーンへのリクエストは、リージョン内の他の利用可能なゾーンで自動的に透過的に処理されます。
リージョンの停止の場合、影響を受けるリージョンが再び使用できるようになるまで、そのリージョンのポリシー計算は使用できません。
アクセスの透明性
アクセスの透明性を使用すると、Google Cloud 組織管理者は Google Cloud のプロジェクトとリソースに対してきめ細かい属性ベースのアクセス制御を定義できます。管理上の目的で Google が顧客データにアクセスする必要がある場合があります。Google が顧客データにアクセスすると、アクセスの透明性により、影響を受ける Google Cloud のお客様にアクセスログが提供されます。これらのアクセスの透明性ログは、Google のデータ セキュリティへの取り組みと、データ処理の透明性を確保するためのものです。
アクセスの透明性には、ゾーンやリージョンの停止に対する耐障害性があります。ゾーンまたはリージョンの停止が発生しても、アクセスの透明性は別のゾーンまたはリージョンで管理者アクセスログの処理を続行します。
AlloyDB for PostgreSQL
AlloyDB for PostgreSQL は、PostgreSQL 互換のフルマネージド データベース サービスです。AlloyDB for PostgreSQL は、リージョンの 2 つの異なるゾーンに配置されている、プライマリ インスタンスの冗長ノードを介してリージョン内で高可用性を提供します。アクティブ ゾーンで問題が発生すると、プライマリ インスタンスはスタンバイ ゾーンへの自動フェイルオーバーをトリガーすることで、リージョンの可用性を維持します。Regional Storage は、単一のゾーンが失われた場合にデータの耐久性を保証します。
障害復旧のもう 1 つの方法として、AlloyDB for PostgreSQL はクロスリージョン レプリケーションを使用し、プライマリ クラスタのデータを別の Google Cloud リージョンにあるセカンダリ クラスタに非同期で複製します。
ゾーンの停止: 通常のオペレーションでは、高可用性プライマリ インスタンスの 2 つのノードのうちの 1 つのみがアクティブになり、すべてのデータ書き込みを処理します。このアクティブ ノードでは、クラスタの個別のリージョン ストレージ レイヤにデータが保存されます。
AlloyDB for PostgreSQL は、ゾーンレベルの障害を自動的に検出し、フェイルオーバーをトリガーしてデータベースの可用性を復元します。フェイルオーバー中、AlloyDB for PostgreSQL は、別のゾーンにすでにプロビジョニングされているスタンバイ ノードでデータベースを開始します。新しいデータベース接続は自動的にこのゾーンにルーティングされます。
クライアント アプリケーションの観点からは、ゾーンの停止はネットワーク接続の一時的な中断に似ています。フェイルオーバーが完了すると、クライアントは同じ認証情報を使用して、同じアドレでインスタンスに再接続でき、データを失うことはありません。
リージョンの停止: クロスリージョン レプリケーションでは、非同期レプリケーションを使用します。これにより、プライマリ インスタンスは、レプリカで commit される前にトランザクションを commit できます。トランザクションがプライマリ インスタンスで commit されてからレプリカで commit されるまでの時間差をレプリケーション ラグといいます。プライマリが write-ahead log(WAL)を生成してから WAL がレプリカに到達するまでの時間差をフラッシュ ラグといいます。レプリケーション ラグとフラッシュ ラグは、データベース インスタンスの構成とユーザー生成ワークロードによって異なります。
リージョンの停止の場合、別のリージョンのセカンダリ クラスタを、書き込み可能なスタンドアロンのプライマリ クラスタに昇格できます。この昇格したクラスタは、以前に関連付けられていた元のプライマリ クラスタのデータを複製しなくなります。フラッシュ ラグのために、セカンダリ クラスタに伝播されなかったトランザクションが元のプライマリに存在する可能性があるので、一部のデータが失われることがあります。
クロスリージョン レプリケーションの RPO は、プライマリ クラスタの CPU 使用率と、プライマリ クラスタのリージョンとセカンダリ クラスタのリージョンとの間の物理的な距離の両方の影響を受けます。RPO を最適化するには、レプリカを含む構成でワークロードのテストを行い、TPS(1 秒あたりのトランザクション)の安全な上限を設定することを推奨しています。この上限は、フラッシュラグが蓄積しない最長の TPS となります。ワークロードが TPS の安全な上限を超えると、フラッシュラグが蓄積し、RPO に影響する可能性があります。ネットワーク ラグを制限するには、同じ大陸内のリージョンペアを選択します。
ネットワーク ラグとその他の AlloyDB for PostgreSQL の指標のモニタリングの詳細については、インスタンスをモニタリングするをご覧ください。
Anti Money Laundering AI
Anti Money Laundering AI(AML AI)は、世界の金融機関がマネー ロンダリングを効果的かつ効率的に検出するための API を提供します。Anti Money Laundering AI はリージョン サービスです。つまり、お客様はリージョンを選択できますが、リージョンを構成するゾーンは選択できません。データとトラフィックは、リージョン内のゾーン間で自動的に負荷分散されます。オペレーション(パイプラインの作成や予測の実行など)は、バックグラウンドで自動的にスケーリングされ、必要に応じてゾーン間で負荷分散されます。
ゾーンの停止: AML AI は、リソースのデータをリージョン内に保存し、同期的に複製します。長時間実行オペレーションが正常に完了すると、ゾーン障害にかかわらず、そのリソースを信頼できます。処理はゾーン間でも複製されますが、このレプリケーションは高可用性ではなくロード バランシングを目的としているため、オペレーション中にゾーンに障害が発生すると、オペレーションが失敗する可能性があります。その場合は、オペレーションを再試行することで問題に対処できます。ゾーンが停止している間、処理時間が影響を受ける可能性があります。
リージョンの停止: お客様は、AML AI リソースを作成する Google Cloud リージョンを選択します。データがリージョン間で複製されることはありません。お客様のトラフィックが AML AI によって別のリージョンにルーティングされることはありません。リージョンに障害が発生した場合、停止から復旧するとすぐに AML AI は再度使用可能になります。
API キー
API キーを使用すると、スケーラブルな API キーのリソース管理をプロジェクトで行えます。API キーはグローバル サービスです。つまり、キーはどの Google Cloud のロケーションからでも表示でき、アクセスできます。そのデータとメタデータは、複数のゾーンとリージョンにわたって冗長的に保存されます。
API キーは、ゾーンとリージョンの両方の停止に対して耐障害性があります。ゾーンまたはリージョンが停止しても、API キーは同一または異なるリージョンの別のゾーンからのリクエストを引き続き処理します。
API キーの詳細については、API キー API の概要をご覧ください。
Apigee
Apigee は、API の開発と管理のための、安全性、スケーラビリティ、信頼性に優れたプラットフォームを提供します。Apigee では、シングル リージョンとマルチリージョンの両方のデプロイを提供します。
ゾーンの停止: お客様のランタイム データが複数のアベイラビリティ ゾーンに複製されます。したがって、シングルゾーンが停止しても Apigee には影響しません。
リージョンの停止: シングル リージョンの Apigee インスタンスでは、リージョンが停止した場合、そのリージョンで Apigee インスタンスが使用できなくなり、別のリージョンに復元できなくなります。マルチリージョン Apigee インスタンスでは、データはすべてのリージョン間で非同期で複製されます。したがって、1 つのリージョンで障害が発生してもトラフィックが完全に減少するわけではありません。ただし、障害が発生したリージョンの commit されていないデータにアクセスできない場合があります。異常なリージョンからトラフィックを迂回できます。トラフィックの自動フェイルオーバーを実現するために、マネージド インスタンス グループ(MIG)を使用してネットワーク ルーティングを構成できます。
AutoML Translation
AutoML Translation は、独自のデータ(文のペア)をインポートして、ドメイン固有のニーズに合わせてカスタムモデルをトレーニングできるようにする機械翻訳サービスです。
ゾーンの停止: AutoML Translation には、複数のゾーンとリージョンにアクティブなコンピューティング サーバーがあります。また、リージョン内のゾーン間におけるデータの同期レプリケーションもサポートしています。これらの機能によって、AutoML Translation はゾーン障害時のデータ損失なしに瞬時のフェイルオーバーを実現できます。また、お客様による入力や調整は必要ありません。
リージョンの停止: リージョン障害の場合、AutoML Translation は使用できません。
AutoML Vision
AutoML Vision は Vertex AI の一部です。データセットの作成、データのインポート、モデルのトレーニング、オンライン予測とバッチ予測のためのモデルのサービングを行う統合フレームワークを提供します。
AutoML Vision はリージョン サービスです。ジョブを起動するリージョンは選択できますが、そのリージョン内の特定のゾーンを選択することはできません。このサービスは、リージョン内のさまざまなゾーンでワークロードを自動的にロードバランスします。
ゾーンの停止: AutoML Vision は、ジョブのメタデータをリージョンに保存し、リージョン内のゾーンに同期的に書き込みます。ジョブは、Cloud Load Balancing によって選択された特定のゾーンで起動されます。
AutoML Vision トレーニング ジョブ: ゾーンが停止すると、実行中のジョブが失敗し、ジョブ ステータスが「失敗」に更新されます。ジョブが失敗した場合は、すぐに再試行します。新しいジョブは、使用可能なゾーンに転送されます。
AutoML Vision バッチ予測ジョブ: バッチ予測は Vertex AI バッチ予測に基づいて構築されています。ゾーンの停止が発生した場合、サービスはジョブを利用可能なゾーンに転送し、自動的に再試行します。再試行が複数回失敗すると、ジョブのステータスが「失敗」に更新されます。ジョブの実行を求める後続のユーザー リクエストは、使用可能なゾーンに転送されます。
リージョンの停止: ユーザーが、ジョブを実行する Google Cloud リージョンを選択します。データがリージョン間で複製されることはありません。リージョン障害が発生すると、そのリージョンで AutoML Vision サービスが使用できなくなります。停止が解消されると、再び使用できるようになります。ジョブを実行する場合は、複数のリージョンを使用することをおすすめします。リージョンの停止が発生した場合は、ジョブを利用可能な別のリージョンに転送します。
バッチ
Batch は、Google Cloud でバッチジョブをキューに入れ、スケジューリングし、実行するためのフルマネージド サービスです。Batch 設定はリージョン レベルで定義されます。お客様は、バッチジョブを送信するために、リージョン内のゾーンではなく、リージョンを選択する必要があります。ジョブが送信されると、Batch は顧客データを複数のゾーンに同期的に書き込みます。ただし、お客様は Batch VM がジョブを実行するゾーンを指定できます。
ゾーン障害: 1 つのゾーンで障害が発生すると、そのゾーンで実行されているタスクも失敗します。タスクに再試行が設定されている場合、Batch ではこれらのタスクが同じリージョン内の他のアクティブ ゾーンに自動的にフェイルオーバーされます。自動フェイルオーバーは、同じリージョン内のアクティブ ゾーン内のリソースの可用性の影響を受けます。障害が発生したゾーンでのみ利用可能なゾーンリソース(VM、GPU、ゾーン永続ディスクなど)を必要とするジョブは、障害が発生したゾーンが復旧するか、ジョブのキュー タイムアウトに達するまでキューに入れられます。可能であれば、ジョブを実行するゾーンリソースを Batch に選択させることをおすすめします。これにより、ジョブはゾーンの停止に対する耐障害性を確保できます。
リージョン障害: リージョン障害の場合、そのリージョンでサービス コントロール プレーンが使用できなくなります。このサービスでは、リージョン間でデータのレプリケーションやリクエストのリダイレクトは行われません。複数のリージョンを使用してジョブを実行し、リージョンに障害が発生した場合にジョブを別のリージョンにリダイレクトすることをおすすめします。
Chrome Enterprise Premium の脅威対策とデータ保護
Chrome Enterprise Premium の脅威対策とデータ保護は、Chrome Enterprise Premium ソリューションの一部です。マルウェアやフィッシングに対する保護、データ損失防止(DLP)、URL フィルタリング ルール、セキュリティ レポートなど、さまざまなセキュリティ機能で Chrome を拡張できます。
Chrome Enterprise Premium 管理者は、DLP ポリシーまたはマルウェア ポリシーに違反するお客様のコアコンテンツを今後の調査のために Google Workspace ルールのログイベントや Cloud Storage に保存することを選択できます。Google Workspace ルールのログイベントは、マルチリージョン Spanner データベースによって処理されます。Chrome Enterprise Premium がポリシー違反を検出するまでに数時間かかることがあります。この間、未処理のデータは、ゾーンまたはリージョンの停止によるデータ損失の影響を受けます。違反が検出されると、ポリシーに違反するコンテンツが Google Workspace ルールのログイベントや Cloud Storage に書き込まれます。
ゾーンとリージョンの停止: Chrome Enterprise Premium の脅威対策とデータ保護はマルチゾーンとマルチリージョンを対象としているため、1 つのゾーンやリージョンが予期せず完全に失われても、可用性を失うことなく処理を継続できます。他のアクティブなゾーンまたはリージョンのサービスにトラフィックをリダイレクトすることで、このレベルの信頼性を確保します。ただし、Chrome Enterprise Premium の脅威対策とデータ保護が DLP とマルウェアの違反を検出するまでに数時間かかる場合があるため、特定のゾーンまたはリージョン内の未処理のデータは、ゾーンまたはリージョンの停止によって失われる可能性があります。
BigQuery
BigQuery は、ビジネスのアジリティを高めるように設計されたサーバーレスでスケーラビリティと費用対効果の高いデータ ウェアハウスです。BigQuery は、ユーザー データセットに対して次のロケーション タイプをサポートします。
- リージョン: アイオワ州(
us-central1)やモントリオール(northamerica-northeast1)などの具体的な地理的場所。 - マルチリージョン: 米国(
US)やヨーロッパ(EU)など、2 つ以上の地理的な場所を含む広い地理的なエリア。
いずれの場合も、データは、選択したロケーション内の 1 つのリージョン内の 2 つのゾーンに冗長的に保存されます。BigQuery に書き込まれたデータは、プライマリ ゾーンとセカンダリ ゾーンの両方に同期的に書き込まれます。これにより、リージョン内の単一のゾーンが使用不能になっても保護されますが、リージョン外では保護されません。
Binary Authorization
Binary Authorization は、GKE と Cloud Run 用のソフトウェア サプライ チェーン セキュリティ プロダクトです。
すべての Binary Authorization ポリシーは、すべてのリージョン内で複数のゾーンにわたって複製されます。レプリケーションは、Binary Authorization ポリシーの読み取りオペレーションで、他のリージョンの障害から復旧する場合に役立ちます。また、レプリケーションにより、各リージョン内でのゾーン障害に対する読み取りオペレーションの耐性が確保されます。
Binary Authorization の適用オペレーションは、ゾーンの停止に対する耐障害性を備えていますが、リージョンの停止に対する耐障害性は備えていません。適用オペレーションは、リクエストを行っている GKE クラスタまたは Cloud Run ジョブと同じリージョンで実行されます。したがって、リージョンが停止した場合、何も Binary Authorization の適用リクエストを実行しません。
Certificate Manager
Certificate Manager を使用すると、さまざまな種類の Cloud Load Balancing で使用する Transport Layer Security(TLS)証明書を取得、管理できます。
ジョブとデータベースはリージョン内の複数のゾーンにわたって冗長化されるため、ゾーンが停止しても、リージョンおよびグローバルの Certificate Manager はゾーン障害に対する耐障害性があります。ジョブとデータベースは複数のリージョンにわたって冗長化されるため、リージョンが停止しても、グローバル Certificate Manager はリージョンの障害に対する耐障害性があります。リージョン Certificate Manager はリージョン プロダクトであるため、リージョンの障害には対応していません。
Cloud Intrusion Detection System
Cloud Intrusion Detection System(Cloud IDS)は、ゾーンをスコープとする IDS エンドポイントを提供するゾーンサービスです。このエンドポイントは 1 つの特定のゾーンで VM のトラフィックを処理するため、ゾーンまたはリージョンの停止には耐えられません。
ゾーンの停止: Cloud IDS は VM インスタンスに関連付けられています。お客様が(手動またはリージョン マネージド インスタンス グループを介して)複数のゾーンに VM をデプロイすることでゾーンの停止を回避することを計画している場合は、それらのゾーンにも Cloud IDS Endpoints をデプロイする必要があります。
リージョンの停止: Cloud IDS はリージョン プロダクトです。リージョン間の機能は提供されません。リージョン障害が発生すると、そのリージョン内のすべてのゾーンの Cloud IDS 機能が停止します。
Google Security Operations SIEM
Google Security Operations SIEM(Google Security Operations の一部)は、セキュリティ チームによる脅威の検出、調査、対応を支援するフルマネージド サービスです。
Google Security Operations SIEM には、リージョン サービスとマルチリージョン サービスがあります。
リージョン サービスでは、データとトラフィックは選択したリージョン内のゾーン間で自動的に負荷分散され、データはリージョン内のアベイラビリティ ゾーンにわたって冗長的に保存されます。
マルチリージョンは地理的に冗長です。この冗長性により、リージョン ストレージよりも幅広い保護が得られます。また、リージョン全体が失われた場合でも、サービスが継続して機能します。
ほとんどのデータの取り込みパスでは、複数のロケーションにわたって顧客データが同期的に複製されます。データが非同期で複製される場合、複数のロケーションにデータがまだ複製されていない時間枠(リカバリ ポイント目標(RPO))があります。これは、マルチリージョン デプロイでフィードを使用して取り込む場合です。RPO の後、データは複数のロケーションで利用できます。
ゾーンの停止:
リージョン デプロイ: リクエストは、リージョン内の任意のゾーンから処理されます。データは複数のゾーンに同期的に複製されます。ゾーン全体が停止しても、残りのゾーンが引き続きトラフィックに対応し、データを処理します。Google Security Operations SIEM の冗長プロビジョニングと自動スケーリングにより、これらの負荷の移動中も残存したゾーンでサービスの運用を継続できます。
マルチリージョン デプロイ: ゾーンの停止はリージョンの停止と同等です。
リージョンの停止:
リージョン デプロイ: Google Security Operations SIEM はすべての顧客データを 1 つのリージョンに保存し、トラフィックがリージョン間で転送されることはありません。リージョンで障害が発生した場合、障害から復旧するまで Google Security Operations SIEM は使用できません。
マルチリージョン デプロイ(フィードなし): リクエストは、マルチリージョン デプロイの任意のリージョンから処理されます。データは複数のリージョンに同期的に複製されます。リージョン全体が停止した場合、残りのリージョンが引き続きトラフィックに対応し、データを処理します。Google Security Operations SIEM の冗長プロビジョニングと自動スケーリングにより、これらの負荷の移動中も残存したリージョンでサービスの運用を継続できます。
マルチリージョン デプロイ(フィードあり): リクエストは、マルチリージョン デプロイの任意のリージョンから処理されます。データは、指定された RPO で複数のリージョンに非同期で複製されます。リージョン全体が停止した場合、残りのリージョンで使用できるのは RPO 後に保存されたデータのみです。RPO ウィンドウ内のデータは複製されない可能性があります。
Cloud Asset Inventory
Cloud Asset Inventory は、Google Cloud リソースとポリシー メタデータのリポジトリを保持する、高パフォーマンスで復元力のあるグローバル サービスです。Cloud Asset Inventory には、組織、フォルダ、プロジェクトにわたってデプロイされたアセットの追跡に役立つ検索ツールと分析ツールが用意されています。
ゾーンが停止しても、Cloud Asset Inventory は、同じリージョンまたは異なるリージョン内の別のゾーンからのリクエストを引き続き処理します。
リージョンが停止しても、Cloud Asset Inventory は他のリージョンからのリクエストを引き続き処理します。
Bigtable
Bigtable は、大規模な分析ワークロードや運用ワークロードに対応できる、フルマネージドで高性能な NoSQL データベース サービスです。
Bigtable レプリケーションの概要
Bigtable の柔軟で完全に構成可能なレプリケーション機能を使用すると、データを複数リージョンのクラスタや、同じリージョン内の複数のゾーンにコピーして、データの可用性と耐久性を高めることができます。Bigtable では、レプリケーションを使用する際のリクエストに対して、自動フェイルオーバーを提供することもできます。
マルチクラスタ ルーティングでマルチゾーンやマルチリージョン構成を使用している場合、ゾーンまたはリージョンが停止すると、Bigtable は自動的にトラフィックを再ルーティングして、最も近い使用可能なクラスタからのリクエストを処理します。Bigtable のレプリケーションは非同期で、結果整合性があるため、停止したロケーションのデータに対する最近行われた変更は、他のロケーションにまだレプリケートされていない場合、使用できません。
パフォーマンスに関する注意事項
CPU リソースの需要が使用可能なノード容量を超えると、Bigtable は常にレプリケーション トラフィックよりも受信リクエストの処理を優先します。
ワークロードで Bigtable レプリケーションを使用する方法については、Cloud Bigtable レプリケーションの概要とレプリケーション設定の例をご覧ください。
Bigtable ノードは、受信リクエストの処理と、他のクラスタからのデータのレプリケーションの実行の両方に使用されます。クラスタごとに十分なノード数を維持するだけでなく、アプリケーションで適切なスキーマ設計を使用して、ホットスポットを回避する必要があります。CPU 使用率が過剰または不均衡になったり、レプリケーション レイテンシが増加する可能性があります。
Bigtable のパフォーマンスと効率を最大化するようにアプリケーション スキーマを設計する方法については、スキーマ設計のベスト プラクティスをご覧ください。
モニタリング
Bigtable には、Google Cloud コンソールのレプリケーションのグラフを使用して、インスタンスとクラスタのレプリケーション レイテンシを視覚的にモニタリングする方法が複数用意されています。
Cloud Monitoring API を使用して、Bigtable レプリケーション指標をプログラムでモニタリングすることもできます。
Certificate Authority Service
Certificate Authority Service(CA Service)を使用すると、プライベート認証局(CA)のデプロイ、管理、セキュリティを簡素化、自動化、カスタマイズし、証明書の発行を高い復元力で大規模に実施できます。
ゾーンの停止: CA Service のコントロール プレーンはリージョン内の複数のゾーンにわたって冗長化されるため、ゾーン障害に対する耐障害性があります。ゾーンが停止しても、CA Service は中断することなく、同じリージョン内の別のゾーンからのリクエストを処理します。データは同期的に複製されるため、データの損失や破損はありません。
リージョンの停止: CA Service はリージョン プロダクトであるため、リージョンの障害には対応していません。リージョンの障害に対する復元力が必要な場合は、発行元 CA を 2 つの異なるリージョンに作成します。プライマリ発行元 CA は、証明書を必要とするリージョンに作成し、別のリージョンにフォールバック CA を作成します。プライマリの下位 CA のリージョンが停止した場合は、フォールバックを使用します。必要に応じて、両方の CA を同じルート CA に連結できます。
Cloud Billing
Cloud Billing API を使用すると、デベロッパーは Google Cloud プロジェクトに対する課金をプログラムで管理できます。Cloud Billing API は、更新情報が複数のゾーンやリージョンに同期的に書き込まれるグローバル システムとして設計されています。
ゾーン障害またはリージョン障害: Cloud Billing API は別のゾーンまたはリージョンに自動的にフェイルオーバーします。個別のリクエストは失敗する可能性がありますが、再試行ポリシーにより、成功するための後続の試行が許可されます。
Cloud Build
Cloud Build は、Google Cloud でビルドを実行するサービスです。
Cloud Build は、リージョンごとに分離されたインスタンスで構成され、リージョン内のゾーン間でデータを同期的に複製します。グローバル リージョンではなく特定の Google Cloud リージョンを使用し、ビルドで使用するリソース(ログバケット、Artifact Registry リポジトリなど)を、ビルドが実行されるリージョンに合わせることをおすすめします。
ゾーンが停止しても、コントロール プレーンのオペレーションは影響を受けません。ただし、障害が発生したゾーン内で現在実行中のビルドは遅延するか、完全に失われます。新たにトリガーされたビルドは、残りの機能しているゾーンに自動的に分散されます。
リージョン障害が発生した場合、コントロール プレーンはオフラインになり、現在実行中のビルドが遅延するか、完全に失われます。トリガー、ワーカープール、ビルドデータは、リージョン間で複製されません。停止をより簡単に軽減できるように、トリガーとワーカープールを複数のリージョンに準備することをおすすめします。
Cloud CDN
Cloud CDN は、Google ネットワーク上のさまざまなロケーションにコンテンツを配信し、キャッシュに保存して、クライアントのサービス レイテンシを短縮します。キャッシュに保存されたコンテンツはベスト エフォートで提供されます。Cloud CDN キャッシュでリクエストを処理できない場合、リクエストは送信元サーバー(バックエンド VM や Cloud Storage バケットなど)に転送されます。ここに、元のコンテンツが保存されます。
ゾーンまたはリージョンに障害が発生した場合、影響を受けるロケーションのキャッシュは使用できません。受信リクエストは、利用可能な Google エッジのロケーションとキャッシュに転送されます。これらの代替キャッシュがリクエストを処理できない場合、使用可能な送信元サーバーにリクエストを転送します。サーバーが最新のデータを含むリクエストを処理できれば、コンテンツが失われることはありません。キャッシュミスの割合が増えると、配信元サーバーで通常よりも多いトラフィック量が発生し、キャッシュがいっぱいになります。以降のリクエストは、ゾーンまたはリージョンの停止の影響を受けないキャッシュから処理されます。
Cloud CDN とキャッシュ動作については、Cloud CDN のドキュメントをご覧ください。
Cloud Composer
Cloud Composer は、クラウドとオンプレミス データセンターに及ぶワークフローの作成、スケジューリング、モニタリング、管理を可能にする、マネージド ワークフロー オーケストレーション サービスです。Cloud Composer 環境は、Apache Airflow オープンソース プロジェクト上に構築されています。
Cloud Composer API の可用性は、ゾーンが利用できなくても影響されません。ゾーンの停止中も、Cloud Composer API へのアクセスは維持され、新しい Cloud Composer 環境の作成も可能です。
Cloud Composer 環境には、アーキテクチャの一部として GKE クラスタがあります。 ゾーンの停止中は、クラスタでのワークフローが中断される場合があります。
- Cloud Composer 1 では、環境のクラスタはゾーンリソースであるため、ゾーンの停止によってクラスタが使用できなくなる場合があります。停止の時点で実行されていたワークフローは、完了前に停止する場合があります。
- Cloud Composer 2 では、環境のクラスタはリージョン リソースです。ただし、ゾーンの停止によって影響されるゾーン内のノードで実行されているワークフローは、完了前に停止する場合があります。
両方のバージョンの Cloud Composer で、ゾーンが停止すると、実行するようにワークフローが構成された外部アクションを含め、部分的に実行されたワークフローが実行を停止する原因になる可能性があります。ワークフローによっては、外部との不整合が生じる場合があります。たとえば、外部データストアを変更するマルチステップの実行中にワークフローが停止すると、このような状況が発生します。したがって、Airflow ワークフローを設計する場合は、部分的に実行されていないワークフローの状態を検出する方法や部分的なデータ変更を修復する方法など、復元プロセスを検討する必要があります。
Cloud Composer 1 では、ゾーンの停止中は、別のゾーンで新しい Cloud Composer 環境を開始することを選択できます。Airflow はワークフローの状態をメタデータ データベースに保持するため、この情報を新しい Cloud Composer 環境に転送すると、追加の手順と準備が必要になる可能性があります。
Cloud Composer 2 では、事前に環境のスナップショットを使用した障害復旧を設定することで、ゾーン停止に対処できます。ゾーンの停止中に、環境のスナップショットを使用してワークフローの状態を転送することで、別の環境に切り替えられます。Cloud Composer 2 のみが、環境のスナップショットを使用した障害復旧をサポートしています。
Cloud Data Fusion
Cloud Data Fusion は、データ パイプラインを素早く構築、管理できる、フルマネージド エンタープライズ データ統合サービスです。3 つのエディションが用意されています。
ゾーンの停止は Developer Edition のインスタンスに影響します。
リージョンの停止は、Basic および Enterprise Edition のインスタンスに影響します。
リソースへのアクセスを制御するには、別々の環境でパイプラインを設計して実行できます。この分離により、パイプラインを一度設計すれば、複数の環境で実行できます。両方の環境でパイプラインを復元できます。詳細については、インスタンス データのバックアップと復元をご覧ください。
次のアドバイスは、リージョンとゾーンの両方の停止に適用されます。
パイプライン設計環境の停止
設計環境で、停止の場合に備え、パイプラインのドラフトを保存します。RTO と RPO の特定の要件に応じて、保存したドラフトを使用して、停止中に別の Cloud Data Fusion インスタンスでパイプラインを復元できます。
パイプライン実行環境の停止
実行環境で、内部的に Cloud Data Fusion のトリガーまたはスケジュールを使用してパイプラインを開始するか、外部で Cloud Composer などのオーケストレーション ツールを使用してパイプラインを開始します。パイプラインのランタイム構成を復元できるようにするには、パイプラインと、プラグインやスケジュールなどの構成をバックアップします。サービスが停止した場合は、バックアップを使用して、影響を受けないリージョンまたはゾーンにインスタンスを複製できます。
サービスの停止に備えるために、複数のリージョンにわたって、同じ構成とパイプラインが設定された複数のインスタンスを作成することもできます。外部オーケストレーションを使用する場合、実行中のパイプラインをインスタンス間で自動的に負荷分散できます。1 つのリージョンに関連付けられ、すべてのインスタンスで使用されるリソース(データソースやオーケストレーション ツールなど)が存在しないように特別な注意を払ってください。これが停止の中心障害点になる可能性があるからです。たとえば、異なるリージョンに複数のインスタンスを配置し、Cloud Load Balancing と Cloud DNS を使用して、停止の影響を受けないインスタンスにパイプライン実行リクエストを転送できます(この例では、階層 1 と階層 3 のアーキテクチャ)。
パイプライン内の他の Google Cloud データサービスの停止
インスタンスでは、Dataproc、Cloud Storage、BigQuery などの他の Google Cloud サービスを、データソースまたはパイプライン実行環境として使用する場合があります。これらのサービスは異なるリージョンに配置できます。リージョン間の実行が必要な場合、いずれかのリージョンで障害が発生するとサービスが停止します。このシナリオでは、標準の障害復旧手順に従いますが、重要なサービスを別のリージョンに配置してリージョン間でセットアップすると、復元力が低下することに注意してください。
Cloud Deploy
Cloud Deploy は、GKE や Cloud Run などのランタイム サービスへのワークロードの継続的デリバリーを提供します。このサービスは、リージョン内のゾーン間でデータを同期的に複製するリージョン インスタンスで構成されています。
ゾーンの停止: コントロール プレーンのオペレーションは影響を受けません。ただし、ゾーン障害の発生時に実行されている Cloud Build ビルド(レンダリングやデプロイのオペレーションなど)は、遅延したり、完全に失われたりする場合があります。停止中、ビルド(リリースまたはロールアウト)をトリガーした Cloud Deploy リソースは、基盤となるオペレーションが失敗したことを示す失敗ステータスを表示します。リソースを再作成して、残りの機能ゾーンで新しいビルドを開始できます。たとえば、リリースをターゲットに再デプロイして、新しいロールアウトを作成します。
リージョンの停止: リージョンが復元されるまで、コントロール プレーンのオペレーションと Cloud Deploy からのデータは使用できません。リージョンが停止した場合にサービスを簡単に復元できるように、デリバリー パイプラインとターゲット定義をソース管理に保存することをおすすめします。これらの構成ファイルを使用すると、機能しているリージョンに Cloud Deploy パイプラインを再作成できます。停止中、既存のリリースに関するデータが失われます。ターゲットへのソフトウェアのデプロイを続行するには、新しいリリースを作成してください。
Cloud DNS
Cloud DNS は、高パフォーマンスで復元力を備えたグローバル ドメイン ネーム システム(DNS)サービスで、費用対効果の高い方法でグローバル DNS にドメイン名を公開します。
ゾーンが停止しても、Cloud DNS は、同じまたは異なるリージョンの別のゾーンからのリクエストを中断なく処理します。Cloud DNS レコードの更新は、受信先のリージョン内のゾーン間で同期的に複製されます。そのため、データが失われることはありません。
リージョンが停止しても、Cloud DNS は引き続き他のリージョンからのリクエストを処理します。Cloud DNS レコードの直近の更新は、他のリージョンと非同期にレプリケートされる前に、単一リージョンで処理されるため、利用できないことがあります。
Cloud Run 関数
Cloud Run 関数は、お客様が Google のインフラストラクチャで関数コードを実行することができるステートレス コンピューティング環境です。Cloud Run 関数はリージョナル サービスです。つまり、お客様はリージョンを選択できますが、リージョンを構成するゾーンは選択できません。データとトラフィックは、リージョン内のゾーン間で自動的にロードバランスされます。関数は受信トラフィックに合わせて自動的にスケーリングされ、必要に応じてゾーン間で負荷分散されます。このようにゾーンごとに自動スケーリングを行うスケジューラが各ゾーンで維持されています。また、他のゾーンが受けている負荷を認識し、ゾーン障害に対応するためにゾーン内の追加容量をプロビジョニングします。
ゾーンの停止: Cloud Run 関数では、メタデータとデプロイされた関数が保存されます。このデータはリージョン別に保存され、同期的な方法で書き込まれます。Cloud Run 関数の Admin API は、データがリージョン内のクォーラムに commit されると API 呼び出しを返します。データはリージョンに保存されるため、データプレーン オペレーションはゾーン障害の影響も受けません。ゾーンに障害が発生した場合、トラフィックは他のゾーンに自動的にルーティングされます。
リージョンの停止: お客様は、関数を作成する Google Cloud リージョンを選択します。データがリージョン間で複製されることはありません。お客様のトラフィックは、Cloud Run 関数によって別のリージョンにルーティングされることはありません。リージョンに障害が発生した場合、停止から復旧するとすぐに Cloud Run 関数は再度使用可能になります。複数のリージョンにデプロイし、必要に応じて Cloud Load Balancing を使用して高可用性を実現することをおすすめします。
Cloud Healthcare API
Cloud Healthcare API は医療データを保存および管理するためのサービスであり、選択した構成に応じて、高可用性と、ゾーンおよびリージョン障害に対する保護を提供するように構築されています。
リージョン構成: デフォルトの構成では、Cloud Healthcare API によりゾーン障害に対する保護が提供されます。サービスは 1 つのリージョン内で 3 つのゾーンにデプロイされ、データもリージョン内の異なるゾーンに三重化されます。1 つのゾーンに障害が発生し、サービスレイヤまたはデータレイヤのいずれかが影響を受けた場合は、残りのゾーンが中断なく取って代わります。リージョン構成では、サービスが存在するリージョン全体が停止すると、そのリージョンがオンラインに復帰するまでサービスを使用できません。リージョン全体が物理的に破壊される不測の事態の場合、そのリージョンに保存されたデータは失われます。
マルチリージョン構成: マルチリージョン構成では、Cloud Healthcare API は 3 つの異なるリージョンに属する 3 つのゾーンにデプロイされます。また、データは 3 つのリージョン間で複製されます。これにより、リージョン全体が停止してもサービスが失われることはありません。残りのリージョンは自動的に引き継がれるためです。FHIR などの構造化データは、複数のリージョン間で同期して複製されるため、リージョン全体の停止時にデータが失われることはありません。Cloud Storage バケットに保存されているデータ(DICOM や Dictation、大規模な HL7v2/FHIR オブジェクトなど)は、複数のリージョンに非同期で複製されます。
Cloud Identity
Cloud Identity サービスは複数のリージョンに分散し、動的なロード バランシングを使用します。Cloud Identity では、ユーザーがリソース スコープを選択することはできません。特定のゾーンまたはリージョンでサービスが停止した場合、トラフィックは他のゾーンまたはリージョンに自動的に分散されます。
ほとんどの場合、永続データは同期レプリケーションで複数のリージョンにミラーリングされます。一部のシステムは、キャッシュや多くのエンティティに影響を及ぼす変更などのパフォーマンス上の理由により、リージョン間で非同期に複製されます。最新のデータが保存されているプライマリ リージョンが停止すると、Cloud Identity は、プライマリ リージョンが使用可能になるまで別の場所からデータを提供しますが、これは最新のデータではありません。
Cloud Interconnect
Cloud Interconnect は、Google のピアリング エッジに接続された物理ケーブルを介して、オンプレミスのデータセンターから Google Cloud ネットワークへの RFC 1918 アクセスをお客様に提供します。
Cloud Interconnect は、大都市圏で 2 つの EAD(エッジ アベイラビリティ ドメイン)への接続をプロビジョニングする場合、99.9% の SLA をお客様に提供します。お客様が 2 つの大都市圏の 2 つの EAD で、グローバル ルーティングを使用して 2 つのリージョンへの接続をプロビジョニングする場合、99.99% の SLA を得ることができます。詳細については、クリティカルでないアプリケーション用のトポロジの概要と本番環境レベル アプリケーションのトポロジの概要をご覧ください。
Cloud Interconnect はコンピューティング ゾーンに依存しないため、EAD の形式で高可用性を提供します。EAD に障害が発生した場合、その EAD への BGP セッションは中断し、トラフィックは他の EAD にフェイルオーバーします。
リージョンに障害が発生した場合、そのリージョンへの BGP セッションは中断し、トラフィックは稼働しているリージョン内のリソースにフェイルオーバーします。これは、グローバル ルーティングが有効な場合に適用されます。
Cloud Key Management Service
Cloud Key Management Service(Cloud KMS)は、スケーラブルで耐久性に優れた暗号鍵リソースの管理機能を提供します。Cloud KMS では、すべてのデータとメタデータが Spanner データベースに保存され、同期レプリケーションによってデータの耐久性と可用性が高めることができます。
Cloud KMS リソースは、単一のリージョン、マルチリージョン、またはグローバルに作成できます。
ゾーンが停止しても、Cloud KMS は、同じまたは異なるリージョンの別のゾーンからのリクエストを中断なく処理します。データは同期的に複製されるため、データの損失や破損はありません。ゾーンが停止から復旧すると、完全な冗長性が復元されます。
リージョンが停止した場合、そのリージョンが再び使用可能になるまで、そのリージョン内のリソースはオフラインになります。1 つのリージョン内で、少なくとも 3 つのレプリカが別々のゾーンで管理されます。高可用性が必要な場合は、リソースをマルチリージョンまたはグローバル構成に保存する必要があります。マルチリージョン構成とグローバル構成は、複数のリージョンでデータを地理的に冗長化して提供することで、1 つのリージョンが停止しても、可能性を維持できるように設計されています。
Cloud External Key Manager(Cloud EKM)
Cloud External Key Manager は Cloud Key Management Service と統合されており、サポートされているサードパーティ パートナーを通じて外部鍵の制御とアクセスを行えます。これらの外部鍵を使用して、顧客管理の暗号鍵(CMEK)の統合をサポートするその他の Google Cloud サービスで使用するために保存データを暗号化できます。
ゾーンの停止: Cloud External Key Manager は、リージョン内の複数のゾーンにより冗長性がもたらされるため、ゾーンの停止に対する耐障害性を備えています。ゾーンの停止が発生すると、トラフィックはリージョン内の他のゾーンに再ルーティングされます。トラフィックの再ルーティング中、エラーが増加する可能性がありますが、サービスは引き続き利用できます。
リージョンの停止: Cloud External Key Manager は、影響を受けるリージョンのリージョン停止中は使用できません。リージョン間でリクエストをリダイレクトするフェイルオーバー メカニズムはありません。お客様には、複数のリージョンを使用してジョブを実行することをおすすめします。
Cloud External Key Manager は、顧客データを永続的に保存しません。そのため、Cloud External Key Manager システム内でリージョン停止中にデータが失われることはありません。ただし、Cloud External Key Manager は、Cloud Key Management Service や外部のサードパーティ ベンダーなどの他のサービスの可用性に依存します。リージョンの停止中にこれらのシステムに障害が発生した場合、データが失われる可能性があります。これらのシステムの RPO / RTO は、Cloud External Key Manager のコミットメントの対象範囲外です。
Cloud Load Balancing
Cloud Load Balancing は、完全に分散された、ソフトウェア定義型のマネージド サービスです。Cloud Load Balancing では、単一のエニーキャスト IP アドレスが世界中のリージョンのバックエンドに対するフロントエンドとして機能します。ハードウェアベースではないため、物理的なロード バランシング インフラストラクチャを管理する必要はありません。ロードバランサは、高可用性を備えたアプリケーションを構築する際に重要な要素となります。
Cloud Load Balancing では、リージョン ロードバランサとグローバル ロードバランサの両方を提供します。Cloud Load Balancing はまた、リージョンにまたがって負荷を分散します(自動マルチリージョン フェイルオーバーなど)。これにより、プライマリ バックエンドが異常な状態になった場合にトラフィックがフェイルオーバー バックエンドに移動します。
グローバル ロードバランサは、ゾーンとリージョンの両方の停止に対して耐障害性があります。リージョン ロードバランサは、ゾーンの停止に対して耐障害性がありますが、リージョン内で停止が発生した場合は影響を受けます。ただし、いずれの場合も、アプリケーション全体の復元力は、デプロイしたロードバランサのタイプだけでなく、バックエンドの冗長性によっても左右される点に注意する必要があります。
Cloud Load Balancing とその機能の詳細については、Cloud Load Balancing の概要をご覧ください。
Cloud Logging
Cloud Logging は、ログルーターと Cloud Logging ストレージの 2 つの部分から構成されています。
ログルーターはストリーミング ログイベントを処理し、ログを Cloud Storage、Pub/Sub、BigQuery、Cloud Logging ストレージに転送します。
Cloud Logging ストレージは、ログの保存、クエリ、コンプライアンスの管理を行うサービスです。開発、コンプライアンス対応、トラブルシューティング、プロアクティブなアラートなど、多くのユーザーやワークフローに対応しています。
ログルーターと受信ログ: ゾーンの停止中、Cloud Logging API がリージョン内の他のゾーンにログをルーティングします。通常、ログルーターから Cloud Logging、BigQuery、または Pub/Sub にルーティングされるログは、できるだけ早く最終的な宛先に書き込まれますが、Cloud Storage に送信されるログはバッファに格納され、1 時間ごとにまとめて書き込まれます。
ログエントリ: ゾーンまたはリージョンが停止すると、影響を受けるゾーンまたはリージョンのバッファに格納され、エクスポート先に書き込まれていないログエントリにはアクセスできなくなります。また、ログベースの指標はログルーターで計算され、同じ制約の対象になります。選択したエクスポート先に配信されると、宛先のサービスによってログが複製されます。Cloud Logging ストレージにエクスポートされたログは、リージョン内の 2 つのゾーンに同期的に複製されます。他の宛先タイプの複製動作については、この記事の関連セクションをご覧ください。Cloud Storage にエクスポートされるログは 1 時間ごとにバッチ処理され、書き込まれることに注意してください。そのため、Cloud Logging ストレージ、BigQuery、または Pub/Sub を使用して停止の影響を受けるデータ量を最小限に抑えることをおすすめします。
ログのメタデータ: シンクや除外構成などのメタデータはグローバルに保存されますが、リージョンのキャッシュに保存されます。停止した場合は、リージョンのログルーター インスタンスが動作します。1 つのリージョンが停止しても、それ以外のリージョンに影響はありません。
Cloud Monitoring
Cloud Monitoring は、ダッシュボード(組み込みとユーザー定義の両方)、アラート、稼働時間モニタリングなど、相互接続されたさまざまな機能で構成されています。
ダッシュボード、稼働時間チェック、アラート ポリシーなど、Cloud Monitoring のすべての構成はグローバルに定義されます。それらへのすべての変更は、複数のリージョンに同期的に複製されます。したがって、ゾーンとリージョンの両方でサービスが停止しても、構成の変更は成功します。また、ゾーンまたはリージョンで最初に障害が発生した場合に、一時的な読み取りおよび書き込みエラーが発生する可能性がありますが、Cloud Monitoring は使用可能なゾーンとリージョンにリクエストを再転送します。このような場合は、指数バックオフを使用して構成変更を再試行できます。
特定のリソースの指標を書き込む際、Cloud Monitoring はまず、リソースが存在するリージョンを特定します。次に、リージョン内に指標データの 3 つの独立したレプリカを書き込みます。3 つの書き込みのいずれかが成功するとすぐに、全体的なリージョン指標の書き込みは成功として返されます。3 つのレプリカは、リージョン内の異なるゾーンに存在するとは限りません。
ゾーン: ゾーンでサービスが停止している間、その影響を受けているゾーンのリソースでは指標の書き込みと読み取りがまったく利用できません。事実上、Cloud Monitoring は、影響を受けているゾーンが存在しないかのように動作します。
リージョン: リージョンが停止している間、その影響を受けているリージョン内のリソースでは指標の書き込みと読み取りがまったく利用できません。事実上、Cloud Monitoring は、影響を受けているゾーンが存在しないかのように動作します。
Cloud NAT
Cloud NAT(ネットワーク アドレス変換)は、ソフトウェア定義の分散マネージド サービスで、外部 IP アドレスを持たない特定のリソースからインターネットへのアウトバウンド接続を作成できます。プロキシ VM やアプライアンスをベースにしていません。代わりに、Cloud NAT は、Virtual Private Cloud ネットワークを強化する Andromeda ソフトウェアを構成します。これにより、外部 IP アドレスを持たない VM に送信元ネットワーク アドレス変換(送信元 NAT または SNAT)を提供します。また、Cloud NAT は、確立された受信レスポンス パケットに対してのみ宛先ネットワーク アドレス変換(宛先 NAT または DNAT)を提供します。
Cloud NAT の機能の詳細については、ドキュメントをご覧ください。
ゾーンの停止: コントロール プレーンとネットワーク データ プレーンはリージョン内の複数のゾーン間で冗長化されるため、Cloud NAT はゾーン障害に対する耐障害性を備えています。
リージョンの停止: Cloud NAT はリージョン プロダクトであるため、リージョンの障害には対応していません。
Cloud Router
Cloud Router は、Border Gateway Protocol(BGP)を使用して IP アドレス範囲をアドバタイズする、完全分散型のマネージド Google Cloud サービスです。ピアから受信する BGP アドバタイズに基づいて動的ルートをプログラムします。物理デバイスまたはアプライアンスの代わりに、各 Cloud Router が BGP スピーカーおよびレスポンダーとして機能するソフトウェア タスクで構成されます。
ゾーンの停止の場合、高可用性(HA)構成の Cloud Router はゾーンの障害に対する耐障害性があります。その場合、一方のインターフェースが接続を失う場合がありますが、トラフィックは BGP を使用した動的ルーティングを通じてもう一方のインターフェースにリダイレクトされます。
リージョンの停止の場合、Cloud Router はリージョン プロダクトであるため、リージョンの障害には対応していません。お客様がグローバル ルーティング モードを有効にしている場合、障害が発生したリージョンと他のリージョン間のルーティングに影響する可能性があります。
Cloud Run
Cloud Run はステートレスなコンピューティング環境であり、そこでは、お客様はコンテナ化されたコードを Google のインフラストラクチャで実行できます。Cloud Run はリージョナル サービスです。つまり、お客様はリージョンを選択できますが、リージョンを構成するゾーンは選択できません。データとトラフィックは、リージョン内のゾーン間で自動的にロードバランスされます。コンテナ インスタンスは、受信トラフィックに合わせて自動的にスケーリングされ、必要に応じてゾーン間で負荷分散されます。このようにゾーンごとに自動スケーリングを行うスケジューラが各ゾーンで維持されています。また、他のゾーンが受けている負荷を認識し、ゾーン障害に対応するためにゾーン内の追加容量をプロビジョニングします。
ゾーンの停止: Cloud Run により、メタデータとデプロイされたコンテナが保存されます。このデータはリージョン別に保存され、同期的な方法で書き込まれます。Cloud Run Admin API は、データがリージョン内のクォーラムに commit されると API 呼び出しを返します。データはリージョンに保存されるため、データプレーン オペレーションはゾーン障害の影響も受けません。ゾーンに障害が発生した場合、トラフィックは他のゾーンに自動的に転送されます。
リージョンの停止: お客様は、Cloud Run サービスを作成する Google Cloud リージョンを選択します。データがリージョン間で複製されることはありません。お客様のトラフィックは、Cloud Run によって別のリージョンにルーティングされることはありません。リージョンに障害が発生した場合、停止から復旧するとすぐに Cloud Run は再度使用可能になります。複数のリージョンにデプロイし、必要に応じて Cloud Load Balancing を使用して高可用性を実現することをおすすめします。
Cloud Shell
Cloud Shell によって、Google Cloud ユーザーは、オンボーディング、教育、開発、運用タスクのために事前に構成された単一ユーザーの Compute Engine インスタンスにアクセスできます。
Cloud Shell は、アプリケーション ワークロードの実行には適しておらず、代わりにインタラクティブな開発と教育のユースケースを対象としています。それにはユーザーごとのランタイム割り当ての上限があり、非アクティブな状態が少し続くと自動的にシャットダウンされ、インスタンスには割り当てられたユーザーのみがアクセスできます。
サービスの基盤となる Compute Engine インスタンスはゾーンリソースであるため、ゾーンが停止した場合、ユーザーの Cloud Shell は使用できなくなります。
Cloud Source Repositories
Cloud Source Repositories を使用すると、ユーザーはプライベート ソース コード リポジトリを作成して管理できます。このプロダクトはグローバル モデルを使用して設計されているため、リージョンやゾーンの復元性のために構成する必要はありません。
代わりに、Cloud Source Repositories に対する git push オペレーションは、ソース リポジトリの更新を複数のリージョンにわたる複数のゾーンに同期的に複製します。つまり、サービスは、1 つのリージョンでの停止に対して耐障害性があります。
特定のゾーンまたはリージョンでサービスが停止した場合、トラフィックは他のゾーンまたはリージョンに自動的に分散されます。
GitHub または Bitbucket からのリポジトリを自動的にミラーリングする機能は、これらのプロダクトの問題の影響を受ける可能性があります。たとえば、GitHub または Bitbucket が Cloud Source Repositories に新しい commit のアラートを送信できない場合、または Cloud Source Repositories が更新されたリポジトリからコンテンツを取得できない場合、ミラーリングに影響が生じます。
Spanner
Spanner は、リレーショナル セマンティクスを備えた、スケーラブルで可用性が高く、マルチバージョンな、同期的に複製される強整合性のあるデータベースです。
リージョンの Spanner インスタンスは、1 つのリージョン内の 3 つのゾーン間でデータを同期的に複製します。リージョンの Spanner インスタンスへの書き込みは、少なくとも 2 つのレプリカ(3 つのうち 2 つの過半数のクォーラム)が書き込みを commit した後に、3 つのレプリカすべてに同期的に送信され、クライアントに承認されます。これにより、最新の書き込みが永続化され、書き込みの過半数のクォーラムを 2 つのレプリカで実現できるため、すべてのデータへのアクセスを許可することによって Spanner でのゾーン障害に対する復元性を実現します。
Spanner のマルチリージョン インスタンスには、3 つのリージョンにある 5 つのゾーンでデータが同期的に複製される書き込みクォーラムが含まれます(デフォルトのリーダー リージョンと別のリージョンにそれぞれ 2 つの読み取り / 書き込みレプリカ、ウィットネス リージョンに 1 つのレプリカ)。マルチリージョンの Spanner インスタンスへの書き込みは、少なくとも 3 つのレプリカ(5 つのうち 3 つの過半数のクォーラム)が書き込みを commit した後に承認されます。ゾーンまたはリージョンの障害が発生した場合、Spanner は最新の書き込みを含むすべてのデータにアクセスし、読み取り / 書き込みリクエストを処理します。データは、クライアントへの書き込みが承認されたときに 2 つのリージョン間の 3 つ以上のゾーンで保持されます。
これらの構成の詳細については、Spanner のインスタンスのドキュメントをご覧ください。また、Spanner レプリケーションの仕組みの詳細については、レプリケーションのドキュメントをご覧ください。
Cloud SQL
Cloud SQL は、MySQL、PostgreSQL、SQL Server 用のフルマネージド リレーショナル データベース サービスです。Cloud SQL は、Compute Engine で管理された仮想マシンを使用してデータベース ソフトウェアを実行します。リージョン冗長性を実現する高可用性構成を提供し、ゾーンの停止からデータベースを保護します。クロスリージョン レプリカをプロビジョニングして、リージョンの停止からデータベースを保護できます。このプロダクトには、リージョンやゾーンの停止の影響を受けないゾーン オプションもあります。高可用性構成、クロスリージョン レプリカ、またはその両方を慎重に選択する必要があります。
ゾーンの停止: 高可用性オプションにより、1 つのリージョン内の 2 つのゾーンにプライマリ VM とスタンバイ VM インスタンスが作成されます。通常のオペレーションでは、プライマリ VM インスタンスがすべてのリクエストを処理し、データベース ファイルをリージョン Persistent Disk に書き込みます。このファイルをプライマリ ゾーンとスタンバイ ゾーンに同期的に複製します。ゾーンの停止でプライマリ インスタンスに影響が生じた場合、Cloud SQL はフェイルオーバーを開始し、その間は Persistent Disk がスタンバイ VM にアタッチされ、トラフィックのルートが変更されます。
このプロセスでデータベースの初期化が必要になります。これには、トランザクション ログに書き込まれ、データベースに適用されていないトランザクションの処理も含まれます。未処理のトランザクションの数と種類によっては RTO 時間が増加する可能性があります。最近の書き込みが多いと、未処理のトランザクションのバックログにつながる可能性があります。RTO 時間は、(a)最近の書き込みアクティビティと(b)データベース スキーマに対する最近の変更によって大きく変わります。
最後に、ゾーンが復旧したら、プライマリ ゾーンでのサービスを再開するため、フェイルバック オペレーションを手動でトリガーします。
高可用性オプションの詳細については、Cloud SQL 高可用性のドキュメントをご覧ください。
リージョンの停止: クロスリージョン レプリカ オプションにより、他のリージョンでプライマリ インスタンスのリードレプリカを作成し、リージョンの停止からデータベースを保護します。クロスリージョン レプリケーションでは、非同期レプリケーションを使用します。これにより、プライマリ インスタンスは、レプリカで commit される前にトランザクションを commit できます。トランザクションがプライマリ インスタンスで commit されてからレプリカで commit されるタイミングの差をレプリケーション ラグといいます(これはモニタリング可能です)。この指標には、プライマリからレプリカに送信されていないトランザクションだけでなく、レプリカで処理されていない受信済みのトランザクションも反映されます。レプリカに送信されなかったトランザクションは、リージョンの停止時に使用できなくなります。レプリカで処理されていない受信済みのトランザクションは、次のようにリカバリ時間に影響します。
Cloud SQL では、レプリカを含む構成でワークロードのテストを行い、TPS(1 秒あたりのトランザクション)の安全な上限を設定することを推奨しています。この上限は、レプリケーション ラグが蓄積しない最長の TPS となります。ワークロードが TPS の安全な上限を超えると、レプリケーション ラグが蓄積され、RPO 値と RTO 値に悪影響を及ぼす可能性があります。一般的なガイダンスとして、小規模なインスタンス構成(1 個の vCPU コア、100 GB 未満のディスク、PD-HDD)は避けてください。この構成ではレプリケーション ラグの影響を受けやすくなります。
リージョンが停止した場合、リードレプリカを手動で昇格するかどうかを決定する必要があります。昇格はスプリット ブレインが発生するため、手動オペレーションになります。スプリット ブレイン状態になると、昇格時にプライマリ インスタンスで遅延が発生しているにもかかわらず、昇格したレプリカが新しいトランザクションを受け入れます。このため、リージョンが復旧したときに問題が発生した場合、プライマリ インスタンスからレプリカ インスタンスに伝播されていないトランザクションを調整する必要があります。これが要件に反する場合は、Spanner など、クロスリージョンの同期データベース プロダクトの使用を検討してください。
ユーザーが昇格プロセスをトリガーすると、高可用性構成でのスタンバイ インスタンスの有効化と同様の処理が行われます。このプロセスでは、リードレプリカによってトランザクション ログを処理する必要があります。これにより、復旧までの合計時間が長くなります。レプリカ プロモーションに関与する組み込みロードバランサはないため、昇格されたプライマリにアプリケーションを手動でリダイレクトします。
クロスリージョン レプリカのオプションの詳細については、Cloud SQL のクロスリージョン レプリカのドキュメントをご覧ください。
Cloud SQL DR の詳細については、以下をご覧ください。
- Cloud SQL for MySQL データベースの障害復旧
- Cloud SQL for PostgreSQL データベースの障害復旧
- Cloud SQL for SQL Server データベースの障害復旧
Cloud Storage
Cloud Storage は、グローバルに分散され、スケーラビリティと耐久性に優れたオブジェクト ストレージを提供します。Cloud Storage バケットは、3 つの異なるロケーション タイプ(シングル リージョン、デュアルリージョン、大陸内のマルチリージョン)のいずれかに作成できます。リージョン バケットでは、オブジェクトがシングル リージョン内のアベイラビリティ ゾーンにわたって冗長的に保存されます。一方、デュアルリージョンとマルチリージョンのバケットは地理的に冗長です。つまり、新しく書き込まれたデータが少なくとも 1 つのリモート リージョンにレプリケートされると、オブジェクトはリージョン間で冗長的に保存されます。このアプローチでは、デュアルリージョン バケットとマルチリージョン バケットのデータに、リージョン ストレージよりも幅広い保護がもたらされます。
リージョン バケットは、単一のアベイラビリティ ゾーンで停止が起きた場合に耐障害性があるように設計されています。ゾーンが停止した場合、使用できないゾーン内のオブジェクトは、リージョン内の他の場所から自動的かつ透過的に提供されます。データとメタデータは、最初の書き込みからゾーン間で冗長に保存されます。ゾーンが利用できなくなっても、書き込みは失われません。リージョンが停止した場合、そのリージョンが再度復旧するまで、そのリージョン内のリージョン バケットはオフラインになります。
高可用性が必要な場合は、デュアルリージョンまたはマルチリージョン構成でデータを保存できます。デュアルリージョン バケットとマルチリージョン バケットは単一のバケットですが(個別のプライマリ ロケーションとセカンダリ ロケーションなし)、データとメタデータをリージョン間で冗長的に保存します。リージョンが停止してもサービスは中断されません。デュアルリージョン バケットとマルチリージョン バケットは、バケットが強整合性を保ちながら、複数のリージョンでワークロードの読み取りと書き込みを同時に実行できるという点で、アクティブ - アクティブと考えることができます。これは、障害復旧アーキテクチャの一環として、ワークロードを 2 つのリージョンに分割する必要があるお客様にとって特に魅力的です。
メタデータは常にリージョン間で同期的に書き込まれるため、デュアルリージョンとマルチリージョンは強整合性です。この方法により、サービスは常に、オブジェクトの最新バージョンとオブジェクトの提供元(リモート リージョンを含む)を判別できます。
データは非同期的に複製されます。つまり、RPO の時間枠があり、この間に、新しく書き込まれたオブジェクトがリージョン オブジェクトとして保護され始め、シングル リージョン内のアベイラビリティ ゾーン間で冗長性が確保されます。このサービスは続いて、その RPO 時間枠内にオブジェクトを 1 つ以上のリモート リージョンに複製し、地理的に冗長にします。レプリケーションが完了すると、リージョンが停止した場合に、別のリージョンから自動的かつ透過的にデータを提供できます。ターボ レプリケーションは、RPO 時間枠を短縮するためにデュアルリージョン バケットで使用できるプレミアム機能です。これは、新しく書き込まれたオブジェクトの 100% が 15 分以内に複製され地理的に冗長化されることを目標としています。
リージョンの停止中、RPO 時間枠内に影響を受けたリージョンに最近書き込まれたデータが他のリージョンにまだ複製されていない可能性があるため、RPO は重要な考慮事項になります。その結果、停止中に対象のデータにアクセスできない場合があります。また、影響を受けたリージョンでデータが物理的に破壊された場合、データが失われる可能性もあります。
Cloud Translation
Cloud Translation には、複数のゾーンとリージョンにアクティブなコンピューティング サーバーがあります。また、リージョン内のゾーン間におけるデータの同期レプリケーションもサポートしています。これらの機能によって、Translation はゾーン障害時のデータ損失なしに瞬時のフェイルオーバーを実現できます。また、お客様による入力や調整は必要ありません。リージョンの障害の場合、Cloud Translation は使用できません。
Compute Engine
Compute Engine は Google Cloud の Infrastructure-as-a-Service オプションの一つです。世界各地にある Google のインフラストラクチャを使用して、お客様に仮想マシン(および関連サービス)を提供しています。
Compute Engine インスタンスはゾーンリソースのため、デフォルトではゾーンが停止しているインスタンスを使用できません。Compute Engine は、マネージド インスタンス グループ(MIG)を提供します。これにより、事前構成のインスタンス テンプレートを使用して、リージョン内の単一ゾーン内または複数ゾーン間で追加の VM を自動的にスケールアップできます。MIG は、ゾーン損失に対して強い耐障害性が必要で、ステートレスではないアプリケーションに適しています。ただし、構成とリソース計画が必要です。ステートレス アプリケーションのリージョンの耐障害性を実現するには、複数のリージョン MIG を使用できます。
ステートフル ワークロードを使用するアプリケーションでは、引き続きステートフル MIG を使用できます。ただし、水平方向にスケーリングされないため、キャパシティ プランニングを行う際に注意が必要です。いずれの場合も、Compute Engine インスタンス テンプレートと MIG を適切に構成し、他のゾーンにフェイルオーバーされるように、事前にテストを行っておく必要があります。詳細については、上記の独自のリファレンス アーキテクチャとガイドを開発するをご覧ください。
単一テナンシー
単一テナンシーを使用すると、単一テナントノードに独占的にアクセスできます。単一テナントノードは、特定のプロジェクトの VM をホストすることに特化した物理 Compute Engine サーバーです。
Compute Engine インスタンスのような単一テナントノードは、ゾーンリソースです。万が一ゾーンに障害が発生した場合は使用できません。ゾーンの障害を軽減するには、別のゾーンに単一テナントノードを作成します。特定のワークロードでは、ライセンスや CAPEX 会計目的で単一テナントノードを使用するとメリットがある可能性があるため、事前にフェイルオーバー戦略を計画する必要があります。
これらのリソースを別のロケーションに再作成すると、追加のライセンス費用が発生するか、CAPEX 会計の要件に違反する可能性があります。一般的なガイダンスについては、独自のリファレンス アーキテクチャとガイドを開発するをご覧ください。
単一テナントノードはゾーンリソースであり、リージョンの障害には対応していません。ゾーン間でスケーリングするには、リージョン MIG を使用します。
Compute Engine のネットワーキング
Interconnect 接続の高可用性の設定については、次のドキュメントをご覧ください。
外部 IP アドレスはグローバル モードまたはリージョン モードでプロビジョニングできます。これは、リージョン障害が発生した場合の可用性に影響します。
Cloud Load Balancing の復元力
ロードバランサは、高可用性を備えたアプリケーションを構築する際に重要な要素となります。アプリケーション全体の復元力は、選択したロードバランサのスコープ(グローバルまたはリージョン)だけでなく、バックエンド サービスの冗長性にも依存する点に注意する必要があります。
次の表は、ロードバランサの分散またはスコープに基づいてロードバランサの復元力をまとめたものです。
| ロードバランサのスコープ | アーキテクチャ | ゾーンの停止に対する耐障害性 | リージョンの停止に対する耐障害性 |
|---|---|---|---|
| グローバル | 各ロードバランサはすべてのリージョンに分散されます。 | ||
| クロスリージョン | 各ロードバランサは複数のリージョンに分散されます。 | ||
| リージョン | 各ロードバランサは、リージョン内の複数のゾーンに分散されます。 | 特定のリージョンが停止すると、そのリージョン内のリージョン ロードバランサに影響します。 |
ロードバランサの選択の詳細については、Cloud Load Balancing のドキュメントをご覧ください。
接続テスト
接続テストは、ネットワーク エンドポイント間の接続を確認できる診断ツールです。構成を分析し、場合によってはエンドポイント間でライブ データプレーン分析を行います。エンドポイントは、VM、Google Kubernetes Engine(GKE)クラスタ、ロードバランサの転送ルール、IP アドレスなどのネットワーク トラフィックの送信元または宛先です。接続テストは、データプレーン コンポーネントを使用しない診断ツールです。ユーザー トラフィックを処理または生成することはありません。
ゾーンの停止: 接続テストのリソースはグローバルです。ゾーンが停止した場合、これらを管理して表示できます。接続テストのリソースは、構成テストの結果です。これらの結果には、影響を受けるゾーン内のゾーンリソース(VM インスタンスなど)の構成データが含まれている場合があります。停止が発生した場合、分析は停止前の古いデータを基にして行われているため、分析結果が正確ではなくなります。これに依存しないでください。
リージョンの停止: リージョンが停止しても、接続テストのリソースの管理と表示は引き続き行えます。接続テストのリソースには、影響を受けるリージョン内のリージョン リソース(サブネットワークなど)の構成データが含まれている場合があります。停止が発生した場合、分析は停止前の古いデータを基にして行われているため、分析結果が正確ではなくなります。これに依存しないでください。
Container Registry
Container Registry は、Docker コンテナ イメージを安全かつ限定公開で保存するスケーラブルな Docker Registry を実装します。Container Registry は HTTP Docker Registry API を実装します。
Container Registry は、デフォルトで複数のゾーンまたはリージョンでイメージ メタデータを同期的に保存するグローバル サービスです。コンテナ イメージは Cloud Storage マルチリージョン バケットに保存されます。このストレージ戦略では、Container Registry はすべてのケースでゾーンの停止に対する耐障害性を提供します。Cloud Storage によって複数のリージョンに非同期で複製されたデータについては、リージョンの停止に対する耐障害性を提供します。
Database Migration Service
Database Migration Service は、他のクラウド プロバイダやオンプレミスのデータセンターから Google Cloud にデータベースを移行するためのフルマネージド Google Cloud サービスです。
Database Migration Service はリージョン コントロール プレーンとして設計されています。コントロール プレーンはリージョン内の個々のゾーンに依存しません。ゾーンが停止しても、Database Migration Service API(移行ジョブの作成と管理を含む)にアクセスできます。リージョンの停止中は、停止から復旧するまで、そのリージョンに属する Database Migration Service リソースにアクセスできなくなります。
Database Migration Service は、移行プロセスに使用される移行元データベースと移行先データベースの可用性に依存します。Database Migration Service の移行元データベースまたは移行先データベースを使用できない場合、移行は続行されませんが、お客様のコアデータやジョブデータは失われません。移行元データベースと移行先データベースが再び使用可能になると、移行ジョブが再開されます。
たとえば、高可用性(HA)を有効にして移行先の Cloud SQL データベースを構成すると、ゾーンの停止に対して耐障害性のある移行先データベースを実現できます。
Database Migration Service の移行は、次の 2 つのフェーズを経由します。
- 完全なダンプ: 移行ジョブの仕様に従って、移行元から移行先への完全なデータコピーを実行します。
- 変更データ キャプチャ(CDC): 移行元から移行先に増分の変更を複製します。
ゾーンの停止: これらのフェーズのいずれかでゾーン障害が発生した場合でも、Database Migration Service のリソースにアクセスして管理できます。データ移行は次のように影響を受けます。
- 完全なダンプ: データの移行に失敗します。移行先データベースがフェイルオーバー オペレーションを完了したら、移行ジョブを再起動する必要があります。
- CDC: データの移行が一時停止されます。移行先データベースがフェイルオーバー オペレーションを完了すると、移行ジョブは自動的に再開されます。
リージョンの停止: Database Migration Service はリージョン間のリソースをサポートしていないため、リージョンの障害に対する耐障害性がありません。
Dataflow
Dataflow は、ストリーミングとバッチ パイプライン用の Google Cloud のフルマネージド サーバーレス データ処理サービスです。デフォルトでは、リージョン エンドポイントは、リージョン内の使用可能なすべてのゾーンを利用するように Dataflow ワーカープールを構成します。ゾーンの選択は、ワーカーの作成時にワーカーごとに計算され、リソースの取得と未使用の予約の使用が最適化されます。Dataflow ジョブのデフォルト構成では、中間データが Dataflow サービスによって保存され、ジョブの状態はバックエンドに保存されます。ワーカーは他のゾーンで再作成されるため、ゾーンに障害が発生しても Dataflow ジョブは引き続き実行できます。
次の制限が適用されます。
- リージョン プレースメントは、Streaming Engine または Dataflow Shuffle を使用するジョブでのみサポートされます。Streaming Engine または Dataflow Shuffle を無効にしたジョブでは、リージョン プレースメントを使用できません。
- リージョン プレースメントは VM にのみ適用されます。Streaming Engine と Dataflow Shuffle 関連のリソースには適用されません。
- VM は複数のゾーン間で複製されません。VM が使用不能になった場合、作業アイテムは失われたと見なされ、別の VM によって再処理されます。
- リージョン全体でストックアウトが発生した場合、Dataflow サービスはこれ以上 VM を作成できなくなります。
高可用性のための Dataflow パイプラインの設計
高可用性データ処理を行うために複数のストリーミング パイプラインを並行して実行できます。たとえば、異なるリージョンで 2 つの並列ストリーミング ジョブを実行できます。パイプラインを並列実行することで、データ処理の地理的冗長性とフォールト トレランスが確保されます。データソースとシンクの地理的な可用性を考慮することで、高可用性のマルチリージョン構成でエンドツーエンドのパイプラインを操作できます。詳細については、「Dataflow パイプライン ワークフローの設計」の高可用性と地理的冗長性をご覧ください。
ゾーンやリージョンが停止した場合、Pub/Sub トピックに同じサブスクリプションを再利用することで、データの損失を回避できます。シャッフル中にレコードが失われないようにするため、Dataflow はアップストリーム バックアップを使用します。つまり、レコードを送信しているワーカーは、レコードが受信されたという確認応答を受け取るまで RPC を再試行します。これにより、レコードの処理がダウンストリームの永続ストレージに commit されるという副作用が発生します。Dataflow はまた、レコードを送信しているワーカーが使用不能になった場合、RPC の再試行を継続します。RPC を再試行すると、すべてのレコードが 1 回だけ配信されます。Dataflow の 1 回限りの保証の詳細については、Dataflow で 1 回限りの保証をご覧ください。
パイプラインでグループ化または時間ウィンドウ処理を使用している場合、ゾーンまたはリージョンの停止の後に Kafka の Pub/Sub またはリプレイ機能を使用して、同じ検索結果になったデータ要素を再処理できます。パイプラインで使用されるビジネス ロジックが停止前のデータに依存していない場合は、パイプライン出力のデータ損失を 0 要素にまで抑えることができます。パイプラインのビジネス ロジックが、停止前に処理されたデータに依存している場合(たとえば、長いスライディング ウィンドウが使用されている場合や、グローバル時間ウィンドウが増加し続けるカウンタを保存している場合)は、Dataflow スナップショットを使用して、ストリーミング パイプラインの状態を保存し、状態を保持したまま新しいバージョンのジョブを開始します。
Dataproc
Dataproc は、ストリーミングとバッチデータ処理の機能を提供します。Dataproc はリージョン コントロール プレーンとして設計され、ユーザーが Dataproc クラスタを管理できます。コントロール プレーンはリージョン内の個々のゾーンに依存しません。したがって、ゾーンが停止しても、Dataproc API へのアクセスは維持され、新しいクラスタの作成も可能です。
次の上に Dataproc クラスタを作成できます。
Compute Engine 上の Dataproc クラスタ
Compute Engine 上の Dataproc クラスタはゾーンリソースのため、ゾーンが停止すると、クラスタが利用不能になるか破棄されます。Dataproc は、クラスタ ステータスのスナップショットを自動的に生成するわけではないため、ゾーンが停止すると、処理中のデータが失われる可能性があります。Dataproc はサービス内でユーザーデータを保持します。ユーザーは、多数のデータストアに結果を書き込むようにパイプラインを構成できます。その際、データストアのアーキテクチャを検討し、必要な障害復旧を行う選択する必要があります。
ゾーンが停止状態になった場合、別のゾーンを選択するか、Dataproc の自動プレースメント機能で利用可能なゾーンを自動的に選択することで、別のゾーンにクラスタの新しいインスタンスを別の再作成できます。クラスタが使用可能になると、データ処理を再開できます。また、高可用性モードを有効にして、クラスタを実行することもできます。これにより、ゾーンの一部停止がマスターノード、つまりクラスタ全員に影響を与える可能性を抑えることができます。
GKE 上の Dataproc クラスタ
GKE 上の Dataproc クラスタは、ゾーンクラスタまたはリージョン クラスタになります。
ゾーンとリージョンの GKE クラスタのアーキテクチャと DR 機能の詳細については、このドキュメントで後述する Google Kubernetes Engine セクションをご覧ください。
Datastream
Datastream は、サーバーレスの変更データ キャプチャ(CDC)とレプリケーションを提供するサービスです。このサービスを利用することで、最小限のレイテンシでデータを同期することができます。Datastream を使用すると、オペレーショナル データベースから BigQuery と Cloud Storage にデータを複製できます。また、Dataflow テンプレートとの統合が効率化されているため、Cloud SQL や Spanner など、幅広い宛先にデータを読み込むカスタム ワークフローを構築できます。
ゾーンの停止: Datastream はマルチゾーン サービスです。ゾーン全体が停止しても、データや可用性が失われることはありません。ゾーン障害が発生しても、Datastream のリソースにアクセスして管理することができます。
リージョンの停止: リージョンが停止した場合、リージョンが再開されるとすぐに Datastream が再度使用可能になります。
Document AI
Document AI はドキュメント理解プラットフォームであり、ドキュメントから非構造化データを取り出して構造化データに変換し、ドキュメントを簡単に理解、分析、利用できるようにします。Document AI はリージョン サービスです。お客様はリージョンを選択できますが、そのリージョン内のゾーンは選択できません。データとトラフィックは、リージョン内のゾーン間で自動的にロードバランスされます。サーバーは受信トラフィックに合わせて自動的にスケーリングされ、必要に応じてゾーン間で負荷分散されます。このようにゾーンごとに自動スケーリングを行うスケジューラが各ゾーンで維持されています。また、スケジューラは他のゾーンが受けている負荷を認識し、ゾーン障害に対応するためにゾーン内の追加容量をプロビジョニングします。
ゾーンの停止: Document AI は、ユーザー ドキュメントとプロセッサ バージョン データを保存します。このデータはリージョンに保存され、同期的に書き込まれます。データはリージョンに保存されるため、データ プレーン オペレーションはゾーン障害の影響を受けません。ゾーンに障害が発生した場合、トラフィックは他のゾーンに自動的にルーティングされ、Vertex AI などの依存サービスの復元にかかる時間に基づいて遅延します。
リージョンの停止: データがリージョン間で複製されることはありません。リージョンが停止しても、Document AI はフェイルオーバーしません。Document AI を使用する Google Cloud リージョンはお客様が選択します。ただし、そのお客様のトラフィックが別のリージョンにルーティングされることはありません。
Endpoint Verification
Endpoint Verification を使用すると、管理者やセキュリティ運用担当者は、組織のデータにアクセスするデバイスのインベントリを作成できます。Endpoint Verification によって、Chrome Enterprise Premium ソリューションの一部として、重要なデバイスの信頼とセキュリティ ベースのアクセス制御も実現できます。
Endpoint Verification は、組織のノートパソコンとデスクトップ デバイスのセキュリティ ポスチャーの概要が必要な場合に使用します。Endpoint Verification を Chrome Enterprise Premium サービスと組み合わせると、Google Cloud リソースに対してきめ細かなアクセス制御を適用できます。
Endpoint Verification は、Google Cloud、Cloud Identity、Google Workspace Business、Google Workspace Enterprise で利用できます。
Eventarc
Eventarc は、状態変化に対応する疎結合サービスを使用して、Google プロバイダ(ファースト パーティ)、ユーザーアプリ(セカンド パーティ)、Software as a Service(サードパーティ)から非同期に配信されたイベントを提供します。これにより、イベント プロバイダ サービスまたはお客様のコードでイベントが発生したときにトリガーされるように、宛先(Cloud Run インスタンスや第 2 世代の Cloud Run 関数など)を構成できます。
ゾーン停止: Eventarc はトリガーに関連するメタデータを保存します。このデータはリージョンに保存され、同期的に書き込まれます。トリガーとチャネルを作成および管理する Eventarc API は、リージョン内のクォーラムにデータが commit されると API 呼び出しを返します。データはリージョンに保存されるため、データプレーン オペレーションはゾーン障害の影響を受けません。ゾーンに障害が発生した場合、トラフィックは自動的に他のゾーンにルーティングされます。セカンド パーティとサードパーティのイベントの受信と配信を行うための Eventarc サービスは、ゾーン間で複製されます。これらのサービスはリージョン内で分散されます。使用できないゾーンへのリクエストは、リージョン内の利用可能なゾーンで自動的に処理されます。
リージョンの停止: お客様は、Eventarc トリガーを作成する Google Cloud リージョンを選択します。データがリージョン間で複製されることはありません。お客様のトラフィックが Eventarc によって別のリージョンにルーティングされることはありません。リージョン障害の場合、停止から復旧するとすぐに Eventarc が再び利用可能になります。高可用性を実現するために、必要に応じて複数のリージョンにトリガーをデプロイすることをおすすめします。
次の点にご注意ください。
- ファースト パーティ イベントの受信と配信を行う Eventarc サービスはベスト エフォート方式で提供され、RTO / RPO の対象外です。
- Google Kubernetes Engine サービスの Eventarc イベント配信はベスト エフォート方式で提供され、RTO/RPO は対象外です。
Filestore
基本階層と高スケール階層はゾーンリソースです。デプロイされたゾーンやリージョンの障害には耐えられません。
エンタープライズ階層の Filestore インスタンスは、リージョン リソースです。Filestore では、NFS で要求される厳格な整合性ポリシーを採用しています。クライアントがデータを書き込んだときに、Filestore は変更が保持されて 2 つのゾーンに複製されるまで確認応答を返しません。これにより、後続の読み取りで正しいデータが返されます。
ゾーンに障害が発生した場合、エンタープライズ階層のインスタンスは他のゾーンからのデータの処理を継続し、その間は新しい書き込みを受け入れます。読み取りオペレーションと書き込みオペレーションではどちらもパフォーマンスが低下する可能性があり、書き込みオペレーションが複製されない可能性があります。鍵は他のゾーンから提供されるため、暗号化は不正使用されません。
同じリージョン内の他のゾーンでさらに停止した場合に備えて、クライアントで外部バックアップを作成することをおすすめします。このバックアップを使用して、インスタンスを他のリージョンに復元できます。
Firestore
Firestore は、Firebase と Google Cloud からのモバイル、ウェブ、サーバー開発に対応した、柔軟でスケーラブルなデータベースです。Firestore では、自動マルチリージョン データ レプリケーション、強整合性の保証、アトミック バッチ オペレーション、ACID トランザクションを提供しています。
Firestore では、シングル リージョンとマルチリージョンの両方のロケーションをお客様に提供します。トラフィックは、リージョン内のゾーン間で自動的に負荷分散されます。
リージョン Firestore インスタンスは、少なくとも 3 つのゾーンにわたってデータを同期的に複製します。ゾーン障害の場合でも、残りの 2 つ(またはそれ以上)のレプリカによって書き込みが commit され、commit されたデータが保持されます。トラフィックは他のゾーンに自動的にルーティングされます。リージョンのロケーションでは、コストが削減され、書き込みレイテンシが短縮され、他の Google Cloud リソースとのコロケーションがもたらされます。
Firestore のマルチリージョン インスタンスは、3 つのリージョン(2 つのサービス リージョンと 1 つのウィットネス リージョン)の 5 つのゾーン間でデータを同期的に複製し、ゾーンとリージョンの障害に対する堅牢性を確保します。ゾーンまたはリージョンの障害の場合、commit されたデータは保持されます。トラフィックは処理中のゾーン / リージョンに自動的にルーティングされ、commit は残りの 2 つのリージョンで少なくとも 3 つのゾーンによって処理されます。マルチリージョンは、データベースの可用性と耐久性を最大化します。
ファイアウォール インサイト
ファイアウォール インサイトは、ファイアウォール ルールの理解と最適化に役立ちます。これは、ファイアウォール ルールの使用状況に関する分析情報、推奨事項、指標を提供します。ファイアウォール インサイトは、機械学習を使用して今後のファイアウォール ルールの使用も予測します。ファイアウォール インサイトを使用すると、ファイアウォール ルールの最適化の際に、より適切な判断を下せるようになります。たとえば、ファイアウォール インサイトでは、制限が過度に緩いルールを特定できます。この情報を使用するとファイアウォール構成をより厳格にできます。
ゾーンの停止: ファイアウォール インサイトのデータはゾーン間で複製されるため、ゾーンの停止の影響を受けず、お客様のトラフィックは他のゾーンに自動的にルーティングされます。
リージョンの停止: ファイアウォール インサイトのデータはリージョン間で複製されるため、リージョンの停止の影響を受けず、お客様のトラフィックは他のリージョンに自動的にルーティングされます。
フリート
フリートを使用すると、お客様は複数の Kubernetes クラスタをグループとして管理でき、プラットフォーム管理者はマルチクラスタ サービスを使用できます。たとえば、フリートを使用すると、管理者はすべてのクラスタにわたって一様なポリシーを適用したり、マルチクラスタ Ingress を設定したりできます。
GKE クラスタをフリートに登録すると、デフォルトでは、クラスタは同じリージョンにリージョン メンバーシップを持ちます。Google Cloud 以外のクラスタをフリートに登録すると、任意のリージョンまたはグローバル ロケーションを選択できます。クラスタの物理的なロケーションに近いリージョンを選択することをおすすめします。これにより、Connect Gateway を使用してクラスタにアクセスするときに最適なレイテンシを実現できます。
ゾーンが停止しても、基盤となるクラスタがゾーンクラスタであり、使用不能にならない限り、フリートの機能は影響を受けません。
リージョンが停止した場合、リージョン内のメンバーシップ クラスタのフリート機能は静的に失敗します。リージョンの停止を回避するには、クラウド インフラストラクチャの停止に対する障害復旧の設計で提案されているように、複数のリージョンにわたってデプロイする必要があります。
Google Cloud Armor
Google Cloud Armor を使用すると、ボリューム型 DDoS 攻撃、クロスサイト スクリプティングや SQL インジェクションなどのアプリケーション攻撃、といったさまざまな種類の脅威からデプロイとアプリケーションを保護できます。Google Cloud Armor は、Google Cloud ロードバランサで不要なトラフィックをフィルタリングし、こうしたトラフィックが VPC に侵入してリソースを消費しないようにします。こうした保護の一部は自動的に行われます。一部の保護では、セキュリティ ポリシーを構成して、バックエンド サービスまたはリージョンに接続する必要があります。グローバル スコープの Google Cloud Armor セキュリティ ポリシーは、グローバル ロードバランサに適用されます。リージョン スコープのセキュリティ ポリシーは、リージョン ロードバランサに適用されます。
ゾーンの停止: ゾーンの停止が発生した場合、Google Cloud ロードバランサは、正常なバックエンド インスタンスが利用可能な他のゾーンにトラフィックをリダイレクトします。Google Cloud Armor セキュリティ ポリシーはリージョン内のすべてのゾーンに同期して複製されるため、Google Cloud Armor による保護はトラフィックのフェイルオーバー後すぐに利用できます。
リージョンの停止: リージョンが停止した場合、グローバル Google Cloud ロードバランサは、正常なバックエンド インスタンスが使用可能な他のリージョンにトラフィックをリダイレクトします。グローバル Google Cloud Armor セキュリティ ポリシーはすべてのリージョンに同期して複製されるため、Google Cloud Armor による保護はトラフィックのフェイルオーバー後すぐに利用できます。リージョンの障害に対する復元力を確保するために、すべてのリージョンに Google Cloud Armor のリージョン セキュリティ ポリシーを構成する必要があります。
Google Kubernetes Engine
Google Kubernetes Engine(GKE)は、Google Cloud にコンテナ化されたアプリケーションをストリーミングでデプロイすることで、Kubernetes マネージド サービスを提供します。リージョンまたはクラスタゾーンのトポロジを選択できます。
- ゾーンクラスタを作成すると、GKE は選択したゾーンに 1 つのコントロール プレーン マシンをプロビジョニングします。また、同じゾーン内にワーカーマシン(ノード)をプロビジョニングします。
- リージョン クラスタの場合、GKE は 3 つのコントロール プレーン マシンを、選択したリージョン内の 3 つの異なるゾーンにプロビジョニングします。デフォルトでは、ノードが 3 つのゾーンにまたがっていますが、1 つのゾーンのみにプロビジョニングされるノードを含むリージョン クラスタを作成することもできます。
- マルチゾーン クラスタはゾーンクラスタに似ていますが、マスターマシンが 1 つ含まれているのため、複数のゾーンのノード間にまたがることもできます。
ゾーンの停止: ゾーンの停止を回避するには、リージョン クラスタを使用します。コントロール プレーンとノードは、リージョン内の 3 つの異なるゾーンに分散されます。ゾーンが停止しても、他の 2 つのゾーンにデプロイされているコントロール プレーンとワーカーノードに影響はありません。
リージョンの停止: リージョンの停止を回避するには、複数のリージョンにわたるデプロイが必要になります。現在のところ、組み込みプロダクトの機能として提供されていませんが、マルチリージョン トポロジは GKE の複数のユーザーで現在採用されているアプローチで、手動での実装も可能です。複数のリージョン クラスタを作成して、複数のリージョンにワークロードを複製し、マルチクラスタの Ingress を使用してクラスタへのトラフィックを制御できます。
HA VPN
HA VPN(高可用性)は、オンプレミス プライベート クラウド、他の Virtual Private Cloud、または他のクラウド サービス プロバイダ ネットワークから Google Cloud の Virtual Private Cloud(VPC)へのトラフィックを安全に暗号化する復元性の高い Cloud VPN サービスです。
HA VPN のゲートウェイには 2 つのインターフェースがあり、それぞれに個別の IP アドレスプールの IP アドレスがあります。これにより、異なる PoP とクラスタ間で論理的にも物理的にも分割され、最適な冗長性が確保されます。
ゾーンの停止: ゾーンが停止した場合、一方のインターフェースが接続を失うことがありますが、トラフィックは Border Gateway Protocol(BGP)を使用した動的ルーティングを介してもう一方のインターフェースにリダイレクトされます。
リージョンの停止: リージョンが停止した場合、両方のインターフェースが短時間切断されることがあります。
Identity and Access Management
Identity and Access Management(IAM)は、クラウド リソースに対するアクションのすべての認可の決定を担当します。IAM は、ポリシーが(データプレーン内の)各アクションに権限を付与していることを確認し、(コントロール プレーンでの)SetPolicy 呼び出しを通じてこれらのポリシーの更新を処理します。
すべての IAM ポリシーは、すべてのリージョン内の複数のゾーンにわたって複製されます。これにより、IAM データプレーン オペレーションは他のリージョン障害から復元でき、各リージョン内のゾーン障害に耐えることができます。ゾーン障害やリージョン障害に対する IAM データプレーンの耐障害性により、高可用性のためのマルチリージョン アーキテクチャとマルチゾーン アーキテクチャを実現できます。
IAM コントロール プレーンのオペレーションは、クロスリージョン レプリケーションンに左右されることがあります。SetPolicy の呼び出しが成功すると、データは複数のリージョンに書き込まれますが、他のリージョンへの伝播は結果整合性になります。IAM コントロール プレーンは、シングル リージョンの障害に対する耐障害性があります。
Identity-Aware Proxy
Identity-Aware Proxy は、Google Cloud、他のクラウド、オンプレミスでホストされているアプリケーションへのアクセスを提供します。IAP はリージョンに分散されており、利用できないゾーンへのリクエストは、そのリージョン内の他の利用可能なゾーンから自動的に処理されます。
IAP でのリージョン停止は、影響を受けるリージョンでホストされているアプリケーションへのアクセスに影響します。複数のリージョンにデプロイし、Cloud Load Balancing を使用して可用性を向上させ、リージョンの停止からの復元力を高めることをおすすめします。
Identity Platform
Identity Platform を使用すると、カスタマイズ可能な Google レベルの Identity and Access Management をアプリに追加できます。Identity Platform はグローバルなサービスです。ユーザーはデータの保存先となるリージョンやゾーンを選択できません。
ゾーン停止: ゾーンが停止しても、Identity Platform は次に近いセルにリクエストをフェイルオーバーします。すべてのデータはグローバル スケールで保存されるため、データが失われることはありません。
リージョンの停止: リージョンが停止している間、Identity Platform は影響を受けたリージョンからトラフィックを削除し、使用できないリージョンへの Identity Platform リクエストを一時的に失敗させます。影響を受けたリージョンへのトラフィックがなくなると、グローバル サーバー ロード バランシング サービスは、最も近い使用可能な正常なリージョンにリクエストをルーティングします。すべてのデータがグローバルに保存されるため、データが失われることはありません。
Knative serving
Knative serving は、お客様がサーバーレス ワークロードをお客様のクラスタで実行できるようにするグローバル サービスです。その目的は、Knative serving ワークロードがお客様のクラスタに適切にデプロイされ、Knative serving のインストール ステータスが GKE Fleet API Feature リソースに反映されるようにすることです。このサービスは、お客様のクラスタに Knative serving リソースをインストールまたはアップグレードする場合にのみ使用されます。クラスタ ワークロードの実行には関与しません。Knative serving が有効になっているプロジェクトに属するお客様のクラスタは、複数のリージョンとゾーンのレプリカ間で分散されます。各クラスタは 1 つのレプリカによってモニタリングされます。
ゾーンとリージョンの停止: 停止中のロケーションでホストされていたレプリカによってモニタリングされているクラスタは、他のゾーンとリージョンの正常なレプリカ間で自動的に再分配されます。この再割り当ての進行中は、一部のクラスタが Knative serving で短期間モニタリングされない場合があります。この期間中に、ユーザーがクラスタで Knative serving 機能を有効にすると、クラスタが正常な Knative serving サービス レプリカに再接続してから、そのクラスタへの Knative serving リソースのインストールが開始されます。
Looker(Google Cloud コア)
Looker(Google Cloud コア)は、Google Cloud コンソールから Looker インスタンスのプロビジョニング、構成、管理を簡素化かつ合理化できるビジネス インテリジェンス プラットフォームです。Looker(Google Cloud コア)を使用すると、ユーザーはデータの探索、ダッシュボードの作成、アラートの設定、レポートの共有を行うことができます。さらに、Looker(Google Cloud コア)には、データ モデリング担当者向けの IDE と、デベロッパー向けの豊富な埋め込み機能と API 機能が用意されています。
Looker(Google Cloud コア)はリージョンごとに分離されたインスタンスで構成され、リージョン内のゾーン間でデータを同期して複製します。インスタンスで使用するリソース(Looker(Google Cloud コア)が接続するデータソースなど)が、インスタンスが実行されているリージョンと同じリージョンにあることを確認してください。
ゾーンの停止: Looker(Google Cloud コア)インスタンスは、メタデータと独自にデプロイされたコンテナを保存します。データは、複製されたインスタンス間で同期して書き込まれます。ゾーンが停止しても、Looker(Google Cloud コア)インスタンスは、同じリージョン内の他の使用可能なゾーンから引き続きサービスを提供します。リージョン内のクォーラムにデータが commit されると、トランザクションまたは API 呼び出しが返されます。レプリケーションが失敗すると、トランザクションは commit されず、ユーザーに失敗が通知されます。複数のゾーンで障害が発生した場合、トランザクションも失敗し、ユーザーに通知されます。Looker(Google Cloud コア)は、現在実行中のスケジュールやクエリを停止します。障害の解決後に、スケジュールを変更するか、再度キューに入れる必要があります。
リージョンの停止: 影響を受けるリージョン内の Looker(Google Cloud コア)インスタンスは使用できません。Looker(Google Cloud コア)は、現在実行中のスケジュールやクエリを停止します。障害の解決後に、スケジュールを変更するか、クエリを再度キューに入れる必要があります。別のリージョンに新しいインスタンスを手動で作成できます。Looker(Google Cloud コア)インスタンスからデータをインポートまたはエクスポートするで定義されているプロセスを使用して、インスタンスを復元することもできます。万一リージョンが停止した場合に備えて、定期的なデータ エクスポート プロセスを設定して、アセットを事前にコピーしておくことをおすすめします。
Looker Studio
Looker Studio は、データの可視化とビジネス インテリジェンスのプロダクトです。これにより、他のシステムに保存されているデータに接続し、そのデータを使用してレポートとダッシュボードを作成し、組織全体でレポートとダッシュボードを共有することができます。Looker Studio はグローバル サービスであり、ユーザーはリソース スコープを選択できません。
ゾーンが停止しても、Looker Studio は中断することなく、同じリージョンまたは別のリージョンの別のゾーンからのリクエストを処理し続けます。ユーザー アセットはリージョン間で同期的に複製されます。そのため、データが失われることはありません。
リージョンが停止した場合、Looker Studio は中断することなく別のリージョンからのリクエストを処理します。ユーザー アセットはリージョン間で同期的に複製されます。そのため、データが失われることはありません。
Memorystore for Memcached
Memorystore for Memcached は、Google Cloud のマネージド Memcached サービスです。Memorystore for Memcached によって、お客様はアプリケーション用の高スループットの Key-Value データベースとして使用できる Memcached クラスタを作成できます。
Memcached クラスタはリージョン単位で、お客様が指定したすべてのゾーンにわたってノードが分散されます。ただし、Memcached はノード間でデータを何も複製しません。したがって、ゾーンの障害により、データの一部が失われる可能性があります(部分的なキャッシュ フラッシュとも呼ばれます)。Memcached インスタンスは引き続き動作しますが、ノード数は少なくなります。ゾーンの障害中は、サービスは新しいノードを起動しません。影響されていないゾーンの Memcached ノードは、引き続きトラフィックを処理しますが、ゾーンの障害によって、ゾーンが復旧するまでキャッシュ ヒット率が低くなります。
リージョンの障害の場合、Memcached ノードはトラフィックを処理しません。その場合、データは失われ、その結果、キャッシュの完全なフラッシュが発生します。リージョンの停止を軽減するには、アプリケーションと Memorystore for Memcached を複数のリージョンにわたってデプロイするアーキテクチャを実装します。
Memorystore for Redis
Memorystore for Redis は、複雑な Redis デプロイの管理の負担を軽減できる、Google Cloud 用のフルマネージド Redis サービスです。現時点では、ベーシック ティアとスタンダード ティアの 2 つのティアがあります。ベーシック ティアの場合、ゾーンまたはリージョンが停止すると、データが失われます(完全なキャッシュ フラッシュとも呼ばれます)。スタンダード ティアの場合、リージョンが停止するとデータが失われます。ゾーンが停止すると、非同期レプリケーションのために、スタンダード ティア インスタンスに部分的なデータの損失が生じる可能性があります。
ゾーンの停止: スタンダード ティアのインスタンスは、プライマリ ノード内のデータセットからレプリカノードに非同期でデータセット オペレーションを複製します。プライマリ ノードのゾーン内で停止が発生すると、レプリカノードがプライマリ ノードに昇格します。昇格の際にフェイルオーバーが発生すると、Redis クライアントはインスタンスに再接続する必要があります。再接続すると、オペレーションが再開されます。スタンダード ティアの Memorystore for Redis インスタンスの高可用性については、Memorystore for Redis の高可用性をご覧ください。
スタンダード ティアのインスタンスでリードレプリカが有効で、レプリカが 1 つしかない場合は、ゾーンが停止している間、読み取りエンドポイントを使用できません。リードレプリカの障害復旧の詳細については、リードレプリカの障害モードをご覧ください。
リージョンの停止: Memorystore for Redis はリージョン プロダクトであるため、1 つのインスタンスではリージョンの障害には対応できません。定期的なタスクをスケジュール設定して、Redis インスタンスを別のリージョンの Cloud Storage バケットにエクスポートできます。リージョンの停止が発生した場合、エクスポートしたデータセットとは別のリージョンに Redis インスタンスを復元できます。
マルチクラスタ サービス ディスカバリとマルチクラスタ Ingress
GKE マルチクラスタ サービス(MCS)は、複数のコンポーネントで構成されています。コンポーネントには、Google Kubernetes Engine ハブ(メンバーシップを使用して複数の Google Kubernetes Engine クラスタをオーケストレートする)、クラスタ自体、GKE Hub コントローラ(マルチクラスタ Ingress、マルチクラスタ サービス ディスカバリ)があります。 ハブ コントローラは、複数のクラスタでバックエンドを使用することで、Compute Engine ロードバランサの構成をオーケストレートします。
ゾーンが停止した場合、マルチクラスタ サービス ディスカバリは別のゾーンまたはリージョンからのリクエストを処理し続けます。リージョンが停止した場合、マルチクラスタ サービス ディスカバリはフェイルオーバーしません。
マルチクラスタ Ingress でゾーンが停止した場合、構成クラスタがゾーンクラスタであり、障害の範囲内にあれば、ユーザーは手動でフェイルオーバーする必要があります。データプレーンはフェイル スタティックであり、ユーザーがフェイルオーバーするまでトラフィックの処理を続行します。手動フェイルオーバーの必要性をなくすには、構成クラスタにリージョン クラスタを使用します。
リージョンが停止した場合、マルチクラスタ Ingress はフェイルオーバーしません。ユーザーは、構成クラスタを手動でフェイルオーバーするための DR 計画を用意する必要があります。詳細については、マルチクラスタ Ingress の設定とマルチクラスタ サービスの構成をご覧ください。
GKE の詳細については、クラウド インフラストラクチャの停止に対する障害復旧の設計の「Google Kubernetes Engine」セクションをご覧ください。
ネットワーク アナライザ
ネットワーク アナライザは、VPC ネットワークの構成を自動的にモニタリングし、構成ミスや最適ではない構成を検出します。ネットワーク トポロジ、ファイアウォール ルール、ルート、構成の依存関係、サービスとアプリケーションへの接続に関する分析情報を提供します。ネットワーク障害を特定し、根本原因の情報と考えられる解決策を提供します。
ネットワーク アナライザは継続的に実行され、ネットワークの構成が更新されると、関連する分析をほぼリアルタイムでトリガーします。ネットワーク アナライザはネットワーク障害を検出すると、その障害と最近の構成変更との関連付けを試み、根本原因を特定します。可能であれば、問題の修正方法を提案する推奨事項を提示します。
ネットワーク アナライザは、データプレーン コンポーネントを使用しない診断ツールです。ユーザー トラフィックを処理または生成することはありません。
ゾーンの停止: ネットワーク アナライザ サービスはグローバルに複製されるため、その可用性はゾーンの停止の影響を受けません。
ネットワーク アナライザの分析情報に、停止しているゾーンの構成が含まれていると、データ品質に影響します。このゾーンの構成を参照するネットワーク分析情報は古いものになります。停止中にネットワーク アナライザから提供された分析情報に依存しないでください。
リージョンの停止: ネットワーク アナライザ サービスはグローバルに複製されるため、その可用性はリージョンの停止の影響を受けません。
ネットワーク アナライザの分析情報に、停止しているリージョンの構成が含まれていると、データ品質に影響します。このリージョンの構成を参照するネットワーク分析情報は古いものになります。停止中にネットワーク アナライザから提供された分析情報に依存しないでください。
ネットワーク トポロジ
ネットワーク トポロジは、ネットワーク インフラストラクチャのトポロジを表示する可視化ツールです。インフラストラクチャ ビューには、Virtual Private Cloud(VPC)ネットワーク、オンプレミス ネットワークとのハイブリッド接続、Google マネージド サービスへの接続、関連する指標が表示されます。
ゾーンの停止: ゾーンが停止した場合、そのゾーンのデータはネットワーク トポロジには表示されません。他のゾーンのデータには影響しません。
リージョンの停止: リージョンが停止した場合、そのリージョンのデータはネットワーク トポロジには表示されません。他のリージョンのデータには影響しません。
パフォーマンス ダッシュボード
パフォーマンス ダッシュボードは、Google Cloud ネットワーク全体のパフォーマンスと、プロジェクトのリソースのパフォーマンスを可視化します。
このパフォーマンス モニタリング機能を使用すると、発生している問題がアプリケーション内の問題なのか、基盤となっている Google Cloud ネットワークの問題なのかを区別できます。過去のネットワーク パフォーマンスの問題を調査することもできます。パフォーマンス ダッシュボードは Cloud Monitoring にもデータをエクスポートします。Monitoring を使用してデータのクエリを実行し、追加情報を取得できます。
ゾーンの停止:
ゾーンが停止した場合、影響を受けたゾーンからのトラフィックのレイテンシとパケットロスのデータは、パフォーマンス ダッシュボードには表示されません。他のゾーンからのトラフィックのレイテンシとパケットロスのデータは影響を受けません。サービスの停止が終了すると、レイテンシとパケットロスのデータが再開されます。
リージョンの停止:
リージョンが停止した場合、影響を受けたリージョンからのトラフィックのレイテンシとパケットロスのデータは、パフォーマンス ダッシュボードには表示されません。他のリージョンからのトラフィックのレイテンシとパケットロスのデータは影響を受けません。サービスの停止が終了すると、レイテンシとパケットロスのデータが再開されます。
Network Connectivity Center
Network Connectivity Center は、ハブ アンド スポーク アーキテクチャを採用したネットワーク接続管理プロダクトです。このアーキテクチャでは、一元管理リソースがハブとして機能し、各接続リソースがスポークとして機能します。ハイブリッド スポークは現在、HA VPN、Dedicated Interconnect、Partner Interconnect、主要なサードパーティ ベンダーの SD-WAN ルーター アプライアンスをサポートしています。Network Connectivity Center のハイブリッド スポークを使用すると、企業は Google Cloud ネットワークのグローバルなリーチを介して、Google Cloud のワークロードとサービスをオンプレミスのデータセンター、他のクラウド、そのブランチに接続できます。
ゾーンの停止: コントロール プレーンとネットワーク データプレーンはリージョン内の複数のゾーンで冗長化されるため、HA 構成を持つ Network Connectivity Center のハイブリッド スポークは、ゾーン障害に対する耐障害性を備えています。
リージョンの停止: Network Connectivity Center ハイブリッド スポークはリージョン リソースであるため、リージョンの障害に耐えることができません。
Network Service Tiers
Network Service Tiers を使用すると、インターネット上のシステムと Google Cloud インスタンス間の接続を最適化できます。プレミアム ティアとスタンダード ティアの 2 つのサービスティアがあります。プレミアム ティアでは、グローバルに通知されたエニーキャスト プレミアム ティア IP アドレスをリージョン バックエンドまたはグローバル バックエンドのフロントエンドとして利用できます。スタンダード ティアでは、リージョンで通知されたスタンダード ティアの IP アドレスをリージョン バックエンドのフロントエンドとして利用できます。アプリケーションの全体的な復元力は、ネットワーク サービス ティアと、それに関連付けられているバックエンドの冗長性の両方によって影響を受けます。
ゾーン停止: プレミアム ティアとスタンダード ティアの両方で、リージョンの冗長バックエンドに関連付けられている場合、ゾーン停止に対する復元力が提供されます。ゾーン停止が発生した場合、リージョン冗長バックエンドを使用するケースのフェイルオーバー動作は、関連するバックエンド自体によって決まります。ゾーン バックエンドに関連付けられると、停止から復旧するとすぐにサービスが再び利用可能になります。
リージョンの停止: プレミアム ティアで、グローバルの冗長バックエンドに関連付けられている場合、リージョン停止に対する復元力が提供されます。スタンダード ティアでは、影響を受けるリージョンへのトラフィックはすべて失敗します。他のすべてのリージョンへのトラフィックは影響を受けません。リージョン停止が発生した場合、グローバル冗長バックエンドを持つプレミアム ティアを使用するケースのファイルオーバー動作は、関連するバックエンド自体によって決まります。リージョン バックエンドまたはスタンダード ティアでプレミアム ティアを使用する場合、停止から復旧するとすぐにサービスは再び利用可能になります。
組織ポリシー サービス
組織のポリシー サービスを使用すると、組織の Google Cloud リソースをプログラムで一元管理できます。組織のポリシー管理者は、リソース階層全体にわたって制限を構成できます。
ゾーンの停止: 組織のポリシー サービスによって作成されたすべての組織のポリシーは、すべてのリージョン内の複数のゾーンに非同期で複製されます。組織のポリシーデータとコントロール プレーン オペレーションは、各リージョンのゾーン障害に耐性があります。
リージョンの停止: 組織のポリシー サービスによって作成されたすべての組織のポリシーは、複数のリージョンに非同期で複製されます。組織のポリシー コントロール プレーン オペレーションは複数のリージョンに書き込まれ、他のリージョンへの伝播は数分以内に整合性が確保されます。組織のポリシー コントロール プレーンは、単一リージョンの障害に対する耐障害性があります。組織のポリシー データプレーン オペレーションは、他のリージョンの障害から復元できます。また、ゾーン障害やリージョン障害に対する組織のポリシー データプレーンの耐障害性により、高可用性のマルチリージョン アーキテクチャとマルチゾーン アーキテクチャを実現できます。
Packet Mirroring
Packet Mirroring では、Virtual Private Cloud(VPC)ネットワーク内で特定のインスタンスのトラフィックのクローンを作成し、クローン化されたデータをリージョンの内部ロードバランサの背後にあるインスタンスに転送して検査します。Packet Mirroring では、ペイロードとヘッダーを含むすべてのトラフィックとパケットデータをキャプチャします。
Packet Mirroring の機能の詳細については、Packet Mirroring の概要ページをご覧ください。
ゾーンの停止: インスタンスが複数のゾーンに存在するように内部ロードバランサを構成します。ゾーンの停止が発生すると、Packet Mirroring はクローン化されたパケットを正常なゾーンに転送します。
リージョンの停止: Packet Mirroring はリージョン プロダクトです。リージョンが停止した場合、影響を受けるリージョンのパケットはクローン化されません。
Persistent Disk
Persistent Disk は、ゾーン構成とリージョン構成で使用できます。
ゾーンの Persistent Disk は単一ゾーンにホストされます。ディスクのゾーンが使用不能になると、そのゾーンが復旧するまで Persistent Disk は使用できなくなります。
リージョンの Persistent Disk の場合、リージョン内の 2 つのゾーン間でデータの同期レプリケーションが行われます。仮想マシンのゾーンが停止すると、ディスクのセカンダリ ゾーンの VM インスタンスにリージョン Persistent Disk を強制的にアタッチできます。このタスクを行うには、そのゾーンで別の VM インスタンスを起動するか、そのゾーン内でホット スタンバイ状態の VM インスタンスを維持する必要があります。
Persistent Disk 内のデータをリージョン間で非同期的に複製するには、Persistent Disk の非同期レプリケーション(PD 非同期レプリケーション)を使用します。つまり、短い RTO と短い RPO のブロック ストレージ レプリケーションにより、リージョン間でのアクティブ / パッシブ DR に対応できます。万一リージョンが停止した場合は、PD 非同期レプリケーションを使用すると、データをセカンダリ リージョンにフェイルオーバーし、そのリージョンでワークロードを再起動できます。
Personalized Service Health
Personalized Service Health は、Google Cloud プロジェクトに関連するサービスの停止を通知します。停止イベント(インシデント、計画メンテナンス)の表示や、インシデント対応プロセスへの統合のために次のような複数のチャネルとプロセスが用意されています。
- Google Cloud コンソールのダッシュボード
- サービス API
- 構成をカスタマイズできるアラート
- 生成され Cloud Logging に送信されるログ
ゾーンの停止: データは特定のロケーションに依存しないグローバル データベースから提供されます。ゾーンの停止が発生した場合、Service Health はリクエストを処理し、まだ機能している同じリージョン内のゾーンにトラフィックを自動的に再送できます。Service Health は、Service Health データベースからイベントデータを取得できる場合、API 呼び出しを正常に返すことができます。
リージョンの停止: データは特定のロケーションに依存しないグローバル データベースから提供されます。リージョンの停止が発生した場合、Service Health は引き続きリクエストを処理できるものの、処理能力は低下する可能性があります。Logging ロケーションのリージョン障害は、ログまたは Cloud Alerting 通知を使用する Service Health ユーザーに影響を与える可能性があります。
Private Service Connect
Private Service Connect は Google Cloud ネットワーキング機能の一つで、コンシューマーが VPC ネットワーク内からマネージド サービスにプライベート接続でアクセスできるようにします。同様に、マネージド サービス プロデューサーがこれらのサービスを個別の VPC ネットワークにホストし、コンシューマーとのプライベート接続を提供できるようにします。
公開サービス用の Private Service Connect エンドポイント
Private Service Connect エンドポイントは、Private Service Connect 転送ルールを使用して、サービス プロデューサーの VPC ネットワーク内のサービスに接続します。サービス プロデューサーは、単一のサービス アタッチメントを公開することで、サービス ユーザーへのプライベート接続を使用してサービスを提供します。これにより、サービス ユーザーは、こうしたサービスに対して VPC から仮想 IP アドレスを割り当てることができます。
ゾーンの停止: コンシューマーの VPC クライアント エンドポイントによって生成された VM トラフィックからの Private Service Connect トラフィックは、サービス プロデューサーの内部 VPC ネットワーク上の公開されたマネージド サービスに引き続きアクセスできます。このアクセスが可能なのは、Private Service Connect トラフィックが別のゾーンの正常なサービス バックエンドにフェイルオーバーするためです。
リージョンの停止: Private Service Connect はリージョン プロダクトです。リージョンの停止に対する耐障害性がありません。マルチリージョン マネージド サービスでは、複数のリージョンにわたって Private Service Connect エンドポイントを構成することで、リージョンの停止中に高可用性を実現できます。
Google API の Private Service Connect エンドポイント
Private Service Connect エンドポイントは、Private Service Connect の転送ルールを使用して Google API に接続します。この転送ルールにより、お客様はカスタマイズしたエンドポイント名とその内部 IP アドレスを使用できます。
ゾーンの停止: VM とエンドポイント間の接続は自動的に同じリージョン内の別の機能ゾーンにフェイルオーバーするため、コンシューマー VPC クライアント エンドポイントからの Private Service Connect トラフィックは Google API にアクセスできます。停止が開始されたときにすでに処理中のリクエストは、クライアントの TCP タイムアウトと復元の再試行の動作によって異なります。
詳細については、Compute Engine の復元をご覧ください。
リージョンの停止: Private Service Connect はリージョン プロダクトです。リージョンの停止に対する耐障害性がありません。マルチリージョン マネージド サービスでは、複数のリージョンにわたって Private Service Connect エンドポイントを構成することで、リージョンの停止中に高可用性を実現できます。
Private Service Connect の詳細については、Private Service Connect のタイプの「エンドポイント」セクションをご覧ください。
Pub/Sub
Pub/Sub は、アプリケーションの統合とストリーム分析で使用されるメッセージング サービスです。Pub/Sub トピックはグローバルです。つまり、これらのトピックは、Google Cloud のすべてのロケーションで表示し、アクセスできます。ただし、メッセージはパブリッシャーに最も近く、リソース ロケーション ポリシーで許可されている単一の Google Cloud リージョンに保存されます。したがって、1 つのトピックが Google Cloud 全体の複数のリージョンに保存されることがあります。Pub/Sub メッセージ ストレージ ポリシーにより、メッセージが保存されるリージョンを制限できます。
ゾーンの停止: Pub/Sub メッセージが公開されると、そのメッセージはリージョン内の複数のゾーンのストレージに書き込まれます。したがって、1 つのゾーンが使用不能になっても、ユーザーに対する影響はありません。
リージョンの停止: リージョンが停止している間、そのリージョン内に保存されているメッセージにはアクセスできません。リージョン エンドポイントまたはグローバル エンドポイントを介して、影響を受けるリージョンに接続するパブリッシャーとサブスクライバーは接続できません。他のリージョンに接続するパブリッシャーとサブスクライバーは引き続き接続でき、他のリージョンで使用可能なメッセージは、容量のある最も近いネットワーク サブスクライバーに送信されます。
アプリケーションがメッセージの順序付けに依存している場合は、Pub/Sub チームからの詳細な推奨事項を確認してください。メッセージの順序指定はリージョンごとに保証され、グローバル エンドポイントを使用すると中断される可能性があります。
reCAPTCHA
reCAPTCHA は、不正行為、スパム、不正使用を検出するグローバル サービスです。リージョンまたはゾーンの復元性を構成する必要はなく、構成することもできません。構成メタデータの更新は、reCAPTCHA が実行される各リージョンに非同期で複製されます。
ゾーンが停止しても、reCAPTCHA は、同じまたは異なるリージョンの別のゾーンからのリクエストを中断なく処理します。
リージョンが停止した場合、reCAPTCHA は別のリージョンからのリクエストを中断なく処理します。
Secret Manager
Secret Manager は、Google Cloud のシークレットおよび認証情報管理プロダクトです。Secret Manager を使用すると、シークレットへのアクセスを簡単に監査、制限して、保存シークレットを暗号化し、Google Cloud にある機密情報を確実に保護できます。
通常、Secret Manager のリソースは、自動レプリケーション ポリシーを使用して作成される(推奨)ため、グローバルに複製されます。組織のポリシーにシークレット データのグローバル レプリケーションを許可しないポリシーがある場合、ユーザーが管理するレプリケーション ポリシー(1 つ以上のリージョンがシークレットの複製先として選択されます)を使用して Secret Manager リソースを作成できます。
ゾーンの停止: ゾーンが停止した場合、Secret Manager は、同じまたは異なるリージョンにある別のゾーンからのリクエストを中断なく処理し続けます。各リージョン内では、Secret Manager が、異なるゾーンに少なくとも 2 つのレプリカ(ほとんどのリージョンで 3 つのレプリカ)を常に維持します。ゾーンが停止から復旧すると、完全な冗長性が復元されます。
リージョンの停止: リージョンが停止しても、Secret Manager は別のリージョンからのリクエストを中断なく処理します。データが複数のリージョンに複製されていることを前提としています。(自動レプリケーション、または複数のリージョンへのユーザー管理のレプリケーション)。リージョンが停止から復旧すると、完全な冗長性が復元されます。
Security Command Center
Security Command Center は、Google Cloud のグローバルでリアルタイムのリスク管理プラットフォームです。検出機能と検出結果の 2 つの主要コンポーネントで構成されています。
検出機能は、リージョン停止とゾーン停止の両方からさまざまな影響を受けます。リージョンの停止中、検出機能は、スキャン対象のリソースが利用できないため、リージョン リソースの新しい検出結果を生成できません。
ゾーンが停止していると、検出機能が通常の動作を再開するまで数分から数時間かかることがあります。Security Command Center が検出結果データを失うことはありません。 また、使用できないリソースに対して新しい検出結果データが生成されることはありません。最悪のシナリオでは、Container Threat Detection エージェントが正常なセルへの接続中にバッファ領域を使い切り、検出結果が失われる可能性があります。
検出結果はリージョン間で同期的に複製されるため、リージョン停止とゾーン停止の両方に対して耐障害性があります。
Sensitive Data Protection(DLP API を含む)
Sensitive Data Protection は、センシティブ データの分類、プロファイリング、匿名化、トークン化、プライバシー リスク分析サービスを提供します。これは、リクエスト本文で送信されたデータに対して同期的に動作するか、クラウド ストレージ システムにすでに存在するデータに対して非同期で動作します。Sensitive Data Protection は、グローバルまたはリージョンに固有のエンドポイントを介して呼び出すことができます。
グローバル エンドポイント: サービスは、リージョン障害とゾーン障害の両方に対して耐障害性があるように設計されています。障害発生中にサービスが過負荷状態になると、サービスの hybridInspect メソッドに送信されたデータが失われる可能性があります。
耐障害性アーキテクチャを作成するには、hybridInspect メソッドによって生成された最新の障害発生前の検出結果を調べるロジックを組み込みます。停止した場合、メソッドに送信されたデータは失われる可能性がありますが、それは障害イベントが発生する前の最後の 10 分以内のものです。停止が始まる 10 分前よりも新しい検出結果がある場合、その検出結果の原因となったデータが失われていないことを示します。この場合、10 分以内であっても、検出結果のタイムスタンプよりも前に収集されたデータを再処理する必要はありません。
リージョン エンドポイント: リージョン エンドポイントには、リージョンの障害に対する耐障害性がありません。リージョンの障害に対する耐障害性が必要な場合は、他のリージョンへのフェイルオーバーを検討してください。ゾーン障害の特性は上記と同じです。
Service Usage
Service Usage API は、Google Cloud のインフラストラクチャ サービスであり、Google Cloud プロジェクトの API とサービスを一覧表示、管理できます。Google、Google Cloud、サードパーティのプロデューサーが提供する API とサービスを一覧表示して管理できます。Service Usage API はグローバル サービスであり、ゾーン停止とリージョン停止の両方に対する耐障害性があります。ゾーンまたはリージョンが停止した場合、Service Usage API は、異なるリージョンにわたる別のゾーンからのリクエストを引き続き処理します。
Service Usage の詳細については、Service Usage のドキュメントをご覧ください。
Speech-to-Text
Speech-to-Text では、ニューラル ネットワーク モデルなどの機械学習技術を使用して、音声をテキストに変換できます。音声は、アプリケーションのマイクからリアルタイムで送信されるか、音声ファイルのバッチとして処理されます。
ゾーンの停止:
Speech-to-Text API v1: ゾーンが停止しても、Speech-to-Text API バージョン 1 は中断することなく、同じリージョン内の別のゾーンからのリクエストを引き続き処理します。ただし、障害が発生したゾーン内で現在実行中のジョブはすべて失われます。失敗したジョブは再試行する必要がありますが、利用可能なゾーンに自動的にルーティングされます。
Speech-to-Text API v2: ゾーンが停止しても、Speech-to-Text API バージョン 2 は引き続き、同じリージョン内の別のゾーンからのリクエストを処理します。ただし、障害が発生したゾーン内で現在実行中のジョブはすべて失われます。失敗したジョブは再試行する必要がありますが、利用可能なゾーンに自動的にルーティングされます。Speech-to-Text API は、データがリージョン内のクォーラムに commit されると API 呼び出しを返します。一部のリージョンでは、AI アクセラレータ(TPU)は 1 つのゾーンでのみ使用できます。この場合、そのゾーンで停止が発生すると音声認識は失敗しますが、データは失われません。
リージョンの停止:
Speech-to-Text API v1: Speech-to-Text API バージョン 1 はグローバルなマルチリージョン サービスであるため、リージョンの障害の影響を受けません。サービスは、別のリージョンからのリクエストを中断なく処理し続けます。ただし、障害が発生したリージョン内で現在実行中のジョブは失われます。失敗したジョブは再試行する必要がありますが、利用可能なリージョンに自動的にルーティングされます。
Speech-to-Text API v2:
マルチリージョン Speech-to-Text API バージョン 2 の場合、サービスは中断することなく、同じリージョン内の別のゾーンからのリクエストを引き続き処理します。
単一リージョンの Speech-to-Text API バージョン 2 の場合、サービスはジョブの実行をリクエストされたリージョンに限定します。Speech-to-Text API バージョン 2 では、トラフィックは別のリージョンにルーティングされません。また、データが別のリージョンに複製されることもありません。リージョン障害が発生している間は、そのリージョンでは Speech-to-Text API バージョン 2 を使用できません。ただし、停止から復旧すると再び使用できるようになります。
Storage Transfer Service
Storage Transfer Service は、さまざまなクラウドソースから Cloud Storage へのデータ転送のほか、ファイル システム間のデータ転送を管理します。
Storage Transfer Service API はグローバル リソースです。
Storage Transfer Service は、転送の転送元と転送先の可用性によって異なります。転送元または転送先が使用できない場合、転送は処理を停止します。ただし、お客様のコアデータやジョブデータは失われません。転送元と転送先が再び使用可能になると、転送が再開されます。
Storage Transfer Service は、次のように、エージェントの有無にかかわらず使用できます。
エージェントレス転送では、リージョン ワーカーを使用して転送ジョブをオーケストレートします。
エージェント ベースの転送では、インフラストラクチャにインストールされているソフトウェア エージェントを使用します。エージェント ベースの転送は、転送エージェントの可用性と、エージェントがファイル システムに接続できるかどうかに依存します。転送エージェントをインストールする場所を決定するときは、ファイル システムの可用性を考慮してください。たとえば、複数の Compute Engine VM で転送エージェントを実行し、Enterprise 階層の Filestore インスタンス(リージョン リソース)にデータを転送する場合は、VM をFilestore インスタンスのリージョン内の複数のゾーンに配置することを検討してください。
エージェントが利用できなくなった場合、またはファイル システムへの接続が中断された場合は、転送は停止しますが、データは失われません。すべてのエージェント プロセスが終了すると、新しいエージェントが転送のエージェント プールに追加されるまで、転送ジョブは一時停止されます。
停止中の Storage Transfer Service の動作は次のとおりです。
ゾーンの停止: ゾーンが停止しても、Storage Transfer Service API は引き続き使用でき、転送ジョブの作成を続行できます。データは転送され続けます。
リージョンの停止: リージョンが停止しても、Storage Transfer Service API は引き続き使用でき、転送ジョブの作成を続行できます。転送のワーカーが影響を受けるリージョンにある場合、リージョンが再び使用可能になり、転送が自動的に再開するまでデータ転送は停止します。
Vertex ML Metadata
Vertex ML Metadata を使用すると、ML システムによって生成されたメタデータとアーティファクトを記録し、そのメタデータに対してクエリを実行できます。これにより、ML システムまたはアーティファクトの生成状況の分析、デバッグ、監査を行うことができます。
ゾーンの停止: デフォルトの構成では、Vertex ML Metadata はゾーン障害から保護します。サービスは各リージョンの複数のゾーンにデプロイされ、データを各リージョン内のさまざまなゾーンに同期して複製します。ゾーンに障害が発生した場合、残りのゾーンが最小限の中断で引き継ぎます。
リージョンの停止: Vertex ML Metadata はリージョン サービスです。リージョンが停止した場合、Vertex ML Metadata は別のリージョンにフェイルオーバーしません。
Vertex AI バッチ予測
バッチ予測を使用すると、Google のインフラストラクチャで AI / ML モデルに対してバッチ予測を実行できます。バッチ予測はリージョン サービスです。ジョブを実行するリージョンは選択できますが、そのリージョン内の特定のゾーンを選択することはできません。バッチ予測サービスは、選択したリージョン内のさまざまなゾーン間でジョブを自動的にロードバランシングします。
ゾーンの停止: バッチ予測により、リージョン内のバッチ予測ジョブのメタデータが保存されます。データは、リージョン内の複数のゾーンに同期して書き込まれます。ゾーンの停止が発生すると、バッチ予測はジョブを実行するワーカーを一部失いますが、それらは他の利用可能なゾーンに自動的に追加されます。複数のバッチ予測の再試行が失敗した場合、UI と API 呼び出しリクエストでジョブのステータスが失敗として表示されます。ジョブの実行を求める後続のユーザー リクエストは、使用可能なゾーンに転送されます。
リージョンの停止: お客様は、バッチ予測ジョブを実行する Google Cloud リージョンを選択します。データがリージョン間で複製されることはありません。バッチ予測は、ジョブ実行のスコープをリクエストされたリージョンに設定します。予測リクエストを別のリージョンに転送することはありません。リージョン障害が発生すると、そのリージョンではバッチ予測を使用できなくなります。停止が解消されると、再び使用できるようになります。お客様には、複数のリージョンを使用してジョブを実行することをおすすめします。リージョンの停止が発生した場合は、ジョブを利用可能な別のリージョンに転送します。
Vertex AI Model Registry
Vertex AI Model Registry を使用すると、モデルの管理、ガバナンス、中央リポジトリでの ML モデルのデプロイを合理化できます。Vertex AI Model Registry は高可用性を備えたリージョン サービスであり、ゾーンの停止から保護します。
ゾーンの停止: Vertex AI Model Registry は、ゾーンの停止から保護します。サービスは各リージョンの 3 つのゾーンにデプロイされ、リージョン内のさまざまなゾーンに同期的にデータを複製します。あるゾーンで障害が発生しても、残りのゾーンが引き継ぐので、データ損失は発生せず、サービスの中断は最小限に抑えられます。
リージョンの停止: Vertex AI Model Registry はリージョン サービスです。リージョンに障害が発生しても、Model Registry はフェイルオーバーしません。
Vertex AI オンライン予測
オンライン予測を使用すると、Google Cloud に AI / ML モデルをデプロイできます。オンライン予測はリージョン サービスです。モデルをデプロイするリージョンは選択できますが、そのリージョン内の特定のゾーンは選択できません。予測サービスは、選択したリージョン内のさまざまなゾーン間でワークロードを自動的にロード バランシングします。
ゾーン停止: オンライン予測では、顧客のコンテンツは保存されません。ゾーンが停止すると、現在の予測リクエスト実行が失敗します。オンライン予測では、使用されているエンドポイントの種類に応じて、予測リクエストが自動的に再試行される場合があります。具体的には、パブリック エンドポイントは自動的に再試行されますが、プライベート エンドポイントは再試行されません。障害を処理し、耐障性を高めるために、指数バックオフを使用した再試行ロジックをコードに組み込みます。
リージョンの停止: お客様は、AI / ML モデルとオンライン予測サービスを実行する Google Cloud リージョンを選択します。データがリージョン間で複製されることはありません。オンライン予測は、AI / ML モデルの実行をリクエストされたリージョンにスコープします。予測リクエストを別のリージョンに転送することはありません。リージョン障害が発生すると、そのリージョンではオンライン予測サービスを使用できなくなります。停止から復旧すると再び使用できるようになります。AI / ML モデルの実行には、複数のリージョンを使用することをおすすめします。リージョンの停止が発生した場合は、トラフィックを別の利用可能なリージョンに転送します。
Vertex AI Pipelines
Vertex AI Pipelines は、サーバーレス方式で機械学習(ML)ワークフローの自動化、モニタリング、管理を行うことができる Vertex AI サービスです。Vertex AI Pipelines は高可用性を実現するように構築されており、ゾーン障害に対する保護を提供します。
ゾーンの停止: デフォルトの構成では、Vertex AI Pipelines はゾーン障害から保護します。サービスは各リージョンの複数のゾーンにデプロイされ、リージョン内のさまざまなゾーンに同期してデータを複製します。ゾーンに障害が発生した場合、残りのゾーンが最小限の中断で引き継ぎます。
リージョンの停止: Vertex AI Pipelines はリージョン サービスです。リージョンが停止した場合、Vertex AI Pipelines は別のリージョンにフェイルオーバーしません。リージョンの停止が発生した場合は、バックアップ リージョンでパイプライン ジョブを実行することをおすすめします。
Vertex AI Search
Vertex AI Search は、生成 AI 機能とネイティブの企業コンプライアンスを備えた、カスタマイズ可能な検索ソリューションです。Vertex AI Search は、Google Cloud 内の複数のリージョンに自動的にデプロイされ、複製されます。グローバル、米国、EU など、サポートされているマルチリージョンを選択することで、データの保存場所を構成できます。
ゾーンとリージョンの停止: Vertex AI Search にアップロードされた UserEvents は、非同期レプリケーションの遅延により復元できない場合があります。Vertex AI Search が提供する他のデータとサービスは、自動フェイルオーバーと同期データ レプリケーションにより、引き続き使用できます。
Vertex AI Training
Vertex AI Training を使用すると、Google のインフラストラクチャでカスタム トレーニング ジョブを実行できます。Vertex AI Training はリージョン サービスです。つまり、お客様はトレーニング ジョブを実行するリージョンを選択できます。ただし、そのリージョン内の特定のゾーンを選択することはできません。トレーニング サービスは、リージョン内のさまざまなゾーンにわたってジョブ実行を自動的に負荷分散できます。
ゾーンの停止: Vertex AI Training は、カスタム トレーニング ジョブのメタデータを保存します。このデータはリージョンに保存され、同期的に書き込まれます。このメタデータがリージョン内のクォーラムに commit されると、Vertex AI Training API 呼び出しが返されます。トレーニング ジョブは特定のゾーンで実行される場合があります。ゾーンが停止すると、現在のジョブ実行が失敗します。その場合、サービスはそのジョブを別のゾーンにルーティングして、自動的に再試行します。再試行が複数回失敗すると、ジョブ ステータスは失敗に更新されます。ジョブの実行を求める後続のユーザー リクエストは、使用可能なゾーンにルーティングされます。
リージョンの停止: お客様は、トレーニング ジョブを実行する Google Cloud リージョンを選択します。データがリージョン間で複製されることはありません。Vertex AI Training は、ジョブ実行のスコープをリクエストされたリージョンに設定します。トレーニング ジョブを別のリージョンにルーティングすることはありません。リージョン障害の場合、そのリージョンで Vertex AI Training サービスが使用できなくなり、停止から復旧すると再び使用できるようになります。複数のリージョンを使用してジョブを実行し、1 つのリージョンが停止した場合にはジョブを利用可能な別のリージョンに転送することをおすすめします。
Virtual Private Cloud(VPC)
VPC は、リソース(VM など)へのネットワーク接続を提供するグローバル サービスです。ただし、障害はゾーン単位です。ゾーンに障害が発生した場合、そのゾーンのリソースは使用できなくなります。同様に、リージョンで障害が発生した場合、障害が発生したリージョンとの間のトラフィックのみに影響します。正常なリージョンの接続は影響を受けません。
ゾーンの停止: VPC ネットワークが複数のゾーンをカバーしている場合、1 つのゾーンで障害が発生しても、VPC ネットワークは正常なゾーンで正常に機能を続けます。正常なゾーン内のリソース間のネットワーク トラフィックは、障害発生中も通常どおり機能します。ゾーン障害は、障害が発生したゾーンのリソースとの間のネットワーク トラフィックにのみ影響します。ゾーン障害の影響を軽減するため、すべてのリソースを単一のゾーンに作成しないことをおすすめします。代わりに、リソースの作成時には、ゾーン間で分散してください。
リージョンの停止: VPC ネットワークが複数のリージョンをカバーしている場合、1 つのリージョンで障害が発生しても、VPC ネットワークは正常なリージョンで正常に機能を続けます。正常なリージョン内のリソース間のネットワーク トラフィックは、障害発生中も通常どおり機能します。リージョン障害は、障害が発生したリージョンのリソースとの間のネットワーク トラフィックにのみ影響します。リージョン障害の影響を軽減するために、リソースを複数のリージョンに分散することをおすすめします。
VPC Service Controls
VPC Service Controls はリージョン サービスです。VPC Service Controls を使用すると、セキュリティ チームは境界制御をきめ細かく定義して、そのセキュリティ方針を多様な Google Cloud サービスやプロジェクトに強制適用できます。お客様のポリシーはリージョン内でミラーリングされます。
ゾーンの停止: VPC Service Controls は、中断することなく、同じリージョン内の別のゾーンからのリクエストを処理します。
リージョンの停止: 影響を受けるリージョンに VPC Service Controls ポリシーを適用するように構成された API は、リージョンが再び使用可能になるまで使用できません。高可用性が必要な場合は、VPC Service Controls が適用されたサービスを複数のリージョンにデプロイすることをおすすめします。
Workflows
Workflows は、Google Cloud のお客様が次のことを行えるようにするオーケストレーション プロダクトです。
- HTTP を使用して他の既存のサービスを接続するワークフローをデプロイして実行する
- プロセスを自動化する(HTTP レスポンスで最大 1 年間の自動再試行の待機を含む)
- 低レイテンシのイベント ドリブンで実行されるリアルタイム処理を実装する
Workflows のお客様は、実行するビジネス ロジックを記述するワークフローをデプロイし、API で直接またはイベント ドリブンのトリガー(現在は Pub/Sub または Eventarc のみ)でワークフローを実行できます。実行されるワークフローでは、変数の操作、HTTP 呼び出しの実行と結果の保存、コールバックの定義、別のサービスによる再開の待機を行えます。
ゾーンの停止: Workflows のソースコードはゾーンの停止の影響を受けません。Workflows には、ワークフローのソースコードと、実行中のワークフローによって受信される変数の値と HTTP レスポンスが保存されます。ソースコードはリージョンに保存され、同期的に書き込まれます。このメタデータがリージョン内のクォーラムに commit されると、コントロール プレーン API が返されます。変数と HTTP の結果もリージョンに保存され、少なくとも 5 秒ごとに同期的に書き込まれます。
ゾーンで障害が発生した場合、Workflows は最後に保存されたデータに基づいて自動的に再開されます。ただし、レスポンスをまだ受信していない HTTP リクエストは自動的に再試行されません。ドキュメントで説明されているように、安全に再試行できるリクエストには再試行ポリシーを使用します。
リージョンの停止: Workflows はリージョン サービスです。リージョンが停止しても Workflows はフェイルオーバーしません。高可用性が必要な場合は、Workflows を複数のリージョンにデプロイすることをおすすめします。
Cloud Service Mesh
Cloud Service Mesh を使用すると、複数の GKE クラスタにまたがるマネージド サービス メッシュを構成できます。このドキュメントは、マネージド Cloud Service Mesh のみを対象としています。クラスタ内のバリアントはセルフホストされているため、通常のプラットフォーム ガイドラインに従う必要があります。
ゾーンの停止: メッシュ構成は GKE クラスタに保存されているため、クラスタがリージョンである限り、ゾーンの停止に対する耐障害性があります。プロダクトが社内簿記に使用するデータは、リージョンまたはグローバルに保存され、シングル ゾーンが停止しても影響を受けません。コントロール プレーンは、サポートする GKE クラスタと同じリージョン(ゾーンクラスタの場合は、含まれるリージョン)で実行され、シングルゾーン内の停止の影響は受けません。
リージョンの停止: Cloud Service Mesh は、リージョン クラスタまたはゾーンクラスタである GKE クラスタにサービスを提供します。リージョンが停止した場合、Cloud Service Mesh はフェイルオーバーしません。GKE もフェイルオーバーしません。 さまざまなリージョンを対象とする GKE クラスタで構成されるメッシュをデプロイすることをおすすめします。
Service Directory
Service Directory は、サービスを検出、公開、接続するためのプラットフォームです。すべてのサービスのリアルタイム情報を 1 か所で提供します。Service Directory を使用すると、サービス エンドポイントの数に関係なく、大規模なサービス インベントリ管理を実行できます。
ユーザーが指定した location パラメータに一致する Service Directory リソースが、リージョン単位で作成されます。
ゾーンの停止: ゾーンが停止しても、Service Directory は、中断することなく、同じリージョンまたは別のリージョン内の別のゾーンからのリクエストを処理します。各リージョン内では、Service Directory が常に複数のレプリカを維持します。ゾーンの停止から復旧すると、完全な冗長性が復元されます。
リージョンの停止: Service Directory には、リージョンの停止に対する耐障害性がありません。