Ce document explique comment déployer l'architecture sur la page Utiliser un pipeline CI/CD pour les workflows de traitement des données.
Ce déploiement est destiné aux data scientists et aux analystes qui créent et exécutent des tâches récurrentes de traitement des données afin de structurer leurs activités de recherche et développement (R&D), et de gérer de manière systématique et automatique les charges de travail de traitement des données.
Les data scientists et les analystes peuvent adapter les méthodologies mises en œuvre dans les pratiques CI/CD pour garantir la haute qualité, la facilité de gestion et l'adaptabilité des processus de données et des workflows. Vous pouvez appliquer les méthodes suivantes :
- Contrôle des versions du code source
- Création, test et déploiement automatiques d'applications
- Isolation et séparation des environnements de développement et de test de l'environnement de production
- Procédures reproductibles pour la configuration des environnements
Architecture
Le schéma suivant présente une vue détaillée des étapes du pipeline CI/CD pour le pipeline de test et le pipeline de production.

Dans le schéma précédent, le pipeline de test commence lorsqu'un développeur valide le code dans Cloud Source Repositories et se termine une fois le test d'intégration du workflow de traitement des données terminé. À ce stade, le pipeline publie dans Pub/Sub un message qui contient une référence au dernier fichier JAR (Java Archive) auto-exécutable (obtenu à partir des variables Airflow) dans le champ de données du message.
Dans le schéma précédent, le pipeline de production commence lorsqu'un message est publié dans un sujet Pub/Sub et se termine lorsque le fichier DAG du workflow de production est déployé dans Cloud Composer.
Dans ce guide de déploiement, vous allez utiliser les produits Google Cloud suivants :
- Cloud Build, pour développer un pipeline CI/CD afin de créer, déployer et tester un workflow de traitement des données, et effectuer le traitement des données. Cloud Build est un service géré qui exécute votre build sur Google Cloud sous la forme d'une série d'étapes de compilation où chaque étape est exécutée dans un conteneur Docker.
- Cloud Composer, pour définir et exécuter les étapes du workflow, telles que le démarrage du traitement des données, le test et la vérification des résultats. Cloud Composer est un service géré basé sur Apache Airflow qui offre un environnement dans lequel vous pouvez créer, planifier, surveiller et gérer des workflows complexes, tels que le workflow de traitement des données développé dans ce déploiement.
- Cloud Dataflow pour exécuter l'exemple Apache Beam WordCount comme exemple de traitement des données.
Objectifs
- Configurer l'environnement Cloud Composer
- Créer des buckets Cloud Storage pour vos données
- Créer les pipelines de compilation, de test et de production
- Configurer le déclencheur de compilation
Optimisation des coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Avant de commencer
Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
Vérifiez que la facturation est activée pour votre projet Google Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Exemple de code
L'exemple de code pour ce déploiement se trouve dans deux dossiers:
- Le dossier
env-setupcontient des scripts shell pour la configuration initiale de l'environnement Google Cloud. Le dossier
source-codecontient du code qui est développé au fil du temps, qui doit être contrôlé par la source et déclenche des processus automatiques de compilation et de test. Ce dossier contient les sous-dossiers suivants :- Le dossier
data-processing-codecontient le code source du processus Apache Beam. - Le dossier
workflow-dagcontient les définitions DAG de Cloud Composer pour les workflows de traitement des données, ainsi que les étapes de conception, de mise en œuvre et de test du processus Cloud Dataflow. - Le dossier
build-pipelinecontient deux configurations Cloud Build, l'une pour le pipeline de test et l'autre pour le pipeline de production. Ce dossier contient également un script d'assistance pour les pipelines.
- Le dossier
Dans le cadre de ce déploiement, les fichiers de code source pour le traitement des données et pour le workflow DAG se trouvent dans des dossiers différents du même dépôt de code source. Dans un environnement de production, les fichiers de code source se trouvent généralement dans leurs propres dépôts de code source, et sont gérés par des équipes différentes.
Intégration et tests unitaires
Outre le test d'intégration qui vérifie le workflow de traitement des données de bout en bout, ce déploiement comporte deux tests unitaires. Les tests unitaires sont des tests automatiques exécutés sur le code de traitement des données et le code du workflow de traitement des données. Le test sur le code de traitement des données est écrit en Java et s'exécute automatiquement lors du processus de compilation Maven. Le test sur le code du workflow de traitement des données est écrit en Python et s'exécute en tant qu'étape de compilation indépendante.
Configurer votre environnement
Dans ce déploiement, vous allez exécuter toutes les commandes dans Cloud Shell. Cloud Shell apparaît sous la forme d'une fenêtre en bas de la console Google Cloud.
Dans Google Cloud Console, ouvrez Cloud Shell :
Clonez l'exemple de dépôt de code :
git clone https://github.com/GoogleCloudPlatform/ci-cd-for-data-processing-workflow.gitExécutez un script pour définir les variables d'environnement :
cd ~/ci-cd-for-data-processing-workflow/env-setup source set_env.shLe script définit les variables d'environnement suivantes :
- L'ID de votre projet Google Cloud
- Votre région et votre zone
- Le nom des buckets Cloud Storage utilisés par le pipeline de compilation et le workflow de traitement des données
Comme les variables d'environnement ne sont pas conservées entre les sessions, si votre session Cloud Shell se ferme ou se déconnecte pendant que vous suivez le déploiement, vous devez reconfigurer les variables d'environnement.
Créer l'environnement Cloud Composer
Dans ce déploiement, vous allez configurer un environnement Cloud Composer.
Dans Cloud Shell, ajoutez le rôle Extension de l'agent de service de l'API Cloud Composer v2 (
roles/composer.ServiceAgentV2Ext) au compte d'agent de service Cloud Composer:gcloud projects add-iam-policy-binding $GCP_PROJECT_ID \ --member serviceAccount:service-$PROJECT_NUMBER@cloudcomposer-accounts.iam.gserviceaccount.com \ --role roles/composer.ServiceAgentV2ExtDans Cloud Shell, créez l'environnement Cloud Composer :
gcloud composer environments create $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --image-version composer-2.0.14-airflow-2.2.5Exécutez un script pour définir les variables de l'environnement Cloud Composer. Les variables sont requises pour les DAG de traitement des données.
cd ~/ci-cd-for-data-processing-workflow/env-setup chmod +x set_composer_variables.sh ./set_composer_variables.shLe script définit les variables d'environnement suivantes :
- L'ID de votre projet Google Cloud
- Votre région et votre zone
- Le nom des buckets Cloud Storage utilisés par le pipeline de compilation et le workflow de traitement des données
Extraire les propriétés de l'environnement Cloud Composer
Cloud Composer utilise un bucket Cloud Storage pour stocker les DAG. Le déplacement d'un fichier de définition de DAG vers ce bucket déclenche la lecture automatique des fichiers par Cloud Composer. Vous avez créé le bucket Cloud Storage pour Cloud Composer lorsque vous avez créé l'environnement Cloud Composer. Dans la procédure suivante, vous allez extraire l'URL des buckets, puis configurer votre pipeline CI/CD pour déployer automatiquement les définitions de DAG dans le bucket Cloud Storage.
Dans Cloud Shell, exportez l'URL du bucket en tant que variable d'environnement :
export COMPOSER_DAG_BUCKET=$(gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.dagGcsPrefix)")Exportez le nom du compte de service utilisé par Cloud Composer pour accéder aux buckets Cloud Storage :
export COMPOSER_SERVICE_ACCOUNT=$(gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.nodeConfig.serviceAccount)")
Créer les buckets Cloud Storage
Dans cette section, vous allez créer un ensemble de buckets Cloud Storage pour stocker les éléments suivants :
- Artefacts des étapes intermédiaires du processus de compilation
- Fichiers d’entrée et de sortie du workflow de traitement des données
- Emplacement de préproduction des tâches Cloud Dataflow dans lequel stocker leurs fichiers binaires
Pour créer les buckets Cloud Storage, procédez comme suit :
Dans Cloud Shell, créez des buckets Cloud Storage, et accordez au compte de service Cloud Composer l'autorisation d'exécuter les workflows de traitement des données :
cd ~/ci-cd-for-data-processing-workflow/env-setup chmod +x create_buckets.sh ./create_buckets.sh
Créer le sujet Pub/Sub
Dans cette section, vous allez créer un sujet Pub/Sub destiné à recevoir les messages envoyés depuis le test d'intégration du workflow de traitement des données afin de déclencher automatiquement le pipeline de compilation en production.
Dans la console Google Cloud, accédez à la page Sujets Pub/Sub.
Cliquez sur Créer un sujet.
Pour configurer le sujet, procédez comme suit :
- Pour l'ID du sujet, saisissez
integration-test-complete-topic. - Vérifiez que l'option Ajouter un abonnement par défaut est cochée.
- Laissez les autres options décochées.
- Dans le champ Chiffrement, sélectionnez Clé de chiffrement gérée par Google.
- Cliquez sur Créer un sujet.
- Pour l'ID du sujet, saisissez
Transférer le code source vers Cloud Source Repositories
Dans ce déploiement, vous disposez d'un codebase source que vous devez intégrer au contrôle des versions. L'étape suivante montre comment un codebase est développé et évolue au fil du temps. Chaque envoi de modifications dans le dépôt déclenche le pipeline de compilation, de déploiement et de test.
Dans Cloud Shell, placez le dossier
source-codedans Cloud Source Repositories :gcloud source repos create $SOURCE_CODE_REPO cp -r ~/ci-cd-for-data-processing-workflow/source-code ~/$SOURCE_CODE_REPO cd ~/$SOURCE_CODE_REPO git init git remote add google \ https://source.developers.google.com/p/$GCP_PROJECT_ID/r/$SOURCE_CODE_REPO git add . git commit -m 'initial commit' git push google masterIl s'agit de commandes standards permettant d'initialiser Git dans un nouveau répertoire et de transférer le contenu vers un dépôt distant.
Créer des pipelines Cloud Build
Dans cette section, vous allez créer les pipelines de compilation qui créent, déploient et testent le workflow de traitement des données.
Accorder l'accès au compte de service Cloud Build
Cloud Build déploie des DAG Cloud Composer et déclenche des workflows, qui sont activés lorsque vous ajoutez un accès supplémentaire au compte de service Cloud Build. Pour en savoir plus sur les différents rôles disponibles lorsque vous utilisez Cloud Composer, consultez la documentation sur le contrôle des accès.
Dans Cloud Shell, ajoutez le rôle
composer.adminau compte de service Cloud Build afin que la tâche Cloud Build puisse définir des variables Airflow dans Cloud Composer :gcloud projects add-iam-policy-binding $GCP_PROJECT_ID \ --member=serviceAccount:$PROJECT_NUMBER@cloudbuild.gserviceaccount.com \ --role=roles/composer.adminAjoutez le rôle
composer.workerau compte de service Cloud Build afin que la tâche Cloud Build puisse déclencher le workflow de données dans Cloud Composer :gcloud projects add-iam-policy-binding $GCP_PROJECT_ID \ --member=serviceAccount:$PROJECT_NUMBER@cloudbuild.gserviceaccount.com \ --role=roles/composer.worker
Créer le pipeline de compilation et de test
Les étapes du pipeline de compilation et de test sont configurées dans le fichier de configuration YAML.
Dans ce déploiement, vous allez utiliser les images de compilateur précompilées pour git, maven, gsutil et gcloud afin d'exécuter les tâches de chaque étape de compilation.
Vous allez utiliser des substitutions de variables de configuration pour définir les paramètres d'environnement au moment de la compilation. L'emplacement du dépôt contenant le code source est défini par les substitutions de variables, ainsi que par l'emplacement des buckets Cloud Storage. La compilation a besoin de ces informations pour déployer le fichier JAR, les fichiers de test et la définition du DAG.
Dans Cloud Shell, envoyez le fichier de configuration du pipeline de compilation pour créer le pipeline dans Cloud Build :
cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline gcloud builds submit --config=build_deploy_test.yaml --substitutions=\ REPO_NAME=$SOURCE_CODE_REPO,\ _DATAFLOW_JAR_BUCKET=$DATAFLOW_JAR_BUCKET_TEST,\ _COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_TEST,\ _COMPOSER_REF_BUCKET=$REF_BUCKET_TEST,\ _COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\ _COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\ _COMPOSER_REGION=$COMPOSER_REGION,\ _COMPOSER_DAG_NAME_TEST=$COMPOSER_DAG_NAME_TESTCette commande indique à Cloud Build d’exécuter une compilation selon la procédure suivante :
Créer et déployer le fichier JAR WordCount auto-exécutable.
- Vérifier le code source.
- Compiler le code source Beam WordCount dans un fichier JAR auto-exécutable.
- Stocker le fichier JAR sur Cloud Storage où il peut être sélectionné par Cloud Composer pour exécuter la tâche de traitement WordCount.
Déployer et configurer le workflow de traitement des données sur Cloud Composer.
- Exécuter le test unitaire sur le code opérateur personnalisé utilisé par le DAG du workflow.
- Déployer le fichier d'entrée du test et le fichier de référence du test sur Cloud Storage. Le fichier d'entrée du test contient les données d'entrée de la tâche de traitement WordCount. Le fichier de référence du test sert de référence pour vérifier le résultat de la tâche de traitement WordCount.
- Définir les variables Cloud Composer de sorte qu'elles pointent vers le fichier JAR qui vient d'être créé.
- Déployer la définition du DAG du workflow dans l'environnement Cloud Composer.
Pour déclencher le workflow de traitement de test, exécutez le workflow de traitement de données dans l'environnement de test.
Vérifier le pipeline de compilation et de test
Après avoir envoyé le fichier de compilation, vérifiez les étapes de compilation.
Dans la console Google Cloud, accédez à la page Historique de compilation pour afficher la liste de toutes les compilations précédentes et en cours d'exécution.
Cliquez sur la version en cours d'exécution.
Sur la page Informations sur le build, vérifiez que les étapes de compilation correspondent aux étapes décrites précédemment.
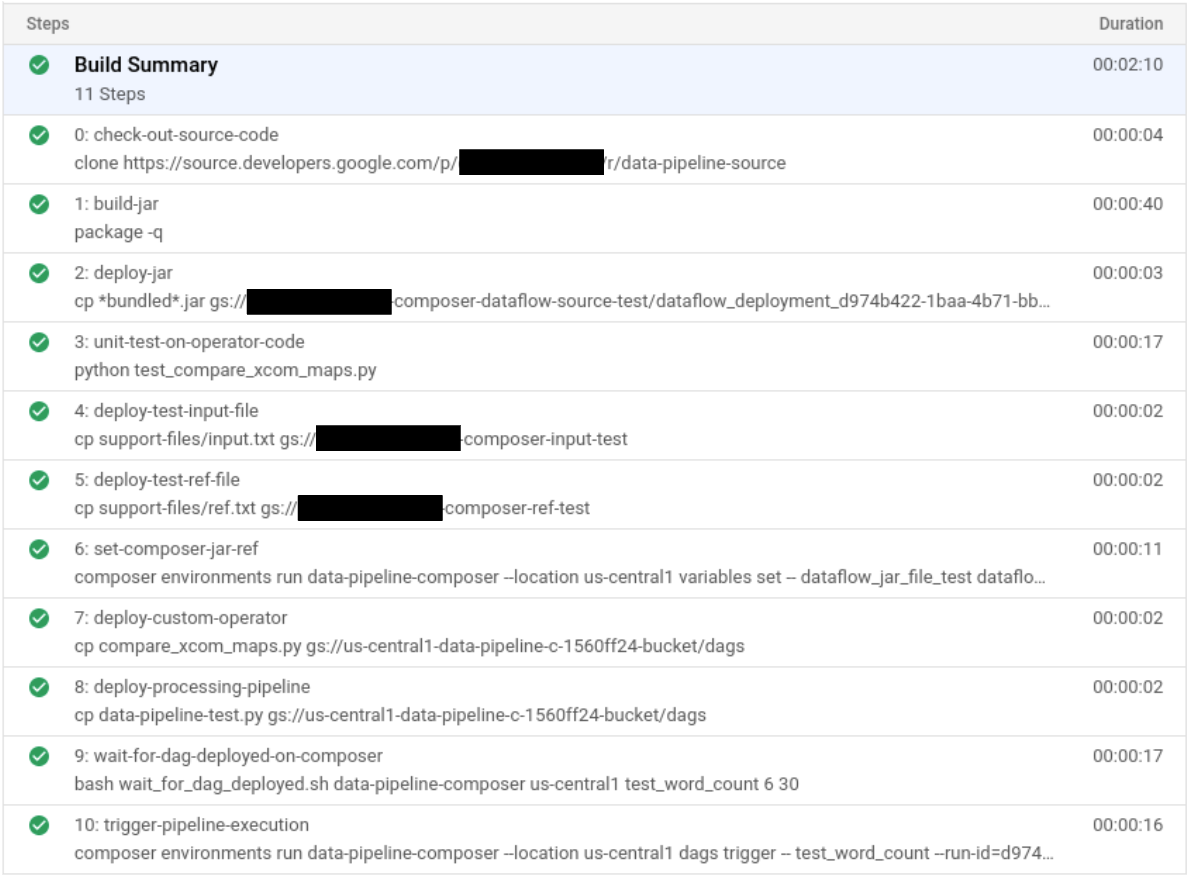
Sur la page Informations sur le build, le champ État du build indique
Build successfullorsque la compilation est terminée.Dans Cloud Shell, vérifiez que le fichier JAR de l'exemple WordCount a été copié dans le bucket approprié :
gsutil ls gs://$DATAFLOW_JAR_BUCKET_TEST/dataflow_deployment*.jarLe résultat ressemble à ce qui suit :
gs://…-composer-dataflow-source-test/dataflow_deployment_e88be61e-50a6-4aa0-beac-38d75871757e.jar
Obtenez l'URL de votre interface Web Cloud Composer. Notez-la car elle sera utilisée à l'étape suivante.
gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.airflowUri)"Utilisez l'URL de l'étape précédente pour accéder à l'interface utilisateur de Cloud Composer afin de vérifier que le DAG s'est exécuté avec succès. Si la colonne Runs (Exécutions) n’affiche aucune information, attendez quelques minutes et actualisez la page.
Pour vérifier que le DAG du workflow de traitement des données (
test_word_count) est déployé et en mode d'exécution, maintenez le pointeur sur le cercle vert clair situé en dessous de Runs (Exécutions) et vérifiez qu'il affiche En cours d'exécution.Pour afficher le workflow de traitement des données sous forme de graphique, cliquez sur le cercle vert clair, puis sur la page DAG Runs (Exécutions DAG), cliquez sur ID du DAG :
test_word_count.Actualisez la page Graph View (Vue graphique) pour mettre à jour l'état d'exécution du DAG en cours. L'exécution du workflow prend généralement entre trois et cinq minutes. Pour vérifier que l'exécution du DAG a bien été effectuée, maintenez le pointeur sur chaque tâche pour vérifier que l'info-bulle indique State: success (État : Opération réussie). L'avant-dernière tâche, appelée
do_comparison, correspond au test d'intégration qui vérifie le résultat du processus par rapport au fichier de référence.
Une fois le test d'intégration terminé, la dernière tâche, appelée
publish_test_complete, publie un message dans le sujet Pub/Subintegration-test-complete-topic, qui sera utilisé pour déclencher le pipeline de compilation en production.Pour vérifier que le message publié contient la référence correcte au dernier fichier JAR, nous pouvons extraire le message de l'abonnement Pub/Sub
integration-test-complete-topic-subpar défaut.Dans la console Google Cloud, accédez à la page Abonnements.
Cliquez sur integration-test-complete-topic-sub, sélectionnez l'onglet Message, puis cliquez sur Extraire.
Le résultat doit se présenter comme suit :

Créer le pipeline de production
Lorsque le workflow de traitement de test s'exécute avec succès, vous pouvez faire passer la version actuelle du workflow en production. Il existe plusieurs manières de déployer le workflow en production :
- Manuellement
- Par déclenchement automatique lorsque tous les tests sont concluants dans les environnements de test ou de prépoduction
- Par déclenchement automatique provoqué par une tâche planifiée
Dans ce déploiement, vous déclenchez automatiquement la compilation en production lorsque tous les tests sont concluants dans l'environnement de test. Pour en savoir plus sur les approches automatisées, consultez la page Ingénierie des versions.
Avant de mettre en œuvre l'approche automatisée, vous devez vérifier la compilation du déploiement de production en effectuant un déploiement manuel en production. La version de déploiement de production suit les étapes ci-dessous :
- Copier le fichier JAR WordCount à partir du bucket de test dans le bucket de production.
- Définir les variables Cloud Composer du workflow de production pour pointer vers le fichier JAR récemment passé en production.
- Déployer la définition du DAG du workflow de production dans l'environnement Cloud Composer et exécuter le workflow.
Les substitutions de variables définissent le nom du dernier fichier JAR déployé en production avec les buckets Cloud Storage utilisés par le workflow de traitement de production. Pour créer le pipeline Cloud Build qui déploie le workflow Airflow de production, procédez comme suit :
Dans Cloud Shell, lisez le nom du dernier fichier JAR en imprimant la variable Cloud Composer correspondant au nom du fichier JAR :
export DATAFLOW_JAR_FILE_LATEST=$(gcloud composer environments run $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION variables get -- \ dataflow_jar_file_test 2>&1 | grep -i '.jar')Utilisez le fichier de configuration du pipeline de compilation,
deploy_prod.yaml,, pour créer le pipeline dans Cloud Build :cd ~/ci-cd-for-data-processing-workflow/source-code/build-pipeline gcloud builds submit --config=deploy_prod.yaml --substitutions=\ REPO_NAME=$SOURCE_CODE_REPO,\ _DATAFLOW_JAR_BUCKET_TEST=$DATAFLOW_JAR_BUCKET_TEST,\ _DATAFLOW_JAR_FILE_LATEST=$DATAFLOW_JAR_FILE_LATEST,\ _DATAFLOW_JAR_BUCKET_PROD=$DATAFLOW_JAR_BUCKET_PROD,\ _COMPOSER_INPUT_BUCKET=$INPUT_BUCKET_PROD,\ _COMPOSER_ENV_NAME=$COMPOSER_ENV_NAME,\ _COMPOSER_REGION=$COMPOSER_REGION,\ _COMPOSER_DAG_BUCKET=$COMPOSER_DAG_BUCKET,\ _COMPOSER_DAG_NAME_PROD=$COMPOSER_DAG_NAME_PROD
Vérifier le workflow de traitement des données créé par le pipeline de production
Obtenez l'URL de votre interface utilisateur Cloud Composer :
gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION \ --format="get(config.airflowUri)"Pour vérifier que le DAG du workflow de production de traitement des données est déployé, accédez à l'URL que vous avez récupérée à l'étape précédente et vérifiez que le DAG
prod_word_countfigure dans la liste des DAG.- Sur la page des DAG, dans la ligne
prod_word_count, cliquez sur Trigger DAG (Déclencher le DAG).
- Sur la page des DAG, dans la ligne
Pour mettre à jour l'état d'exécution du DAG, cliquez sur le logo Airflow ou actualisez la page. Un cercle vert clair dans la colonne Exécutions indique que le DAG est en cours d'exécution.
Une fois l'exécution réussie, maintenez le pointeur sur le cercle vert foncé situé à côté de la colonne Exécutions DAG et vérifiez qu'il affiche l'état Opération réussie.
Dans Cloud Shell, répertoriez les fichiers de résultats dans le bucket Cloud Storage :
gsutil ls gs://$RESULT_BUCKET_PRODLe résultat ressemble à ce qui suit :
gs://…-composer-result-prod/output-00000-of-00003 gs://…-composer-result-prod/output-00001-of-00003 gs://…-composer-result-prod/output-00002-of-00003
Créer des déclencheurs Cloud Build
Dans cette section, vous allez créer le déclencheur Cloud Build qui lie les modifications du code source au processus de compilation de test et celui situé entre le pipeline de test et le pipeline de compilation en production.
Configurer le déclencheur du pipeline de compilation de test
Vous allez configurer un déclencheur Cloud Build qui déclenche une nouvelle compilation lorsque les modifications sont envoyées dans la branche principale du dépôt source.
Dans la console Google Cloud, accédez à la page Déclencheurs de compilation.
Cliquez sur Créer un déclencheur.
Pour configurer les paramètres du déclencheur, procédez comme suit :
- Dans le champ Nom, saisissez
trigger-build-in-test-environment. - Dans la liste déroulante Région, sélectionnez global (non régional).
- Pour Événement, cliquez sur Déployer sur une branche.
- Pour Source, sélectionnez
data-pipeline-source. - Dans le champ Nom de la branche, saisissez
master. - Pour le champ Configuration, cliquez sur Fichier de configuration Cloud Build (yaml ou json).
- Pour le champ Emplacement, cliquez sur Dépôt.
- Dans le champ Emplacement du fichier de configuration Cloud Build, saisissez
build-pipeline/build_deploy_test.yaml.
- Dans le champ Nom, saisissez
Dans Cloud Shell, exécutez la commande suivante pour obtenir toutes les variables de substitution nécessaires à la compilation. Notez ces valeurs car vous en aurez besoin ultérieurement.
echo "_COMPOSER_DAG_BUCKET : ${COMPOSER_DAG_BUCKET} _COMPOSER_DAG_NAME_TEST : ${COMPOSER_DAG_NAME_TEST} _COMPOSER_ENV_NAME : ${COMPOSER_ENV_NAME} _COMPOSER_INPUT_BUCKET : ${INPUT_BUCKET_TEST} _COMPOSER_REF_BUCKET : ${REF_BUCKET_TEST} _COMPOSER_REGION : ${COMPOSER_REGION} _DATAFLOW_JAR_BUCKET : ${DATAFLOW_JAR_BUCKET_TEST}"Sur la page Paramètres du déclencheur, sous Avancé, Variables de substitution, remplacez les variables par les valeurs correspondant à votre environnement, que vous avez obtenues à l'étape précédente. Ajoutez les éléments suivants un à un, puis cliquez sur + Ajouter un élément pour chacune des paires nom-valeur.
_COMPOSER_DAG_BUCKET_COMPOSER_DAG_NAME_TEST_COMPOSER_ENV_NAME_COMPOSER_INPUT_BUCKET_COMPOSER_REF_BUCKET_COMPOSER_REGION_DATAFLOW_JAR_BUCKET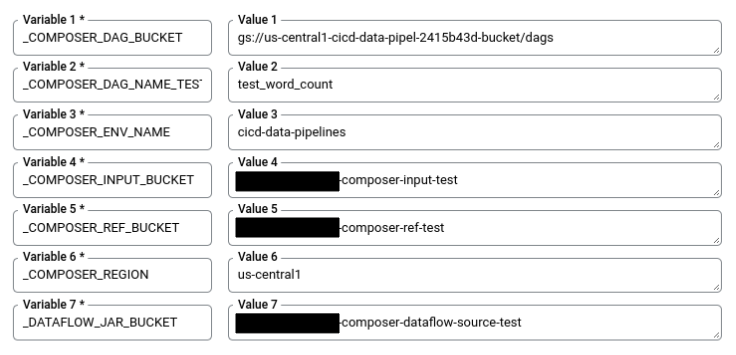
Cliquez sur Créer.
Configurer le déclencheur du pipeline de compilation en production
Vous allez configurer un déclencheur Cloud Build qui déclenche une compilation en production lorsque les tests sont concluants dans l'environnement de test et qu'un message est publié dans le sujet Pub/Sub tests-complete. Ce déclencheur comprend une étape d'approbation au cours de laquelle la compilation doit être approuvée manuellement avant l'exécution du pipeline de production.
Dans la console Google Cloud, accédez à la page Déclencheurs de compilation.
Cliquez sur Créer un déclencheur.
Pour configurer les paramètres du déclencheur, procédez comme suit :
- Dans le champ Nom, saisissez
trigger-build-in-prod-environment. - Dans la liste déroulante Région, sélectionnez global (non régional).
- Pour le champ Événement, cliquez sur Message Pub/Sub.
- Pour Abonnement, sélectionnez integration-test-complete-topic.
- Pour Source, sélectionnez
data-pipeline-source. - Pour Révision, sélectionnez Branche.
- Dans le champ Nom de la branche, saisissez
master. - Pour le champ Configuration, cliquez sur Fichier de configuration Cloud Build (yaml ou json).
- Pour le champ Emplacement, cliquez sur Dépôt.
- Dans le champ Emplacement du fichier de configuration Cloud Build, saisissez
build-pipeline/deploy_prod.yaml.
- Dans le champ Nom, saisissez
Dans Cloud Shell, exécutez la commande suivante pour obtenir toutes les variables de substitution nécessaires à la compilation. Notez ces valeurs car vous en aurez besoin ultérieurement.
echo "_COMPOSER_DAG_BUCKET : ${COMPOSER_DAG_BUCKET} _COMPOSER_DAG_NAME_PROD : ${COMPOSER_DAG_NAME_PROD} _COMPOSER_ENV_NAME : ${COMPOSER_ENV_NAME} _COMPOSER_INPUT_BUCKET : ${INPUT_BUCKET_PROD} _COMPOSER_REGION : ${COMPOSER_REGION} _DATAFLOW_JAR_BUCKET_PROD : ${DATAFLOW_JAR_BUCKET_PROD} _DATAFLOW_JAR_BUCKET_TEST : ${DATAFLOW_JAR_BUCKET_TEST}"Sur la page Paramètres du déclencheur, sous Avancé, Variables de substitution, remplacez les variables par les valeurs correspondant à votre environnement, que vous avez obtenues à l'étape précédente. Ajoutez les éléments suivants un à un, puis cliquez sur + Ajouter un élément pour chacune des paires nom-valeur.
_COMPOSER_DAG_BUCKET_COMPOSER_DAG_NAME_PROD_COMPOSER_ENV_NAME_COMPOSER_INPUT_BUCKET_COMPOSER_REGION_DATAFLOW_JAR_BUCKET_PROD_DATAFLOW_JAR_BUCKET_TEST_DATAFLOW_JAR_FILE_LATEST = $(body.message.data)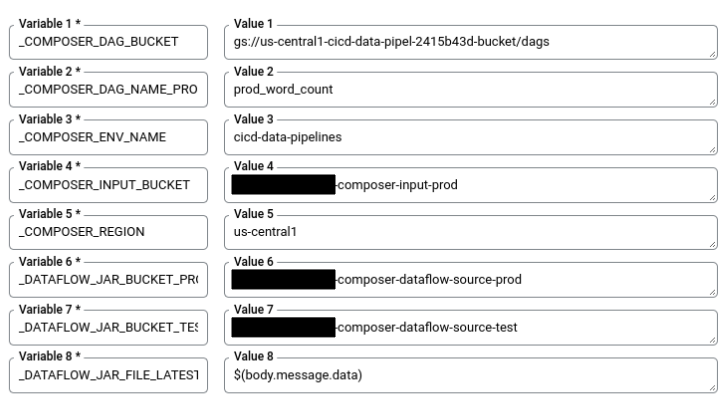
Pour Approbation, cochez Nécessite une approbation pour exécuter le build.
Cliquez sur Créer.
Tester les déclencheurs
Pour tester le déclencheur, vous devez ajouter un nouveau mot dans le fichier d'entrée de test et effectuer l'ajustement correspondant dans le fichier de référence de test. Vous allez vérifier que le pipeline de compilation est déclenché par l'envoi d'un commit dans Cloud Source Repositories et que le workflow de traitement des données s'exécute correctement avec les fichiers de test mis à jour.
Dans Cloud Shell, ajoutez un mot test à la fin du fichier de test :
echo "testword" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/input.txtMettez à jour le fichier de référence des résultats de test,
ref.txt, pour qu'il corresponde aux modifications effectuées dans le fichier d'entrée de test :echo "testword: 1" >> ~/$SOURCE_CODE_REPO/workflow-dag/support-files/ref.txtValidez les modifications et déployez-les sur Cloud Source Repositories.
cd ~/$SOURCE_CODE_REPO git add . git commit -m 'change in test files' git push google masterDans la console Google Cloud, accédez à la page Historique.
Pour confirmer qu'une nouvelle compilation de test est déclenchée par l'envoi précédent dans la branche principale, la colonne Ref de la compilation en cours d'exécution indique master.
Dans Cloud Shell, obtenez l'URL de votre interface Web Cloud Composer :
gcloud composer environments describe $COMPOSER_ENV_NAME \ --location $COMPOSER_REGION --format="get(config.airflowUri)"Une fois la compilation terminée, accédez à l'URL de la commande précédente pour vérifier que le DAG
test_word_countest en cours d'exécution.Attendez la fin de l'exécution du DAG, signalée par la disparition du cercle vert clair de la colonne Exécutions DAG. L'exécution du processus prend généralement trois à cinq minutes.
Dans Cloud Shell, téléchargez les fichiers de résultats du test :
mkdir ~/result-download cd ~/result-download gsutil cp gs://$RESULT_BUCKET_TEST/output* .Vérifiez que le mot que vous venez d'ajouter figure dans l'un des fichiers de résultats :
grep testword output*Le résultat ressemble à ce qui suit :
output-00000-of-00003:testword: 1
Dans la console Google Cloud, accédez à la page Historique.
Vérifiez qu'une compilation en production a bien été déclenchée à la fin du test d'intégration et que la compilation est en attente d'approbation.
Pour exécuter le pipeline de compilation en production, cochez la case située à côté du build, cliquez sur Approuver, puis sur Approuver dans la zone de confirmation.
Une fois la compilation terminée, accédez à l'URL de la commande précédente et déclenchez manuellement le DAG
prod_word_countpour exécuter le pipeline de production.
Effectuer un nettoyage
Les sections suivantes expliquent comment éviter les frais futurs pour votre projet Google Cloud et pour les ressources Apache Hive et Dataproc que vous avez utilisées dans ce déploiement.
Supprimer le projet Google Cloud
Pour éviter que les ressources utilisées dans ce déploiement ne soient facturées sur votre compte Google Cloud, vous pouvez supprimer le projet Google Cloud.
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Supprimer les ressources individuelles
Si vous souhaitez conserver le projet utilisé pour ce déploiement, exécutez la procédure suivante pour supprimer les ressources que vous avez créées.
Pour supprimer le déclencheur Cloud Build, procédez comme suit :
Dans la console Google Cloud, accédez à la page Déclencheurs.
À côté des déclencheurs que vous avez créés, cliquez sur Plusmore_vert, puis sur Supprimer.
Dans Cloud Shell, supprimez l'environnement Cloud Composer :
gcloud -q composer environments delete $COMPOSER_ENV_NAME \ --location $COMPOSER_REGIONSupprimez les buckets Cloud Storage et leurs fichiers :
gsutil -m rm -r gs://$DATAFLOW_JAR_BUCKET_TEST \ gs://$INPUT_BUCKET_TEST \ gs://$REF_BUCKET_TEST \ gs://$RESULT_BUCKET_TEST \ gs://$DATAFLOW_STAGING_BUCKET_TEST \ gs://$DATAFLOW_JAR_BUCKET_PROD \ gs://$INPUT_BUCKET_PROD \ gs://$RESULT_BUCKET_PROD \ gs://$DATAFLOW_STAGING_BUCKET_PRODPour supprimer le sujet Pub/Sub et l'abonnement par défaut, exécutez les commandes suivantes dans Cloud Shell :
gcloud pubsub topics delete integration-test-complete-topic gcloud pubsub subscriptions delete integration-test-complete-topic-subSupprimez le dépôt :
gcloud -q source repos delete $SOURCE_CODE_REPOSupprimez les fichiers et le dossier que vous avez créés :
rm -rf ~/ci-cd-for-data-processing-workflow rm -rf ~/$SOURCE_CODE_REPO rm -rf ~/result-downloadÉtapes suivantes
- Découvrez la livraison continue de type GitOps avec Cloud Build.
- Apprenez à utiliser un pipeline CI/CD pour les workflows de traitement des données.
- Apprenez-en plus sur les modèles courants de cas d'utilisation de Cloud Dataflow.
- Découvrez l'ingénierie des versions.
- Pour découvrir d'autres architectures de référence, schémas et bonnes pratiques, consultez le Centre d'architecture cloud.