이 Dataflow 파이프라인은 민감한 정보 보호를 사용해서 개인 식별 정보(PII)와 같은 민감한 정보를 감지하고 Data Catalog에서 발견 항목에 태그를 지정합니다.
이 문서에 설명된 솔루션은 해당 포함된 문서인 민감한 정보 보호, Cloud Key Management Service, Dataflow를 사용하여 민감한 파일 기반 데이터 자동 토큰화에 설명된 파일 기반 토큰화 솔루션의 아키텍처를 기반으로 합니다. 포함된 문서와 달리 이 문서에서는 민감한 정보 보호 발견 항목에 대해 소스 및 데이터 민감도 태그의 스키마를 사용해서 Data Catalog 항목을 만드는 솔루션을 설명합니다. 또한 자바 데이터베이스 연결(JDBC) 연결을 사용해서 관계형 데이터베이스를 조사할 수 있습니다.
이 문서는 데이터 보안, 데이터 거버넌스, 데이터 처리, 데이터 분석 등을 담당하는 기술 관련 사용자를 대상으로 합니다. 이 문서에서는 사용자가 전문가가 아니어도 데이터 처리 및 데이터 개인 정보 보호에 익숙하다고 가정합니다. 또한 셸 스크립트 및 Google Cloud에 대해 기본 지식이 있다고 가정합니다.
아키텍처
이 아키텍처는 다음 작업을 수행하는 파이프라인을 정의합니다.
- JDBC를 사용하여 관계형 데이터베이스에서 데이터를 추출합니다.
- 데이터베이스의
LIMIT절을 사용해서 레코드를 샘플링합니다. - Cloud Data Loss Prevention API(민감한 정보 보호의 일부)를 통해 레코드를 처리하여 민감도 범주를 식별합니다.
- BigQuery 테이블 및 Data Catalog에 발견 항목을 저장합니다.
다음 다이어그램은 파이프라인이 수행하는 작업을 보여줍니다.

이 솔루션은 JDBC 연결을 사용해서 관계형 데이터베이스에 액세스합니다. BigQuery 테이블을 데이터 소스로 사용할 때 이 솔루션은 BigQuery Storage API를 사용하여 로드 시간을 개선합니다.
sample-and-identify 파이프라인은 다음 파일을 Cloud Storage에 출력합니다.
- 소스 스키마의 Avro 스키마(또는 동등 항목)
- 각 입력 열(
PERSON_NAME,PHONE_NUMBER,STREET_ADDRESS)에 대해 감지된infoTypes데이터
이 솔루션은 레코드 평면화를 사용해서 레코드의 중첩 및 반복 필드를 처리합니다.
목표
- Data Catalog 태그 및 항목 그룹 만들기
- sampling-and-identify 파이프라인 배포
- 커스텀 Data Catalog 항목 만들기
- 커스텀 Data Catalog 항목에 민감도 태그 적용
- 민감도 태그 데이터가 BigQuery에도 있는지 확인
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
API Cloud Build, DLP API, Cloud SQL, Cloud Storage, Compute Engine, Dataflow, Data Catalog, and Secret Manager 사용 설정
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
API Cloud Build, DLP API, Cloud SQL, Cloud Storage, Compute Engine, Dataflow, Data Catalog, and Secret Manager 사용 설정
-
Google Cloud 콘솔에서 Cloud Shell을 활성화합니다.
Google Cloud 콘솔 하단에서 Cloud Shell 세션이 시작되고 명령줄 프롬프트가 표시됩니다. Cloud Shell은 Google Cloud CLI가 사전 설치된 셸 환경으로, 현재 프로젝트의 값이 이미 설정되어 있습니다. 세션이 초기화되는 데 몇 초 정도 걸릴 수 있습니다.
환경 설정하기
Cloud Shell에서 소스 저장소를 클론하고 클론된 파일의 디렉터리로 이동합니다.
git clone https://github.com/GoogleCloudPlatform/auto-data-tokenize.git cd auto-data-tokenize/텍스트 편집기를 사용해서
set_variables.sh스크립트를 수정하여 필요한 환경 변수를 설정합니다. 스크립트의 다른 변수는 무시합니다. 이 문서와는 관련이 없습니다.# The Google Cloud project to use: export PROJECT_ID="PROJECT_ID" # The Compute Engine region to use for running dataflow jobs and create a # temporary storage bucket: export REGION_ID= "REGION_ID" # The Cloud Storage bucket to use as a temporary bucket for Dataflow: export TEMP_GCS_BUCKET="CLOUD_STORAGE_BUCKET_NAME" # Name of the service account to use (not the email address) # (For example, tokenizing-runner): export DLP_RUNNER_SERVICE_ACCOUNT_NAME="DLP_RUNNER_SERVICE_ACCOUNT_NAME" # Entry Group ID to use for creating/searching for Entries # in Data Catalog for non-BigQuery entries. # The ID must begin with a letter or underscore, contain only English # letters, numbers and underscores, and have 64 characters or fewer. export DATA_CATALOG_ENTRY_GROUP_ID="DATA_CATALOG_ENTRY_GROUP_ID" # The Data Catalog Tag Template ID to use # for creating sensitivity tags in Data Catalog. # The ID must contain only lowercase letters (a-z), numbers (0-9), or # underscores (_), and must start with a letter or underscore. # The maximum size is 64 bytes when encoded in UTF-8 export INSPECTION_TAG_TEMPLATE_ID="INSPECTION_TAG_TEMPLATE_ID"
다음을 바꿉니다.
- PROJECT_ID: 프로젝트 ID입니다.
- REGION_ID: 스토리지 버킷이 포함된 리전입니다. Data Catalog 리전에 있는 위치를 선택합니다.
- CLOUD_STORAGE_BUCKET_NAME: 스토리지 버킷의 이름입니다.
- DLP_RUNNER_SERVICE_ACCOUNT_NAME: 서비스 계정의 이름입니다.
- DATA_CATALOG_ENTRY_GROUP_ID: 비BigQuery Data Catalog 항목 그룹의 이름입니다.
- INSPECTION_TAG_TEMPLATE_ID: Data Catalog에 대해 태그 템플릿에 지정한 이름입니다
스크립트를 실행하여 환경 변수를 설정합니다.
source set_variables.sh
리소스 만들기
이 문서에서 설명하는 아키텍처에서는 다음 리소스를 사용합니다.
- 세밀한 액세스 제어를 가능하게 해주는 Dataflow 파이프라인을 실행할 서비스 계정
- 임시 데이터 및 테스트 데이터를 저장할 Cloud Storage 버킷
- 민감도 태그를 항목에 연결하는 Data Catalog 태그 템플릿
- Cloud SQL 인스턴스에서 JDBC 소스로 사용되는 MySQL
서비스 계정 만들기
액세스 분할을 개선하기 위해서는 세밀한 액세스 제어로 파이프라인을 실행하는 것이 좋습니다. 프로젝트에 사용자가 만든 서비스 계정이 없으면 하나 만듭니다.
Cloud Shell에서 Dataflow에 대해 사용자 관리 컨트롤러 서비스 계정으로 사용할 서비스 계정을 만듭니다.
gcloud iam service-accounts create ${DLP_RUNNER_SERVICE_ACCOUNT_NAME} \ --project="${PROJECT_ID}" \ --description="Service Account for Sampling and Cataloging pipelines." \ --display-name="Sampling and Cataloging pipelines"민감한 정보 보호, Dataflow, Cloud SQL, Data Catalog에 액세스하는 데 필요한 권한을 사용해서 커스텀 역할을 만듭니다.
export SAMPLING_CATALOGING_ROLE_NAME="sampling_cataloging_runner" gcloud iam roles create ${SAMPLING_CATALOGING_ROLE_NAME} \ --project="${PROJECT_ID}" \ --file=tokenizing_runner_permissions.yamlDataflow 작업자로 실행될 수 있도록 서비스 계정에 커스텀 역할 및 Dataflow 작업자 역할을 적용합니다.
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${DLP_RUNNER_SERVICE_ACCOUNT_EMAIL}" \ --role=projects/${PROJECT_ID}/roles/${SAMPLING_CATALOGING_ROLE_NAME} gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${DLP_RUNNER_SERVICE_ACCOUNT_EMAIL}" \ --role=roles/dataflow.worker
Cloud Storage 버킷 만들기
Cloud Shell에서 테스트 데이터 저장을 위해 그리고 Dataflow 스테이징 위치로 사용할 Cloud Storage 버킷을 만듭니다.
gsutil mb -p ${PROJECT_ID} -l ${REGION_ID} "gs://${TEMP_GCS_BUCKET}"
Data Catalog 항목 그룹 만들기
Data Catalog는 Google Cloud 리소스 또는 기타 리소스를 나타내는 항목 목록이 포함되어 있습니다. 항목은 항목 그룹으로 정리됩니다. 암시적 항목 그룹이 BigQuery(@bigquery)에 대해 존재합니다. 다른 유형의 리소스에 대해서는 항목 그룹을 만들어야 합니다. Data Catalog 항목에 대한 자세한 내용은 파일 세트 항목을 사용하여 Cloud Storage에서 파일 표시를 참조하세요.
Data Catalog에서 항목 그룹은 항목을 포함하는 폴더와 비슷합니다. 항목은 데이터 애셋을 나타냅니다.
Cloud Shell에서 파이프라인이 MySQL 테이블에 대해 항목을 추가할 수 있는 새 항목 그룹을 만듭니다.
gcloud data-catalog entry-groups create \ "${DATA_CATALOG_ENTRY_GROUP_ID}" \ --project="${PROJECT_ID}" \ --location="${REGION_ID}"
검사 태그 템플릿 만들기
Cloud Shell에서 민감한 정보 보호와 함께 민감도 정보를 사용하여 항목 태그 지정을 사용 설정하도록 Data Catalog 태그 템플릿을 만듭니다.
gcloud data-catalog tag-templates create ${INSPECTION_TAG_TEMPLATE_ID} \ --project="${PROJECT_ID}" \ --location="${REGION_ID}" \ --display-name="Auto DLP sensitive categories" \ --field=id=infoTypes,type=string,display-name="DLP infoTypes",required=TRUE \ --field=id=inspectTimestamp,type=timestamp,display-name="Inspection run timestamp",required=TRUE
BigQuery에서 검사 결과 테이블 만들기
Cloud Shell에서 민감한 정보 보호에서 집계된 발견 항목을 저장할 BigQuery 테이블을 만듭니다.
bq mk --dataset \ --location="${REGION_ID}" \ --project_id="${PROJECT_ID}" \ inspection_results bq mk --table \ --project_id="${PROJECT_ID}" \ inspection_results.SensitivityInspectionResults \ inspection_results_bigquery_schema.json
Cloud SQL 인스턴스에서 MySQL 설정
데이터 소스의 경우 Cloud SQL 인스턴스를 사용합니다.
Cloud Shell에서 Cloud SQL 인스턴스에서 MySQL을 인스턴스화하고 여기에 샘플 데이터를 로드합니다.
export SQL_INSTANCE="mysql-autodlp-instance" export SQL_ROOT_PASSWORD="root1234" gcloud sql instances create "${SQL_INSTANCE}" \ --project="${PROJECT_ID}" \ --region="${REGION_ID}" \ --database-version=MYSQL_5_7 \ --root-password="${SQL_ROOT_PASSWORD}"Secret Manager에서 데이터베이스 비밀번호를 저장합니다.
데이터베이스 비밀번호 및 기타 보안 비밀 정보는 저장하거나 로깅하지 않아야 합니다. Secret Manager를 사용하면 이러한 보안 비밀을 안전하게 저장하고 검색할 수 있습니다.
MySQL 데이터베이스 루트 비밀번호를 클라우드 보안 비밀로 저장합니다.
export SQL_PASSWORD_SECRET_NAME="mysql-password" printf $SQL_ROOT_PASSWORD | gcloud secrets create "${SQL_PASSWORD_SECRET_NAME}" \ --data-file=- \ --locations="${REGION_ID}" \ --replication-policy="user-managed" \ --project="${PROJECT_ID}"
테스트 데이터를 Cloud SQL 인스턴스에 복사
테스트 데이터는 무작위로 생성된 5,000개의 이름과 성, 미국 스타일의 전화 번호가 있는 데모 데이터 세트입니다. demonstration-dataset 테이블에는 row_id, person_name, contact_type, contact_number의 4개 열이 있습니다. 자체 데이터 세트를 사용할 수도 있습니다. 자체 데이터 세트를 사용할 경우 이 문서의 BigQuery에서 확인에 있는 권장 값을 조정해야 합니다. 포함된 데모 데이터 세트(contacts5k.sql.gz)를 Cloud SQL 인스턴스에 복사하려면 다음을 수행합니다.
Cloud SQL에 스테이징하기 위해 Cloud Shell에서 샘플 데이터 세트를 Cloud Storage에 복사합니다.
gsutil cp contacts5k.sql.gz gs://${TEMP_GCS_BUCKET}Cloud SQL 인스턴스에서 새 데이터베이스를 만듭니다.
export DATABASE_ID="auto_dlp_test" gcloud sql databases create "${DATABASE_ID}" \ --project="${PROJECT_ID}" \ --instance="${SQL_INSTANCE}"스토리지에 액세스할 수 있도록 Cloud SQL 서비스 계정에 스토리지 객체 관리자 역할을 부여합니다.
export SQL_SERVICE_ACCOUNT=$(gcloud sql instances describe "${SQL_INSTANCE}" --project="${PROJECT_ID}" | grep serviceAccountEmailAddress: | sed "s/serviceAccountEmailAddress: //g") gsutil iam ch "serviceAccount:${SQL_SERVICE_ACCOUNT}:objectAdmin" \ gs://${TEMP_GCS_BUCKET}새 테이블에 데이터를 로드합니다.
gcloud sql import sql "${SQL_INSTANCE}" \ "gs://${TEMP_GCS_BUCKET}/contacts5k.sql.gz" \ --project="${PROJECT_ID}" \ --database="${DATABASE_ID}"Cloud SQL에 데이터 가져오기에 대한 자세한 내용은 데이터 가져오기 및 내보내기 권장사항을 참조하세요.
모듈 컴파일
Cloud Shell에서 sampling-and-identify 파이프라인 및 토큰화 파이프라인을 배포하기 위해 실행 파일을 빌드하도록 모듈을 컴파일합니다.
./gradlew clean buildNeeded shadowJar -x test선택적으로 단위 및 통합 테스트를 실행하려면
-x test플래그를 삭제합니다. 아직libncurses5를 설치하지 않았으면 Cloud Shell에서sudo apt-get install libncurses5를 사용하여 설치합니다.
sampling-and-identify 파이프라인 실행
샘플링 및 민감한 정보 보호 식별 파이프라인은 다음 태스크를 다음 순서로 수행합니다.
- 제공된 소스에서 레코드를 추출합니다. 예를 들어 민감한 정보 보호 식별 메서드는 플랫 테이블만 지원합니다. 따라서 해당 레코드에 중첩 및 반복 필드가 포함될 수 있기 때문에 파이프라인이 Avro, Parquet, BigQuery 레코드를 평면화합니다.
null또는 빈 값을 제외하고 필요한 샘플에 대해 개별 열을 샘플링합니다.- 민감한 정보 보호에 대해 허용되는 배치 크기(500Kb 미만 및 50,000개 미만 값)로 샘플을 일괄 처리하여 민감한 정보 보호를 사용해서 민감한
infoTypes데이터를 식별합니다. - 나중에 참조할 수 있도록 보고서를 Cloud Storage 및 BigQuery에 기록합니다.
- 태그 템플릿 및 항목 그룹 정보를 제공할 때 Data Catalog 항목을 만듭니다. 이 정보를 제공하면 파이프라인이 Data Catalog에서 적합한 열에 따라 항목에 대해 민감도 태그를 만듭니다.
Dataflow Flex 템플릿 만들기
Dataflow Flex 템플릿을 사용하면 Google Cloud 콘솔, Google Cloud CLI 또는 REST API 호출을 사용하여 Google Cloud에서 파이프라인을 설정하고 실행할 수 있습니다. 이 문서에서는 Google Cloud 콘솔에 대한 안내를 제공합니다. 기본 템플릿은 Cloud Storage에서 실행 그래프로 스테이징됩니다. Flex 템플릿은 프로젝트의 Container Registry에서 파이프라인을 컨테이너 이미지 번들로 포함합니다. Flex 템플릿을 사용하면 파이프라인 빌드 및 실행을 분리하고 예약된 파이프라인 실행을 위해 조정 시스템과 통합됩니다. Dataflow Flex 템플릿에 대한 자세한 내용은 사용할 템플릿 유형 평가를 참조하세요.
Dataflow Flex 템플릿은 실행 중인 단계에서 빌드 및 스테이징 단계를 분리합니다. 이 템플릿은 이를 위해 API 호출에서 그리고 Cloud Composer에서 DataflowStartFlexTemplateOperator 모듈을 사용하여 Dataflow 파이프라인을 실행할 수 있도록 설정합니다.
Cloud Shell에서 Dataflow 작업 실행에 필요한 정보가 포함된 템플릿 사양 파일을 저장할 위치를 정의합니다.
export FLEX_TEMPLATE_PATH="gs://${TEMP_GCS_BUCKET}/dataflow/templates/sample-inspect-tag-pipeline.json" export FLEX_TEMPLATE_IMAGE="us.gcr.io/${PROJECT_ID}/dataflow/sample-inspect-tag-pipeline:latest"Dataflow Flex 템플릿을 빌드합니다.
gcloud dataflow flex-template build "${FLEX_TEMPLATE_PATH}" \ --image-gcr-path="${FLEX_TEMPLATE_IMAGE}" \ --service-account-email="${DLP_RUNNER_SERVICE_ACCOUNT_EMAIL}" \ --sdk-language="JAVA" \ --flex-template-base-image=JAVA11 \ --metadata-file="sample_identify_tag_pipeline_metadata.json" \ --jar="build/libs/auto-data-tokenize-all.jar" \ --env="FLEX_TEMPLATE_JAVA_MAIN_CLASS=\"com.google.cloud.solutions.autotokenize.pipeline.DlpInspectionPipeline\""
파이프라인 실행
샘플링 및 식별 파이프라인은 sampleSize 값으로 지정된 레코드 수를 추출합니다. 그런 후 각 레코드를 평면화하고 민감한 정보 보호를 사용해서 infoTypes 필드를 식별합니다(민감한 정보 유형 식별). infoTypes 값이 계산된 후 민감도 보고서 빌드를 위해 열 이름 및 infoType 필드에 따라 집계됩니다.
Cloud Shell에서 sampling-and-identify 파이프라인을 실행하여 데이터 소스에 있는 민감한 열을 식별합니다.
export CLOUD_SQL_JDBC_CONNECTION_URL="jdbc:mysql:///${DATABASE_ID}?cloudSqlInstance=${PROJECT_ID}%3A${REGION_ID}%3A${SQL_INSTANCE}&socketFactory=com.google.cloud.sql.mysql.SocketFactory" gcloud dataflow flex-template run "sample-inspect-tag-`date +%Y%m%d-%H%M%S`" \ --template-file-gcs-location "${FLEX_TEMPLATE_PATH}" \ --region "${REGION_ID}" \ --service-account-email "${DLP_RUNNER_SERVICE_ACCOUNT_EMAIL}" \ --staging-location "gs://${TEMP_GCS_BUCKET}/staging" \ --worker-machine-type "n1-standard-1" \ --parameters sampleSize=2000 \ --parameters sourceType="JDBC_TABLE" \ --parameters inputPattern="Contacts" \ --parameters reportLocation="gs://${TEMP_GCS_BUCKET}/auto_dlp_report/" \ --parameters reportBigQueryTable="${PROJECT_ID}:inspection_results.SensitivityInspectionResults" \ --parameters jdbcConnectionUrl="${CLOUD_SQL_JDBC_CONNECTION_URL}" \ --parameters jdbcDriverClass="com.mysql.cj.jdbc.Driver" \ --parameters jdbcUserName="root" \ --parameters jdbcPasswordSecretsKey="projects/${PROJECT_ID}/secrets/${SQL_PASSWORD_SECRET_NAME}/versions/1" \ --parameters ^:^jdbcFilterClause="ROUND(RAND() * 10) IN (1,3)" \ --parameters dataCatalogEntryGroupId="projects/${PROJECT_ID}/locations/${REGION_ID}/entryGroups/${DATA_CATALOG_ENTRY_GROUP_ID}" \ --parameters dataCatalogInspectionTagTemplateId="projects/${PROJECT_ID}/locations/${REGION_ID}/tagTemplates/${INSPECTION_TAG_TEMPLATE_ID}"
jdbcConnectionUrl 매개변수는 사용자 이름 및 비밀번호 세부정보를 사용해서 JDBC 데이터베이스 연결 URL을 지정합니다. 정확한 연결 URL 빌드에 대한 세부정보는 데이터베이스 공급업체 및 호스팅 파트너에 따라 달라집니다. Cloud SQL 기반 관계형 데이터베이스 연결에 대한 자세한 내용은 Cloud SQL 커넥터를 사용하여 연결을 참조하세요.
파이프라인은 검사할 테이블 레코드를 읽기 위해 SELECT * FROM [TableName]과 같은 쿼리를 생성합니다.
이 쿼리는 데이터베이스에서 그리고 특히 대규모 테이블의 경우에는 파이프라인에서 부하를 일으킬 수 있습니다. 선택적으로 데이터베이스 측에서 검사할 레코드 샘플을 최적화할 수 있습니다.
이렇게 하려면 jdbcFilterClause를 이 문서의 뒷부분에 있는 BigQuery에서 확인 섹션에 제공된 코드 샘플에 표시되는 쿼리의 WHERE 절로 삽입합니다.
보고서를 실행하려면 다음 보고 싱크를 하나 이상 선택할 수 있습니다.
reportLocation은 Cloud Storage 버킷에 보고서를 저장합니다.reportBIGQUERY_TABLE은BigQueryTable에 보고서를 저장합니다.dataCatalogEntryGroupId는 Data Catalog에서 항목을 만들고 태그 지정합니다(sourceType이BIGQUERY_TABLE이면 이 매개변수 생략).
이 파이프라인은 다음 소스 유형을 지정합니다. sourceType 및 inputPattern 인수의 올바른 조합을 결정하려면 다음 테이블에 나열된 옵션을 사용합니다.
이 경우에는 JDBC_TABLE 테이블만 사용합니다.
sourceType |
데이터 소스 | inputPattern |
|---|---|---|
|
관계형 데이터베이스(JDBC 사용) |
|
|
Cloud Storage의 Avro 파일입니다. 패턴과 일치하는 여러 파일을 선택하려면 단일 와일드 카드를 사용할 수 있습니다. 다음 패턴은 프리픽스로 시작하는 모든 파일을 선택합니다( data-).
|
|
|
Cloud Storage의 Parquet 파일 패턴과 일치하는 여러 파일을 선택하려면 단일 와일드 카드를 사용할 수 있습니다. 다음 패턴은 프리픽스로 시작하는 모든 파일을 선택합니다( data-).
|
|
|
BigQuery 테이블입니다. 모든 행을 읽은 후 파이프라인을 사용해서 무작위로 샘플링합니다. |
|
파이프라인은 민감한 정보 보호에서 지원되는 모든 표준 infoTypes를 검색합니다. --observableinfoTypes 매개변수를 사용하여 추가적인 커스텀 infoTypes를 제공할 수 있습니다.
Sampling-and-identify 파이프라인 방향성 비순환 그래프(DAG)
다음 다이어그램은 Dataflow 실행 DAG를 보여줍니다. DAG에는 2개의 분기가 있습니다. 두 분기 모두 ReadJdbcTable에서 시작하여 ExtractReport에서 종료됩니다. 여기에서 보고서가 생성되거나 데이터가 저장됩니다.
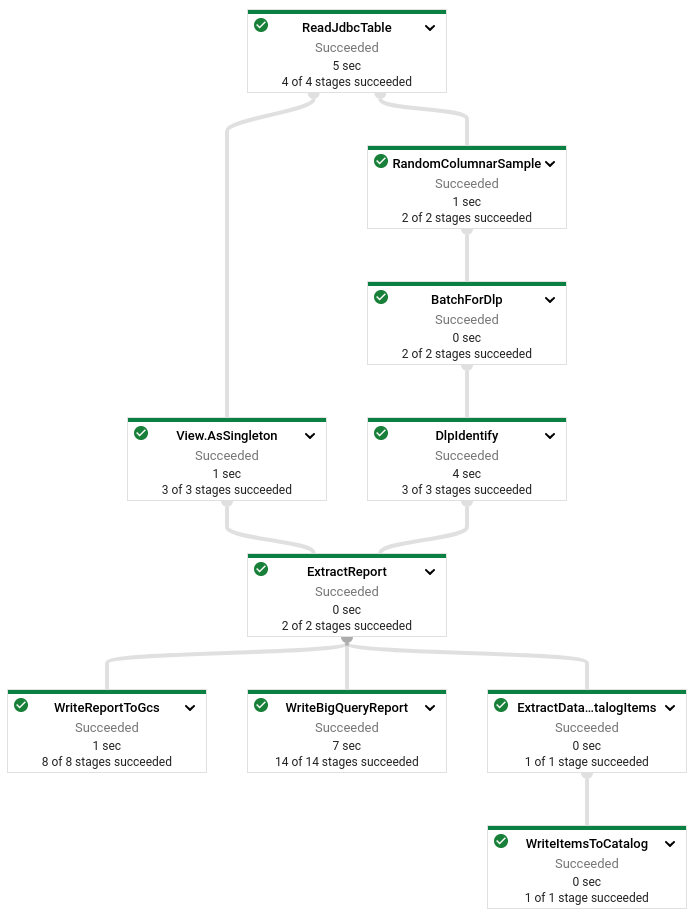
보고서 검색
샘플링 및 식별 파이프라인은 다음 파일을 출력합니다.
- 소스의 Avro 스키마 파일(또는 Avro로 전환되는 스키마)
infoType정보 및 개수가 포함된 각 민감한 열마다 하나의 파일
보고서를 검색하려면 다음을 수행합니다.
Cloud Shell에서 보고서를 검색합니다.
mkdir -p auto_dlp_report/ gsutil -m cp "gs://${TEMP_GCS_BUCKET}/auto_dlp_report/*.json" auto_dlp_report/식별된 모든 열 이름을 나열합니다.
cat auto_dlp_report/col-*.json | jq .columnName출력은 다음과 같습니다.
"$.topLevelRecord.contact_number" "$.topLevelRecord.person_name"파일에 대해
cat명령어를 사용해서 식별된 열의 세부정보를 확인합니다.cat auto_dlp_report/col-topLevelRecord-contact_number-00000-of-00001.json다음은
cc열의 스니펫입니다.{ "columnName": "$.topLevelRecord.contact_number", "infoTypes": [{ "infoType": "PHONE_NUMBER", "count": "990" }] }columnName값은 Avro 레코드에 대한 데이터베이스 행의 암시적 변환으로 인해 일반적이지 않습니다.count값은 실행 중 무작위로 선택된 샘플에 따라 달라집니다.
Data Catalog에서 민감도 태그 확인
샘플링 및 식별 파이프라인은 새 항목을 만들고 민감도 태그를 적합한 열에 적용합니다.
Cloud Shell에서 Contacts 테이블에 대해 생성된 항목을 검색합니다.
gcloud data-catalog entries describe Contacts \ --entry-group=${DATA_CATALOG_ENTRY_GROUP_ID} \ --project="${PROJECT_ID}" \ --location="${REGION_ID}"이 명령어는 스키마를 포함하여 테이블의 세부정보를 보여줍니다.
이 항목에 연결된 모든 민감도 태그를 보여줍니다.
gcloud data-catalog tags list --entry=Contacts --entry-group=${DATA_CATALOG_ENTRY_GROUP_ID} \ --project="${PROJECT_ID}" \ --location="${REGION_ID}"민감도 태그가
contact_number,person_name열에 있는지 확인합니다.민감한 정보 보호로 식별된
infoTypes데이터는 몇 가지 false 유형을 포함할 수 있습니다. 예를 들어 이 데이터는 일부 무작위person_names문자열이 April, May, June, 등일 수 있기 때문에person_name유형을DATE유형으로 식별할 수 있습니다.출력되는 민감도 태그 세부정보는 다음과 같습니다.
column: contact_number fields: infoTypes: displayName: DLP infoTypes stringValue: '[PHONE_NUMBER]' inspectTimestamp: displayName: Inspection run timestamp timestampValue: '2021-05-20T16:34:29.596Z' name: projects/auto-dlp/locations/asia-southeast1/entryGroups/sql_databases/entries/Contacts/tags/CbS0CtGSpZyJ template: projects/auto-dlp/locations/asia-southeast1/tagTemplates/auto_dlp_inspection templateDisplayName: Auto DLP sensitive categories --- column: person_name fields: infoTypes: displayName: DLP infoTypes stringValue: '[DATE, PERSON_NAME]' inspectTimestamp: displayName: Inspection run timestamp timestampValue: '2021-05-20T16:34:29.594Z' name: projects/auto-dlp/locations/asia-southeast1/entryGroups/sql_databases/entries/Contacts/tags/Cds1aiO8R0pT template: projects/auto-dlp/locations/asia-southeast1/tagTemplates/auto_dlp_inspection templateDisplayName: Auto DLP sensitive categories
BigQuery에서 확인
Dataflow 파이프라인은 집계된 발견 항목을 제공된 BigQuery 테이블에 추가합니다. 쿼리는 BigQuery 테이블에서 검색된 검사 결과를 출력합니다.
Cloud Shell에서 결과를 확인합니다.
bq query \ --location="${REGION_ID}" \ --project="${PROJECT_ID}" \ --use_legacy_sql=false \ 'SELECT input_pattern AS table_name, ColumnReport.column_name AS column_name, ColumnReport.info_types AS info_types FROM `inspection_results.SensitivityInspectionResults`, UNNEST(column_report) ColumnReport; WHERE column_name="$.topLevelRecord.contact_number"'출력은 다음과 같습니다.
+------------+---------------------------------+----------------------------------------------+ | table_name | column_name | info_types | +------------+---------------------------------+----------------------------------------------+ | Contacts | $.topLevelRecord.contact_number | [{"info_type":"PHONE_NUMBER","count":"990"}] | +------------+---------------------------------+----------------------------------------------+
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
프로젝트 삭제
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
다음 단계
- 파일을 입력으로 사용하는 비슷한 솔루션에 대한 포함된 문서 민감한 정보 보호, Cloud Key Management Service, Dataflow를 사용하여 민감한 파일 기반 데이터 자동 토큰화 참조
- 스토리지 및 데이터베이스에서 민감한 정보 검사 알아보기
- 민감한 정보 보호를 사용하여 대규모 데이터 세트에서 PII 익명화 및 재식별화 처리 알아보기
- 그 밖의 참조 아키텍처, 다이어그램, 튜토리얼, 권장사항을 알아보려면 클라우드 아키텍처 센터를 확인하세요.