Lorsque vous choisissez des services de stockage Google Cloud pour vos charges de travail d'intelligence artificielle (IA) et de machine learning (ML), vous devez prendre soin de sélectionner la bonne combinaison d'options de stockage pour chaque job spécifique. Cette nécessité d'une sélection minutieuse s'applique lorsque vous importez votre ensemble de données, entraînez et réglez votre modèle, placez le modèle en production ou stockez l'ensemble de données et le modèle dans une archive. En résumé, vous devez sélectionner les meilleurs services de stockage pour bénéficier d'une latence, d'une évolutivité et de coûts appropriés pour chaque étape de vos charges de travail d'IA et de ML.
Pour vous aider à prendre des décisions éclairées, ce document fournit des conseils de conception pour l'utilisation et l'intégration des diverses options de stockage proposées par Google Cloud pour les charges de travail clés d'IA et de ML.
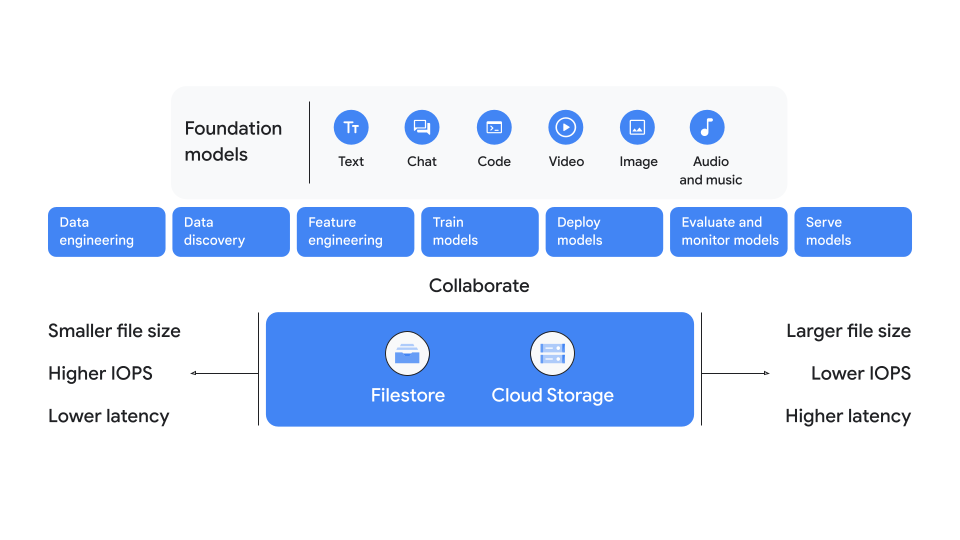
La Figure 1 présente un résumé des principales options de stockage. Comme le montre le schéma, vous choisirez généralement Cloud Storage si vous travaillez avec des fichiers de plus grande taille, un nombre réduit d'opérations d'entrée et de sortie par seconde (IOPS) ou une faible sensibilité à la latence. Toutefois, lorsque vous avez besoin d'IOPS plus élevées, de fichiers plus petits ou d'une latence plus faible, choisissez plutôt Filestore.
Figure 1 : Considérations relatives au stockage principal pour l'IA et le ML
Présentation des étapes des charges de travail d'IA et de ML
Les charges de travail d'IA et de ML comprennent quatre étapes principales : préparer, entraîner, diffuser et archiver. Il s'agit des quatre étapes du cycle de vie d'une charge de travail d'IA et de ML au cours desquelles vous devez décider des options de stockage à utiliser. Dans la plupart des cas, nous vous recommandons d'utiliser la même option de stockage que celle sélectionnée lors de l'étape de préparation pour les étapes restantes. Le respect de cette recommandation vous permet de réduire la copie des ensembles de données entre différents services de stockage. Cependant, il existe des exceptions à cette règle générale, qui sont décrites plus loin dans ce guide.
Certaines solutions de stockage fonctionnent mieux que d'autres pour chaque étape, et il peut s'avérer nécessaire de les combiner avec des options de stockage supplémentaires pour obtenir de meilleurs résultats. L'efficacité de l'option de stockage dépend des propriétés de l'ensemble de données, de l'échelle des ressources de calcul et de stockage requises, de la latence et d'autres facteurs. Le tableau suivant décrit les étapes et fournit un bref résumé des options de stockage recommandées pour chaque étape. Pour obtenir une représentation visuelle de cette table et des détails supplémentaires, consultez l'arbre de décision.
Tableau 1 : Recommandations de stockage pour les étapes des charges de travail d'IA et de ML
| Étapes | Étapes | Recommandations de stockage |
|---|---|---|
Préparer le terrain |
Préparation des données
|
Cloud Storage
Firestore Zonal
|
Entraîner |
|
Cloud Storage
Cloud Storage avec un disque SSD local ou Filestore
Filestore
|
|
Cloud Storage
Firestore Zonal
|
|
Diffuser |
|
Cloud Storage
Filestore
|
Archiver |
|
Cloud Storage
|
Pour plus de détails sur les hypothèses sous-jacentes de ce tableau, consultez les sections suivantes :
- Critères
- Options de stockage
- Mapper vos options de stockage aux étapes d'IA et de ML
- Recommandations de stockage pour l'IA et le ML
Critères
Pour affiner les options de stockage à utiliser pour vos charges de travail d'IA et de ML, commencez par répondre aux questions suivantes :
- La taille de vos fichiers et de vos requêtes d'E/S d'IA et de ML est-elle petite, moyenne ou grande ?
- Vos charges de travail d'IA et de ML sont-elles sensibles à la latence des E/S et au temps de latence du premier octet (TTFB) ?
- Avez-vous besoin d'un débit de lecture et d'écriture élevé pour les clients uniques, les clients agrégés ou les deux ?
- Quel est le plus grand nombre de GPU Cloud ou de Cloud TPU requis pour votre charge de travail d'entraînement d'IA et de ML la plus importante ?
En plus de répondre aux questions précédentes, vous devez également connaître les options de calcul et les accélérateurs que vous pouvez choisir pour optimiser vos charges de travail d'IA et de ML.
Considérations relatives à la plate-forme de calcul
Google Cloud accepte trois méthodes principales pour exécuter des charges de travail d'IA et de ML :
- Compute Engine : les machines virtuelles (VM) sont compatibles avec tous les services de stockage gérés par Google ainsi qu'avec les offres partenaires. Compute Engine est compatible avec les disques SSD locaux, Persistent Disk, Cloud Storage, Cloud Storage FUSE, NetApp Volumes et Filestore. Pour les jobs d'entraînement à grande échelle dans Compute Engine, Google s'est associé à SchedMD afin d'améliorer le planificateur Slurm.
Google Kubernetes Engine (GKE) : GKE est une plate-forme d'IA populaire qui s'intègre aux frameworks, charges de travail et outils de traitement de données courants. GKE est compatible avec les disques SSD locaux, les volumes persistants, Cloud Storage FUSE et Filestore.
Vertex AI : Vertex AI est une plate-forme d'IA entièrement gérée qui fournit une solution de bout en bout pour les charges de travail d'IA et de ML. Vertex AI est compatible avec Cloud Storage et avec le stockage basé sur des fichiers Network File System (NFS) (Filestore et NetApp Volumes, par exemple).
Pour Compute Engine et GKE, nous vous recommandons d'utiliser le kit HPC pour déployer des clusters reproductibles et clé en main qui respectent les bonnes pratiques de Google Cloud.
Considérations relatives aux accélérateurs
Lorsque vous choisissez des options de stockage pour les charges de travail d'IA et de ML, vous devez également choisir les options de traitement d'accélérateur appropriées pour votre tâche. Google Cloud accepte deux accélérateurs : les GPU Cloud NVIDIA et les Cloud TPU Google, qui sont développés sur mesure. Ces deux types d'accélérateurs sont des circuits intégrés spécifiques à l'application (ASIC) qui permettent de traiter les charges de travail de machine learning plus efficacement que les processeurs standards.
Il existe des différences de stockage importantes entre les accélérateurs GPU Cloud et Cloud TPU. Les instances qui utilisent les GPU Cloud sont compatibles avec les disques SSD locaux offrant un débit de stockage distant pouvant atteindre 200 Gbit/s. Les nœuds et les VM Cloud TPU ne sont pas compatibles avec les disques SSD locaux et reposent exclusivement sur l'accès au stockage à distance.
Pour en savoir plus sur les types de machines optimisés pour les accélérateurs, consultez la section Famille de machines optimisées pour les accélérateurs. Pour en savoir plus sur les GPU Cloud, consultez la page Plates-formes de GPU sur Google Cloud. Pour en savoir plus sur les Cloud TPU, consultez la Présentation des Cloud TPU. Pour vous aider à choisir entre les Cloud TPU et les GPU Cloud, consultez la page Quand utiliser des Cloud TPU.
Options de stockage
Comme résumé précédemment dans le tableau 1, utilisez le stockage d'objets ou de fichiers pour vos charges de travail d'IA et de ML, puis complétez cette option de stockage avec le stockage de blocs. La figure 2 présente trois options types que vous pouvez envisager comme choix de stockage initial pour votre charge de travail d'IA et de ML : Cloud Storage, Filestore et Google Cloud NetApp Volumes.
Figure 2 : Services de stockage adaptés à l'IA et au ML proposés par Google Cloud
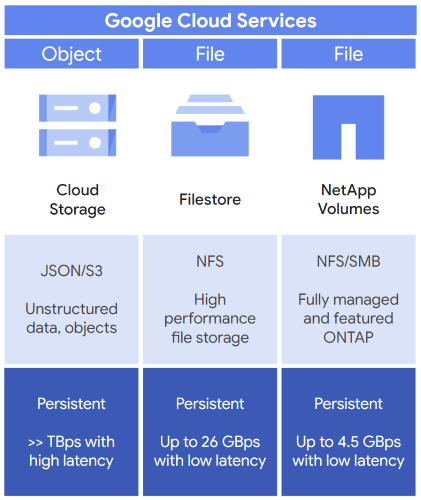
Si vous avez besoin d'un stockage d'objets, choisissez Cloud Storage. Cloud Storage fournit les services suivants :
- Un emplacement de stockage pour les données et les objets non structurés.
- Des API, telles que l'API JSON Cloud Storage, pour accéder à vos buckets de stockage.
- Un espace de stockage persistant pour enregistrer vos données.
- Débit de plusieurs téraoctets par seconde, mais nécessite une latence de stockage plus élevée.
Si vous avez besoin de stockage de fichiers, deux choix s'offrent à vous (Filestore et NetApp Volumes), avec les avantages suivants :
- Filestore
- Stockage de fichiers professionnel hautes performances basé sur NFS.
- Un espace de stockage persistant pour enregistrer vos données.
- Faible latence de stockage et débit de 26 Gbit/s.
- NetApp Volumes
- Stockage de fichiers compatible NFS et Server Message Block (SMB).
- Peut être géré avec l'option permettant d'utiliser l'outil logiciel de stockage NetApp ONTAP.
- Un espace de stockage persistant pour enregistrer vos données.
- Débit de 4,5 Gbit/s.
Utilisez les options de stockage suivantes comme premier choix pour les charges de travail d'IA et de ML :
Utilisez les options de stockage suivantes pour compléter vos charges de travail d'IA et de ML :
Si vous devez transférer des données entre ces options de stockage, vous pouvez utiliser les outils de transfert de données.
Cloud Storage
Cloud Storage est un service de stockage d'objets entièrement géré, axé sur la préparation des données, l'entraînement de modèles d'IA, la diffusion, la sauvegarde et l'archivage de données non structurées. Voici quelques-uns des avantages de Cloud Storage :
- Capacité de stockage illimitée, évolutive à l'exaoctet et à l'échelle mondiale
- Performances à très haut débit
- Options de stockage régional et birégional pour les charges de travail d'IA et de ML
Cloud Storage adapte le débit à plusieurs téraoctets par seconde et au-delà, mais sa latence est relativement supérieure (quelques dizaines de millisecondes) à celle de Filestore ou d'un système de fichiers local. Le débit des threads individuels est limité à environ 100 à 200 Mo par seconde, ce qui signifie qu'un débit élevé ne peut être atteint qu'en utilisant des centaines, voire des milliers de threads individuels. De plus, un débit élevé nécessite également d'utiliser des fichiers volumineux et des requêtes d'E/S volumineuses.
Cloud Storage est compatible avec les bibliothèques clientes dans divers langages de programmation, mais est également compatible avec Cloud Storage FUSE. Cloud Storage FUSE vous permet d'installer des buckets Cloud Storage sur votre système de fichiers local. Cloud Storage FUSE permet à vos applications d'utiliser des API de système de fichiers standards pour lire ou écrire dans un bucket. Vous pouvez stocker vos données, modèles et points de contrôle d'entraînement et y accéder en bénéficiant de l'évolutivité, des tarifs abordables et des performances de Cloud Storage.
Pour en savoir plus sur Cloud Storage, consultez les ressources suivantes :
- Présentation du produit Cloud Storage
- Consignes applicables aux taux de demandes et à la distribution des accès
- Cloud Storage FUSE
- Performances et bonnes pratiques de Cloud Storage FUSE
Filestore
Filestore est un service de stockage NFS entièrement géré basé sur des fichiers. Les niveaux de service Filestore utilisés pour les charges de travail d'IA et de ML sont les suivants :
- Niveau entreprise : utilisé pour les charges de travail critiques nécessitant une disponibilité régionale.
- Niveau zonal : utilisé pour les applications hautes performances nécessitant une disponibilité zonale avec des exigences élevées en termes de performances d'IOPS et de débit.
- Niveau de base : utilisé pour le partage de fichiers, le développement logiciel, l'hébergement Web et les charges de travail d'IA et de ML de base.
Filestore offre des performances d'E/S à faible latence. Il s'agit d'un bon choix pour les ensembles de données qui présentent de faibles exigences d'ES d'accès ou qui utilisent de petits fichiers. Toutefois, Filestore peut également gérer des cas d'utilisation avec des E/S volumineuses ou des fichiers volumineux si nécessaire. Filestore peut atteindre une taille d'environ 100 To. Pour les charges de travail d'entraînement IA qui lisent des données de manière répétée, vous pouvez améliorer le débit de lecture en utilisant FS-Cache avec un disque SSD local.
Pour en savoir plus sur Filestore, consultez la présentation de Filestore. Pour en savoir plus sur les niveaux de service Filestore, consultez la section Niveaux de service. Pour en savoir plus sur les performances de Filestore, consultez la page Optimiser et tester les performances des instances.
Google Cloud NetApp Volumes
NetApp Volumes est un service entièrement géré doté de fonctionnalités avancées de gestion des données compatibles avec les environnements multiprotocoles, NFS et SMB. NetApp Volumes offre une faible latence, des volumes de plusieurs tébioctets et un débit de plusieurs gigaoctets par seconde.
Pour en savoir plus sur NetApp Volumes, consultez la page Qu'est-ce que Google Cloud NetApp Volumes ? Pour en savoir plus sur les performances de NetApp Volumes, consultez la page Performances attendues.
Stockage de blocs
Une fois que vous avez sélectionné votre choix de stockage principal, vous pouvez utiliser le stockage de blocs pour améliorer les performances, transférer des données entre différentes options de stockage et bénéficier d'opérations à faible latence. Vous disposez de deux options de stockage avec le stockage de blocs : disques SSD local et Persistent Disk.
SSD local
Le disque SSD local fournit un stockage local directement sur une VM ou sur un conteneur. La plupart des types de machines Google Cloud contenant des GPU Cloud incluent une certaine quantité de disques SSD locaux. Les disques SSD locaux étant associés physiquement aux GPU Cloud, ils fournissent un accès à faible latence, avec potentiellement des millions d'IOPS. En revanche, les instances basées sur Cloud TPU n'incluent pas de disques SSD locaux.
Bien que les disques SSD locaux offrent de hautes performances, chaque instance de stockage est éphémère. Ainsi, les données stockées sur un disque SSD local sont perdues lorsque vous arrêtez ou supprimez l'instance. En raison de la nature éphémère des disques SSD locaux, envisagez d'autres types de stockage lorsque vos données nécessitent une meilleure durabilité.
Cependant, lorsque la quantité de données d'entraînement est très faible, il est courant de les copier depuis Cloud Storage vers le disque SSD local d'un GPU. En effet, les disques SSD locaux offrent une latence d'E/S plus faible et une durée d'entraînement réduite.
Pour en savoir plus sur les disques SSD locaux, consultez la page À propos des disques SSD locaux. Pour en savoir plus sur la capacité SSD locale disponible pour les types d'instances avec GPU Cloud, consultez la page Plates-formes GPU.
Persistent Disk
Persistent Disk est un service de stockage de blocs réseau qui offre une suite complète de fonctionnalités de persistance et de gestion des données. En plus de son utilisation comme disque de démarrage, vous pouvez utiliser Persistent Disk avec des charges de travail d'IA, par exemple pour le stockage de données. Persistent Disk est disponible avec les options suivantes :
- Standard : fournit un stockage de blocs efficace et fiable.
- Équilibré : fournit un stockage de blocs économique et fiable.
- SSD : fournit un stockage de blocs rapide et fiable.
- Extrême : fournit le stockage de blocs aux meilleures performances avec des IOPS personnalisables.
Pour en savoir plus sur Persistent Disk, consultez la page Persistent Disk.
Outils de transfert de données
Lorsque vous effectuez des tâches d'IA et de ML, il peut arriver que vous ayez besoin de copier vos données d'un emplacement à un autre. Par exemple, si vos données sont initialement stockées dans Cloud Storage, vous pouvez les déplacer ailleurs pour entraîner le modèle, puis copier les instantanés de point de contrôle ou le modèle entraîné dans Cloud Storage. Vous pouvez également effectuer la plupart de vos tâches dans Filestore, puis déplacer vos données et votre modèle dans Cloud Storage à des fins d'archivage. Cette section décrit les options disponibles pour déplacer des données entre différents services de stockage dans Google Cloud.
Service de transfert de stockage
Avec le service de transfert de stockage, vous pouvez transférer vos données entre Cloud Storage, Filestore et NetApp Volumes. Ce service entièrement géré vous permet également de copier des données entre vos dépôts de stockage de fichiers et d'objets sur site, votre stockage Google Cloud et depuis d'autres fournisseurs de services cloud. Le service de transfert de stockage vous permet de copier vos données de manière sécurisée de l'emplacement source vers l'emplacement cible, et de transférer périodiquement les données modifiées. Il fournit également une validation de l'intégrité des données, des nouvelles tentatives automatiques et un équilibrage de charge.
Pour en savoir plus sur le service de transfert de stockage, consultez la page Qu'est-ce que le service de transfert de stockage ?
Options de l'interface de ligne de commande
Lorsque vous déplacez des données entre Filestore et Cloud Storage, vous pouvez utiliser les outils suivants :
- gcloud storage (recommandé) : créez et gérez des buckets et des objets Cloud Storage avec un débit optimal et une suite complète de commandes gcloud CLI.
- gsutil : permet de gérer et d'assurer la maintenance des composants Cloud Storage. Nécessite un réglage pour obtenir un meilleur débit.
Mapper vos options de stockage aux étapes d'IA et de ML
Cette section développe le résumé fourni dans le tableau 1 pour explorer les recommandations et les conseils spécifiques pour chaque étape d'une charge de travail d'IA et de ML. L'objectif est de vous aider à comprendre la logique de ces choix et à sélectionner les meilleures options de stockage pour chaque étape d'IA et de ML. Cette analyse génère trois recommandations principales explorées dans la section Recommandations de stockage pour l'IA et le ML.
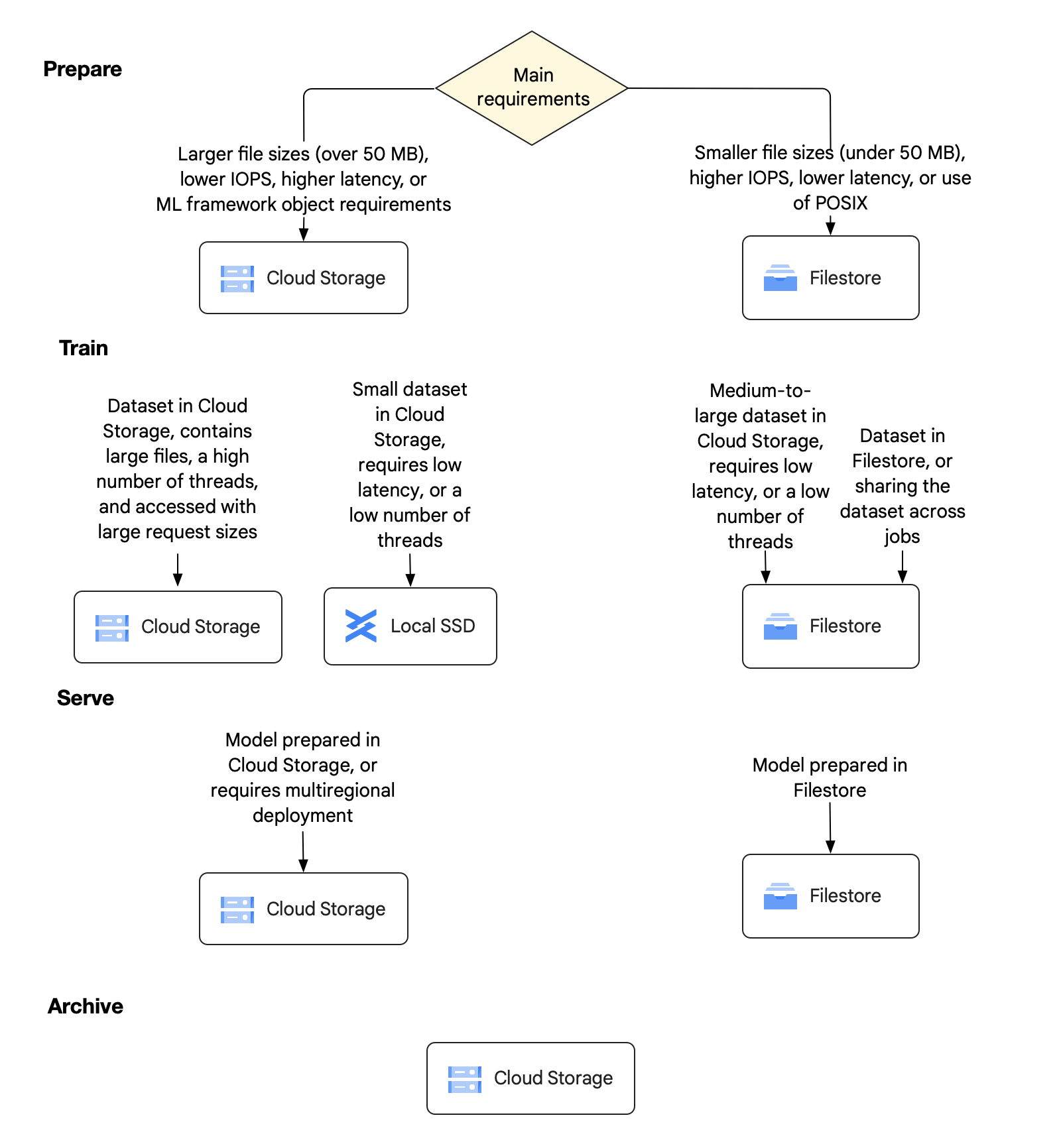
La figure suivante fournit un arbre de décision qui présente les options de stockage recommandées pour les quatre principales étapes d'une charge de travail d'IA et de ML. Le diagramme est suivi d'une explication détaillée de chaque étape et des choix que vous pouvez faire pour chacune d'entre elles.
Figure 3 : Options de stockage pour chaque étape d'IA et de ML
Préparation
À cette étape initiale, vous devez choisir si vous souhaitez utiliser Cloud Storage ou Filestore comme source de vérité persistante pour vos données. Vous pouvez également sélectionner des optimisations potentielles pour un entraînement qui utilise beaucoup de données. Sachez que les différentes équipes de votre organisation peuvent avoir des types de charges de travail et d'ensembles de données variables qui peuvent les amener à prendre des décisions différentes en matière de stockage. Pour répondre à ces besoins variés, vous pouvez combiner vos choix de stockage entre Cloud Storage et Filestore en conséquence.
Cloud Storage pour l'étape de préparation
- Votre charge de travail contient des fichiers volumineux de 50 Mo ou plus.
- Votre charge de travail nécessite un nombre réduit d'IOPS.
Votre charge de travail peut tolérer une latence de stockage plus élevée de quelques dizaines de millisecondes.
Vous devez accéder à l'ensemble de données via les API Cloud Storage ou via Cloud Storage FUSE et un sous-ensemble d'API de fichiers.
Pour optimiser votre charge de travail dans Cloud Storage, vous pouvez sélectionner un stockage régional et placer votre bucket dans la même région que vos ressources de calcul. Toutefois, si vous avez besoin d'une fiabilité plus élevée ou si vous utilisez des accélérateurs situés dans deux régions différentes, vous devez sélectionner le stockage birégional.
Filestore pour l'étape de préparation
Vous devez sélectionner Filestore pour préparer vos données si l'une des conditions suivantes s'applique :
- Votre charge de travail contient des fichiers d'une taille inférieure à 50 Mo.
- Votre charge de travail nécessite un nombre plus élevé d'IOPS.
- Votre charge de travail nécessite une latence inférieure à une milliseconde pour répondre aux exigences de stockage pour l'accès aléatoire aux E/S et aux métadonnées.
- Vos utilisateurs ont besoin d'une expérience semblable à un ordinateur avec compatibilité POSIX complète pour afficher et gérer les données.
- Vos utilisateurs doivent effectuer d'autres tâches, comme le développement de logiciels.
Autres éléments à prendre en compte pour l'étape de préparation
Si vous avez du mal à choisir une option à ce stade, tenez compte des points suivants pour vous aider à prendre votre décision :
- Si vous souhaitez utiliser d'autres frameworks d'IA et de ML, tels que Dataflow, Spark ou BigQuery sur l'ensemble de données, Cloud Storage est un choix logique en raison de l'intégration personnalisée avec ces types de frameworks.
- Filestore a une capacité maximale d'environ 100 To. Si vous devez entraîner votre modèle avec des ensembles de données plus volumineux ou si vous ne pouvez pas diviser l'ensemble en plusieurs instances de 100 To, Cloud Storage constitue une meilleure option.
Au cours de la phase de préparation des données, de nombreux utilisateurs réorganisent leurs données en grands fragments pour améliorer l'efficacité d'accès et éviter les requêtes de lecture aléatoires. Pour réduire davantage les exigences de performances d'E/S sur le système de stockage, de nombreux utilisateurs utilisent les pipelines ou l'optimisation d'entraînement (voire les deux) pour augmenter le nombre de threads d'E/S.
Entraîner
Lors de l'entraînement, vous réutilisez généralement l'option de stockage principale que vous avez sélectionnée pour l'étape de préparation. Si votre choix de stockage principal ne peut pas gérer seul la charge de travail d'entraînement, vous devrez peut-être compléter l'espace de stockage principal. Vous pouvez ajouter un espace de stockage supplémentaire selon vos besoins (disques SSD locaux, par exemple) pour équilibrer la charge de travail.
En plus de fournir des recommandations pour l'utilisation de Cloud Storage ou de Filestore à ce stade, cette section vous fournit plus de détails sur ces recommandations. Ces détails incluent les suivants :
- Conseils concernant les tailles de fichier et les tailles de requêtes
- Suggestions pour compléter votre choix de stockage principal
- Une explication des détails de mise en œuvre pour les deux charges de travail clés à ce stade : chargement des données, et création de points de contrôle et redémarrage
Cloud Storage pour l'étape d'entraînement
Voici les principales raisons de sélectionner Cloud Storage pour l'entraînement de vos données :
- Si vous utilisez Cloud Storage pour préparer vos données, il est préférable d'effectuer l'entraînement dans Cloud Storage.
- Cloud Storage est une solution idéale pour le débit, pour les charges de travail ne nécessitant pas un débit élevé sur une seule VM ou pour les charges de travail qui utilisent de nombreux threads pour augmenter le débit selon les besoins.
Cloud Storage avec un disque SSD local ou Filestore pour l'étape d'entraînement
La principale raison de choisir Cloud Storage avec disque SSD local ou Filestore pour l'entraînement de vos données est la nécessité de prendre en charge de petites requêtes d'E/S petites ou de petits fichiers. Dans ce cas, vous pouvez compléter votre tâche d'entraînement Cloud Storage en déplaçant certaines des données vers un disque SSD local ou vers Filestore zonal.
Filestore pour l'étape d'entraînement
Les principales raisons de sélectionner Filestore pour l'entraînement de vos données sont les suivantes :
- Si vous utilisez Filestore lorsque vous préparez vos données, dans la plupart des cas, vous devez continuer l'entraînement dans Filestore.
- Filestore est un bon choix pour obtenir une latence plus faible, pour atteindre un débit par client élevé et pour les applications qui utilisent un faible nombre de threads mais nécessitent toujours des performances élevées.
- Si vous devez compléter vos tâches d'entraînement dans Filestore, envisagez de créer un cache SSD local si nécessaire.
Tailles des fichiers et tailles des requêtes
Une fois l'ensemble de données prêt pour l'entraînement, deux options principales peuvent vous aider à évaluer les différentes options de stockage.
- Ensembles de données contenant des fichiers volumineux auxquels l'accès se fait avec des requêtes de grande taille
- Ensembles de données contenant des fichiers de petite à moyenne taille, ou auxquels l'accès se fait avec des requêtes de petite taille
Ensembles de données contenant des fichiers volumineux auxquels l'accès se fait avec des requêtes de grande taille
Dans cette option, le job d'entraînement inclut principalement des fichiers volumineux de 50 Mo ou plus. Le job d'entraînement ingère les fichiers dont la taille varie de 1 à 16 Mo. Nous recommandons généralement Cloud Storage avec Cloud Storage FUSE pour cette option, car les fichiers sont suffisamment volumineux pour que Cloud Storage puisse alimenter en continu les accélérateurs. Gardez à l'esprit que vous aurez peut-être besoin de centaines, voire de milliers de threads pour obtenir des performances maximales avec cette option.
Toutefois, si vous avez besoin d'API POSIX complètes pour d'autres applications ou si votre charge de travail n'est pas adaptée au nombre élevé de threads requis, Filestore est une bonne alternative.
Ensembles de données contenant des fichiers de petite à moyenne taille, ou auxquels l'accès se fait avec des requêtes de petite taille
Avec cette option, vous pouvez classer votre job d'entraînement de deux manières :
- Beaucoup de fichiers de petite à moyenne taille de moins de 50 Mo.
- Un ensemble de données contenant des fichiers plus volumineux, mais dont les données sont lues de manière séquentielle ou aléatoire avec des requêtes de lecture de taille relativement petite (par exemple, inférieures à 1 Mo). Ce cas d'utilisation peut par exemple se produire lorsque le système lit moins de 100 Ko à la fois à partir d'un fichier de plusieurs gigaoctets ou plusieurs téraoctets.
Si vous utilisez déjà Filestore pour ses fonctionnalités POSIX, nous vous recommandons de conserver vos données dans Filestore pour l'entraînement. Filestore offre un accès aux données à faible latence d'E/S. Cette latence plus faible peut réduire la durée globale d'entraînement et réduire le coût d'entraînement de votre modèle.
Si vous utilisez Cloud Storage pour stocker vos données, nous vous recommandons de les copier sur un disque SSD local ou sur Filestore avant l'entraînement.
Chargement des données
Lors du chargement des données, les GPU Cloud ou les Cloud TPU importent des lots de données de manière répétée pour entraîner le modèle. Cette phase peut être compatible avec la mise en cache, en fonction de la taille des lots et de l'ordre dans lequel vous les demandez. À ce stade, votre objectif est d'entraîner le modèle avec une efficacité maximale, mais au moindre coût.
Si la taille de vos données d'entraînement peut atteindre plusieurs pétaoctets, vous devrez peut-être les relire plusieurs fois. Une telle échelle nécessite un traitement intensif via un accélérateur GPU ou TPU. Cependant, vous devez vous assurer que vos GPU Cloud et vos Cloud TPU ne sont pas inactifs, mais qu'ils traitent vos données activement. Sinon, un accélérateur coûteux et inactif vous sera facturé pendant la copie des données d'un emplacement à un autre.
Pour le chargement des données, tenez compte des points suivants :
- Parallélisme : il existe de nombreuses façons de paralléliser l'entraînement. Chacune d'elles peut avoir un impact sur les performances globales de stockage requises et sur la nécessité de mise en cache des données localement sur chaque instance.
- Nombre maximal de GPU Cloud ou de Cloud TPU pour un seul job d'entraînement : à mesure que le nombre d'accélérateurs et de VM augmente, l'impact sur le système de stockage peut être important et peut entraîner une augmentation des coûts si les GPU Cloud ou les Cloud TPU sont inactifs. Cependant, il existe des moyens de réduire les coûts lorsque vous augmentez le nombre d'accélérateurs. Selon le type de parallélisme que vous utilisez, vous pouvez réduire les coûts en augmentant les exigences de débit de lecture globales nécessaires pour éviter les accélérateurs inactifs.
Pour profiter de ces améliorations dans Cloud Storage ou Filestore, vous devez ajouter un disque SSD local à chaque instance afin de pouvoir décharger les E/S du système de stockage surchargé.
Cependant, le préchargement des données dans le disque SSD local de chaque instance à partir de Cloud Storage présente ses propres défis. Vous risquez de générer une augmentation des coûts liés aux accélérateurs inactifs lors du transfert des données. Si vos délais de transfert de données et vos coûts d'inactivité des accélérateurs sont élevés, vous pourrez peut-être réduire les coûts en utilisant Filestore avec un disque SSD local.
- Nombre de GPU sur Google Cloud par instance : lorsque vous déployez davantage de GPU Cloud sur chaque instance, vous pouvez augmenter le débit des GPU Cloud avec NVLink. Cependant, le débit réseau disponible pour les disques SSD locaux et le stockage n'augmente pas toujours de manière linéaire.
- Optimisations du stockage et des applications : les options de stockage et les applications ont des exigences de performances spécifiques pour s'exécuter de manière optimale. Veillez à équilibrer ces exigences de stockage et d'application avec vos optimisations de chargement des données, en veillant à ce que vos GPU Cloud ou Cloud TPU soient sollicités et fonctionnent efficacement.
Création de points de contrôle et redémarrage
Pour la création de points de contrôle et le redémarrage, les jobs d'entraînement doivent enregistrer régulièrement leur état afin de pouvoir récupérer rapidement en cas de défaillance d'une instance. En cas d'échec, les jobs doivent redémarrer, ingérer le dernier point de contrôle, puis reprendre l'entraînement. Le mécanisme exact utilisé pour créer et ingérer des points de contrôle est généralement spécifique à un framework, tel que TensorFlow ou PyTorch. Certains utilisateurs ont créé des frameworks complexes pour améliorer l'efficacité de la création de points de contrôle. Ces frameworks complexes leur permettent de créer plus fréquemment des points de contrôle.
Cependant, la plupart des utilisateurs utilisent généralement un espace de stockage partagé, tel que Cloud Storage ou Filestore. Lorsque vous enregistrez des points de contrôle, vous n'avez besoin d'enregistrer que trois à cinq points de contrôle à un moment donné. Les charges de travail de point de contrôle ont tendance à se composer principalement d'écritures, de quelques suppressions et, idéalement, de lectures peu fréquentes en cas d'échec. Lors de la récupération, le modèle d'E/S inclut des écritures intensives et fréquentes, des suppressions fréquentes et des lectures fréquentes du point de contrôle.
Vous devez également tenir compte de la taille du point de contrôle que chaque GPU ou TPU doit créer. La taille du point de contrôle détermine le débit en écriture requis pour effectuer le job d'entraînement de manière rentable et rapide.
Pour réduire les coûts, envisagez d'augmenter les éléments suivants :
- La fréquence des points de contrôle
- Le débit en écriture global requis pour les points de contrôle
- L'efficacité du redémarrage
Diffuser
Lorsque vous diffusez votre modèle (on parle également d'inférence d'IA), le modèle d'E/S principal est en lecture seule pour charger le modèle dans la mémoire des GPU Cloud ou des Cloud TPU. À ce stade, votre objectif est d'exécuter votre modèle en production. Le modèle est beaucoup plus petit que les données d'entraînement. Vous pouvez donc le répliquer et le mettre à l'échelle sur plusieurs instances. La haute disponibilité et la protection contre les défaillances zonales et régionales sont importantes à ce stade. Vous devez donc vous assurer que votre modèle est disponible pour divers scénarios de défaillance.
Dans de nombreux cas d'utilisation de l'IA générative, les données d'entrée dans le modèle peuvent être assez petites et ne pas avoir besoin d'être stockées de manière persistante. Dans d'autres cas, vous devrez peut-être utiliser de grands volumes de données sur le modèle (par exemple, des ensembles de données scientifiques). Dans ce cas, vous devez sélectionner une option permettant de conserver les GPU Cloud ou les Cloud TPU fournis lors de l'analyse de l'ensemble de données, et de sélectionner un emplacement persistant pour stocker les résultats d'inférence.
Deux options principales s'offrent à vous lorsque vous diffusez votre modèle.
Cloud Storage pour l'étape de diffusion
Les principales raisons de choisir Cloud Storage pour la diffusion de vos données sont les suivantes :
- Lorsque vous entraînez votre modèle dans Cloud Storage, vous pouvez réduire les coûts de migration en le laissant dans Cloud Storage lorsque vous le diffusez.
- Vous pouvez enregistrer le contenu généré dans Cloud Storage.
- Cloud Storage est un bon choix lorsque l'inférence d'IA se produit dans plusieurs régions.
- Vous pouvez utiliser des buckets birégionaux et multirégionaux pour garantir la disponibilité des modèles en cas de défaillance régionale.
Filestore pour l'étape de diffusion
Les principales raisons de choisir Filestore pour la diffusion de vos données sont les suivantes :
- Lorsque vous entraînez votre modèle dans Filestore, vous pouvez réduire les coûts de migration en laissant le modèle dans Filestore lorsque vous le diffusez.
- Étant donné que son contrat de niveau de service offre une disponibilité de 99,99 %, le niveau de service Filestore Enterprise est un bon choix pour la haute disponibilité lorsque vous souhaitez diffuser votre modèle sur plusieurs zones d'une région.
- Les niveaux de service zonaux de Filestore peuvent être un choix raisonnable à moindre coût, mais seulement si la haute disponibilité n'est pas requise pour votre charge de travail d'IA et de ML.
- Si vous avez besoin d'une récupération interrégionale, vous pouvez stocker le modèle dans un emplacement de sauvegarde distant ou dans un bucket Cloud Storage distant, puis le restaurer si nécessaire.
- Filestore offre une option durable et hautement disponible pour un accès à faible latence à votre modèle lorsque vous générez de petits fichiers ou avez besoin d'API de fichiers.
Archiver
Le modèle d'E/S de l'étape d'archivage est "écriture unique, lecture rare". Votre objectif est de stocker les différents ensembles de données d'entraînement ainsi que les différentes versions des modèles que vous avez générés. Vous pouvez utiliser ces versions incrémentielles des données et des modèles à des fins de sauvegarde et de reprise après sinistre. Vous devez également stocker ces éléments dans un emplacement durable pendant une longue période. Même si vous n'avez pas particulièrement besoin d'accéder aux données et aux modèles, vous souhaitez que ces éléments soient disponibles lorsque vous en avez besoin.
En raison de sa durabilité extrême, de son évolutivité et de son faible coût, Cloud Storage constitue la meilleure option pour stocker des données d'objets sur une longue période. Selon la fréquence à laquelle vous accédez à l'ensemble de données, au modèle et aux fichiers de sauvegarde, Cloud Storage propose différentes classes de stockage pour l'optimisation des coûts, selon les approches suivantes :
- Placez les données fréquemment consultées dans un stockage standard.
- Conservez les données que vous consultez chaque mois dans un stockage Nearline.
- Stockez les données que vous consultez chaque trimestre dans un stockage Coldline.
- Stockez les données que vous consultez une fois par an dans un stockage Archive.
La gestion du cycle de vie des objets vous permet de créer des stratégies visant à déplacer des données vers des classes de stockage plus "froides" ou à supprimer des données en fonction de critères spécifiques. Si vous ne savez pas à quelle fréquence vous allez accéder à vos données, vous pouvez utiliser la classe automatique pour déplacer automatiquement les données d'une classe de stockage à une autre, en fonction de votre modèle d'accès.
Si vos données se trouvent dans Filestore, il est souvent judicieux de les déplacer vers Cloud Storage à des fins d'archivage. Toutefois, vous pouvez fournir une protection supplémentaire pour vos données Filestore en créant des sauvegardes Filestore dans une autre région. Vous pouvez également prendre des instantanés Filestore pour la récupération des systèmes de fichiers et des fichiers locaux. Pour en savoir plus sur les sauvegardes Filestore, consultez la présentation des sauvegardes. Pour en savoir plus sur les instantanés Filestore, consultez la présentation des instantanés.
Recommandations de stockage pour l'IA et le ML
Cette section récapitule l'analyse fournie dans la section précédente, Mapper vos choix de stockage aux étapes d'IA et de ML. Elle fournit des détails sur les trois principales combinaisons d'options de stockage que nous recommandons pour la plupart des charges de travail d'IA et de ML. Vous disposez des trois options suivantes :
- Choisir Cloud Storage
- Choisir Cloud Storage avec un disque SSD local ou Filestore
- Choisir Filestore avec un disque SSD local facultatif
Choisir Cloud Storage
Cloud Storage est l'offre de stockage avec le meilleur rapport prix/capacité par rapport à toutes les autres offres de stockage. elle s'adapte à un grand nombre de clients, offre une accessibilité et une disponibilité régionales et birégionales, et est accessible via Cloud Storage FUSE. Vous devez sélectionner le stockage régional lorsque votre plate-forme de calcul pour l'entraînement se trouve dans la même région, et choisir le stockage birégional si vous avez besoin d'une fiabilité plus élevée ou si vous utilisez des GPU Cloud ou des Cloud TPU situés dans deux régions différentes.
Cloud Storage est le meilleur choix pour la conservation des données à long terme et pour les charges de travail dont les exigences de performances de stockage sont inférieures. Cependant, d'autres options telles que Filestore et les disques SSD locaux constituent des alternatives utiles dans les cas spécifiques où vous avez besoin d'une compatibilité POSIX complète ou lorsque Cloud Storage devient un goulot d'étranglement des performances.
Choisir Cloud Storage avec un disque SSD local ou Filestore
Pour les charges de travail d'entraînement ou de création de points de contrôle et redémarrage qui utilisent beaucoup de données, il peut être judicieux d'utiliser une offre de stockage plus rapide pendant la phase d'entraînement intensive en E/S. Les options classiques incluent la copie des données sur un disque SSD local ou sur Filestore. Cette action réduit la durée d'exécution globale du job en alimentant en permanence en données les GPU Cloud ou Cloud TPU. Elle empêche également le blocage des instances pendant la durée des opérations de cré"ation de point de contrôle. En outre, plus vous créez des points de contrôle fréquemment, plus vous disposez de points de contrôle en tant que sauvegardes. Cette augmentation du nombre de sauvegardes augmente également le taux global d'arrivée des données utiles (également appelé goodput). Cette combinaison d'optimisation des processeurs et d'augmentation du "goodput" réduit les coûts globaux d'entraînement de votre modèle.
Il existe des compromis à prendre en compte lors de l'utilisation de disques SSD locaux ou de Filestore. La section suivante décrit certains avantages et inconvénients pour chacune d'entre elles.
Avantages des disques SSD locaux
- Haut débit et IOPS une fois les données transférées
- Coûts supplémentaires faibles ou minimes
Inconvénients des disques SSD locaux
- Les GPU Cloud ou Cloud TPU restent inactifs pendant le chargement des données.
- Le transfert de données doit avoir lieu sur chaque job, pour chaque instance.
- Ne sont disponible que pour certains types d'instances avec GPU Cloud.
- Fournissent une capacité de stockage limitée.
- Compatible avec la création de points de contrôle, mais vous devez les transférer manuellement vers une option de stockage durable, telle que Cloud Storage.
Avantages de Filestore
- Fournit un espace de stockage NFS partagé qui permet de transférer des données une seule fois, puis de les partager entre plusieurs jobs et utilisateurs.
- Il n'y a pas de GPU Cloud ou de Cloud TPU inactifs, car les données sont transférées avant que vous ne payez les GPU Cloud ou les Cloud TPU.
- Offre une grande capacité de stockage.
- Permet la création de points de contrôle rapides pour des milliers de VM.
- Compatible avec les GPU Cloud, les Cloud TPU et tous les autres types d'instances Compute Engine.
Inconvénients de Filestore
- Coûts initiaux élevés Toutefois, l'efficacité de calcul accrue peut réduire les coûts globaux d'entraînement.
Choisir Filestore avec un disque SSD local facultatif
Filestore est le meilleur choix pour les charges de travail d'IA et de ML qui nécessitent une faible latence et une compatibilité POSIX complète. En plus d'être le choix recommandé pour les petits fichiers ou les jobs d'entraînement à faibles E/S, Filestore peut offrir une expérience réactive pour les notebooks d'IA et de ML, le développement de logiciels et de nombreuses autres applications. Vous pouvez également déployer Filestore dans une zone pour un entraînement hautes performances et un stockage persistant des points de contrôle. Le déploiement de Filestore dans une zone permet également un redémarrage rapide en cas de défaillance. Vous pouvez également déployer Filestore au niveau régional pour prendre en charge les jobs d'inférence à disponibilité élevée. L'ajout facultatif de FS-Cache pour la mise en cache des disques SSD locaux permet des lectures rapides et répétées des données d'entraînement pour optimiser les charges de travail.
Étapes suivantes
Pour plus d'informations sur les options de stockage, ainsi que sur l'IA et le ML, consultez les ressources suivantes :
- Concevez une stratégie de stockage optimale pour votre charge de travail cloud
- Présentation du produit Cloud Storage
- Cloud Storage FUSE
- Présentation de Filestore
- À propos des disques SSD locaux
- Présentation du service de transfert de stockage
- Présentation de Vertex AI
- Étendre la joignabilité du réseau de Vertex AI Pipelines
- Vidéo : Accédez plus rapidement et plus facilement à des ensembles de données plus volumineux pour accélérer l'entraînement de vos modèles de ML dans Vertex AI | Google Cloud
- Cloud Storage en tant que système de fichiers pour l'entraînement d'IA
- Lire et stocker des données pour l'entraînement personnalisé de modèles sur Vertex AI | Blog Google Cloud
Contributeurs
Auteurs :
- Dean Hildebrand | Directeur technique, bureau du directeur de la technologie
- Sean Derrington | Group Outbound Product Manager, Stockage
- Richard Hendricks | Personnel du centre d'architecture
Autre contributeur : Kumar Dhanagopal | Développeur de solutions multi-produits