Dieser Artikel ist Teil einer Reihe zur Notfallwiederherstellung (Disaster Recovery, DR) in Google Cloud. In diesem Teil wird der Ablauf zur Architekturplanung von Arbeitslasten mit Google Cloud und von Bausteinen diskutiert, die gegen Ausfälle der Cloud-Infrastruktur resistent sind.
Die Reihe besteht aus folgenden Teilen:
- Leitfaden zur Planung der Notfallwiederherstellung
- Bausteine der Notfallwiederherstellung
- Szenarien der Notfallwiederherstellung von Daten
- Szenarien der Notfallwiederherstellung von Anwendungen
- Architektur der Notfallwiederherstellung von Arbeitslasten mit Standortbeschränkung entwickeln
- Anwendungsfälle für die Notfallwiederherstellung: Datenanalyseanwendungen mit Standortbeschränkung
- Architektur der Notfallwiederherstellung für Ausfälle der Cloud-Infrastruktur entwickeln (dieses Dokument)
Einführung
Wenn Unternehmen ihre Arbeitslasten in die öffentliche Cloud verschieben, müssen ihre Kenntnisse der Entwicklung belastbarer, lokaler Systeme auf die Hyperscale-Infrastruktur von Cloud-Anbietern wie Google Cloud übertragen werden. In diesem Artikel werden Branchenstandards zur Notfallwiederherstellung wie RTO (Recovery Time Objective) und RPO (Recovery Point Objective) der Google Cloud-Infrastruktur zugeordnet.
Die Anleitung in diesem Dokument entspricht einem der Hauptgrundsätze von Google zum Erzielen einer extrem hohen Dienstverfügbarkeit: Auf Ausfälle vorbereitet zu sein. Google Cloud arbeitet zwar äußerst zuverlässig, doch Katastrophen kommen vor – Naturkatastrophen, Glasfaserkabelbrüche und komplexe, unvorhersehbare Infrastrukturausfälle – und diese Katastrophen führen zu Ausfällen. Die richtige Vorbereitung auf Ausfälle ermöglicht es Google Cloud-Kunden, Anwendungen zu erstellen, die bei diesen unvermeidlichen Ereignissen eine vorhersehbare Leistung erzielen. Dazu wenden Google Cloud-Produkte "integrierte" DR-Mechanismen an.
Die Notfallwiederherstellung ist ein breites Thema, das weit mehr umfasst als nur Infrastrukturausfälle, wie z. B. Software-Fehler oder Datenschäden, und Sie sollten einen umfassenden End-to-End-Plan haben. Der Schwerpunkt dieses Artikels liegt jedoch auf einem Teil eines DR-Plans: Wie werden Anwendungen entworfen, die gegen Ausfälle der Cloud-Infrastruktur resistent sind? Dieser Artikel behandelt folgende Themen:
- Die Google Cloud-Infrastruktur, wie sich Katastrophenereignisse als Ausfälle der Google Cloud manifestieren und wie die Google Cloud konzipiert ist, sodass die Häufigkeit und der Umfang von Ausfällen minimiert werden.
- Einen Leitfaden zur Architekturplanung, der ein Framework zum Kategorisieren und Entwerfen von Anwendungen basierend auf der gewünschten Zuverlässigkeit bietet.
- Eine detaillierte Liste ausgewählter Google Cloud-Produkte mit integrierten DR-Funktionen, die Sie in Ihrer Anwendung verwenden können.
Weitere Informationen zur allgemeinen DR-Planung und zur Verwendung von Google Cloud als Komponente in Ihrer lokalen DR-Strategie finden Sie im Leitfaden zur Planung der Notfallwiederherstellung. Die Hochverfügbarkeit ist zwar eng mit der Notfallwiederherstellung verbunden, wird in diesem Artikel jedoch nicht behandelt. Weitere Informationen zur Architektur für Hochverfügbarkeit finden Sie im Architektur-Framework von Google Cloud.
Ein Hinweis zur Terminologie: Dieser Artikel bezieht sich auf Verfügbarkeit, wenn es darum geht, dass ein Produkt im Laufe der Zeit sinnvoll aufgerufen und genutzt werden soll. Zuverlässigkeit hingegen bezieht sich auf eine Reihe von Attributen, einschließlich Verfügbarkeit, aber auch Langlebigkeit und Richtigkeit.
Wie Google Cloud auf Ausfallsicherheit setzt
Google-Rechenzentren
In traditionellen Rechenzentren wird die Verfügbarkeit einzelner Komponenten maximiert. In der Cloud ermöglicht die Skalierbarkeit es Betreibern wie Google, Dienste über viele Komponenten mithilfe von Virtualisierungstechnologien zu verteilen und so die Zuverlässigkeit herkömmlicher Komponenten zu übertreffen. Sie können mit Ihrer Denkweise der Zuverlässigkeitsarchitektur nun also von den unzähligen Details abrücken, um die Sie sich früher lokal Sorgen gemacht haben. Sie müssen sich nicht mehr um die verschiedenen Fehlermodi von Komponenten wie Kühlung oder Stromversorgung kümmern, sondern können mit den Google Cloud-Produkten und ihren angegebenen Zuverlässigkeitsmesswerten planen. Diese Messwerte spiegeln das aggregierte Ausfallrisiko der gesamten zugrunde liegenden Infrastruktur wider. So können Sie sich anstatt um die Infrastrukturverwaltung mehr um das Design, die Bereitstellung und den Betrieb von Anwendungen kümmern.
Google entwirft basierend auf der umfangreichen Erfahrung beim Aufbau und dem Betrieb moderner Rechenzentren seine Infrastruktur so, dass aggressive Verfügbarkeitsziele erreicht werden. Google ist bei Rechenzentren weltweit führend. Von der Stromversorgung über die Kühlung bis hin zu Netzwerken hat jede Rechenzentrumstechnologie ihre eigenen Redundanzen und Abhilfemaßnahmen, einschließlich FMEA-Pläne. Die Rechenzentren von Google sind so aufgebaut, dass sie diese vielen verschiedenen Risiken ausgleichen und den Kunden eine konsistente erwartete Verfügbarkeit der Google Cloud-Produkte bieten. Google nutzt seine Erfahrung, um die Verfügbarkeit der gesamten physischen und logischen Systemarchitektur zu modellieren, damit die Rechenzentren den Erwartungen entsprechen. Die Entwickler von Google setzen alles daran, dass diese Erwartungen erfüllt werden können. Die tatsächlich gemessene Verfügbarkeit übertrifft unsere Ziele in der Regel um einiges.
Durch die Zusammenfassung all dieser Rechenzentrumsrisiken und -maßnahmen in nutzerorientierte Produkte entlastet Google Cloud Sie von diesen Design- und Betriebsverantwortlichkeiten. Stattdessen können Sie sich auf die Zuverlässigkeit konzentrieren, die in Google Cloud-Regionen und -Zonen integriert wurde.
Regionen und Zonen
Google Cloud-Produkte werden in einer Vielzahl von Regionen und Zonen angeboten. Regionen sind physisch unabhängige geografische Gebiete, die drei oder mehr Zonen enthalten. Zonen stellen physische Computerressourcen innerhalb einer Region dar, die im Hinblick auf die physische und logische Infrastruktur einen hohen Grad an Unabhängigkeit haben. Sie bieten anderen Zonen in derselben Region Netzwerkverbindungen mit hoher Bandbreite und niedriger Latenz. Die Region asia-northeast1 in Japan enthält beispielsweise drei Zonen: asia-northeast1-a, asia-northeast1-b und asia-northeast1-c.
Google Cloud-Produkte sind in zonale Ressourcen, regionale Ressourcen oder multiregionale Ressourcen unterteilt.
Zonale Ressourcen werden in einer einzigen Zone gehostet. Eine Dienstunterbrechung in dieser Zone kann sich auf alle Ressourcen in dieser Zone auswirken. Beispielsweise wird eine Compute Engine-Instanz in einer einzelnen, angegebenen Zone ausgeführt. Wenn ein Hardwarefehler einen Ausfall in dieser Zone hervorruft, ist diese Compute Engine-Instanz während der Unterbrechung nicht verfügbar.
Regionale Ressourcen werden redundant in mehreren Zonen innerhalb einer Region bereitgestellt. Sie haben eine höhere Zuverlässigkeit als zonale Ressourcen.
Multiregionale Ressourcen werden innerhalb und zwischen den Regionen verteilt. Im Allgemeinen haben multiregionale Ressourcen eine höhere Zuverlässigkeit als regionale Ressourcen. Auf dieser Ebene müssen die Produkte jedoch Verfügbarkeit, Leistung und Ressourceneffizienz optimieren. Deshalb ist es wichtig, die Vor- und Nachteile der Verwendung eines multiregionalen Produkts zu verstehen. Diese Nachteile werden weiter unten in diesem Dokument produktspezifisch beschrieben.
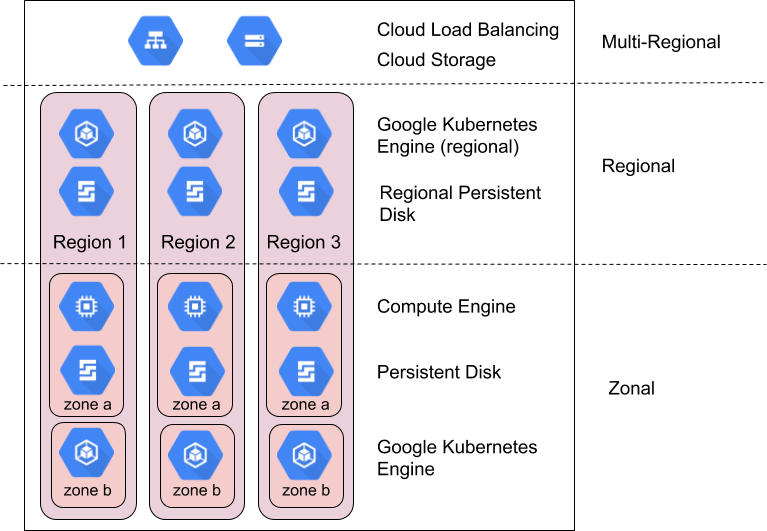
Wie Sie Zonen und Regionen nutzen, um Zuverlässigkeit zu erreichen
Google SREs verwalten und skalieren hochzuverlässige, globale Nutzerprodukte wie Gmail und die Google Suche mithilfe einer Vielzahl von Techniken und Technologien, die eine nahtlose Nutzung der Computing-Infrastruktur auf der ganzen Welt ermöglichen. Dies beinhaltet das Weiterleiten von Traffic von nicht verfügbaren Standorten mithilfe von globalem Load-Balancing, die Ausführung mehrerer Replikate an vielen Standorten auf der Welt und die Replikation von Daten zwischen Standorten. Diese Funktionen stehen Google Cloud-Kunden über Produkte wie Cloud Load Balancing, Google Kubernetes Engine (GKE) und Spanner zur Verfügung.
Google Cloud entwirft im Allgemeinen Produkte, die die folgenden Verfügbarkeitsstufen für Zonen und Regionen ermöglichen:
| Ressource | Beispiele | Ziele für das Verfügbarkeitsdesign | Implizierte Ausfallzeiten |
|---|---|---|---|
| Zonal | Compute Engine, Persistent Disk | 99,9 % | 8,75 Stunden/Jahr |
| Regional | Regionaler Cloud Storage, replizierte Persistent Disk, regionale GKE | 99,99 % | 52 Minuten/Jahr |
Vergleichen Sie die Ziele für das Verfügbarkeitsdesign von Google Cloud mit der für Sie akzeptablen Ausfallzeit, um die entsprechenden Google Cloud-Ressourcen zu ermitteln. Während sich herkömmliche Designs auf die Verbesserung der Verfügbarkeit auf Komponentenebene konzentrieren, um die resultierende Anwendungsverfügbarkeit zu verbessern, konzentrieren sich Cloud-Modelle stattdessen auf die Zusammensetzung von Komponenten, um dieses Ziel zu erreichen. Viele Produkte in Google Cloud verwenden diese Technik. Spanner bietet beispielsweise eine multiregionale Datenbank mit mehreren Regionen, um eine Verfügbarkeit von 99,999 % zu ermöglichen.
Die Zusammensetzung ist wichtig, da ohne sie die Verfügbarkeit Ihrer Anwendung nicht höher sein kann als die der von Ihnen verwendeten Google Cloud-Produkte. Außer Ihre Anwendung fällt nie aus, hat sie sogar eine geringere Verfügbarkeit als die zugrunde liegenden Google Cloud-Produkte. Der Rest dieses Abschnitts zeigt allgemein, wie Sie mit einer Zusammensetzung aus zonalen und regionalen Produkten eine höhere Anwendungsverfügbarkeit als mit einer einzelnen Zone oder Region erreichen können. Im nächsten Abschnitt finden Sie einen praktischen Leitfaden zum Anwenden dieser Prinzipien auf Ihre Anwendungen.
Planung für zonale Ausfallbereiche
Infrastrukturausfälle verursachen in der Regel Dienstausfälle in einer einzelnen Zone. Innerhalb einer Region sind Zonen darauf ausgelegt, das Risiko von korrelierten Ausfällen mit anderen Zonen zu minimieren. Eine Dienstunterbrechung in einer Zone wirkt sich normalerweise nicht auf den Dienst in einer anderen Zone in derselben Region aus. Ein Ausfall, der auf eine Zone begrenzt ist, bedeutet nicht unbedingt, dass die gesamte Zone nicht verfügbar ist. Er definiert lediglich die Grenzen des Vorfalls. Möglicherweise hat ein Zonenausfall keine spürbaren Auswirkungen auf Ihre Ressourcen in dieser Zone.
Dies kommt selten vor. Es ist jedoch wichtig anzumerken, dass mehrere Zonen irgendwann innerhalb einer einzigen Region einen korrelierenden Ausfall erfahren werden. Wenn zwei oder mehr Zonen ausfallen, wird die unten beschriebene Strategie für den regionalen Ausfallbereich angewendet.
Regionale Ressourcen sind so konzipiert, dass sie Zonenausfälle tolerieren, indem sie einen Dienst aus mehreren Zonen bereitstellen. Wenn eine der Zonen, die eine regionale Ressource unterstützen, unterbrochen wird, stellt sich die Ressource automatisch selbst aus einer anderen Zone zur Verfügung. Lesen Sie die Beschreibung der Produktfähigkeiten im Anhang für weitere Einzelheiten sorgfältig durch.
Google Cloud bietet nur ein paar zonale Ressourcen, nämlich virtuelle Compute Engine-Maschinen (VMs) und Persistent Disk. Wenn Sie zonale Ressourcen verwenden möchten, müssen Sie Ihre eigene Ressourcenzusammensetzung durchführen, indem Sie Failover und Wiederherstellung zwischen zonalen Ressourcen, die sich in mehreren Zonen befinden, entwerfen, bauen und testen. Zu den Strategien gehören:
- Schnelles Routing Ihres Traffics zu virtuellen Maschinen in einer anderen Zone mithilfe von Cloud Load Balancing, wenn bei einer Systemdiagnose Probleme in einer Zone festgestellt werden.
- Mit Compute Engine-Instanzvorlagen und/oder verwalteten Instanzgruppen identische VM-Instanzen in mehreren Zonen ausführen und skalieren.
- Mit einer regionalen Persistent Disk Daten synchron in einer anderen Zone innerhalb einer Region replizieren. Weitere Informationen finden Sie unter Hochverfügbarkeitsoptionen mit regionalen Persistent Disks.
Planung für regionale Ausfallbereiche
Ein regionaler Ausfall ist eine Dienstunterbrechung, die sich auf mehrere Zonen in einer einzelnen Region auswirkt. Es handelt sich um größere, weniger häufige Ausfälle, die durch Naturkatastrophen oder umfangreiche Infrastrukturausfälle verursacht werden können.
Bei einem regionalen Produkt, das auf eine Verfügbarkeit von 99,99 % ausgelegt ist, kann ein Ausfall immer noch zu fast einer Stunde Ausfallzeit pro Jahr bei einem bestimmten Produkt führen. Daher müssen Ihre kritischen Anwendungen möglicherweise über einen Plan zur Notfallwiederherstellung für mehrere Regionen verfügen, wenn diese Ausfallzeit inakzeptabel ist.
Multiregionale Ressourcen sind so konzipiert, dass sie regionale Ausfälle tolerieren, indem sie Dienste aus mehreren Regionen bereitstellen. Wie oben beschrieben wird bei multiregionalen Produkten ein Kompromiss zwischen Latenzzeit, Konsistenz und Kosten eingegangen. Der häufigste Kompromiss besteht zwischen der synchronen und asynchronen Datenreplikation. Die asynchrone Replikation bietet eine geringere Latenzzeit auf Kosten des Risikos eines Datenverlusts während eines Ausfalls. Sehen Sie sich daher für weitere Informationen die Beschreibung der Produktfunktion im Anhang an.
Wenn Sie regionale Ressourcen nutzen und gegenüber regionalen Ausfällen widerstandsfähig bleiben möchten, müssen Sie Ihre eigene Ressourcenzusammensetzung vornehmen, indem Sie Failover und Wiederherstellung zwischen regionalen Ressourcen, die sich in mehreren Regionen befinden, entwerfen, bauen und testen. Zusätzlich zu den zonalen Strategien oben, die Sie auch regionenübergreifend anwenden können, empfehlen wir Folgendes:
- Regionale Ressourcen sollten Daten in eine sekundäre Region, in einen multi-regionalen Speicher wie Cloud Storage oder eine Hybrid-Cloud wie GKE Enterprise replizieren.
- Nachdem Sie eine regionale Ausfallminderung eingerichtet haben, testen Sie diese regelmäßig. Nichts ist schlimmer, als zu glauben, man sei gegen einen Ausfall einer einzelnen Region resistent, nur um im Fall der Fälle festzustellen, dass das nicht stimmt.
Google Cloud-Ansatz zu Ausfallsicherheit und Verfügbarkeit
Google Cloud übertrifft regelmäßig die eigenen Verfügbarkeitsziele. Sie sollten jedoch nicht davon ausgehen, dass diese bisherige starke Leistung die Mindestverfügbarkeit darstellt, für die Sie entwickeln können. Stattdessen sollten Sie Google Cloud-Abhängigkeiten auswählen, deren vorgesehene Ziele die beabsichtigte Zuverlässigkeit Ihrer Anwendung übersteigen, sodass die Summe der Ausfallzeit Ihrer Anwendung und von Google Cloud das gewünschte Ergebnis liefert.
Ein gut konzipiertes System kann die folgende Frage beantworten: "Was geschieht, wenn eine Zone oder Region 1, 5, 10 oder 30 Minuten ausfällt?" Dies sollte auf vielen Ebenen betrachtet werden, einschließlich:
- Wie erleben meine Kunden einen Ausfall?
- Wie erkenne ich, dass ein Ausfall vorliegt?
- Was passiert mit meiner Anwendung während eines Ausfalls?
- Was passiert mit meinen Daten während eines Ausfalls?
- Was passiert mit anderen Anwendungen bei einem Ausfall (aufgrund von gegenseitigen Abhängigkeiten)?
- Was muss ich tun, um die Wiederherstellung nach einem Ausfall zu gewährleisten? Wer erledigt sie?
- Wer muss innerhalb eines bestimmten Zeitraums über einen Ausfall informiert werden?
Detaillierte Anleitung zur Entwicklung der Notfallwiederherstellung für Anwendungen in Google Cloud
In den vorherigen Abschnitten wurde beschrieben, wie Google eine Cloud-Infrastruktur erstellt. Außerdem wurden einige Ansätze für den Umgang mit zonalen und regionalen Ausfällen beschrieben.
Dieser Abschnitt hilft Ihnen bei der Entwicklung eines Frameworks für die Anwendung des Zusammensetzungsprinzips auf Ihre Anwendungen, basierend auf den von Ihnen gewünschten Zuverlässigkeitswerten.
Kundenanwendungen in Google Cloud, die auf Ziele der Notfallwiederherstellung wie RTO und RPO abzielen, müssen so konzipiert werden, dass geschäftskritische Vorgänge gemäß RTO/RPO nur von Komponenten der Datenebene abhängig sind, die für für die kontinuierliche Verarbeitung von Vorgängen für den Dienst verantwortlich sind. Das bedeutet, dass geschäftskritische Vorgänge des Kunden nicht von den Vorgängen der Verwaltungsebene abhängen, die den Konfigurationsstatus verwalten und die Konfiguration an die Steuerungsebene und die Datenebene übertragen.
Beispielsweise sollten Google Cloud-Kunden, die einen RTO für geschäftskritische Vorgänge erreichen möchten, nicht von einer VM-Erstellungs-API oder der Aktualisierung einer Identitäts- und Zugriffsverwaltungsberechtigung abhängig sein.
Schritt 1: Vorhandene Anforderungen erfassen
Der erste Schritt besteht darin, die Verfügbarkeitsanforderungen für Ihre Anwendungen festzulegen. Die meisten Unternehmen haben bereits gewisse Design-Leitlinien in diesem Bereich, die intern entwickelt oder von Vorschriften oder anderen rechtlichen Erfordernissen abgeleitet worden sein können. Diese Design-Leitlinien werden normalerweise in zwei Messwerte unterteilt: "Recovery Time Objective (RTO)" und "Recovery Point Objective" (RPO). Aus geschäftlicher Sicht bedeutet RTO: "Wie schnell bin ich nach einem Notfall wieder einsatzbereit?". RPO bedeutet demnach: "Wie viele Daten darf ich im Falle eines Notfalls verlieren?".

In der Vergangenheit wurden von Unternehmen RTO- und RPO-Anforderungen für eine Vielzahl von Notfällen von Komponentenausfällen bis hin zu Erdbeben festgelegt. Dies war in lokalen Umgebungen sinnvoll, in der Planer die RTO-/RPO-Anforderungen über den gesamten Software- und Hardwarebereich abbilden mussten. In der Cloud müssen Sie Ihre Anforderungen nicht mehr derart genau bestimmen, da der Anbieter dies übernimmt. Stattdessen können Sie Ihre RTO- und RPO-Anforderungen in Bezug auf den Umfang des Verlusts (ganze Zonen oder Regionen) definieren, ohne die zugrunde liegenden Gründe anzugeben. Für Google Cloud vereinfacht dies Ihre Anforderungen auf 3 Szenarien: einen zonalen Ausfall, einen regionalen Ausfall oder den äußerst unwahrscheinlichen Ausfall mehrerer Regionen.
In dem Wissen, dass nicht jede Anwendung gleich kritisch ist, kategorisieren die meisten Kunden ihre Anwendungen in Kritikalitätsstufen, auf die eine bestimmte RTO/RPO-Anforderung angewendet werden kann. Zusammengenommen vereinfachen RTO/RPO und die Anwendungskritikalität die Erstellung einer bestimmten Anwendung durch Beantwortung der folgenden Fragen:
- Muss die Anwendung in mehreren Zonen in derselben Region oder in mehreren Zonen in mehreren Regionen ausgeführt werden?
- Von welchen Google Cloud-Produkten darf die Anwendung abhängen?
Dies ist ein Beispiel für das Ergebnis der Anforderungserhebung:
RTO und RPO nach Anwendungskritikalität für die Beispielfirma Co:
| Anwendungskritikalität | % der Apps | Beispiel-Apps | Zonenausfall | Regionsausfall |
|---|---|---|---|---|
| Stufe 1
(am wichtigsten) |
5 % | In der Regel globale oder kundenseitige Anwendungen wie Echtzeitzahlungen und E-Commerce-Verkäuferseiten. | RTO Null
RPO Null |
RTO Null
RPO Null |
| Preisstufe 2 | 35 % | In der Regel regionale Anwendungen oder wichtige interne Anwendungen wie CRM oder ERP. | RTO 15 Minuten
RPO 15 Minuten |
RTO 1 Stunde
RPO 1 Stunde |
| Stufe 3
(am wenigsten wichtig) |
60 % | In der Regel Team- oder Abteilungsanwendungen wie Backoffice, Abwesenheitsbuchungen, interne Reisen, Buchhaltung und Personalwesen. | RTO 1 Stunde
RPO 1 Stunde |
RTO 12 Std.
RPO 12 Stunden |
Schritt 2: Funktionszuordnung von verfügbaren Produkten
Im zweiten Schritt werden die Robustheitsfunktionen von Google Cloud-Produkten erläutert, die Ihre Anwendungen verwenden werden. Die meisten Unternehmen prüfen die relevanten Produktinformationen und fügen dann Anleitungen hinzu, wie sie ihre Architekturen modifizieren können, um Lücken zwischen den Produktfunktionen und ihren Robustheitsanforderungen zu schließen. In diesem Abschnitt werden einige gängige Bereiche und Empfehlungen zu Daten- und Anwendungseinschränkungen in diesem Bereich beschrieben.
Wie bereits erwähnt, bieten DR-fähige Produkte von Google im Allgemeinen zwei Arten von Ausfallbereichen: regionale und zonale. Partielle Ausfälle sollten für die Notfallwiederherstellung auf die gleiche Weise geplant werden wie ein Komplettausfall. Daraus ergibt sich eine erste Gesamtmatrix, welche Produkte standardmäßig für jedes Szenario geeignet sind:
Allgemeine Produktfunktionen von Google Cloud
(siehe Anhang für spezifische Produktfunktionen)
| Alle Google Cloud-Produkte | Regionale Google Cloud-Produkte mit automatischer Replikation über Zonen hinweg | Multiregionale oder globale Google Cloud-Produkte mit automatischer Replikation über Regionen hinweg | |
|---|---|---|---|
| Ausfall einer Komponente in einer Zone | Abgedeckt* | Abgedeckt | Abgedeckt |
| Zonenausfall | Nicht abgedeckt | Abgedeckt | Abgedeckt |
| Regionsausfall | Nicht abgedeckt | Nicht abgedeckt | Abgedeckt |
* Alle Google Cloud-Produkte sind gegenüber Komponentenausfällen stabil, außer in speziellen Fällen, die in der Produktdokumentation aufgeführt sind. Es handelt sich in der Regel um Szenarien, in denen das Produkt einen direkten Zugriff oder eine statische Zuordnung zu einer besonderen Hardware wie Speicher oder Solid State Disks (SSD) bietet.
So schränkt RPO die Produktauswahl ein
Bei den meisten Cloud-Bereitstellungen ist die Datenintegrität der architektonisch bedeutendste Aspekt, der für einen Dienst in Betracht gezogen werden muss. Zumindest einige Anwendungen haben eine RPO-Anforderung von Null, was bedeutet, dass es bei einem Ausfall keinen Datenverlust geben sollte. Dies erfordert in der Regel, dass Daten synchron in eine andere Zone oder Region repliziert werden. Die synchrone Replikation geht Kompromisse in Bezug auf Kosten und Latenz ein. Während viele Google Cloud-Produkte die synchrone Replikation über Zonen hinweg anbieten, ermöglichen nur wenige die regionenübergreifende Replikation. Diese Kompromisse in Bezug auf Kosten und Komplexität bedeuten, dass es nicht ungewöhnlich ist, dass verschiedene Arten von Daten innerhalb einer Anwendung unterschiedliche RPO-Werte haben.
Bei Daten mit einem RPO-Wert größer als null können Anwendungen die asynchrone Replikation nutzen. Eine asynchrone Replikation ist akzeptabel, wenn verloren gegangene Daten einfach neu erstellt oder bei Bedarf aus einer goldenen Datenquelle wiederhergestellt werden können. Sie kann auch eine vernünftige Wahl sein, wenn geringer Datenverlust im Kontext erwarteter zonaler und regionaler Ausfallzeiten ein akzeptabler Kompromiss ist. Es ist auch von Bedeutung, dass während eines vorübergehenden Ausfalls Daten, die an den betroffenen Standort geschrieben, aber noch nicht an einen anderen Standort repliziert wurden, im Allgemeinen verfügbar werden, nachdem der Ausfall behoben ist. Das bedeutet, dass das Risiko eines dauerhaften Datenverlusts geringer ist als das Risiko, während eines Ausfalls den Datenzugriff zu verlieren.
Schlüsselaktionen: Stellen Sie fest, ob Sie definitiv RPO Null benötigen, und wenn ja, ob dies für eine Teilmenge Ihrer Daten ausreicht. Hierdurch erweitert sich das Spektrum der Ihnen zur Verfügung stehenden DR-fähigen Dienste. In Google Cloud bedeutet das Erreichen von RPO Null, dass Sie für Ihre Anwendung vorwiegend regionale Produkte verwenden, die standardmäßig gegenüber Ausfällen auf Zonen-, nicht aber auf Regionsebene ausfallsicher sind.
So schränkt RTO die Produktauswahl ein
Einer der Hauptvorteile von Cloud-Computing ist die Möglichkeit, Infrastruktur nach Bedarf bereitzustellen. Dies entspricht jedoch nicht der sofortigen Bereitstellung. Der RTO-Wert für Ihre Anwendung muss die kombinierte RTO der Google Cloud-Produkte, die Ihre Anwendung nutzt, sowie alle Maßnahmen berücksichtigen, die Ihre Ingenieure oder SREs (Site Reliability Engineers) ergreifen müssen, um Ihre VMs oder Anwendungskomponenten neu zu starten. Ein in Minuten gemessener RTO-Wert heißt, dass eine Anwendung entworfen wird, die sich nach einem Notfall ohne menschliches Eingreifen oder mit minimalen Schritten wie dem Drücken eines Knopfes für ein Failover automatisch wiederherstellt. Die Kosten und Komplexität eines solchen Systems waren in der Vergangenheit sehr hoch, aber Google Cloud-Produkte wie Load-Balancer und Instanzgruppen machen dieses Design wesentlich kostengünstiger und nutzerfreundlicher. Daher sollten Sie für die meisten Anwendungen einen automatischen Failover und die automatische Wiederherstellung in Betracht ziehen. Die Entwicklung eines Systems für diese Art von "heißem Failover" über Regionen hinweg ist sowohl kompliziert als auch kostspielig. Diese Funktion kann nur von einem sehr kleinen Teil kritischer Dienste genutzt werden.
Die meisten Anwendungen werden einen RTO-Wert zwischen einer Stunde und einem Tag haben, was ein "warmes Failover" in einem Notfallwiederherstellungsszenario ermöglicht. Dabei werden einige Komponenten der Anwendung die ganze Zeit im Standby-Modus laufen (wie z. B. Datenbanken), während andere im Falle eines tatsächlichen Notfalls horizontal skaliert werden (scale out), wie z. B. Webserver. Bei diesen Anwendungen sollten Sie für die Scale-Out-Ereignisse unbedingt eine Automatisierung in Betracht ziehen. Dienste mit einem RTO-Wert über einen Tag haben die niedrigste Kritikalität und können häufig aus einer Sicherung wiederhergestellt oder von Grund auf neu erstellt werden.
Schlüsselaktionen: Legen Sie fest, ob für einen regionalen Failover wirklich ein RTO von (fast) null erforderlich ist. Ist dies der Fall, sollten Sie dies nur für einen Teil Ihrer Dienste anwenden. Dadurch ändern sich die Kosten für den Betrieb und die Wartung Ihres Dienstes.
Schritt 3: Eigene Referenzarchitekturen und -anleitungen entwickeln
Der letzte empfohlene Schritt besteht darin, eigene unternehmensspezifische Architekturmuster zu entwickeln, die Ihren Teams dabei helfen, den Ansatz der Notfallwiederherstellung zu standardisieren. Die meisten Google Cloud-Kunden erstellen einen Leitfaden für ihre Entwicklerteams, der ihre individuellen Erwartungen an die geschäftliche Robustheit mit den beiden Hauptkategorien von Ausfallszenarien in Google Cloud in Einklang bringt. Auf diese Weise können Teams leicht erkennen, welche DR-fähigen Produkte für die einzelnen Kritikalitätsstufen geeignet sind.
Produktrichtlinien erstellen
Betrachtet man die RTO/RPO-Beispieltabelle von oben noch einmal, so erhält man einen hypothetischen Leitfaden, der auflistet, welche Produkte standardmäßig für jede Kritikalitätsstufe zugelassen wären. Beachten Sie, dass Sie in Fällen, in denen bestimmte Produkte standardmäßig als ungeeignet identifiziert wurden, jederzeit Ihre eigenen Replikations- und Failover-Mechanismen hinzufügen können, um eine zonen- oder regionenübergreifende Synchronisierung zu ermöglichen. Dies ginge jedoch über den Rahmen dieses Artikels hinaus. Die Tabellen enthalten außerdem Links zu weiteren Informationen über die einzelnen Produkte, damit Sie ihre Funktionen in Bezug auf die Verwaltung von Zonen- oder Regionsausfällen besser verstehen können.
Beispiele für Architekturmuster für die Beispielorganisation "Co" – Zonenausfallrobustheit
| Google Cloud-Produkt | Erfüllt das Produkt die Anforderungen an Zonenausfälle für die Beispielorganisation (mit entsprechender Produktkonfiguration)? | ||
|---|---|---|---|
| Stufe 1 | Stufe 2 | Stufe 3 | |
| Compute Engine | Nein | Nein | Nein |
| Dataflow | Nein | Nein | Nein |
| BigQuery | Nein | Nein | Ja |
| GKE | Ja | Ja | Ja |
| Cloud Storage | Ja | Ja | Ja |
| Cloud SQL | Nein | Ja | Ja |
| Spanner | Ja | Ja | Ja |
| Cloud Load Balancing | Ja | Ja | Ja |
Diese Tabelle basiert nur auf den oben gezeigten hypothetischen Stufen.
Architekturmuster für die Beispielorganisation "Co" – Regionsausfallrobustheit
| Google Cloud-Produkt | Erfüllt das Produkt die Anforderungen an Regionsausfälle für die Beispielorganisation (mit entsprechender Produktkonfiguration)? | ||
|---|---|---|---|
| Stufe 1 | Stufe 2 | Stufe 3 | |
| Compute Engine | Ja | Ja | Ja |
| Dataflow | Nein | Nein | Nein |
| BigQuery | Nein | Nein | Ja |
| GKE | Ja | Ja | Ja |
| Cloud Storage | Nein | Nein | Nein |
| Cloud SQL | Nein | Ja | Ja |
| Spanner | Ja | Ja | Ja |
| Cloud Load Balancing | Ja | Ja | Ja |
Diese Tabelle basiert nur auf den oben gezeigten hypothetischen Stufen.
Anhand der folgenden Abschnitten werden einige Referenzarchitekturen für jede der hypothetischen Anwendungskritikalitätsstufen durchlaufen, um zu zeigen, wie diese Produkte eingesetzt würden. Dabei handelt es sich bewusst um Beschreibungen auf hohem Niveau, um die wichtigsten architektonischen Entscheidungen zu veranschaulichen. Sie sind nicht repräsentativ für einen vollständigen Lösungsentwurf.
Beispielarchitektur für Stufe 3
| Anwendungskritikalität | Zonenausfall | Regionsausfall |
|---|---|---|
| Stufe 3 (niedrigste Priorität) |
RTO 12 Stunden RPO 24 Stunden |
RTO 28 Tage RPO 24 Stunden |
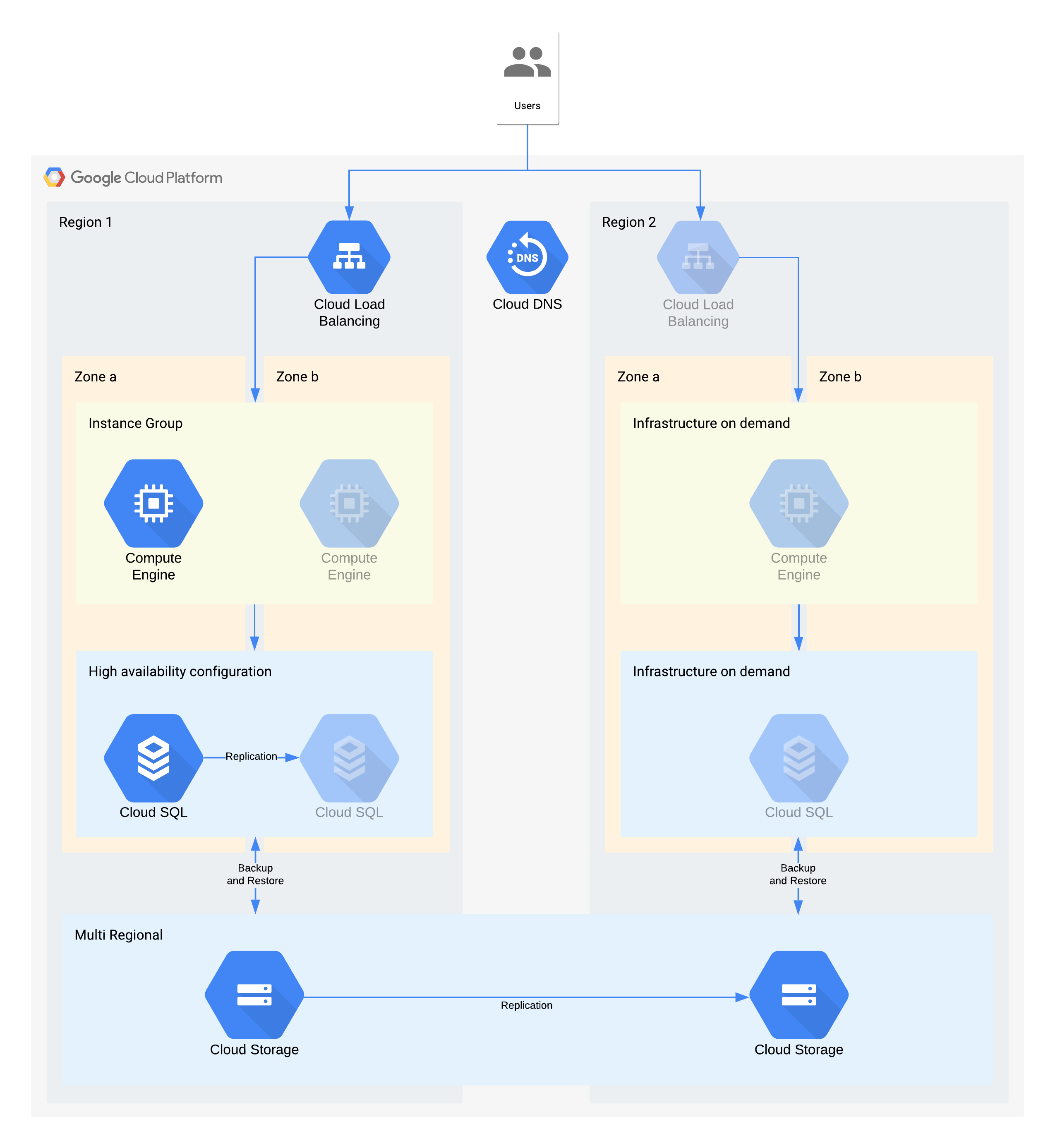
(Ausgegraute Symbole zeigen an, dass die Infrastruktur für die Wiederherstellung aktiviert werden muss.)
Diese Architektur beschreibt eine herkömmliche Client-/Server-Anwendung: Interne Nutzer stellen eine Verbindung zu einer Anwendung her, die auf einer Compute-Instanz läuft, die von einer Datenbank für nichtflüchtigen Speicher unterstützt wird.
Beachten Sie, dass von dieser Architektur bessere RTO- und RPO-Werte unterstützt werden, als dies erforderlich ist. Sie sollten jedoch auch das Entfernen zusätzlicher manueller Schritte in Betracht ziehen, sollten sich diese als teuer oder unzuverlässig herausstellen. Die Wiederherstellung einer Datenbank aus einer Nachtsicherung kann z. B. einen RPO-Wert von 24 Stunden unterstützen. Insbesondere wenn mehrere Dienste gleichzeitig betroffen sind, wäre hierfür jedoch in der Regel eine Fachkraft (z. B. ein Datenbankadministrator) erforderlich, die möglicherweise nicht verfügbar ist. Mit der On-Demand-Infrastruktur von Google Cloud können Sie diese Funktion aufbauen, ohne große Kompromisse bei den Kosten einzugehen. Daher verwendet diese Architektur Cloud SQL HA anstelle einer manuellen Sicherungs-/Wiederherstellungsfunktion bei zonalen Ausfällen.
Wichtige Architekturentscheidungen für den Ausfall einer Zone – RTO von 12 Stunden und RPO von 24 Stunden:
- Ein interner Load-Balancer wird verwendet, um den Nutzern einen skalierbaren Zugriffspunkt zur Verfügung zu stellen, der ein automatisches Failover auf eine andere Zone ermöglicht. Auch wenn der RTO-Wert 12 Stunden beträgt, können manuelle Änderungen an IP-Adressen oder sogar DNS-Aktualisierungen länger dauern als erwartet.
- Eine regional verwaltete Instanzgruppe wird mit mehreren Zonen, aber minimalen Ressourcen konfiguriert. Dadurch werden Kosten optimiert, gleichzeitig können virtuelle Maschinen in der Sicherungszone jedoch schnell horizontal skaliert werden.
- Eine Cloud SQL-Konfiguration für Hochverfügbarkeit bietet automatisches Failover in eine andere Zone. Datenbanken sind im Vergleich zu den virtuellen Maschinen in Compute Engine erheblich schwieriger zu erstellen und wiederherzustellen.
Wichtige Architekturentscheidungen für den Ausfall einer Region – RTO von 28 Tagen und RPO von 24 Stunden:
- Ein Load-Balancer würde nur im Falle eines regionalen Ausfalls in Region 2 erstellt werden. Cloud DNS wird verwendet, um eine orchestrierte, aber manuelle regionale Failover-Funktion bereitzustellen, da die Infrastruktur in Region 2 nur im Falle eines Regionsausfalls verfügbar wäre.
- Eine neue verwaltete Instanzgruppe würde nur im Falle eines regionalen Ausfalls erstellt werden. Dies optimiert Kosten und wird wahrscheinlich aufgrund der kurzen Dauer der meisten regionalen Ausfälle nicht aufgerufen. Beachten Sie bitte, dass das Diagramm der Einfachheit halber nicht das Kopieren der benötigten Compute Engine-Bilder und auch nicht die zugehörigen Tools zeigt, die für die erneute Bereitstellung benötigt werden.
- Eine neue Cloud SQL-Instanz würde neu erstellt und die Daten aus einer Sicherung wiederhergestellt werden. Auch hier ist das Risiko eines erweiterten Ausfalls in einer Region extrem niedrig. Es handelt sich hier also um einen weiteren Kompromiss zur Kostenoptimierung.
- Zum Speichern dieser Sicherungen wird multiregionaler Cloud Storage verwendet. Dies ermöglicht automatische zonale und regionale Robustheit innerhalb des RTO- und RPO-Werts.
Beispielarchitektur für Stufe 2
| Anwendungskritikalität | Zonenausfall | Regionsausfall |
|---|---|---|
| Stufe 2 | RTO 4 Stunden RPO null |
RTO 24 Stunden RPO 4 Stunden |
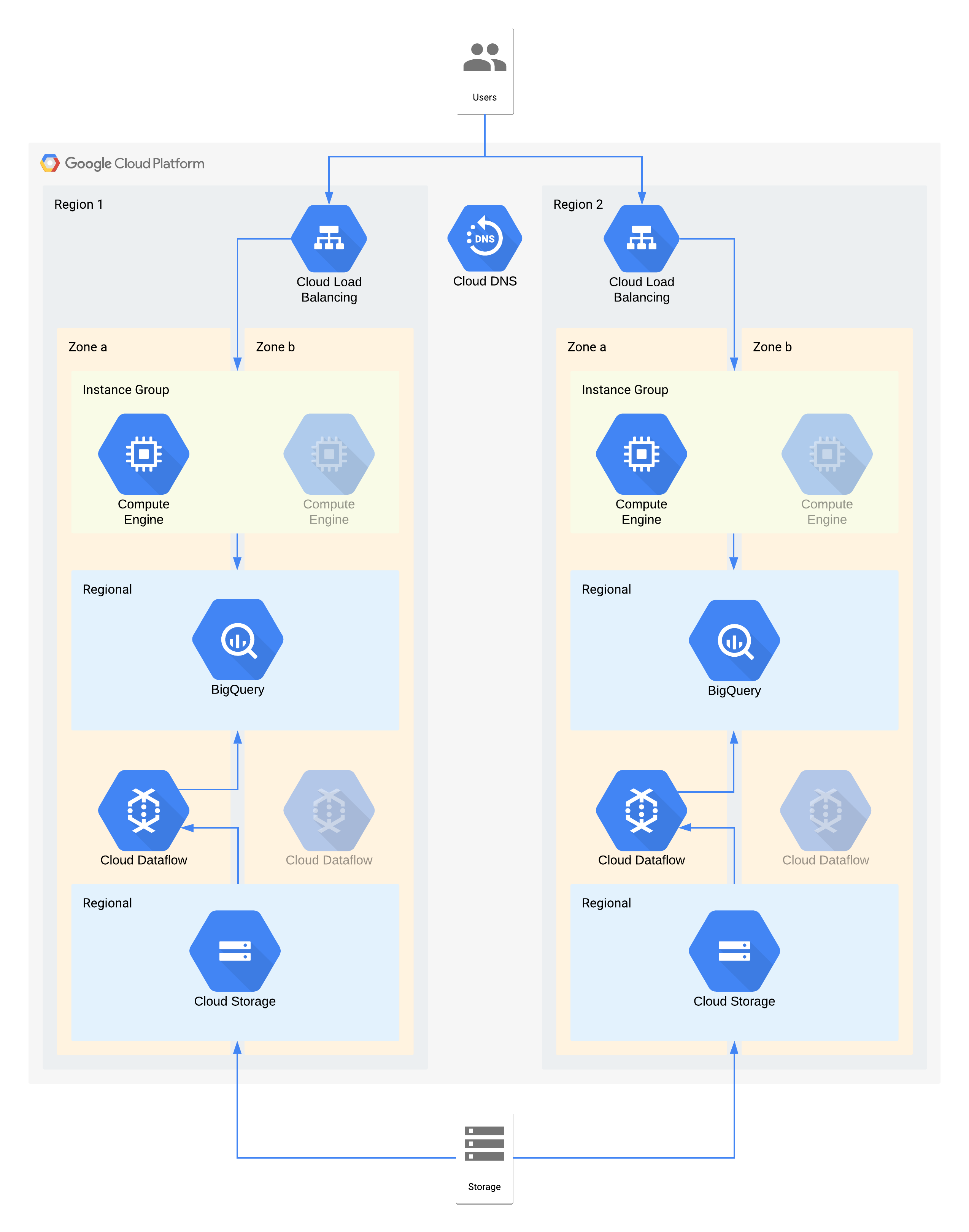
Diese Architektur beschreibt ein Data Warehouse mit internen Nutzern, die eine Verbindung zu einer Visualisierungsebene für die Compute-Instanz und einer Datenaufnahme- und Transformationsebene herstellen, die das Backend-Data Warehouse füllt.
Einige Einzelkomponenten dieser Architektur unterstützen den RPO-Wert, der für ihre Stufe erforderlich ist, nicht direkt. Aufgrund der gemeinsamen Nutzung erfüllt der Dienst insgesamt jedoch den RPO-Wert. Da Dataflow ein zonales Produkt ist, folgen Sie in diesem Fall den Empfehlungen für Hochverfügbarkeitsdesigns, um Datenverluste während eines Ausfalls zu vermeiden. Die Cloud Storage-Ebene ist jedoch die goldene Quelle dieser Daten und unterstützt einen RPO-Wert von null. Daher können Sie alle verlorenen Daten wieder in BigQuery aufnehmen, indem Sie bei einem Ausfall in Zone a Zone b verwenden.
Wichtige Architekturentscheidungen für den Ausfall einer Zone – RTO von 4 Stunden und RPO von null:
- Ein Load-Balancer wird verwendet, um den Nutzern einen skalierbaren Zugriffspunkt zur Verfügung zu stellen, der ein automatisches Failover auf eine andere Zone ermöglicht. Auch wenn der RTO-Wert 4 Stunden beträgt, können manuelle Änderungen an IP-Adressen oder sogar DNS-Aktualisierungen länger dauern als erwartet.
- Eine regional verwaltete Instanzgruppe für die Computing-Ebene der Datenvisualisierung wird mit mehreren Zonen, aber minimalen Ressourcen konfiguriert. Dadurch werden Kosten optimiert, gleichzeitig können virtuelle Maschinen jedoch schnell horizontal skaliert werden.
- Regionaler Cloud Storage wird als Staging-Ebene für die erste Datenaufnahme verwendet und bietet automatische Zonenausfallsicherheit.
- Mit Dataflow werden Daten aus Cloud Storage extrahiert und vor dem Laden in BigQuery transformiert. Bei einem Zonenausfall handelt es sich um einen zustandslosen Prozess, der in einer anderen Zone neu gestartet werden kann.
- BigQuery stellt das Data-Warehouse-Backend für das Frontend der Datenvisualisierung bereit. Im Falle eines Zonenausfalls werden alle verlorenen Daten wieder aus Cloud Storage aufgenommen.
Wichtige Architekturentscheidungen für den Ausfall einer Region – RTO von 24 Stunden und RPO von 4 Stunden:
- Ein Load-Balancer in jeder Region wird verwendet, um Nutzern einen skalierbaren Zugriffspunkt bereitzustellen. Cloud DNS wird verwendet, um eine orchestrierte, aber manuelle regionale Failover-Funktion bereitzustellen, da die Infrastruktur in Region 2 nur im Falle eines Regionsausfalls verfügbar wäre.
- Eine regional verwaltete Instanzgruppe für die Computing-Ebene der Datenvisualisierung wird mit mehreren Zonen, aber minimalen Ressourcen konfiguriert. Dies ist nur möglich, wenn der Load-Balancer neu konfiguriert wurde, erfordert aber ansonsten keinen manuellen Eingriff.
- Regionaler Cloud Storage wird als Staging-Ebene für die erste Datenaufnahme verwendet. Diese wird gleichzeitig in beide Regionen geladen, um die RPO-Anforderungen zu erfüllen.
- Mit Dataflow werden Daten aus Cloud Storage extrahiert und vor dem Laden in BigQuery transformiert. Im Falle eines Regionsausfalls würde BigQuery die aktuellen Daten aus Cloud Storage erhalten.
- BigQuery stellt das Data Warehouse-Back-End bereit. Im Normalbetrieb würde es unregelmäßig aktualisiert werden. Im Falle eines Regionsausfalls werden die neuesten Daten über Dataflow aus Cloud Storage wieder aufgenommen.
Beispielarchitektur für Stufe 1
| Anwendungskritikalität | Zonenausfall | Regionsausfall |
|---|---|---|
| Stufe 1 (am wichtigsten) |
RTO null RPO null |
RTO 4 Stunden RPO 1 Stunde |
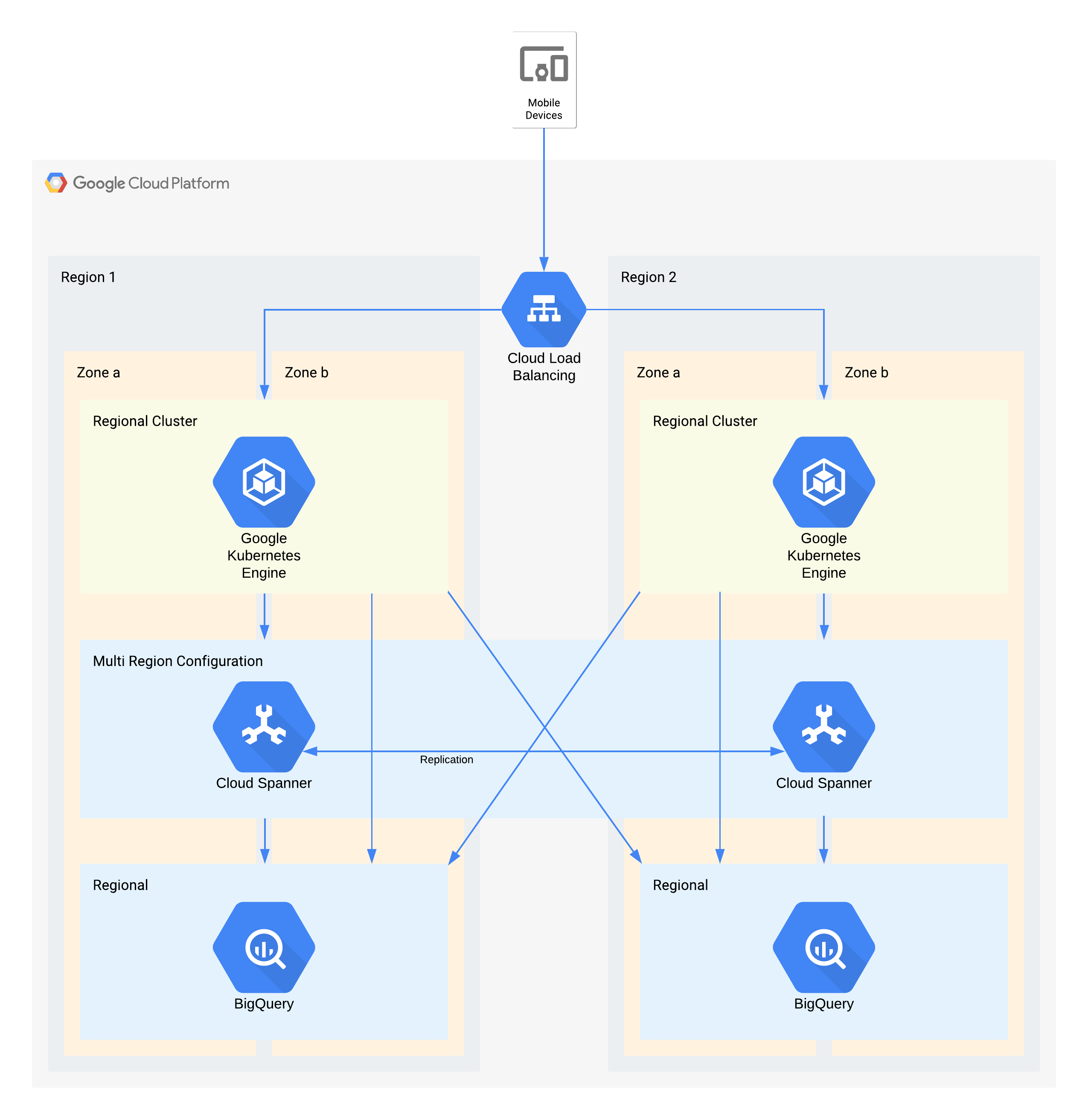
Diese Architektur beschreibt eine Back-End-Infrastruktur für mobile Apps, die externe Nutzer mit einer Reihe von Mikrodiensten verbindet, die in GKE ausgeführt werden. Spanner stellt die Backend-Datenspeicherebene für Echtzeitdaten bereit und Verlaufsdaten werden in jeder Region in einen BigQuery-Data Lake gestreamt.
Auch hier unterstützen einige Einzelkomponenten dieser Architektur den RPO-Wert, der für ihre Stufe erforderlich ist, nicht direkt. Aufgrund der gemeinsamen Nutzung erfüllt der Dienst insgesamt jedoch den RPO-Wert. In diesem Fall wird BigQuery für Analyseabfragen verwendet. Jede Region wird gleichzeitig aus Spanner gespeist.
Wichtige Architekturentscheidungen für den Ausfall einer Zone – RTO von null und RPO von null:
- Ein Load-Balancer wird verwendet, um den Nutzern einen skalierbaren Zugriffspunkt zur Verfügung zu stellen, der ein automatisches Failover auf eine andere Zone ermöglicht.
- Für die Anwendungsebene, die mit mehreren Zonen konfiguriert ist, wird ein regionaler GKE-Cluster verwendet. Dadurch wird das RTO von null in jeder Region erreicht.
- Spanner mit mehreren Regionen wird als Datenpersistenzebene verwendet und bietet automatische Zonendatenstabilität und Transaktionskonsistenz.
- BigQuery bietet die Analysefunktion für die Anwendung. Jede Region wird unabhängig von Spanner mit Daten versorgt und die Anwendung greift unabhängig darauf zu.
Wichtige Architekturentscheidungen für den Ausfall einer Region – RTO von 4 Stunden und RPO von 1 Stunde:
- Ein Load-Balancer wird verwendet, um den Nutzern einen skalierbaren Zugriffspunkt zur Verfügung zu stellen, der ein automatisches Failover in eine andere Region ermöglicht.
- Für die Anwendungsebene, die mit mehreren Zonen konfiguriert ist, wird ein regionaler GKE-Cluster verwendet. Bei einem Ausfall der Region wird der Cluster in der alternativen Region automatisch skaliert, um die zusätzliche Verarbeitungslast zu übernehmen.
- Spanner mit mehreren Regionen wird als Datenpersistenzebene verwendet und bietet automatische regionale Datenstabilität und Transaktionskonsistenz. Dies ist die Schlüsselkomponente zum Erreichen des regionenübergreifenden RPO von 1 Stunde.
- BigQuery bietet die Analysefunktion für die Anwendung. Jede Region wird unabhängig von Spanner mit Daten versorgt und die Anwendung greift unabhängig darauf zu. Diese Architektur kompensiert die BigQuery-Komponente, sodass sie den Anforderungen der Gesamtanwendung entspricht.
Anhang: Produktreferenz
In diesem Abschnitt werden die Architektur und die DR-Funktionen der Google Cloud-Produkte beschrieben, die am häufigsten in Kundenanwendungen verwendet werden und die leicht zur Erfüllung Ihrer DR-Anforderungen genutzt werden können.
Häufige Themen
Viele Google Cloud-Produkte bieten regionale oder multiregionale Konfigurationen. Regionale Produkte sind widerstandsfähig gegen Zonenausfälle und multiregionale und globale Produkte sind widerstandsfähig gegen regionale Ausfälle. Im Allgemeinen bedeutet dies, dass Ihre Anwendung während eines Ausfalls nur minimale Unterbrechungen erfährt. Google erreicht diese Ergebnisse durch einige gemeinsame Architekturansätze, die die oben beschriebenen Leitlinien spiegeln.
- Redundante Bereitstellung: Die Anwendungs-Back-Ends und der Datenspeicher werden über mehrere Zonen innerhalb einer Region und mehrere Regionen innerhalb eines multiregionalen Standorts bereitgestellt.
Datenreplikation: Produkte verwenden eine synchrone oder asynchrone Replikation über die redundanten Standorte hinweg.
Synchrone Replikation bedeutet, dass Ihre Anwendung bei einem API-Aufruf zum Erstellen oder Ändern von Daten, die vom Produkt gespeichert werden, erst dann eine erfolgreiche Antwort erhält, wenn das Produkt die Daten an mehrere Standorte geschrieben hat. Die synchrone Replikation sorgt dafür, dass Sie während eines Ausfalls der Google Cloud-Infrastruktur auf Ihre Daten zugreifen können, da sämtliche Ihrer Daten an einem der verfügbaren Back-End-Standorte zugänglich sind.
Obwohl diese Technik den maximalen Schutz Ihrer Daten gewährleistet, kann sie im Hinblick auf Latenz und Leistung mit Kompromissen einhergehen. Bei Produkten mit mehreren Regionen, die die synchrone Replikation verwenden, wird dieser Kompromiss am deutlichsten – in der Regel in der Größenordnung von 10 oder 100 Millisekunden zusätzlicher Latenzzeit.
Asynchrone Replikation bedeutet, dass Ihre Anwendung bei einem API-Aufruf zum Erstellen oder Ändern von Daten, die vom Produkt gespeichert werden, eine erfolgreiche Antwort erhält, sobald das Produkt die Daten an einen einzigen Standort geschrieben hat. Im Anschluss an Ihre Schreibanfrage repliziert das Produkt Ihre Daten an weitere Standorte.
Dieses Verfahren bietet eine geringere Latenz und einen höheren Durchsatz bei der API als die synchrone Replikation, allerdings auf Kosten des Schutzes Ihrer Daten. Wenn der Standort, an dem Sie Daten geschrieben haben, einen Ausfall erfährt, bevor die Replikation abgeschlossen wurde, haben Sie keinen Zugriff mehr auf diese Daten, bis der Standortausfall behoben wurde.
Ausfälle mit Load-Balancing verwalten: Google Cloud verwendet Software-Load-Balancing, um Anfragen an die entsprechenden Anwendungs-Back-Ends weiterzuleiten. Im Vergleich zu anderen Ansätzen wie dem DNS-Load-Balancing verkürzt dieser Ansatz die Systemantwortzeit auf einen Ausfall. Wenn ein Google Cloud-Standortausfall auftritt, erkennt der Load-Balancer schnell, dass das an diesem Standort bereitgestellte Back-End fehlerhaft ist, und leitet alle Anfragen an ein Back-End an einem anderen Speicherort weiter. Dadurch kann das Produkt die Anfragen Ihrer Anwendung während eines Standortausfalls weiter verarbeiten. Sobald der Standortausfall behoben wurde, erkennt der Load-Balancer die Verfügbarkeit der Produkt-Back-Ends an diesem Standort und leitet den Traffic noch einmal dorthin.
Access Context Manager
Mit Access Context Manager können Unternehmen Zugriffsebenen konfigurieren, die einer Richtlinie entsprechen, die für Anfrageattribute definiert ist. Richtlinien werden regional gespiegelt.
Bei einem zonalen Ausfall werden Anfragen an nicht verfügbare Zonen automatisch und transparent von anderen verfügbaren Zonen in der Region bearbeitet.
Bei einem regionalen Ausfall sind Richtlinienberechnungen aus der betroffenen Region erst wieder verfügbar, wenn die Region wieder verfügbar ist.
Access Transparency
Mit Access Transparency können Administratoren der Google Cloud-Organisation eine detaillierte, attributbasierte Zugriffssteuerung für Projekte und Ressourcen in Google Cloud definieren. Gelegentlich muss Google zu Verwaltungszwecken auf Kundendaten zugreifen. Wenn wir auf Kundendaten zugreifen, bietet Access Transparency Zugriffslogs für betroffene Google Cloud-Kunden. Diese Access Transparency-Logs tragen dazu bei, dass Google sich für Datensicherheit und Transparenz bei der Datenverarbeitung einsetzt.
Access Transparency ist gegen zonale und regionale Ausfälle resistent. Wenn ein zonaler oder regionaler Ausfall auftritt, verarbeitet Access Transparency weiterhin Administratorzugriffslogs in einer anderen Zone oder Region.
AlloyDB for PostgreSQL
AlloyDB for PostgreSQL ist ein vollständig verwalteter, PostgreSQL-kompatibler Datenbankdienst. AlloyDB for PostgreSQL bietet Hochverfügbarkeit in einer Region über die redundanten Knoten der primären Instanz, die sich in zwei verschiedenen Zonen der Region befinden. Die primäre Instanz behält die regionale Verfügbarkeit bei, indem sie einen automatischen Failover zur Standby-Zone auslöst, wenn in der aktiven Zone ein Problem auftritt. Regionaler Speicher garantiert die Langlebigkeit von Daten, sollte es in einer einzelnen Zone zu einem Ausfall kommen.
Als weitere Methode zur Notfallwiederherstellung verwendet AlloyDB for PostgreSQL die regionenübergreifende Replikation, um Funktionen zur Notfallwiederherstellung zu bieten. Dazu werden die Daten Ihres primären Clusters asynchron in sekundäre Cluster repliziert, die sich in separaten Google Cloud-Regionen befinden.
Zonaler Ausfall: Während des normalen Betriebs ist nur einer der beiden Knoten einer primären Instanz mit Hochverfügbarkeit aktiv und verarbeitet alle Datenschreibvorgänge. Dieser aktive Knoten speichert die Daten auf der separaten regionalen Speicherebene des Clusters.
AlloyDB for PostgreSQL erkennt automatisch zonale Ausfälle und löst ein Failover aus, um die Datenbankverfügbarkeit wiederherzustellen. Während des Failovers startet AlloyDB for PostgreSQL die Datenbank auf dem Standby-Knoten, der bereits in einer anderen Zone bereitgestellt ist. Neue Datenbankverbindungen werden automatisch an diese Zone weitergeleitet.
Aus Sicht einer Clientanwendung ähnelt ein zonaler Ausfall einer vorübergehenden Unterbrechung der Netzwerkverbindung. Nach Abschluss des Failovers kann ein Client wieder eine Verbindung zur Instanz unter derselben Adresse herstellen. Dabei werden dieselben Anmeldedaten verwendet, ohne dass Daten verloren gehen.
Regionaler Ausfall: Bei der regionenübergreifenden Replikation wird die asynchrone Replikation verwendet. Somit kann die primäre Instanz einen Commit für Transaktionen durchführen, bevor ein Commit auf Replikate durchgeführt wird. Der Zeitunterschied zwischen dem Commit einer Transaktion auf der primären Instanz und dem Commit einer Transaktion auf dem Replikat wird als Replikationsverzögerung bezeichnet. Der Zeitunterschied zwischen dem Erstellen des Write-Ahead-Logs (WAL) durch die primäre Instanz und dem Zeitpunkt, zu dem das WAL das Replikat erreicht, wird als Löschverzögerung bezeichnet. Die Replikationsverzögerung und die Löschverzögerung hängen von der Konfiguration der Datenbankinstanz und der nutzergenerierten Arbeitslast ab.
Bei einem regionalen Ausfall können Sie sekundäre Cluster in einer anderen Region zu einem beschreibbaren, eigenständigen primären Cluster hochstufen. Dieser hochgestufte Cluster repliziert nicht mehr die Daten aus dem ursprünglichen primären Cluster, mit dem er zuvor verknüpft war. Aufgrund der Löschverzögerung kann es zu Datenverlusten kommen, da möglicherweise Transaktionen auf dem ursprünglichen primären Knoten vorhanden sind, die nicht an den sekundären Cluster weitergegeben wurden.
Die regionenübergreifende Replikations-RPO ist sowohl von der CPU-Auslastung des primären Clusters als auch von der physischen Entfernung zwischen der Region des primären Clusters und der Region des sekundären Clusters betroffen. Zur Optimierung des RPO empfehlen wir, Ihre Arbeitslast mit einer Konfiguration zu testen, die ein Replikat enthält, um eine Begrenzung für "sichere Transaktionen pro Sekunde (TPS)" festzulegen. Diese entspricht dem höchsten kontinuierlichen TPS-Wert, der keine Löschverzögerung verursacht. Wenn Ihre Arbeitslast diese Begrenzung überschreitet, nimmt die Löschverzögerung zu, was sich auf das RPO auswirken kann. Zum Begrenzen der Netzwerkverzögerung wählen Sie Regionspaare innerhalb desselben Kontinents aus.
Weitere Informationen zum Überwachen der Netzwerkverzögerung und anderer AlloyDB for PostgreSQL-Messwerte finden Sie unter Instanzen überwachen.
Anti Money Laundering AI
Die Anti Money Laundering AI (AML AI) bietet eine API, mit der globale Finanzinstitute Geldwäsche effektiver und effizienter erkennen können. Die Anti Money Laundering AI ist ein regionales Angebot, d. h. Kunden können die Region auswählen, nicht jedoch die Zonen, aus denen eine Region besteht. Daten und Traffic werden automatisch auf Zonen in einer Region verteilt. Die Vorgänge (z. B. zum Erstellen einer Pipeline oder zum Ausführen einer Vorhersage) werden automatisch im Hintergrund skaliert und je nach Bedarf per Load-Balancing auf die Zonen verteilt.
Zonaler Ausfall: AML AI speichert Daten für die Ressourcen regional und synchron repliziert. Wenn ein lang andauernder Vorgang erfolgreich abgeschlossen wurde, können die Ressourcen unabhängig von zonalen Ausfällen sicher verwendet werden. Die Verarbeitung wird auch zonenübergreifend repliziert. Diese Replikation ist jedoch auf Load-Balancing und nicht auf Hochverfügbarkeit ausgerichtet, sodass ein Zonenausfall während eines Vorgangs zu einem Vorgangsfehler führen kann. In diesem Fall kann das Problem durch Wiederholen des Vorgangs behoben werden. Ein zonaler Ausfall kann sich auf die Verarbeitungszeiten auswirken.
Regionaler Ausfall: Kunden wählen die Google Cloud-Region aus, in der sie ihre AML AI-Ressourcen erstellen möchten. Daten werden nie über Regionen hinweg repliziert. Kunden-Traffic wird von AML AI nie an eine andere Region weitergeleitet. Bei einem regionalen Ausfall wird AML AI wieder verfügbar, sobald der Ausfall behoben ist.
API-Schlüssel
API-Schlüssel bieten eine skalierbare Verwaltung von API-Schlüsselressourcen für ein Projekt. API-Schlüssel sind ein globaler Dienst, das heißt, Schlüssel sind von jedem Google Cloud-Standort aus sichtbar und zugänglich. Die zugehörigen Daten und Metadaten werden redundant in mehreren Zonen und Regionen gespeichert.
API-Schlüssel sind sowohl zonalen als auch regionalen Ausfällen gegenüber geschützt. Im Falle eines Zonenausfalls oder eines regionalen Ausfalls verarbeiten API-Schlüssel weiterhin Anfragen aus einer anderen Zone in derselben oder einer anderen Region.
Weitere Informationen zu API-Schlüsseln finden Sie unter API-Schlüssel – API-Übersicht.
Apigee
Apigee bietet eine sichere, skalierbare und zuverlässige Plattform zum Entwickeln und Verwalten von APIs. Apigee bietet sowohl Bereitstellungen in einer als auch in mehreren Regionen.
Zonaler Ausfall: Kundenlaufzeitdaten werden über mehrere Verfügbarkeitszonen repliziert. Daher wirkt sich ein Ausfall einer einzelnen Zone nicht auf Apigee aus.
Regionaler Ausfall: Wenn bei Apigee-Instanzen mit einer einzelnen Region eine Region ausfällt, sind Apigee-Instanzen in dieser Region nicht verfügbar und können nicht in anderen Regionen wiederhergestellt werden. Bei multiregionalen Apigee-Instanzen werden die Daten in allen Regionen asynchron repliziert. Daher reduziert der Ausfall einer Region den Traffic nicht vollständig. Möglicherweise können Sie jedoch auf nicht festgelegte Daten in der fehlgeschlagenen Region nicht zugreifen. Sie können den Traffic von fehlerhaften Regionen wegleiten. Für ein automatisches Traffic-Failover können Sie das Netzwerkrouting mithilfe von verwalteten Instanzgruppen (MIGs) konfigurieren.
AutoML Translation
AutoML Translation ist ein Dienst für maschinelle Übersetzungen, mit dem Sie eigene Daten (Satzpaare) importieren können, um benutzerdefinierte Modelle für Ihre domainspezifischen Anforderungen zu trainieren.
Zonaler Ausfall: AutoML Translation hat aktive Compute-Server in mehreren Zonen und Regionen. Außerdem wird die synchrone Datenreplikation über Zonen in Regionen unterstützt. Mit diesen Funktionen kann AutoML Translation sofort ein Failover erreichen, ohne dass Datenverluste bei zonalen Fehlern auftreten und ohne dass Eingaben oder Anpassungen von Kunden erforderlich sind.
Regionaler Ausfall: Bei einem regionalen Ausfall ist AutoML Translation nicht verfügbar.
AutoML Vision
AutoML Vision ist Teil von Vertex AI. Die Lösung bietet ein einheitliches Framework zum Erstellen von Datasets, Importieren von Daten, Trainieren von Modellen und Bereitstellen von Modellen für Online- und Batchvorhersagen.
AutoML Vision ist ein regionales Angebot. Kunden können wählen, aus welcher Region sie einen Job starten möchten, aber sie können nicht die spezifischen Zonen innerhalb dieser Region auswählen. Der Dienst verteilt die Arbeitslasten automatisch auf verschiedene Zonen innerhalb der Region.
Zonenausfall: AutoML Vision speichert Metadaten für die Jobs und schreibt synchron in Zonen innerhalb der Region. Die Jobs werden in einer bestimmten Zone gestartet, die von Cloud Load Balancing ausgewählt wird.
AutoML Vision-Trainingsjobs: Ein Zonenausfall führt dazu, dass alle laufenden Jobs fehlschlagen und die Aktualisierung des Jobstatus fehlschlägt. Wenn ein Job fehlschlägt, wiederholen Sie ihn sofort. Der neue Job wird an eine verfügbare Zone weitergeleitet.
AutoML Vision-Batch-Vorhersagejobs: Die Batch-Vorhersage basiert auf der Batch-Vorhersage von Vertex AI. Wenn ein Zonenausfall auftritt, wiederholt der Dienst den Job automatisch, indem der Job an verfügbare Zonen weitergeleitet wird. Wenn mehrere Wiederholungsversuche fehlschlagen, wird der Jobstatus auf „Fehlgeschlagen“ aktualisiert. Nachfolgende Nutzeranfragen zum Ausführen des Jobs werden an eine verfügbare Zone weitergeleitet.
Regionaler Ausfall: Kunden wählen die Google Cloud-Region aus, in der sie ihre Jobs ausführen möchten. Daten werden nie über Regionen hinweg repliziert. Bei einem regionalen Ausfall ist der AutoML Vision-Dienst in dieser Region nicht verfügbar. Er wird wieder verfügbar, wenn der Ausfall behoben ist. Zum Ausführen ihrer Jobs empfehlen wir Kunden, mehrere Regionen zu verwenden. Bei einem regionalen Ausfall werden Jobs an eine andere verfügbare Region weitergeleitet.
Batch
Batch ist ein vollständig verwalteter Dienst, mit dem Sie Batchjobs in Google Cloud in die Warteschlange stellen, planen und ausführen können. Batch-Einstellungen werden auf Regionsebene definiert. Kunden müssen eine Region zum Senden ihrer Batchjobs auswählen, nicht eine Zone in einer Region. Wenn ein Job gesendet wird, schreibt Batch synchron Kundendaten in mehrere Zonen. Kunden können jedoch die Zonen angeben, in denen Batch-VMs Jobs ausführen.
Zonaler Ausfall: Wenn eine einzelne Zone ausfällt, schlagen die in dieser Zone ausgeführten Aufgaben ebenfalls fehl. Wenn Aufgaben Wiederholungseinstellungen haben, führt Batch automatisch einen Failover dieser Aufgaben auf andere aktive Zonen in derselben Region durch. Der automatische Failover hängt von der Verfügbarkeit von Ressourcen in aktiven Zonen in derselben Region ab. Jobs, die zonale Ressourcen erfordern, z. B. VMs, GPUs oder zonale nichtflüchtige Speicher, die nur in der fehlgeschlagenen Zone verfügbar sind, werden so lange in die Warteschlange gestellt, bis die fehlgeschlagene Zone wiederhergestellt ist oder bis die Zeitüberschreitungen für Jobs in der Warteschlange erreicht sind. Wir empfehlen Kunden, Batch nach Möglichkeit zonale Ressourcen zur Ausführung ihrer Jobs auswählen zu lassen. Auf diese Weise wird sichergestellt, dass die Jobs gegen einen zonalen Ausfall resistent sind.
Regionaler Ausfall: Bei einem regionalen Ausfall ist die Dienststeuerungsebene in der Region nicht verfügbar. Der Dienst repliziert keine Daten oder leitet Anfragen regionenübergreifend weiter. Wir empfehlen Kunden, mehrere Regionen zu verwenden, um ihre Jobs auszuführen und Jobs an eine andere Region weiterzuleiten, wenn eine Region ausfällt.
Chrome Enterprise Premium-Bedrohungs- und Datenschutz
Der Chrome Enterprise Premium-Bedrohungs- und Datenschutz ist Teil der Chrome Enterprise Premium-Lösung. Es erweitert Chrome um eine Vielzahl von Sicherheitsfunktionen, einschließlich Malware- und Phishing-Schutz, Schutz vor Datenverlust (DLP), URL-Filterregeln und Sicherheitsberichten.
Chrome Enterprise Premium-Administratoren können aktivieren, dass Kundeninhalte, die gegen DLP- oder Richtlinien zu Malware verstoßen, in Google Workspace-Regelprotokollereignissen und/oder in Cloud Storage gespeichert werden, um sie später zu untersuchen. Google Workspace-Regelprotokollereignisse basieren auf einer multiregionalen Spanner-Datenbank. Es kann mehrere Stunden dauern, bis Chrome Enterprise Premium Richtlinienverstöße erkennt. Während dieser Zeit unterliegen nicht verarbeitete Daten bei einem zonalen oder regionalen Ausfall Datenverlusten. Sobald ein Verstoß erkannt wurde, werden die Inhalte, die gegen Ihre Richtlinien verstoßen, in Google Workspace-Regelprotokollereignisse und/oder in Cloud Storage geschrieben.
Zonen- und regionaler Ausfall: Da der Bedrohungs- und Datenschutz in Chrome Enterprise Premium multizonal und multiregional ist, kann er einen vollständigen, ungeplanten Ausfall einer Zone oder Region ohne Einbußen bei der Verfügbarkeit überstehen. Es bietet dieses Maß an Zuverlässigkeit, indem Traffic an seinen Dienst in anderen aktiven Zonen oder Regionen weitergeleitet wird. Da es jedoch mehrere Stunden dauern kann, bis der Bedrohungs- und Datenschutz in Chrome Enterprise Premium DLP- und Malware-Verstöße erkennt, sind nicht verarbeitete Daten in einer bestimmten Zone oder Region bei einem Zonen- oder regionalen Ausfall Verlusten ausgesetzt.
BigQuery
BigQuery ist ein serverloses, höchst skalierbares und kostengünstiges Cloud Data Warehouse, das speziell für geschäftliche Agilität konzipiert ist. BigQuery unterstützt die folgenden Standorttypen für Nutzer-Datasets:
- Eine Region: ein bestimmter geografischer Standort, z. B. Iowa (
us-central1) oder Montreal (northamerica-northeast1). - Mehrere Regionen: ein großes geografisches Gebiet, das zwei oder mehr geografische Orte enthält, z. B. die USA (
US) oder Europa (EU).
In beiden Fällen werden die Daten redundant in zwei Zonen innerhalb einer einzelnen Region innerhalb des ausgewählten Standorts gespeichert. In BigQuery geschriebene Daten werden synchron sowohl in die primären als auch in die sekundären Zonen geschrieben. Dies schützt vor Nichtverfügbarkeit einer einzelnen Zone innerhalb der Region, jedoch nicht vor einem regionalen Ausfall.
Binärautorisierung
Die Binärautorisierung ist ein Sicherheitsprodukt der Softwarelieferkette für GKE und Cloud Run.
Alle Richtlinien für die Binärautorisierung werden in mehreren Zonen innerhalb jeder Region repliziert. Durch die Replikation können Lesevorgänge von Richtlinien für die Binärautorisierung nach Fehlern anderer Regionen wiederhergestellt werden. Die Replikation macht Lesevorgänge auch tolerant gegenüber zonalen Fehlern in jeder Region.
Die Erzwingungsvorgänge für die Binärautorisierung sind vor zonalen Ausfälle geschützt, aber nicht vor regionalen Ausfällen. Erzwingungsvorgänge werden in derselben Region wie der GKE-Cluster oder der Cloud Run-Job ausgeführt, von dem die Anfrage stammt. Daher wird bei einem regionalen Ausfall nichts ausgeführt, um Anfragen zur Erzwingung der Binärautorisierung zu senden.
Zertifikatmanager
Mit Certificate Manager können Sie Transport Layer Security-Zertifikate (TLS) für die Verwendung mit verschiedenen Arten von Cloud Load Balancing abrufen und verwalten.
Bei einem Zonenausfall sind der regionale und der globale Certificate Manager vor zonalen Ausfällen geschützt, da Jobs und Datenbanken über mehrere Zonen innerhalb einer Region redundant sind. Bei einem regionalen Ausfall ist der globale Certificate Manager vor regionalen Ausfällen geschützt, da Jobs und Datenbanken in mehreren Regionen redundant sind. Der regionale Certificate Manager ist ein regionales Produkt und kann daher einem regionalen Ausfall nicht standhalten.
Cloud Intrusion Detection System
Cloud Intrusion Detection System (Cloud IDS) ist ein zonaler Dienst, der zonale IDS-Endpunkte bereitstellt, die den Traffic von VMs in einer bestimmten Zone verarbeiten, und daher nicht tolerant gegenüber zonalen oder regionalen Ausfällen ist.
Zonaler Ausfall: Cloud IDS ist an VM-Instanzen gebunden. Wenn Kunden zonale Ausfälle durch die Bereitstellung von VMs in mehreren Zonen (manuell oder über regionale verwaltete Instanzgruppen) minimieren möchten, müssen sie auch Cloud IDS-Endpunkte in diesen Zonen bereitstellen.
Regionaler Ausfall: Cloud IDS ist ein regionales Produkt. Es bietet keine regionenübergreifende Funktionalität. Ein regionaler Ausfall deaktiviert alle Cloud IDS-Funktionen in allen Zonen dieser Region.
Google Security Operations SIEM
Google Security Operations SIEM (ein Teil von Google Security Operations) ist ein vollständig verwalteter Dienst, mit dem Sicherheitsteams Bedrohungen erkennen, untersuchen und darauf reagieren können.
Google Security Operations SIEM hat regionale und multiregionale Angebote.
Bei regionalen Angeboten können Kunden die Region auswählen, nicht jedoch die Zonen, aus denen eine Region besteht. Daten und Traffic werden automatisch auf Zonen in der ausgewählten Region verteilt und redundant in Verfügbarkeitszonen innerhalb der Region gespeichert.
Multiregionen sind georedundant. Die Daten werden redundant über Regionen hinweg gespeichert. Dies bietet einen umfassenderen Schutz, als der regionale Speicher, denn die Dienstfunktionalität bleibt auch beim Verlust einer vollständigen Region gewahrt. Die Daten werden asynchron repliziert. Dies bedeutet, dass ein Zeitfenster (Recovery Point Objective, RPO) vorhanden ist, in dem die Daten noch nicht über Regionen repliziert werden. Nach dem RPO sind die Daten in mehreren Regionen verfügbar. Für die Replikationsverzögerung sind keine Garantien verfügbar.
Zonaler Ausfall:
Regionale Bereitstellungen: Google Security Operations SIEM wird in mehreren Zonen innerhalb einer Region bereitgestellt. Anfragen werden aus jeder Zone innerhalb der Region verarbeitet und die Daten werden in mehreren Zonen der Region repliziert. Bei einem Ausfall in der gesamten Zone werden die verbleibenden Zonen weiterhin weitergeleitet und die Daten werden verarbeitet. Eine redundante Bereitstellung und eine automatisierte Skalierung für Google Security Operations SIEM sorgen dafür, dass der Dienst während dieser Lastverschiebungen in den vorhandenen Zonen verfügbar bleibt.
Multiregionale Bereitstellungen: Google Security Operations SIEM wird in mehreren Regionen bereitgestellt. Die Daten werden asynchron über die Regionen hinweg repliziert. Bei einem Ausfall der gesamten Region sind keine Garantien für die Datenreplikation verfügbar und auch nicht für die Fähigkeit des Dienstes, auf eine andere Zone oder Region zurückzugreifen.
Regionaler Ausfall:
Regionale Bereitstellungen: Google Security Operations SIEM speichert alle Kundendaten in einer einzigen Region und der Traffic wird niemals über Regionen hinweg weitergeleitet. Bei einem regionalen Ausfall ist Google Security Operations SIEM erst wieder verfügbar, wenn der Ausfall behoben ist.
Multiregionale Bereitstellungen: Google Security Operations SIEM repliziert die Daten über mehrere Regionen hinweg und der Traffic wird automatisch an die verbleibenden Regionen weitergeleitet. Es gibt keine Garantien für die Replikationsverzögerung und die Möglichkeit, weiterhin aus den verbleibenden Regionen bereitzustellen.
Cloud Asset Inventory
Cloud Asset Inventory ist ein stabiler globaler Hochleistungsdienst, der ein Repository der Google Cloud-Ressourcen- und Richtlinienmetadaten verwaltet. Cloud Asset Inventory bietet Such- und Analysetools, mit denen Sie bereitgestellte Assets organisations-, ordner- und projektübergreifend verfolgen können.
Bei einem Zonenausfall verarbeitet Cloud Asset Inventory weiterhin Anfragen aus einer anderen Zone in derselben oder einer anderen Region.
Bei einem regionalen Ausfall verarbeitet Cloud Asset Inventory weiterhin Anfragen aus anderen Regionen.
Bigtable
Bigtable ist ein vollständig verwalteter, leistungsstarker NoSQL-Datenbankdienst für große analytische und operative Arbeitslasten.
Bigtable-Replikation – Übersicht
Bigtable bietet ein flexibles und vollständig konfigurierbares Replikationsfeature, mit dem Sie die Verfügbarkeit und Langlebigkeit Ihrer Daten erhöhen können. Dazu kopieren Sie sie in Cluster in mehreren Regionen oder mehrere Zonen innerhalb derselben Region. Bigtable kann auch automatischen Failover für Ihre Anfragen bereitstellen, wenn Sie die Replikation verwenden.
Wenn Sie multizonale oder multiregionale Konfigurationen mit Multi-Cluster-Routing verwenden, leitet Bigtable bei einem zonalen oder regionalen Ausfall automatisch den Traffic um und verarbeitet Anfragen vom nächstgelegenen verfügbaren Cluster Da Bigtable-Replikation asynchron ist und Eventual Consistency bietet, können sehr aktuelle Änderungen an Daten am Standort des Ausfalls nicht verfügbar sein, wenn sie noch nicht an andere Standorte repliziert wurden.
Hinweise zur Leistung
Wenn die Anforderungen für CPU-Ressourcen die verfügbare Knotenkapazität überschreiten, priorisiert Bigtable immer die Verarbeitung eingehender Anfragen gegenüber Replikationstraffic.
Weitere Informationen zur Verwendung der Bigtable-Replikation mit Ihrer Arbeitslast finden Sie unter Cloud Bigtable-Replikation – Übersicht und Beispiele für Replikationseinstellungen.
Bigtable-Knoten werden sowohl für die Verarbeitung eingehender Anfragen als auch für die Replikation von Daten aus anderen Clustern verwendet. Sie müssen nicht nur genügend Knoten pro Cluster verwalten, sondern auch dafür sorgen, dass Ihre Anwendungen das richtige Schemadesign verwenden, um Hotspots zu vermeiden. Hotspots können zu einer übermäßigen oder unausgeglichenen CPU-Nutzung und einer höheren Replikationslatenz führen.
Weitere Informationen zum Entwerfen Ihres Anwendungsschemas, um die Leistung und Effizienz von Bigtable zu maximieren, finden Sie unter Best Practices für das Schemadesign.
Monitoring
Bigtable bietet mehrere Möglichkeiten, die Replikationslatenz Ihrer Instanzen und Cluster mithilfe der in der Google Cloud Console verfügbaren Diagramme zur Replikation visuell zu überwachen.
Außerdem können Sie mit der Cloud Monitoring API die Messwerte der Bigtable-Replikation programmatisch überwachen.
Certificate Authority Service
Der Certificate Authority Service (CA Service) ermöglicht es Kunden, die Bereitstellung, Verwaltung und Sicherheit privater Zertifizierungsstellen (Certificate Authorities, CAs) zu vereinfachen, zu automatisieren und anzupassen sowie Zertifikate in großem Maßstab auszustellen.
Zonaler Ausfall: CA Service kann zonalen Ausfällen standhalten, da seine Steuerungsebene über mehrere Zonen innerhalb einer Region redundant ist. Bei einem Zonenausfall verarbeitet CA Service weiterhin Anfragen aus einer anderen Zone derselben Region, ohne dass eine Unterbrechung auftritt. Da die Daten synchron repliziert werden, treten weder Datenverlust noch Datenschäden auf.
Regionaler Ausfall: CA Service ist ein regionales Produkt und kann daher einem regionalen Ausfall nicht standhalten. Wenn Sie Ausfallsicherheit bei regionalen Ausfällen benötigen, müssen Sie ausstellende Zertifizierungsstellen in zwei verschiedenen Regionen erstellen. Erstellen Sie die primäre ausstellende Zertifizierungsstelle in der Region, in der Sie Zertifikate benötigen. Erstellen Sie eine Fallback-CA in einer anderen Region. Verwenden Sie das Fallback, wenn die Region der primären untergeordneten Zertifizierungsstelle ausfällt. Bei Bedarf können beide Zertifizierungsstellen mit derselben Stamm-CA verkettet werden.
Cloud Billing
Mit der Cloud Billing API können Entwickler die Abrechnung für ihre Google Cloud-Projekte programmatisch verwalten. Die Cloud Billing API ist als globales System konzipiert, bei dem Aktualisierungen synchron in mehrere Zonen und Regionen geschrieben werden.
Zonaler oder regionaler Ausfall: Die Cloud Billing API führt automatisch ein Failover auf eine andere Zone oder Region durch. Einzelne Anfragen können fehlschlagen, aber eine Wiederholungsrichtlinie sollte nachfolgende Versuche zulassen.
Cloud Build
Cloud Build ist ein Dienst, der Ihre Builds in Google Cloud ausführt.
Cloud Build besteht aus regional isolierten Instanzen, die Daten zonenübergreifend innerhalb der Region synchron replizieren. Wir empfehlen, bestimmte Google Cloud-Regionen anstelle der globalen Region zu verwenden und dafür zu sorgen, dass die von Ihrem Build verwendeten Ressourcen (einschließlich Log-Buckets, Artifact Registry-Repositories usw.) mit der Region übereinstimmen in dem Ihr Build läuft.
Bei einem Zonenausfall sind die Vorgänge der Steuerungsebene nicht betroffen. Derzeit wird die Ausführung von Builds innerhalb der ausgefallenen Zone jedoch verzögert oder dauerhaft verloren. Neu ausgelöste Builds werden automatisch an die verbleibenden funktionierenden Zonen verteilt.
Bei einem regionalen Ausfall ist die Steuerungsebene offline, sodass derzeit ausgeführte Builds verzögert oder dauerhaft verloren gehen. Trigger, Worker-Pools und Build-Daten werden nie über Regionen hinweg repliziert. Wir empfehlen Ihnen, Trigger und Worker-Pools in mehreren Regionen vorzubereiten, um einen Ausfall zu minimieren.
Cloud CDN
Cloud CDN verteilt Inhalte und speichert Inhalte im Cache an vielen Standorten im Google-Netzwerk, um die Bereitstellungslatenz für Clients zu reduzieren. Im Cache gespeicherte Inhalte werden auf Best-Effort-Basis bereitgestellt. Wenn eine Anfrage nicht vom Cloud CDN-Cache verarbeitet werden kann, wird die Anfrage an Ursprungsserver wie Backend-VMs oder Cloud Storage-Buckets weitergeleitet, wo der ursprüngliche Inhalt gespeichert ist.
Wenn eine Zone oder Region ausfällt, sind die Caches an den betroffenen Standorten nicht verfügbar. Eingehende Anfragen werden an verfügbare Google Edge-Standorte und -Caches weitergeleitet. Wenn diese alternativen Caches die Anfrage nicht verarbeiten können, leiten sie die Anfrage an einen verfügbaren Ursprungsserver weiter. Wenn der Server die Anfrage mit aktuellen Daten verarbeiten kann, kommt es zu keinem Verlust von Inhalten. Eine erhöhte Rate von Cache-Fehlern führt dazu, dass beim Ursprungsserver höhere Traffic-Volumen als normalerweise auftreten, wenn die Caches gefüllt werden. Nachfolgende Anfragen werden über die Caches verarbeitet, die nicht vom Ausfall der Zone oder Region betroffen sind.
Weitere Informationen zu Cloud CDN und zum Cache-Verhalten finden Sie in der Cloud CDN-Dokumentation.
Cloud Composer
Cloud Composer ist ein verwalteter Dienst zur Workflow-Orchestrierung, mit dem Sie Workflows, die sich über Clouds und lokale Rechenzentren erstrecken, erstellen, planen, überwachen und verwalten können. Cloud Composer-Umgebungen basieren auf dem Open-Source-Projekt Apache Airflow.
Die Verfügbarkeit der Cloud Composer API ist von der zonalen Nichtverfügbarkeit nicht betroffen. Während eines Zonenausfalls behalten Sie den Zugriff auf die Cloud Composer API, einschließlich der Möglichkeit, neue Cloud Composer-Umgebungen zu erstellen.
Eine Cloud Composer-Umgebung enthält einen GKE-Cluster als Teil seiner Architektur. Während eines zonalen Ausfall werden die Workflows im Cluster möglicherweise unterbrochen:
- In Cloud Composer 1 ist der Cluster der Umgebung eine zonale Ressource. Daher kann ein zonaler Ausfall den Cluster nicht verfügbar machen. Workflows, die während des Ausfalls ausgeführt werden, können vor dem Abschluss beendet werden.
- In Cloud Composer 2 ist der Cluster der Umgebung eine regionale Ressource. Workflows, die auf Knoten in den Zonen ausgeführt werden, die von einem zonalen Ausfall betroffen sind, können jedoch vor dem Abschluss beendet werden.
In beiden Versionen von Cloud Composer kann ein zonaler Ausfall dazu führen, dass teilweise ausgeführte Workflows nicht mehr ausgeführt werden, einschließlich aller externen Aktionen, die vom Workflow konfiguriert wurden. Je nach Workflow können hierdurch Inkonsistenzen entstehen, z. B. wenn der Workflow inmitten einer mehrstufigen Ausführung zum Ändern externer Datenspeicher anhält. Daher sollten Sie beim Entwerfen Ihres Airflow-Workflows den Wiederherstellungsprozess berücksichtigen. Hierzu zählt auch, wie Sie teilweise nicht ausgeführte Workflow-Zustände erkennen und partielle Datenänderungen reparieren können.
In Cloud Composer 1 können Sie während eines zonalen Ausfalls eine neue Cloud Composer-Umgebung in einer anderen Zone starten. Da Airflow den Status Ihrer Workflows in seiner Metadatendatenbank behält, kann das Übertragen dieser Informationen in eine neue Cloud Composer-Umgebung zusätzliche Schritte und Vorbereitungen erfordern.
In Cloud Composer 2 können Sie zonale Ausfälle beheben, wenn Sie im Voraus eine Notfallwiederherstellung mit Umgebungs-Snapshots einrichten. Während eines Zonenausfalls können Sie zu einer anderen Umgebung wechseln, wenn Sie den Status Ihrer Workflows mit einem Umgebungs-Snapshot übertragen. Nur Cloud Composer 2 unterstützt die Notfallwiederherstellung mit Umgebungs-Snapshots.
Cloud Data Fusion
Cloud Data Fusion ist ein vollständig verwalteter, Datenintegrationsdienst für Unternehmen, die schnell Datenpipelines erstellen und verwalten möchten. Er bietet drei Versionen.
Zonale Ausfälle wirken sich auf Instanzen der Developer Edition aus.
Regionale Ausfälle betreffen Einfache- und Enterprise-Instanzen.
Um den Zugriff auf Ressourcen zu steuern, können Sie Pipelines in separaten Umgebungen entwerfen und ausführen. Durch diese Trennung können Sie eine Pipeline einmal entwerfen und dann in mehreren Umgebungen ausführen. Sie können Pipelines in beiden Umgebungen wiederherstellen. Weitere Informationen finden Sie unter Instanzdaten sichern und wiederherstellen.
Die folgenden Hinweise gelten sowohl für regionale als auch für zonale Ausfälle.
Ausfälle in der Pipeline-Designumgebung
Speichern Sie in der Designumgebung Pipelineentwürfe im Falle eines Ausfalls. Abhängig von den spezifischen RTO- und RPO-Anforderungen können Sie die gespeicherten Entwürfe verwenden, um die Pipeline während eines Ausfalls in einer anderen Cloud Data Fusion-Instanz wiederherzustellen.
Ausfälle in der Pipeline-Ausführungsumgebung
In der Ausführungsumgebung starten Sie die Pipeline intern mit Cloud Data Fusion-Triggern oder -Zeitplänen oder extern mit Orchestrierungstools wie Cloud Composer. Damit Sie Laufzeitkonfigurationen von Pipelines wiederherstellen können, sichern Sie die Pipelines und Konfigurationen wie Plug-ins und Zeitpläne. Bei einem Ausfall können Sie die Sicherung verwenden, um eine Instanz in einer nicht betroffenen Region oder Zone zu replizieren.
Eine weitere Möglichkeit zur Vorbereitung auf Ausfälle besteht darin, mehrere Instanzen in den Regionen mit derselben Konfiguration und derselben Pipeline zu haben. Wenn Sie die externe Orchestrierung verwenden, kann beim Ausführen von Pipelines das Load-Balancing zwischen Instanzen automatisch erfolgen. Achten Sie besonders darauf, dass keine Ressourcen (z. B. Datenquellen oder Orchestrierungstools) an eine einzelne Region gebunden sind und von allen Instanzen verwendet werden, da dies zu einem zentralen Schwachpunkt bei einem Ausfall werden könnte. Sie können beispielsweise mehrere Instanzen in verschiedenen Regionen haben und Cloud Load Balancing und Cloud DNS verwenden, um die Anfragen zur Pipelineausführung an eine Instanz weiterzuleiten, die nicht von einem Ausfall betroffen ist (siehe Beispielarchitekturen der Stufe 1 und Stufe 3).
Ausfälle anderer Google Cloud-Datendienste in der Pipeline
Ihre Instanz kann andere Google Cloud-Dienste wie Dataproc, Cloud Storage oder BigQuery als Datenquellen oder Pipeline-Ausführungsumgebungen verwenden. Diese Dienste können sich in verschiedenen Regionen befinden. Wenn eine regionenübergreifende Ausführung erforderlich ist, führt ein Fehler in einer der Regionen zu einem Ausfall. In diesem Szenario folgen Sie den standardmäßigen Schritten zur Notfallwiederherstellung. Die regionenübergreifende Einrichtung mit kritischen Diensten in verschiedenen Regionen ist jedoch weniger stabil.
Cloud Deploy
Cloud Deploy bietet Continuous Delivery von Arbeitslasten an Laufzeitdienste wie GKE und Cloud Run. Der Dienst besteht aus regionalen Instanzen, die Daten innerhalb einer Region synchron über Zonen hinweg replizieren.
Zonaler Ausfall: Die Vorgänge der Steuerungsebene sind nicht betroffen. Cloud Build-Builds (z. B. Rendering- oder Bereitstellungsvorgänge), die ausgeführt werden, wenn eine Zone fehlschlägt, werden jedoch verzögert oder gehen dauerhaft verloren. Während eines Ausfalls zeigt die Cloud Deploy-Ressource, die den Build ausgelöst hat (ein Release oder Rollout), einen Fehlerstatus, der angibt, dass der zugrunde liegende Vorgang fehlgeschlagen ist. Sie können die Ressource neu erstellen, um einen neuen Build in den verbleibenden funktionierenden Zonen zu starten. Erstellen Sie beispielsweise einen neuen Rollout, indem Sie den Release noch einmal für ein Ziel bereitstellen.
Regionaler Ausfall: Vorgänge der Steuerungsebene sind ebenso wie Daten von Cloud Deploy nicht verfügbar, bis die Region wiederhergestellt ist. Damit Sie den Dienst bei einem regionalen Ausfall einfacher wiederherstellen können, sollten Sie Ihre Lieferpipeline und Zieldefinitionen in der Versionsverwaltung speichern. Sie können diese Konfigurationsdateien verwenden, um Ihre Cloud Deploy-Pipelines in einer funktionierenden Region neu zu erstellen. Während eines Ausfalls gehen Daten über vorhandene Releases verloren. Erstellen Sie einen neuen Release, um weiterhin Software an Ihren Zielen bereitstellen zu können.
Cloud DNS
Cloud DNS ist ein stabiles, globales Hochleistungs-Domain Name System, der Ihre Domainnamen kostengünstig im globalen DNS veröffentlicht.
Bei einem Zonenausfall verarbeitet Cloud DNS weiterhin Anfragen aus einer anderen Zone in derselben oder einer anderen Region, ohne dass eine Unterbrechung auftritt. Aktualisierungen von Cloud DNS-Einträgen werden synchron über Zonen in der Region hinweg repliziert, in der sie empfangen sind. Daher gibt es keinen Datenverlust.
Im Falle eines regionalen Ausfalls verarbeitet Cloud DNS weiterhin Anfragen aus anderen Regionen. Es ist möglich, dass sehr neue Aktualisierungen von Cloud DNS-Einträgen nicht verfügbar sind, da Aktualisierungen zuerst in einer einzelnen Region verarbeitet werden, bevor sie asynchron in andere Regionen repliziert werden.
Cloud Functions
Cloud Functions ist eine zustandslose Rechenumgebung, in der Kunden ihren Funktionscode in der Infrastruktur von Google ausführen können. Cloud Functions ist ein regionales Angebot, d. h., Kunden können die Region auswählen, nicht jedoch die Zonen, aus denen eine Region besteht. Daten und Traffic werden automatisch auf Zonen in einer Region verteilt. Funktionen werden automatisch skaliert, um eingehenden Traffic zu verarbeiten, und nach Bedarf auf verschiedene Zonen verteilt. Jede Zone hat einen Planer, der dieses Autoscaling pro Zone bereitstellt. Außerdem wird die Auslastung anderer Zonen erkannt und zusätzliche Kapazitäten innerhalb von Zonen werden bereitgestellt, um Zonenausfälle kompensieren zu können.
Zonaler Ausfall: Cloud Functions speichert Metadaten sowie die bereitgestellte Funktion. Diese Daten werden regional gespeichert und synchron geschrieben. Die Cloud Functions Admin API gibt den API-Aufruf erst zurück, wenn die Daten an ein Quorum innerhalb einer Region übertragen wurden. Da die Daten regional gespeichert sind, sind die Vorgänge der Datenebene ebenfalls nicht von zonalen Ausfällen betroffen. Der Traffic wird bei einem Zonenausfall automatisch an andere Zonen weitergeleitet.
Regionaler Ausfall: Kunden wählen die Google Cloud-Region aus, in der sie ihre Funktion erstellen möchten. Daten werden nie über Regionen hinweg repliziert. Kunden-Traffic wird von Cloud Functions nie an eine andere Region weitergeleitet. Bei einem regionalen Ausfall wird Cloud Functions wieder verfügbar, sobald der Ausfall behoben ist. Kunden wird empfohlen, sie in mehreren Regionen bereitzustellen und Cloud Load Balancing zu verwenden, um bei Bedarf eine höhere Verfügbarkeit zu erreichen.
Cloud Healthcare API
Die Cloud Healthcare API, ein Dienst zum Speichern und Verwalten von Gesundheitsdaten, bietet Hochverfügbarkeit und bietet Schutz vor zonalen und regionalen Ausfällen, je nach ausgewählter Konfiguration.
Regionale Konfiguration: Die Cloud Healthcare API bietet in der Standardkonfiguration Schutz vor Zonenausfällen. Der Dienst wird in drei Zonen einer Region bereitgestellt, wobei die Daten dreifach in verschiedene Zonen innerhalb der Region gespeichert werden. Bei einem Zonenausfall, der sich entweder auf die Dienstebene oder auf die Datenebene auswirkt, übernehmen die verbleibenden Zonen ohne Unterbrechung. Wenn bei einer regionalen Konfiguration eine ganze Region ausfällt, in der sich der Dienst befindet, ist der Dienst erst wieder verfügbar, wenn die Region wieder online ist. Im unvorhergesehenen Fall einer physischen Zerstörung einer ganzen Region gehen die in dieser Region gespeicherten Daten verloren.
Multiregionale Konfiguration: In der multiregionalen Konfiguration wird die Cloud Healthcare API in drei Zonen bereitgestellt, die zu drei verschiedenen Regionen gehören. Außerdem werden Daten in drei Regionen repliziert. Dies schützt vor Dienstverlust bei einem Ausfall der gesamten Region, da die verbleibenden Regionen automatisch übernehmen würden. Strukturierte Daten wie FHIR werden synchron über mehrere Regionen hinweg repliziert, sodass sie bei einem Ausfall der gesamten Region vor Datenverlust geschützt sind. Daten, die in Cloud Storage-Buckets gespeichert sind, z. B. DICOM und Dictation oder große HL7v2/FHIR-Objekte, werden asynchron über mehrere Regionen hinweg repliziert.
Cloud Identity
Cloud Identity-Dienste sind auf mehrere Regionen verteilt und verwenden dynamisches Load-Balancing. In Cloud Identity können Nutzer keinen Ressourcenbereich auswählen. Wenn eine bestimmte Zone oder Region ausfällt, wird der Traffic automatisch auf andere Zonen oder Regionen verteilt.
Nichtflüchtige Daten werden in mehreren Regionen gespiegelt, wobei in den meisten Fällen eine synchrone Replikation erfolgt. Aus Leistungsgründen werden einige wenige Systeme, wie z. B. Caches oder Änderungen, die eine große Anzahl von Entitäten betreffen, asynchron über Regionen hinweg repliziert. Wenn die primäre Region ausfällt, in der die aktuellsten Daten gespeichert sind, stellt Cloud Identity veraltete Daten von einem anderen Speicherort bereit, bis die primäre Region wieder verfügbar ist.
Cloud Interconnect
Cloud Interconnect bietet Kunden über RFC 1918 Zugriff auf Google Cloud-Netzwerke von ihren lokalen Rechenzentren über physische Kabel, die mit Google Peering Edge verbunden sind.
Cloud Interconnect bietet Kunden ein SLA von 99,9 %, wenn sie Verbindungen zu zwei EADs (Edge Availability Domains) in einer Metropolregion bereitstellen. Ein SLA von 99,99 % ist verfügbar, wenn der Kunde mit globalem Routing Verbindungen in zwei EADs in zwei Metropolregionen in zwei Regionen bereitstellt. Weitere Informationen finden Sie unter Topologie für nicht kritische Anwendungen im Überblick und Topologie für Anwendungen auf Produktionsebene.
Cloud Interconnect ist unabhängig von der Computing-Zone und bietet Hochverfügbarkeit in Form von EADs. Bei einem EAD-Fehler wird die BGP-Sitzung für diese EAD unterbrochen und der Traffic wird zur anderen EAD geleitet.
Bei einem regionalen Ausfall werden die BGP-Sitzungen in dieser Region unterbrochen und der Traffic auf die Ressourcen in der Arbeitsregion übertragen. Dies gilt, wenn das globale Routing aktiviert ist.
Cloud Key Management Service
Cloud Key Management Service (Cloud KMS) bietet skalierbare und hochverfügbare kryptografische Schlüsselressourcenverwaltung. Cloud KMS speichert alle Daten und Metadaten in Spanner-Datenbanken, die eine hohe Datenlanglebigkeit und -verfügbarkeit mit synchroner Replikation bieten.
Cloud KMS-Ressourcen können in einer einzelnen Region, in mehreren Regionen oder weltweit erstellt werden.
Im Falle eines Zonenausfalls verarbeitet Cloud KMS weiterhin ohne Unterbrechung Anfragen aus einer anderen Zone in derselben oder einer anderen Region. Da die Daten synchron repliziert werden, treten weder Datenverlust noch Datenschäden auf. Wenn der Zonenausfall behoben wurde, wird die vollständige Redundanz wiederhergestellt.
Bei einem regionalen Ausfall sind die regionalen Ressourcen in dieser Region offline, bis die Region wieder verfügbar ist. Beachten Sie, dass auch innerhalb einer Region mindestens drei Replikate in separaten Zonen verwaltet werden. Wenn eine höhere Verfügbarkeit erforderlich ist, sollten die Ressourcen in einer multiregionalen oder globalen Konfiguration gespeichert werden. Multiregionale und globale Konfigurationen sind so konzipiert, dass sie auch bei einem regionalen Ausfall verfügbar bleiben, indem Daten in mehr als einer Region georedundant gespeichert und bereitgestellt werden.
Cloud External Key Manager (Cloud EKM)
Cloud External Key Manager ist in den Cloud Key Management Service eingebunden, damit Sie externe Schlüssel über unterstützte Drittanbieter steuern und aufrufen können. Sie können diese externen Schlüssel verwenden, um inaktive Daten zu verschlüsseln und für andere Google Cloud-Dienste zu verwenden, die die vom Kunden verwalteten Verschlüsselungsschlüssel (Customer-Managed Encryption Key, CMEK) unterstützen.
Zonaler Ausfall: Cloud External Key Manager ist aufgrund der Redundanz, die von mehreren Zonen in einer Region bereitgestellt wird, gegen zonale Ausfälle resistent. Wenn ein Zonenausfall auftritt, wird der Traffic auf andere Zonen innerhalb der Region umgeleitet. Während der Traffic umgeleitet wird, kann es zu einem Anstieg der Fehler kommen. Der Dienst ist jedoch weiterhin verfügbar.
Regionaler Ausfall: Cloud External Key Manager ist während eines regionalen Ausfalls in der betroffenen Region nicht verfügbar. Es gibt keinen Failover-Mechanismus, der Anfragen regionenübergreifend weiterleitet. Wir empfehlen Kunden, mehrere Regionen zum Ausführen ihrer Jobs zu verwenden.
Cloud External Key Manager speichert Kundendaten nicht dauerhaft. Daher gibt es während eines regionalen Ausfalls im Cloud External Key Manager-System keinen Datenverlust. Cloud External Key Manager hängt jedoch von der Verfügbarkeit anderer Dienste wie Cloud Key Management Service und externer Drittanbieter ab. Wenn diese Systeme während eines regionalen Ausfalls ausfallen, können Sie Daten verlieren. Das RPO/RTO dieser Systeme liegt nicht im Rahmen der Cloud External Key Manager-Zusicherungen.
Cloud Load Balancing
Cloud Load Balancing ist ein vollständig verteilter, softwarebasierter verwalteter Dienst. Mit Cloud Load Balancing kann eine einzelne Anycast-IP-Adresse als Frontend für Backends in Regionen auf der ganzen Welt dienen. Da der Dienst nicht hardwarebasiert ist, benötigen Sie keine Infrastruktur für physisches Load-Balancing. Load-Balancer sind ein sehr wichtiger Bestandteil der meisten hochverfügbaren Anwendungen.
Cloud Load Balancing bietet sowohl regionale als auch globale Load-Balancer. Sie profitieren auch von einem regionenübergreifenden Load-Balancing, einschließlich automatischen Failovers auf mehrere Regionen. Dabei wird der Traffic zu Failover-Back-Ends verschoben, wenn Ihre primären Back-Ends fehlerhaft werden.
Die globalen Load-Balancer sind sowohl zonalen als auch regionalen Ausfällen gegenüber geschützt. Die regionalen Load-Balancer halten zonalen Ausfällen stand, sind aber von Ausfällen in ihrer Region betroffen. In beiden Fällen ist es jedoch wichtig zu verstehen, dass die Ausfallsicherheit Ihrer gesamten Anwendung nicht nur vom Typ des bereitgestellten Load-Balancers, sondern auch von der Redundanz Ihrer Back-Ends abhängt.
Weitere Informationen zu Cloud Load Balancing und seinen Features finden Sie unter Übersicht über Cloud Load Balancing.
Cloud Logging
Cloud Logging besteht aus zwei Hauptteilen: dem Logs Router und dem Cloud Logging-Speicher.
Der Logs Router verarbeitet Streaming-Logereignisse und leitet die Logs an den Cloud Storage-, Pub/Sub-, BigQuery- oder Cloud Logging-Speicher weiter.
Der Cloud Logging-Speicher ist ein Dienst zum Speichern, Abfragen und Verwalten der Compliance für Logs. Er unterstützt viele Nutzer und Workflows, einschließlich Entwicklung, Compliance, Fehlerbehebung und proaktive Benachrichtigungen.
Logs Router und eingehende Logs: Während eines Zonenausfalls leitet die Cloud Logging API Logs an andere Zonen in der Region weiter. Normalerweise werden Logs, die vom Logs Router an Cloud Logging, BigQuery oder Pub/Sub weitergeleitet werden, so schnell wie möglich an ihren Zielort geschrieben, während an Cloud Storage gesendete Logs zwischengespeichert und stündlich in Batches geschrieben werden.
Logeinträge: Im Falle eines zonalen oder regionalen Ausfalls werden Logeinträge, die in der betroffenen Zone oder Region zwischengespeichert und nicht in das Exportziel geschrieben wurden, unzugänglich. Logbasierte Messwerte werden auch in Logs Router berechnet und unterliegen denselben Einschränkungen. Nach der Übermittlung an den ausgewählten Logexportort werden Logs gemäß dem Zieldienst repliziert. Logs, die in den Cloud Logging-Speicher exportiert werden, werden synchron über zwei Zonen in einer Region repliziert. Informationen zum Replikationsverhalten anderer Zieltypen finden Sie im entsprechenden Abschnitt in diesem Artikel. Beachten Sie, dass in Cloud Storage exportierte Logs stündlich zusammengefasst und geschrieben werden. Daher empfehlen wir die Verwendung von Cloud Logging-Speicher, BigQuery oder Pub/Sub, um die durch einen Ausfall beeinträchtigte Datenmenge zu minimieren.
Log-Metadaten: Metadaten wie Senken- und Ausschlusskonfigurationen werden global gespeichert, aber regional im Cache gespeichert, sodass bei einem Ausfall die regionalen Log Router-Instanzen funktionieren würden. Ausfälle einzelner Regionen haben keine Auswirkungen außerhalb der Region.
Cloud Monitoring
Cloud Monitoring besteht aus einer Vielzahl von miteinander verbundenen Features, wie z. B. integrierten und benutzerdefinierten Dashboards, Benachrichtigungen und Verfügbarkeitsmonitoring.
Die gesamte Cloud Monitoring-Konfiguration, einschließlich Dashboards, Verfügbarkeitsdiagnosen und Benachrichtigungsrichtlinien, ist global definiert. Alle Änderungen an ihnen werden synchron in mehrere Regionen repliziert. Daher sind sowohl bei zonalen als auch bei regionalen Ausfällen erfolgreiche Konfigurationsänderungen langlebig. Darüber hinaus kann es zwar zu vorübergehenden Lese- und Schreibfehlern kommen, wenn eine Zone oder Region anfangs ausfällt, aber Cloud Monitoring leitet Anfragen an verfügbare Zonen und Regionen weiter. In diesem Fall können Sie Konfigurationsänderungen mit exponentiellem Backoff wiederholen.
Beim Schreiben von Messwerten für eine bestimmte Ressource identifiziert Cloud Monitoring zuerst die Region, in der sich die Ressource befindet. Anschließend werden drei unabhängige Replikate der Messwertdaten innerhalb der Region geschrieben. Der regionale Schreibvorgang wird als erfolgreich zurückgegeben, sobald einer der drei Schreibvorgänge erfolgreich ist. Es kann nicht vorausgesetzt werden, dass sich die drei Replikate in verschiedenen Zonen innerhalb der Region befinden.
Zonal: Während eines zonalen Ausfalls sind Schreib- und Lesevorgänge von Messwerten für Ressourcen in der betroffenen Zone vollständig nicht verfügbar. Cloud Monitoring verhält sich praktisch so, als wäre die betroffene Zone nicht vorhanden.
Regional: Während eines regionalen Ausfalls sind Schreib- und Lesevorgänge von Messwerten für Ressourcen in der betroffenen Region vollständig nicht verfügbar. Cloud Monitoring verhält sich praktisch so, als wäre die betroffene Region nicht vorhanden.
Cloud NAT
Cloud NAT (Netzwerkadressübersetzung) ist ein verteilter, softwarebasierter verwalteter Dienst, der bestimmten Ressourcen ohne externe IP-Adressen ausgehende Verbindungen zum Internet ermöglicht. Cloud NAT basiert nicht auf Proxy-VMs oder -Appliances. Cloud NAT konfiguriert stattdessen die Andromeda-Software, die Ihr VPC-Netzwerk unterstützt, um SNAT (Source Network Address Translation) oder NAT (Network Address Translation) für VMs ohne externe IP-Adressen zu ermöglichen. Cloud NAT bietet auch Destination Network Address Translation (Ziel-NAT oder DNAT) für etablierte eingehende Antwortpakete.
Weitere Informationen zur Funktionalität von Cloud NAT finden Sie in der Dokumentation.
Zonaler Ausfall: Cloud NAT ist zonalen Ausfällen standhalten, da die Steuerungsebene und die Netzwerkdatenebene in mehreren Zonen innerhalb einer Region redundant sind.
Regionaler Ausfall: Cloud NAT ist ein regionales Produkt und kann daher einem regionalen Ausfall nicht standhalten.
Cloud Router
Cloud Router ist ein vollständig verteilter und verwalteter Google Cloud-Dienst, der das Border Gateway Protocol (BGP) verwendet, um IP-Adressbereiche zu bewerben. Er programmiert dynamische Routen auf der Grundlage von BGP-Advertisements, die von einem Peer empfangen werden. Anstelle eines physischen Geräts oder einer Appliance besteht jeder Cloud Router aus Softwareaufgaben, die als BGP-Speaker und -Responder dienen.
Bei einem zonalen Ausfall ist Cloud Router mit einer Hochverfügbarkeitskonfiguration (zonal) gegen zonale Ausfälle resistent. In diesem Fall kann eine Schnittstelle die Verbindung verlieren, der Traffic wird jedoch durch dynamisches Routing mit BGP an die andere Schnittstelle weitergeleitet.
Bei einem regionalen Ausfall ist Cloud Router ein regionales Produkt, das einem regionalen Ausfall nicht standhalten kann. Wenn Kunden den globalen Routingmodus aktiviert haben, ist das Routing zwischen der fehlgeschlagenen Region und anderen Regionen möglicherweise betroffen.
Cloud Run
Cloud Run ist eine zustandslose Rechenumgebung, in der Kunden ihren containerisierten Code in der Infrastruktur von Google ausführen können. Cloud Run ist ein regionales Angebot, d. h., Kunden können die Region auswählen, nicht jedoch die Zonen, aus denen eine Region besteht. Daten und Traffic werden automatisch auf Zonen in einer Region verteilt. Containerinstanzen werden automatisch skaliert, um eingehenden Traffic zu verarbeiten, und werden nach Bedarf auf die Zonen verteilt. Jede Zone hat einen Planer, der dieses Autoscaling pro Zone bereitstellt. Außerdem wird die Auslastung anderer Zonen erkannt und zusätzliche Kapazitäten innerhalb von Zonen werden bereitgestellt, um Zonenausfälle kompensieren zu können.
Zonaler Ausfall: Cloud Run speichert Metadaten sowie den bereitgestellten Container. Diese Daten werden regional gespeichert und synchron geschrieben. Die Cloud Run Admin API gibt den API-Aufruf erst zurück, wenn die Daten an ein Quorum innerhalb einer Region übertragen wurden. Da die Daten regional gespeichert sind, sind die Vorgänge der Datenebene ebenfalls nicht von zonalen Ausfällen betroffen. Der Traffic wird bei einem Zonenausfall automatisch an andere Zonen weitergeleitet.
Regionaler Ausfall: Kunden wählen die Google Cloud-Region aus, in der sie ihren Cloud Run-Dienst erstellen möchten. Daten werden nie über Regionen hinweg repliziert. Kunden-Traffic wird von Cloud Run nie an eine andere Region weitergeleitet. Bei einem regionalen Ausfall wird Cloud Run wieder verfügbar, sobald der Ausfall behoben ist. Kunden wird empfohlen, sie in mehreren Regionen bereitzustellen und Cloud Load Balancing zu verwenden, um bei Bedarf eine höhere Verfügbarkeit zu erreichen.
Cloud Shell
Cloud Shell bietet Google Cloud-Nutzern Zugriff auf Compute Engine-Instanzen für einzelne Nutzer, die für Onboarding-, Bildungs-, Entwicklungs- und Operatoraufgaben vorkonfiguriert sind.
Cloud Shell eignet sich nicht zum Ausführen von Anwendungsarbeitslasten und ist stattdessen für interaktive Entwicklungs- und Bildungsanwendungsfälle vorgesehen. Es hat Laufzeitlimits pro Nutzer, wird nach einer kurzen Inaktivitätszeit automatisch heruntergefahren und die Instanz kann nur auf den zugewiesenen Nutzer zugegriffen werden.
Die Compute Engine-Instanzen, die den Dienst unterstützen, sind zonale Ressourcen. Daher ist die Cloud Shell eines Nutzers bei einem Zonenausfall nicht verfügbar.
Cloud Source Repositories
Mit Cloud Source Repositories können Nutzer private Quellcode-Repositories erstellen und verwalten. Dieses Produkt wird mit einem globalen Modell entwickelt, sodass Sie es nicht für regionale oder zonale Ausfallsicherheit konfigurieren müssen.
Stattdessen replizieren git push-Vorgänge an Cloud Source Repositories synchron das Quell-Repository-Update auf mehrere Zonen in mehreren Regionen. Das bedeutet, dass der Dienst Ausfällen in einer Region ausgesetzt ist.
Wenn eine bestimmte Zone oder Region ausfällt, wird der Traffic automatisch auf andere Zonen oder Regionen verteilt.
Die Funktion zum automatischen Spiegeln von Repositories von GitHub oder Bitbucket kann von Problemen in diesen Produkten beeinträchtigt werden. Die Spiegelung ist beispielsweise betroffen, wenn GitHub oder Bitbucket Cloud Source Repositories nicht über neue Commits benachrichtigen kann oder Cloud Source Repositories keine Inhalte aus dem aktualisierten Repository abrufen kann.
Spanner
Spanner ist eine skalierbare, hochverfügbare, versionsübergreifende, synchron replizierte und strikt konsistente Datenbank mit relationaler Semantik.
Regionale Spanner-Instanzen replizieren Daten synchron in drei Zonen einer Region. Ein Schreibvorgang in eine regionale Spanner-Instanz wird synchron an alle drei Replikate gesendet und dem Client nach mindestens zwei Replikaten (Mehrheitsquorum von 2 aus 3) übergeben. Dadurch wird Spanner beständig gegenüber einem Ausfall einer Zone. Dazu wird Zugriff auf alle Daten bereitgestellt, da die neuesten Schreibvorgänge beibehalten wurden und ein Mehrheitsquorum für Schreibvorgänge weiterhin mit zwei Replikaten erreicht werden kann.
Multiregionale Spanner-Instanzen enthalten ein Schreibquorum, das Daten synchron über fünf Zonen in drei Regionen repliziert (zwei Lese-/Schreibreplikate jeweils in der Standard-Leader-Region und einer anderen Region; ein Replikat in der Zeugenregion). Ein Schreibvorgang in eine multiregionale Spanner-Instanz wird bestätigt, wenn mindestens drei Replikate (Mehrheitsquorum von 3 aus 5) den Schreibvorgang festgeschrieben haben. Wenn eine Zone oder Region ausfällt, hat Spanner Zugriff auf alle Daten (einschließlich der neuesten Schreibvorgänge) und verarbeitet Lese-/Schreibanfragen, da die Daten in mindestens drei Zonen in zwei Regionen gespeichert werden, wenn der Schreibvorgang für den Client bestätigt wird.
Weitere Informationen zu diesen Konfigurationen finden Sie in der Dokumentation zu Spanner. Weitere Informationen zur Funktionsweise der Cloud Spanner-Replikation finden Sie in der Dokumentation zur Replikation.
Cloud SQL
Cloud SQL ist ein vollständig verwalteter relationaler Datenbankdienst für MySQL, PostgreSQL und SQL Server. Cloud SQL verwendet zum Ausführen der Datenbanksoftware verwaltete virtuelle Compute Engine-Maschinen. Der Dienst bietet eine Konfiguration für Hochverfügbarkeit für die regionale Redundanz und schützt die Datenbank vor Zonenausfällen. Regionenübergreifende Replikate können bereitgestellt werden, um die Datenbank vor dem Ausfall einer Region zu schützen. Da das Produkt auch eine zonale Option bietet, die gegenüber dem Ausfall einer Zone oder Region nicht ausfallsicher ist, sollten Sie die Hochverfügbarkeitskonfiguration, regionenübergreifende Replikate oder beide Optionen nur mit Bedacht auswählen.
Zonenausfall: Mit der Option für Hochverfügbarkeit erstellen Sie eine primäre und eine Standby-VM-Instanz in zwei separaten Zonen innerhalb einer Region. Während des normalen Betriebs verarbeitet die primäre VM-Instanz alle Anfragen und schreibt die Datenbankdateien in eine regionale Persistent Disk, die synchron in die primäre Zone und in die Standby-Zonen repliziert wird. Wenn ein Zonenausfall die primäre Instanz betrifft, initiiert Cloud SQL einen Failover, bei dem die Persistent Disk an die Standby-VM angehängt und der Traffic umgeleitet wird.
Während dieses Vorgangs muss die Datenbank initialisiert werden, was die Verarbeitung aller Transaktionen einschließt, die in das Transaktionslog geschrieben, aber nicht auf die Datenbank angewendet wurden. Die Anzahl und der Typ der nicht verarbeiteten Transaktionen können die RTO-Zeit erhöhen. Aktuellste Schreibvorgänge können zu einem Rückstau unverarbeiteter Transaktionen führen. Die RTO-Zeit wird am stärksten beeinflusst durch (a) eine hohe aktuelle Schreibaktivität und (b) kürzliche Änderungen an Datenbankschemas.
Wenn der Zonenausfall behoben wurde, können Sie manuell einen Failback-Vorgang auslösen, um die Bereitstellung in der primären Zone fortzusetzen.
Weitere Informationen zur Hochverfügbarkeit finden Sie in der Dokumentation zu Cloud SQL für Hochverfügbarkeit.
Regionaler Ausfall: Mit der Option regionenübergreifendes Replikat schützen Sie Ihre Datenbank vor regionalen Ausfällen, indem Sie Lesereplikate Ihrer primären Instanz in anderen Regionen erstellen. Bei der regionenübergreifenden Replikation wird die asynchrone Replikation verwendet. Dies ermöglicht es der primären Instanz, einen Commit für Transaktionen durchzuführen, bevor diese per Commit auf Replikate festgelegt werden. Der Zeitunterschied zwischen dem Commit einer Transaktion auf der primären Instanz und dem Commit einer Transaktion auf dem Replikat wird als "Replikationsverzögerung" bezeichnet (was per Monitoring überwacht werden kann). Bei diesem Messwert werden sowohl Transaktionen berücksichtigt, die noch nicht von der primären Instanz an Replikate gesendet wurden, als auch Transaktionen, die vom Replikat empfangen, aber noch nicht verarbeitet wurden. Transaktionen, die nicht an das Replikat gesendet wurden, sind auch bei einem regionalen Ausfall nicht verfügbar. Transaktionen, die vom Replikat empfangen, aber nicht verarbeitet wurden, wirken sich wie unten beschrieben auf die Wiederherstellungszeit aus.
Cloud SQL empfiehlt daher, Ihre Arbeitslast mit einer Konfiguration zu testen, die ein Replikat enthält, um eine Begrenzung für "sichere Transaktionen pro Sekunde (TPS)" festzulegen. Diese entspricht dem höchsten kontinuierlichen TPS-Wert, der keine Replikationsverzögerung verursacht. Wenn Ihre Arbeitslast die sichere TPS-Begrenzung überschreitet, nimmt die Replikationsverzögerung zu, was sich negativ auf die RPO- und RTO-Werte auswirkt. Als allgemeine Richtlinie sollten Sie keine kleinen Instanzkonfigurationen verwenden (d. h. weniger als 2 vCPU-Kerne, Laufwerke kleiner als 100 GB oder PD-HDD), da diese zu Replikationsverzögerungen führen können.
Bei einem regionalen Ausfall müssen Sie entscheiden, ob ein Lesereplikat manuell hochgestuft werden soll. Es handelt sich deshalb um einen manuellen Vorgang, da das Hochstufen zu einer Split-Brain-Situation führen kann, in der das hochgestufte Replikat neue Transaktionen akzeptiert, obwohl es die primäre Instanz zum Zeitpunkt des Hochstufens verzögert hat. Dies kann zu Problemen führen, wenn der regionale Ausfall behoben ist, und Sie müssen die Transaktionen abgleichen, die nie von den Primär- zu den Replikat-Instanzen weitergegeben wurden. Wenn dies für Ihre Anforderungen problematisch ist, können Sie eine regionenübergreifende synchrone Replikationsdatenbank wie Spanner in Betracht ziehen.
Sobald der Vorgang vom Nutzer ausgelöst wird, folgt die Hochstufung ähnlichen Schritten wie die Aktivierung einer Standby-Instanz in der Hochverfügbarkeitskonfiguration. Bei diesem Prozess muss das Lesereplikat das Transaktionslog verarbeiten, das die insgesamt erforderliche Wiederherstellungszeit bestimmt. Da an der Replikat-Hochstufung kein integrierter Load Balancer beteiligt ist, leiten Sie Anwendungen manuell an die hochgestufte primäre Instanz weiter.
Weitere Informationen zur Option für regionenübergreifende Replikate finden Sie in der Dokumentation zu regionenübergreifenden Replikaten in Cloud SQL.
Weitere Informationen zur Cloud SQL-DR finden Sie hier:
- Notfallwiederherstellung von Cloud SQL for MySQL-Datenbanken
- Notfallwiederherstellung von Cloud SQL for PostgreSQL-Datenbanken
- Notfallwiederherstellung von Cloud SQL for SQL Server-Datenbanken
Cloud Storage
Cloud Storage bietet einen global einheitlichen, skalierbaren und höchst langlebigen Objektspeicher. Cloud Storage-Buckets können an einem von drei verschiedenen Standorttypen erstellt werden: in einer einzelnen Region, in zwei Regionen (biregional) oder in mehreren Regionen (multiregional) innerhalb eines Kontinents. Mit regionalen Buckets werden Objekte redundant über Verfügbarkeitszonen hinweg in einer einzelnen Region gespeichert. Biregionale und multiregionale Buckets hingegen sind georedundant. Dies bedeutet, dass Objekte redundant regionenübergreifend gespeichert werden, nachdem neu geschriebene Daten in mindestens einer Remote-Region repliziert wurden. Dieser Ansatz bietet Daten in biregionalen und multiregionalen Buckets umfassendere Schutzmaßnahmen, als mit Regional Storage erreicht werden kann.
Regionale Buckets sind so konzipiert, dass sie bei einem Ausfall in einer einzelnen Verfügbarkeitszone stabil sind. Wenn es bei einer Zone zu einem Ausfall kommt, werden Objekte in der nicht verfügbaren Zone automatisch und transparent von einem anderen Ort in der Region bereitgestellt. Daten und Metadaten werden zonenübergreifend beginnend mit dem ersten Schreibvorgang redundant gespeichert. Wenn eine Zone nicht mehr verfügbar ist, gehen keine Schreibvorgänge verloren. Bei einem regionalen Ausfall sind die regionalen Buckets in dieser Region offline, bis die Region wieder verfügbar ist.
Wenn Sie eine höhere Verfügbarkeit benötigen, können Sie Daten in einer biregionalen oder multiregionalen Konfiguration speichern. Biregionale und multiregionale Buckets sind einzelne Buckets (keine separaten primären und sekundären Standorte), die Daten und Metadaten redundant regionenübergreifend speichern. Bei einem regionalen Ausfall wird der Dienst nicht unterbrochen. Sie können sich biregionale und multiregionale Buckets mit zwei Regionen und mehreren Regionen als aktiv-aktiv vorstellen, da Sie Arbeitslasten in mehreren Regionen gleichzeitig lesen und schreiben können, während der Bucket strikt konsistent bleibt. Dies ist insbesondere für Kunden interessant, die ihre Arbeitslast im Rahmen einer Architektur zur Notfallwiederherstellung auf die beiden Regionen aufteilen möchten.
Biregionale und multiregionale Regionen sind strikt konsistent, da Metadaten immer synchron regionenübergreifend geschrieben werden. Bei diesem Ansatz kann der Dienst immer ermitteln, welche Version eines Objekts aktuell ist und wo es bereitgestellt werden kann, auch aus Remoteregionen.
Daten werden asynchron repliziert. Dies bedeutet, dass es ein RPO-Zeitfenster gibt, in dem neu geschriebene Objekte als regionale Objekte geschützt sind, mit Redundanz in Verfügbarkeitszonen innerhalb einer einzelnen Region. Der Dienst repliziert dann die Objekte in diesem RPO-Fenster in eine oder mehrere Remote-Regionen, um sie georedundant zu machen. Nachdem diese Replikation abgeschlossen ist, können Daten bei einem regionalen Ausfall automatisch und transparent aus einer anderen Region bereitgestellt werden. Die Turboreplikation ist eine Premiumfunktion, die für einen biregionalen Bucket verfügbar ist, um ein kleineres RPO-Fenster zu erhalten, das 100 % der neu geschriebenen Objekte repliziert und innerhalb von 15 Minuten georedundant gemacht wird.
Ein RPO ist ein wichtiger Aspekt, da während eines regionalen Ausfalls Daten, die kürzlich in die betroffene Region innerhalb des RPO-Fensters geschrieben wurden, möglicherweise noch nicht in andere Regionen repliziert wurden. Daher sind Daten während des Ausfalls möglicherweise nicht zugänglich und könnten im Falle einer physischen Zerstörung der Daten in der betroffenen Region verloren gehen.
Cloud Translation
Cloud Translation hat aktive Compute-Server in mehreren Zonen und Regionen. Außerdem wird die synchrone Datenreplikation über Zonen in Regionen unterstützt. Mit diesen Funktionen kann Translation sofort ein Failover erreichen, ohne dass Datenverluste bei zonalen Fehlern auftreten und ohne dass Eingaben oder Anpassungen von Kunden erforderlich sind. Bei einem regionalen Ausfall ist Cloud Translation nicht verfügbar.
Compute Engine
Compute Engine ist eine der Infrastructure as a Service-Optionen von Google Cloud. Sie verwendet die globale Infrastruktur von Google, um Kunden virtuelle Maschinen (und zugehörige Dienste) anzubieten.
Compute Engine-Instanzen sind zonale Ressourcen, d. h. dass im Falle eines Zonenausfalls standardmäßig keine Instanzen verfügbar sind. Compute Engine bietet verwaltete Instanzgruppen (Managed Instance Groups, MIGs), die automatisch zusätzliche VMs aus vorkonfigurierten Instanzvorlagen hochskalieren können, sowohl innerhalb einer einzigen Zone als auch über mehrere Zonen innerhalb einer Region hinweg. MIGs sind ideal für Anwendungen, die Widerstandsfähigkeit gegen Zonenverlust erfordern und zustandslos sind, aber Konfiguration und Ressourcenplanung erfordern. Mit mehreren regionalen MIGs können Sie regionale Ausfallsicherheit für zustandslose Anwendungen erreichen.
Anwendungen mit zustandsorientierten Arbeitslasten können weiterhin zustandsorientierte MIGs verwenden, für die jedoch zusätzliche Kapazitäten erforderlich sind, da sie nicht horizontal skaliert werden können. In beiden Szenarien ist es wichtig, Compute Engine-Instanzvorlagen und MIGs im Vorfeld ordnungsgemäß zu konfigurieren und zu testen, um sicherzustellen, dass die Failover-Funktionen für andere Zonen funktionieren. Weitere Informationen finden Sie oben im Abschnitt Eigene Referenzarchitekturen und -anleitungen entwickeln.
Einzelne Mandanten
Die Einzelmandantenfähigkeit ermöglicht Ihnen exklusiven Zugriff auf einen Knoten für einzelne Mandanten, bei dem es sich um einen physischen Compute Engine-Server handelt, der ausschließlich für das Hosten der VMs Ihres Projekts vorgesehen ist.
Knoten für einzelne Mandanten wie Compute Engine-Instanzen sind zonale Ressourcen. Im unwahrscheinlichen Fall eines zonalen Ausfalls sind sie nicht verfügbar. Zur Vermeidung zonaler Ausfälle können Sie einen Knoten für einzelne Mandanten in einer anderen Zone erstellen. Da bestimmte Arbeitslasten zu Lizenzierungs- oder CAPEX-Buchhaltungszwecken von Knoten für einzelne Mandanten profitieren können, sollten Sie eine Failover-Strategie im Voraus planen.
Wenn Sie diese Ressourcen an einem anderen Standort neu erstellen, können zusätzliche Lizenzierungskosten anfallen oder es kann sein, dass Sie gegen die CAPEX-Buchhaltungsanforderungen verstoßen. Allgemeine Anleitungen finden Sie unter Eigene Referenzarchitekturen und -anleitungen entwickeln.
Knoten für einzelne Mandanten sind zonale Ressourcen, die regionalen Ausfällen nicht standhalten können. Verwenden Sie für die zonenübergreifende Skalierung regionale MIGs.
Netzwerk für Compute Engine
Informationen zu Hochverfügbarkeitskonfigurationen für Interconnect-Verbindungen finden Sie in den folgenden Dokumenten:
Sie können externe IP-Adressen im globalen oder regionalen Modus bereitstellen. Dies wirkt sich auf ihre Verfügbarkeit aus, wenn ein regionaler Ausfall auftritt.
Ausfallsicherheit von Cloud Load Balancing
Load-Balancer sind ein sehr wichtiger Bestandteil der meisten hochverfügbaren Anwendungen. Beachten Sie, dass die Ausfallsicherheit der gesamten Anwendung nicht nur vom Bereich des ausgewählten Load-Balancers (global oder regional), sondern auch von der Redundanz Ihrer Backend-Dienste abhängt.
In der folgenden Tabelle wird die Ausfallsicherheit des Load-Balancers basierend auf der Verteilung oder dem Bereich des Load-Balancers zusammengefasst.
| Load-Balancer-Bereich | Architektur | Stabil bei zonalem Ausfall | Stabil bei regionalem Ausfall |
|---|---|---|---|
| Global | Jeder Load-Balancer ist auf alle Regionen verteilt. | ||
| Regionenübergreifend | Jeder Load-Balancer ist auf alle Regionen verteilt. | ||
| Regional | Jeder Load-Balancer ist auf mehrere Zonen in der Region verteilt. | Ein Ausfall in einer bestimmten Region wirkt sich auf die regionalen Load-Balancer in dieser Region aus. |
Weitere Informationen zur Auswahl eines Load-Balancers finden Sie in der Dokumentation zu Cloud Load Balancing.
Konnektivitätstests
Konnektivitätstests ist ein Diagnosetool, mit dem Sie die Konnektivität zwischen Netzwerkendpunkten prüfen können. Es analysiert Ihre Konfiguration und führt in einigen Fällen eine Live-Datenebenenanalyse zwischen den Endpunkten durch. Ein Endpunkt ist eine Quelle oder ein Ziel des Netzwerktraffics, z. B. eine VM, ein GKE-Cluster (Google Kubernetes Engine), eine Weiterleitungsregel für den Load-Balancer oder eine IP-Adresse im Internet. Konnektivitätstests sind ein Diagnosetool ohne Komponenten der Datenebene. Der Nutzertraffic wird nicht verarbeitet oder generiert.
Zonaler Ausfall: Konnektivitätstests-Ressourcen sind global. Sie können sie bei einem Zonenausfall verwalten und aufrufen. Konnektivitätstests-Ressourcen sind die Ergebnisse Ihrer Konfigurationstests. Diese Ergebnisse können die Konfigurationsdaten von zonalen Ressourcen (z. B. VM-Instanzen) in einer betroffenen Zone enthalten. Wenn es zu einem Ausfall kommt, sind die Analyseergebnisse nicht genau, da die Analyse auf veralteten Daten aus der Zeit vor dem Ausfall basiert. Sie sind also nicht verlässlich.
Regionaler Ausfall: Bei einem regionalen Ausfall können Sie weiterhin Konnektivitätstests-Ressourcen verwalten und ansehen. Ressourcen von Konnektivitätstests können Konfigurationsdaten regionaler Ressourcen wie Subnetzwerke in einer betroffenen Region enthalten. Wenn es zu einem Ausfall kommt, sind die Analyseergebnisse nicht genau, da die Analyse auf veralteten Daten aus der Zeit vor dem Ausfall basiert. Sie sind also nicht verlässlich.
Container Registry
Die Container Registry bietet eine skalierbare, gehostete Docker Registry-Implementierung, die Docker-Container-Images sicher und privat speichert. Die Container Registry implementiert die HTTP Docker Registry API.
Die Container Registry ist ein globaler Dienst, der Image-Metadaten standardmäßig synchron und redundant über mehrere Zonen und Regionen hinweg speichert. Container-Images werden in multiregionalen Cloud Storage-Buckets gespeichert. Mit dieser Speicherstrategie bietet die Container Registry in allen Fällen eine zonale Ausfallsicherheit und eine regionale Ausfallsicherheit für alle Daten, die von Cloud Storage asynchron in mehrere Regionen repliziert wurden.
Database Migration Service
Database Migration Service ist ein vollständig verwalteter Google Cloud-Dienst, mit dem Sie Datenbanken von anderen Cloudanbietern oder aus lokalen Rechenzentren zu Google Cloud migrieren können.
Database Migration Service ist als regionale Steuerungsebene konzipiert. Die Steuerungsebene ist nicht von einer einzelnen Zone in einer bestimmten Region abhängig. Während eines Zonenausfalls behalten Sie Zugriff auf die Database Migration Service APIs, einschließlich der Möglichkeit, Migrationsjobs zu erstellen und zu verwalten. Während eines regionalen Ausfalls haben Sie keinen Zugriff auf Database Migration Service-Ressourcen, die zu dieser Region gehören, bis der Ausfall behoben ist.
Database Migration Service hängt von der Verfügbarkeit der Quell- und Zieldatenbanken ab, die für den Migrationsvorgang verwendet werden. Wenn eine Quell- oder Zieldatenbank in Database Migration Service nicht verfügbar ist, wird der Migrationsvorgang unterbrochen; dabei gehen jedoch keine wichtigen Kunden- oder Jobdaten verloren. Der Migrationsjob wird erst wieder fortgesetzt, wenn die Quell- und Zieldatenbanken wieder verfügbar sind.
Sie können beispielsweise eine Cloud SQL-Zieldatenbank mit Hochverfügbarkeit (HA) konfigurieren, um eine Zieldatenbank abzurufen, die vor zonalen Ausfällen geschützt ist.
Migrationen in Database Migration Service erfolgen in zwei Phasen:
- Vollständiger Dump: Führt eine vollständige Datenkopie von der Quelle zum Ziel gemäß der Spezifikation des Migrationsjobs aus.
- Change Data Capture (CDC): Repliziert inkrementelle Änderungen von der Quelle zum Ziel.
Zonaler Ausfall: Wenn während einer dieser Phasen ein Zonenausfall auftritt, können Sie weiterhin auf Ressourcen in Database Migration Service zugreifen und diese verwalten. Die Datenmigration ist folgendermaßen betroffen:
- Vollständiger Dump: Die Datenmigration schlägt fehl; Sie müssen den Migrationsjob neu starten, sobald die Zieldatenbank den Failover-Vorgang abgeschlossen hat.
- CDC: Die Datenmigration wird pausiert. Der Migrationsjob wird automatisch fortgesetzt, sobald die Zieldatenbank den Failover-Vorgang abgeschlossen hat.
Regionaler Ausfall: Database Migration Service unterstützt keine regionenübergreifenden Ressourcen und ist daher nicht vor regionalen Ausfällen geschützt.
Dataflow
Dataflow ist der vollständig verwaltete und serverlose Datenverarbeitungsdienst von Google Cloud für Streaming- und Batchpipelines. Standardmäßig konfiguriert ein regionaler Endpunkt den Dataflow-Worker-Pool so, dass alle verfügbaren Zonen innerhalb der Region verwendet werden. Die Zonenauswahl wird für jeden Worker zum Zeitpunkt der Erstellung des Workers berechnet, um die Ressourcengewinnung und die -nutzung nicht verwendeter Reservierungen zu optimieren. In der Standardkonfiguration für Dataflow-Jobs werden Zwischendaten vom Dataflow-Dienst und der Status des Jobs im Backend gespeichert. Wenn eine Zone ausfällt, können Dataflow-Jobs weiterhin ausgeführt werden, da Worker in anderen Zonen neu erstellt werden.
Es gelten folgende Einschränkungen:
- Die regionale Platzierung wird nur für Jobs mit Streaming Engine oder Dataflow Shuffle unterstützt. Jobs, die Streaming Engine oder Dataflow Shuffle deaktiviert haben, können keine regionale Platzierung verwenden.
- Die regionale Platzierung gilt nur für VMs. Sie gilt nicht für Streaming Engine- und Dataflow Shuffle-bezogene Ressourcen.
- VMs werden nicht über mehrere Zonen repliziert. Wenn eine VM nicht mehr verfügbar ist, gelten ihre Arbeitselemente als verloren und werden von einer anderen VM noch einmal verarbeitet.
- Wenn eine regionsweiter Ressourcenmangel auftritt, kann der Dataflow-Dienst keine weiteren VMs mehr erstellen.
Dataflow-Pipelines für Hochverfügbarkeit aufbauen
Sie können mehrere Streamingpipelines parallel ausführen, um Daten mit Hochverfügbarkeit zu verarbeiten. Sie können beispielsweise zwei parallele Streamingjobs in verschiedenen Regionen ausführen. Das Ausführen paralleler Pipelines bietet geografische Redundanz und Fehlertoleranz für die Datenverarbeitung. Unter Berücksichtigung der geografischen Verfügbarkeit von Datenquellen und -senken können Sie End-to-End-Pipelines in einer hochverfügbaren, multiregionalen Konfiguration betreiben. Weitere Informationen finden Sie unter Hochverfügbarkeit und geografische Redundanz in „Dataflow-Pipeline-Workflows entwerfen“.
Bei einem Ausfall einer Zone oder Region können Sie Datenverluste vermeiden, indem Sie dasselbe Abo beim Pub/Sub-Thema wiederverwenden. Um sicherzustellen, dass Datensätze während des Shuffles nicht verloren gehen, verwendet Dataflow Upstream-Sicherungen. Dies bedeutet, dass der Worker, der die Datensätze sendet, RPCs wiederholt, bis er eine positive Bestätigung erhält, dass der Datensatz empfangen wurde und dass die Nebeneffekte bei der Verarbeitung des Datensatzes in den nachgelagerten nichtflüchtigen Speicher übergeben werden. Dataflow wiederholt RPCs auch dann, wenn der Worker, der die Datensätze sendet, nicht mehr verfügbar ist. Durch das Wiederholen von RPCs wird sichergestellt, dass jeder Datensatz genau einmal zugestellt wird. Weitere Informationen zur Garantie „Genau einmal“ von Dataflow finden Sie unter Genau einmal in Dataflow.
Wenn die Pipeline Gruppierung oder Zeitfenster verwendet, können Sie die Suchfunktion der Pub/Sub- oder Wiederholungsfunktion von Kafka nach einem zonalen oder regionalen Ausfall verwenden, um Datenelemente neu zu verarbeiten, um zu den gleichen Berechnungsergebnissen zu gelangen. Wenn die von der Pipeline verwendete Geschäftslogik nicht auf Daten vor dem Ausfall beruht, kann der Datenverlust der Pipeline-Ausgaben auf 0 Elemente reduziert werden. Wenn die Geschäftslogik der Pipeline auf Daten basiert, die vor dem Ausfall verarbeitet wurden (z. B. wenn lange fließende Fenster verwendet werden oder wenn in einem globalen Zeitfenster immer höhere Zähler gespeichert werden), verwenden Sie Dataflow-Snapshots, um den Zustand der Streamingpipeline zu speichern und eine neue Version Ihres Jobs zu starten, ohne den Zustand zu verlieren.
Dataproc
Dataproc bietet Funktionen für Streaming- und Batch-Datenverarbeitung. Dataproc ist als regionale Steuerungsebene konzipiert, die den Nutzern die Verwaltung von Dataproc-Clustern ermöglicht. Die Steuerungsebene ist nicht von einer einzelnen Zone in einer bestimmten Region abhängig. Daher behalten Sie während eines Zonenausfalls Zugriff auf die Dataproc APIs, einschließlich der Möglichkeit, neue Cluster zu erstellen.
Sie können Dataproc-Cluster auf folgenden Plattformen erstellen:
Dataproc-Cluster in Compute Engine
Da es sich bei einem Dataproc-Cluster in Compute Engine um eine zonale Ressource handelt, führt ein zonaler Ausfall dazu, dass der Cluster nicht verfügbar ist oder zerstört wird. Dataproc macht keinen automatischen Snapshot des Cluster-Status, sodass ein Zonenausfall zu einem Verlust der zu verarbeitenden Daten führen könnte. Dataproc speichert Nutzerdaten innerhalb des Dienstes nicht dauerhaft. Nutzer können ihre Pipelines so konfigurieren, dass Ergebnisse in viele Datenspeicher geschrieben werden. Sie sollten die Architektur des Datenspeichers berücksichtigen und ein Produkt wählen, das die erforderliche Ausfallsicherheit bietet.
Wenn es in einer Zone zu einem Ausfall kommt, können Sie eine neue Instanz des Clusters in einer anderen Zone erstellen. Dazu können Sie entweder eine andere Zone auswählen oder die automatische Platzierung in Dataproc verwenden, um automatisch eine verfügbare Zone auszuwählen. Sobald der Cluster verfügbar ist, kann die Datenverarbeitung fortgesetzt werden. Sie können einen Cluster auch mit aktiviertem Hochverfügbarkeitsmodus ausführen, wodurch die Wahrscheinlichkeit verringert wird, dass sich ein teilweiser Zonenausfall auf einen Master-Knoten und damit auf den gesamten Cluster auswirkt.
Dataproc-Cluster in GKE
Dataproc-Cluster in GKE können zonal oder regional sein.
Weitere Informationen zur Architektur und zu den DR-Funktionen von zonalen und regionalen GKE-Clustern finden Sie weiter unten in diesem Dokument im Abschnitt "Google Kubernetes Engine".
Document AI
Document AI ist eine Plattform zum Verstehen von Dokumenten, die unstrukturierte Daten aus Dokumenten in strukturierte Daten transformiert, um sie leichter zu verstehen, zu analysieren und zu nutzen. Document AI ist ein regionales Angebot. Kunden können die Region auswählen, aber nicht die Zonen innerhalb dieser Region. Daten und Traffic werden automatisch auf Zonen in einer Region verteilt. Server werden automatisch skaliert, um eingehenden Traffic zu verarbeiten, und nach Bedarf auf verschiedene Zonen verteilt. Jede Zone hat einen Planer, der dieses Autoscaling pro Zone bereitstellt. Der Planer erkennt auch die Last, die andere Zonen empfangen, und stellt zusätzliche Kapazitäten innerhalb der Zone bereit, um Zonenausfälle kompensieren zu können.
Zonaler Ausfall: Document AI speichert Nutzerdokumente und Prozessorversionsdaten. Diese Daten werden regional gespeichert und synchron geschrieben. Da die Daten regional gespeichert sind, sind die Vorgänge der Datenebene nicht von zonalen Ausfällen betroffen. Der Traffic wird bei einem zonalen Ausfall automatisch an andere Zonen mit einer Verzögerung weitergeleitet, die davon abhängt, wie lange die Wiederherstellung abhängiger Dienste wie Vertex AI dauert.
Regionaler Ausfall: Daten werden nie über Regionen hinweg repliziert. Während eines regionalen Ausfalls führt Document AI kein Failover durch. Kunden wählen die Google Cloud-Region aus, in der sie Document AI verwenden möchten. Dieser Kundentraffic wird jedoch nie an eine andere Region weitergeleitet.
Endpunktprüfung
Mit der Endpunktprüfung können Administratoren und Sicherheitsexperten ein Inventar von Geräten erstellen, die auf die Daten einer Organisation zugreifen. Die Endpunktprüfung bietet außerdem als Teil der Chrome Enterprise Premium-Lösung eine wichtige Gerätevertrauensstellung und eine sicherheitsbasierte Zugriffssteuerung.
Mit der Endpunktprüfung können Sie sich einen Überblick über die Sicherheitsstatus der Laptops und Computer Ihrer Organisation verschaffen. In Kombination mit Chrome Enterprise Premium-Angeboten hilft die Endpunktprüfung, eine detaillierte Zugriffssteuerung für Ihre Google Cloud-Ressourcen zu erzwingen.
Die Endpunktprüfung ist für Google Cloud, Cloud Identity, Google Workspace Business und Google Workspace Enterprise verfügbar.
Eventarc
Eventarc bietet asynchron bereitgestellte Ereignisse von Google-Anbietern (Erstanbieter), Nutzeranwendungen (Zweitanbieter) und Software as a Service (Drittanbieter) mit lose gekoppelten Diensten, die auf Statusänderungen reagieren. Damit können Kunden ihre Ziele konfigurieren (z. B. eine Cloud Run-Instanz oder eine Cloud Functions-Funktion der 2. Generation), die ausgelöst werden, wenn ein Ereignis in einem Ereignisanbieterdienst oder im Code des Kunden auftritt.
Zonaler Ausfall: Eventarc speichert Metadaten für Trigger. Diese Daten werden regional gespeichert und synchron geschrieben. Die Eventarc API, die Trigger und Kanäle erstellt und verwaltet, gibt den API-Aufruf nur zurück, wenn die Daten an ein Quorum innerhalb einer Region übergeben wurden. Da die Daten regional gespeichert sind, sind die Vorgänge der Datenebene nicht von zonalen Ausfällen betroffen. Bei einem Zonenausfall wird der Traffic automatisch an andere Zonen weitergeleitet. Eventarc-Dienste zum Empfangen und Bereitstellen von Zweitanbieter- und Drittanbieterereignissen werden zonenübergreifend repliziert. Diese Dienste sind regional verteilt. Anfragen an nicht verfügbare Zonen werden automatisch aus den verfügbaren Zonen in der Region bearbeitet.
Regionaler Ausfall: Kunden wählen die Google Cloud-Region aus, in der sie ihre Eventarc-Trigger erstellen möchten. Daten werden nie über Regionen hinweg repliziert. Kunden-Traffic wird von Eventarc nie an eine andere Region weitergeleitet. Bei einem regionalen Ausfall wird Eventarc wieder verfügbar, sobald der Ausfall behoben ist. Kunden wird empfohlen, Trigger in mehreren Regionen bereitzustellen, um eine höhere Verfügbarkeit zu erreichen.
Hinweis:
- Eventarc-Dienste zum Empfangen und Bereitstellen von eigenen Ereignissen werden auf Best-Effort-Basis bereitgestellt und sind nicht durch RTO/RPO abgedeckt.
- Die Zustellung von Eventarc-Ereignissen für Google Kubernetes Engine-Dienste erfolgt auf Best-Effort-Basis und ist nicht durch RTO/RPO abgedeckt.
Filestore
Die Basisstufe und die Skalierungsstufe Hoch sind zonale Ressourcen. Sie sind nicht tolerant gegenüber Ausfällen der bereitgestellten Zone oder Region.
Filestore-Instanzen der Enterprise-Stufe sind regionale Ressourcen. Filestore verwendet die für NFS erforderliche Richtlinie für strikte Konsistenz. Wenn ein Client Daten schreibt, gibt Filestore erst eine Bestätigung zurück, wenn die Änderung festgeschrieben und in zwei Zonen repliziert wurde, sodass nachfolgende Lesevorgänge die richtigen Daten zurückgeben.
Bei einem Zonenausfall sendet die Instanz der Enterprise-Stufe weiterhin Daten aus anderen Zonen und akzeptiert in der Zwischenzeit neue Schreibvorgänge. Sowohl die Lese- als auch die Schreibvorgänge können zu Leistungseinbußen führen. Der Schreibvorgang wird möglicherweise nicht repliziert. Die Verschlüsselung ist nicht beeinträchtigt, da der Schlüssel aus anderen Zonen bereitgestellt wird.
Wir empfehlen Clients, externe Sicherungen bei weiteren Ausfällen in anderen Zonen in derselben Region zu erstellen. Mit der Sicherung können Sie die Instanz in anderen Regionen wiederherstellen.
Firestore
Firestore ist eine flexible, skalierbare Datenbank für die Mobil-, Web- und Serverentwicklung über Firebase und Google Cloud. Firestore bietet multiregionale Datenreplikation, Garantien strikter Konsistenz, atomare Batchvorgänge und ACID-Transaktionen.
Firestore bietet Kunden sowohl einzelne Regionen als auch multiregionale Standorte an. Für den Traffic erfolgt automatisches Load-Balancing über Zonen in einer Region hinweg.
Regionale Firestore-Instanzen replizieren Daten synchron über mindestens drei Zonen. Bei einem Zonenausfall können Schreibvorgänge immer noch von den verbleibenden zwei (oder mehr) Replikaten durchgeführt werden und die übergebenen Daten werden beibehalten. Der Traffic wird automatisch an andere Zonen weitergeleitet. Ein regionaler Standort bietet niedrigere Kosten, eine geringere Schreiblatenz und die gemeinsame Speicherung mit anderen Google Cloud-Ressourcen.
Multiregionale Firestore-Instanzen replizieren Daten in fünf Zonen in drei Regionen (zwei Bereitstellungsregionen und eine Zeugenregion) synchron. Sie sind außerdem widerstandfähig gegenüber zonalen und regionalen Ausfällen. Bei einem zonalen oder regionalen Ausfall werden die übergebenen Daten beibehalten. Der Traffic wird automatisch an Bereitstellungszonen/-regionen weitergeleitet und Commits werden in den beiden verbleibenden Regionen weiterhin von mindestens drei Zonen bereitgestellt. Multiregionale Standorte maximieren die Verfügbarkeit und Langlebigkeit von Datenbanken.
Firewall Insights
Firewall Insights hilft Ihnen, Ihre Firewallregeln zu verstehen und zu optimieren. Sie erhalten Informationen, Empfehlungen und Messwerte zur Verwendung Ihrer Firewallregeln. Firewall Insights verwendet auch maschinelles Lernen, um die zukünftige Verwendung von Firewallregeln vorherzusagen. Mit Firewall Insights können Sie bei der Optimierung von Firewallregeln bessere Entscheidungen treffen. Beispielsweise identifiziert Firewall Insights Regeln, die es als zu weit gefasst klassifiziert. Anhand dieser Informationen können Sie eine strengere Konfiguration Ihrer Firewall einrichten.
Zonaler Ausfall: Da Firewall Insights-Daten zonenübergreifend repliziert werden, sind sie nicht von einem zonalen Ausfall betroffen und der Kundentraffic wird automatisch an andere Zonen weitergeleitet.
Regionaler Ausfall: Da Firewall Insights-Daten regionenübergreifend repliziert werden, sind sie nicht von einem regionalen Ausfall betroffen und der Kundentraffic wird automatisch an andere Regionen weitergeleitet.
Flotte
Mit Flotten können Kunden mehrere Kubernetes-Cluster als Gruppe verwalten und Plattformadministratoren die Verwendung von Multi-Cluster-Diensten ermöglichen. Mit Flotten können Administratoren beispielsweise einheitliche Richtlinien auf alle Cluster anwenden oder Multi-Cluster-Ingress einrichten.
Wenn Sie einen GKE-Cluster bei einer Flotte registrieren, hat der Cluster standardmäßig eine regionale Mitgliedschaft in derselben Region. Wenn Sie einen Drittanbieter-Cloud-Cluster bei einer Flotte registrieren, können Sie eine beliebige Region oder den globalen Standort auswählen. Es wird empfohlen, eine Region in der Nähe des physischen Standorts des Clusters auszuwählen. Dies ermöglicht eine optimale Latenz bei Verwendung des Connect-Gateways für den Zugriff auf den Cluster.
Bei einem zonalen Ausfall sind die Flotten-Funktionen nicht betroffen, es sei denn, der zugrunde liegende Cluster ist zonal und nicht mehr verfügbar.
Bei einem regionalen Ausfall schlagen Flotten-Funktionen für die Mitgliedschafts-Cluster in der Region statisch fehl. Die Risikominderung eines regionalen Ausfalls erfordert die Bereitstellung in mehreren Regionen, wie unter Architektonische Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur vorgeschlagen.
Google Cloud Armor
Mit Google Cloud Armor können Sie Ihre Bereitstellungen und Anwendungen vor mehreren Arten von Bedrohungen schützen. Dazu gehören volumetrische DDoS-Angriffe und Anwendungsangriffe wie Cross-Site-Scripting und SQL-Injection. Google Cloud Armor filtert unerwünschten Traffic bei Google Cloud-Load-Balancern und verhindert, dass dieser Traffic in Ihre VPC gelangt und Ressourcen verbraucht. Einige dieser Schutzfunktionen erfolgen automatisch. Für einige müssen Sie Sicherheitsrichtlinien konfigurieren und sie an Backend-Dienste oder Regionen anhängen. Google Cloud Armor-Sicherheitsrichtlinien mit globalem Geltungsbereich werden auf globale Load-Balancer angewendet. Sicherheitsrichtlinien mit regionalem Bereich werden auf regionale Load-Balancer angewendet.
Zonaler Ausfall: Bei einem Zonenausfall leiten Google Cloud-Load-Balancer Ihren Traffic an andere Zonen weiter, in denen fehlerfreie Backend-Instanzen verfügbar sind. Der Google Cloud Armor-Schutz ist sofort nach dem Traffic-Failover verfügbar, da Ihre Google Cloud Armor-Sicherheitsrichtlinien synchron in alle Zonen in einer Region repliziert werden.
Regionaler Ausfall: Bei regionalen Ausfällen leiten globale Google Cloud-Load-Balancer Ihren Traffic an andere Regionen weiter, in denen fehlerfreie Backend-Instanzen verfügbar sind. Der Google Cloud Armor-Schutz ist sofort nach dem Traffic-Failover verfügbar, da Ihre globalen Google Cloud Armor-Sicherheitsrichtlinien synchron in alle Regionen repliziert werden. Damit Sie vor regionalen Ausfällen geschützt sind, müssen Sie die regionalen Google Cloud Armor-Sicherheitsrichtlinien für alle Regionen konfigurieren.
Google Kubernetes Engine
Google Kubernetes Engine (GKE) bietet einen verwalteten Kubernetes-Dienst, indem die Bereitstellung containerisierter Anwendungen in Google Cloud optimiert wird. Sie können zwischen regionalen oder zonalen Cluster-Topologien wählen.
- Beim Erstellen eines zonalen Clusters stellt GKE eine Maschine der Steuerungsebene in der ausgewählten Zone sowie Worker-Maschinen (Knoten) innerhalb derselben Zone bereit.
- Für regionale Cluster stellt GKE drei Maschinen der Steuerungsebene in drei verschiedenen Zonen innerhalb der ausgewählten Region bereit. Standardmäßig sind Knoten über drei Zonen hinweg verteilt. Sie können aber auch einen regionalen Cluster erstellen, bei dem die Knoten nur in einer Zone bereitgestellt werden.
- Cluster mit mehreren Zonen ähneln zonalen Clustern, da sie eine Master-Maschine enthalten, aber zusätzlich die Möglichkeit bieten, Knoten über mehrere Zonen hinweg zu verteilen.
Zonaler Ausfall: Verwenden Sie regionale Cluster, um zonale Ausfälle zu vermeiden. Die Steuerungsebene und die Knoten werden auf drei verschiedene Zonen innerhalb einer Region verteilt. Ein Zonenausfall hat keinen Einfluss auf die Steuerungsebene und Worker-Knoten, die in den anderen beiden Zonen bereitgestellt werden.
Regionaler Ausfall: Die Risikominderung eines regionalen Ausfalls erfordert die Bereitstellung in mehreren Regionen. Obwohl die multiregionale Topologie derzeit nicht als integrierte Produktfunktion angeboten wird, stellt sie einen Ansatz dar, der bereits von zahlreichen GKE-Kunden verfolgt wird und manuell implementiert werden kann. Sie können mehrere regionale Cluster erstellen, um Ihre Arbeitslasten über mehrere Regionen hinweg zu replizieren, und den Traffic zu diesen Clustern mithilfe von Multi-Cluster-Ingress steuern.
HA VPN
HA VPN (Hochverfügbarkeit) ist ein stabiles Cloud VPN-Angebot, mit dem Sie Ihren Traffic von Ihrer lokalen privaten Cloud, einer anderen Virtual Private Cloud oder einem anderen Netzwerk des Cloud-Dienstanbieters sicher mit Google Cloud Virtual Private Cloud (VPC) verschlüsseln können.
Gateways von HA VPN haben zwei Schnittstellen, die jeweils eine IP-Adresse aus separaten IP-Adresspools haben, die sowohl logisch als auch physisch über verschiedene PoPs und Cluster verteilt sind, um eine optimale Redundanz zu gewährleisten.
Zonaler Ausfall: Bei einem zonalen Ausfall kann eine Schnittstelle die Verbindung verlieren, der Traffic wird jedoch über dynamisches Routing mit dem Border Gateway Protocol (BGP) an die andere Schnittstelle weitergeleitet.
Regionaler Ausfall: Bei einem regionalen Ausfall kann die Verbindung zwischen beiden Schnittstellen für kurze Zeit unterbrochen werden.
Identity and Access Management
Identity and Access Management (IAM) ist für alle Autorisierungsentscheidungen für Aktionen in Bezug auf Cloud-Ressourcen verantwortlich. IAM bestätigt, dass eine Richtlinie die Berechtigung für jede Aktion (in der Datenebene) gewährt. Die Aktualisierung dieser Richtlinien erfolgt über einen SetPolicy-Aufruf (auf der Steuerungsebene).
Alle IAM-Richtlinien werden in mehreren Zonen innerhalb jeder Region repliziert. Dadurch können Vorgänge der IAM-Datenebene nach Ausfällen anderer Regionen schnell wiederhergestellt werden und sind tolerant gegenüber Zonenausfällen in den einzelnen Regionen. Die Robustheit der IAM-Datenebene gegenüber Zonen- und Regionsausfällen ermöglicht multiregionale und multizonale Architekturen für eine hohe Verfügbarkeit.
Vorgänge der IAM-Steuerungsebene können von der regionenübergreifenden Replikation abhängen. Wenn SetPolicy-Aufrufe erfolgreich sind, wurden die Daten in mehrere Regionen geschrieben, die Weitergabe in andere Regionen ist jedoch letztendlich konsistent.
Die IAM-Steuerungsebene ist beim Ausfall einer einzelnen Region stabil.
Identity-Aware Proxy
Identity-Aware Proxy bietet Zugriff auf Anwendungen, die in Google Cloud, in anderen Clouds und lokal gehostet werden. IAP ist regional verteilt und Anfragen an nicht verfügbare Zonen werden automatisch aus anderen verfügbaren Zonen in der Region verarbeitet.
Regionale Ausfälle in IAP wirken sich auf den Zugriff auf die Anwendungen aus, die in der betroffenen Region gehostet werden. Wir empfehlen, in mehreren Regionen bereitzustellen und Cloud Load Balancing zu verwenden, um eine höhere Verfügbarkeit und Ausfallsicherheit bei regionalen Ausfällen zu erreichen.
Identity Platform
Mit Identity Platform können Kunden ihren Anwendungen anpassbare Identitäts- und Zugriffsverwaltung auf Google-Niveau hinzufügen. Identity Platform ist ein globales Angebot. Kunden können die Regionen oder Zonen, in denen ihre Daten gespeichert werden, nicht auswählen.
Zonaler Ausfall: Während eines zonalen Ausfalls überträgt Identity Platform Anfragen an die nächstgelegene Zelle. Alle Daten werden global gespeichert, sodass kein Datenverlust auftritt.
Regionaler Ausfall: Während eines regionalen Ausfalls schlagen Identity Platform-Anfragen an die nicht verfügbare Region vorübergehend fehl, während Identity Platform den Traffic aus der betroffenen Region entfernt. Sobald kein Traffic mehr in die betroffene Region vorhanden ist, leitet ein globaler Load-Balancing-Dienst für Server Anfragen an die nächste verfügbare fehlerfreie Region weiter. Alle Daten werden global gespeichert, es gibt also kein Datenverlust.
Knative Serving
Knative Serving ist ein globaler Dienst, mit dem Kunden serverlose Arbeitslasten auf Kundenclustern ausführen können. Damit soll sichergestellt werden, dass Knative-Serving-Arbeitslasten ordnungsgemäß auf Kundenclustern bereitgestellt werden und der Installationsstatus von Knative Serving in GKE Fleet API Feature Ressourcen angezeigt wird. Dieser Dienst wird nur bei der Installation oder Aktualisierung von Knative-Serving-Ressourcen auf Kundenclustern genutzt. Er ist nicht an der Ausführung von Clusterarbeitslasten beteiligt. Kundencluster, die zu Projekten gehören, für Knative Serving aktiviert ist, werden auf Replikate in mehreren Regionen verteilt und die Zonen werden von jedem Cluster von einem Replikat überwacht.
Zonaler und regionaler Ausfall: Cluster, die von Replikaten überwacht werden, die an einem Standort gehostet werden, an dem ein Ausfall stattfindet, werden automatisch auf fehlerfreie Replikate in anderen Zonen und Regionen verteilt. Während dieser Neuzuweisung kann es für kurze Zeit kommen, in der einige Cluster nicht von Knative Serving überwacht werden. Wenn der Nutzer während dieser Zeit die Knative-Serving-Funktionen im Cluster aktiviert, wird die Installation der Knative-Serving-Ressourcen im Cluster gestartet, sobald der Cluster wieder mit einem fehlerfreien Replikat des Knative-Serving-Dienstes verbunden ist.
Looker (Google Cloud Core)
Looker (Google Cloud Core) ist eine Business-Intelligence-Plattform, die die Bereitstellung, Konfiguration und Verwaltung einer Looker-Instanz über die Google Cloud Console vereinfacht und optimiert. Mit Looker (Google Cloud Core) können Nutzer Daten untersuchen, Dashboards erstellen, Benachrichtigungen einrichten und Berichte freigeben. Darüber hinaus bietet Looker (Google Cloud Core) eine IDE für Datenmodellierer sowie umfangreiche Einbettungs- und API-Funktionen für Entwickler.
Looker (Google Cloud Core) besteht aus regional isolierten Instanzen, die Daten zonenübergreifend in der Region synchron replizieren. Achten Sie darauf, dass sich die von Ihrer Instanz verwendeten Ressourcen, z. B. die Datenquellen, zu denen Looker (Google Cloud Core) eine Verbindung herstellt, in derselben Region befinden, in der Ihre Instanz ausgeführt wird.
Zonaler Ausfall: Looker-Instanzen (Google Cloud Core) speichern Metadaten und ihre eigenen bereitgestellten Container. Die Daten werden synchron über replizierte Instanzen geschrieben. Bei einem Zonenausfall werden Instanzen von Looker (Google Cloud Core) weiterhin über andere verfügbare Zonen in derselben Region bereitgestellt. Alle Transaktionen oder API-Aufrufe werden zurückgegeben, nachdem die Daten an ein Quorum innerhalb einer Region übergeben wurden. Wenn die Replikation fehlschlägt, wird die Transaktion nicht per Commit bestätigt und der Nutzer wird über den Fehler benachrichtigt. Wenn mehrere Zonen fehlschlagen, schlagen die Transaktionen auch fehl und der Nutzer wird benachrichtigt. Looker (Google Cloud Core) beendet alle derzeit ausgeführten Zeitpläne oder Abfragen. Sie müssen sie neu planen oder in die Warteschlange stellen, nachdem Sie den Fehler behoben haben.
Regionaler Ausfall: Looker-Instanzen (Google Cloud Core) in der betroffenen Region sind nicht verfügbar. Looker (Google Cloud Core) stoppt alle derzeit ausgeführten Zeitpläne oder Abfragen. Sie müssen die Abfragen noch einmal planen oder in die Warteschlange stellen, nachdem Sie den Fehler behoben haben. Sie können manuell neue Instanzen in einer anderen Region erstellen. Sie können Ihre Instanzen auch mit dem unter Daten von einer Looker-Instanz (Google Cloud Core) importieren oder exportieren definierten Prozess wiederherstellen. Wir empfehlen, einen regelmäßigen Datenexportprozess einzurichten, um die Assets im unwahrscheinlichen Fall eines regionalen Ausfalls zu kopieren.
Looker Studio
Looker Studio ist ein Datenvisualisierungs- und Business-Intelligence-Produkt. Damit können Kunden eine Verbindung zu in anderen Systemen gespeicherten Daten herstellen, mit den Daten Berichte und Dashboards erstellen und die Berichte und Dashboards im gesamten Unternehmen nutzen. Looker ist ein globaler Dienst, der es Nutzern nicht ermöglicht, einen Ressourcenbereich auszuwählen.
Bei einem Zonenausfall verarbeitet Looker Studio weiterhin Anfragen von einer anderen Zone in derselben Region oder in einer anderen Region, ohne dass eine Unterbrechung auftritt. Nutzerassets werden synchron über Regionen hinweg repliziert. Daher gibt es keinen Datenverlust.
Bei einem regionalen Ausfall verarbeitet Looker Studio weiterhin Anfragen aus einer anderen Region ohne Unterbrechung. Nutzerassets werden synchron über Regionen hinweg repliziert. Daher gibt es keinen Datenverlust.
Memorystore for Memcached
Memorystore for Memcached ist das verwaltete Memcached-Angebot von Google Cloud. Mit Memorystore for Memcached können Kunden Memcached-Cluster erstellen, die als Schlüssel/Wert-Datenbanken mit hohem Durchsatz für Anwendungen verwendet werden können.
Memcached-Cluster sind regional, wobei Knoten über alle vom Kunden angegebenen Zonen verteilt sind. Memcache repliziert jedoch keine Daten über Knoten hinweg. Daher kann ein zonaler Ausfall zu einem Datenverlust führen, der auch als teilweise Cache-Leerung bezeichnet wird. Memcache-Instanzen funktionieren weiterhin, haben jedoch weniger Knoten. Der Dienst startet während eines zonalen Ausfalls keine neuen Knoten. Memcache-Knoten in betroffenen Zonen verarbeiten weiterhin Traffic, wobei der Zonenausfall zu einer niedrigeren Cache-Trefferquote führt, bis die Zone wiederhergestellt ist.
Bei einem regionalen Ausfall stellen die Memcache-Knoten keinen Traffic bereit. In diesem Fall gehen Daten verloren, was zu einer vollständigen Cache-Leerung führt. Zur Vermeidung eines regionalen Ausfalls können Sie eine Architektur implementieren, die die Anwendung und Memorystore for Memcached in mehreren Regionen bereitstellt.
Memorystore for Redis
Memorystore for Redis ist ein vollständig verwalteter Redis-Dienst für Google Cloud, der den Aufwand für die Verwaltung komplexer Redis-Bereitstellungen reduzieren kann. Derzeit sind 2 Stufen verfügbar: Basis- und Standard-Stufe. Bei der Basis-Stufe führt ein zonaler oder regionaler Ausfall zu einem Datenverlust, der auch als vollständige Cache-Leerung bezeichnet wird. Bei der Standard-Stufe führt ein regionaler Ausfall zu einem Datenverlust. Ein zonaler Ausfall kann aufgrund der asynchronen Replikation einen teilweisen Datenverlust auf der Instanz der Standardstufe verursachen.
Zonaler Ausfall: Instanzen der Standard-Stufe replizieren Dataset-Vorgänge asynchron vom Dataset im primären Knoten auf den Replikatknoten. Wenn der Ausfall innerhalb der Zone des primären Knotens auftritt, wird der Replikatknoten zum primären Knoten hochgestuft. Während der Hochstufung tritt ein Failover auf und der Redis-Client muss die Verbindung zur Instanz wiederherstellen. Nach dem Wiederverbinden werden die Vorgänge fortgesetzt. Weitere Informationen zur Hochverfügbarkeit von Memorystore for Redis-Instanzen der Standard-Stufe finden Sie unter Hochverfügbarkeit von Memorystore for Redis.
Wenn Sie Lesereplikate auf Ihrer Instanz der Standardstufe aktivieren und nur ein Replikat haben, ist der Leseendpunkt für die Dauer eines zonalen Ausfalls nicht verfügbar. Weitere Informationen zur Notfallwiederherstellung von Lesereplikaten finden Sie unter Fehlermodi für Lesereplikate.
Regionaler Ausfall: Memorystore for Redis ist ein regionales Produkt, sodass eine einzelne Instanz einem regionalen Ausfall nicht standhalten kann. Alternativ können Sie regelmäßige Aufgaben planen, um eine Redis-Instanz in einen Cloud Storage-Bucket in einer anderen Region zu exportieren. Wenn ein regionaler Ausfall auftritt, können Sie die Redis-Instanz in einer anderen Region als der des exportierten Datasets wiederherstellen.
Multi-Cluster-Service-Discovery und Multi-Cluster-Ingress
GKE Multi-Cluster-Services (MCS) bestehen aus mehreren Komponenten. Zu den Komponenten gehören der Google Kubernetes Engine-Hub (der mehrere Google Kubernetes Engine-Cluster mithilfe von Mitgliedschaften orchestriert), die Cluster selbst und GKE-Hub-Controller (Multi-Cluster-Ingress, Multi-Cluster Service Discovery). Die Hub-Controller orchestrieren die Konfiguration des Compute Engine-Load-Balancers mithilfe von Back-Ends in mehreren Clustern.
Bei einem Zonenausfall verarbeitet Multi-Cluster Service Discovery weiterhin Anfragen aus einer anderen Zone oder Region. Bei einem regionalen Ausfall führt Multi-Cluster Service Discovery kein Failover durch.
Wenn der Konfigurationscluster bei einem zonalen Ausfall für Multi-Cluster-Ingress zonal ist und im Bereich des Fehlers liegt, muss der Nutzer ein Failover manuell ausführen. Die Datenebene ist ausfallsicher und leitet den Traffic so lange weiter, bis für den Nutzer ein Failover durchgeführt wurde. Verwenden Sie einen regionalen Cluster für den Konfigurationscluster, um die Notwendigkeit eines manuellen Failover zu vermeiden.
Bei einem regionalen Ausfall führt Multi-Cluster-Ingress kein Failover durch. Nutzer benötigen einen DR-Plan für ein manuelles Failover auf den Konfigurationscluster. Weitere Informationen finden Sie unter Multi-Cluster-Ingress einrichten und Multi-Cluster-Services konfigurieren.
Weitere Informationen zu GKE finden Sie im Abschnitt „Google Kubernetes Engine“ im Abschnitt Architektur der Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur.
Network Analyzer
Der Network Analyzer überwacht automatisch Ihre VPC-Netzwerkkonfigurationen und erkennt Fehlkonfigurationen und suboptimale Konfigurationen. Sie erhalten Informationen zu Netzwerktopologie, Firewallregeln, Routen, Konfigurationsabhängigkeiten und zu Verbindungen zu Diensten und Anwendungen. Der Analyzer ermittelt Netzwerkfehler, bietet mögliche Ursacheninformationen und schlägt Lösungen vor.
Der Network Analyzer wird kontinuierlich ausgeführt und löst basierend auf Aktualisierungen in Fast-Echtzeit in Ihrem Netzwerk relevante Analysen aus. Wenn der Network Analyzer einen Netzwerkfehler erkennt, wird versucht, den Fehler mit den letzten Konfigurationsänderungen zu korrelieren, um die Ursache zu identifizieren. Wo möglich werden Empfehlungen zur Problembehebung gegeben.
Network Analyzer ist ein Diagnosetool ohne Komponenten der Datenebene. Der Nutzertraffic wird nicht verarbeitet oder generiert.
Zonaler Ausfall: Der Network Analyzer-Dienst wird global repliziert und seine Verfügbarkeit ist von einem zonalen Ausfall nicht betroffen.
Wenn Statistiken vom Network Analyzer Konfigurationen aus einer Zone enthalten, die ausfällt, wirkt sich das auf die Datenqualität aus. Die Netzwerkstatistiken, die sich auf Konfigurationen in dieser Zone beziehen, sind dann veraltet. Verlassen Sie sich bei Ausfällen nicht auf Statistiken, die vom Network Analyzer bereitgestellt werden.
Regionaler Ausfall: Der Network Analyzer-Dienst wird global repliziert und seine Verfügbarkeit ist von einem regionalen Ausfall nicht betroffen.
Wenn Statistiken vom Network Analyzer Konfigurationen aus einer Region enthalten, die ausfällt, wirkt sich das auf die Datenqualität aus. Die Netzwerkstatistiken, die sich auf Konfigurationen in dieser Region beziehen, sind dann veraltet. Verlassen Sie sich bei Ausfällen nicht auf Statistiken, die vom Network Analyzer bereitgestellt werden.
Netzwerktopologie
Netzwerktopologie ist ein Visualisierungstool, das zur Veranschaulichung der Topologie Ihrer Netzwerkinfrastruktur dient. In der Infrastrukturansicht werden VPC-Netzwerke (Virtual Private Cloud), Hybridkonnektivität zu und von Ihren lokalen Netzwerken, die Verbindung zu von Google verwalteten Diensten und die zugehörigen Messwerte angezeigt.
Zonaler Ausfall: Bei einem Zonenausfall werden Daten für diese Zone nicht in Netzwerktopologie angezeigt. Daten für andere Zonen sind davon nicht betroffen.
Regionaler Ausfall: Bei einem regionalen Ausfall werden Daten für diese Region nicht in Netzwerktopologie angezeigt. Daten für andere Regionen sind nicht betroffen.
Dashboard zur Leistungsüberwachung
Über Dashboards zur Leistungsüberwachung erhalten Sie Einblick in die Leistung des gesamten Google Cloud-Netzwerks und die Leistung Ihrer Projektressourcen.
Mit diesen Leistungsüberwachungsfunktionen können Sie zwischen Problemen in Ihrer Anwendung und Problemen im zugrunde liegenden Google Cloud-Netzwerk unterscheiden. Sie können auch Probleme mit der bisherigen Leistung des Netzwerks untersuchen. Dashboards zur Leistungsüberwachung exportieren auch Daten nach Cloud Monitoring. Mit Monitoring können Sie die Daten abfragen und auf zusätzliche Informationen zugreifen.
Zonaler Ausfall:
Bei einem Zonenausfall werden Latenz- und Paketverlustdaten für Traffic aus der betroffenen Zone nicht im Dashboard zur Leistungsüberwachung angezeigt. Latenz- und Paketverlustdaten für Traffic aus anderen Zonen sind nicht betroffen. Wenn der Ausfall endet, werden die Latenz- und Paketverlustdaten fortgesetzt.
Regionaler Ausfall:
Bei einem regionalen Ausfall werden Latenz- und Paketverlustdaten für Traffic aus der betroffenen Region nicht im Dashboard zur Leistungsüberwachung angezeigt. Latenz- und Paketverlustdaten für Traffic aus anderen Regionen sind nicht betroffen. Wenn der Ausfall endet, werden die Latenz- und Paketverlustdaten fortgesetzt.
Network Connectivity Center
Network Connectivity Center ist ein Produkt zur Verwaltung von Netzwerkverbindungen, das eine Hub-and-Spoke-Architektur verwendet. Bei dieser Architektur dient eine zentrale Verwaltungsressource als Hub und jede Verbindungsressource als Spoke. Hybrid-Spokes unterstützen derzeit HA VPN-, Dedicated und Partner Interconnect- sowie SD-WAN-Router-Appliances von wichtigen Drittanbietern. Mit den Network Connectivity Center-Hybrid-Spokes können Unternehmen Google Cloud-Arbeitslasten und -Dienste über die globale Reichweite des Google Cloud-Netzwerks mit lokalen Rechenzentren, anderen Clouds und ihren Zweigstellen verbinden.
Zonaler Ausfall: Ein Network Connectivity Center-Hybrid-Spoke mit Hochverfügbarkeitskonfiguration kann zonalen Ausfällen standhalten, da die Steuerungsebene und die Netzwerkdatenebene in mehreren Zonen innerhalb einer Region redundant sind.
Regionaler Ausfall: Ein Network Connectivity Center-Hybrid-Spoke ist eine regionale Ressource und kann daher regionalen Ausfällen nicht standhalten.
Netzwerkdienststufen
In Netzwerkdienststufen können Sie Verbindungen zwischen Systemen im Internet und Ihren Google Cloud-Instanzen optimieren. Sie können zwischen zwei verschiedenen Dienststufen wählen: der Premium- und der Standard-Stufe. In der Premium-Stufe kann eine global angekündigte IP-Adresse der Anycast-Premium-Stufe als Frontend für regionale oder globale Backends dienen. Bei der Standard-Stufe kann eine regional angekündigte IP-Adresse der Standard-Stufe als Frontend für regionale Backends dienen. Die allgemeine Ausfallsicherheit einer Anwendung wird sowohl von der Netzwerkdienststufe als auch von der Redundanz der Backends, denen sie zugeordnet ist, beeinflusst.
Zonaler Ausfall: Sowohl die Premium- als auch die Standard-Stufe bieten Ausfallsicherheit bei zonalen Ausfällen, wenn sie mit regional redundanten Backends verknüpft sind. Wenn ein Zonenausfall auftritt, wird das Failover-Verhalten für Fälle mit regional redundanten Backends von den zugehörigen Backends selbst bestimmt. In Verbindung mit zonalen Backends wird der Dienst wieder verfügbar, sobald der Ausfall behoben ist.
Regionaler Ausfall: Die Premium-Stufe bietet Sicherheit bei regionalen Ausfällen, wenn sie mit global redundanten Backends verknüpft ist. In der Standard-Stufe schlägt der gesamte Traffic zur betroffenen Region fehl. Der Traffic zu allen anderen Regionen ist davon nicht betroffen. Wenn ein regionaler Ausfall auftritt, wird das Failover-Verhalten für Fälle, die die Premium-Stufe mit global redundanten Backends verwenden, von den zugehörigen Backends selbst bestimmt. Bei Verwendung der Premium-Stufe mit regionalen Backends oder der Standard-Stufe wird der Dienst wieder verfügbar, sobald der Ausfall behoben ist.
Paketspiegelung
Bei der Paketspiegelung wird Traffic bestimmter Instanzen in Ihrem VPC-Netzwerk (Virtual Private Cloud) geklont und die geklonten Daten werden zur Prüfung an Instanzen hinter einem regionalen internen Load Balancer weitergeleitet. Bei der Paketspiegelung werden alle Traffic- und Paketdaten erfasst, einschließlich Nutzlasten und Headern.
Weitere Informationen zur Funktionalität der Paketspiegelung finden Sie auf der Seite Paketspiegelung – Übersicht.
Zonaler Ausfall: Konfigurieren Sie den internen Load Balancer so, dass Instanzen in mehreren Zonen vorhanden sind. Wenn ein Zonenausfall auftritt, werden die geklonten Pakete bei der Paketspiegelung in eine fehlerfreie Zone umgeleitet.
Regionaler Ausfall: Die Paketspiegelung ist ein regionales Produkt. Bei einem regionalen Ausfall werden Pakete in der betroffenen Region nicht geklont.
Persistent Disk
Persistent Disks sind in zonalen und regionalen Konfigurationen verfügbar.
Zonale Persistent Disks werden in einer einzigen Zone gehostet. Wenn die Zone der Disk nicht verfügbar ist, ist die Persistent Disk nicht verfügbar, bis der Zonenausfall behoben wurde.
Regionale Persistent Disks ermöglichen die synchrone Replikation von Daten zwischen zwei Zonen in einer Region. Bei einem Ausfall in der Zone Ihrer virtuellen Maschine können Sie erzwingen, dass eine regionale Persistent Disk an eine VM-Instanz in der sekundären Zone der Disk angehängt wird. Hierfür müssen Sie entweder eine weitere VM-Instanz in dieser Zone starten oder Sie verwalten eine VM-Instanz mit Hot-Standby in dieser Zone.
Personalized Service Health
Personalized Service Health kommuniziert Dienstunterbrechungen, die für Ihre Google Cloud-Projekte relevant sind. Dieses Dashboard bietet mehrere Kanäle und Prozesse, um störende Ereignisse (Vorfälle, geplante Wartungsarbeiten) anzusehen oder in Ihren Prozess zur Reaktion auf Vorfälle zu integrieren, darunter:
- Ein Dashboard in der Google Cloud Console
- Eine Dienst-API
- Konfigurierbare Benachrichtigungen
- Generierte und an Cloud Logging gesendete Logs
Zonaler Ausfall: Die Daten werden aus einer globalen Datenbank bereitgestellt, ohne von bestimmten Standorten abhängig zu sein. Wenn ein Zonenausfall auftritt, kann Service Health Anfragen verarbeiten und den Traffic automatisch an Zonen in derselben Region umleiten, die noch funktionieren. Service Health kann API-Aufrufe erfolgreich zurückgeben, wenn Ereignisdaten aus der Service Health-Datenbank abgerufen werden können.
Regionaler Ausfall: Die Daten werden aus einer globalen Datenbank bereitgestellt, ohne von bestimmten Standorten abhängig zu sein. Bei einem regionalen Ausfall kann Service Health weiterhin Anfragen verarbeiten, jedoch möglicherweise mit reduzierter Kapazität. Regionale Fehler an Logging-Standorten können sich auf Service Health-Nutzer auswirken, die Logs oder Cloud-Benachrichtigungen verwenden.
Private Service Connect
Private Service Connect ist eine Funktion des Google Cloud-Netzwerks, mit der Nutzer privat aus ihrem VPC-Netzwerk auf verwaltete Dienste zugreifen können. Ebenso können Ersteller verwalteter Dienste diese Dienste in ihren eigenen separaten VPC-Netzwerken hosten und ihren Nutzern eine private Verbindung bieten.
Private Service Connect-Endpunkte für veröffentlichte Dienste
Ein Private Service Connect-Endpunkt stellt mithilfe einer Private Service Connect-Weiterleitungsregel eine Verbindung zu Diensten in einem VPC-Netzwerk von Erstellern verwalteter Dienste her. Der Dienstersteller stellt einen Dienst über eine private Verbindung zu einem Dienstnutzer bereit. Dazu stellt er einen einzelnen Dienstanhang bereit. Anschließend kann der Dienstnutzer eine virtuelle IP-Adresse aus seiner VPC für diesen Dienst zuweisen.
Zonaler Ausfall: Private Service Connect-Traffic, der vom VM-Traffic stammt, der von VPC-Client-Endpunkten generiert wird, kann weiterhin auf bereitgestellte verwaltete Dienste im internen VPC-Netzwerk des Diensterstellers zugreifen. Dieser Zugriff ist möglich, da Private Service Connect-Traffic auf fehlerfreie Dienst-Back-Ends in einer anderen Zone übertragen wird.
Regionaler Ausfall: Private Service Connect ist ein regionales Produkt. Es ist nicht anfällig für regionale Ausfälle. Multiregionale verwaltete Dienste können Hochverfügbarkeit bei einem regionalen Ausfall erreichen, indem sie Private Service Connect-Endpunkte in mehreren Regionen konfigurieren.
Private Service Connect-Endpunkte für Google APIs
Ein privater Service Connect-Endpunkt stellt mithilfe einer Private Service Connect-Weiterleitungsregel eine Verbindung zu Google APIs her. Mit dieser Weiterleitungsregel können Kunden benutzerdefinierte Endpunktnamen mit ihren internen IP-Adressen verwenden.
Zonaler Ausfall: Private Service Connect-Traffic von VPC-Clientendpunkten von Nutzern kann weiterhin auf Google APIs zugreifen, da die Verbindung zwischen der VM und dem Endpunkt automatisch per Failover auf eine andere funktionale Zone in derselben Region übertragen wird. Anfragen, die bereits zu Beginn eines Ausfalls aktiv sind, hängen vom TCP-Zeitlimit und dem Wiederholungsverhalten des Clients für die Wiederherstellung ab.
Weitere Informationen finden Sie unter Compute Engine-Wiederherstellung.
Regionaler Ausfall: Private Service Connect ist ein regionales Produkt. Es ist nicht anfällig für regionale Ausfälle. Multiregionale verwaltete Dienste können Hochverfügbarkeit bei einem regionalen Ausfall erreichen, indem sie Private Service Connect-Endpunkte in mehreren Regionen konfigurieren.
Weitere Informationen zu Private Service Connect finden Sie im Abschnitt „Endpunkte“ unter Private Service Connect-Typen.
Pub/Sub
Pub/Sub ist ein Messaging-Dienst für Anwendungsintegration und Streaminganalysen. Pub/Sub-Themen sind global, d. h. sie sind von jedem Google Cloud-Standort aus sichtbar und zugänglich. Jede Nachricht wird jedoch in einer einzelnen Google Cloud-Region gespeichert, die dem Publisher am nächsten liegt und von der Richtlinie für Ressourcenstandorte zugelassen ist. Bei einem Thema können Nachrichten also in verschiedenen Regionen innerhalb von Google Cloud gespeichert sein. Die Pub/Sub-Nachrichtenspeicherrichtlinie kann die Regionen einschränken, in denen Nachrichten gespeichert werden.
Zonaler Ausfall: Wenn eine Pub/Sub-Nachricht veröffentlicht wird, wird sie synchron in mindestens zwei Zonen innerhalb der Region geschrieben. Wenn also eine einzelne Zone nicht mehr verfügbar ist, hat dies für Kunden keine sichtbaren Auswirkungen.
Regionaler Ausfall: Während eines regionalen Ausfalls sind die in der Region gespeicherten Nachrichten nicht zugänglich. Publisher und Abonnenten, die entweder über einen regionalen Endpunkt oder den globalen Endpunkt mit der betroffenen Region verbunden sind, können keine Verbindung herstellen. Publisher und Abonnenten, die eine Verbindung zu anderen Regionen herstellen, können trotzdem eine Verbindung herstellen. Nachrichten in anderen Regionen werden an Abonnenten im Netzwerk gesendet, die Kapazitäten haben.
Wenn Ihre Anwendung auf die Nachrichtenreihenfolge angewiesen ist, lesen Sie die detaillierten Empfehlungen vom Pub/Sub-Team. Garantien zur Nachrichtenreihenfolge werden pro Region bereitgestellt und können bei der Verwendung eines globalen Endpunkts beeinträchtigt werden.
reCAPTCHA
reCAPTCHA ist ein globaler Dienst, der betrügerische Aktivitäten, Spam und Missbrauch erkennt. Die Konfiguration für regionale oder zonale Ausfallsicherheit ist nicht erforderlich oder möglich. Aktualisierungen von Konfigurationsmetadaten werden asynchron in jede Region repliziert, in der reCAPTCHA ausgeführt wird.
Bei einem Zonenausfall verarbeitet reCAPTCHA weiterhin Anfragen aus einer anderen Zone in derselben oder einer anderen Region, ohne dass eine Unterbrechung auftritt.
Bei einem regionalen Ausfall verarbeitet reCAPTCHA weiterhin Anfragen aus einer anderen Region ohne Unterbrechung.
Secret Manager
Secret Manager ist ein Produkt für die Verwaltung von Secrets und Anmeldedaten für Google Cloud. Mit Secret Manager können Sie den Zugriff auf Secrets einfach prüfen und einschränken, Secrets im Ruhezustand verschlüsseln und dafür sorgen, dass vertrauliche Informationen in Google Cloud gesichert sind.
Secret Manager-Ressourcen werden normalerweise mit der automatischen Replikationsrichtlinie erstellt (empfohlen), wodurch sie global repliziert werden. Wenn Ihre Organisation Richtlinien hat, die eine globale Replikation von Secret-Daten nicht zulassen, können Secret Manager-Ressourcen mit nutzerverwalteten Replikationsrichtlinien erstellt werden, in denen eine oder mehrere Regionen als Replikationsziel für ein Secret ausgewählt werden.
Zonenausfall: Bei einem Zonenausfall verarbeitet Secret Manager weiterhin Anfragen aus einer anderen Zone in derselben oder einer anderen Region ohne Unterbrechung. In jeder Region verwaltet Secret Manager immer mindestens zwei Replikate in separaten Zonen (in den meisten Regionen drei Replikate). Wenn der Zonenausfall behoben wurde, wird die vollständige Redundanz wiederhergestellt.
Regionaler Ausfall: Bei einem regionalen Ausfall verarbeitet Secret Manager weiterhin Anfragen aus einer anderen Region ohne Unterbrechung, vorausgesetzt, die Daten wurden in mehrere Regionen repliziert (entweder durch automatische Replikation oder durch eine vom Nutzer verwaltete Replikation in mehr als einer Region). Wenn der regionale Ausfall behoben wurde, wird die vollständige Redundanz wiederhergestellt.
Security Command Center
Security Command Center ist die globale Echtzeit-Risikomanagementplattform für Google Cloud. Sie besteht aus zwei Hauptkomponenten: Detektoren und Ergebnissen.
Detektoren sind sowohl von regionalen als auch zonalen Ausfällen betroffen, allerdings unterschiedlich. Während eines regionalen Ausfalls können Detektoren keine neuen Ergebnisse für regionale Ressourcen generieren, da die Ressourcen, die sie scannen möchten, nicht verfügbar sind.
Während eines Zonenausfalls kann es Minuten bis hin zu Stunden dauern, bis die Detektoren den normalen Betrieb fortsetzen. Security Command Center verliert keine Ergebnisdaten. Außerdem werden keine neuen Ergebnisdaten für nicht verfügbare Ressourcen generiert. Im schlimmsten Fall haben die Container Threat Detection-Agents möglicherweise nicht mehr genügend Zwischenspeicher, während sie eine Verbindung zu einer fehlerfreien Zelle herstellen, was zum Verlust von Erkennungung führen kann.
Die Ergebnisse sind sowohl gegenüber regionalen als auch gegenüber zonalen Ausfällen ausfallsicher, da sie synchron über Regionen hinweg repliziert werden.
Sensitive Data Protection (einschließlich DLP API)
Sensitive Data Protection bietet Dienste zur Klassifizierung, Profilerstellung, De-Identifikation, Tokenisierung und Datenschutzanalyse sensibler Daten. Es arbeitet synchron mit den Daten, die in den Anfragetexten gesendet werden, oder asynchron mit den Daten, die bereits in Cloud-Speichersystemen vorhanden sind. Sensitive Data Protection kann über die globalen oder regionsspezifischen Endpunkte aufgerufen werden.
Globaler Endpunkt: Der Dienst ist so konzipiert, dass er sowohl regionalen als auch zonalen Ausfällen standhalten kann. Wenn der Dienst während eines Fehlers überlastet ist, gehen möglicherweise Daten verloren, die an die Methode hybridInspect des Dienstes gesendet werden.
Fügen Sie zum Erstellen einer fehlertoleranten Architektur eine Logik hinzu, um das neueste Ergebnis vor dem Fehler zu untersuchen, das von der Methode hybridInspect generiert wurde. Bei einem Ausfall gehen die an die Methode gesendeten Daten möglicherweise verloren. Sie dürfen jedoch nicht mehr als die letzten 10 Minuten vor dem Fehlerereignis haben. Wenn Ergebnisse aktueller als 10 Minuten vor Beginn des Ausfalls sind, werden die Daten angezeigt, die zu diesem Ergebnis geführt haben. In diesem Fall müssen Sie die Daten vor dem Ergebniszeitstempel nicht noch einmal wiedergeben, selbst wenn sie innerhalb des 10-Minuten-Intervalls liegen.
Regionaler Endpunkt: Regionale Endpunkte sind nicht anfällig für regionale Ausfälle. Wenn Ausfallsicherheit bei einem regionalen Ausfall erforderlich ist, sollten Sie ein Failover auf andere Regionen vornehmen. Die zonalen Ausfallmerkmale sind mit denen oben identisch.
Service Usage
Die Service Usage API ist ein Infrastrukturdienst von Google Cloud, mit dem Sie APIs und Dienste in Ihren Google Cloud-Projekten auflisten und verwalten können. Sie können APIs und Dienste auflisten und verwalten, die von Google, Google Cloud und Drittanbietern bereitgestellt werden. Die Service Usage API ist ein globaler Dienst, der sowohl zonalen als auch regionalen Ausfällen gegenüber resistent ist. Im Falle eines Zonenausfalls oder eines regionalen Ausfalls verarbeitet die Service Usage API weiterhin Anfragen aus einer anderen Zone in verschiedenen Regionen.
Weitere Informationen zu Service Usage finden Sie in der Dokumentation zu Service Usage.
Speech-to-Text
Mit Speech-to-Text können Sie mithilfe von Techniken für maschinelles Lernen wie neuronalen Netzwerkmodellen Audio in Text umwandeln. Audiodaten werden in Echtzeit vom Mikrofon einer Anwendung gesendet oder als Batch von Audiodateien verarbeitet.
Zonaler Ausfall:
Speech-to-Text API Version 1: Während eines Zonenausfalls verarbeitet die Speech-to-Text API Version 1 weiterhin ohne Unterbrechung Anfragen aus einer anderen Zone in derselben Region. Alle Jobs, die derzeit in der ausgefallenen Zone ausgeführt werden, gehen jedoch verloren. Nutzer müssen die fehlgeschlagenen Jobs wiederholen, die automatisch an eine verfügbare Zone weitergeleitet werden.
Speech-to-Text API Version 2: Während eines Zonenausfalls verarbeitet die Speech-to-Text API Version 2 weiterhin Anfragen von einer anderen Zone in derselben Region. Alle Jobs, die derzeit in der ausgefallenen Zone ausgeführt werden, gehen jedoch verloren. Nutzer müssen die fehlgeschlagenen Jobs wiederholen, die automatisch an eine verfügbare Zone weitergeleitet werden. Die Speech-to-Text API gibt den API-Aufruf erst zurück, wenn die Daten an ein Quorum innerhalb einer Region übergeben wurden. In einigen Regionen sind KI-Beschleuniger (TPUs) nur in einer Zone verfügbar. In diesem Fall führt ein Ausfall in dieser Zone dazu, dass die Spracherkennung fehlschlägt, aber es kommt zu keinem Datenverlust.
Regionaler Ausfall:
Speech-to-Text API Version 1: Die Speech-to-Text API Version 1 ist vom regionalen Ausfall nicht betroffen, da es sich um einen globalen multiregionalen Dienst handelt. Der Dienst verarbeitet weiterhin Anfragen aus einer anderen Region ohne Unterbrechung. Jobs, die derzeit in der ausgefallenen Region ausgeführt werden, gehen jedoch verloren. Nutzer müssen diese fehlgeschlagenen Jobs wiederholen, die automatisch in eine verfügbare Region weitergeleitet werden.
Speech-to-Text API Version 2:
Mit der multiregionalen Speech-to-Text API Version 2 verarbeitet der Dienst weiterhin Anfragen aus einer anderen Zone in derselben Region ohne Unterbrechung.
Speech-to-Text API Version 2 in einer einzigen Region – der Dienst weist die Jobausführung auf die angeforderte Region zu. Die Speech-to-Text API Version 2 leitet keinen Traffic an eine andere Region weiter und Daten werden nicht in eine andere Region repliziert. Während eines regionalen Ausfalls ist die Speech-to-Text API Version 2 in dieser Region nicht verfügbar. Sie wird jedoch wieder verfügbar, wenn der Ausfall behoben ist.
Storage Transfer Service
Storage Transfer Service verwaltet Datenübertragungen aus verschiedenen Cloud-Quellen zu Cloud Storage sowie von, zu und zwischen Dateisystemen.
Die Storage Transfer Service API ist eine globale Ressource.
Storage Transfer Service hängt von der Verfügbarkeit der Quelle und des Ziels einer Übertragung ab. Wenn eine Übertragungsquelle oder ein Ziel nicht verfügbar ist, werden die Übertragungen unterbrochen. Dabei gehen jedoch keine wichtigen Kundendaten oder Jobdaten verloren. Die Übertragungen werden fortgesetzt, wenn die Quelle und das Ziel wieder verfügbar sind.
Sie können Storage Transfer Service mit oder ohne Agent verwenden:
Übertragungen ohne Agent verwenden regionale Worker, um Übertragungsjobs zu orchestrieren.
Übertragungen mit Agent verwenden Software-Agents, die in Ihrer Infrastruktur installiert sind. Übertragungen mit Agent hängen von der Verfügbarkeit der Übertragungs-Agents und der Fähigkeit der Agents ab, eine Verbindung zum Dateisystem herzustellen. Berücksichtigen Sie bei der Entscheidung, wo Übertragungs-Agents installiert werden sollen, die Verfügbarkeit des Dateisystems. Wenn Sie beispielsweise Übertragungs-Agents auf mehreren Compute Engine-VMs ausführen, um Daten an eine Filestore-Instanz der Enterprise-Stufe (eine regionale Ressource) zu übertragen, sollten sich die VMs in verschiedenen Zonen innerhalb der Region der Filestore-Instanz befinden.
Wenn Agents nicht mehr verfügbar sind oder die Verbindung zum Dateisystem unterbrochen wird, werden die Übertragungen nicht fortgesetzt. Dabei gehen jedoch keine Daten verloren. Nach Beendigung aller Agent-Prozesse wird der Übertragungsjob angehalten, bis dem Agent-Pool der Übertragung neue Agents hinzugefügt werden.
Während eines Ausfalls verhält sich Storage Transfer Service so:
Zonaler Ausfall: Während eines zonalen Ausfalls bleiben die Storage Transfer Service APIs verfügbar und Sie können mit dem Erstellen von Übertragungsjobs fortfahren. Die Übertragung der Daten wird fortgesetzt.
Regionaler Ausfall: Während eines regionalen Ausfalls bleiben die Storage Transfer Service APIs verfügbar und Sie können mit dem Erstellen von Übertragungsjobs fortfahren. Wenn sich die Worker Ihrer Übertragung in der betroffenen Region befinden, wird die Datenübertragung so lange unterbrochen, bis die Region wieder verfügbar ist. Daraufhin wird die Übertragung automatisch fortgesetzt.
Vertex ML Metadata
Mit Vertex ML Metadata können Sie die von Ihrem ML-System erzeugten Metadaten und Artefakte aufzeichnen. Außerdem können Sie damit Metadaten abfragen, um die Leistung Ihres ML-Systems oder der Artefakte zu analysieren, zu debuggen und zu prüfen.
Zonaler Ausfall: In der Standardkonfiguration bietet Vertex ML Metadata Schutz vor Zonenausfällen. Der Dienst wird in mehreren Zonen jeder Region bereitgestellt, wobei Daten synchron über verschiedene Zonen innerhalb der Region repliziert werden. Bei einem Zonenausfall übernehmen die verbleibenden Zonen mit minimaler Unterbrechung.
Regionaler Ausfall: Vertex ML Metadata ist ein regionaler Dienst. Bei einem regionalen Ausfall erfolgt für Vertex ML Metadata kein Failover auf eine andere Region.
Vertex AI-Batchvorhersagen
Mit der Batchvorhersage können Nutzer Batchvorhersagen für KI/ML-Modelle in der Google-Infrastruktur ausführen. Batchvorhersagen sind ein regionales Angebot. Kunden können die Region auswählen, in der sie Jobs ausführen, jedoch nicht die spezifischen Zonen innerhalb dieser Region. Der Batchvorhersagedienst verteilt den Job automatisch auf verschiedene Zonen innerhalb der ausgewählten Region.
Zonaler Ausfall: Die Batchvorhersage speichert Metadaten für Batchvorhersagejobs innerhalb einer Region. Die Daten werden synchron über mehrere Zonen innerhalb dieser Region geschrieben. Bei einem Zonenausfall verliert die Batchvorhersage teilweise Worker, die Jobs ausführen, fügt sie jedoch automatisch anderen verfügbaren Zonen hinzu. Wenn mehrere Wiederholungsversuche für die Batchvorhersage fehlschlagen, wird der Jobstatus in der UI und in den API-Aufrufanfragen als fehlgeschlagen angezeigt. Nachfolgende Nutzeranfragen zum Ausführen des Jobs werden an verfügbare Zonen weitergeleitet.
Regionaler Ausfall: Kunden wählen die Google Cloud-Region aus, in der sie ihre Batchvorhersagejobs ausführen möchten. Daten werden nie über Regionen hinweg repliziert. Die Batchvorhersage beschränkt die Jobausführung auf die angeforderte Region und leitet Vorhersageanfragen nie an eine andere Region weiter. Wenn ein regionaler Ausfall auftritt, ist in dieser Region keine Batchvorhersage verfügbar. Sie wird wieder verfügbar, wenn der Ausfall behoben ist. Wir empfehlen Kunden, mehrere Regionen zum Ausführen ihrer Jobs zu verwenden. Bei einem regionalen Ausfall können Sie Jobs an eine andere verfügbare Region weiterleiten.
Vertex AI Model Registry
Mit Vertex AI Model Registry können Nutzer die Modellverwaltung, Governance und die Bereitstellung von ML-Modellen in einem zentralen Repository optimieren. Vertex AI Model Registry ist ein regionales Angebot mit Hochverfügbarkeit und bietet Schutz vor zonalen Ausfällen.
Zonaler Ausfall: Vertex AI Model Registry bietet Schutz vor zonalen Ausfällen. Der Dienst wird in drei Zonen jeder Region bereitgestellt, wobei Daten synchron über verschiedene Zonen innerhalb der Region repliziert werden. Wenn eine Zone ausfällt, übernehmen die verbleibenden Zonen ohne Datenverlust und minimale Dienstunterbrechung.
Regionaler Ausfall: Vertex AI Model Registry ist ein regionaler Dienst. Wenn eine Region ausfällt, führt Model Registry kein Failover aus.
Vertex AI-Onlinevorhersagen
Mit Onlinevorhersagen können Nutzer KI/ML-Modelle in Google Cloud bereitstellen. Onlinevorhersagen sind ein regionales Angebot. Kunden können die Region auswählen, in der sie ihre Modelle bereitstellen, jedoch nicht die spezifischen Zonen innerhalb dieser Region. Der Vorhersagedienst verteilt die Arbeitslast automatisch auf verschiedene Zonen innerhalb der ausgewählten Region.
Zonaler Ausfall: Die Onlinevorhersage speichert keine Kundeninhalte. Ein zonaler Ausfall führt zu einem Fehler bei der aktuellen Ausführung einer Vorhersageanfrage. Onlinevorhersagen können die Vorhersageanfrage automatisch wiederholen, je nachdem, welcher Endpunkttyp verwendet wird. Bei einem öffentlichen Endpunkt wird dies automatisch versucht, bei privaten Endpunkten nicht. Binden Sie eine Wiederholungslogik mit exponentiellem Backoff in Ihren Code ein, um Fehler zu beheben und die Ausfallsicherheit zu verbessern.
Regionaler Ausfall: Kunden wählen die Google Cloud-Region aus, in der sie ihre KI/ML-Modelle und Onlinevorhersagedienste ausführen möchten. Daten werden nie über Regionen hinweg repliziert. Bei Onlinevorhersagen wird die KI/ML-Modellausführung auf die angeforderte Region beschränkt und die Vorhersageanfragen werden niemals an eine andere Region weitergeleitet. Wenn ein regionaler Ausfall auftritt, ist der Onlinevorhersagedienst in dieser Region nicht verfügbar. Er wird wieder verfügbar, wenn der Ausfall behoben ist. Wir empfehlen Kunden, mehrere Regionen zum Ausführen ihrer KI/ML-Modelle zu verwenden. Leiten Sie bei einem regionalen Ausfall den Traffic an eine andere, verfügbare Region weiter.
Vertex AI Pipelines
Vertex AI Pipelines ist ein Vertex AI-Dienst, mit dem Sie Ihre ML-Workflows serverlos automatisieren, überwachen und steuern können. Vertex AI Pipelines bietet Hochverfügbarkeit und Schutz vor zonalen Fehlern.
Zonaler Ausfall: In der Standardkonfiguration bietet Vertex AI Pipelines Schutz vor Zonenausfällen. Der Dienst wird in mehrere Zonen jeder Region bereitgestellt, wobei Daten synchron über verschiedene Zonen innerhalb der Region repliziert werden. Bei einem Zonenausfall übernehmen die verbleibenden Zonen mit minimaler Unterbrechung.
Regionaler Ausfall: Vertex AI Pipelines ist ein regionaler Dienst. Bei einem regionalen Ausfall erfolgt für Vertex AI Pipelines kein Failover auf eine andere Region. Wenn ein regionaler Ausfall auftritt, empfehlen wir Ihnen, Ihre Pipelinejobs in einer Sicherungsregion auszuführen.
Vertex AI Search
Vertex AI Search ist eine anpassbare Suchlösung mit generativen KI-Funktionen und nativer Unternehmenscompliance. Vertex AI Search wird automatisch in mehreren Regionen innerhalb von Google Cloud bereitgestellt und repliziert. Sie können konfigurieren, wo Daten gespeichert werden, indem Sie eine unterstützte Mehrfachregion auswählen, z. B. global, USA oder EU.
Zonaler und regionaler Ausfall: UserEvents, in Vertex AI Search hochgeladen, kann aufgrund einer asynchronen Replikationsverzögerung möglicherweise nicht wiederhergestellt werden. Andere von Vertex AI Search bereitgestellte Daten und Dienste bleiben aufgrund des automatischen Failovers und der synchronen Datenreplikation verfügbar.
Vertex AI Training
Vertex AI Training bietet Nutzern die Möglichkeit, benutzerdefinierte Trainingsjobs in der Infrastruktur von Google auszuführen. Vertex AI Training ist ein regionales Angebot, d. h., Kunden können die Region auswählen, in der ihre Trainingsjobs ausgeführt werden. Kunden können jedoch nicht die spezifischen Zonen innerhalb dieser Region auswählen. Der Trainingsdienst verteilt die Jobausführung automatisch auf verschiedene Zonen innerhalb der Region.
Zonaler Ausfall: Vertex AI Training speichert Metadaten für den benutzerdefinierten Trainingsjob. Diese Daten werden regional gespeichert und synchron geschrieben. Der Aufruf der Vertex AI Training API wird erst zurückgegeben, wenn diese Metadaten einem Quorum innerhalb einer Region zugewiesen wurden. Der Trainingsjob kann in einer bestimmten Zone ausgeführt werden. Ein zonaler Ausfall führt zu einem Fehler der aktuellen Jobausführung. In diesem Fall wiederholt der Dienst den Job automatisch, indem er an eine andere Zone weitergeleitet wird. Wenn mehrere Wiederholungsversuche fehlschlagen, wird der Jobstatus in „Fehlgeschlagen“ aktualisiert. Nachfolgende Nutzeranfragen zum Ausführen des Jobs werden an eine verfügbare Zone weitergeleitet.
Regionaler Ausfall: Kunden wählen die Google Cloud-Region aus, in der sie ihre Trainingsjobs ausführen möchten. Daten werden nie über Regionen hinweg repliziert. Vertex AI Training beschränkt die Jobausführung auf die angeforderte Region und leitet die Trainingsjobs nie in eine andere Region weiter. Bei einem regionalen Ausfall ist der Vertex AI Training-Dienst in dieser Region nicht verfügbar und wieder verfügbar, wenn der Ausfall behoben ist. Wir empfehlen Kunden, ihre Jobs in mehreren Regionen auszuführen. Bei einem regionalen Ausfall können sie Jobs an eine andere verfügbare Region weiterleiten.
Virtual Private Cloud (VPC)
VPC ist ein globaler Dienst, der eine Netzwerkverbindung zu Ressourcen herstellt (z. B. VMs). Ausfälle sind jedoch zonal. Bei einem Zonenausfall sind die Ressourcen in dieser Zone nicht verfügbar. Wenn eine Region ausfällt, ist nur der Traffic zur und aus der ausgefallenen Region betroffen. Die Verbindung fehlerfreier Regionen ist nicht betroffen.
Zonaler Ausfall: Wenn ein VPC-Netzwerk mehrere Zonen abdeckt und eine Zone ausfällt, ist das VPC-Netzwerk für fehlerfreie Zonen weiterhin fehlerfrei. Der Netzwerk-Traffic zwischen Ressourcen in fehlerfreien Zonen funktioniert während des Ausfalls weiterhin normal. Ein Zonenausfall betrifft nur den Netzwerk-Traffic zu und von Ressourcen in der ausgefallenen Zone. Wir empfehlen Ihnen, nicht alle Ressourcen in einer einzigen Zone zu erstellen, um die Auswirkungen von zonalen Ausfällen zu minimieren. Wenn Sie Ressourcen erstellen, verteilen Sie sie stattdessen auf Zonen.
Regionaler Ausfall: Wenn ein VPC-Netzwerk mehrere Regionen abdeckt und eine Region ausfällt, ist das VPC-Netzwerk für fehlerfreie Regionen weiterhin fehlerfrei. Der Netzwerk-Traffic zwischen Ressourcen in fehlerfreien Regionen funktioniert während des Ausfalls weiterhin normal. Ein regionaler Ausfall wirkt sich nur auf den Netzwerk-Traffic zu und von Ressourcen in der ausgefallenen Region aus. Um die Auswirkungen regionaler Ausfälle zu minimieren, empfehlen wir, Ressourcen auf mehrere Regionen zu verteilen.
VPC Service Controls
VPC Service Controls ist ein regionaler Dienst. Mit VPC Service Controls können Sicherheitsteams in Unternehmen detailliertere Bereichskontrollen definieren und diesen Sicherheitsstatus für zahlreiche Google Cloud-Dienste und -Projekte durchsetzen. Kundenrichtlinien werden regional gespiegelt.
Zonaler Ausfall: VPC Service Controls verarbeitet weiterhin Anfragen aus einer anderen Zone in derselben Region ohne Unterbrechung.
Regionaler Ausfall: APIs, die für die Durchsetzung von VPC Service Controls-Richtlinien in der betroffenen Region konfiguriert sind, sind erst wieder verfügbar, wenn die Region wieder verfügbar ist. Kunden wird empfohlen, von VPC Service Controls erzwungene Dienste in mehreren Regionen bereitzustellen, wenn eine höhere Verfügbarkeit erwünscht ist.
Workflows
Workflows ist ein Orchestrierungsprodukt, mit dem Google Cloud-Kunden:
- Workflows bereitstellen und ausführen können, die andere vorhandene Dienste über HTTP verbinden,
- Prozesse automatisieren und bis zu einem Jahr auf HTTP-Antworten mit automatischen Wiederholungsversuchen warten können und
- Echtzeit-Prozesse mit ereignisgesteuerten Ausführungen mit niedriger Latenz implementieren können.
Workflows-Kunden können Workflows bereitstellen, die die Geschäftslogik beschreiben, die sie ausführen möchten. Anschließend können Sie die Workflows entweder direkt mit der API oder mit ereignisgesteuerten Triggern ausführen (derzeit auf Pub/Sub oder Eventarc beschränkt). Der ausgeführte Workflow kann Variablen bearbeiten, HTTP-Aufrufe ausführen und die Ergebnisse speichern oder Callbacks definieren und warten, bis sie von einem anderen Dienst fortgesetzt werden.
Zonaler Ausfall: Der Quellcode von Workflows ist nicht von zonalen Ausfällen betroffen. In Workflows wird der Quellcode von Workflows zusammen mit den Variablenwerten und HTTP-Antworten gespeichert, die von ausgeführten Workflows empfangen werden. Quellcode wird regional gespeichert und synchron geschrieben: Die API der Steuerungsebene wird erst zurückgegeben, wenn diese Metadaten einem Quorum innerhalb einer Region zugewiesen wurden. Variablen und HTTP-Ergebnisse werden auch regional gespeichert und mindestens alle fünf Sekunden synchron geschrieben.
Wenn eine Zone ausfällt, werden die Workflows automatisch auf der Grundlage der letzten gespeicherten Daten fortgesetzt. HTTP-Anfragen, die noch keine Antworten erhalten haben, werden jedoch nicht automatisch wiederholt. Verwenden Sie Wiederholungsrichtlinien für Anfragen, die sicher wiederholt werden können, wie in unserer Dokumentation beschrieben.
Regionaler Ausfall: Workflows sind ein regionaler Dienst. Bei einem regionalen Ausfall erfolgt für Workflows kein Failover. Kunden wird empfohlen, Workflows in mehreren Regionen bereitzustellen, wenn eine höhere Verfügbarkeit gewünscht ist.
Cloud Service Mesh
Mit Cloud Service Mesh können Sie ein verwaltetes Service Mesh konfigurieren, das sich über mehrere GKE-Cluster erstreckt. Diese Dokumentation betrifft nur das verwaltete Cloud Service Mesh, die clusterinterne Variante ist selbstgehostet und reguläre Plattformrichtlinien sollten befolgt werden.
Zonaler Ausfall: Die Mesh-Konfiguration, wie sie im GKE-Cluster gespeichert ist, ist gegenüber zonalen Ausfällen stabil, solange der Cluster regional ist. Daten, die das Produkt für die interne Buchhaltung verwendet, werden entweder regional oder global gespeichert und sind nicht betroffen, wenn eine einzelne Zone außer Betrieb ist. Die Steuerungsebene wird in derselben Region wie der unterstützte GKE-Cluster ausgeführt (bei zonalen Clustern ist sie die enthaltende Region) und ist nicht von Ausfällen innerhalb einer einzelnen Zone betroffen.
Regionaler Ausfall: Cloud Service Mesh bietet Dienste für GKE-Cluster, die entweder regional oder zonal sind. Bei einem regionalen Ausfall erfolgt für Cloud Service Mesh kein Failover. Das selbe gilt für GKE. Kunden wird empfohlen, Mesh-Netzwerke bereitzustellen, die aus GKE-Clustern in verschiedenen Regionen bestehen.
Service Directory
Service Directory ist eine Plattform zum Erkennen, Veröffentlichen und Verbinden von Diensten. Sie erhalten an einem zentralen Ort Echtzeitinformationen zu allen Ihren Diensten. Mit Service Directory können Sie eine umfangreiche Dienstinventarverwaltung durchführen, unabhängig davon, ob Sie einige wenige oder Tausende von Dienstendpunkten haben.
Service Directory-Ressourcen werden regional erstellt und entsprechen dem vom Nutzer angegebenen Standortparameter.
Zonenausfall: Während eines Zonenausfalls verarbeitet Service Directory weiterhin Anfragen aus einer anderen Zone in derselben oder einer anderen Region ohne Unterbrechung. In jeder Region verwaltet Service Directory immer mehrere Replikate. Sobald der zonale Ausfall behoben wurde, wird die vollständige Redundanz wiederhergestellt.
Regionaler Ausfall: Service Directory ist anfällig für regionale Ausfälle.