Auf dieser Seite wird beschrieben, wie Sie AlloyDB-Instanzen mit den folgenden Methoden überwachen können:
- Instanz mit dem AlloyDB-Systemstatistik-Dashboard überwachen
- Instanz mit dem Cloud Monitoring-Dashboard beobachten
- Messwerte auf der Übersichtsseite des AlloyDB-Clusters ansehen
Sie können Gemini Cloud Assist verwenden, um Ihre AlloyDB-Ressourcen zu überwachen und Fehler zu beheben. Weitere Informationen finden Sie unter Mit Gemini überwachen und Fehler beheben.
Hinweise
Damit Sie auf das Systemstatistik-Dashboard zugreifen können, müssen Sie den Zugriff auf AlloyDB for PostgreSQL in Ihrem Google Cloud -Projekt aktivieren.
Erforderliche Rollen
Wenn Sie AlloyDB-Systemstatistiken verwenden möchten, benötigen Sie Berechtigungen für Folgendes:
- Für den Zugriff auf System-Insights benötigen Sie Berechtigungen für das AlloyDB System-Insights-Dashboard.
- Zum Bearbeiten von System-Insights benötigen Sie Berechtigungen zum Aktualisieren von AlloyDB-Instanzen.
Bitten Sie Ihren Administrator, Ihnen eine der folgenden Rollen zuzuweisen, um diese Berechtigungen zu erhalten:
- Einfache Oberfläche (
roles/viewer) - Database Insights Viewer (
roles/databaseinsights.eventsViewer)
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff verwalten.
Instanz mit dem AlloyDB-Systemstatistik-Dashboard überwachen
Im AlloyDB-Dashboard „Systemstatistik“ werden Messwerte der von Ihnen verwendeten Ressourcen angezeigt. Sie können diese Ressourcen und Messwerte überwachen.
Zusätzlich zum vordefinierten Dashboard, das von Systemstatistiken generiert wird, können Sie ein benutzerdefiniertes Dashboard mit den folgenden Anpassungen erstellen:
- AlloyDB-Messwerte hinzufügen oder entfernen
- Messwerte aus anderen Google Cloud -Produkten wie GKE Enterprise einbinden, um einen ganzheitlicheren Überblick über Ihr System zu erhalten
- Dashboard-Layout neu anordnen
So rufen Sie das AlloyDB-Systemstatistik-Dashboard auf:
Öffnen Sie in der Google Cloud Console die Seite AlloyDB.
Klicken Sie auf den Namen eines Clusters, um die entsprechende Übersicht zu öffnen.
Wählen Sie den Tab Systemstatistiken aus.
Das AlloyDB-Systemstatistik-Dashboard wird geöffnet. Oben werden Details zum Cluster angezeigt, gefolgt von Diagrammen für die wichtigsten Messwerte.
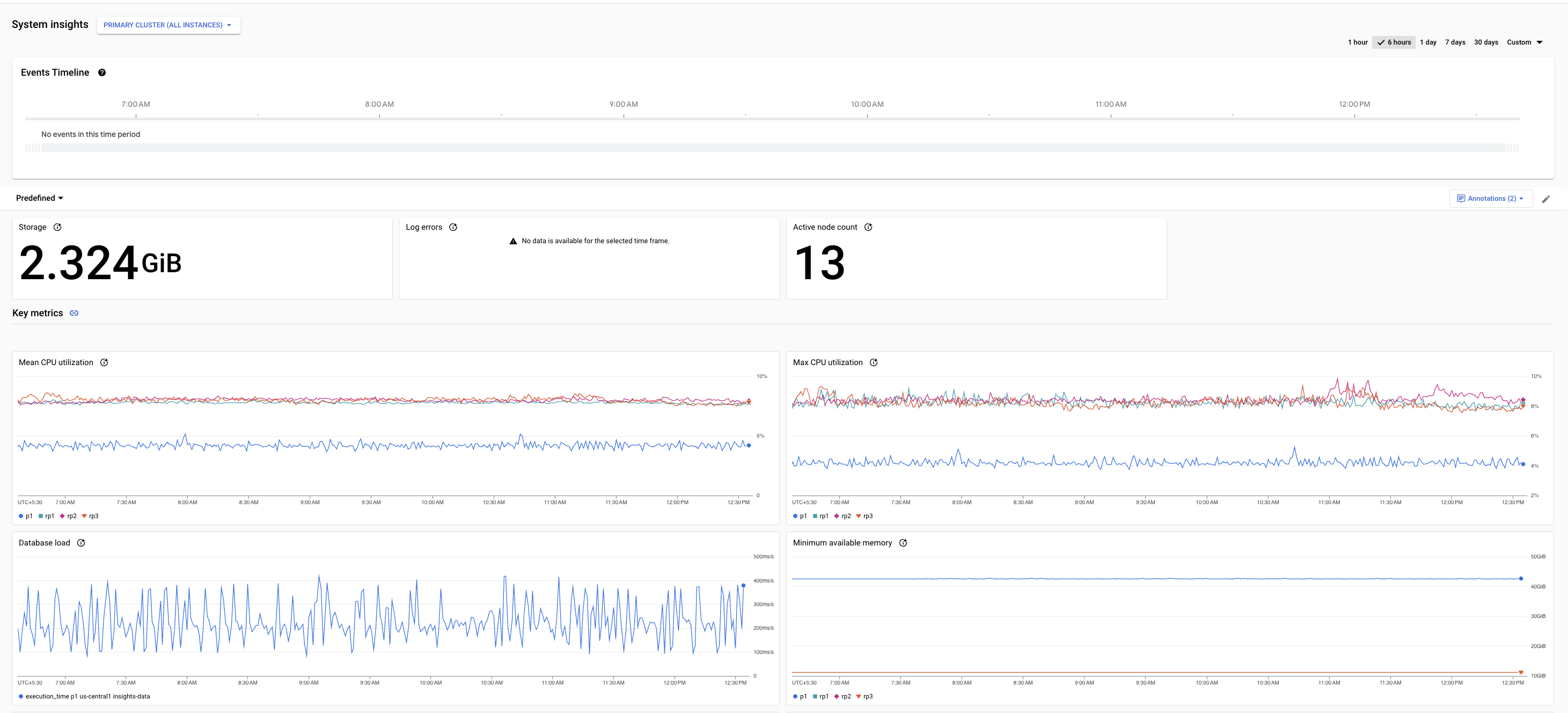
Vordefinierte und benutzerdefinierte Dashboards enthalten die folgenden Funktionen:
Standardmäßig ist die Ansicht Cluster (alle Instanzen) ausgewählt. Sie können Messwerte für die primäre Instanz oder für Lesepoolinstanzen aufrufen.
In der Zeitauswahl ist standardmäßig
1 dayausgewählt. Wählen Sie einen der anderen vordefinierten Zeiträume aus oder klicken Sie auf Benutzerdefiniert und definieren Sie eine Start- und Endzeit, um den Zeitraum zu ändern. Es stehen die Daten der letzten 30 Tage zur Verfügung.
Jedes Dashboard enthält die folgenden Abschnitte:
Die Zusammenfassungskarten zeigen die neuesten oder aggregierten Werte für einige Messwerte an und bieten eine Übersicht über den Datenbankstatus und die Leistung im ausgewählten Zeitraum.
Die Messwertdiagramme enthalten Informationen zu wichtigen Messwerten, mit denen Sie Einblicke in die Ressourcennutzung wie CPU, Arbeitsspeicher, Verbindungen, Replikation und Speicher erhalten und proaktiv reagieren können, wenn sich die Anforderungen Ihrer Anwendung ändern.
Die Systemereignisse enthalten Informationen, mit denen Sie die Auswirkungen von Systemereignissen auf den Zustand und die Leistung der Instanz bewerten können.
Zusammenfassungskarten
In der folgenden Tabelle werden die Zusammenfassungskarten beschrieben, die im AlloyDB-Dashboard „Systemstatistik“ angezeigt werden. Diese Karten bieten einen Überblick über den Datenbankstatus und die Leistung im ausgewählten Zeitraum.
| Zusammenfassungskarten | Beschreibung | Verfügbarkeit von Dashboards |
|---|---|---|
| Speicherplatz | Der vom AlloyDB-Cluster im ausgewählten Zeitraum verwendete Gesamtspeicherplatz. | Cluster-Dashboard |
| Anzahl aktiver Knoten | Die aktuelle Anzahl der aktiven Knoten, die Nutzer-Traffic im Cluster im ausgewählten Zeitraum bereitstellen können. |
|
| CPU-Auslastung | Die Werte für das 99. und 50. Perzentil der CPU-Auslastung im ausgewählten Zeitraum. |
|
| Höchste Anzahl von Verbindungen | Das Verhältnis der höchsten Anzahl von Verbindungen zur maximalen Anzahl von Verbindungen auf allen Bereitstellungsknoten der Instanz im ausgewählten Zeitraum. Dies schließt sowohl aktive als auch inaktive Verbindungen ein. |
|
| Fehler protokollieren | Die Gesamtzahl der Fehlerprotokolle, die im ausgewählten Zeitraum generiert wurden. |
|
| Transaktions-ID-Nutzung | Der aktuelle Wert der Transaktions-ID-Nutzung im ausgewählten Zeitraum. |
|
| Verzögerung der Replikation | Der durchschnittliche Wert der maximalen Replikationsverzögerung im ausgewählten Zeitraum. |
|
Messwertdiagramme
Das Systemstatistik-Dashboard enthält Messwerte auf den folgenden Ebenen:
- Primärer Cluster (alle Instanzen)
- Primäre Instanz
- Einzelne Lesepoolinstanzen
Wenn Sie die Messwerte für eine bestimmte Ebene aufrufen möchten, klicken Sie auf das Drop-down-Menü Primärer Cluster (Alle Instanzen) und wählen Sie das entsprechende Dashboard aus.
Weitere Informationen zu den Messwerten für die einzelnen Ebenen finden Sie in der Referenz zu Messwerten für Systemstatistiken.
Eine Diagrammkarte für einen Beispielmesswert wird so angezeigt.
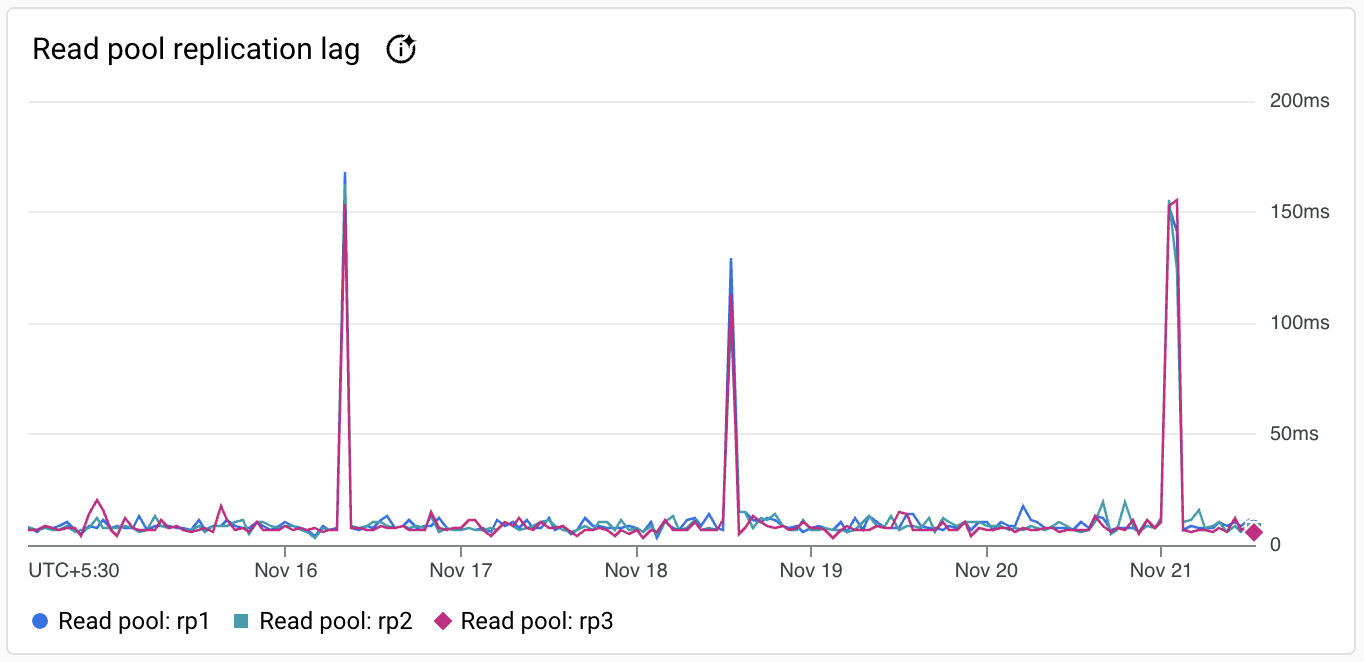
Die Symbolleiste jeder Diagrammkarte enthält folgende Standardoptionen:
Wenn Sie die Legende ein- oder ausblenden möchten, klicken Sie auf Weitere Diagrammoptionen und dann auf Diagrammlegende maximieren.
Bewegen Sie den Mauszeiger über das Diagramm, um sich Messwerte für einen bestimmten Zeitpunkt im ausgewählten Zeitraum anzusehen.
Wenn Sie ein Diagramm im Vollbildmodus ansehen möchten, klicken Sie auf Weitere Diagrammoptionen und dann auf Im Vollbildmodus ansehen.
Wenn Sie ein Diagramm vergrößern möchten, klicken Sie auf Daten auswerten.
Klicken Sie auf more_vert, um weitere Optionen aufzurufen. Die meisten Diagramme bieten diese Optionen:
- PNG-Bild herunterladen.
- CSV-Datei herunterladen
- In Metrics Explorer ansehen. Sehen Sie sich den Messwert im Metrics Explorer an. Sie können sich weitere AlloyDB-Messwerte im Metrics Explorer ansehen, indem Sie den Ressourcentyp AlloyDB-Instanz auswählen.
Ereigniszeitachse
Das Dashboard enthält Details zu den folgenden Ereignissen. Systemereignisse werden innerhalb von etwa 5 Minuten nach dem Eintreten des Ereignisses in der Ereigniszeitachse angezeigt.
| Ereignisname | Beschreibung | Vorgangstyp |
|---|---|---|
Instance create |
Erstellt eine AlloyDB-Instanz. | INSTANCE_CREATE |
Instance update |
Aktualisiert eine AlloyDB-Instanz. | INSTANCE_UPDATE |
Instance restart |
Startet die AlloyDB-Instanz neu. | INSTANCE_RESTART |
Instance failover |
Initiiert einen manuellen Failover einer hochverfügbaren primären Instanz, damit eine Standby-Instanz zur primären Instanz wird. | INSTANCE_FAILOVER |
Cluster maintenance |
Gibt an, dass sich der Cluster in der Wartung befindet und die Instanzen einige Minuten lang nicht verfügbar sind. | MAINTENANCE |
Backup create |
Erstellt eine Sicherung einer AlloyDB-Instanz. | BACKUP_CREATE |
Backup update |
Aktualisiert eine Sicherung einer AlloyDB-Instanz. | BACKUP_UPDATE |
Cluster create |
Erstellt einen AlloyDB-Cluster. | CLUSTER_CREATE |
Cluster update |
AlloyDB-Cluster aktualisieren | CLUSTER_UPDATE |
Cluster promote |
Stuft einen sekundären Cluster zum primären Cluster hoch. | CLUSTER_PROMOTE |
User create |
Erstellt einen neuen Nutzer. | USER_CREATE |
User update |
Nutzer aktualisieren | USER_UPDATE |
User delete |
Löscht einen Nutzer. | USER_DELETE |
Benutzerdefiniertes Dashboard erstellen
Das vordefinierte Dashboard enthält eine Reihe von Standardmesswerten. Sie können zusätzliche Widgets erstellen, um andere Messwerte für AlloyDB oder andere Google Cloud -Produkte hinzuzufügen und eine einheitliche Monitoring-Ansicht in AlloyDB zu erhalten. Wenn Sie beispielsweise AlloyDB mit der Google Kubernetes Engine (GKE) Enterprise-Version (GKE Enterprise) verwenden, können Sie das vordefinierte Dashboard anpassen und neben AlloyDB-Messwerten auch erforderliche GKE Enterprise-Messwerte wie Pod- oder Knotenmesswerte hinzufügen.
Zusätzlich zum vordefinierten Dashboard können Sie ein benutzerdefiniertes Dashboard erstellen.
So erstellen Sie ein benutzerdefiniertes Dashboard:
Öffnen Sie in der Google Cloud Console die Seite AlloyDB.
Klicken Sie auf den Namen eines Clusters, um die entsprechende Übersicht zu öffnen.
Wählen Sie den Tab Systemstatistiken aus.
Klicken Sie auf Vordefiniert und dann auf Dashboard anpassen.
So fügen Sie dem Dashboard einen Messwert hinzu:
- Geben Sie unter Name der benutzerdefinierten Ansicht einen Namen für das Dashboard ein, z. B.
my-custom-dashboard. Klicken Sie auf Widget hinzufügen und wählen Sie einen Widget-Typ aus, um dem Dashboard einen Messwert hinzuzufügen.
Ein Konfigurationsbereich wird geöffnet. Sie können beispielsweise das Widget Messwert als Datenquelle auswählen und dann die Visualisierung auf Balkendiagramm gestapelt festlegen. Alternativ können Sie das Widget Balkendiagramm gestapelt auswählen und dann den Messwert.
Konfigurieren Sie das Widget.
Klicken Sie in der Symbolleiste auf Anwenden, um das angepasste Dashboard zu speichern.
- Geben Sie unter Name der benutzerdefinierten Ansicht einen Namen für das Dashboard ein, z. B.
Benutzerdefiniertes Dashboard bearbeiten
- Bewegen Sie den Mauszeiger auf das Dashboard und klicken Sie auf Bearbeiten, um den Bearbeitungsmodus aufzurufen.
- Wenn Sie ein Widget neu positionieren möchten, klicken Sie auf die Widget-Überschrift und ziehen Sie das Widget an eine neue Position.
- Wenn Sie ein Widget bearbeiten möchten, platzieren Sie den Mauszeiger auf dem Dashboard und klicken Sie auf Bearbeiten. Klicken Sie in der Symbolleiste auf Übernehmen, um die Änderungen auf das Dashboard anzuwenden. Wenn Sie die Änderungen verwerfen möchten, klicken Sie auf Abbrechen.
- Wenn Sie ein Widget löschen möchten, bewegen Sie den Mauszeiger darauf, klicken Sie auf das Dreipunkt-Menü Weitere Diagrammoptionen und dann auf Widget löschen. Klicken Sie in der Symbolleiste auf Übernehmen, um die Änderungen auf das Dashboard anzuwenden. Wenn Sie die Änderungen verwerfen möchten, klicken Sie auf Abbrechen.
- Klicken Sie in der Symbolleiste auf Speichern, um das geänderte Dashboard zu speichern.
In der Liste der Dashboards wird my-custom-dashboard angezeigt. Wenn Sie ein Dashboard löschen möchten, bewegen Sie den Mauszeiger auf das Widget und klicken Sie dann auf Löschen.
Instanz mit dem Cloud Monitoring-Dashboard überwachen
Cloud Monitoring bietet vordefinierte Dashboards für mehrere Google Cloud -Produkte. Sie können auch eigene benutzerdefinierte Dashboards erstellen, um für Sie interessante Daten anzuzeigen und den Allgemeinzustand Ihrer primären Instanzen und Lesepoolinstanzen zu überwachen.
Warnungen einrichten
Sie können Cloud Monitoring verwenden, um Benachrichtigungen für ein Projekt oder eine bestimmte Instanz einzurichten.
Beispielsweise können Sie eine Benachrichtigung für eine Nachricht einrichten, die an bestimmte E-Mail-IDs gesendet wird, wenn der Messwert Arbeitsspeichernutzung für eine AlloyDB-Instanz den Grenzwert von 80 % überschreitet.
Clustermesswerte auf der Übersichtsseite des AlloyDB-Clusters ansehen
Auf der Übersichtsseite des Clusters werden die clusterbezogenen Messwerte oben auf der Seite angezeigt.
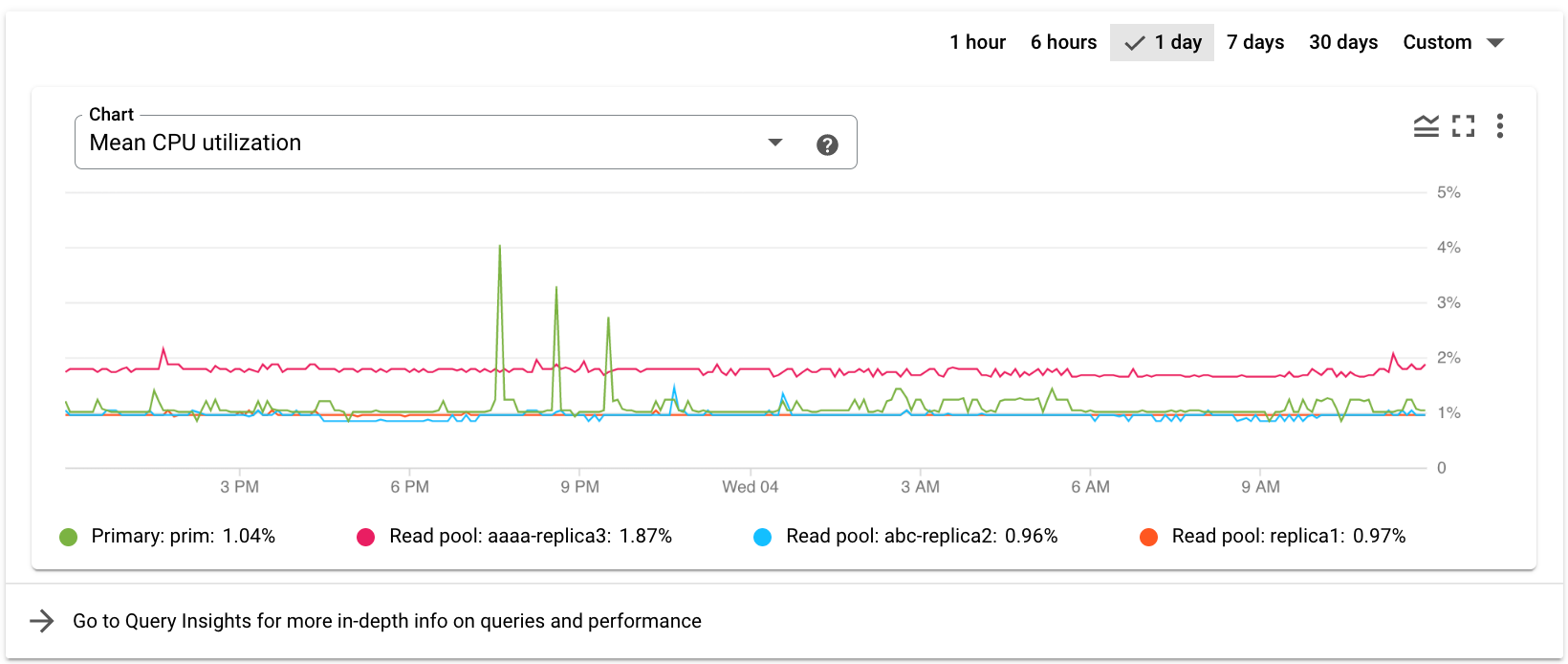
Wählen Sie einen anderen Messwert aus der Drop-down-Liste Diagramm aus. Das Diagramm zeigt die Daten für den ausgewählten Messwert.
Nächste Schritte
- Liste der AlloyDB-Messwerte aufrufen.
- Referenz zu Systemstatistiken
- Abfragestatistiken verwenden, um die Abfrageleistung zu verbessern
- Weitere Informationen zu Cloud Logging und Cloud Monitoring.
- Aktive Abfragen überwachen, um Ursachen für Systemlatenz und hohe CPU-Auslastung zu ermitteln.