在传统的企业应用中,来自客户端的请求是在数据库事务中执行。通常,完成请求所需的所有数据都存储在具有 ACID 属性的单个数据库中(其中,ACID 一词代表原子性、一致性、隔离性和耐用性)。因此,您可以使用关系型数据库系统的事务功能来保证一致性。如果执行事务期间出现问题,数据库系统可以自动回滚并重试事务。本文档介绍如何使用 Cloud Run、Pub/Sub、Workflows 和 Datastore 模式的 Firestore (Datastore) 来设计事务工作流。本文档面向想要在基于微服务的应用中设计事务工作流的应用开发者。
本文档是系列文章中的一篇,该系列文章包括以下部分:
- Google Cloud 上的微服务架构中的事务工作流(本文档)。
- 在微服务架构中部署示例事务工作流应用:本教程介绍如何部署和使用采用本文档所介绍架构的示例应用。
微服务中的端到端事务
在微服务架构中,端到端事务可能跨多个服务。每个服务都可能提供一项特定功能并具有自己的独立数据库,如下图所示。

如上图所示,客户端通过网关访问多个微服务。由于这种客户端访问安排,您不能依赖于单个数据库的事务功能来帮助数据库系统从故障中恢复或是确保一致性。因此,我们建议您在微服务架构中实现事务工作流。
本文档介绍了下面两种可用来在微服务架构中实现事务工作流的模式:
- 基于编排的 Saga
- 同步编排
示例应用
为了帮助演示工作流,本文档使用一个简单的示例应用,该应用可以处理一个购物网站的订单事务。该应用负责管理客户及其订单。客户都具有信用额度,因此该应用必须在客户生成新订单时确认订单金额没有超过客户的信用额度。如下图所示,该事务工作流将在以下微服务上运行:Order 服务和 Customer 服务。

工作流如下:
- 客户提交订单请求,该请求将指定客户 ID 和一些商品。
Order服务将分配一个订单 ID,并将订单信息存储在数据库中。此时,订单状态被标记为pending。Customer服务会根据所订购商品的数量增加存储在数据库中的客户信用额度用量。(例如,一个商品增加 100 点信用额度用量。)- 如果信用额度总用量小于或等于预定义限额,则订单将被接受,并且
Order服务会将数据库中订单的状态更改为accepted。 - 如果信用额度总用量大于预定义限额,则
Order服务会将订单状态更改为rejected。在这种情况下,信用额度用量不会增加。
Order 服务
Order 服务负责管理订单的状态。该服务会为每个客户端请求生成订单记录,并将其存储在 Order 数据库中。该记录包含以下列内容:
Order_id:订单的 ID。此 ID 由Order服务生成。Customer_id:客户 ID。Number:订单中的商品数量。Status:订单的状态。
Customer 服务
Customer 服务负责管理客户的信用额度用量。该服务会为每个客户端请求生成客户记录,并将其存储在 Customer 数据库中。该记录包含以下列内容:
Customer_id:由Customer服务生成的客户 ID。Credit:客户消耗的信用额度用量。当客户订购商品时,信用额度用量会增加。Limit:客户的个人信用额度用量限额。当客户的信用额度用量超出设定的限额时,订单将被拒绝。
基于编排的 Saga
本部分介绍如何在事务工作流中实现基于编排的 Saga 微服务模式。
架构概览
在基于编排的 Saga 微服务模式中,微服务充当自治分布式系统。当服务更改自己的实体的状态时,它会发布一个事件来通知其他服务此项更新。通知事件会触发其他服务执行相应操作。通过这种方式,多个服务便可以协同工作来完成事务流程。微服务之间的通信是异步进行的。当一个服务发布事件时,系统不会向该服务发送任何信息来确认其他服务是否接收到事件或是接收事件的时间。
下图展示了基于编排的 Saga 微服务模式的示例。

上图中显示的示例架构实现流程如下:
发布事件之前,您需要使用 Datastore 来存储事件。如事件发布流程部分所述,微服务会先存储事件,而不是立即发布事件。
Order 和 Customer 服务首先将事件存储在事件数据库中。然后,使用 Cloud Scheduler 定期发布存储的事件。Cloud Scheduler 会通过调用 event-publisher 服务来发布事件。此事件流程如下图所示:

事务工作流
在事务工作流中,两个服务是通过事件相互通信。在此架构中,客户订单的处理流程如下:
- 客户端提交订单请求,该请求将指定客户的 ID 以及他们订购的商品数量。该请求通过 REST API 发送到
Order服务。 Order服务会为订单分配一个 ID,并将订单信息存储在Order数据库中。此时,订单状态被标记为pending。Order服务会将订单信息返回给客户端,并将包含订单信息的事件发布到以下 Pub/Sub 主题:order-service-event。Customer服务会通过推送通知来接收事件。该服务会根据所订购商品的数量增加存储在Customer数据库中的客户信用额度用量。- 如果信用额度总用量小于或等于预定义限额,
Customer服务会发布一个事件,说明已成功增加信用额度用量。否则,该服务会发布一个事件,说明未能增加信用额度用量。在这种情况下,信用额度用量不会增加。 Order服务会通过推送通知来接收事件。该服务会相应地将订单状态更改为accepted或rejected。客户端可以使用从Order服务返回的订单 ID 跟踪订单的状态。
下图总结了此工作流:
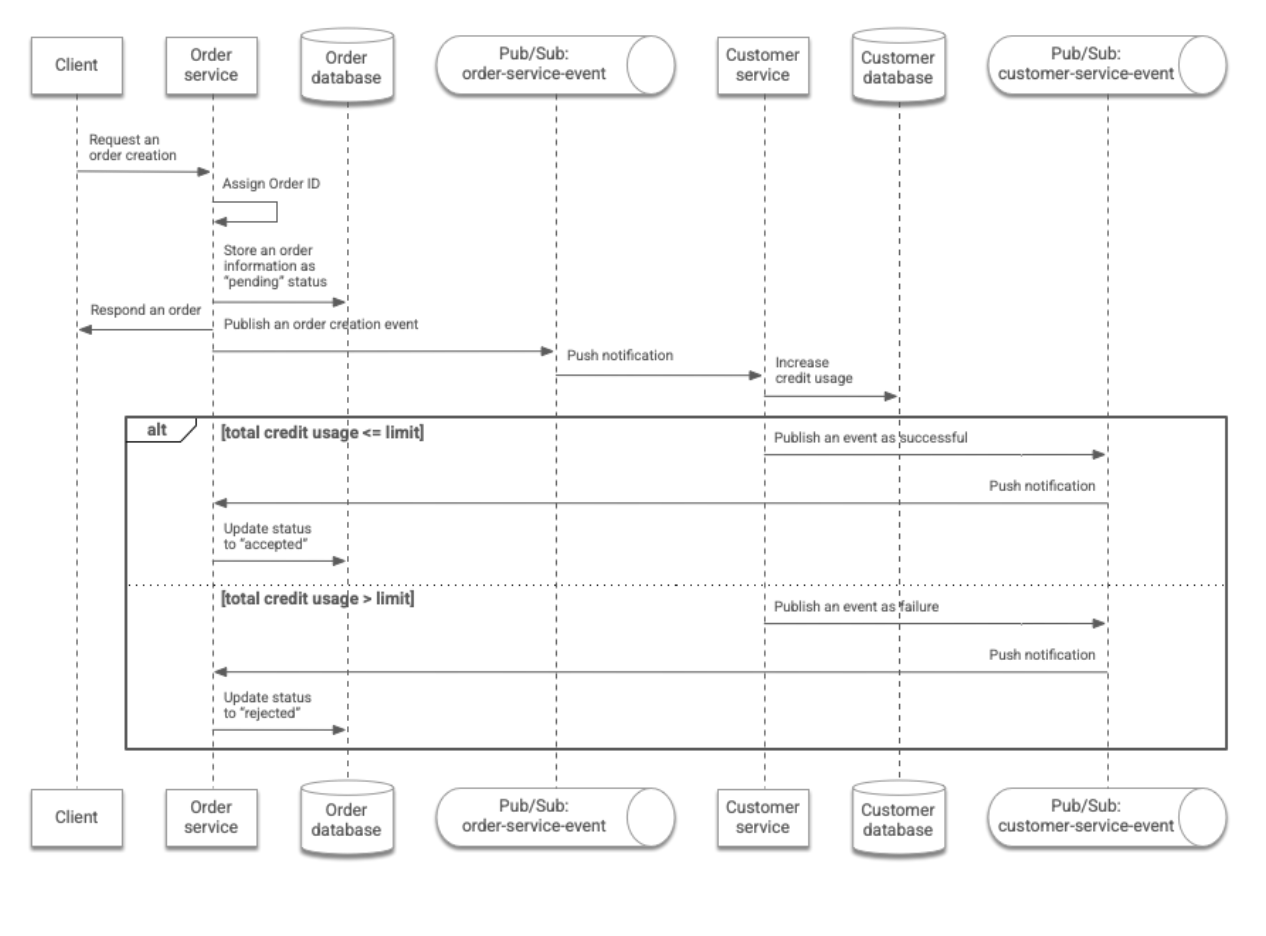
事件发布流程
当微服务在数据库中修改自己的数据并发布事件来通知数据库时,这两种操作都必须以原子方式执行。例如,如果微服务在修改数据后失败但未发布事件,则事务流程会停止。在这种情况下,数据可能会在事务中涉及的多个微服务中处于不一致的状态。为避免此问题,在本文档所用的示例应用中,微服务会将事件数据写入后端数据库,而不是直接将事件发布到 Pub/Sub。
系统会使用后端数据库的事务功能以原子方式修改数据并写入关联的事件数据。此模式(如下图所示)通常称为应用事件或“事务性发件箱”。

如上图所示,事件数据中的 published 列最初标记为 False。然后,event-publisher 服务会定期扫描数据库,并发布 published 列为 False 的事件。成功发布事件后,event-publisher 服务会将 published 列更改为 True。
如下图所示,同一命名空间中的 Order 数据库和 Event 数据库都可以通过 Datastore 事务以原子方式更新。

如果 event-publisher 服务在发布事件后失败但没有更改 published 列,则该服务会在故障恢复后再次发布同一事件。由于重新发布事件会导致事件重复,因此接收事件的微服务必须检查潜在的重复情况并相应地予以处理。此方法有助于保证事件处理的幂等性。
下图展示了示例应用如何处理事件重复情况。
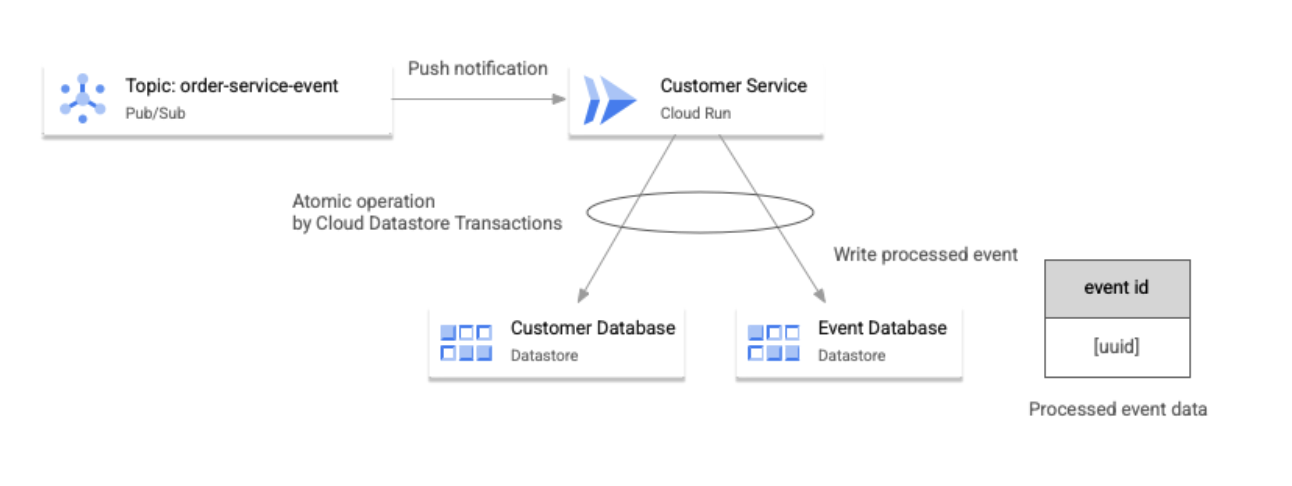
如上图所示,应用会通过以下工作流来处理重复事件:
- 每个微服务都会根据事件触发的业务逻辑更新其相应的后端数据库,并将事件 ID 写入其数据库。
- 这两个写入操作都使用后端数据库使用的事务功能以原子方式执行。
- 如果服务接收到重复事件,则当服务在其数据库中查找事件 ID 时便会检测到该重复事件。
从 Pub/Sub 接收事件时,经常会遇到需要处理重复事件的情况,因为 Pub/Sub 有可能会导致重复的消息传送。
扩展架构
在示例应用中,您可以在处理消息之前,使用 Datastore 来检查该消息是否为重复事件。此方法可确保使用消息的服务(在本例中为 Customer 服务)具有幂等性。此方法通常称为“幂等性使用方”模式。一些框架会将此模式作为一个内置功能来实现,例如 Eventuate。
但是,这需要每次处理消息时都访问数据库,从而可能导致性能问题。一种解决方案是使用具有良好性能和可伸缩性的数据库,例如 Redis。
同步编排
本部分介绍如何在事务工作流中实现同步编排微服务模式。
架构概览
在此模式中,会使用一个编排器来控制事务的执行流程。微服务和编排器之间的通信通过 REST API 同步完成。
在本文档介绍的示例架构中,Cloud Run 用作微服务的运行时,Datastore 用作每个服务的后端数据库。此外,Workflows 则用作编排器。此模式如下图所示:
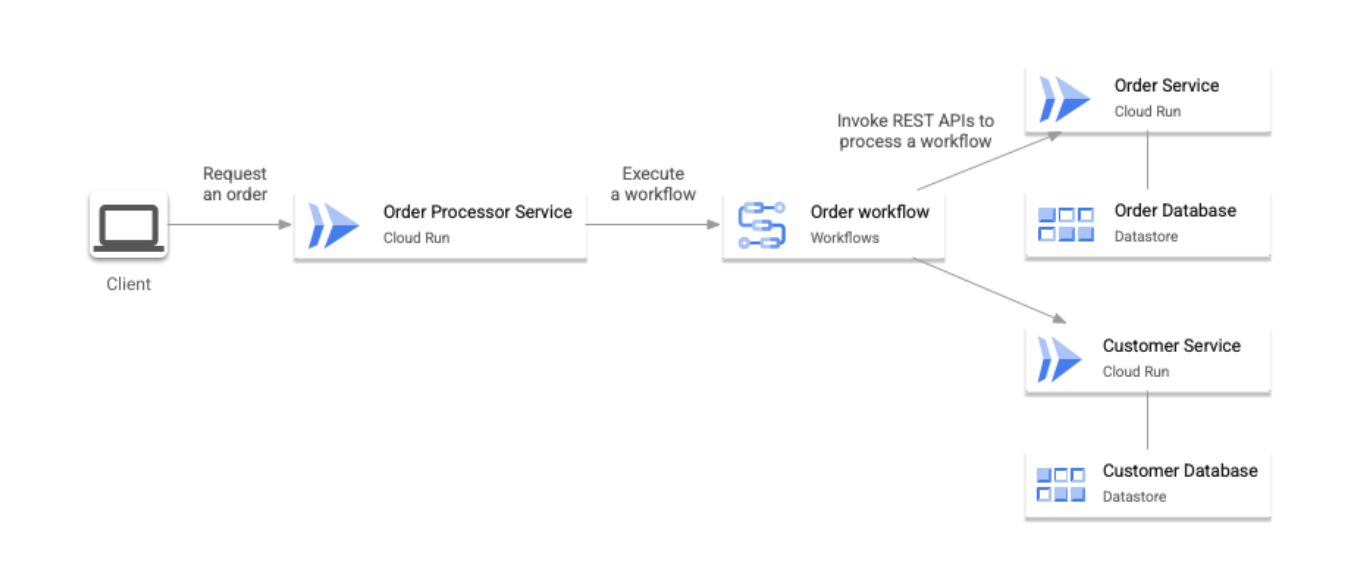
事务工作流
在同步工作流的架构中,客户订单的处理流程如下:
- 客户端提交订单请求,该请求将指定客户的 ID 以及客户订购的商品数量。该请求通过 REST API 发送到
Order processor服务。 Order processor服务会执行一个工作流来将客户 ID 和商品数量传递给 Workflows。- 该工作流会调用
Order服务的 REST API,并传递客户 ID 和客户订购的商品数量。然后,Order服务会为客户的订单分配一个订单 ID,并将订单信息存储在Order数据库中。此时,订单状态被标记为pending。Order服务会将订单信息返回给该工作流。 - 该工作流会调用
Customer服务的 REST API,并传递客户 ID 和客户订购的商品数量。然后,Customer服务会根据所订购商品的数量增加存储在Customer数据库中的客户信用额度用量。 - 如果信用额度总用量小于或等于预定义限额,
Customer服务会返回相应数据,说明已成功增加信用额度用量。否则,该服务会返回相应数据,说明未能增加信用额度用量。在这种情况下,信用额度用量不会增加。 - 该工作流会调用
Order服务的 REST API,以将订单状态相应地更改为accepted或rejected。最后,该工作流会将最终状态更新中的订单信息返回给Order processor服务。然后,Order processor服务会将该信息返回给客户端。
此工作流汇总如下:
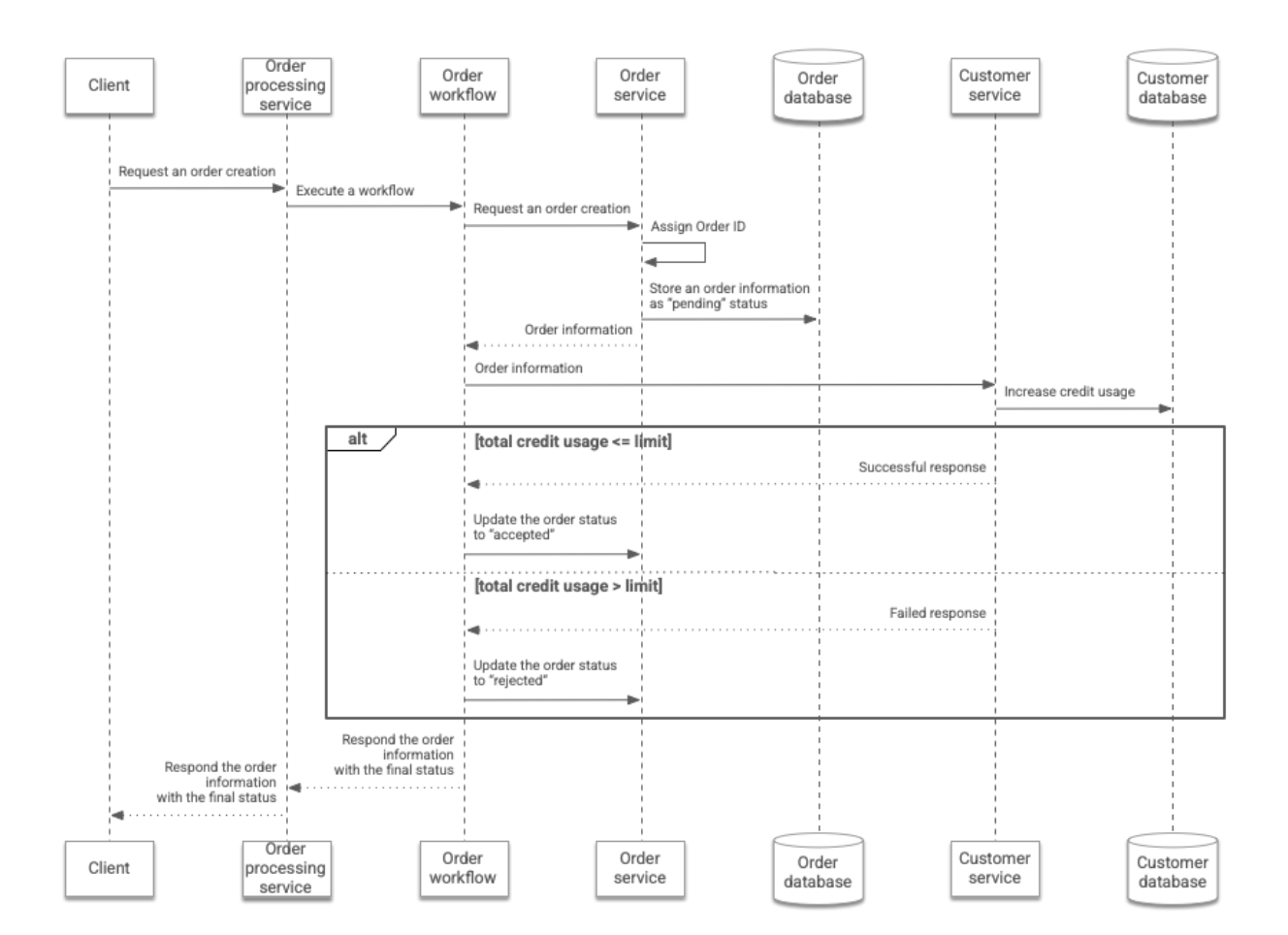
优点和缺点
在考虑是实现基于编排的 Saga 还是同步编排时,您始终应选择最适合贵组织需求的模式。但是,一般来说,由于同步编排的设计简单,因此它通常是许多企业的首选。
下表总结了本文档中介绍的基于编排的 Saga 模式和同步编排模式的优缺点。
优点 |
缺点 |
|
|---|---|---|
基于编排的 Saga |
耦合松散:每个服务都会在其自己的数据发生更改时向 Datastore 发布事件;而系统不会向任何其他服务发送任何信息。这种方法使每个服务都更加独立,并且在工作流中引入新服务时,您基本无需修改现有服务。 |
依赖项复杂:整个工作流的实现是在服务之间分布式完成的。因此,工作流理解起来可能会较为复杂。这种方法可能会意外地给未来的设计更改和问题排查增加复杂性。 |
同步编排 |
依赖项简单:一个编排器就可以控制事务的整个执行流程。因此,事务流程的工作原理理解起来会更为容易。此模式简化了工作流的修改过程和问题排查过程。 |
存在紧密耦合风险:中央编排器依赖于构成事务工作流的所有服务。因此,当您修改其中一个服务或是向工作流添加新服务时,您可能需要相应地修改编排器。与单体式系统相比,由于需要完成这些额外的工作量,这一弊端可能会大于能够更加独立地为微服务架构修改和添加服务所带来的益处。 |
后续步骤
- 详细了解微服务架构
- 探索有关 Google Cloud 的参考架构、图表和最佳做法。查看我们的 Cloud Architecture Center。