In dieser Anleitung verwenden Sie Striim zur Migration von Oracle® Database Enterprise Edition 18c oder höher, entweder von einer lokalen Umgebung oder von einer Cloud-Umgebung zu einer Cloud SQL for PostgreSQL-Instanz in Google Cloud. In dieser Anleitung werden Tabellen im HR-Beispielschema von Oracle verwendet.
Diese Anleitung richtet sich an Unternehmensarchitekten, Datenbankentwickler und Dateninhaber, die Striim für die Migration oder Replikation von Oracle-Datenbanken zu Cloud SQL for PostgreSQL verwenden möchten. Sie sollten Grundkenntnisse in der Verwendung von Striim zum Erstellen von Pipelines haben. Außerdem sollten Sie mit der Striim-Web-UI, mit Schlüsselkonzepten von Striim und mit dem Erstellen einer Anwendung mit Striims Flow Designer vertraut sein.
Striim ist Google Cloud-Technologiepartner für die Datenbankmigration. Striim vereinfacht Online-Migrationen durch die Verwendung einer Drag-and-drop-Oberfläche zur Einrichtung einer kontinuierlichen Datenverschiebung zwischen Datenbanken. Für Migrationen zu Google Cloud bietet Striim eine nicht eingreifende ETL-Plattform (Extrahieren, Transformieren und Laden), die sich effizient bereitstellen und einfach iterieren lässt. Zum Erstellen der Migrationspipeline verwenden Sie in dieser Anleitung den Flow Designer von Striim.
Wenn die Datenbankmigration Ihnen nicht vertraut ist, finden Sie weitere Informationen unter Dieses Tech-Talk von der Google Cloud Next '19.
Architektur
Die Datenbankmigration mit Striim umfasst zwei Phasen der sequenziellen Datenverschiebung:
- Phase 1: Einmalige anfängliche Replikation der Oracle-Datenbank.
- Phase 2: Die kontinuierliche Replikation jeder Änderung, die anschließend im Quelldatenbanksystem per Commit geschrieben wird, mithilfe von Change Data Capture (CDC).
Das folgende Diagramm veranschaulicht eine grundlegende Bereitstellungsarchitektur:

Bei dieser Architektur wird die Striim-Anwendung auf einer Compute Engine-Instanz ausgeführt. Sie stellt eine Verbindung zu einer Oracle-Datenbank her, die lokal oder in der Cloud gehostet wird, und schreibt Daten in eine Cloud SQL for PostgreSQL-Instanz in Google Cloud.
Verwenden Sie für beide Instanzen dasselbe Netzwerk, um Netzwerk- oder Verbindungsprobleme zwischen den Striim- und Cloud SQL-Instanzen zu vermeiden. Sie haben folgende Möglichkeiten: Striim aus Google Cloud Marketplace auf einer Compute Engine-Instanz bereitstellen oder, wenn Sie eine hochverfügbare Instanz benötigen, Striim als Cluster bereitstellen.
Für diese Anleitung stellen Sie die Bereitstellung über Cloud Marketplace bereit.
Der Vorteil der Bereitstellung von Striim über Cloud Marketplace besteht darin, dass Sie eine Verbindung zu verschiedenen Datenbanken und Datenquellen mithilfe ihrer integrierten Adapter herstellen können. Sie können die Adapter über Flow Designer, die interaktive Drag-and-drop-Oberfläche von Striim, verbinden und so einen azyklischen Graphen erstellen. Dieser Graph wird auch als Striim-Pipeline oder Striim-Anwendung bezeichnet.
Beim Migrationsanwendungsfall in dieser Anleitung werden drei Striim-Adapter verwendet:
- Datenbank-Leser: Liest Daten aus der Oracle-Quelldatenbank während der anfänglichen Ladephase.
- Oracle Leser: Liest Daten mit LogMiner aus der Oracle-Quelldatenbank während der Phase der kontinuierlichen Datenreplikation.
- Datenbankautor: Schreibt Daten während des anfänglichen Ladevorgangs und während der kontinuierlichen Datenreplikation in die Cloud SQL for PostgreSQL-Datenbank.
Ziele
Bereiten Sie die Oracle-Datenbank als Quelldatenbank für die Migration oder Replikation vor.
Bereiten Sie eine Cloud SQL for PostgreSQL-Datenbank als Zieldatenbank für die Migration oder Replikation vor.
Erfüllen Sie die Voraussetzungen für die Installation und Ausführung von Striim.
Konvertieren Sie das Schema der Oracle-Datenbank in das entsprechende Schema in PostgreSQL.
Führen Sie den anfänglichen Ladevorgang aus Ihrer Oracle-Datenbank in Cloud SQL for PostgreSQL aus.
Richten Sie die kontinuierliche Replikation von Ihrer Oracle-Datenbank in Cloud SQL for PostgreSQL ein.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Die Striim-Lösung im Cloud Marketplace bietet eine zeitlich begrenzte kostenlose Testversion. Nach Ablauf der Testphase werden die Nutzungsgebühren Ihrem Google Cloud-Konto in Rechnung gestellt. Sie können Striim-Lizenzen auch direkt von Striim für die lokale Bereitstellung und auf einer virtuellen Maschine (VM) von Compute Engine erhalten. Möglicherweise fallen auch Kosten für die Ausführung einer Oracle-Datenbank außerhalb von Google Cloud an.
Hinweis
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
In dieser Anleitung wird Folgendes vorausgesetzt:
- Eine Oracle Database Enterprise Edition 18c oder höher für Linux x86-64, die Sie migrieren möchten.
- Compute Engine mit CentOS, auf dem Striim installiert ist. Sie können Striim über die Google Cloud Marketplace-Lösung bereitstellen.
Oracle-Datenbank vorbereiten
In den folgenden Abschnitten werden Konfigurationsänderungen beschrieben, die Sie möglicherweise für die Verbindung mit Ihrer Oracle-Datenbank und deren Migration mit Striim benötigen. Konfigurationsdetails finden Sie unter Grundlegende Oracle-Konfigurationsaufgabe.
Quelle für Oracle CDC auswählen
Obwohl es verschiedene Oracle CDC-Quellen gibt, wird in dieser Anleitung LogMiner verwendet. Informationen zu alternativen Optionen finden Sie unter Alternative Oracle CDC-Quellen.
Oracle Database Enterprise Edition 18c (oder höher) vorbereiten
Folgen Sie der Anleitung auf der Striim-Dokumentationsseite, um die Oracle-Datenbank vorzubereiten:
- Aktivieren Sie
archivelogvon Striim. - Aktivieren Sie zusätzliche Logdaten von Striim.
- Aktivieren Sie das Primärschlüssel-Logging von Striim.
Erstellen Sie einen Oracle-Nutzer mit LogMiner-Berechtigungen für Striim.
Zur Ausführung dieser Schritte müssen Sie mit der Containerdatenbank (CDB) verbunden sein, unabhängig davon, ob Sie eine CDB oder eine Plug-in-Datenbank (PDB) migrieren. Wir empfehlen, SQL*Plus zu installieren und zu verwenden, um mit der Oracle-Datenbank zu interagieren.
Erstellen Sie eine Striim-
quiescemarker-Tabelle.Der Oracle Leser-Adapter für CDC von Striim benötigt eine Tabelle zum Speichern von Metadaten, wenn eine Anwendung stillgelegt wird. Wenn Sie LogMiner als Quelle für CDC verwenden (wie in dieser Anleitung), benötigen Sie die quiescemarker-Tabelle. Sie müssen mit der CDB verbunden sein, wenn Sie die Schritte zum Erstellen der Tabelle ausführen.
Stellen Sie eine Netzwerkverbindung zwischen der Oracle-Datenbank und der Striim-Instanz her.
Der Oracle-Listener ist standardmäßig an Port
1521. Achten Sie darauf, dass die IP-Adresse für die Striim-Instanz eine Verbindung zum Oracle-Listener-Port herstellen darf und dass keine Firewallregeln sie blockieren. Der Port, für den der Oracle-Listener konfiguriert ist, befindet sich in der Datei$ORACLE_HOME/network/admin/tnsnames.ora.Notieren Sie sich die System Change Number (SCN) für die Oracle-Datenbank.
Die SCN ist ein interner Zeitstempel, mit dem auf Änderungen an einer Datenbank verwiesen wird.
Rufen Sie für Ihre Oracle-Datenbank das älteste SCN ab:
SELECT MIN(start_scn) FROM gv$transaction;Kopieren Sie diese Nummer. Sie benötigen sie später in den Pipeline-Schritten der kontinuierlichen Replikation.
Striim-Instanz vorbereiten
Informationen zu den von Striim unterstützten Betriebssystemen finden Sie unter Systemanforderungen. Um den Oracle Leser mit LogMiner zu verwenden, fügen Sie den Oracle-JDBC-Treiber in den Java-Klassenpfad Ihrer Striim-Instanz ein. Führen Sie die folgenden Schritte auf jedem Striim-Server aus, auf dem ein Oracle Leser-Adapter ausgeführt wird:
- Melden Sie sich in Ihrem Oracle-Konto an und laden Sie die Datei
ojdbc8.jarauf Ihren lokalen Computer herunter.- Wenn Sie kein Oracle-Konto haben, erstellen Sie eines.
Klicken Sie für die Datei
ojdbc8.jarauf den Link Herunterladen.- Klicken Sie auf Ich habe die Oracle-Lizenzvereinbarung überprüft und akzeptiere sie, um die Datei herunterzuladen, wenn Sie die Lizenzbedingungen akzeptieren.
Erstellen Sie in Cloud Shell einen Cloud Storage-Bucket und laden Sie die Datei
.jarin diesen hoch:gsutil mb -b on -l REGION gs://BUCKET_NAME gsutil cp PATH/ojdbc8.jar gs://BUCKET_NAMEDabei gilt:
- REGION: die Region, in der Sie den Cloud Storage-Bucket erstellen möchten
- BUCKET_NAME: der Name des Cloud Storage-Buckets, in dem die Datei
ojdbc8.jargespeichert werden soll - PATH: der Pfad zum Downloadort der Datei
ojdbc8.jar
Nachdem die Datei auf Ihrem lokalen Computer gespeichert wurde, sollten Sie die Datei
.jarin einen Cloud Storage-Bucket hochladen, damit Sie sie auf jeden beliebigen Instanz herunterladen können.Öffnen Sie eine SSH-Sitzung mit Ihrer Striim-Instanz, laden Sie dann die Datei
.jarauf Ihre Striim-Instanz herunter und speichern Sie sie im Verzeichnis/opt/striim/lib:sudo su - striim gsutil cp gs://BUCKET_NAME/ojdbc8.jar /opt/striim/libPrüfen Sie, ob die Datei
ojdbc8.jardie richtigen Dateiberechtigungen hat:sudo ls -l /opt/striim/lib/ojdbc8.jarDie Ausgabe sollte so aussehen:
-rwxrwx--- striim striim(Optional) Wenn die Datei
.jarnicht die vorherigen Berechtigungen hat, legen Sie die richtigen Berechtigungen fest:sudo chmod 770 /opt/striim/lib/ojdbc8.jar sudo chown striim /opt/striim/lib/ojdbc8.jar sudo chgrp striim /opt/striim/lib/ojdbc8.jarStriim beenden und neu starten.
Nachdem Sie Konfigurationsänderungen vorgenommen haben (z. B. die vorherigen Berechtigungsänderungen), müssen Sie Striim neu starten.
Wenn Sie die Linux-Distribution für CentOS 7 verwenden, beenden Sie Striim:
sudo systemctl stop striim-node sudo systemctl stop striim-dbmsWenn Sie die Linux-Distribution für CentOS 7 verwenden, starten Sie Striim:
sudo systemctl start striim-dbms sudo systemctl start striim-node
Weitere Informationen zum Beenden und Neustarten von Striim für ein anderes Betriebssystem finden Sie unter Striim starten und beenden.
psql-Client auf der Striim-Instanz installieren.
Sie verwenden diesen Client, um eine Verbindung zur Cloud SQL-Instanz herzustellen und Schemas später in dieser Anleitung zu erstellen.
Cloud SQL für PostgreSQL-Schema vorbereiten
Wenn Sie tabellarische Daten von einer Datenbank in eine andere kopieren oder kontinuierlich replizieren, erfordert Striim normalerweise, dass die Zieldatenbank entsprechende Tabellen mit dem richtigen Schema enthält. Google Cloud hat kein Dienstprogramm zum Vorbereiten des Schemas. Sie können jedoch das Dienstprogramm zur Schemakonvertierung von Striim oder ein Open-Source-Dienstprogramm wie Ora2Pg verwenden.
Fremdschlüssel beim anfänglichen Ladevorgang beibehalten
Achten Sie in der anfänglichen Ladephase auf die Behandlung von Fremdschlüsseln. Mit Fremdschlüsseln wird die Beziehung zwischen den Tabellen in einer relationalen Datenbank hergestellt. Das Erstellen oder Einfügen eines Fremdschlüssels in die Zieldatenbank kann die Beziehung zwischen den beiden Tabellen zerstören. Wenn die Integrität zwischen den beiden Datenbanken beeinträchtigt ist, können Fehler auftreten. Daher ist es wichtig, dass alle Fremdschlüsseldeklarationen während des Schemaexports später in diesem Abschnitt in eine separate Datei ausgegeben werden.
Bei der kontinuierlichen Replikation in CDC-Pipelines werden die Quelldatenbankereignisse in der Reihenfolge ihres Auftretens an die Zieldatenbank weitergegeben. Wenn Sie die Fremdschlüssel für Ihre Quelle ordnungsgemäß verwalten, werden die Fremdschlüsselvorgänge in derselben Reihenfolge von der Quell- zur Zieldatenbank repliziert.
Im Gegensatz dazu werden bei der anfänglichen Ladepipeline standardmäßig Ihre Tabellen in alphabetischer Reihenfolge geladen. Wenn Sie die Fremdschlüssel vor dem anfänglichen Ladevorgang nicht deaktivieren, treten Fremdschlüsselfehler auf. Wenn Sie Daten beim anfänglichen Ladevorgang aus den Quelldatenbanktabellen in die Zieltabellen in Cloud SQL for PostgreSQL replizieren möchten, müssen Sie die Fremdschlüsseleinschränkungen für die Tabellen deaktivieren. Andernfalls könnten die Einschränkungen während der Replikation verletzt werden.
Ab Juni 2021 unterstützt Cloud SQL for PostgreSQL Konfigurationsoptionen zum Deaktivieren von Fremdschlüsselbeschränkungen nicht mehr.
So verarbeiten Sie Einschränkungen für Fremdschlüssel:
- Geben Sie während des Schemaexports alle Fremdschlüsseldeklarationen in eine separate Datei aus.
- Erstellen Sie Tabellenschemas in der Cloud SQL for PostgreSQL-Datenbank ohne die Fremdschlüsseleinschränkungen.
- Führen Sie die erste Datenreplikation durch.
- Wenden Sie Fremdschlüsseleinschränkungen auf die Tabellen an.
- Erstellen Sie die kontinuierliche Replikations-Pipeline.
Diese Anleitung bietet zwei Optionen für die Schemakonvertierung, die in den folgenden Abschnitten erläutert werden:
- Das Dienstprogramm Striim für Schema-Konvertierung (empfohlen)
- Den Oracle-zu-PostgreSQL-Datenbankschema-Converter (Ora2Pg)
Schema mit dem Dienstprogramm zur Schemakonvertierung von Striim konvertieren
Verwenden Sie das Dienstprogramm zur Schemakonvertierung von Striim, um Cloud SQL for PostgreSQL dafür vorzubereiten, Daten in das Zielschema einzubinden und Tabellen zu erstellen, die die Oracle-Quelldatenbank widerspiegeln.
Das Striim-Schemakonvertierungstool konvertiert die folgenden Quellobjekte in äquivalente Zielobjekte:
- Tabellen
- Primärschlüssel
- Datentypen
- Eindeutige Einschränkungen
NOT NULLEinschränkungen- Fremdschlüssel
Mit dem Dienstprogramm zur Schemakonvertierung von Striim können Sie die Quelldatenbank analysieren und DDL-Skripts generieren, um entsprechende Schemas in der Zieldatenbank zu erstellen.
Wir empfehlen, das Schema manuell mit den generierten DDL-Skripts in der Zieldatenbank zu erstellen. Am einfachsten ist es, eine Teilmenge der Tabellen auszuwählen, das Schema zu exportieren und es in die Cloud SQL für PostgreSQL-Datenbank zu importieren.
Das folgende Beispiel zeigt, wie Sie Ihre Cloud SQL for PostgreSQL-Datenbank für den anfänglichen Ladevorgang vorbereiten. Dazu importieren Sie Ihr Schema mit dem Dienstprogramm zur Schemakonvertierung von Striim:
Öffnen Sie eine SSH-Verbindung zu Ihrer Striim-Instanz.
Wechseln Sie in das Verzeichnis
/opt/striim:cd /opt/striimListen Sie alle Argumente auf:
bin/schemaConversionUtility.sh --helpFühren Sie das Dienstprogramm zur Schemakonvertierung aus und geben Sie dabei die Flags an, die für Ihren Anwendungsfall geeignet sind:
bin/schemaConversionUtility.sh \ -s=oracle \ -d=SOURCE_DATABASE_CONNECTION_URL \ -u=SOURCE_DATABASE_USERNAME \ -p=SOURCE_DATABASE_PASSWORD \ -b=SOURCE_TABLES_TO_CONVERT \ -t=postgres \ -f=falseDabei gilt:
- SOURCE_DATABASE_CONNECTION_URL: Verbindungs-URL für die Oracle-Datenbank, z. B.
"jdbc:oracle:thin:@12.123.123.12:1521/APPSPDB.WORLD"oder"jdbc:oracle:thin:@12.123.123.12:1521:XE" - SOURCE_DATABASE_USERNAME: Oracle-Nutzername für die Verbindung zur Oracle-Datenbank
- SOURCE_DATABASE_PASSWORD: Oracle-Passwort für die Verbindung zur Oracle-Datenbank
- SOURCE_TABLES_TO_CONVERT: Tabellennamen aus der Quelldatenbank, die zum Konvertieren von Schemas verwendet werden
Achten Sie darauf, das Argument
-f=falsezu verwenden. Dieses Argument exportiert die Fremdschlüsseldeklarationen in eine separate Datei.Der Ausgabeordner enthält möglicherweise einige oder alle der folgenden Dateien. Weitere Informationen zu diesen Dateien finden Sie in der Dokumentation zum Dienstprogramm zur Schemakonvertierung von Striim.
Dateiname der Ausgabe Beschreibung converted_tables.sqlEnthält alle konvertierten Tabellen, die keine Erzwingung erfordern converted_tables_with_striim_intelligence.sqlEnthält alle konvertierten Tabellen, die mit einer gewissen Erzwingung konvertiert wurden conversion_failed_tables.sqlEnthält Tabellen, in denen die Konvertierung versucht wurde, aber keine Zuordnung ermittelt wurde converted_foreignkey.sqlEnthält alle Deklarationen zu Fremdschlüsseleinschränkungen conversion_failed_foreignkey.sqlEnthält alle fehlgeschlagenen Fremdschlüsselkonvertierungen conversion_report.txtEnthält einen ausführlichen Bericht der Schemakonvertierung In dieser Anleitung verwenden Sie die Datei
converted_tables.sql, um entsprechende Tabellen in der Cloud SQL for PostgreSQL-Datenbank ohne Fremdschlüsseleinschränkungen zu erstellen. Nach der ersten Replikation wenden Sie mit der Dateiconverted_foreignkey.sqldie Einschränkungen für Fremdschlüssel an.- SOURCE_DATABASE_CONNECTION_URL: Verbindungs-URL für die Oracle-Datenbank, z. B.
Schema mithilfe von Ora2Pg konvertieren
Eine weitere Möglichkeit, Oracle-Tabellenschemas in entsprechende PostgreSQL-Schemas zu konvertieren, ist das Ora2Pg-Dienstprogramm. Sie können dieses Dienstprogramm auf einer separaten Google Cloud-VM installieren.
Das Ora2Pg-Dienstprogramm konvertiert das Oracle-Schema und exportiert die DDL-Anweisungen, die zum Erstellen äquivalenter Tabellen in der PostgreSQL-Datenbank erforderlich sind. Diese DDL-Anweisungen werden in eine Ausgabedatei mit dem Namen output.sql exportiert.
Während des Schemaexports exportieren und speichern Sie alle Deklarationen des Fremdschlüssels in einer separaten Datei, indem Sie das folgende Flag in der Ora2Pg-Konfigurationsdatei verwenden:
FILE_PER_FKEYS 1
Standardmäßig werden Fremdschlüssel in die Hauptausgabedatei (output.sql) exportiert. Wenn Sie das Flag FILE_PER_FKEYS aktivieren (1), werden Fremdschlüssel in eine separate Datei exportiert, nämlich in FKEYS_output.sql.
In dieser Anleitung verwenden Sie die Datei output.sql, um entsprechende Tabellen in der Cloud SQL for PostgreSQL-Datenbank ohne Fremdschlüsseleinschränkungen zu erstellen.
Nach der ersten Replikation wenden Sie mit der Datei FKEY_output.sql die Einschränkungen für Fremdschlüssel an.
Cloud SQL for PostgreSQL-Instanz vorbereiten
Damit Striim Daten in eine Cloud SQL for PostgreSQL-Instanz schreiben kann, müssen Sie eine Cloud SQL-Instanz erstellen. Außerdem müssen Sie die Datenbanktabellen und das Schema erstellen, in das Striim schreibt:
Erstellen Sie in Cloud Shell eine Cloud SQL for PostgreSQL-Instanz. Wir empfehlen, Cloud SQL für die Verwendung einer privaten IP-Adresse zu konfigurieren. Verwenden Sie den Parameter
--network, um diese Adresse zu konfigurieren:$INSTANCE_NAME=INSTANCE_NAME gcloud beta sql instances create INSTANCE_NAME \ --database-version=POSTGRES_12 \ --network=NETWORK \ --cpu=NUMBER_CPUS \ --memory=MEMORY_SIZE \ --region=REGIONDabei gilt:
- INSTANCE_NAME: der Name der Instanz
- NETWORK: der Name des VPC-Netzwerks, das Sie für diese Instanz verwenden
- NUMBER_CPUS: Anzahl von vCPUs in der Instanz
- MEMORY_SIZE: Größe des Arbeitsspeichers der Instanz. Beispiel: 3.072 MiB oder 9 GiB. Wenn Sie die Einheit nicht angeben, wird GiB angenommen.
- REGION: die Region, in der Sie den Cloud Storage-Bucket erstellt haben
Erstellen Sie einen Nutzernamen und ein Passwort auf der Cloud SQL-Instanz:
CLOUD_SQL_USERNAME=CLOUD_SQL_USERNAME gcloud sql users create $CLOUD_SQL_USERNAME \ --instance=$INSTANCE_NAME \ --password=CLOUD_SQL_PASSWORDDabei gilt:
- CLOUD_SQL_USERNAME: Nutzername für Ihre Cloud SQL-Instanz
- CLOUD_SQL_PASSWORD: Passwort für den Cloud SQL-Nutzernamen
Dieser Nutzer erhält die Inhaberschaft für die PostgreSQL-Tabellen. Striim verwendet die Anmeldedaten dieses Nutzers auch, um eine Verbindung zur Cloud SQL for PostgreSQL-Datenbank herzustellen.
Die Schemadateien, die während des Schemakonvertierungsschritts exportiert werden, enthalten möglicherweise eine DDL-Anweisung, die einem Nutzer wie im folgenden Beispiel die Inhaberschaft zuweist:
CREATE SCHEMA <SCHEMA_NAME>; ALTER SCHEMA <SCHEMA_NAME> OWNER TO <USER>;
Möglicherweise müssen Sie
SCHEMA_NAMEdurchCLOUD_SQL_SCHEMAundUSERdurch den zuvor erstelltenCLOUD_SQL_USERNAMEersetzen.PostgreSQL-Datenbank erstellen
CLOUD_SQL_DATABASE_NAME=CLOUD_SQL_DATABASE_NAME gcloud sql databases create $CLOUD_SQL_DATABASE_NAME \ --instance=$INSTANCE_NAMEDabei gilt:
- CLOUD_SQL_DATABASE_NAME: Name der PostgreSQL-Datenbank
Konfigurieren Sie die Cloud SQL für PostgreSQL-Datenbank so, dass der Zugriff von der Striim-Instanz zugelassen wird. Die Verbindungsoptionen hängen davon ab, ob Sie die Cloud SQL-Instanz für die Verwendung einer öffentlichen oder privaten IP-Adresse konfiguriert haben.
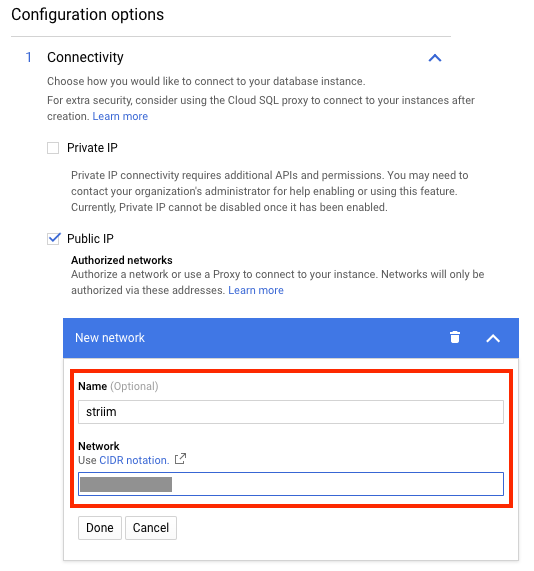
Wenn Sie eine öffentliche IP-Adresse konfiguriert haben, fügen Sie die IP-Adresse der Striim-Instanz als autorisierte Adresse der Cloud SQL-Instanz hinzu. Im folgenden Screenshot wird gezeigt, wie Sie dies über die Google Cloud Console tun können:
Wenn Sie eine private IP-Adresse konfiguriert haben, hängen die verfügbaren Verbindungsoptionen davon ab, ob die Cloud SQL-Instanz und Striim-Instanz befindet sich im selben VPC-Netzwerk.
Wenn sich die Striim-Instanz im selben VPC-Netzwerk wie die Cloud SQL-Instanz befindet, kann die Striim-Instanz eine Verbindung zur Cloud SQL-Instanz herstellen.
Der folgende Screenshot zeigt, dass die Cloud SQL-Instanz dem Standard-VPC-Netzwerk zugeordnet ist. Wenn die Striim-Instanz auch im Standard-VPC-Netzwerk erstellt wurde, kann sie privat eine Verbindung zur Cloud SQL-Instanz herstellen.
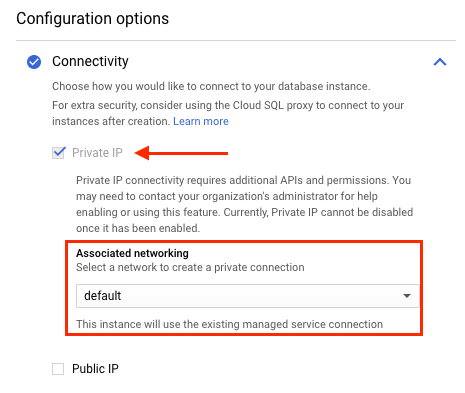
Wenn sich die Striim-Instanz in einem anderen VPC-Netzwerk als die Cloud SQL-Instanz befindet, konfigurieren Sie den Zugriff auf private Dienste im VPC-Netzwerk der Striim-Instanz.
Erstellen Sie Tabellenschemas ohne Fremdschlüsseleinschränkungen in der Cloud SQL for PostgreSQL-Datenbank.
Wenn Sie
output.sqlwährend des Schemakonvertierungsschritts exportieren möchten, erstellen Sie die Schemas mit der Dateioutput.sql.Wenn Sie während des Schemakonvertierungsschritts
converted_tables.sqlexportieren möchten, erstellen Sie die Schemas mit der Dateiconverted_tables.sql.Sie können jedes der beiden Skripts ausführen. Dazu verwenden Sie einen beliebigen PostgreSQL-Client, der mit der Cloud SQL for PostgreSQL-Instanz verbunden ist. Wir empfehlen jedoch, den PostgreSQL-Client zu verwenden, den Sie zuvor auf der Striim-Instanz installiert haben.
Erstellen Sie die Schemas:
psql -h HOSTNAME -p CLOUD_SQL_PORT -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -f PATH_TO_MAIN_SQL_FILEDabei gilt:
- HOSTNAME: IP-Adresse der Cloud SQL-Instanz
- CLOUD_SQL_PORT: Port der Cloud SQL-Instanz, zu der eine Verbindung hergestellt werden soll – standardmäßig
5432 - PATH_TO_MAIN_SQL_FILE: Pfad zum Hauptskript auf der Striim-Instanz
Beispiel:
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
Prüfen Sie, ob die Tabellen erstellt wurden:
Stellen Sie eine Verbindung zur Cloud SQL for PostgreSQL-Datenbank her:
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMEListen Sie die Tabellen in dieser Datenbank auf:
\dtDie Ausgabe ist eine Liste der Tabellen, die das im vorherigen Schritt erstellte Skript zur Tabellenschemakonvertierung erstellt hat.
Erstellen Sie eine Prüfpunktausführung-Tabelle in der Cloud SQL for PostgreSQL-Datenbank:
Stellen Sie eine Verbindung zur Cloud SQL for PostgreSQL-Datenbank her:
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMEErstellen Sie die Tabelle:
CREATE TABLE chkpoint ( id character varying(100) primary key, sourceposition bytea, pendingddl numeric(1), ddl text);Striim benötigt diese Tabelle, um Prüfpunkte während der kontinuierlichen Replikation beizubehalten.
Oracle-Datenbank in Cloud SQL for PostgreSQL-Datenbank laden
In diesem Abschnitt wird die einmalige Replikation der Oracle-Datenbank in die Cloud SQL for PostgreSQL-Datenbank beschrieben.
Verbindung zu Oracle von Striim herstellen
Folgen Sie der Anleitung unter Striim in Google Cloud ausführen. Für den anfänglichen Ladevorgang verwenden Sie den Striim Datenbank-Leser-Adapter, um von Striim eine Verbindung zu Oracle herzustellen. Sie können auch den CDC-Assistenten von Striim verwenden.
Gehen Sie im Striim Datenbank Leser-Adapter zu Sources (Quellen) und suchen Sie in der Liste nach Datenbank und wählen es aus.
Legen Sie im Fenster Datenbank die folgenden Attribute fest:
- Name: Geben Sie diese Komponente der Migrationspipeline an.
- Adapter:
DatabaseReader Verbindungs URL: Geben Sie einen eindeutigen String ein, um eine Verbindung zur Oracle-Datenbank herzustellen:
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT:SIDOR
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT/PDB_OR_CDB_SERVICE_NAMEDabei gilt:
- ORACLE_PORT: Oracle-Datenbankport (standardmäßig
1521) - SID: Oracle-Datenbank-SID
- PDB_OR_CDB_SERVICE_NAME: Name des Oracle-PDB- oder -CDB-Dienstes: Wenn sich Ihre Tabellen in einer PDB befinden, verwenden Sie
PDB_SERVICE_NAME. Wenn sie sich in einer CDB befinden, verwenden SieCDB_SERVICE_NAME.
Den Port und den Dienstnamen finden Sie in der Datei
tnsnames.oraauf der Oracle-Instanz unter$ORACLE_HOME/network/admin/tnsnames.ora.- ORACLE_PORT: Oracle-Datenbankport (standardmäßig
Nutzername und Passwort: Verwenden Sie den Oracle-Nutzer (
c##striim-Nutzer), den Sie in den vorherigen Schritten erstellt haben. Striim verwendet diesen Nutzernamen und dieses Passwort, um eine Verbindung zu Ihrer Oracle-Datenbank herzustellen und die Tabellen zu lesen.Tabellen: Für Oracle benötigt der Datenbank-Leser auch eine Liste der Tabellennamen, die repliziert werden sollen. Dieses Attribut wird im Feld „Tabellen“ unter Optionale Attribute anzeigen angegeben. Das Attribut hat folgendes Format:
ORACLE_SCHEMA.ORACLE_TABLE_NAMEDabei gilt:
- ORACLE_SCHEMA: Oracle-Schemaname
- ORACLE_TABLE_NAME: Oracle-Tabellennamen in diesem Schema
Sie können auch mehrere Tabellen und materialisierte Ansichten als Liste durch Semikolons getrennt oder mit den folgenden Platzhaltern angeben:
%: eine beliebige Reihe von Zeichen_: ein beliebiges einzelnes ZeichenBeispielsweise liest
HR.%alle Tabellen im HR-Schema. Mindestens eine Tabelle muss mit dem Platzhalter übereinstimmen. Andernfalls schlägt der Datenbank-Leser mit folgendem Fehler fehl:Could not find tables specified in the databaseStilllegen bei Abschluss des anfänglichen Ladevorgangs: Dieses Feld wird auf grün gesetzt, indem Sie es nach rechts schieben, um die Pipeline nach Abschluss des anfänglichen Ladevorgangs zu pausieren.
Ausgabe in: Benennen Sie die Ausgabe dieses Adapters. Verwenden Sie einen String mit Beachtung der Groß- und Kleinschreibung ohne Sonderzeichen oder Leerzeichen.
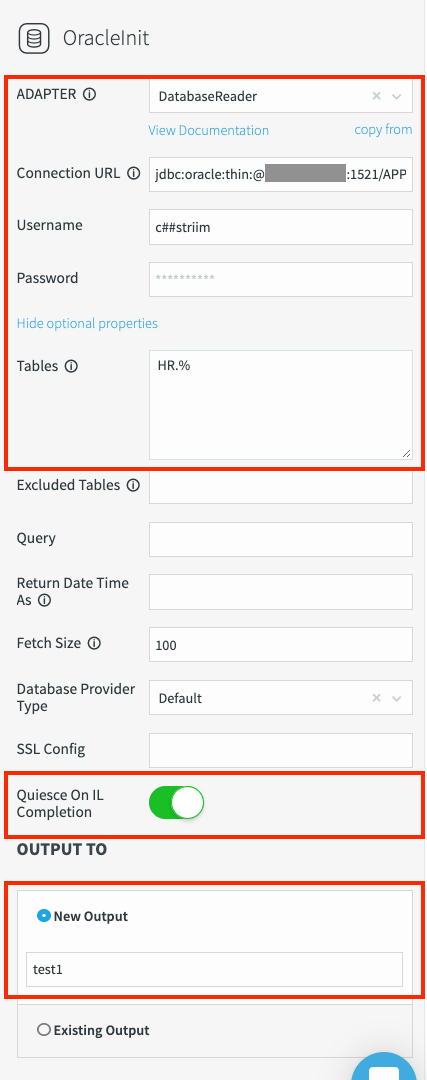
Klicken Sie auf Speichern. Die Attribute des Adapters werden angezeigt:
Verbindung testen
Nachdem Sie eine Verbindung zu Oracle über Striim hergestellt haben, testen Sie die Verbindung.
Klicken Sie auf die Drop-down-Liste Erstellt, um die Striim-Verbindungen zur Oracle-Datenbank zu testen.
Klicken Sie auf App bereitstellen.
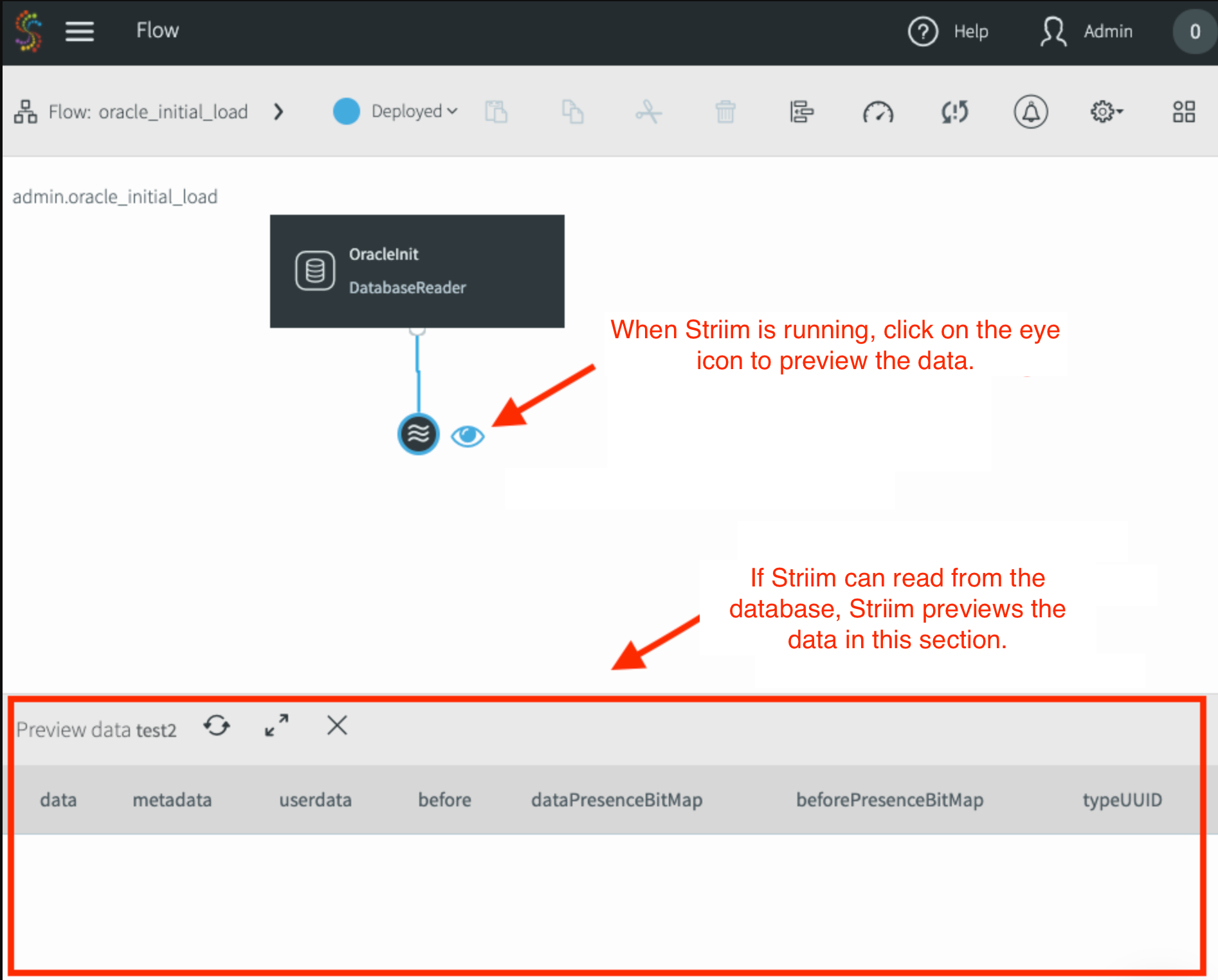
Wählen Sie die Ausgabe dieses Adapters aus und klicken Sie dann auf Vorschau, um die Daten in Echtzeit anzuzeigen, wenn Striim sie aus der Quelle liest.
Klicken Sie auf die Drop-down-Liste Bereitgestellt und dann auf App starten.
Optional: Klicken Sie auf die Drop-down-Liste Bereitgestellt und dann auf Bereitstellung der Anwendung aufheben, um alle Fehler zu beheben.
Optional: Klicken Sie auf Anwendung fortsetzen, nachdem alle Fehler behoben wurden, um die Anwendung neu zu starten.
Klicken Sie auf die Bereitstellungsgruppe Standard.
Prüfen Sie, ob die Option Tabellenzuordnungen validieren aktiviert ist, und klicken Sie dann auf Bereitstellen.
Der Vorschaudatenbereich und der Pipelinestatus ändern sich in Stillgelegt.
An diesem Punkt der Anleitung haben Sie erfolgreich überprüft, ob Striim eine Verbindung zu Ihrer Oracle-Datenbank herstellen und die darin enthaltenen Daten lesen kann.
Cloud SQL for PostgreSQL-Datenbank als Ziel hinzufügen
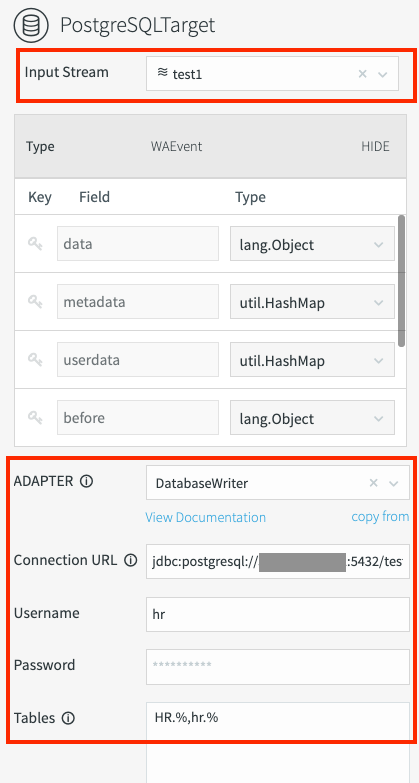
Für diese Migration schreiben Sie Daten in die Cloud SQL for PostgreSQL-Instanz. Striim bietet einen generischen Datenbankautor-Adapter namens Datenbankautor, den Sie für die Migration verwenden können.
- Rufen Sie in Striim Flow Designer Ziele auf und suchen Sie nach Cloud SQL Postgres in der Liste und wählen Sie es aus.
- Ziehen Sie den Datenbankautor in die Pipeline.
Legen Sie die folgenden Attribute fest:
Adapter:
DatabaseWriterConnection URL (Verbindungs-URL): Geben Sie einen eindeutigen String ein, um eine Verbindung zur Cloud SQL-Instanz herzustellen:
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecifiedDabei gilt:
- CLOUD_SQL_IP_ADDRESS: IP-Adresse der Cloud SQL-Instanz
Beispiel:
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedNutzername und Passwort: Geben Sie den zuvor erstellten Cloud SQL-Nutzernamen und das Passwort ein.
Tabellen: Erstellen Sie eine Zuordnung von Ihren Oracle-Datenbanktabellennamen zu Cloud SQL-Tabellennamen. Geben Sie an, welche Oracle-Datenbanktabelle in welche Cloud SQL-Tabelle geschrieben wird. Diese Zuordnung hat das folgende Format:
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAMEDabei gilt:
- CLOUD_SQL_SCHEMA: PostgreSQL-Schemaname
- CLOUD_SQL_TABLE_NAME: PostgreSQL-Tabellenname
Sie können mehrere Tabellen mithilfe des Platzhaltersymbols (%) im Feld Tabellen zuordnen. Beispiel:
HR.%,hr.%Die Pflichtfelder für Datenbankautor sind im folgenden Screenshot markiert:
Migrationspipeline bereitstellen
Wenn die Migrationspipeline bereit ist, stellen Sie sie über Striim Flow Designer bereit und starten Sie die Anwendung. Sie können auch eine Vorschau der Daten, die repliziert werden, in Echtzeit anzeigen. Verwenden Sie Berichte überwachen, um den Fortschritt der Replikation zu verfolgen. Klicken Sie auf das Symbol Anwendungsfortschritt, um den Fortschritt zu verfolgen.
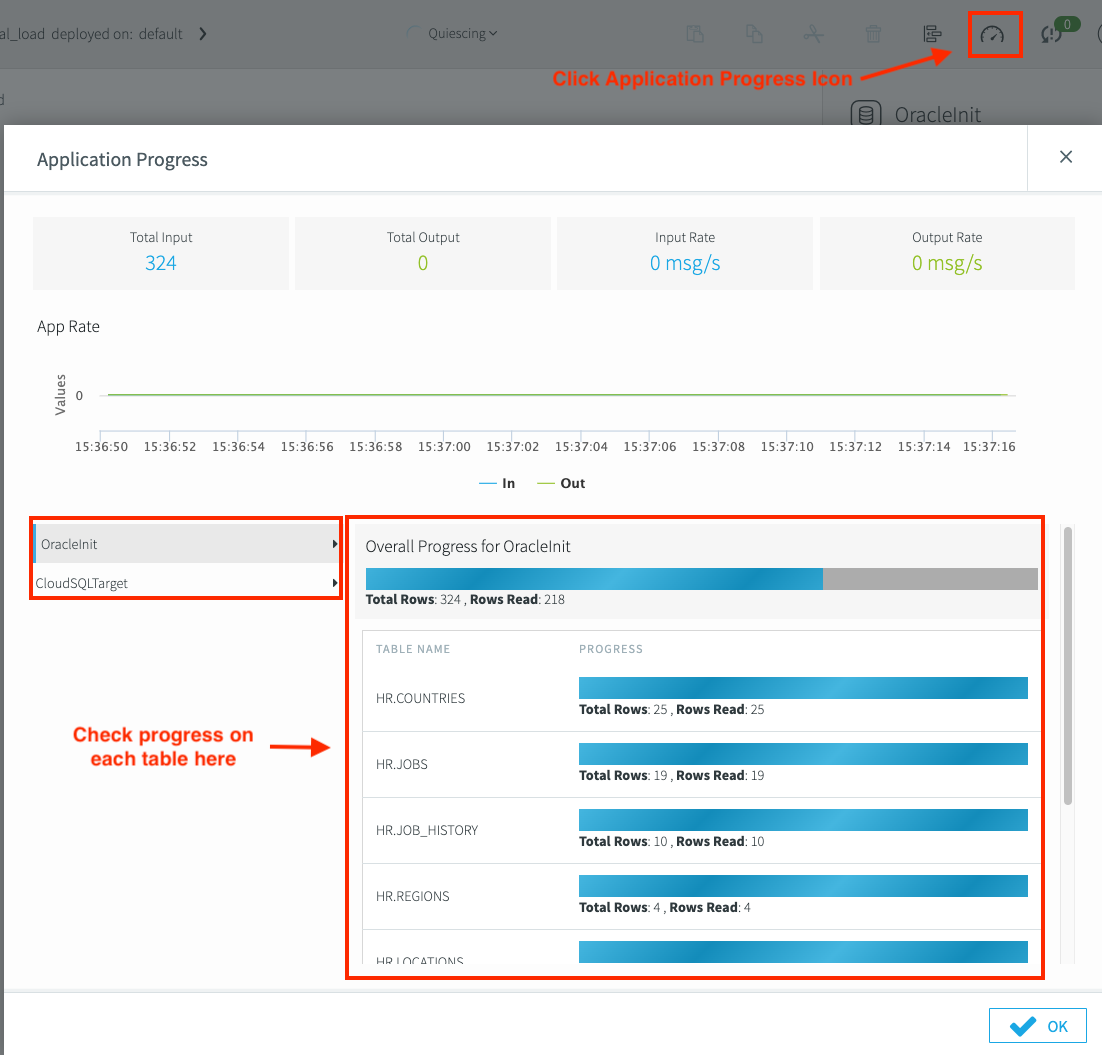
Stellen Sie die Migrationspipeline in Striim Flow Designer bereit. Klicken Sie auf die Drop-down-Liste Erstellt und dann auf Anwendung bereitstellen. Nach Abschluss des anfänglichen Ladevorgangs ändert sich der Pipelinestatus in
Quiesced.Klicken Sie auf Bereitstellung der Anwendung aufheben, um die Bereitstellung rückgängig zu machen.
Überprüfen Sie anhand der Zeilenanzahl, ob das Laden der Daten erfolgreich war:
SELECT COUNT(*) FROM <TARGET CLOUD SQL TABLE>;Die Ausgabe sollte ungleich null sein. Andernfalls ist das Laden der Daten fehlgeschlagen.
Der anfängliche Datenladevorgang von der Oracle-Datenbank zu Cloud SQL for PostgreSQL ist atomar. Entweder ist der gesamte Datenladevorgang erfolgreich oder der gesamte Datenladevorgang schlägt fehl. Wenn der anfängliche Ladevorgang fehlschlägt, müssen Sie die Daten noch einmal laden.
Einschränkungen für Fremdschlüssel in den Cloud SQL for PostgreSQL-Tabellen aktivieren
Aktivieren Sie nach Abschluss des anfänglichen Ladevorgangs die Einschränkungen für Fremdschlüssel für die Zieltabellen. Verwenden Sie die Datei mit Fremdschlüsseldeklarationen (FKEY_output.sql oder converted_foreignkey.sql), die Sie während der Schemakonvertierung erstellt haben.
Erstellen Sie Fremdschlüsseleinschränkungen für die Tabellen:
psql -h HOSTNAME -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -p CLOUD_SQL_PORT -f PATH_TO_FOREIGN_KEY_FILEDabei gilt:
- CLOUD_SQL_USERNAME: Cloud SQL for PostgreSQL-Nutzername
PATH_TO_FOREIGN_KEY_FILE: Pfad zum Skript mit Fremdschlüsseleinschränkungen für die Striim-Instanz
Beispiel:
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
Oracle-Datenbank kontinuierlich in Cloud SQL for PostgreSQL replizieren
Erstellen Sie nach Abschluss des anfänglichen Datenladevorgangs eine separate Pipeline, um Änderungen an der Oracle-Datenbank zu replizieren. Solange diese ausgeführt wird, sorgt diese Pipeline auch für die Synchronisierung der Quelldatenbank mit der Zieldatenbank.
Verbindung zu Oracle von Striim herstellen
Für die kontinuierliche Replikation verwenden Sie den Striim Oracle Leser-Adapter, um eine Verbindung von Striim zur Oracle-Datenbank herzustellen. Dieser Striim-Adapter kann CDC-Daten aus Oracle lesen.
- Gehen Sie im Striim Oracle Leser-Adapter zu Sources (Quellen).
Suchen Sie nach Oracle und wählen Sie Oracle CDC aus der Liste aus, die ausgefüllt wird.
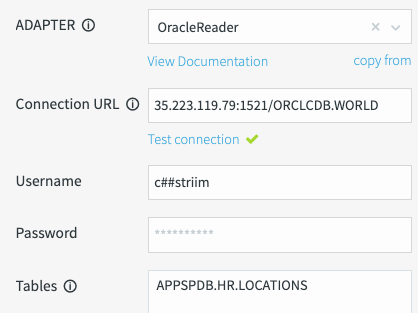
Legen Sie die folgenden Attribute fest:
Verbindungs-URL
HOSTNAME:ORACLE_PORT/SIDOR
HOSTNAME:ORACLE_PORT/CDB_SERVICE_NAMEDabei gilt:
- CDB_SERVICE_NAME: CDB-Dienstname von Oracle
Die Verbindungs-URL ist ein eindeutiger String, mit dem eine Verbindung zur Oracle-Datenbank hergestellt wird. Im Gegensatz zum Datenbank-Leser-Adapter, der für den anfänglichen Ladevorgang verwendet wird, verwenden Sie den CDB-Dienstnamen, unabhängig davon, ob sich Ihre Datenbanktabellen in einer PDB oder CDB befinden.
Beispiel:
12.123.123.12:1521/ORCLCDB.WORLD.Nutzername/Passwort: Verwenden Sie den Oracle-Nutzernamen (
c##striimNutzer), den Sie in den vorher erforderlichen Schritten erstellt haben.Dieser Oracle-Nutzer muss zum Lesen Ihrer Tabellen berechtigt sein.
Tabellen: Zum Replizieren benötigen Sie auch eine Liste von Tabellennamen. Der Name wird im folgenden Format angegeben, je nachdem, ob sich die Tabellen in einer CDB oder PDB befinden.
Für die CDB-Tabelle:
ORACLE_SCHEMA.ORACLE_TABLE_NAMEFür die PDB-Tabelle:
PDB_NAME.ORACLE_SCHEMA.ORACLE_TABLE_NAMEDabei gilt:
- PDB_NAME: Name der Oracle-PDB
Mit diesem Befehl werden Ihre CDB- oder PDB-Tabellen repliziert. Sie finden den
PDB_NAMEin der Dateitnsnames.oraunter$ORACLE_HOME/network/admin/tnsnames.oraauf der Oracle-Instanz.PDB_NAMEundPDB_SERVICE_NAMEsind nicht identisch. Sie haben denPDB_SERVICE_NAMEzuvor im Abschnitt verwendet. Rufen Sie die Dateitnsnames.oraauf, um den PDB-Namen abzurufen:sudo su - oracle // Login as oracle user cat ORACLE_HOME/network/admin/tnsnames.oraDas folgende Beispiel zeigt
PDB_NAME(APPSPDB) in der Dateitnsnames.ora:APPSPDB = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP) (HOST = orainst) (PORT = 1521)) ) (CONNECT_DATA = (SERVICE NAME = APPSPDB.WORLD) ) )Wenn Sie mehrere Tabellen und materialisierte Ansichten als Liste angeben möchten, trennen Sie die Tabellennamen oder Ansichtsnamen durch Semikolons oder Platzhalter. Mindestens eine Tabelle muss dem Platzhalter entsprechen. Andernfalls schlägt der Oracle Leser mit dem Fehler
Could not find tables specified in the databasefehl.Start-SCN: Für die kontinuierliche Pipeline müssen Sie die Oracle-Datenbank-SCN angeben. Striim benötigt sie, um alle Transaktionen zu replizieren. Geben Sie den SCN-Wert ein, den Sie zuvor generiert haben.
Unterstützungs-PDB und -CDB: Sie können eine CDB oder ein PDB verwenden. Maximieren Sie Optionale Attribute anzeigen und stellen Sie den Schieberegler nach rechts.
Stilllegungs-Markierungstabelle: Verwenden Sie den zuvor erstellten Tabellennamen.
Der folgende Screenshot bietet einen Überblick über die Pflichtfelder für den Oracle Leser-Adapter:
Verbindung testen: Klicken Sie auf Verbindung testen. Die Verbindungs-URL, der Nutzername und das Passwort sind erforderlich, um die Datenbankverbindung zu testen. Wenn Striim erfolgreich eine Verbindung herstellen kann, wird ein grünes Häkchen angezeigt.
Testen Sie die Fähigkeit von Striim, die Oracle-Datenbanktabellen zu lesen:
- Wählen Sie im Oracle Leser-Adapter App bereitstellen aus.
- Wählen Sie die Bereitstellungsgruppe Standard aus.
- Klicken Sie auf Deploy.
Klicken Sie auf das Wellensymbol (Ausgabe) für diesen Adapter. Das angezeigte Augensymbol (Vorschau) wird verwendet, um sich die Daten in Echtzeit in der Vorschau anzusehen, während Striim sie aus der Quelle liest.
Klicken Sie im Drop-down-Menü Bereitgestellt auf Anwendung starten.
Sollten Fehler auftreten, wählen Sie im selben Drop-down-Menü die Option Bereitstellung der Anwendung aufheben aus und beheben Sie die Fehler. Klicken Sie nach dem Beheben der Fehler auf Anwendung fortsetzen, um die Anwendung neu zu starten.
Beim Start der Pipeline wird der Pipelinestatus zu Wird ausgeführt aktualisiert. Alle neuen Änderungen an der Quelltabelle werden im Vorschaufenster angezeigt. Da der Oracle Leser-Adapter CDC verwendet, werden im Vorschaudatenbereich nur die Tabellenänderungen angezeigt, die nach dem Start der Anwendung vorgenommen wurden.
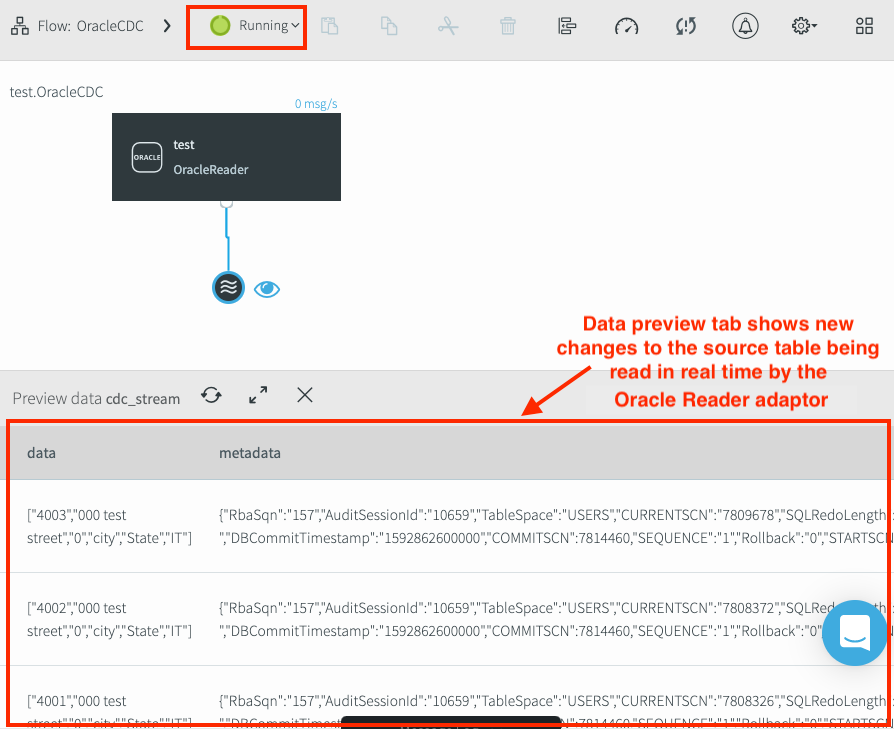
Prüfen, ob CDC-Daten aus Oracle gelesen werden können
So testen Sie, ob der Adapter neue Änderungen lesen kann:
- Verwenden Sie SQL-Anweisungen, um neue Transaktionen in die Oracle-Quelltabellen einzufügen.
- Prüfen Sie, ob die neuen Transaktionen auf dem Tab Vorschaudaten des Oracle Leser-Adapters angezeigt werden.
- Beenden Sie die Anwendung und klicken Sie auf Bereitstellung aufheben. Jetzt können Sie mit dem nächsten Schritt fortfahren.
Bisher haben Sie der Pipeline keinen Zieladapter hinzugefügt. Daten werden nur dann kopiert, wenn Sie einen Zieladapter hinzufügen. Im nächsten Abschnitt fügen Sie einen Zieladapter hinzu.
Cloud SQL for PostgreSQL-Datenbank als Ziel hinzufügen
Um Daten in die Cloud SQL for PostgreSQL-Datenbank zu schreiben, müssen Sie der Pipeline einen Adapter für den Datenbankautor hinzufügen. Für die kontinuierliche Replikationspipeline verwenden Sie denselben Adapter, den Sie in der ursprünglichen Ladepipeline verwendet haben.
- Rufen Sie in Striim Ablauf Designer Ziele auf und suchen Sie nach Cloud SQL Postgres in der Liste und wählen Sie es aus.
- Ziehen Sie den Datenbankautor in die Pipeline.
Legen Sie die folgenden Attribute fest:
Adapter:
DatabaseWriter.Verbindungs-URL: Geben Sie die Verbindungs-URL ein, die Sie eingegeben haben, um eine Verbindung zur Cloud SQL-Instanz herzustellen:
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecifiedBeispiel:
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedNutzername und Passwort: Geben Sie den zuvor erstellten Cloud SQL-Nutzernamen und das Passwort ein.
Tabellen: Erstellen Sie eine Zuordnung von Ihren Oracle-Datenbanktabellennamen zu Cloud SQL-Tabellennamen. Geben Sie an, welche Oracle-Datenbanktabelle in welche Cloud SQL-Tabelle geschrieben wird. Diese Zuordnung hat das folgende Format:
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAMESie können mehrere Tabellen mithilfe des Platzhaltersymbols (%) im Feld Tabellen zuordnen. Beispiel:
HR.%,hr.%Zusätzlich zu diesen Attributen müssen Sie auch die folgenden Attribute für die Kontinuierliche-Replikations-Pipeline festlegen:
Klicken Sie auf Optionale Attribute anzeigen.
Wählen Sie den folgenden Wert für das Feld Ignorable Exception Code (Ignorierbaren Ausnahmecode) aus:
23505,NO_OP_UPDATE,NO_OP_DELETEDa Sie die CDC-Pipeline aus einem Verlaufspunkt starten, sind möglicherweise Duplikate vorhanden. Striim dedupliziert Ihr Ziel mithilfe der vorherigen Attribute, die Sie ignorieren können. Details zu den Ausnahmecodes finden Sie in der folgenden Tabelle:
Ausnahmecode Details 23505Doppelter Primärschlüsselwert verstößt gegen eindeutige Einschränkung NO_OP_UPDATEEine Zeile im Ziel konnte nicht aktualisiert werden (in der Regel, weil es keinen entsprechenden Primärschlüssel gab) NO_OP_DELETEEine Zeile im Ziel konnte nicht gelöscht werden (normalerweise, weil kein entsprechender Primärschlüssel vorhanden war) Geben Sie
chkpointin das Feld Prüfpunkttabelle ein. Striim verwendet diese Tabelle zum Speichern von Metadaten, die mit der Prüfpunktausführung der kontinuierlichen Replikationspipeline verknüpft sind.
Wiederherstellung und Verschlüsselung aktivieren
Bevor Sie die CDC-Pipeline bereitstellen, sollten Sie unbedingt die Wiederherstellung aktivieren. Wenn die Striim-Anwendung oder die VM ausfällt, sorgt die Wiederherstellung dafür, dass Striim die Verarbeitung fortsetzen kann. Mit diesem Schritt wird auch eine genau einmalige Verarbeitungssemantik sichergestellt. Diese Semantik verfolgt den zuletzt als funktionierend bekannten Leseprüfpunkt in der Quelldatenbank und den zuletzt als funktionierend bekannten Schreibprüfpunkt in der Zieldatenbank. Wenn eine Anwendung oder VM fehlschlägt, koordiniert Striim die beiden Prüfpunkte, um sicherzustellen, dass keine Daten verloren gehen oder dupliziert werden. Die Wiederherstellung gilt nicht für anfängliche Ladeanwendungen.
Wiederherstellung aktivieren
- Klicken Sie in Striim Ablauf Designer auf das Symbol Konfiguration und wählen Sie App-Einstellungen aus.
- Klicken Sie auf Wiederherstellungsintervall.
- Geben Sie
5ein und wählen Sie aus der Drop-down-Liste Zweites aus. - Klicken Sie auf Verschlüsselung aktivieren. Striim verschlüsselt alle Streams, die Daten zwischen Striim-Servern oder von einem Weiterleitungs-Agent auf einen Striim-Server verschieben.
Verschlüsselung aktivieren
- Klicken Sie in Striim Ablauf Designer auf das Symbol Konfiguration, wählen Sie App-Einstellungen aus und klicken Sie dann unter Verschlüsselung das Kästchen an.
Weitere Informationen zu den Wiederherstellungsmethoden von Striim finden Sie auf der Striim-Website.
Logging-Ausnahmen aktivieren
Bevor Sie die Pipeline für die kontinuierliche Replikation bereitstellen, wird empfohlen, den Ausnahmespeicher in Striim zu aktivieren. Als Teil der CDC-Anwendung können Duplikate von der anfänglichen Ladeanwendung geschrieben werden. Die Striim-Anwendung ignoriert diese Fehler, schreibt sie in einen Speicher, damit Sie sie überprüfen und verarbeiten können, und fährt mit der Verarbeitung fort.
- Wählen Sie in Striim Flow Designer das Symbol Ausnahmen aus. Das Symbol ist ein Ausrufezeichen zwischen zwei gebogenen Pfeilen.
- Klicken Sie auf Aktivieren.
Stellen Sie die Pipeline bereit.
Wenn die Pipeline bereit ist, können Sie sie bereitstellen und die Anwendung starten. Sie können auch eine Vorschau der Daten anzeigen, während sie in Echtzeit repliziert werden, und Monitoring-Berichte aufrufen. Wenn die Pipeline die kontinuierliche Replikation erfolgreich gestartet hat, ändert sich der Pipelinestatus in Wird ausgeführt.
- Wählen Sie im Oracle Leser-Adapter App bereitstellen aus.
- Wählen Sie die Bereitstellungsgruppe Standard aus.
- Klicken Sie auf Deploy.
Sie können die Pipeline so lange ausführen, wie Sie die Oracle-Tabellen mit den Cloud SQL-Tabellen synchron halten möchten.
Sie haben die Anleitung abgeschlossen. Wenn Sie mehr über andere Oracle-CDC-Quellen erfahren möchten, werden sie im folgenden Abschnitt behandelt.
Oracle-CDC-Quellen abwechseln
Neben LogMiner kann der Adapter von Striim Oracle-Datenbanken aus XStream-Dateien oder Oracle Golden Gate-Traildateien lesen.
Verwenden Sie zum Lesen aus XStream den Oracle Leser-Adapter von Striim. XStream hat möglicherweise eine bessere Leistung, erfordert jedoch eine Golden Gate-Lizenz und wird nur für Oracle Database 11.2.0.4 unterstützt.
Mit dem GG Trail Leser-Adapter von Striim können Sie Golden Gate-Pfad-Dateien lesen.
In der folgenden Tabelle werden die Unterschiede zwischen LogMiner und XStream beschrieben:
CDC-Features der Oracle-Datenbank |
Von LogMiner unterstützt? |
Von XStream Out unterstützt? |
|---|---|---|
Datendefinitionssprache (DDL), ROLLBACK und nicht per Commit festgeschriebene Transaktionen lesen |
Ja | Nein |
DATA()- und BEFORE()-Funktionen verwenden |
Ja | Nein |
QUIESCE verwenden (siehe Konsolenbefehle)
|
Ja | Nein |
| CDC-Ereignisse empfangen | Er empfängt Ereignisse in Batches, wie von der Oracle-Leser-Attribut FetchSize definiert. |
Kontinuierlicher Empfang von Daten-Änderungsereignissen |
| Aus Tabellen lesen, die nicht unterstützte Typen enthalten | Wird Tabelle nicht lesen | Liest Spalten mit unterstützten Typen |
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Lesen Sie die Striim-Dokumentation: Migrationsleitfaden für die Migration von Oracle zu Google Cloud PostgreSQL.
- Schauen Sie sich das Video zur Migration von Oracle-Datenbanken zu Cloud SQL PostgreSQL an.
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.
Oracle, Java und MySQL sind eingetragene Marken von Oracle und/oder seinen Tochtergesellschaften. Andere Namen können Marken der jeweiligen Inhaber sein.