Was ist eine Mikrodienstarchitektur?
Eine Mikrodienstarchitektur (oft als Mikrodienste bezeichnet) bezeichnet einen Architekturstil zur Entwicklung von Anwendungen. Mit Mikrodiensten kann eine große Anwendung in kleinere, unabhängige Elemente mit einem eigenen Zuständigkeitsbereich aufgeteilt werden. Zur Verarbeitung einer einzelnen Nutzeranfrage lässt sich eine auf Mikrodiensten beruhende Anwendung auf vielen internen Mikrodiensten aufrufen.
Container sind ein gutes Beispiel für Mikrodienste. Damit können Sie sich auf die Entwicklung der Dienste konzentrieren, ohne sich Gedanken über die Abhängigkeiten machen zu müssen. Moderne cloudnative Anwendungen werden in der Regel als Mikrodienste mithilfe von Containern erstellt.
Erfahren Sie mehr darüber, wie Sie mit Google Kubernetes Engine Anwendungen auf der Basis von Mikrodiensten durch Verwendung von Containern erstellen können.
Startbereit? Neukunden erhalten ein Guthaben im Wert von 300 $ für Google Cloud.
Definition von Mikrodienstarchitektur
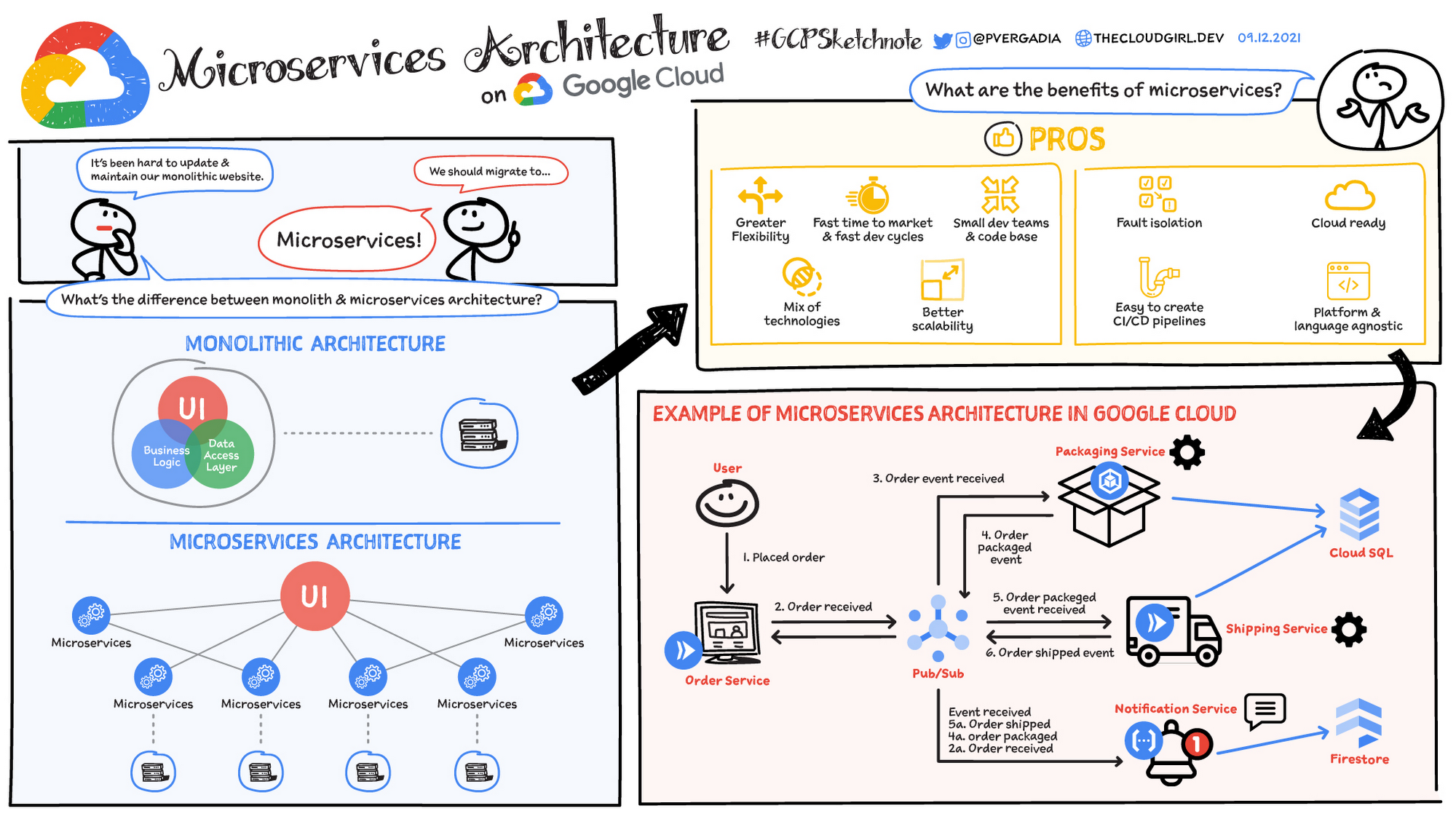
Eine Mikrodienstarchitektur ist eine Art Anwendungsarchitektur, in der die Anwendung als eine Sammlung von Diensten entwickelt wird. Sie bietet das Framework, mit dem Sie Diagramme und Dienste der Mikrodienstarchitektur unabhängig voneinander entwickeln, bereitstellen und verwalten können.
Innerhalb einer Mikrodienstarchitektur ist jeder Mikrodienst ein einzelner Dienst, der für ein Anwendungsfeature und die Verarbeitung diskreter Aufgaben entwickelt wurde. Jeder Mikrodienst kommuniziert über einfache Schnittstellen mit anderen Diensten, um Geschäftsprobleme zu lösen.
Monolithische vs. Mikrodienstarchitektur
Traditionelle monolithische Anwendungen werden als eine einzige, einheitliche Einheit erstellt. Alle Komponenten sind eng miteinander verknüpft und teilen sich Ressourcen und Daten. Das kann zu Herausforderungen bei der Skalierung, Bereitstellung und Wartung der Anwendung führen, insbesondere wenn sie komplexer wird. Im Gegensatz dazu wird eine Anwendung in einer Mikrodienstarchitektur in eine Reihe kleiner, unabhängiger Dienste aufgeteilt. Jeder Mikrodienst ist in sich geschlossen und verfügt über eigenen Code, Daten und Abhängigkeiten. Dieser Ansatz bietet mehrere potenzielle Vorteile:
- Verbesserte Skalierbarkeit: Einzelne Microservices können je nach Bedarf unabhängig voneinander skaliert werden.
- Mehr Agilität: Mikrodienste können unabhängig voneinander entwickelt, bereitgestellt und aktualisiert werden. Dadurch sind schnellere Release-Zyklen möglich.
- Erhöhte Ausfallsicherheit: Wenn ein Microservice ausfällt, ist nicht automatisch die gesamte Anwendung betroffen.
- Technologievielfalt: Die Flexibilität von Mikrodiensten ermöglicht es Teams, die am besten geeignete Technologie für jeden Dienst zu verwenden.
Branchenbeispiele
Viele Unternehmen aus verschiedenen Branchen haben eine Mikrodienstarchitektur eingeführt, um spezifische Geschäftsherausforderungen zu bewältigen und Innovationen voranzutreiben. Hier einige Beispiele:
- E-Commerce: Viele E-Commerce-Plattformen nutzen Microservices, um verschiedene Aspekte ihrer Abläufe zu verwalten, z. B. Produktkatalog, Einkaufswagen, Auftragsabwicklung und Kundenkonten. So können sie einzelne Dienste je nach Bedarf skalieren, die Kundenerfahrung personalisieren und neue Funktionen schnell bereitstellen.
- Streamingdienste: Streamingdienste setzen häufig auf Mikrodienste, um Aufgaben wie Video-Encoding, Inhaltsbereitstellung, Nutzerauthentifizierung und Empfehlungssysteme zu bewältigen. So können sie Millionen von Nutzern gleichzeitig hochwertiges Streaming bieten.
- Finanzdienstleistungen: Finanzinstitute nutzen Microservices, um verschiedene Aspekte ihrer Geschäftstätigkeit zu verwalten, z. B. Betrugserkennung, Zahlungsabwicklung und Risikomanagement. So können sie schnell auf sich ändernde Marktbedingungen reagieren, die Sicherheit verbessern und behördlichen Anforderungen nachkommen.
Wofür wird die Mikrodienstarchitektur verwendet?
In der Regel werden Mikrodienste verwendet, um die Anwendungsentwicklung zu beschleunigen. Häufig werden Mikrodienstarchitekturen mit Java und insbesondere mit Spring Boot erstellt. Mikrodienste lassen sich mit einer dienstorientierten Architektur vergleichen. Beide haben das gleiche Ziel: Monolithische Anwendungen werden in kleinere Komponenten aufgeteilt. Sie verfolgen jedoch unterschiedliche Ansätze. Im Folgenden finden Sie einige Beispiele für Mikrodienstarchitekturen:
Websitemigration
Websitemigration
Eine komplexe Website, die auf einer monolithischen Plattform gehostet wird, kann zu einer cloud- und containerbasierten Mikrodienstplattform migriert werden.
Medieninhalte
Medieninhalte
Mit der Mikrodienstarchitektur können Bilder und Video-Assets in einem skalierbaren Objektspeichersystem gespeichert und direkt im Web oder auf Mobilgeräten bereitgestellt werden.
Transaktionen und Rechnungen
Transaktionen und Rechnungen
Zahlungsabwicklung und Bestellung können als unabhängige Diensteinheiten aufgeteilt werden. Zahlungen werden dann weiterhin akzeptiert, auch wenn die Rechnungsstellung nicht funktioniert.
datenverarbeitung
datenverarbeitung
Eine Mikrodienstplattform kann die Cloud-Unterstützung für vorhandene modulare Datenverarbeitungsdienste erweitern.
Ähnliche Produkte und Dienste
Wenn Sie Google Cloud verwenden, können Sie Mikrodienste ganz einfach mit dem verwalteten Containerdienst Google Kubernetes Engine oder dem vollständig verwalteten serverlosen Angebot Cloud Run bereitstellen.
Je nach Anwendungsfall können Cloud SQL und andere Google Cloud-Produkte und -Dienste problemlos eingebunden werden, um Mikrodienstarchitekturen zu unterstützen.
 Google Kubernetes EngineGesicherter und verwalteter Kubernetes-Dienst mit Vier-Wege-Autoscaling und Multi-Cluster-Unterstützung.
Google Kubernetes EngineGesicherter und verwalteter Kubernetes-Dienst mit Vier-Wege-Autoscaling und Multi-Cluster-Unterstützung. Cloud RunVollständig verwaltete Computing-Plattform zum schnellen und sicheren Bereitstellen und Skalieren von Containeranwendungen.
Cloud RunVollständig verwaltete Computing-Plattform zum schnellen und sicheren Bereitstellen und Skalieren von Containeranwendungen. Cloud SQLVollständig verwalteter Dienst für relationale Datenbanken für MySQL, PostgreSQL und SQL Server.
Cloud SQLVollständig verwalteter Dienst für relationale Datenbanken für MySQL, PostgreSQL und SQL Server. AnthosModernisieren Sie vorhandene Anwendungen und erstellen Sie cloudnative Anwendungen überall, um Agilität und Kosteneinsparungen zu fördern.
AnthosModernisieren Sie vorhandene Anwendungen und erstellen Sie cloudnative Anwendungen überall, um Agilität und Kosteneinsparungen zu fördern.Lösung
Entwicklung cloudnativer AnwendungenSie können cloudnative Anwendungen mit Google Cloud erstellen, ausführen und betreiben. Führen Sie moderne Ansätze wie serverlose Dienste, Mikrodienste und Container ein. Sie können ohne Einbußen bei der Sicherheit oder Qualität programmieren, erstellen, bereitstellen und verwalten.Lösung
Legacy-Anwendungen mit APIs nutzenMit der API-Verwaltungsplattform von Google als Abstraktionsschicht zusätzlich zu bestehenden Diensten können Sie die Nutzungsdauer von Legacy-Anwendungen verlängern, moderne Dienste aufbauen und rasch neue Nutzerumgebungen erstellen.
Gleich loslegen
Profitieren Sie von einem Guthaben über 300 $, um Google Cloud und mehr als 20 „Immer kostenlos“-Produkte kennenzulernen.
Benötigen Sie Hilfe beim Einstieg?
Vertrieb kontaktierenMit einem zertifizierten Partner arbeiten
Partner findenMehr ansehen
Alle Produkte ansehen











