Dieses Dokument im Abschnitt Google Cloud-Architektur-Framework: Zuverlässigkeit enthält Details zu Benachrichtigungen zu SLOs.
Der falsche Ansatz beim Einführen eines neuen Beobachtbarkeitssystems wie einem SLO-System besteht darin, das alte System vollständig durch dieses System zu ersetzen. Stattdessen sollten Sie SLOs als ergänzendes System betrachten. Anstatt dass Sie z. B. die vorhandenen Benachrichtigungen löschen, sollten Sie dafür sorgen, dass diese parallel zu den hier vorgestellten SLO-Benachrichtigungen ausgeführt werden. Mit diesem Ansatz können Sie ermitteln, welche Legacy-Benachrichtigungen darauf hindeuten, dass auch SLO-Benachrichtigungen ausgelöst werden, welche Benachrichtigungen parallel zu den SLO-Benachrichtigungen ausgelöst werden und welche Benachrichtigungen nie ausgelöst werden.
Ein Prinzip des SRE besteht darin, dass Benachrichtigungen auf Grundlage von Symptomen und nicht auf Grundlage von Ursachen ausgelöst werden. Bei SLOs werden immer Symptome gemessen. Wenn Sie zunehmend mehr SLO-Benachrichtigungen integrieren, stellen Sie möglicherweise fest, dass eine Symptombenachrichtigung zusammen mit anderen Benachrichtigungen ausgelöst wird. Wenn Sie feststellen, dass die ursachenbasierten Legacy-Benachrichtigungen ausgelöst werden, ohne dass ein SLO betroffen ist oder Symptome aufgetreten sind, sollten Sie diese vollständig deaktivieren, in Ticketbenachrichtigungen umwandeln oder einfach für später in Logs speichern.
Weitere Informationen finden Sie im SRE-Workbook, Kapitel 5.
SLO-Brennrate
Der Durchsatz eines SLO ist ein Messwert dafür, wie schnell es bei einem Ausfall für Nutzer zu Fehlern kommt und das Fehlerbudget aufgebraucht ist. Durch das Messen des Durchsatzes können Sie die Zeit ermitteln, bis ein Dienst gegen sein SLO verstößt. Das Einrichten von Benachrichtigungen auf Basis des SLO-Durchsatzes ist ein guter Ansatz. Denken Sie daran, dass der SLO auf einer Zeitdauer basiert, die ziemlich lang sein kann (Wochen oder sogar Monate). Das Ziel besteht jedoch darin, schnell eine Bedingung zu ermitteln, die zu einem SLO-Verstoß führt, bevor dieser Verstoß tatsächlich auftritt.
Die folgende Tabelle zeigt die Zeitdauer, die zum Überschreiten eines Ziels erforderlich ist, wenn 100 % der Anfragen für das angegebene Intervall fehlschlagen, vorausgesetzt, die Abfragen pro Sekunde (Queries Per Second, QPS) sind konstant. Wenn Sie beispielsweise ein 99,9 %-SLO haben, das für einen Zeitraum von 30 Tagen gemessen wurde, ist während dieser 30 Tage eine Zeit von 43,2 Minuten tolerierbar, in denen ein vollständiger Ausfall vorlag. Diese Ausfallzeit kann beispielsweise auf einmal oder auf mehrere Vorfälle verteilt auftreten.
| Ziel | 90 Tage | 30 Tage | 7 Tage | 1 Tag |
|---|---|---|---|---|
| 90 % | 9 Tage | 3 Tage | 16,8 Stunden | 2,4 Stunden |
| 99 % | 21,6 Stunden | 7,2 Stunden | 1,7 Stunden | 14,4 Minuten |
| 99,9 % | 2,2 Stunden | 43,2 Minuten | 10,1 Minuten | 1,4 Minuten |
| 99,99 % | 13 Minuten | 4,3 Minuten | 1 Minute | 8,6 Sekunden |
| 99,99 % | 1,3 Minuten | 25,9 Sekunden | 6 Sekunden | 0,9 Sekunden |
In der Praxis können Sie sich keine Vorfälle mit einem 100 %-Ausfall leisten, wenn Sie hohe Erfolgsquoten erreichen möchten. Viele verteilte Systeme können jedoch teilweise ausfallen oder ihre Leistung schrittweise herabsetzen. Auch in diesen Fällen möchten Sie wissen, ob ein Mensch eingreifen muss, selbst bei Teilausfällen. Mit SLO-Benachrichtigungen können Sie dies feststellen.
Zeitpunkt der Benachrichtigung
Eine wichtige Frage ist, wann anhand des SLO-Durchsatzes gehandelt werden sollte. Wenn das Fehlerbudget in 24 Stunden aufgebraucht sein wird, sollten Sie in der Regel jetzt jemanden zur Fehlerbehebung kontaktieren.
Das Messen der Fehlerrate ist nicht immer einfach. Eine Reihe kleinerer Fehler kann im Moment beunruhigend wirken, sich jedoch als kurzlebig erweisen und sich dann kaum auf das SLO auswirken. Wenn ein System dagegen über einen längeren Zeitraum leicht fehlerhaft ist, können diese Fehler in Summe zu einem SLO-Verstoß führen.
Im Idealfall reagiert Ihr Team so auf diese Signale, dass Sie in einem bestimmten Zeitraum fast das gesamte Fehlerbudget ausschöpfen, aber es nicht überschreiten. Wenn Sie das Budget überschreiten, verstoßen Sie gegen das SLO. Wenn zu wenige Fehler auftreten, gehen Sie nicht genug Risiken ein oder brennen möglicherweise Ihr Bereitschaftsteam aus.
Sie müssen eine Möglichkeit finden, um festzustellen, wann ein System so fehlerhaft ist, dass ein Mensch eingreifen sollte. In den folgenden Abschnitten werden einige Ansätze zum Beantworten dieser Frage erläutert.
Schneller Durchsatz
Eine Art des SLO-Durchsatzes ist der schnelle SLO-Durchsatz, da das Fehlerbudget schnell ausgeschöpft wird und Sie einschreiten müssen, um einen SLO-Verstoß zu vermeiden.
Angenommen, Ihr Dienst verarbeitet normalerweise 1.000 QPS und Sie möchten eine Verfügbarkeit von 99 % aufrechterhalten, die für einen Zeitraum von einer Woche gemessen wird. Ihr Fehlerbudget beträgt etwa 6 Millionen zulässige Fehler bei etwa 600 Millionen Anfragen. Wenn Sie beispielsweise noch 24 Stunden Zeit haben, bevor das Fehlerbudget aufgebraucht ist, liegt das Fehlermaximum bei etwa 70 Fehlern pro Sekunde oder 252.000 Fehlern pro Stunde. Diese Parameter basieren auf der allgemeinen Regel, dass auf Seiten aufteilbare Vorfälle mindestens 1 % des vierteljährlichen Fehlerbudgets aufbrauchen sollten.
Sie können diese Fehlerrate vor Ablauf der Stunde ermitteln. Wenn Sie beispielsweise 15 Minuten lang eine Rate von 70 Fehlern pro Sekunde beobachtet haben, können Sie den Bereitschaftsentwickler anrufen, wie das folgende Diagramm zeigt.
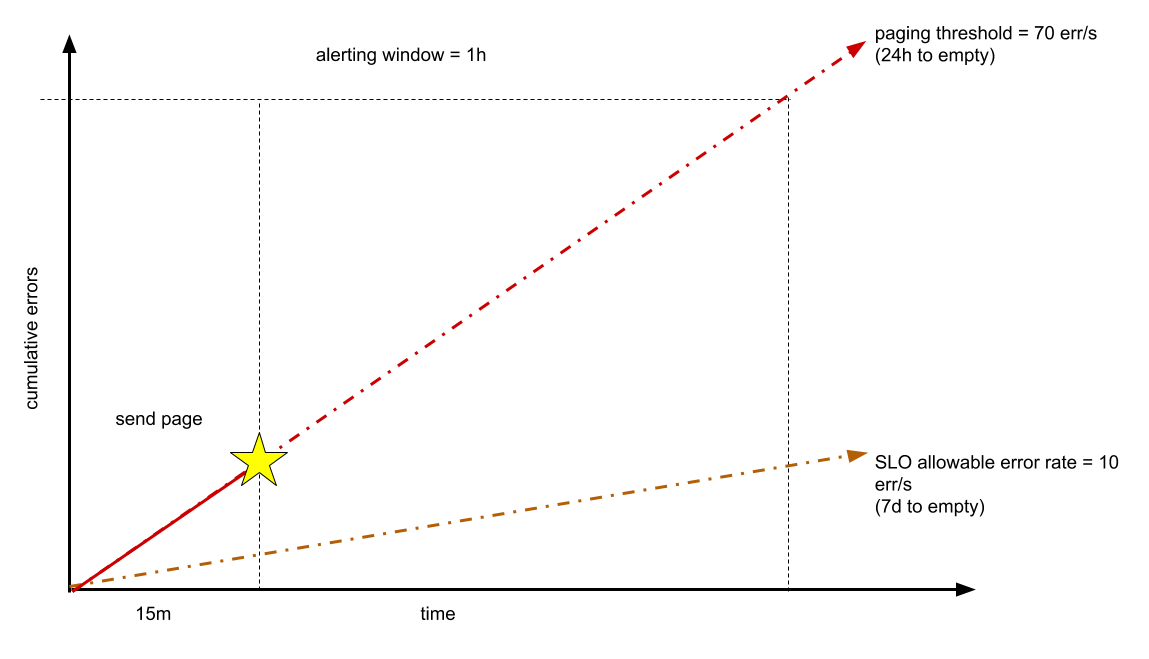
Im Idealfall wird das Problem gelöst, bevor eine Stunde der verbleibenden 24 Stunden vergangen ist. Wenn Sie diese Rate für ein kürzeres Zeitfenster (z. B. eine Minute) ermitteln möchten, kommt es wahrscheinlich zu einer zu großen Fehlerzahl. Wenn die Zielzeit für die Erkennung weniger als 15 Minuten beträgt, kann dieser Wert angepasst werden.
Langsames Brennen
Eine weitere Art des Durchsatzes ist ein langsamer Durchsatz. Nehmen Sie an, Sie führen einen Programmfehler ein, infolgedessen Ihr wöchentliches Fehlerbudget am fünften oder sechsten Tag oder das Monatsbudget nach der zweiten Woche aufgebraucht ist. Wie gehen Sie am besten damit um?
In diesem Fall können Sie eine Benachrichtigung zum langsamen SLO-Durchsatz einrichten, die Sie darüber informiert, dass Sie nach derzeitigem Stand das gesamte Fehlerbudget vor Ende des Benachrichtigungsfensters ausgeschöpft haben werden. Natürlich kann sich diese Warnung im Nachhinein oftmals als falsch erweisen. Es kann beispielsweise oft vorkommen, dass Fehler nur kurz auftreten, aber mit einer Rate, die das Fehlerbudget schnell ausschöpfen würde. In diesen Fällen wurde die Benachrichtigung zu Unrecht ausgelöst, da die Fehler nur für kurze Zeit aufgetreten sind und keine langfristige Gefahr besteht, dass das Fehlerbudget ausgeschöpft wird. Denken Sie daran, dass das Ziel nicht darin besteht, alle Fehlerquellen zu beseitigen, sondern sich innerhalb des zulässigen Bereichs zu bewegen, um das Fehlerbudget nicht zu überschreiten. Sie sollten vermeiden, dass ein Mitarbeiter per Benachrichtigung zum Eingreifen aufgefordert wird, wenn das entsprechende Ereignis gar nicht dazu führen wird, dass das Fehlerbudget ausgeschöpft wird.
Wir empfehlen Ihnen, bei Ereignisse mit langsamem Durchsatz eine Ticketwarteschlange zu benachrichtigen, anstatt den Mitarbeiter auszurufen, ihn anzupiepsen oder ihn per E-Mail zu benachrichtigen. Ereignisse mit langsamem Durchsatz sind keine Notfälle, erfordern aber dennoch die Aufmerksamkeit eines Mitarbeiters, bevor das Budget abläuft. Diese Warnungen sollten nicht per E-Mail an einen Teamverteiler geschickt werden, da solche E-Mails schnell ignoriert werden können. Tickets sollten nachverfolgbar, zuweisbar und übertragbar sein. Teams sollten Berichte zu Ticketbelastung, Erledigungsraten, Bearbeitbarkeit und Duplikatanteil erstellen. Übermäßig viele Tickets, aus denen sich keine Handlungen ableiten lassen, sind ein gutes Beispiel für mühevolle Arbeit.
Die gezielte Verwendung von SLO-Benachrichtigungen kann Zeit in Anspruch nehmen und hängt von der Kultur und den Erwartungen Ihres Teams ab. Vergessen Sie nicht, dass Sie die SLO-Benachrichtigungen auch im Laufe der Zeit optimieren können. Sie können je nach Bedarf auch mehrere Benachrichtigungsmethoden mit unterschiedlichen Benachrichtigungsfenstern verwenden.
Latenzbenachrichtigungen
Zusätzlich zu Verfügbarkeitsbenachrichtigungen können Sie auch Latenzbenachrichtigungen einrichten. Mit Latenz-SLOs messen Sie den Prozentsatz der Anfragen, für die ein Latenzziel nicht erreicht wird. Wenn Sie dieses Modell verwenden, können Sie dasselbe Benachrichtigungsmodell verwenden, mit dem Sie auch schnelle oder langsame Durchsätze in Bezug auf Ihr Fehlerbudget ermitteln.
Wie bereits erwähnt, kann bei SLOs mit Medianlatenz die Hälfte der Anfragen außerhalb des SLO liegen. Es kann also sein, dass Ihre Nutzer tagelang mit einer hohen Latenz zu kämpfen haben, bevor Sie deren Auswirkung auf Ihr langfristiges Fehlerbudget feststellen. Stattdessen sollten für Dienste Extremwertlatenzziele und typische Latenzziele definiert werden. Wir empfehlen, das historische 90. Perzentil zu verwenden, um die typische Latenz zu definieren, und das 99. Perzentil, um die Extremwertlatenz zu definieren. Nachdem Sie diese Ziele festgelegt haben, können Sie die SLOs basierend auf der Anzahl der Anfragen definieren, die laut Ihren Erwartungen in der jeweiligen Latenzkategorie landen und wie viele zu langsam sein werden. Dieser Ansatz entspricht dem Konzept eines Fehlerbudgets und sollte genauso behandelt werden. Ihre Aussage könnte also so lauten: "Bei 90 % der Anfragen wird die Verarbeitung innerhalb der typischen Latenzziele stattfinden und bei 99,9 % innerhalb der Ziele der Extremwertlatenz." Mit diesen Zielen sorgen Sie dafür, dass bei den meisten Nutzern die typische Latenz auftritt und können trotzdem nachverfolgen, wie viele Anfragen langsamer sind als es in den Extremwertlatenzzielen festgelegt ist.
Bei einigen Diensten variieren die erwarteten Laufzeiten möglicherweise stark. So kann es beispielsweise vorkommen, dass Sie beim Lesen aus einem Datenspeichersystem deutlich andere Leistungserwartungen als beim Schreiben in das Datenspeichersystem haben. Anstatt alle möglichen Erwartungen aufzuzählen, können Sie Laufzeitleistungs-Buckets einführen, wie in den folgenden Tabellen gezeigt. Bei diesem Ansatz wird davon ausgegangen, dass diese Anfragetypen identifizierbar sind und dem jeweiligen Bucket durch Vorkategorisieren zugeordnet wurden. Sie sollten nicht davon ausgehen, Anfragen dynamisch kategorisieren zu können.
| Für den Nutzer sichtbare Website | |
|---|---|
| Bucket | Erwartete maximale Laufzeit |
| Lesen | 1 Sekunde |
| Schreiben/Aktualisieren | 3 Sekunden |
| Datenverarbeitungssysteme | |
|---|---|
| Bucket | Erwartete maximale Laufzeit |
| Klein | 10 Sekunden |
| Mittel | 1 Minute |
| Groß | 5 Minuten |
| Riesig | 1 Stunde |
| Riesengroß | 8 Stunden |
Indem Sie das aktuelle System messen, können Sie ermitteln, wie lange die Ausführung dieser Anfragen normalerweise dauert. Betrachten Sie als Beispiel ein System zum Verarbeiten von Videouploads. Wenn das Video sehr lang ist, sollte davon ausgegangen werden, dass die Verarbeitung länger dauert. Wir können die Länge des Videos in Sekunden verwenden, um diese Arbeit in einem Bucket zu kategorisieren, wie die folgende Tabelle zeigt. In der Tabelle werden die Anzahl der Anfragen pro Bucket sowie verschiedene Perzentile für die Laufzeitverteilung im Laufe einer Woche aufgezeichnet.
| Videolänge | Anzahl der in einer Woche gemessenen Anfragen | 10 % | 90 % | 99,95 % |
|---|---|---|---|---|
| Klein | 0 | - | – | - |
| Mittel | 1,9 Millionen | 864 Millisekunden | 17 Sekunden | 86 Sekunden |
| Groß | 25 Millionen | 1,8 Sekunden | 52 Sekunden | 9,6 Minuten |
| Riesig | 4,3 Millionen | 2 Sekunden | 43 Sekunden | 23,8 Minuten |
| Riesengroß | 81.000 | 36 Sekunden | 1,2 Minuten | 41 Minuten |
Aus einer solchen Analyse können Sie einige Parameter für Benachrichtigungen ableiten:
- fast_typical: Höchstens 10 % der Anfragen sind schneller als dieser Zeitwert. Wenn zu viele Anfragen schneller als dieser Zeitwert sind, sind Ihre Ziele möglicherweise inkorrekt oder es hat sich vielleicht etwas an Ihrem System geändert.
- slow_typical: Mindestens 90 % der Anfragen sind schneller als dieser Zeitwert. Durch dieses Limit wird Ihr Hauptlatenz-SLO bestimmt. Dieser Parameter gibt an, ob die meisten Anfragen schnell genug sind.
- slow_tail: Mindestens 99,95 % der Anfragen sind schneller als dieser Zeitwert. Mit diesem Limit wird sichergestellt, dass nicht zu viele langsame Anfragen vorhanden sind.
- deadline: Zeitpunkt, an dem ein Nutzer-RPC oder die Hintergrundverarbeitung das Zeitlimit überschreitet und fehlschlägt. Dieses Limit ist in der Regel bereits im System hartcodiert. Diese Anfragen sind nicht langsam, sondern schlagen mit einem Fehler fehl und werden stattdessen auf Ihr Verfügbarkeits-SLO angerechnet.
Eine Richtlinie beim Definieren von Buckets besteht darin, die Kategorien fast_typical, slow_typical und slow_tail eines Buckets in eine Größenordnung zueinander zu zwingen. Mit dieser Richtlinie wird sichergestellt, dass der Bucket nicht zu umfassend ist. Wir empfehlen, dass Sie nicht versuchen, Überschneidungen oder Lücken zwischen den Buckets zu vermeiden.
| Bucket | fast_typical | slow_typical | slow_tail | deadline |
|---|---|---|---|---|
| Klein | 100 Millisekunden | 1 Sekunde | 10 Sekunden | 30 Sekunden |
| Mittel | 600 Millisekunden | 6 Sekunden | 60 Sekunden (1 Minute) | 300 Sekunden |
| Groß | 3 Sekunden | 30 Sekunden | 300 Sekunden (5 Minuten) | 10 Minuten |
| Riesig | 30 Sekunden | 6 Minuten | 60 Minuten (1 Stunde) | 3 Stunden |
| Riesengroß | 5 Minuten | 50 Minuten | 500 Minuten (8 Stunden) | 12 Stunden |
Dies führt zu einer Regel wie api.method: SMALL => [1s, 10s].
In diesem Fall würde das SLO-Tracking-System eine Anfrage registrieren, den passenden Bucket ermitteln (möglicherweise durch Analysieren des Methodennamens oder URIs und Vergleichen des Namens mit einer Suchtabelle) und dann die Statistik anhand der Laufzeit dieser Anfrage aktualisieren. Wenn dies 700 Millisekunden gedauert hat, liegt die Anfrage innerhalb des Ziels slow_typical. Wenn es 3 Sekunden dauerte, liegt sie innerhalb von slow_tail. Wenn es 22 Sekunden dauerte, fällt sie nicht mehr in slow_tail, zählt jedoch noch nicht als Fehler.
Im Hinblick auf die Zufriedenheit der Nutzer können Sie sich Anfragen, deren Antwort die Extremwertlatenz überschreitet, so vorstellen, als wäre die Verfügbarkeit nicht gegeben. Die Antwort ist also so langsam, dass sie als "fehlgeschlagen" angesehen werden sollte. Aus diesem Grund empfehlen wir, denselben Prozentsatz wie für die Verfügbarkeit zu verwenden. Beispiel:
Was Sie als typische Latenz betrachten, liegt ganz bei Ihnen. Einige Teams bei Google halten 90 % für ein gutes Ziel. Dies hängt mit Ihrer Analyse und der Auswahl der Dauerwerte für slow_typical zusammen. Beispiel:
Vorgeschlagene Benachrichtigungen
Im Sinne dieser Richtlinien enthält die folgende Tabelle einen Vorschlag für einen grundlegenden Satz von SLO-Benachrichtigungen.
| SLOs | Messfenster | Durchsatz | Aktion |
|---|---|---|---|
|
Verfügbarkeit, schneller Durchsatz Typische Latenz Extremwertlatenz |
Zeitfenster von einer Stunde | Weniger als 24 Stunden bis zum SLO-Verstoß | Jemanden ausrufen oder anpiepsen |
|
Verfügbarkeit, langsamer Durchsatz Typische Latenz, langsamer Durchsatz Extremwertlatenz, langsamer Durchsatz |
Fenster von sieben Tagen | Mehr als 24 Stunden bis zum SLO-Verstoß | Ein Ticket erstellen |
Das Entwickeln von SLO-Benachrichtigungen kann einige Zeit in Anspruch nehmen. Die Dauerwerte in diesem Abschnitt sind Vorschläge. Sie können diese gemäß Ihrer eigenen Bedürfnisse und Genauigkeitslevels anpassen. Es kann hilfreich sein, die Benachrichtigungen mit dem Messfenster oder dem Ausschöpfungsgrad des Fehlerbudgets zu verknüpfen. Sie können alternativ auch eine weitere Benachrichtigungsebene zwischen dem schnellen Durchsatz und dem langsamen Durchsatz hinzufügen.