Diese Dataflow-Pipeline verwendet Schutz sensibler Daten, um sensible Daten, wie personenidentifizierbare Informationen (PII), zu erkennen und die Ergebnisse dann in Data Catalog zu taggen.
Die in diesem Dokument beschriebene Lösung baut auf der Architektur der dateibasierten Tokenisierungslösung auf, die im Begleitdokument Vertrauliche dateibasierte Daten mit Schutz sensibler Daten, Cloud Key Management Service und Dataflow automatisch tokenisieren beschrieben wird. Der Hauptunterschied zwischen den beiden Dokumenten besteht darin, dass in diesem Dokument eine Lösung beschrieben wird, die auch einen Data Catalog-Eintrag mit einem Schema der Quell- und Datenvertraulichkeits-Tags für Ergebnisse vom Schutz sensibler Daten erstellt. Außerdem können Sie relationale Datenbanken mit Java Database Connectivity (JDBC) prüfen.
Dieses Dokument richtet sich an eine technische Zielgruppe, deren Aufgaben in den Bereichen Datensicherheit, Data Governance, Datenverarbeitung oder Datenanalyse liegen. In diesem Dokument wird davon ausgegangen, dass Sie mit Datenverarbeitung und Datenschutz vertraut sind, ohne Experte darin zu sein. Außerdem werden gewisse Kenntnisse zu Shell-Skripts und Grundkenntnissen in Google Cloud vorausgesetzt.
Architektur
Diese Architektur definiert eine Pipeline, die die folgenden Aktionen ausführt:
- Sie extrahiert mit JDBC die Daten aus einer relationalen Datenbank.
- Sie erstellt Stichproben der Datensätze mit der
LIMIT-Klausel der Datenbank. - Sie verarbeitet Datensätze über die Cloud Data Loss Prevention API (Teil von Schutz sensibler Daten), um Vertraulichkeitskategorien zu identifizieren.
- Sie speichert die Ergebnisse in einer BigQuery-Tabelle und in Data Catalog.
Das folgende Diagramm zeigt die Aktionen, die die Pipeline ausführt:

Die Lösung verwendet JDBC-Verbindungen, um auf relationale Datenbanken zuzugreifen. Wenn Sie BigQuery-Tabellen als Datenquelle verwenden, nutzt die Lösung die BigQuery Storage API, um die Ladezeiten zu verbessern.
Die Pipeline für Stichprobenerstellung und Identifizierung gibt die folgenden Dateien an Cloud Storage aus:
- Avro-Schema (äquivalent) des Schemas der Quelle
- Erkannte
infoTypes-Daten für jede Eingabespalte (PERSON_NAME,PHONE_NUMBERundSTREET_ADDRESS)
Diese Lösung verwendet die Datensatzvereinfachung, um verschachtelte und wiederkehrende Felder in Datensätzen zu verarbeiten.
Ziele
- Data Catalog-Tags und Entitätengruppe erstellen
- Stichproben- und Identifizierungspipeline bereitstellen
- Benutzerdefinierte Data Catalog-Entität erstellen
- Vertraulichkeits-Tags auf benutzerdefinierte Data Catalog-Entität anwenden
- Prüfen, ob sich die Datenvertraulichkeits-Tags auch in BigQuery befinden
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Cloud Build, DLP API, Cloud SQL, Cloud Storage, Compute Engine, Dataflow, Data Catalog, and Secret Manager APIs aktivieren.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Cloud Build, DLP API, Cloud SQL, Cloud Storage, Compute Engine, Dataflow, Data Catalog, and Secret Manager APIs aktivieren.
-
Aktivieren Sie Cloud Shell in der Google Cloud Console.
Unten in der Google Cloud Console wird eine Cloud Shell-Sitzung gestartet und eine Eingabeaufforderung angezeigt. Cloud Shell ist eine Shell-Umgebung, in der das Google Cloud CLI bereits installiert ist und Werte für Ihr aktuelles Projekt bereits festgelegt sind. Das Initialisieren der Sitzung kann einige Sekunden dauern.
Umgebung einrichten
Klonen Sie in Cloud Shell das Quell-Repository und wechseln Sie in das Verzeichnis für die geklonten Dateien:
git clone https://github.com/GoogleCloudPlatform/auto-data-tokenize.git cd auto-data-tokenize/Verwenden Sie einen Texteditor, um das Skript
set_variables.shzu ändern, um die erforderlichen Umgebungsvariablen festzulegen. Ignorieren Sie die anderen Variablen im Skript. Sie sind in diesem Dokument nicht relevant.# The Google Cloud project to use: export PROJECT_ID="PROJECT_ID" # The Compute Engine region to use for running dataflow jobs and create a # temporary storage bucket: export REGION_ID= "REGION_ID" # The Cloud Storage bucket to use as a temporary bucket for Dataflow: export TEMP_GCS_BUCKET="CLOUD_STORAGE_BUCKET_NAME" # Name of the service account to use (not the email address) # (For example, tokenizing-runner): export DLP_RUNNER_SERVICE_ACCOUNT_NAME="DLP_RUNNER_SERVICE_ACCOUNT_NAME" # Entry Group ID to use for creating/searching for Entries # in Data Catalog for non-BigQuery entries. # The ID must begin with a letter or underscore, contain only English # letters, numbers and underscores, and have 64 characters or fewer. export DATA_CATALOG_ENTRY_GROUP_ID="DATA_CATALOG_ENTRY_GROUP_ID" # The Data Catalog Tag Template ID to use # for creating sensitivity tags in Data Catalog. # The ID must contain only lowercase letters (a-z), numbers (0-9), or # underscores (_), and must start with a letter or underscore. # The maximum size is 64 bytes when encoded in UTF-8 export INSPECTION_TAG_TEMPLATE_ID="INSPECTION_TAG_TEMPLATE_ID"
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Projekt-ID.
- REGION_ID: Die Region mit Ihren Storage-Buckets. Wählen Sie einen Standort aus, der sich in einer Data Catalog-Region befindet.
- CLOUD_STORAGE_BUCKET_NAME: Der Name Ihres Storage-Buckets.
- DLP_RUNNER_SERVICE_ACCOUNT_NAME: Der Name Ihres Dienstkontos.
- DATA_CATALOG_ENTRY_GROUP_ID: Der Name der Nicht-BigQuery-Datenkatalog-Eintragsgruppe.
- INSPECTION_TAG_TEMPLATE_ID: Der Name, den Sie Ihrer Tag-Vorlage für Data Catalog gegeben haben.
Führen Sie das Skript aus, um die Umgebungsvariablen festzulegen:
source set_variables.sh
Ressourcen erstellen
Die in diesem Dokument beschriebene Architektur verwendet die folgenden Ressourcen:
- Ein Dienstkonto zum Ausführen von Dataflow-Pipelines, die eine differenzierte Zugriffssteuerung ermöglichen
- Ein Cloud Storage-Bucket zum Speichern von temporären Daten und Testdaten
- Eine Data Catalog-Tag-Vorlage, um Vertraulichkeits-Tags an Einträge anzuhängen
- Eine MySQL on Cloud SQL-Instanz als JDBC-Quelle
Dienstkonten erstellen
Wir empfehlen Ihnen, Pipelines mit einer detaillierten Zugriffssteuerung auszuführen, um die Zugriffspartitionierung zu verbessern. Wenn Ihr Projekt kein vom Nutzer erstelltes Dienstkonto hat, erstellen Sie eines.
Erstellen Sie in Cloud Shell ein Dienstkonto, das als nutzerverwaltetes Controller-Dienstkonto für Dataflow verwendet wird:
gcloud iam service-accounts create ${DLP_RUNNER_SERVICE_ACCOUNT_NAME} \ --project="${PROJECT_ID}" \ --description="Service Account for Sampling and Cataloging pipelines." \ --display-name="Sampling and Cataloging pipelines"Erstellen Sie eine benutzerdefinierte Rolle mit den erforderlichen Berechtigungen für den Zugriff auf den Schutz sensibler Daten, Dataflow, Cloud SQL und Data Catalog:
export SAMPLING_CATALOGING_ROLE_NAME="sampling_cataloging_runner" gcloud iam roles create ${SAMPLING_CATALOGING_ROLE_NAME} \ --project="${PROJECT_ID}" \ --file=tokenizing_runner_permissions.yamlWenden Sie die benutzerdefinierte Rolle und die Dataflow-Worker-Rolle auf das Dienstkonto an, damit es als Dataflow-Worker ausgeführt werden kann:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${DLP_RUNNER_SERVICE_ACCOUNT_EMAIL}" \ --role=projects/${PROJECT_ID}/roles/${SAMPLING_CATALOGING_ROLE_NAME} gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${DLP_RUNNER_SERVICE_ACCOUNT_EMAIL}" \ --role=roles/dataflow.worker
Cloud Storage-Bucket erstellen
Erstellen Sie in Cloud Shell einen Cloud Storage-Bucket zum Speichern von Testdaten sowie als Dataflow-Staging-Speicherort:
gsutil mb -p ${PROJECT_ID} -l ${REGION_ID} "gs://${TEMP_GCS_BUCKET}"
Data Catalog-Eintragsgruppe erstellen
Data Catalog verwaltet eine Liste von Einträgen, die Google Cloud-Ressourcen oder andere Ressourcen repräsentieren. Die Einträge sind in Eintragsgruppen organisiert. Für BigQuery ist eine implizite Eintragsgruppe vorhanden (@bigquery). Eintragsgruppen für andere Ressourcentypen müssen erstellt werden. Weitere Informationen zu Data Catalog-Einträgen finden Sie unter Dateien aus Cloud Storage mit Dateisatzeinträgen anzeigen.
In Data Catalog ist eine Eintragsgruppe wie ein Ordner, der Einträge enthält. Ein Eintrag stellt ein Daten-Asset dar.
Erstellen Sie in Cloud Shell eine neue Eintragsgruppe, in der die Pipeline einen Eintrag für Ihre MySQL-Tabelle hinzufügen kann:
gcloud data-catalog entry-groups create \ "${DATA_CATALOG_ENTRY_GROUP_ID}" \ --project="${PROJECT_ID}" \ --location="${REGION_ID}"
Prüfungs-Tag-Vorlage erstellen
Erstellen Sie in Cloud Shell eine Data Catalog-Tag-Vorlage, damit Einträge über den Schutz sensibler Daten mit vertraulichen Informationen getaggt werden können:
gcloud data-catalog tag-templates create ${INSPECTION_TAG_TEMPLATE_ID} \ --project="${PROJECT_ID}" \ --location="${REGION_ID}" \ --display-name="Auto DLP sensitive categories" \ --field=id=infoTypes,type=string,display-name="DLP infoTypes",required=TRUE \ --field=id=inspectTimestamp,type=timestamp,display-name="Inspection run timestamp",required=TRUE
Prüfungssergebnistabelle in BigQuery erstellen
Erstellen Sie in Cloud Shell eine BigQuery-Tabelle, um aggregierte Ergebnisse zum Schutz sensibler Daten zu speichern:
bq mk --dataset \ --location="${REGION_ID}" \ --project_id="${PROJECT_ID}" \ inspection_results bq mk --table \ --project_id="${PROJECT_ID}" \ inspection_results.SensitivityInspectionResults \ inspection_results_bigquery_schema.json
MySQL on Cloud SQL-Instanz einrichten
Für die Datenquelle verwenden Sie eine Cloud SQL-Instanz.
Instanziieren Sie in Cloud Shell eine MySQL on Cloud SQL-Instanz und laden Sie sie mit Beispieldaten:
export SQL_INSTANCE="mysql-autodlp-instance" export SQL_ROOT_PASSWORD="root1234" gcloud sql instances create "${SQL_INSTANCE}" \ --project="${PROJECT_ID}" \ --region="${REGION_ID}" \ --database-version=MYSQL_5_7 \ --root-password="${SQL_ROOT_PASSWORD}"Speichern Sie das Datenbankpasswort in Secret Manager.
Das Datenbankpasswort und andere Secret-Informationen sollten nicht anderweitig gespeichert oder protokolliert werden. Mit Secret Manager können Sie solche Secrets sicher speichern und abrufen.
Speichern Sie das Root-Passwort der MySQL-Datenbank als Cloud-Secret:
export SQL_PASSWORD_SECRET_NAME="mysql-password" printf $SQL_ROOT_PASSWORD | gcloud secrets create "${SQL_PASSWORD_SECRET_NAME}" \ --data-file=- \ --locations="${REGION_ID}" \ --replication-policy="user-managed" \ --project="${PROJECT_ID}"
Testdaten in die Cloud SQL-Instanz kopieren
Die Testdaten sind ein Demo-Dataset,das 5.000 zufällig generierte Vor- und Nachnamen sowie Telefonnummern im US-Format enthält. Die Tabelle demonstration-dataset enthält vier Spalten: row_id, person_name, contact_type, contact_number. Sie können auch Ihr eigenes Dataset verwenden. Wenn Sie Ihr eigenes Dataset verwenden, müssen Sie die vorgeschlagenen Werte unter In BigQuery überprüfen in diesem Dokument anpassen. So kopieren Sie das enthaltene Demo-Dataset (contacts5k.sql.gz) in die Cloud SQL-Instanz:
Kopieren Sie in Cloud Shell das Beispiel-Dataset in Cloud Storage für das Staging in Cloud SQL:
gsutil cp contacts5k.sql.gz gs://${TEMP_GCS_BUCKET}Erstellen Sie eine neue Datenbank in der Cloud SQL-Instanz:
export DATABASE_ID="auto_dlp_test" gcloud sql databases create "${DATABASE_ID}" \ --project="${PROJECT_ID}" \ --instance="${SQL_INSTANCE}"Weisen Sie Ihrem Cloud SQL-Dienstkonto die Rolle "Storage-Objekt-Administrator" zu, damit es auf den Speicher zugreifen kann:
export SQL_SERVICE_ACCOUNT=$(gcloud sql instances describe "${SQL_INSTANCE}" --project="${PROJECT_ID}" | grep serviceAccountEmailAddress: | sed "s/serviceAccountEmailAddress: //g") gsutil iam ch "serviceAccount:${SQL_SERVICE_ACCOUNT}:objectAdmin" \ gs://${TEMP_GCS_BUCKET}Laden Sie die Daten in eine neue Tabelle:
gcloud sql import sql "${SQL_INSTANCE}" \ "gs://${TEMP_GCS_BUCKET}/contacts5k.sql.gz" \ --project="${PROJECT_ID}" \ --database="${DATABASE_ID}"Weitere Informationen zum Importieren von Daten in Cloud SQL finden Sie unter Best Practices zum Importieren und Exportieren von Daten.
Module kompilieren
Kompilieren Sie in Cloud Shell die Module, um die ausführbaren Dateien für die Bereitstellung der Stichproben- und Identifizierungspipeline und der Tokenisierungspipeline zu erstellen:
./gradlew clean buildNeeded shadowJar -x testWenn Sie den Unit- und Integrationstest ausführen möchten, entfernen Sie das Flag
-x test. Wennlibncurses5noch nicht installiert ist, installieren Sie es in Cloud Shell mitsudo apt-get install libncurses5.
Stichproben- und Identifizierungspipeline ausführen
Die Stichprobenpipeline und die Identifizierungspipeline für den Schutz sensibler Daten führt die folgenden Aufgaben in der folgenden Reihenfolge aus:
- Datensätze aus der bereitgestellten Quelle extrahieren. Die Identifizierungsmethode für den Schutz sensibler Daten unterstützt beispielsweise nur flache Tabellen, sodass die Pipeline die Avro-, Parquet- oder BigQuery-Datensätze vereinfacht, da sie verschachtelte und wiederkehrende Felder enthalten können.
- Erforderliche Stichproben der einzelnen Spalten erstellen, unter Ausschluss von
null- oder leeren Werten. - Vertrauliche
infoTypes-Daten mit dem Schutz sensibler Daten identifizieren. Dabei werden die Beispiele in Batchgrößen zusammengefasst, die für den Schutz sensibler Daten akzeptabel sind (kleiner als 500 KB und weniger als 50.000 Werte). - Berichte für Cloud Storage und BigQuery zur späteren Verwendung verstellen.
- Data Catalog-Entitäten erstellen, wenn Sie Informationen zu Tag-Vorlagen und Eintragsgruppen angeben. Wenn Sie diese Informationen angeben, erstellt die Pipeline Vertraulichkeits-Tags für Einträge in Data Catalog anhand der entsprechenden Spalten.
Flexible Dataflow-Vorlage erstellen
Mit Dataflow Flex Templates können Sie die Google Cloud Console, das Google Cloud CLI oder REST API-Aufrufe verwenden, um Ihre Pipelines in Google Cloud einzurichten und auszuführen. Dieses Dokument enthält eine Anleitung für die Google Cloud Console. Klassische Vorlagen werden als Ausführungsgrafiken in Cloud Storage bereitgestellt, während flexible Vorlagen die Pipeline als Container-Image in der Container Registry Ihres Projekts zusammenfassen. Mit flexiblen Vorlagen können Sie Pipelines erstellen und ausführen und in Orchestrierungssysteme für geplante Pipelineausführungen einbinden. Weitere Informationen zu flexiblen Dataflow-Vorlagen finden Sie unter Den zu verwendenden Vorlagentyp bestimmen.
Flexible Dataflow-Vorlagen trennen die Erstellungs- und Staging-Schritte von den ausgeführten Schritten. Dazu ermöglichen sie das Starten einer Dataflow-Pipeline über einen API-Aufruf sowie aus Cloud Composer mit dem Modul DataflowStartFlexTemplateOperator.
Legen Sie in Cloud Shell den Speicherort für die Vorlagenspezifikationsdatei fest, die die zum Ausführen des Dataflow-Jobs erforderlichen Informationen enthält:
export FLEX_TEMPLATE_PATH="gs://${TEMP_GCS_BUCKET}/dataflow/templates/sample-inspect-tag-pipeline.json" export FLEX_TEMPLATE_IMAGE="us.gcr.io/${PROJECT_ID}/dataflow/sample-inspect-tag-pipeline:latest"Erstellen Sie die flexible Dataflow-Vorlage:
gcloud dataflow flex-template build "${FLEX_TEMPLATE_PATH}" \ --image-gcr-path="${FLEX_TEMPLATE_IMAGE}" \ --service-account-email="${DLP_RUNNER_SERVICE_ACCOUNT_EMAIL}" \ --sdk-language="JAVA" \ --flex-template-base-image=JAVA11 \ --metadata-file="sample_identify_tag_pipeline_metadata.json" \ --jar="build/libs/auto-data-tokenize-all.jar" \ --env="FLEX_TEMPLATE_JAVA_MAIN_CLASS=\"com.google.cloud.solutions.autotokenize.pipeline.DlpInspectionPipeline\""
Pipeline ausführen
Die Stichproben- und Identifizierungspipeline extrahiert die Anzahl von Datensätzen, die durch den Wert sampleSize angegeben ist. Anschließend werden die Datensätze vereinfacht und die Felder infoTypes mithilfe vom Schutz sensibler Daten identifiziert, um vertrauliche Informationstypen zu erkennen. Die infoTypes-Werte werden gezählt und dann nach Spaltenname und infoType-Feld aggregiert, um einen Vertraulichkeitsbericht zu erstellen.
Starten Sie in Cloud Shell die Stichproben- und Identifizierungspipeline, um vertrauliche Spalten in der Datenquelle zu identifizieren:
export CLOUD_SQL_JDBC_CONNECTION_URL="jdbc:mysql:///${DATABASE_ID}?cloudSqlInstance=${PROJECT_ID}%3A${REGION_ID}%3A${SQL_INSTANCE}&socketFactory=com.google.cloud.sql.mysql.SocketFactory" gcloud dataflow flex-template run "sample-inspect-tag-`date +%Y%m%d-%H%M%S`" \ --template-file-gcs-location "${FLEX_TEMPLATE_PATH}" \ --region "${REGION_ID}" \ --service-account-email "${DLP_RUNNER_SERVICE_ACCOUNT_EMAIL}" \ --staging-location "gs://${TEMP_GCS_BUCKET}/staging" \ --worker-machine-type "n1-standard-1" \ --parameters sampleSize=2000 \ --parameters sourceType="JDBC_TABLE" \ --parameters inputPattern="Contacts" \ --parameters reportLocation="gs://${TEMP_GCS_BUCKET}/auto_dlp_report/" \ --parameters reportBigQueryTable="${PROJECT_ID}:inspection_results.SensitivityInspectionResults" \ --parameters jdbcConnectionUrl="${CLOUD_SQL_JDBC_CONNECTION_URL}" \ --parameters jdbcDriverClass="com.mysql.cj.jdbc.Driver" \ --parameters jdbcUserName="root" \ --parameters jdbcPasswordSecretsKey="projects/${PROJECT_ID}/secrets/${SQL_PASSWORD_SECRET_NAME}/versions/1" \ --parameters ^:^jdbcFilterClause="ROUND(RAND() * 10) IN (1,3)" \ --parameters dataCatalogEntryGroupId="projects/${PROJECT_ID}/locations/${REGION_ID}/entryGroups/${DATA_CATALOG_ENTRY_GROUP_ID}" \ --parameters dataCatalogInspectionTagTemplateId="projects/${PROJECT_ID}/locations/${REGION_ID}/tagTemplates/${INSPECTION_TAG_TEMPLATE_ID}"
Der Parameter jdbcConnectionUrl gibt eine URL für die JDBC-Datenbankverbindung mit Nutzername und Passwort an. Die Details zum Erstellen der genauen Verbindungs-URL hängen vom Datenbankanbieter und vom Hostpartner ab. Weitere Informationen zum Herstellen einer Verbindung zu Cloud SQL-basierten relationalen Datenbanken finden Sie unter Verbindung über Cloud SQL-Connectors herstellen.
Die Pipeline erstellt eine Abfrage wie SELECT * FROM [TableName], um die Tabellendatensätze zur Prüfung zu lesen.
Diese Abfrage kann die Last der Datenbank und der Pipeline erhöhen, insbesondere bei einer großen Tabelle. Optional können Sie die Stichprobe von Datensätzen optimieren, die Sie auf der Datenbankseite prüfen möchten.
Fügen Sie dazu jdbcFilterClause als WHERE-Klausel der Abfrage ein, die im Codebeispiel im Abschnitt In BigQuery überprüfen weiter unten in diesem Dokument angezeigt wird.
Um einen Bericht auszuführen, können Sie eine oder mehrere der folgenden Berichtsenken auswählen:
reportLocation, um den Bericht in einem Cloud Storage-Bucket zu speichernreportBIGQUERY_TABLEzum Speichern des Berichts in einerBigQueryTabledataCatalogEntryGroupId, um den Eintrag in Data Catalog zu erstellen und zu taggen (diesen Parameter weglassen, wennsourceTypegleichBIGQUERY_TABLEist)
Die Pipeline unterstützt die folgenden Quelltypen. Mit den Optionen in der folgenden Tabelle können Sie die richtige Kombination von sourceType- und inputPattern-Argumenten ermitteln.
In diesem Fall verwenden Sie nur die Tabelle JDBC_TABLE.
sourceType |
Datenquelle | inputPattern |
|---|---|---|
|
Relationale Datenbanken (mit JDBC) |
|
|
Avro-Datei in Cloud Storage. Wenn Sie mehrere Dateien auswählen möchten, die einem Muster entsprechen, können Sie einen einzelnen Platzhalter verwenden. Mit dem folgenden Muster werden alle Dateien mit dem Präfix ( data-) ausgewählt:
|
|
|
Parquet-Datei in Cloud Storage. Wenn Sie mehrere Dateien auswählen möchten, die einem Muster entsprechen, können Sie einen einzelnen Platzhalter verwenden. Mit dem folgenden Muster werden alle Dateien mit dem Präfix ( data-) ausgewählt:
|
|
|
BigQuery-Tabelle. Liest alle Zeilen und erstellt dann zufällige Stichproben über die Pipeline. |
|
Die Pipeline erkennt alle Standard-infoTypes, die vom Schutz sensibler Daten unterstützt werden. Mit dem Parameter --observableinfoTypes können Sie zusätzliche benutzerdefinierte infoTypes angeben.
Gerichteter azyklischer Graph (DAG) der Stichproben- und Identifizierungspipeline
Das folgende Diagramm zeigt den Dataflow-Ausführungs-DAG. Der DAG hat zwei Zweige. Beide Zweige beginnen bei ReadJdbcTable und enden bei ExtractReport. Von dort aus werden Berichte generiert oder Daten gespeichert.
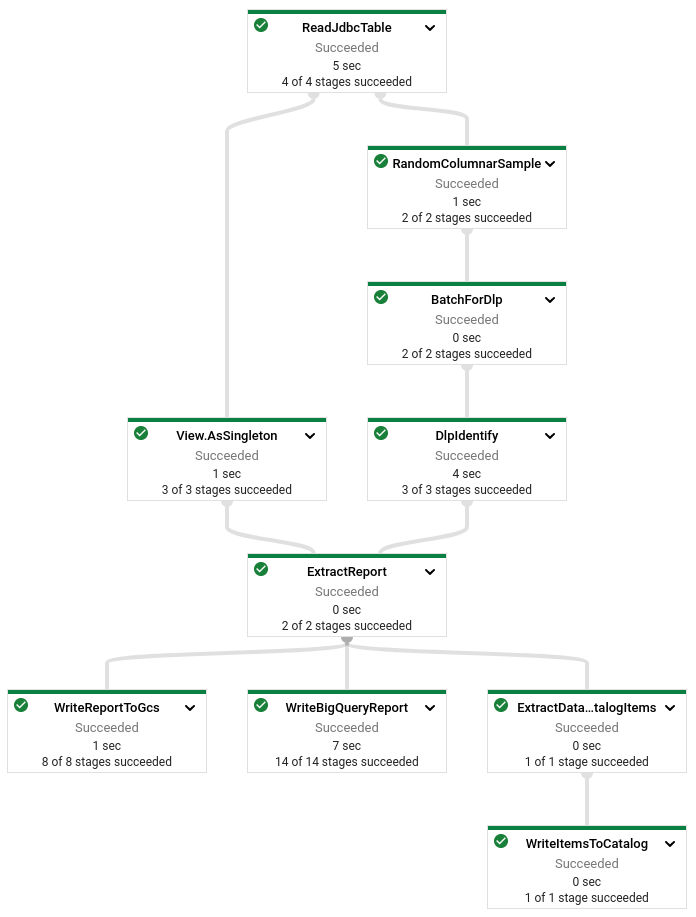
Bericht abrufen
Die Stichproben- und Identifizierungspipeline gibt die folgenden Dateien aus:
- Avro-Schemadatei (oder ein in Avro konvertiertes Schema) der Quelle
- Eine Datei für jede vertrauliche Spalte mit
infoType-Informationen und Anzahlen
So rufen Sie den Bericht ab:
Rufen Sie in Cloud Shell den Bericht ab:
mkdir -p auto_dlp_report/ gsutil -m cp "gs://${TEMP_GCS_BUCKET}/auto_dlp_report/*.json" auto_dlp_report/Listen Sie alle identifizierten Spaltennamen auf:
cat auto_dlp_report/col-*.json | jq .columnNameDie Ausgabe sieht so aus:
"$.topLevelRecord.contact_number" "$.topLevelRecord.person_name"Rufen Sie die Details einer identifizierten Spalte mit dem
cat-Befehl für die Datei auf:cat auto_dlp_report/col-topLevelRecord-contact_number-00000-of-00001.jsonDies ist ein Snippet der Spalte
cc:{ "columnName": "$.topLevelRecord.contact_number", "infoTypes": [{ "infoType": "PHONE_NUMBER", "count": "990" }] }- Der Wert
columnNameist aufgrund der impliziten Konvertierung einer Datenbankzeile in einen Avro-Datensatz ungewöhnlich. - Der Wert
countvariiert je nach den zufällig ausgewählten Stichproben während der Ausführung.
- Der Wert
Vertraulichkeits-Tags in Data Catalog überprüfen
Die Stichproben- und Identifizierungspipeline erstellt einen neuen Eintrag und wendet die Vertraulichkeits-Tags auf die entsprechenden Spalten an.
Rufen Sie in Cloud Shell den erstellten Eintrag für die Tabelle "Contacts" ab:
gcloud data-catalog entries describe Contacts \ --entry-group=${DATA_CATALOG_ENTRY_GROUP_ID} \ --project="${PROJECT_ID}" \ --location="${REGION_ID}"Dieser Befehl zeigt die Details der Tabelle, einschließlich ihres Schemas.
Lassen Sie alle Vertraulichkeits-Tags anzeigen, die mit diesem Eintrag verknüpft sind:
gcloud data-catalog tags list --entry=Contacts --entry-group=${DATA_CATALOG_ENTRY_GROUP_ID} \ --project="${PROJECT_ID}" \ --location="${REGION_ID}"Prüfen Sie, ob die Vertraulichkeits-Tags in den folgenden Spalten vorhanden sind:
contact_number,person_name.Die vom Schutz sensibler Daten identifizierten
infoTypes-Daten können einige falsche Typen enthalten. Beispielsweise kann der Typperson_namealsDATE-Typ identifiziert werden, da einige zufälligeperson_names-Strings April, May, June usw. lauten können.Dies sind die ausgegebenen Details der Vertraulichkeits-Tags:
column: contact_number fields: infoTypes: displayName: DLP infoTypes stringValue: '[PHONE_NUMBER]' inspectTimestamp: displayName: Inspection run timestamp timestampValue: '2021-05-20T16:34:29.596Z' name: projects/auto-dlp/locations/asia-southeast1/entryGroups/sql_databases/entries/Contacts/tags/CbS0CtGSpZyJ template: projects/auto-dlp/locations/asia-southeast1/tagTemplates/auto_dlp_inspection templateDisplayName: Auto DLP sensitive categories --- column: person_name fields: infoTypes: displayName: DLP infoTypes stringValue: '[DATE, PERSON_NAME]' inspectTimestamp: displayName: Inspection run timestamp timestampValue: '2021-05-20T16:34:29.594Z' name: projects/auto-dlp/locations/asia-southeast1/entryGroups/sql_databases/entries/Contacts/tags/Cds1aiO8R0pT template: projects/auto-dlp/locations/asia-southeast1/tagTemplates/auto_dlp_inspection templateDisplayName: Auto DLP sensitive categories
In BigQuery überprüfen
Die Dataflow-Pipeline hängt die aggregierten Ergebnisse an die bereitgestellte BigQuery-Tabelle an. Die Abfrage gibt die aus der BigQuery-Tabelle abgerufenen Prüfungsergebnisse aus.
Prüfen Sie die Ergebnisse in Cloud Shell:
bq query \ --location="${REGION_ID}" \ --project="${PROJECT_ID}" \ --use_legacy_sql=false \ 'SELECT input_pattern AS table_name, ColumnReport.column_name AS column_name, ColumnReport.info_types AS info_types FROM `inspection_results.SensitivityInspectionResults`, UNNEST(column_report) ColumnReport; WHERE column_name="$.topLevelRecord.contact_number"'Die Ausgabe sieht so aus:
+------------+---------------------------------+----------------------------------------------+ | table_name | column_name | info_types | +------------+---------------------------------+----------------------------------------------+ | Contacts | $.topLevelRecord.contact_number | [{"info_type":"PHONE_NUMBER","count":"990"}] | +------------+---------------------------------+----------------------------------------------+
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Begleitdokument zu einer ähnlichen Lösung, die Dateien als Eingabe verwendet: Vertrauliche dateibasierte Daten mit dem Schutz sensibler Daten, Cloud Key Management Service und Dataflow automatisch tokenisieren
- Speicher und Datenbanken auf vertrauliche Daten prüfen
- Personenidentifizierbare Informationen in umfangreichen Datasets mit dem Schutz sensibler Daten schützen
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.