In diesem Leitfaden wird die Referenzarchitektur beschrieben, die zur Bereitstellung von Distributed Cloud verwendet wird. Diese Anleitung richtet sich an Plattformadministratoren, die GKE Enterprise auf einer Bare-Metal-Plattform in einer hochverfügbaren, geografisch redundanten Konfiguration bereitstellen möchten. Sie sollten für diese Anleitung mit den grundlegenden GKE Enterprise-Konzepten vertraut sein, wie in der technischen Übersicht zu GKE Enterprise beschrieben. Sie sollten außerdem Grundkenntnisse zu Kubernetes-Konzepten und Google Kubernetes Engine (GKE) haben, wie in Kubernetes-Grundlagen und in der GKE-Dokumentation beschreiben.
Diese Anleitung enthält ein GitHub-Quell-Repository mit Skripts, mit denen Sie die beschriebene Architektur bereitstellen können. In dieser Anleitung werden auch die Architekturkomponenten beschrieben, die die Skripts und Module begleiten, die zum Erstellen dieser Komponenten verwendet werden. Wir empfehlen, dass Sie diese Dateien als Vorlage verwenden, um Module zu erstellen, die den Best Practices und Richtlinien Ihrer Organisation genügen.
Architekturmodell für Distributed Cloud
Im Leitfaden "GKE Enterprise-Architekturgrundlagen" wird die Plattformarchitektur über deren Ebenen beschrieben. Die Ressourcen auf den einzelnen Ebenen bieten einen bestimmten Satz von Funktionen. Diese Ressourcen gehören einer oder mehreren Identitäten und werden von ihnen verwaltet. Wie im folgenden Diagramm dargestellt, besteht die GKE Enterprise-Plattformarchitektur für Bare-Metal aus folgenden Ebenen und Ressourcen:
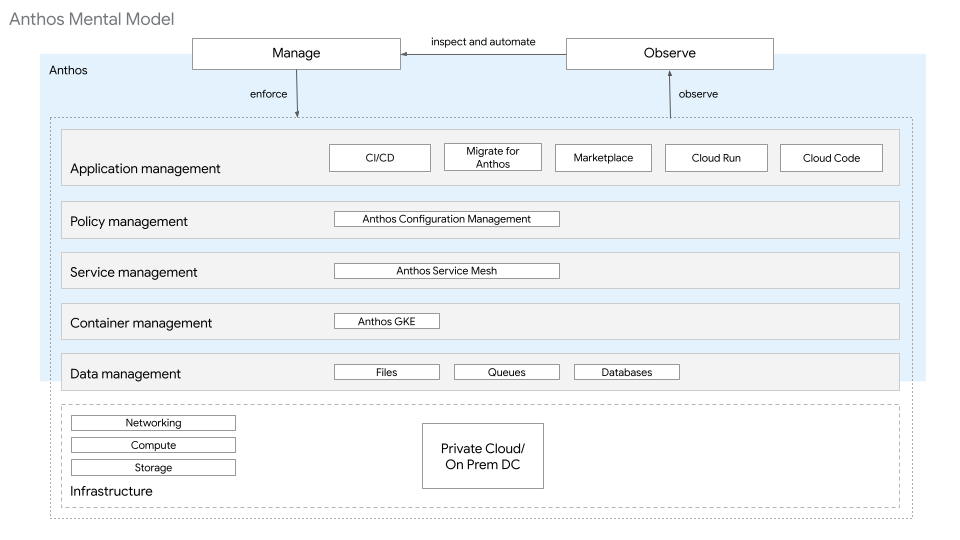
- Infrastruktur: Diese Ebene umfasst Speicher, Computing und Netzwerke, was mit lokalen Konstrukten bewältigt wird.
- Datenverwaltung: Für diese Anleitung ist auf der Datenverwaltungsebene eine SQL-Datenbank erforderlich, die außerhalb der bereitgestellten Kubernetes-Cluster verwaltet wird.
- Containerverwaltungsebene: Diese Ebene verwendet GKE-Cluster.
- Dienstverwaltungsebene: Diese Ebene verwendet Cloud Service Mesh.
- Richtlinienverwaltungsebene: Diese Ebene verwendet Config Sync und Policy Controller.
- Ebene zur Anwendungsverwaltung: Diese Ebene verwendet Cloud Build und Cloud Source Repositories.
- Beobachtbarkeitsebene: Diese Ebene verwendet Dashboards für Google Cloud Observability und Cloud Service Mesh.
Jede dieser Ebenen wird im Stack für verschiedene Lebenszyklusumgebungen wie Entwicklung, Staging und Produktion wiederholt.
Die folgenden Abschnitte enthalten ausschließlich Zusatzinformationen speziell für Distributed Cloud. Sie knüpfen an den jeweiligen Abschnitten im Leitfaden zu den GKE Enterprise-Architekturgrundlagen an. Wir empfehlen dir, beim Lesen dieses Artikels die Anleitung zurate zu ziehen.
Netzwerk
Weitere Informationen zu den Netzwerkanforderungen finden Sie unter Netzwerkanforderungen.
Für Distributed Cloud-Load-Balancer gibt es zwei Optionen: gebündelt und manuell.
Im gebündelten Modus wird L4-Load-Balancing-Software während der Clustererstellung bereitgestellt. Die Load-Balancer-Prozesse können in einem dedizierten Worker-Knoten-Pool oder auf denselben Knoten wie die Steuerungsebene ausgeführt werden. Dieser Load-Balancer kann virtuelle IP-Adressen (VIPs) über zwei Optionen bewerben:
- Address Resolution Protocol (ARP): Erfordert Ebene-2-Konnektivität zwischen den Knoten, auf denen der Load Balancer ausgeführt wird.
- Border Gateway Protocol (BGP): Verwendet Peering, um Ihr Clusternetzwerk (ein autonomes System) mit einem anderen autonomen System, z. B. einem externen Netzwerk, zu verbinden.
Im manuellen Modus konfigurieren Sie eigene Load-Balancing-Lösungen für den Traffic auf Steuerungs- und Datenebene. Für externe Load-Balancer stehen viele Hardware- und Softwareoptionen zur Verfügung. Sie müssen einen externen Load-Balancer für die Steuerungsebene einrichten, bevor Sie einen Bare-Metal-Cluster erstellen. Der Load-Balancer der externen Steuerungsebene kann auch für den Traffic der Datenebene verwendet werden oder Sie richten einen separaten Load-Balancer für die Datenebene ein. Zur Bestimmung der Verfügbarkeit muss der Load-Balancer den Traffic anhand einer konfigurierbaren Bereitschaftsprüfung an einen Knotenpool verteilen können.
Weitere Informationen zu Load-Balancern für Distributed Cloud finden Sie unter Load-Balancer – Übersicht.
Clusterarchitektur
Distributed Cloud unterstützt mehrere Bereitstellungsmodelle, die auf unterschiedliche Anforderungen in Sachen Verfügbarkeit, Isolation und Ressourcen abgestimmt sind. Diese Bereitstellungsmodelle werden unter Bereitstellungsmodell auswählen erläutert.
Identitätsverwaltung
Distributed Cloud verwendet den GKE Identity Service zur Einbindung in Identitätsanbieter. Unterstützt werden OpenID Connect (OIDC) und Lightweight Directory Access Protocol (LDAP). Für Anwendungen und Dienste kann Cloud Service Mesh mit verschiedenen Identitätslösungen verwendet werden.
Weitere Informationen zur Identitätsverwaltung finden Sie unter Identitätsverwaltung mit OIDC in Distributed Cloud und Mit OIDC authentifizieren und unter Anthos Identity Service mit LDAP einrichten
Sicherheits- und Richtlinienverwaltung
Für die Sicherheits- und Richtlinienverwaltung in Distributed Cloud empfehlen wir die Verwendung von Config Sync und Policy Controller. Mit Policy Controller können Sie Richtlinien für alle Ihre Cluster erstellen und erzwingen. Config Sync ermittelt Änderungen und wendet sie auf alle Cluster an, um den angemessenen Status zu erreichen.
Dienste
Wenn Sie den gebündelten Modus von Distributed Cloud für das Load-Balancing verwenden, können Sie Dienste vom Typ LoadBalancer erstellen. Wenn Sie diese Dienste erstellen, weist Distributed Cloud dem Dienst eine IP-Adresse aus dem konfigurierten IP-Adresspool des Load-Balancers zu. Der Diensttyp LoadBalancer wird verwendet, um den Kubernetes-Dienst außerhalb des Clusters für Nord-Süd-Traffic verfügbar zu machen.
Wenn Sie Distributed Cloud verwenden, wird standardmäßig auch ein IngressGateway im Cluster erstellt. Sie können im manuellen Modus keine Dienste vom Typ LoadBalancer für Distributed Cloud erstellen. Stattdessen können Sie entweder ein Ingress-Objekt erstellen, das das IngressGateway verwendet, oder Dienste des Typs NodePort erstellen und Ihren externen Load-Balancer manuell konfigurieren, um den Kubernetes-Dienst als Back-End zu verwenden.
Für Dienstverwaltung, auch als Ost-West-Traffic bezeichnet, empfehlen wir die Verwendung von Cloud Service Mesh. Cloud Service Mesh basiert auf offenen Istio-APIs und bietet einheitliche Beobachtbarkeit, Authentifizierung, Verschlüsselung, differenzierte Trafficsteuerungen und andere Features und Funktionen. Weitere Informationen zu Dienstverwaltung finden Sie unter Cloud Service Mesh.
Persistenz und Statusverwaltung
Distributed Cloud ist für sitzungsspezifischen Speicher, Volume-Speicher und PersistentVolume-Speicher weitgehend von der vorhandenen Infrastruktur abhängig. Sitzungsspezifische Daten verwenden die lokalen Laufwerkressourcen auf dem Knoten, auf dem der Kubernetes-Pod geplant ist. Für nichtflüchtige Daten ist GKE Enterprise mit dem Container Storage Interface (CSI) kompatibel, einer Open-Standard-API, die von vielen Speicheranbietern unterstützt wird. Für die Produktionsspeicherung empfehlen wir die Installation eines CSI-Treibers von einem GKE Enterprise Ready-Speicherpartner. Die vollständige Liste der GKE Enterprise Ready Speicherpartner finden Sie unter GKE Enterprise Ready-Speicherpartner.
Weitere Informationen zum Speicher finden Sie unter Speicher konfigurieren.
Datenbanken
Distributed Cloud bietet keine zusätzlichen datenbankspezifischen Funktionen, die über die Standardfunktionen der GKE Enterprise-Plattform hinausgehen. Die meisten Datenbanken werden in einem externen Datenverwaltungssystem ausgeführt. Arbeitslasten auf der GKE Enterprise-Plattform können auch so konfiguriert werden, dass eine Verbindung zu allen zugänglichen externen Datenbanken hergestellt werden kann.
Beobachtbarkeit
Die Google Cloud Observability erfasst Logs und Monitoring-Messwerte für Distributed Cloud-Cluster auf eine Art, die den Sammlungs- und Monitoring-Richtlinien von GKE-Clustern ähnelt. Standardmäßig werden die Clusterlogs und die Messwerte für Systemkomponenten an Cloud Monitoring gesendet.
Damit Google Cloud Observability Anwendungslogs und -messwerte erfassen kann, aktivieren Sie die Option clusterOperations.enableApplication in der YAML-Datei für die Clusterkonfiguration.
Weitere Informationen zur Beobachtbarkeit finden Sie unter Logging und Monitoring konfigurieren.
Anwendungsfall: Cymbal Bank-Bereitstellung
In dieser Anleitung wird die Anwendung Cymbal Bank/Bank of Anthos verwendet, um Planung, Plattformbereitstellung und Anwendungsbereitstellung von Distributed Cloud zu simulieren.
Der Rest dieses Dokuments besteht aus drei Abschnitten. Im Abschnitt Planung werden die Entscheidungen erläutert, die auf den in den Abschnitten zum Architekturmodell erläuterten Optionen basieren. Im Abschnitt Plattformbereitstellung werden die Skripts und Module beschrieben, die von einem Quell-Repository für die Bereitstellung der GKE Enterprise-Plattform bereitgestellt werden. Im Bereich Anwendungsbereitstellung wird die Cymbal Bank-Anwendung auf der Plattform bereitgestellt.
Diese Distributed Cloud-Anleitung kann für die Bereitstellung auf selbstverwalteten Hosts oder auf Compute Engine-Instanzen verwendet werden. Mit Google Cloud-Ressourcen kann jeder diese Anleitung abschließen, ohne Zugriff auf physische Hardware zu benötigen. Die Verwendung von Compute Engine-Instanzen dient nur zu Demonstrationszwecken. Verwenden Sie diese Instanzen NICHT für Produktionsarbeitslasten. Wenn Zugriff auf physische Hardware verfügbar ist und dieselben IP-Adressbereiche verwendet werden, können Sie das bereitgestellte Quell-Repository unverändert verwenden. Wenn sich die Umgebung von der Vorgehensweise im Abschnitt Planung unterscheidet, können Sie die Scripts und Module so ändern, dass die Unterschiede berücksichtigt werden. Das verknüpfte Quell-Repository enthält eine Anleitung für die physische Hardware und die Szenarien der Compute Engine-Instanz.
Planung
Im folgenden Abschnitt werden die Architekturentscheidungen beschrieben, die bei der Planung und Gestaltung der Plattform für die Bereitstellung der Bank of GKE Enterprise-Anwendung in Distributed Cloud getroffen wurden. Diese Abschnitte konzentrieren sich auf eine Produktionsumgebung. Zur Erstellung niedrigerer Umgebungen wie für Entwicklung oder Staging können Sie ähnliche Schritte verwenden.
Google Cloud-Projekte
Zum Erstellen von Projekten in Google Cloud für Distributed Cloud ist ein Flotten-Hostprojekt erforderlich. Pro Umgebung oder Geschäftsfunktion werden zusätzliche Projekte empfohlen. Mit dieser Projektkonfiguration können Sie Ressourcen basierend auf der Identität organisieren, die mit der Ressource interagiert.
In den folgenden Unterabschnitten werden die empfohlenen Projekttypen und die zugehörigen Identitäten behandelt.
Hub-Projekt:
Das Hub-Projekt hub-prod bezieht sich auf die Identität "Netzwerkadministrator". Über dieses Projekt ist das lokale Rechenzentrum über die von Ihnen ausgewählte Hybridkonnektivität mit Google Cloud verbunden. Weitere Informationen zu den Hybridkonnektivitätsoptionen finden Sie unter Google Cloud-Konnektivität
Flotten-Hostprojekt
Das Flotten-Hostprojekt fleet-prod bezieht sich auf die Identität "Plattformadministrator". Die Distributed Cloud-Cluster werden im Projekt registriert. In diesem Projekt befinden sich auch die plattformbezogenen Google Cloud-Ressourcen. Zu diesen Ressourcen gehören Google Cloud-Beobachtbarkeit, Cloud Source Repositories und anderes. Einem gegebenen Google Cloud-Projekt kann maximal eine einzige Flotte (oder keine Flotten) zugeordnet sein. Diese Einschränkung fördert die Nutzung von Google Cloud-Projekten, um Ressourcen, die nicht gemeinsam gesteuert oder genutzt werden, effiktiver zu isolieren.
Anwendungs- oder Teamprojekt
Das Anwendungs- oder Teamprojekt app-banking-prod bezieht sich auf die Entwickleridentität. In diesem Projekt befinden sich anwendungs- oder teamspezifische Google Cloud-Ressourcen. Das Projekt enthält alles außer GKE-Cluster. Je nach Anzahl der Teams oder Anwendungen kann es mehrere Instanzen dieses Projekttyps geben. Wenn Sie separate Projekte für verschiedene Teams erstellen, können Sie IAM, Abrechnung und Kontingente für jedes Team separat verwalten.
Netzwerk
Für jeden Distributed Cloud-Cluster sind die folgenden IP-Adress-Subnetze erforderlich:
- Knoten-IP-Adressen
- Kubernetes-Pod-IP-Adressen
- IP-Adressen von Kubernetes-Diensten/-Clustern
- Load-Balancer-IP-Adressen (gebündelter Modus)
Wählen Sie ein Netzwerkmodell im Inselmodus aus, um in jedem Cluster dieselben nicht routingfähigen IP-Adressbereiche für die Kubernetes-Pod- und -Dienstsubnetze zu verwenden. In dieser Konfiguration können Pods direkt in einem Cluster miteinander kommunizieren, sind aber nicht direkt von außerhalb eines Clusters über Pod-IP-Adressen erreichbar. Diese Konfiguration bildet eine Insel innerhalb des Netzwerks, die nicht mit dem externen Netzwerk verbunden ist. Die Cluster bilden ein vollständiges Knoten-zu-Knoten-Mesh-Netzwerk über die Clusterknoten innerhalb der Insel, sodass der Pod direkt andere Pods innerhalb des Clusters erreichen kann.
Zuweisung von IP-Adressen
| Cluster | Knoten | Pod | Dienste | Load-Balancer |
|---|---|---|---|---|
| metal-admin-dc1-000-prod | 10.185.0.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | – |
| metal-user-dc1a-000-prod | 10.185.1.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | 10.185.1.3-10.185.1.10 |
| metal-user-dc1b-000-prod | 10.185.2.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | 10.185.2.3-10.185.2.10 |
| metal-admin-dc2-000-prod | 10.195.0.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | – |
| metal-user-dc2a-000-prod | 10.195.1.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | 10.195.1.3-10.195.1.10 |
| metal-user-dc2b-000-prod | 10.195.2.0/24 | 192.168.0.0/16 | 10.96.0.0/12 | 10.195.2.3-10.195.2.10 |
Im Inselmodus muss unbedingt dafür gesorgt werden, dass die für die Kubernetes-Pods und -Dienste ausgewählten IP-Adress-Subnetze vom Knotennetzwerk nicht verwendet werden und nicht von diesem aus routingfähig sind.
Netzwerkanforderungen
Wenn Sie einen integrierten Load-Balancer für Distributed Cloud bereitstellen möchten, der keine Konfiguration erfordert, verwenden Sie pro Cluster den gebündelten Load-Balancer-Modus. Wenn Arbeitslasten LoadBalancer-Dienste ausführen, wird aus dem Load-Balancer-Pool eine IP-Adresse zugewiesen.
Ausführliche Informationen zu den Anforderungen und zur Konfiguration des gebündelten Load-Balancers finden Sie unter Übersicht über Load-Balancer und Gebündeltes Load-Balancing konfigurieren.
Clusterarchitektur
Für Produktionsumgebungen empfehlen wir die Verwendung eines Administrator- und Nutzercluster-Bereitstellungsmodells mit einem Administratorcluster und zwei Nutzerclustern an den verschiedenen geografischen Standorten, um eine optimale Redundanz und Fehlertoleranz für Distributed Cloud zu erreichen.
Wir empfehlen, pro Produktionsumgebung mindestens vier Nutzercluster zu verwenden. Verwenden Sie zwei geografisch redundante Standorte, die jeweils zwei fehlertolerante Cluster enthalten. Jeder fehlertolerante Cluster hat redundante Hardware und redundante Netzwerkverbindungen. Wenn Sie die Anzahl der Cluster verringern, wird entweder die Redundanz oder die Fehlertoleranz der Architektur reduziert.
Für eine hohe Verfügbarkeit verwendet die Steuerungsebene für jeden Cluster drei Knoten. Mit mindestens drei Worker-Knoten pro Benutzercluster können Sie Arbeitslasten auf diese Knoten verteilen, um die Auswirkungen zu verringern, wenn ein Knoten offline geht. Die Anzahl und Größe der Worker-Knoten hängt weitgehend vom Typ und der Anzahl der Arbeitslasten ab, die im Cluster ausgeführt werden. Die empfohlene Größe für die einzelnen Knoten wird unter Hardware für Distributed Cloud konfigurieren erläutert.
In der folgenden Tabelle wird die empfohlene Knotengröße für CPU-Kerne, Arbeitsspeicher und lokaler Festplattenspeicher in diesem Anwendungsfall beschrieben.
| Knotentyp | CPUs / vCPUs | Speicher | Speicher |
|---|---|---|---|
| Steuerungsebene | 8 Kerne | 32 GiB | 256 GiB |
| Worker | 8 Kerne | 64 GiB | 512 GiB |
Weitere Informationen zu den Maschinenvoraussetzungen und zur Größenanpassung finden Sie unter Voraussetzungen für Clusterknoten-Rechner.
Identitätsverwaltung
Für die Identitätsverwaltung empfehlen wir die Einbindung in OIDC über den GDK Identity Service. In den im Quell-Repository bereitgestellten Beispielen wird die lokale Authentifizierung verwendet, um die Anforderungen zu vereinfachen. Ist OIDC verfügbar, so können Sie das Beispiel anpassen, um es zu verwenden. Weitere Informationen finden Sie unter Identitätsverwaltung mit OIDC in Distributed Cloud.
Sicherheits- und Richtlinienverwaltung
Im Cymbal Bank-Anwendungsfall werden Config Sync und Policy Controller zur Richtlinienverwaltung verwendet. Cloud Source Repositories wird zum Speichern der Konfigurationsdaten erstellt, die Config Sync verwendet. Der Operator ConfigManagement, mit dem Config Sync und Policy Controller installiert und verwaltet werden, benötigt Lesezugriff auf das Konfigurationsquell-Repository. Verwenden Sie eine Form der zulässigen Authentifizierung, um diesen Zugriff zu gewähren. In diesem Beispiel wird ein Google-Dienstkonto verwendet.
Dienste
Für die Dienstverwaltung wird in diesem Anwendungsfall Cloud Service Mesh verwendet, um eine Grundlage für die Erstellung verteilter Dienste bereitzustellen. Standardmäßig wird im Cluster auch ein IngressGateway erstellt, das standardmäßige Kubernetes-Ingress-Objekte verarbeitet.
Persistenz und Statusverwaltung
Da der nichtflüchtige Speicher weitgehend von der vorhandenen Infrastruktur abhängt, ist dies für diesen Anwendungsfall nicht erforderlich. In anderen Fällen empfehlen wir jedoch die Verwendung der Speicheroptionen von GKE ENterprise Ready-Speicherpartnern. Wenn eine CSI-Speicheroption verfügbar ist, kann sie mithilfe der vom Anbieter bereitgestellten Anleitung im Cluster installiert werden. Für Proof of Concept und fortgeschrittene Anwendungsfälle können Sie lokale Volumes verwenden. Für die meisten Anwendungsfällen ist es jedoch nicht empfohlen, lokale Volumes in Produktionsumgebungen zu verwenden.
Datenbanken
Viele zustandsorientierte Anwendungen in Distributed Cloud verwenden Datenbanken als Persistenzspeicher. Eine zustandsorientierte Datenbankanwendung benötigt Zugriff auf eine Datenbank, um den Kunden ihre Geschäftslogik bereitstellen zu können. Es gibt keine Einschränkungen für den on Distributed Cloud verwendeten Datenspeichertyp. Datenspeicherentscheidungen sollten daher vom Entwickler oder zugehörigen Datenverwaltungsteams getroffen werden. Da verschiedene Anwendungen unterschiedliche Datenspeicher erfordern können, können diese Datenspeicher auch ohne Einschränkung verwendet werden. Datenbanken können im Cluster, lokal oder auch in der Cloud verwaltet werden.
Die Cymbal Bank-Anwendung ist eine zustandsorientierte Anwendung, die auf zwei PostgreSQL-Datenbanken zugreift. Der Datenbankzugriff erfolgt über Umgebungsvariablen. Die PostgreSQL-Datenbank muss über die Knoten zugänglich sein, auf denen die Arbeitslasten ausgeführt werden, auch wenn die Datenbank extern vom Cluster aus verwaltet wird. In diesem Beispiel greift die Anwendung auf eine vorhandene externe PostgreSQL-Datenbank zu. Während die Anwendung auf der Plattform ausgeführt wird, wird die Datenbank extern verwaltet. Daher ist die Datenbank nicht Teil der GKE Enterprise-Plattform Ist eine PostgreSQL-Datenbank verfügbar, verwenden Sie sie. Falls nicht, erstellen und verwenden Sie eine Cloud SQL-Datenbank für die Anwendung "Cymbal Bank".
Beobachtbarkeit
Die einzelnen Cluster im Cymbal Bank-Anwendungsfall sind so konfiguriert, dass Google Cloud Observability-Logs und -Messwerte sowohl für Systemkomponenten als auch für Anwendungen erfasst. Das Installationsprogramm der Google Cloud Console erstellt mehrere Cloud Monitoring-Dashboards. Diese können über die Seite Monitoring-Dashboards aufgerufen werden. Weitere Informationen zur Beobachtbarkeit finden Sie unter Logging und Monitoring konfigurieren sowie Funktionsweise von Logging und Monitoring für Distributed Cloud.
Plattformbereitstellung
Weitere Informationen finden Sie im GitHub-Quell-Repository im Dokumentationsabschnitt Plattform bereitstellen.
Bereitstellung von Anwendungen
Weitere Informationen finden Sie im GitHub-Quell-Repository im Dokumentationsabschnitt Plattform bereitstellen.
Nächste Schritte
- Weitere Informationen zu Cloud Service Mesh, Config Sync und Policy Controller.
- Sehen Sie sich einige andere GKE Enterprise-Referenzarchitekturen an.
- Testen Sie GKE Enterprise on Google Cloud mit dem Beispiel-Deployment für GKE Enterprise.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center