Saat memilih layanan penyimpanan Google Cloud untuk workload kecerdasan buatan (AI) dan machine learning (ML), Anda harus berhati-hati dalam memilih kombinasi opsi penyimpanan yang tepat untuk setiap tugas tertentu. Kebutuhan untuk memilih yang cermat ini berlaku saat Anda mengupload set data, melatih dan menyesuaikan model, menempatkan model ke produksi, atau menyimpan set data dan model di arsip. Singkatnya, Anda harus memilih layanan penyimpanan terbaik yang menyediakan latensi, skala, dan biaya yang tepat untuk setiap tahap workload AI dan ML Anda.
Untuk membantu Anda membuat pilihan yang tepat, dokumen ini memberikan panduan desain tentang cara menggunakan dan mengintegrasikan berbagai opsi penyimpanan yang ditawarkan oleh Google Cloud untuk workload AI dan ML utama.
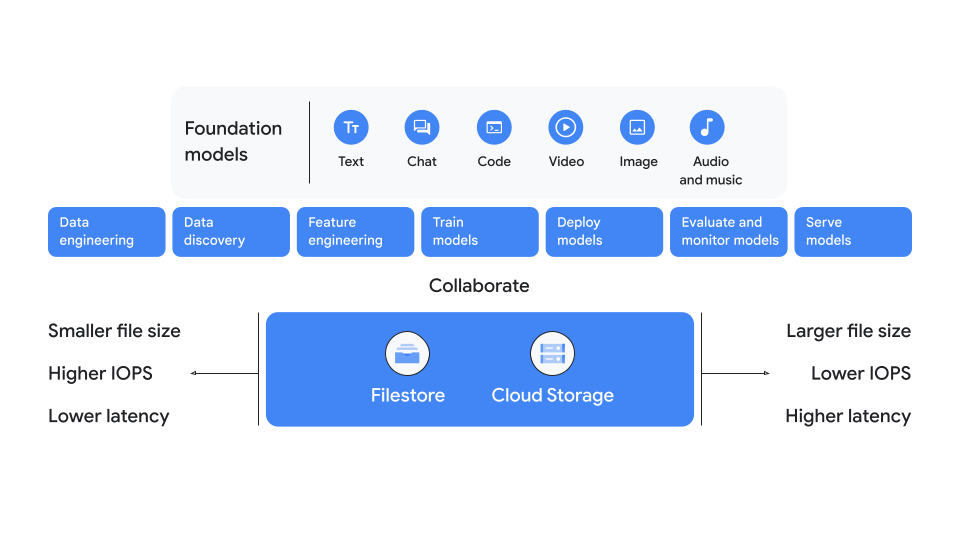
Gambar 1 menunjukkan ringkasan pilihan penyimpanan utama. Seperti yang ditampilkan dalam diagram, biasanya Anda memilih Cloud Storage jika ukuran file Anda lebih besar, operasi input dan output per detik (IOPS) yang lebih rendah, atau latensi yang lebih tinggi. Namun, jika Anda memerlukan IOPS yang lebih tinggi, ukuran file yang lebih kecil, atau latensi yang lebih rendah, pilih Filestore.
Gambar 1: Pertimbangan utama untuk penyimpanan AI dan ML
Ringkasan tahap workload AI dan ML
Workload AI dan ML terdiri dari empat tahap utama: persiapan, pelatihan, penyaluran, dan pengarsipan. Ini adalah periode empat kali dalam siklus proses workload AI dan ML di mana Anda perlu memutuskan opsi penyimpanan mana yang harus Anda pilih untuk digunakan. Pada umumnya, sebaiknya Anda terus menggunakan pilihan penyimpanan yang sama dengan yang Anda pilih pada tahap persiapan untuk tahap yang tersisa. Ikuti rekomendasi ini untuk membantu Anda mengurangi penyalinan set data di antara layanan penyimpanan. Namun, ada beberapa pengecualian untuk aturan umum ini, yang akan dijelaskan nanti dalam panduan ini.
Beberapa solusi penyimpanan berfungsi lebih baik daripada yang lain pada setiap tahap dan mungkin perlu digabungkan dengan pilihan penyimpanan tambahan untuk mendapatkan hasil terbaik. Efektivitas pilihan penyimpanan bergantung pada properti set data, skala resource komputasi dan penyimpanan yang diperlukan, latensi, serta faktor lainnya. Tabel berikut menjelaskan tahapan dan ringkasan singkat pilihan penyimpanan yang direkomendasikan untuk setiap tahap. Untuk representasi visual tabel ini dan detail tambahan, lihat hierarki keputusan.
Tabel 1: Rekomendasi penyimpanan untuk tahapan dan langkah workload AI dan ML
| Tahap | Langkah | Rekomendasi penyimpanan |
|---|---|---|
Persiapan |
Persiapan data
|
Cloud Storage
Zona Filestore
|
Kereta |
|
Cloud Storage
Cloud Storage dengan SSD Lokal atau Filestore
Filestore
|
|
Cloud Storage
Zona Filestore
|
|
Tayangkan |
|
Cloud Storage
Filestore
|
Mengarsipkan |
|
Cloud Storage
|
Untuk detail selengkapnya tentang asumsi yang mendasari tabel ini, lihat bagian berikut:
- Kriteria
- Opsi penyimpanan
- Petakan pilihan penyimpanan Anda ke tahapan AI dan ML
- Rekomendasi penyimpanan untuk AI dan ML
Kriteria
Untuk mempersempit pilihan opsi penyimpanan yang akan digunakan untuk workload AI dan ML Anda, mulailah dengan menjawab pertanyaan-pertanyaan berikut:
- Apakah ukuran permintaan AI dan ML I/O serta ukuran file Anda berukuran kecil, sedang, atau besar?
- Apakah beban kerja AI dan ML Anda sensitif terhadap latensi I/O dan waktu ke byte pertama (TTFB)?
- Apakah Anda memerlukan throughput baca dan tulis yang tinggi untuk klien tunggal, klien gabungan, atau keduanya?
- Berapa jumlah Cloud GPU atau Cloud TPU terbanyak yang diperlukan oleh satu workload pelatihan AI dan ML terbesar Anda?
Selain menjawab pertanyaan sebelumnya, Anda juga perlu mengetahui opsi komputasi dan akselerator yang dapat dipilih untuk membantu mengoptimalkan workload AI dan ML.
Pertimbangan platform komputasi
Google Cloud mendukung tiga metode utama untuk menjalankan workload AI dan ML:
- Compute Engine: Virtual machine (VM) mendukung semua layanan penyimpanan yang dikelola Google dan penawaran partner. Compute Engine memberikan dukungan untuk SSD Lokal, Persistent Disk, Cloud Storage, Cloud Storage FUSE, Volume NetApp, dan Filestore. Untuk tugas pelatihan skala besar di Compute Engine, Google telah berpartner dengan SchedMD untuk memberikan peningkatan kualitas penjadwal Slurm.
Google Kubernetes Engine (GKE): GKE adalah platform populer untuk AI yang terintegrasi dengan framework, workload, dan alat pemrosesan data populer. GKE memberikan dukungan untuk SSD Lokal, volume persisten, Cloud Storage FUSE, dan Filestore.
Vertex AI: Vertex AI adalah platform AI terkelola sepenuhnya yang menyediakan solusi end-to-end untuk workload AI dan ML. Vertex AI mendukung Cloud Storage dan penyimpanan berbasis file Network File System (NFS), seperti Filestore dan NetApp Volumes.
Untuk Compute Engine dan GKE, sebaiknya gunakan HPC Toolkit untuk men-deploy cluster siap pakai yang dapat diulang dan yang mengikuti praktik terbaik Google Cloud.
Pertimbangan akselerator
Saat memilih pilihan penyimpanan untuk workload AI dan ML, Anda juga harus memilih opsi pemrosesan akselerator yang sesuai untuk tugas Anda. Google Cloud mendukung dua pilihan akselerator: GPU NVIDIA Cloud dan TPU Google Cloud yang dikembangkan khusus. Kedua jenis akselerator ini adalah application-specific integrated circuits (ASIC) yang digunakan untuk memproses workload machine learning secara lebih efisien daripada prosesor standar.
Ada beberapa perbedaan penyimpanan penting antara Cloud GPU dan akselerator Cloud TPU. Instance yang menggunakan Cloud GPU mendukung SSD Lokal dengan throughput penyimpanan jarak jauh hingga 200 GBps yang tersedia. Node dan VM Cloud TPU tidak mendukung SSD Lokal, dan hanya mengandalkan akses penyimpanan jarak jauh.
Untuk mengetahui informasi selengkapnya tentang jenis mesin yang dioptimalkan akselerator, lihat Kelompok mesin yang dioptimalkan akselerator. Untuk mengetahui informasi selengkapnya tentang Cloud GPU, lihat Platform Cloud GPU. Untuk mengetahui informasi selengkapnya tentang Cloud TPU, lihat Pengantar Cloud TPU. Untuk mengetahui informasi selengkapnya tentang cara memilih antara Cloud TPU dan Cloud GPU, lihat Kapan harus menggunakan Cloud TPU.
Opsi penyimpanan
Seperti yang dirangkum sebelumnya dalam Tabel 1, gunakan penyimpanan objek atau penyimpanan file dengan workload AI dan ML Anda lalu lengkapi opsi penyimpanan ini dengan block storage. Gambar 2 menunjukkan tiga opsi umum yang dapat Anda pertimbangkan saat memilih pilihan penyimpanan awal untuk workload AI dan ML Anda: Cloud Storage, Filestore, dan Google Cloud NetApp Volumes.
Gambar 2: Layanan penyimpanan sesuai AI dan ML yang ditawarkan oleh Google Cloud
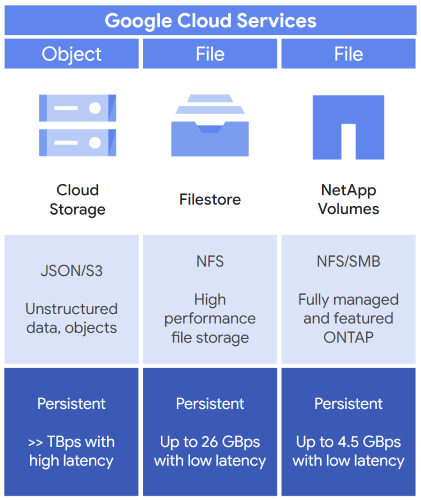
Jika Anda memerlukan penyimpanan objek, pilih Cloud Storage. Cloud Storage menyediakan hal berikut:
- Lokasi penyimpanan untuk data dan objek yang tidak terstruktur.
- API, seperti Cloud Storage JSON API, untuk mengakses bucket penyimpanan Anda.
- Penyimpanan persisten untuk menyimpan data Anda.
- Throughput terabyte per detik, tetapi memerlukan latensi penyimpanan yang lebih tinggi.
Jika memerlukan penyimpanan file, Anda memiliki dua pilihan, yaitu Filestore dan NetApp Volumes, yang menawarkan hal berikut:
- Filestore
- Penyimpanan file perusahaan berperforma tinggi berdasarkan NFS.
- Penyimpanan persisten untuk menyimpan data Anda.
- Latensi penyimpanan rendah dan throughput 26 GBps.
- NetApp Volumes
- Penyimpanan file yang kompatibel dengan NFS dan Server Message Block (SMB).
- Dapat dikelola dengan opsi untuk menggunakan alat software penyimpanan ONTAP NetApp.
- Penyimpanan persisten untuk menyimpan data Anda.
- Throughput 4,5 GBps.
Gunakan opsi penyimpanan berikut sebagai pilihan pertama Anda untuk workload AI dan ML:
Gunakan opsi penyimpanan berikut untuk menambah workload AI dan ML Anda:
Jika perlu mentransfer data di antara opsi penyimpanan ini, Anda dapat menggunakan alat transfer data.
Cloud Storage
Cloud Storage adalah layanan penyimpanan objek terkelola sepenuhnya yang berfokus pada persiapan data, pelatihan model AI, penayangan data, pencadangan, dan pengarsipan untuk data tidak terstruktur. Beberapa manfaat Cloud Storage antara lain sebagai berikut:
- Kapasitas penyimpanan tak terbatas yang diskalakan hingga exabyte secara global
- Performa throughput ultra tinggi
- Opsi penyimpanan regional dan dual-region untuk workload AI dan ML
Cloud Storage menskalakan throughput hingga terabyte per detik dan seterusnya, tetapi memiliki latensi yang relatif lebih tinggi (puluhan milidetik) daripada Filestore atau sistem file lokal. Throughput thread individual dibatasi hingga sekitar 100-200 MB per detik, yang berarti throughput tinggi hanya dapat dicapai dengan menggunakan ratusan hingga ribuan thread individual. Selain itu, throughput tinggi juga memerlukan penggunaan file yang besar dan permintaan I/O yang besar.
Cloud Storage mendukung library klien dalam berbagai bahasa pemrograman, tetapi juga mendukung Cloud Storage FUSE. Cloud Storage FUSE dapat digunakan untuk memasang bucket Cloud Storage ke sistem file lokal. Dengan Cloud Storage FUSE, aplikasi Anda dapat menggunakan API sistem file standar untuk membaca dari bucket atau menulis ke bucket. Anda dapat menyimpan dan mengakses data pelatihan, model, dan checkpoint dengan skala, keterjangkauan, dan performa Cloud Storage.
Untuk mempelajari Cloud Storage lebih lanjut, gunakan referensi berikut:
- Ringkasan produk Cloud Storage
- Panduan distribusi akses dan rasio permintaan
- FUSE Cloud Storage
- Performa dan praktik terbaik Cloud Storage FUSE
Filestore
Filestore adalah layanan penyimpanan berbasis file NFS yang terkelola sepenuhnya. Tingkat layanan Filestore yang digunakan untuk workload AI dan ML mencakup:
- Tingkat perusahaan: Digunakan untuk workload penting yang memerlukan ketersediaan regional.
- Tingkat zona: Digunakan untuk aplikasi berperforma tinggi yang memerlukan ketersediaan zona dengan persyaratan performa throughput dan IOPS tinggi.
- Paket dasar: Digunakan untuk berbagi file, pengembangan software, hosting web, serta beban kerja AI dan ML dasar.
Filestore memberikan performa I/O latensi rendah. Ini adalah pilihan yang baik untuk set data dengan persyaratan akses I/O kecil atau file kecil. Namun, Filestore juga dapat menangani I/O besar atau kasus penggunaan file besar sesuai kebutuhan. Filestore dapat meningkatkan skala hingga sekitar 100 TB. Untuk workload pelatihan AI yang membaca data berulang kali, Anda dapat meningkatkan throughput baca menggunakan FS-Cache dengan SSD Lokal.
Untuk informasi selengkapnya tentang Filestore, lihat Ringkasan Filestore. Untuk mengetahui informasi selengkapnya tentang tingkat layanan Filestore, lihat Tingkat layanan. Untuk mengetahui informasi selengkapnya tentang performa Filestore, lihat Mengoptimalkan dan menguji performa instance.
Google Cloud NetApp Volumes
NetApp Volumes adalah layanan terkelola sepenuhnya dengan fitur pengelolaan data lanjutan yang mendukung lingkungan NFS, SMB, dan multiprotokol. NetApp Volumes mendukung latensi rendah, volume multi-tebibyte, dan throughput gigabyte per detik.
Untuk mengetahui informasi selengkapnya tentang NetApp Volumes, baca artikel Apa yang dimaksud dengan Google Cloud NetApp Volumes? Untuk mengetahui informasi selengkapnya tentang performa NetApp Volumes, lihat Performa yang diharapkan.
Block storage
Setelah memilih pilihan penyimpanan utama, Anda dapat menggunakan block storage untuk meningkatkan performa, mentransfer data antar-opsi penyimpanan, dan memanfaatkan operasi latensi rendah. Anda memiliki dua opsi penyimpanan dengan block storage: SSD Lokal dan Persistent Disk.
SSD Lokal
SSD lokal menyediakan penyimpanan lokal langsung ke VM atau container. Sebagian besar jenis mesin Google Cloud yang berisi Cloud GPU menyertakan sejumlah SSD Lokal. Karena disk SSD Lokal terpasang secara fisik ke Cloud GPU, disk tersebut memberikan akses latensi rendah dengan potensi jutaan IOPS. Sebaliknya, instance berbasis Cloud TPU tidak menyertakan SSD Lokal.
Meskipun SSD Lokal memberikan performa tinggi, setiap instance penyimpanan bersifat sementara. Dengan demikian, data yang disimpan di drive SSD Lokal akan hilang saat Anda menghentikan atau menghapus instance. Karena sifat efemeral SSD Lokal, pertimbangkan jenis penyimpanan lain saat data Anda memerlukan ketahanan yang lebih baik.
Namun, jika jumlah data pelatihan sangat kecil, biasanya data pelatihan disalin dari Cloud Storage ke SSD Lokal GPU. Alasannya adalah SSD Lokal memberikan latensi I/O yang lebih rendah dan mengurangi waktu pelatihan.
Untuk mengetahui informasi selengkapnya tentang SSD Lokal, lihat Tentang SSD Lokal. Untuk mengetahui informasi selengkapnya tentang jumlah kapasitas SSD Lokal yang tersedia dengan jenis instance Cloud GPU, lihat platform GPU.
Persistent Disk
Persistent Disk adalah layanan block storage jaringan dengan rangkaian kemampuan pengelolaan dan persistensi data yang komprehensif. Selain digunakan sebagai boot disk, Anda dapat menggunakan Persistent Disk dengan workload AI, seperti penyimpanan scratch. Persistent Disk tersedia dalam opsi berikut:
- Standard, yang menyediakan block storage yang efisien dan andal.
- Seimbang, yang menyediakan block storage yang hemat biaya dan andal.
- SSD, yang menyediakan block storage yang cepat dan andal.
- Extreme, yang memberikan opsi block storage performa tertinggi dengan IOPS yang dapat disesuaikan.
Untuk mengetahui informasi selengkapnya tentang Persistent Disk, lihat Persistent Disk.
Alat transfer data
Saat Anda melakukan tugas AI dan ML, ada kalanya Anda perlu menyalin data dari satu lokasi ke lokasi lainnya. Misalnya, jika data dimulai di Cloud Storage, Anda dapat memindahkannya ke tempat lain untuk melatih model, lalu menyalin snapshot checkpoint atau model yang telah dilatih kembali ke Cloud Storage. Anda juga dapat melakukan sebagian besar tugas di Filestore, lalu memindahkan data dan model ke Cloud Storage untuk tujuan pengarsipan. Bagian ini membahas opsi Anda untuk memindahkan data antarlayanan penyimpanan di Google Cloud.
Storage Transfer Service
Dengan Storage Transfer Service, Anda dapat mentransfer data antara Volume Cloud Storage, Filestore, dan NetApp. Dengan layanan yang terkelola sepenuhnya ini, Anda juga dapat menyalin data antara penyimpanan file lokal dan repositori penyimpanan objek, penyimpanan Google Cloud Anda, serta dari penyedia cloud lainnya. Dengan Storage Transfer Service, Anda dapat menyalin data dengan aman dari lokasi sumber ke lokasi target, serta melakukan transfer data yang berubah secara berkala. API ini juga menyediakan validasi integritas data, percobaan ulang otomatis, dan load balancing.
Untuk informasi selengkapnya tentang Storage Transfer Service, lihat Apa yang dimaksud dengan Storage Transfer Service?
Opsi antarmuka command line
Saat memindahkan data antara Filestore dan Cloud Storage, Anda dapat menggunakan alat berikut:
- gcloud storage (direkomendasikan): Membuat dan mengelola bucket dan objek Cloud Storage dengan throughput optimal dan rangkaian lengkap perintah gcloud CLI.
- gsutil: Mengelola dan memelihara komponen Cloud Storage. Memerlukan fine-tuning untuk mencapai throughput yang lebih baik.
Petakan pilihan penyimpanan Anda ke tahapan AI dan ML
Bagian ini dikembangkan dari ringkasan yang diberikan di Tabel 1 untuk mempelajari rekomendasi dan panduan spesifik untuk setiap tahap workload AI dan ML. Tujuannya adalah untuk membantu Anda memahami alasan pilihan ini dan memilih opsi penyimpanan terbaik untuk setiap tahap AI dan ML. Analisis ini menghasilkan tiga rekomendasi utama yang dibahas di bagian ini, Rekomendasi penyimpanan untuk AI dan ML.
Gambar berikut memberikan pohon keputusan yang menunjukkan opsi penyimpanan yang direkomendasikan untuk empat tahap utama workload AI dan ML. Diagram ini diikuti dengan penjelasan mendetail tentang setiap tahap dan pilihan yang dapat Anda buat pada setiap tahap.
Gambar 3: Pilihan penyimpanan untuk setiap tahap AI dan ML
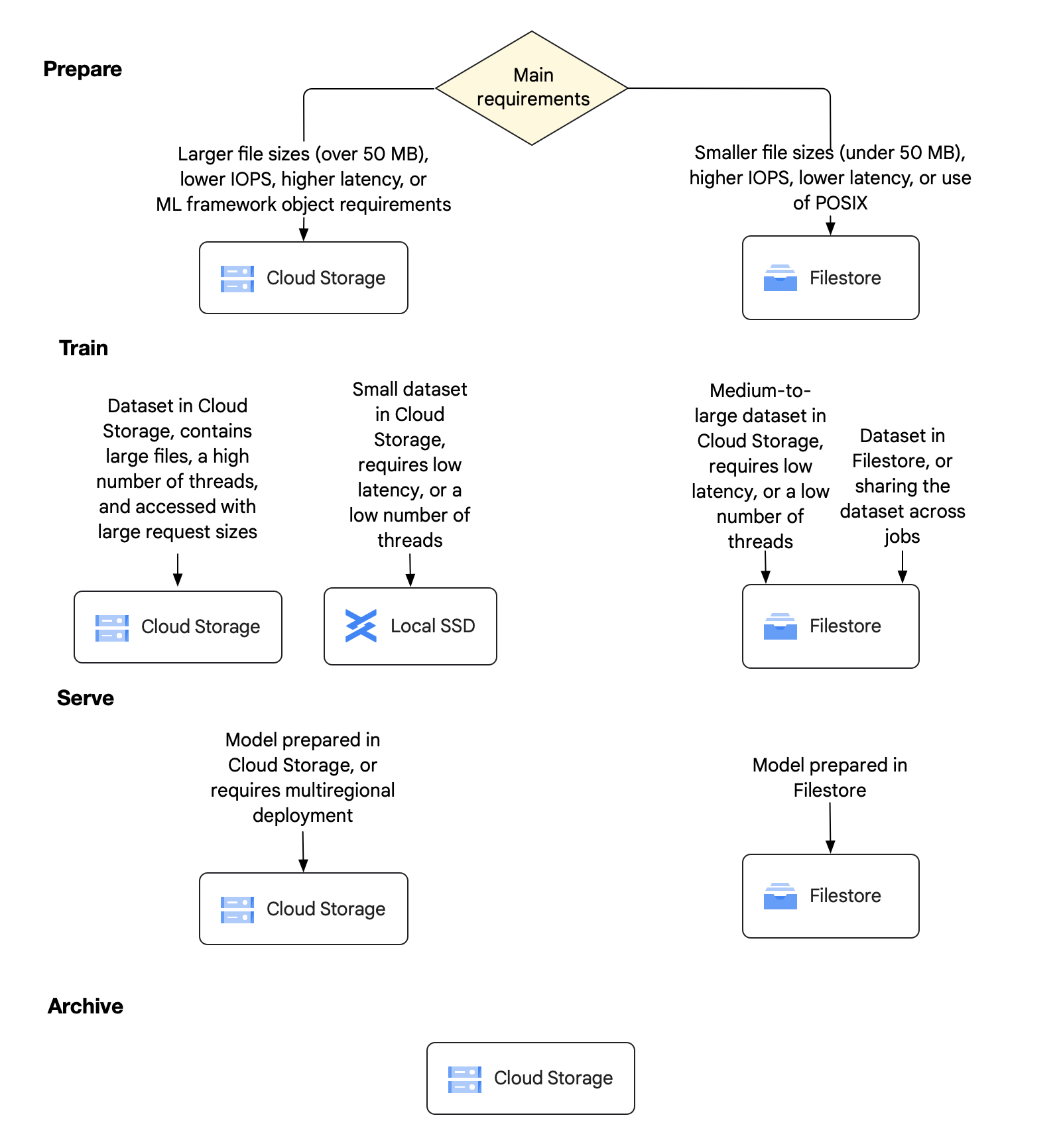
Persiapan
Pada tahap awal ini, Anda harus memilih apakah ingin menggunakan Cloud Storage atau Filestore sebagai sumber tepercaya yang persisten untuk data Anda. Anda juga dapat memilih potensi pengoptimalan untuk pelatihan yang menggunakan banyak data. Perlu diketahui bahwa tim yang berbeda di organisasi Anda dapat memiliki jenis workload dan set data yang bervariasi, sehingga tim tersebut dapat mengambil keputusan penyimpanan yang berbeda. Untuk mengakomodasi beragam kebutuhan ini, Anda dapat memadupadankan pilihan penyimpanan antara Cloud Storage dan Filestore.
Cloud Storage untuk tahap persiapan
- Beban kerja Anda berisi file berukuran besar berukuran 50 MB atau lebih.
- Beban kerja Anda memerlukan IOPS yang lebih rendah.
Beban kerja Anda dapat menoleransi latensi penyimpanan yang lebih tinggi dalam puluhan milidetik.
Anda perlu mendapatkan akses ke set data melalui Cloud Storage API, atau Cloud Storage FUSE dan subset file API.
Untuk mengoptimalkan beban kerja di Cloud Storage, Anda dapat memilih penyimpanan regional dan menempatkan bucket di region yang sama dengan resource komputasi Anda. Namun, jika Anda memerlukan keandalan yang lebih tinggi, atau jika menggunakan akselerator yang terletak di dua region berbeda, sebaiknya pilih penyimpanan dual-region.
Filestore untuk tahap persiapan
Anda harus memilih Filestore untuk mempersiapkan data jika salah satu kondisi berikut berlaku:
- Beban kerja Anda berisi ukuran file yang lebih kecil, yaitu kurang dari 50 MB.
- Beban kerja Anda memerlukan IOPS yang lebih tinggi.
- Workload Anda memerlukan latensi yang lebih rendah, kurang dari 1 milidetik, guna memenuhi persyaratan penyimpanan untuk I/O acak dan akses metadata.
- Pengguna Anda membutuhkan pengalaman seperti desktop dengan dukungan POSIX penuh untuk melihat dan mengelola data.
- Pengguna Anda perlu melakukan tugas lainnya, seperti pengembangan software.
Pertimbangan lain untuk tahap persiapan
Jika Anda kesulitan memilih opsi pada tahap ini, pertimbangkan poin-poin berikut untuk membantu Anda membuat keputusan:
- Jika Anda ingin menggunakan framework AI dan ML lain, seperti Dataflow, Spark, atau BigQuery pada set data, Cloud Storage adalah pilihan logis karena integrasi kustom yang dimilikinya dengan jenis framework ini.
- Filestore memiliki kapasitas maksimum sekitar 100 TB. Jika Anda perlu melatih model dengan set data yang lebih besar dari ini, atau jika Anda tidak dapat memecah set menjadi beberapa instance 100 TB, Cloud Storage adalah pilihan yang lebih baik.
Selama fase persiapan data, banyak pengguna mengatur ulang data mereka menjadi bagian besar untuk meningkatkan efisiensi akses dan menghindari permintaan baca acak. Untuk lebih mengurangi persyaratan performa I/O pada sistem penyimpanan, banyak pengguna menggunakan pipeline, pengoptimalan pelatihan untuk meningkatkan jumlah thread I/O, atau keduanya.
Latih
Pada tahap pelatihan, Anda biasanya menggunakan kembali opsi penyimpanan utama yang Anda pilih untuk tahap persiapan. Jika pilihan penyimpanan utama Anda tidak dapat menangani beban kerja pelatihan saja, Anda mungkin perlu menambah penyimpanan utama. Anda dapat menambahkan penyimpanan tambahan sesuai kebutuhan, seperti SSD Lokal, untuk menyeimbangkan beban kerja.
Selain memberikan rekomendasi untuk menggunakan Cloud Storage atau Filestore pada tahap ini, bagian ini juga memberikan detail lebih lanjut tentang rekomendasi ini. Detailnya meliputi:
- Panduan untuk ukuran file dan ukuran permintaan
- Saran tentang kapan perlu melengkapi pilihan penyimpanan utama Anda
- Penjelasan detail implementasi untuk dua workload utama pada tahap ini—pemuatan data, serta checkpointing dan mulai ulang
Cloud Storage untuk tahap pelatihan
Alasan utama untuk memilih Cloud Storage saat melatih data Anda meliputi hal-hal berikut:
- Jika Anda menggunakan Cloud Storage saat menyiapkan data, sebaiknya latih data di Cloud Storage.
- Cloud Storage adalah pilihan tepat untuk throughput, beban kerja yang tidak memerlukan throughput VM tunggal yang tinggi, atau beban kerja yang menggunakan banyak thread untuk meningkatkan throughput sesuai kebutuhan.
Cloud Storage dengan SSD Lokal atau Filestore untuk tahap pelatihan
Alasan utama untuk memilih Cloud Storage dengan SSD Lokal atau Filestore saat melatih data terjadi saat Anda perlu mendukung permintaan I/O kecil atau file kecil. Di kasus ini, Anda dapat melengkapi tugas pelatihan Cloud Storage dengan memindahkan sebagian data ke SSD Lokal atau Zonal Filestore.
Filestore untuk panggung kereta
Alasan utama untuk memilih Filestore saat melatih data Anda meliputi hal-hal berikut:
- Jika menggunakan Filestore saat menyiapkan data, pada umumnya, Anda harus terus melatih data di Filestore.
- Filestore adalah pilihan yang tepat untuk latensi rendah, throughput per klien yang tinggi, dan aplikasi yang menggunakan jumlah thread rendah tetapi tetap memerlukan performa tinggi.
- Jika Anda perlu menambah tugas pelatihan di Filestore, pertimbangkan untuk membuat cache SSD Lokal sesuai kebutuhan.
Ukuran file dan ukuran permintaan
Setelah set data siap untuk pelatihan, ada dua opsi utama yang dapat membantu Anda mengevaluasi berbagai opsi penyimpanan.
- Set data yang berisi file besar dan diakses dengan ukuran permintaan besar
- Set data yang berisi file berukuran kecil hingga sedang, atau diakses dengan ukuran permintaan kecil
Set data yang berisi file besar dan diakses dengan ukuran permintaan besar
Dalam opsi ini, tugas pelatihan sebagian besar terdiri dari file berukuran lebih besar sebesar 50 MB atau lebih. Tugas pelatihan menyerap file berukuran 1 MB hingga 16 MB per permintaan. Secara umum, kami merekomendasikan Cloud Storage dengan Cloud Storage FUSE untuk opsi ini karena filenya cukup besar sehingga Cloud Storage seharusnya dapat mempertahankan akselerator tetap disediakan. Perlu diingat bahwa Anda mungkin memerlukan ratusan hingga ribuan thread untuk mencapai performa maksimum dengan opsi ini.
Namun, jika Anda memerlukan POSIX API lengkap untuk aplikasi lain, atau beban kerja Anda tidak sesuai untuk banyaknya thread yang diperlukan, maka Filestore adalah alternatif yang baik.
Set data yang berisi file berukuran kecil hingga sedang, atau yang diakses dengan ukuran permintaan kecil
Dengan opsi ini, Anda dapat mengklasifikasikan tugas pelatihan dalam salah satu dari dua cara berikut:
- Banyak file berukuran kecil hingga sedang yang berukuran kurang dari 50 MB.
- Set data dengan file yang lebih besar, tetapi data dibaca secara berurutan atau acak dengan ukuran permintaan baca yang relatif kecil (misalnya, kurang dari 1 MB). Contoh kasus penggunaan ini adalah ketika sistem membaca kurang dari 100 KB sekaligus dari file multi-gigabyte atau multi-terabyte.
Jika Anda sudah menggunakan Filestore untuk kemampuan POSIX, sebaiknya simpan data Anda di Filestore untuk pelatihan. Filestore menawarkan akses latensi I/O yang rendah ke data. Latensi yang lebih rendah ini dapat mengurangi waktu pelatihan secara keseluruhan dan dapat menurunkan biaya pelatihan model Anda.
Jika Anda menggunakan Cloud Storage untuk menyimpan data, sebaiknya salin data ke SSD Lokal atau Filestore sebelum pelatihan.
Pemuatan data
Selama pemuatan data, Cloud GPU atau Cloud TPU mengimpor batch data berulang kali untuk melatih model. Fase ini dapat disimpan di cache, bergantung pada ukuran batch dan urutan Anda memintanya. Tujuan Anda pada tahap ini adalah melatih model dengan efisiensi maksimum, tetapi dengan biaya terendah.
Jika ukuran data pelatihan Anda diskalakan hingga petabyte, data tersebut mungkin perlu dibaca ulang beberapa kali. Skala semacam itu memerlukan pemrosesan intensif oleh akselerator GPU atau TPU. Namun, Anda perlu memastikan bahwa Cloud GPU dan Cloud TPU tidak nonaktif, tetapi memproses data Anda secara aktif. Jika tidak, Anda akan membayar akselerator nonaktif yang mahal saat menyalin data dari satu lokasi ke lokasi lain.
Untuk pemuatan data, pertimbangkan hal berikut:
- Paralelisme: Ada banyak cara untuk paralelkan pelatihan, dan masing-masing cara tersebut dapat berdampak pada performa penyimpanan keseluruhan yang diperlukan dan perlunya menyimpan data dalam cache secara lokal di setiap instance.
- Jumlah maksimum Cloud GPU atau Cloud TPU untuk satu tugas pelatihan: Seiring peningkatan jumlah akselerator dan VM, dampaknya terhadap sistem penyimpanan dapat menjadi signifikan dan dapat mengakibatkan peningkatan biaya jika Cloud GPU atau Cloud TPU tidak ada aktivitas. Namun, ada cara untuk meminimalkan biaya saat Anda meningkatkan jumlah akselerator. Bergantung pada jenis paralelisme yang digunakan, Anda dapat meminimalkan biaya dengan meningkatkan persyaratan throughput baca agregat yang diperlukan untuk menghindari akselerator nonaktif.
Untuk mendukung peningkatan ini di Cloud Storage atau Filestore, Anda perlu menambahkan SSD Lokal ke setiap instance sehingga Anda dapat memindahkan I/O dari sistem penyimpanan yang kelebihan beban.
Namun, pramuat data ke SSD Lokal setiap instance dari Cloud Storage memiliki tantangannya sendiri. Anda berisiko menimbulkan peningkatan biaya untuk akselerator nonaktif saat data sedang ditransfer. Jika waktu transfer data dan biaya tidak ada aktivitas akselerator tinggi, Anda mungkin dapat menurunkan biaya menggunakan Filestore dengan SSD Lokal.
- Jumlah Cloud GPU per instance: Saat Anda men-deploy lebih banyak Cloud GPU ke setiap instance, Anda dapat meningkatkan throughput antar-Cloud GPU dengan NVLink. Namun, throughput jaringan penyimpanan dan SSD Lokal yang tersedia tidak selalu meningkat secara linear.
- Pengoptimalan penyimpanan dan aplikasi: Opsi penyimpanan dan aplikasi memiliki persyaratan performa tertentu agar dapat berjalan secara optimal. Pastikan untuk menyeimbangkan persyaratan sistem penyimpanan dan aplikasi ini dengan pengoptimalan pemuatan data Anda, seperti membuat Cloud GPU atau Cloud TPU tetap sibuk dan beroperasi secara efisien.
Pemeriksaan dan mulai ulang
Untuk checkpointing dan memulai ulang, tugas pelatihan harus menyimpan statusnya secara berkala agar dapat pulih dengan cepat dari kegagalan instance. Jika terjadi kegagalan, tugas harus dimulai ulang, menyerap checkpoint terbaru, lalu melanjutkan pelatihan. Mekanisme yang tepat yang digunakan untuk membuat dan menyerap checkpoint biasanya khusus untuk framework, seperti TensorFlow atau PyTorch. Beberapa pengguna telah membuat framework yang kompleks untuk meningkatkan efisiensi checkpointing. Framework yang kompleks ini memungkinkan mereka lebih sering melakukan checkpoint.
Namun, sebagian besar pengguna biasanya menggunakan penyimpanan bersama, seperti Cloud Storage atau Filestore. Saat menyimpan checkpoint, Anda hanya perlu menyimpan tiga hingga lima checkpoint dalam satu waktu. Workload checkpoint cenderung terdiri dari sebagian besar operasi tulis, beberapa penghapusan, dan idealnya, pembacaan jarang terjadi saat kegagalan terjadi. Selama pemulihan, pola I/O mencakup penulisan yang intensif dan sering, penghapusan yang sering, dan pembacaan yang sering pada checkpoint.
Anda juga perlu mempertimbangkan ukuran checkpoint yang perlu dibuat oleh setiap GPU atau TPU. Ukuran checkpoint menentukan throughput operasi tulis yang diperlukan untuk menyelesaikan tugas pelatihan dengan cara yang hemat biaya dan tepat waktu.
Untuk meminimalkan biaya, pertimbangkan untuk meningkatkan item berikut:
- Frekuensi checkpoint
- Throughput tulis agregat yang diperlukan untuk checkpoint
- Efisiensi memulai ulang
Inferensikan
Saat Anda menyajikan model, yang juga dikenal sebagai inferensi AI, pola I/O utama bersifat hanya baca untuk memuat model ke dalam Cloud GPU atau memori Cloud TPU. Tujuan Anda pada tahap ini adalah menjalankan model dalam produksi. Model ini jauh lebih kecil daripada data pelatihan, sehingga Anda dapat mereplikasi dan menskalakan model di beberapa instance. Ketersediaan tinggi dan perlindungan terhadap kegagalan zona dan regional sangat penting pada tahap ini, sehingga Anda harus memastikan bahwa model Anda tersedia untuk berbagai skenario kegagalan.
Untuk banyak kasus penggunaan AI generatif, data input ke model mungkin cukup kecil dan mungkin tidak perlu disimpan secara persisten. Dalam kasus lain, Anda mungkin perlu menjalankan data dalam jumlah besar pada model (misalnya set data ilmiah). Dalam hal ini, Anda perlu memilih opsi yang dapat mempertahankan Cloud GPU atau Cloud TPU selama analisis set data, serta memilih lokasi yang persisten untuk menyimpan hasil inferensi.
Ada dua pilihan utama ketika Anda menyajikan model Anda.
Cloud Storage untuk tahap penayangan
Berikut adalah alasan utama untuk memilih Cloud Storage saat menyajikan data:
- Saat melatih model di Cloud Storage, Anda dapat menghemat biaya migrasi dengan membiarkan model di Cloud Storage saat menayangkannya.
- Anda dapat menyimpan konten yang dihasilkan di Cloud Storage.
- Cloud Storage adalah pilihan yang baik saat inferensi AI terjadi di beberapa region.
- Anda dapat menggunakan bucket dual-region dan multi-region untuk memberikan ketersediaan model di seluruh kegagalan regional.
Filestore untuk tahap penayangan
Alasan utama untuk memilih Filestore saat menyajikan data Anda meliputi:
- Saat melatih model di Filestore, Anda dapat menghemat biaya migrasi dengan membiarkan model di Filestore saat Anda menayangkannya.
- Karena perjanjian tingkat layanan (SLA)-nya memberikan ketersediaan 99,99%, tingkat layanan Filestore Enterprise adalah pilihan yang tepat untuk ketersediaan tinggi saat Anda ingin menyajikan model di antara beberapa zona dalam satu region.
- Tingkat layanan Filestore Zonal mungkin merupakan pilihan dengan biaya yang lebih rendah yang wajar, tetapi hanya jika ketersediaan tinggi bukan merupakan persyaratan untuk workload AI dan ML Anda.
- Jika memerlukan pemulihan lintas region, Anda dapat menyimpan model di lokasi pencadangan jarak jauh atau bucket Cloud Storage jarak jauh, lalu memulihkan model sesuai kebutuhan.
- Filestore menawarkan opsi yang andal dan sangat tersedia yang memberikan akses latensi rendah ke model Anda saat Anda membuat file kecil atau memerlukan API file.
Arsip
Tahap arsip memiliki pola I/O "tulis sekali, jarang dibaca". Sasaran Anda adalah menyimpan berbagai set data pelatihan dan berbagai versi model yang Anda hasilkan. Anda dapat menggunakan versi data dan model inkremental ini untuk keperluan pencadangan dan pemulihan dari bencana (disaster recovery). Anda juga harus menyimpan item ini di lokasi yang tahan lama untuk jangka waktu yang lama. Meskipun Anda mungkin tidak memerlukan akses ke data dan model terlalu sering, Anda ingin item ini tersedia saat Anda membutuhkannya.
Karena ketahanannya yang ekstrem, skalanya yang luas, dan biayanya yang rendah, pilihan terbaik untuk menyimpan data objek dalam jangka waktu yang lama adalah Cloud Storage. Bergantung pada frekuensi Anda mengakses set data, model, dan file cadangan, Cloud Storage menawarkan pengoptimalan biaya melalui berbagai kelas penyimpanan dengan pendekatan berikut:
- Tempatkan data yang sering diakses di Penyimpanan standar.
- Simpan data yang Anda akses setiap bulan di Nearline Storage.
- Simpan data yang Anda akses setiap tiga bulan di Coldline Storage.
- Simpan data yang Anda akses setahun sekali di penyimpanan Arsip.
Dengan pengelolaan siklus proses objek, Anda dapat membuat kebijakan untuk memindahkan data ke kelas penyimpanan yang lebih jarang diakses atau menghapus data berdasarkan kriteria tertentu. Jika tidak yakin seberapa sering Anda akan mengakses data, Anda dapat menggunakan fitur Autoclass untuk memindahkan data antar-class penyimpanan secara otomatis, berdasarkan pola akses Anda.
Jika data Anda berada di Filestore, memindahkan data ke Cloud Storage untuk tujuan pengarsipan sering kali masuk akal. Namun, Anda dapat memberikan perlindungan tambahan untuk data Filestore dengan membuat cadangan Filestore di region lain. Anda juga dapat mengambil snapshot Filestore untuk pemulihan file lokal dan sistem file. Untuk mengetahui informasi selengkapnya tentang cadangan Filestore, lihat Ringkasan cadangan. Untuk mengetahui informasi selengkapnya tentang snapshot Filestore, lihat Ringkasan snapshot.
Rekomendasi penyimpanan untuk AI dan ML
Bagian ini merangkum analisis yang diberikan di bagian sebelumnya, Memetakan pilihan penyimpanan Anda ke tahap AI dan ML. Panduan ini memberikan detail tentang tiga kombinasi opsi penyimpanan utama yang kami rekomendasikan untuk sebagian besar workload AI dan ML. Ketiga opsi tersebut adalah sebagai berikut:
- Pilih Cloud Storage
- Pilih Cloud Storage dan SSD Lokal atau Filestore
- Pilih Filestore dan SSD Lokal Opsional
Pilih Cloud Storage
Cloud Storage memberikan penawaran penyimpanan dengan biaya per kapasitas paling rendah jika dibandingkan dengan semua penawaran penyimpanan lainnya. Layanan ini diskalakan ke sejumlah besar klien, menyediakan aksesibilitas dan ketersediaan regional dan dual-region, serta dapat diakses melalui Cloud Storage FUSE. Anda harus memilih penyimpanan regional saat platform komputasi untuk pelatihan berada di region yang sama, dan memilih penyimpanan dual-region jika Anda memerlukan keandalan yang lebih tinggi atau menggunakan Cloud GPU atau Cloud TPU yang terletak di dua region berbeda.
Cloud Storage adalah pilihan terbaik untuk retensi data jangka panjang, dan untuk workload dengan persyaratan performa penyimpanan yang lebih rendah. Namun, opsi lain seperti Filestore dan SSD Lokal adalah alternatif yang tepat dalam kasus tertentu saat Anda memerlukan dukungan POSIX penuh atau Cloud Storage menjadi bottleneck performa.
Memilih Cloud Storage dengan SSD Lokal atau Filestore
Untuk pelatihan atau checkpoint intensif data dan memulai ulang workload, sebaiknya gunakan penawaran penyimpanan yang lebih cepat selama fase pelatihan intensif I/O. Pilihan umum termasuk menyalin data ke SSD Lokal atau Filestore. Tindakan ini akan mengurangi runtime tugas secara keseluruhan dengan memastikan Cloud GPU atau Cloud TPU tetap disediakan dengan data dan mencegah instance terhenti saat operasi checkpoint selesai. Selain itu, makin sering Anda membuat checkpoint, makin banyak checkpoint yang tersedia sebagai cadangan. Peningkatan jumlah cadangan ini juga meningkatkan keseluruhan kecepatan penerimaan data yang berguna (juga dikenal sebagai goodput). Kombinasi pengoptimalan prosesor dan peningkatan Goodput ini dapat menurunkan biaya keseluruhan pelatihan model Anda.
Ada beberapa konsekuensi yang perlu dipertimbangkan saat menggunakan SSD Lokal atau Filestore. Bagian berikut menjelaskan beberapa kelebihan dan kelemahan masing-masing platform.
Keuntungan SSD lokal
- Throughput dan IOPS tinggi setelah data ditransfer
- Biaya tambahan rendah hingga minimal
Kekurangan SSD lokal
- Cloud GPU atau Cloud TPU tetap tidak ada aktivitas saat data dimuat.
- Transfer data harus terjadi pada setiap tugas untuk setiap instance.
- Hanya tersedia untuk beberapa jenis instance Cloud GPU.
- Menyediakan kapasitas penyimpanan terbatas.
- Mendukung checkpointing, tetapi Anda harus mentransfer checkpoint secara manual ke opsi penyimpanan yang andal seperti Cloud Storage.
Kelebihan Filestore
- Menyediakan penyimpanan NFS bersama yang memungkinkan data ditransfer satu kali, lalu dibagikan ke berbagai tugas dan pengguna.
- Tidak ada waktu tidak aktif Cloud GPU atau Cloud TPU karena data ditransfer sebelum Anda membayar Cloud GPU atau Cloud TPU.
- Memiliki kapasitas penyimpanan yang besar.
- Mendukung checkpointing cepat untuk ribuan VM.
- Mendukung Cloud GPU, Cloud TPU, dan semua jenis instance Compute Engine lainnya.
Kekurangan Filestore
- Biaya awal yang tinggi; tetapi peningkatan efisiensi komputasi berpotensi mengurangi biaya pelatihan secara keseluruhan.
Pilih Filestore dengan SSD Lokal opsional
Filestore adalah pilihan terbaik untuk workload AI dan ML yang memerlukan latensi rendah dan dukungan POSIX penuh. Selain menjadi pilihan yang direkomendasikan untuk tugas pelatihan I/O berukuran kecil atau file berukuran kecil, Filestore dapat memberikan pengalaman yang responsif untuk notebook AI dan ML, pengembangan software, dan banyak aplikasi lainnya. Anda juga dapat men-deploy Filestore dalam zona untuk pelatihan berperforma tinggi dan penyimpanan checkpoint yang persisten. Men-deploy Filestore di suatu zona juga menawarkan mulai ulang cepat jika terjadi kegagalan. Atau, Anda dapat men-deploy Filestore secara regional untuk mendukung tugas inferensi yang sangat tersedia. Penambahan FS-Cache opsional untuk mendukung caching SSD Lokal memungkinkan pembacaan data pelatihan berulang dengan cepat untuk mengoptimalkan beban kerja.
Langkah selanjutnya
Untuk informasi lebih lanjut tentang opsi penyimpanan serta AI dan ML, lihat referensi berikut:
- Merancang strategi penyimpanan yang optimal untuk workload cloud Anda
- Ringkasan produk Cloud Storage
- FUSE Cloud Storage
- Ringkasan filestore
- Tentang SSD Lokal
- Ringkasan Storage Transfer Service
- Pengantar Vertex AI
- Memperluas keterjangkauan jaringan Vertex AI Pipelines
- Video -- Mengakses set data yang lebih besar dengan lebih cepat dan lebih mudah untuk mempercepat pelatihan model ML Anda di Vertex AI | Google Cloud
- Cloud Storage sebagai Sistem File dalam Pelatihan AI
- Membaca dan menyimpan data untuk pelatihan model kustom di Vertex AI | Blog Google Cloud
Kontributor
Penulis:
- Dean Hildebrand | Direktur Teknis, Kantor CTO
- Sean Derrington | Group Outbound Product Manager, Penyimpanan
- Richard Hendricks | Staf Pusat Arsitektur
Kontributor lain: Kumar Dhanagopal | Developer Solusi Lintas Produk