このドキュメントでは、 Google Cloud リソースから Splunk にログとイベントをストリーミングする、本番環境対応のスケーラブルでフォールト トレラントなログ エクスポート メカニズムの作成に役立つリファレンス アーキテクチャについて説明します。Splunk は、セキュリティとオブザーバビリティの統合プラットフォームを提供する一般的な分析ツールです。実際、ロギングデータは、Splunk Enterprise と Splunk Cloud Platform のいずれかにエクスポートすることを選べます。管理者であれば、IT オペレーションやセキュリティのユースケースにもこのアーキテクチャを使用できます。
このリファレンス アーキテクチャでは、次の図のようなリソース階層を想定しています。組織、フォルダ、プロジェクト レベルのすべての Google Cloud リソースログが集約シンクに収集されます。次に、集約シンクがこれらのログをログ エクスポート パイプラインに送信し、それがログを処理して、Splunk にエクスポートします。

アーキテクチャ
次の図は、このソリューションをデプロイするときに使用するリファレンス アーキテクチャを示しています。この図は、ログデータがGoogle Cloud から Splunk にどのように流れるかを示しています。

このアーキテクチャには次のコンポーネントが含まれています。
- Cloud Logging: プロセスを開始するには、Cloud Logging が組織レベルの集約ログシンクにログを収集し、Pub/Sub に送信します。
- Pub/Sub: Pub/Sub サービスは、ログに単一のトピックとサブスクリプションを作成し、メインの Dataflow パイプラインにログを転送します。
- Dataflow: このリファレンス アーキテクチャには 2 つの Dataflow パイプラインがあります。
- プライマリ Dataflow パイプライン: プロセスの中心にあるメインの Dataflow パイプラインは、Pub/Sub から Splunk へのストリーミング パイプラインであり、Pub/Sub サブスクリプションからログを取得して Splunk に配信します。
- セカンダリ Dataflow パイプライン: プライマリ Dataflow パイプラインと同様に、セカンダリ Dataflow パイプラインは Pub/Sub から Pub/Sub へのストリーミング パイプラインであり、配信が失敗した場合にメッセージを再生します。
- Splunk: プロセスの最後に、Splunk Enterprise または Splunk Cloud Platform が HTTP Event Collector(HEC)として機能し、詳細な分析のためにログを受信します。Splunk をオンプレミスにデプロイすることも、Google Cloud as SaaS として使用することもできます。また、ハイブリッド アプローチも可能です。
ユースケース
このリファレンス アーキテクチャでは、クラウドの push ベースのアプローチを使用します。この push ベースの方法では、Pub/Sub to Splunk Dataflow テンプレートを使用して、ログを Splunk HTTP Event Collector(HEC)にストリーミングします。リファレンス アーキテクチャでは、Dataflow パイプラインの容量計画と、サーバーまたはネットワークに一時的な問題が発生した際に生じる可能性のある配信エラーを処理する方法についても説明します。
このリファレンス アーキテクチャはログに焦点を当てていますが、同じアーキテクチャを使用して、リアルタイムのアセット変更やセキュリティ検出結果など、他のデータをエクスポートすることもできます。 Google Cloud Google Cloud Cloud Logging のログを統合することで、Splunk などの既存のパートナー サービスを統合ログ分析ソリューションとして引き続き使用できます。
データを Splunk にストリーミングする push ベースの方法には、次の利点があります。 Google Cloud
- マネージド サービス。マネージド サービスとして、Dataflow は、ログ エクスポートなどのデータ処理タスク用に必要なリソースを保持します。 Google Cloud
- 分散ワークロード。この方法では、ワークロードを複数のワーカーに分散して並列処理できるため、単一障害点は発生しません。
- セキュリティ: Google Cloud はデータを Splunk HEC に push するため、サービス アカウントキーの作成と管理に関連するメンテナンスとセキュリティの負担はありません。
- 自動スケーリング。Dataflow サービスが、受信ログの量とバックログの変動に応じてワーカー数を自動的にスケーリングします。
- フォールト トレラント。一時的なサーバーまたはネットワークの問題がある場合、push ベースの方法では、Splunk の HEC へのデータの再送信が自動的に試みられます。そこでは、配信できないログメッセージによるデータ損失を回避するため、未処理のトピック(デッドレター トピック)もサポートされます。
- シンプル。管理オーバーヘッドと、Splunk で 1 つ以上の負荷の高いフォワーダーの実行にかかるコストを回避できます。
このリファレンス アーキテクチャは、製薬や金融サービスなど、規制対象の業種をはじめとするさまざまな業種のビジネスに適用されます。 Google Cloud データを Splunk にエクスポートすることを選ぶ際は、次の理由でそうすることを選ぶ場合があります。
- ビジネス分析
- IT 運用担当者
- アプリケーション パフォーマンスのモニタリング
- セキュリティ運用
- コンプライアンス
代替案を設計する
Splunk にログをエクスポートする別の方法として、Google Cloudからログを pull するものがあります。この pull ベースの方式では、Google Cloud APIs を使用して、Splunk アドオン Google Cloudによってデータを取得します。次の状況では、pull ベースの方法を使用することを選ぶこともできます。
- Splunk のデプロイメントで Splunk HEC エンドポイントが提供されない。
- ログの数量が少ない。
- Cloud Monitoring の指標、Cloud Storage オブジェクト、Cloud Resource Manager API メタデータ、Cloud 課金データ、少量のログをエクスポートして分析したい。
- すでに 1 つ以上のフォワーダーを負荷の高い Splunk で管理している。
- ホストされている Splunk Cloud の Inputs Data Manager を使用する。
また、この pull ベースの方法を使用する際に発生する追加の考慮事項にも留意する必要があります。
- 単一のワーカーがデータ取り込みワークロードを処理しますが、ここで自動スケーリング機能は提供しません。
- Splunk では、負荷の大きいフォワーダーを使用してデータを pull すると、単一障害点が発生する場合があります。
- pull ベースの方法では、 Google Cloudの Splunk アドオンを構成するのに使用するサービス アカウントキーを作成、管理する必要があります。
Splunk アドオンを使用する前に、ログシンクを使用してログエントリを Pub/Sub に転送する必要があります。Pub/Sub トピックを宛先としてログシンクを作成するには、シンクを作成するをご覧ください。その Pub/Sub トピックの宛先で、シンクの書き込み ID に Pub/Sub パブリッシャーのロール(roles/pubsub.publisher)を付与してください。シンクの宛先の権限の構成の詳細については、宛先の権限を設定するをご覧ください。
Splunk アドオンを有効にするには、次の手順を実行します。
- Splunk で Splunk の手順に沿って、Splunk Add-on for Google Cloud をインストールします。
- ログが転送される Pub/Sub トピックに Pub/Sub pull サブスクリプションを作成します(まだ作成していない場合)。
- サービス アカウントを作成します。
- 作成したサービス アカウントのサービス アカウント キーを作成します。
- Pub/Sub 閲覧者(
roles/pubsub.viewer)と Pub/Sub サブスクライバー(roles/pubsub.subscriber)のロールをサービス アカウントに付与して、アカウントが Pub/Sub サブスクリプションからメッセージを受信できるようにします。 Splunk で Splunk の指示に沿って、 Google Cloudの Splunk アドオンで、新しい Pub/Sub 入力を構成します。
ログ エクスポートからの Pub/Sub メッセージが Splunk に表示されます。
アドオンが機能していることを確認するには、次の手順を実行します。
- Cloud Monitoring で Metrics Explorer を開きます。
- [リソース] メニューで、
pubsub_subscriptionを選択します。 - [指標] カテゴリで、
pubsub/subscription/pull_message_operation_countを選択します。 - 1~2 分間、メッセージ pull オペレーションの数をモニタリングします。
設計上の考慮事項
次のガイドラインは、セキュリティ、プライバシー、コンプライアンス、業務の効率化、信頼性、フォールト トレラント、パフォーマンス、費用の最適化に関する組織の要件を満たすアーキテクチャの開発に役立ちます。
セキュリティ、プライバシー、コンプライアンス
以降のセクションでは、このリファレンス アーキテクチャのセキュリティの考慮事項について説明します。
- プライベート IP アドレスを使用して Dataflow パイプラインをサポートする VM を保護する
- 限定公開の Google アクセスの有効化
- Splunk の HEC 上り(内向き)トラフィックを Cloud NAT で使用される既知の IP アドレスに限定する
- Secret Manager に Splunk の HEC トークンを保存する
- 最小権限のベスト プラクティスに沿ったカスタム Dataflow ワーカー サービス アカウントを作成する
- プライベート CA を使用する場合に、内部ルート CA 証明書の SSL 検証を構成する
プライベート IP アドレスを使用して Dataflow パイプラインをサポートする VM を保護する
Dataflow パイプラインで使用されるワーカー VM へのアクセスを制限する必要があります。アクセスを制限するには、これらの VM をプライベート IP アドレスでデプロイします。ただし、これらの VM は、HTTPS を使用して、エクスポートされたログを Splunk にストリーミングし、インターネットにアクセスできる必要もあります。この HTTPS アクセスを提供するには、Cloud NAT IP アドレスが必要な VM にそれらを自動的に割り振る Cloud NAT ゲートウェイが必要です。VM を含むサブネットを Cloud NAT ゲートウェイにマッピングしてください。
限定公開の Google アクセスを有効にする
Cloud NAT ゲートウェイを作成すると、限定公開の Google アクセスが自動的に有効になります。ただし、プライベート IP アドレスを持つ Dataflow ワーカーが Google Cloud APIs とサービスが使用する外部 IP アドレスにアクセスできるようにするには、サブネットの限定公開の Google アクセスを手動で有効にする必要があります。
Splunk の HEC 上り(内向き)トラフィックを Cloud NAT で使用される既知の IP アドレスに限定する
Splunk HEC へのトラフィックを既知の IP アドレスのサブセットに制限する場合は、静的 IP アドレスを予約して Cloud NAT ゲートウェイに手動で割り当てます。Splunk のデプロイによっては、これらの静的 IP アドレスを使用して Splunk の HEC 上り(内向き)ファイアウォール ルールを構成できます。Cloud NAT の詳細については、Cloud NAT でネットワーク アドレス変換を設定、管理するをご覧ください。
Secret Manager に Splunk の HEC トークンを保存する
Dataflow パイプラインをデプロイすると、次のいずれかの方法でトークン値を渡すことができます。
- 平文
- Cloud Key Management Service 鍵で暗号化された暗号テキスト
- Secret Manager によって暗号化、管理されるシークレットのバージョン
このリファレンス アーキテクチャでは、Splunk HEC トークンを保護する最も簡単で最も効率的な方法である、Secret Manager オプションを使用します。このオプションは、Dataflow コンソールまたはジョブの詳細からの Splunk HEC トークンの漏洩も防止します。
Secret Manager のシークレットには、シークレット バージョンのコレクションが含まれています。各シークレット バージョンには、実際のシークレット データ(Splunk の HEC トークンなど)が格納されています。後で追加のセキュリティ対策として Splunk HEC トークンをローテーションする場合は、新しいトークンを新しいシークレット バージョンとしてこのシークレットに追加できます。シークレットのローテーションの一般的な情報については、ローテーション スケジュールについてをご覧ください。
最小権限のベスト プラクティスに沿ったカスタム Dataflow ワーカー サービス アカウントを作成する
Dataflow パイプラインのワーカーは、Dataflow ワーカー サービス アカウントを使用してリソースにアクセスし、オペレーションを実行します。デフォルトでは、ワーカーはプロジェクトの Compute Engine のデフォルト サービス アカウントをワーカー サービス アカウントとして使用します。これにより、プロジェクト内のすべてのリソースに対する幅広い権限が付与されます。ただし、Dataflow ジョブを本番環境で実行するには、最小限のロールと権限のセットでカスタム サービス アカウントを作成することをおすすめします。このカスタム サービス アカウントは、Dataflow パイプライン ワーカーに割り当てることができます。
次の図は、Dataflow ワーカーが Dataflow ジョブを正常に実行するために、サービス アカウントに割り当てる必要があるロールを示しています。
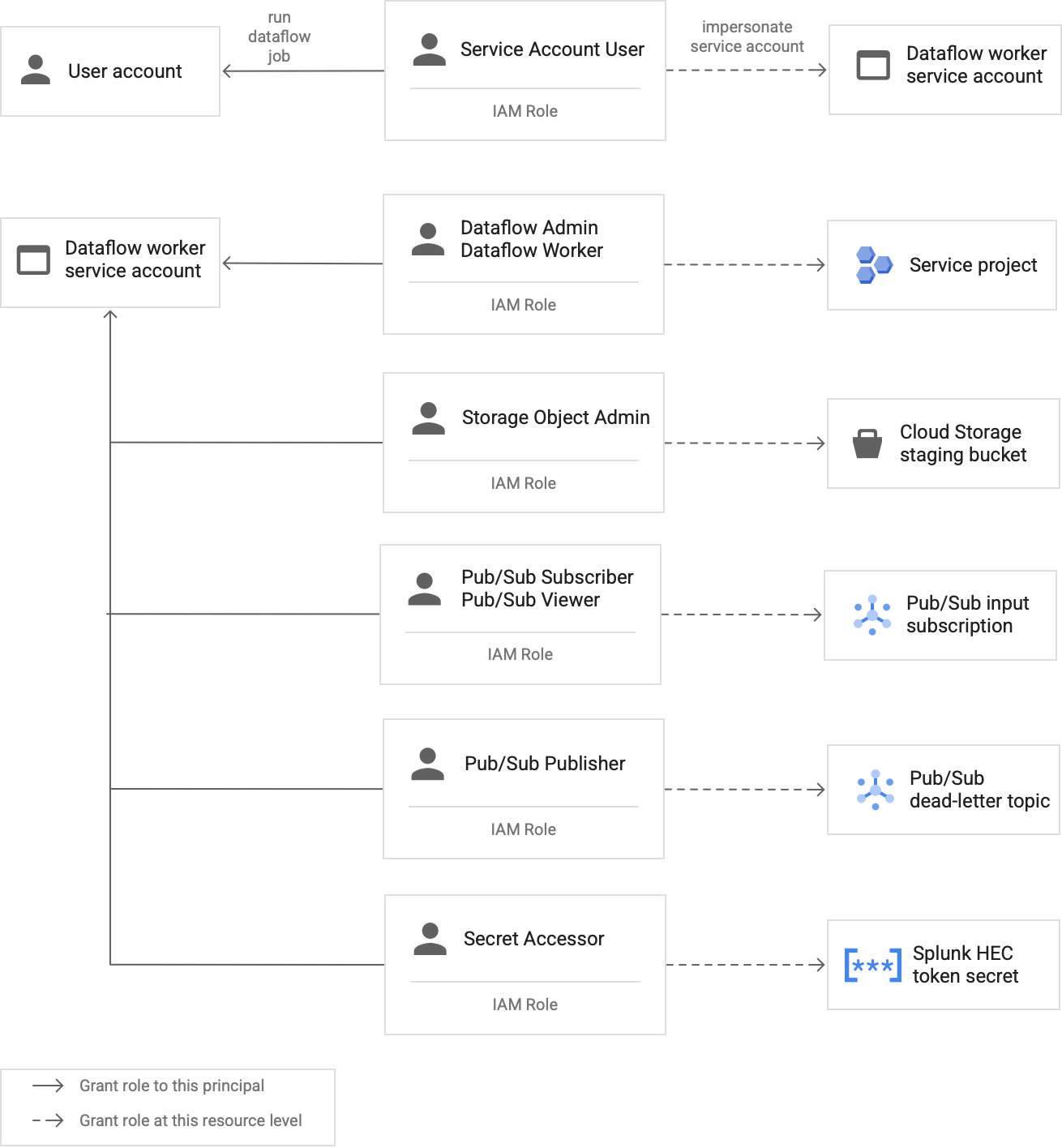
図に示すように、Dataflow ワーカーのサービス アカウントに次のロールを割り当てる必要があります。
- Dataflow 管理者
- Dataflow ワーカー
- Storage オブジェクト管理者
- Pub/Sub サブスクライバー
- Pub/Sub 閲覧者
- Pub/Sub パブリッシャー
- シークレット アクセサー
プライベート CA を使用する場合に、内部ルート CA 証明書を使用して SSL 検証を構成する
デフォルトでは、Dataflow パイプラインは Dataflow ワーカーのデフォルトのトラストストアを使用して、Splunk HEC エンドポイントの SSL 証明書を検証します。プライベート認証局(CA)を使用して、Splunk HEC エンドポイントで使用される SSL 証明書に署名する場合は、内部ルート CA 証明書をトラストストアにインポートできます。Dataflow ワーカーは、インポートされた証明書を SSL 証明書の検証に使用できます。
自己署名証明書または非公開署名の証明書による Splunk のデプロイでは、独自の内部ルート CA 証明書を使用してインポートできます。SSL 検証は、完全に内部の開発とテストの目的でのみ無効にすることもできます。この内部ルート CA 方式は、インターネットに接続しない内部 Splunk のデプロイに最適です。
詳細については、Pub/Sub to Splunk Dataflow テンプレートのパラメータ
rootCaCertificatePath と disableCertificateValidation をご覧ください。
業務の効率化
以降のセクションでは、このリファレンス アーキテクチャの業務の効率化に関する考慮事項について説明します。
UDF を使用して、処理中のログまたはイベントを変換する
Pub/Sub to Splunk Dataflow テンプレートは、カスタム イベント変換のユーザー定義関数(UDF)をサポートしています。使用例として、レコードにフィールドを追加して拡張する、一部の機密性のフィールドを消去する、必要のないレコードをフィルタにより除外するなどが挙げられます。UDF によって、テンプレート コード自体の再コンパイルや保持をすることなく、Dataflow パイプラインの出力形式を変更できます。このリファレンス アーキテクチャでは、UDF を使用して、パイプラインが Splunk に配信できないメッセージを処理します。
未処理のメッセージを再生する
パイプラインが配信エラーを受信し、メッセージの配信を再試行しない場合があります。この場合、次の図に示すように、Dataflow はこれらの未処理のメッセージを未処理のトピックに送信します。配信エラーの根本原因を修正したら、未処理のメッセージを再生できるようになります。
次のステップは、前の図に示したプロセスの概要を示しています。
- Pub/Sub から Splunk へのメイン配信パイプラインでは、ユーザーの調査のため、配信不能のメッセージが自動的に未処理トピックに転送されます。
オペレーターまたはサイト信頼性エンジニア(SRE)が、未処理のサブスクリプション内の失敗したメッセージを調査します。オペレーターがトラブルシューティングを行い、配信エラーの根本原因を解決します。たとえば、HEC トークンの構成ミスを修正すると、メッセージが配信される場合があります。
オペレーターが、再生に失敗したメッセージ パイプラインをトリガーします。この Pub/Sub から Pub/Sub へのパイプライン(前の図の点で強調表示された部分)は一時的なパイプラインで、失敗したメッセージを未処理のサブスクリプションから元のログシンクのトピックに戻します。
メイン配信パイプラインは、以前失敗したメッセージを再処理します。この手順では、パイプラインで UDF を使用して、失敗したメッセージ ペイロードを正しく検出およびデコードする必要があります。次のコードは、追跡目的の配信試行の集計を含む、条件付きデコード ロジックを実装する関数の例です。
// If the message has already been converted to a Splunk HEC object // with a stringified obj.event JSON payload, then it's a replay of // a previously failed delivery. // Unnest and parse the obj.event. Drop the previously injected // obj.attributes such as errorMessage and timestamp if (obj.event) { try { event = JSON.parse(obj.event); redelivery = true; } catch(e) { event = obj; } } else { event = obj; } // Keep a tally of delivery attempts event.delivery_attempt = event.delivery_attempt || 1; if (redelivery) { event.delivery_attempt += 1; }
信頼性とフォールト トレラント
信頼性とフォールト トレラントに関して、いくつか考えられる Splunk 配信エラーの一覧を次の表(表 1)に示します。この表には、パイプラインが各メッセージを未処理のトピックに転送する前に記録する、対応する errorMessage 属性もリストされています。
表 1: Splunk 配信エラーの種類
| 配信エラーの種類 | パイプラインによって自動的に再試行されるか? | errorMessage 属性の例 |
|---|---|---|
一時的なネットワーク エラー |
○ |
または
|
Splunk サーバー 5xx エラー |
○ |
|
Splunk サーバー 4xx エラー |
× |
|
Splunk サーバーの停止 |
× |
|
Splunk SSL 証明書が無効 |
× |
|
ユーザー定義関数(UDF)の JavaScript 構文エラー |
いいえ |
|
場合によっては、パイプラインは指数バックオフを適用し、自動的にメッセージの配信を再び試みます。たとえば、Splunk サーバーが 5xx エラーコードを生成した場合、パイプラインはメッセージを再配信する必要があります。これらのエラーコードは、Splunk の HEC エンドポイントが過負荷になった場合に発生します。
または、メッセージが HEC エンドポイントに送信されない永続的な問題が発生することがあります。このような永続的な問題の場合、パイプラインはメッセージの配信を再び試みません。以下に、永続的な問題の例を示します。
- UDF 関数の構文エラー。
- Splunk サーバーが
4xx「Forbidden」のサーバー レスポンスを生成する原因となる無効な HEC トークン。
パフォーマンスと費用の最適化
パフォーマンスと費用の最適化に関して、Dataflow パイプラインの最大サイズとスループットを決定する必要があります。パイプラインがアップストリームの Pub/Sub サブスクリプションから 1 日におけるピーク時のログボリューム(GB/日)とログ メッセージのレート(1 秒あたりのイベント数または EPS)を処理できるように、正しいサイズとスループット値を計算する必要があります。
システムで次のいずれかの問題が発生しないように、サイズとスループット値を選択する必要があります。
- メッセージ バックロギングまたはメッセージ スロットリングに起因する遅延。
- パイプラインのオーバープロビジョニングによる追加費用。
サイズとスループットを計算した後、その結果を使用して、パフォーマンスと費用のバランスが取れた最適なパイプラインを構成できます。パイプライン容量を構成するには、次の設定を使用します。
- マシンタイプとマシン数のフラグは、Dataflow ジョブをデプロイする gcloud コマンドの一部です。これらのフラグによって、使用する VM のタイプと数を定義できます。
- 並列処理とバッチ数パラメータは、Pub/Sub to Splunk Dataflow テンプレートの一部です。これらのパラメータは、Splunk の HEC エンドポイントの過負荷を避けながら EPS を増やすために重要です。
以下のセクションでは、これらの設定について説明します。該当する場合、これらのセクションでは、数式および各数式を使用する計算例も紹介します。これらの計算例と結果の値は、次の特性を持つ組織を想定しています。
- 1 日あたり 1 TB のログを生成する。
- メッセージの平均サイズは 1 KB である。
- 継続メッセージのピーク時のレートが、平均レートの 2 倍である。
Dataflow 環境は一意であるため、手順に沿って、サンプル値で独自の組織の値を置き換えます。
マシンタイプ
ベスト プラクティス: --worker-machine-type フラグを n2-standard-4 に設定して、コスト比に対する最適なパフォーマンスを提供するマシンサイズを選択します。
n2-standard-4 マシンタイプは 12,000 EPS を処理できるため、このマシンタイプをすべての Dataflow ワーカーのマシンタイプのベースラインとして使用することをおすすめします。
このリファレンス アーキテクチャでは、--worker-machine-type フラグを n2-standard-4 の値に設定します。
マシン台数
ベスト プラクティス: --max-workers フラグを設定して、予想されるピーク時の EPS を処理するために必要なワーカーの最大数を制御します。
Dataflow の自動スケーリングにより、リソースの使用量と負荷が変更された場合に、ストリーミング パイプライン実行するために使用されるワーカーの数がサービスによって適切に変更されます。自動スケーリング時のオーバープロビジョニングを回避するため、Dataflow ワーカーとして使用される仮想マシンの最大数を常に定義することをおすすめします。仮想マシンの最大数は、Dataflow パイプラインをデプロイする際に --max-workers フラグで定義します。
Dataflow は、次のようにストレージ コンポーネントを静的にプロビジョニングします。
自動スケーリング パイプラインは、可能性のあるストリーミング ワーカーごとに 1 つのデータ永続ディスクをデプロイします。デフォルトの永続ディスクサイズは 400 GB で、
--max-workersフラグでワーカーの最大数を設定します。ディスクは、起動時を含め、実行中の任意の時点でワーカー間でマウントされます。各ワーカー インスタンスは 15 個の永続ディスクに制限されているため、起動ワーカーの最小数は
⌈--max-workers/15⌉です。そのため、デフォルト値が--max-workers=20の場合は、パイプライン使用量(と費用)は次のようになります。- ストレージ: 20 個の永続ディスクを使用する静的ストレージ。
- コンピューティング: 少なくとも 2 つのワーカー インスタンス(⌈20/15⌉ = 2)以上、かつ最大 20 個のワーカー インスタンスを使用する動的コンピューティング。
この値は 8 TB の永続ディスクに相当します。ディスクが完全に使用されていない場合、特にほとんどの時間で 1 つまたは 2 つのワーカーしか稼働していない場合、このサイズの永続ディスクに不要なコストが発生する可能性があります。
パイプラインに必要なワーカーの最大数を決定するには、次の数式を順番に使用します。
次の数式を使用して、1 秒あたりの平均イベント数(EPS)を決定します。
\( {AverageEventsPerSecond}\simeq\frac{TotalDailyLogsInTB}{AverageMessageSizeInKB}\times\frac{10^9}{24\times3600} \)計算例: 平均メッセージ サイズが 1 KB で、1 日あたり 1 TB のログのサンプル値の場合、この数式の平均 EPS 値は 11,500 EPS になります。
次の数式を使用して継続ピーク EPS を特定します。ここで、乗数 N はロギングのバースト性を表します。
\( {PeakEventsPerSecond = N \times\ AverageEventsPerSecond} \)計算例: 値の例が N=2 で、前のステップで計算した平均 EPS 値が 11,500 とすると、この数式では持続的なピーク EPS 値が 23,000 EPS となります。
次の数式を使用して、必要な vCPU の最大数を決定します。
\( {maxCPUs = ⌈PeakEventsPerSecond / 3k ⌉} \)計算例: 前の手順で計算した持続ピーク EPS 値の 23,000 を使用すると、この数式から最大 ⌈23 / 3⌉ = 8 個の vCPU コア数となります。
次の数式を使用して、Dataflow ワーカーの最大数を決定します。
\( maxNumWorkers = ⌈maxCPUs / 4 ⌉ \)計算例:前の手順で計算された例の最大 vCPU 値の 8 を使用して、この数式 [8/4] から
n2-standard-4マシンタイプは最大 2 となります。
この例では、前の一連の計算例に基づいて --max-workers フラグを 2 の値に設定します。ただし、このリファレンス アーキテクチャを環境にデプロイする場合は、独自の一意の値と計算を使用するようにしてください。
並列処理
ベスト プラクティス: Pub/Sub to Splunk Dataflow テンプレートの parallelism パラメータを、Dataflow ワーカーの最大数によって使用される vCPU の数の 2 倍に設定します。
parallelism パラメータは、並列 Splunk HEC 接続数を最大化し、その結果、パイプラインの EPS レートを最大化します。
デフォルトの parallelism 値が 1 の場合、並列処理は無効になり、出力レートは制限されます。このデフォルト設定をオーバーライドして、デプロイされた最大数のワーカーで、vCPU あたり 2~4 の同時接続に構成する必要があります。原則として、この設定のオーバーライド値は、Dataflow ワーカーの最大数にワーカーあたりの vCPU 数を乗算してから、この値を 2 倍にすることで計算します。
すべての Dataflow ワーカーにおける Splunk の HEC への並列接続の総数を決定するには、次の数式を使用します。
計算例: マシン数として以前に計算された、例の最大 vCPU 数の 8 を使用して、この数式では同時接続数が 8 x 2 = 16 になります。
この例では、前の計算例に基づいて、parallelism パラメータの値を 16 に設定します。ただし、このリファレンス アーキテクチャを環境にデプロイする場合は、独自の一意の値と計算を使用するようにしてください。
バッチ数
ベスト プラクティス: Splunk の HEC で一度に 1 つずつではなく一括でイベントを処理できるようにするには、batchCount パラメータをログあたりのイベント / リクエストを 10~50 の値に設定します。
バッチ数を構成すると、EPS を増やし、Splunk HEC エンドポイントの負荷を軽減できます。設定では、処理の効率化のために、複数のイベントが単一のバッチに結合されます。最大バッファリング遅延が 2 秒で許容可能とすれば、batchCount パラメータをログあたり 10~50 イベント / リクエストの値に設定することをおすすめします。
この例では、ログ メッセージの平均サイズは 1 KB であるため、リクエストごとに少なくとも 10 件のイベントをバッチ処理することをおすすめします。この例では、batchCount パラメータを 10 の値に設定します。ただし、このリファレンス アーキテクチャを環境にデプロイする場合は、独自の一意の値と計算を使用するようにしてください。
これらのパフォーマンスと費用の最適化に関する推奨事項の詳細については、Dataflow パイプラインを計画するをご覧ください。
次のステップ
- Pub/Sub to Splunk Dataflow テンプレート パラメータの一覧については、Pub/Sub to Splunk Dataflow のドキュメントをご覧ください。
- このリファレンス アーキテクチャのデプロイに役立つ、対応する Terraform テンプレートについては、
terraform-splunk-log-exportGitHub リポジトリをご覧ください。それには、Splunk Dataflow パイプラインをモニタリングするためのビルド済みの Cloud Monitoring ダッシュボードが含まれています。 - Splunk Dataflow のモニタリングとトラブルシューティングに役立つ Splunk Dataflow のカスタム指標とロギングの詳細については、ブログ Splunk Dataflow ストリーミング パイプライン用の新しいオブザーバビリティ機能をご覧ください。
- Cloud アーキテクチャ センターで、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。