Dieses Dokument ist der zweite Teil einer Reihe, in der die Notfallwiederherstellung (Disaster Recovery, DR) in Google Cloudbehandelt wird. Das Thema dieses Teils sind Dienste und Produkte, die Sie als Bausteine für den DR-Plan verwenden können. Hierzu zählen neben Google Cloud -Produkten auch plattformübergreifend einsetzbare Produkte.
Die Reihe besteht aus folgenden Teilen:
- Leitfaden zur Planung der Notfallwiederherstellung
- Bausteine der Notfallwiederherstellung (dieser Artikel)
- Szenarien der Notfallwiederherstellung für Daten
- Szenarien der Notfallwiederherstellung von Anwendungen
- Architektur der Notfallwiederherstellung von Arbeitslasten mit Standortbeschränkung entwickeln
- Anwendungsfälle für die Notfallwiederherstellung: Datenanalyseanwendungen mit Standortbeschränkung
- Architektonische Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur
Google Cloud bietet eine breite Palette von Produkten, die Sie als Teil der Architektur für die Notfallwiederherstellung verwenden können. In diesem Abschnitt werden die in Google Cloud am häufigsten als DR-Bausteine verwendeten DR-Features erläutert.
Viele der Dienste haben Funktionen zum Erreichen einer hohen Verfügbarkeit. Die Implementierung von Hochverfügbarkeit überschneidet sich nicht in allen Bereichen mit der Notfallwiederherstellung. Zahlreiche Aspekte der Hochverfügbarkeit gelten jedoch auch für das Entwerfen eines DR-Plans. Durch ein Erhöhen der Verfügbarkeit kann sich beispielsweise die Betriebszeit von Architekturen verbessern. Folglich verringern sich mitunter die Auswirkungen kleinerer Fehler, wie etwa der Ausfall einer einzelnen VM. Weitere Informationen zum Zusammenhang von Notfallwiederherstellung und Hochverfügbarkeit finden Sie im Leitfaden zur Planung der Notfallwiederherstellung.
In den folgenden Abschnitten werden diese Google Cloud DR-Bausteine beschrieben. Außerdem erfahren Sie, wie Sie damit Ihre DR-Ziele erreichen können.
Computing und Speicher
In der folgenden Tabelle finden Sie eine Zusammenfassung der Funktionen in Google Cloud Compute- und Speicherdiensten, die als Bausteine für DR dienen:
| Produkt | Funktion |
|---|---|
| Compute Engine |
|
| Cloud Storage |
|
| Google Kubernetes Engine (GKE) |
|
Weitere Informationen dazu, wie die Funktionen und das Design dieser und andererGoogle Cloud -Produkte Ihre DR-Strategie beeinflussen können, finden Sie unter Architektonische Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur: Produktreferenz.
Compute Engine
Compute Engine ist ein wichtiges Tool von Google Cloudzum Bereitstellen von VM-Instanzen. Neben dem Konfigurieren, Starten und Überwachen von Compute Engine-Instanzen kommen zum Umsetzen eines DR-Plans in der Regel diverse damit verbundene Features zum Einsatz.
Sie können bei DR-Szenarien durch Angabe des Löschschutz-Flags ein versehentliches Löschen von VMs verhindern. Dies ist besonders beim Hosting zustandsorientierter Dienste wie Datenbanken nützlich.
Informationen dazu, wie Sie niedrige RTO- und RPO-Werte erreichen, finden Sie unter Resiliente Systeme konzipieren.
Instanzvorlagen
Sie können die Konfigurationsdetails der VM mit Instanzvorlagen von Compute Engine speichern und anschließend Compute Engine-Instanzen aus vorhandenen Instanzvorlagen erstellen. Die Vorlagen bieten Ihnen die Möglichkeit, eine beliebige Anzahl von Instanzen zu starten, die entsprechend der gewünschten DR-Zielumgebung konfiguriert sind. Instanzvorlagen werden global repliziert, sodass Sie die Instanz jederzeit an beliebiger Stelle in Google Cloud mit derselben Konfiguration neu erstellen können.
Weitere Informationen finden Sie in den folgenden Ressourcen:
Weitere Informationen zur Verwendung von Compute Engine-Images finden Sie im Abschnitt Image-Konfiguration und Bereitstellungsgeschwindigkeit ausbalancieren.
Verwaltete Instanzgruppen
Verwaltete Instanzgruppen sorgen in Verbindung mit Cloud Load Balancing dafür, dass Traffic an Gruppen mit identisch konfigurierten Instanzen verteilt wird, die zwischen Zonen kopiert werden. Zu Cloud Load Balancing lesen Sie später in diesem Dokument mehr. Verwaltete Instanzgruppen ermöglichen die Verwendung von Funktionen wie Autoscaling und der automatischen Reparatur. Die verwaltete Instanzgruppe kann Instanzen dadurch automatisch löschen und neu erstellen.
Reservierungen
Compute Engine ermöglicht die Reservierung von VM-Instanzen in einer bestimmten Zone mithilfe von benutzerdefinierten oder vordefinierten Maschinentypen mit oder ohne zusätzliche GPUs oder lokale SSDs. Sie sollten in Ihren DR-Zielzonen Reservierungen erstellen, um die Kapazität Ihrer geschäftskritischen Arbeitslasten für die Notfallwiederherstellung zu gewährleisten. Ohne Reservierungen kann es vorkommen, dass Sie nicht die On-Demand-Kapazität erhalten, die Sie benötigen, um das Wiederherstellungszeitziel zu erreichen. Reservierungen können in kalten, warmen oder heißen DR-Szenarien nützlich sein. Dadurch können Sie Wiederherstellungsressourcen für ein Failover verfügbar machen, um niedrigere RTO-Anforderungen zu erfüllen, ohne sie im Voraus vollständig konfigurieren und bereitstellen zu müssen.
Nichtflüchtige Speicher und Snapshots
Nichtflüchtige Speicher sind dauerhafte Netzwerkspeichergeräte, auf die Ihre Instanzen zugreifen können. Aufgrund der Unabhängigkeit von den Instanzen können Sie nichtflüchtige Speicher trennen und verschieben. Ihre Daten bleiben dadurch auch nach dem Löschen der Instanzen erhalten.
Sie haben die Möglichkeit, inkrementelle Sicherungen oder Snapshots von Compute Engine-VMs zu erstellen und zwischen Regionen zu kopieren. Nichtflüchtige Speicher lassen sich so nach einem Notfall neu erstellen. Durch das Erstellen von Snapshots nichtflüchtiger Speicher können Sie außerdem Datenverlusten infolge von Nutzerfehlern vorbeugen. Snapshots werden inkrementell erstellt. Die Erstellung dauert nur wenige Minuten und ist auch bei Laufwerken möglich, die mit laufenden Instanzen verbunden sind.
Nichtflüchtige Speicher sind von Haus aus redundant. Ihre Daten bleiben dadurch bei Geräteausfällen erhalten und sind auch während Wartungsarbeiten am Rechenzentrum verfügbar. Nichtflüchtige Speicher sind entweder zonale oder regionale Speicher. Regionale nichtflüchtige Speicher replizieren Schreibvorgänge in zwei Zonen einer Region. Bei einem zonalen Ausfall kann eine VM-Sicherungsinstanz das Hinzufügen eines regionalen nichtflüchtigen Speichers in der sekundären Zone erzwingen. Weitere Informationen finden Sie unter Hochverfügbarkeitsoptionen mit regionalen nichtflüchtigen Speichern.
Transparente Wartung
Google führt regelmäßig Wartungsarbeiten an der Infrastruktur durch. Dabei werden aktuelle Software-Patches eingespielt, Routinetests durchgeführt und vorbeugende Wartungsaufgaben ausgeführt. Es wird insgesamt sichergestellt, dass die Google-Infrastruktur so schnell und effizient arbeitet, wie es Google möglich ist.
Standardmäßig sind alle Compute Engine-Instanzen so konfiguriert, dass diese Wartungsarbeiten für Ihre Anwendungen und Arbeitslasten transparent sind. Weitere Informationen finden Sie unter Transparente Wartung.
Wenn ein Wartungsereignis eintritt, verwendet Compute Engine die Live-Migration, um Ihre laufenden Instanzen automatisch zu einem anderen Host in derselben Zone zu migrieren. Dank der Live-Migration kann Google Wartungsarbeiten ausführen, die für den Schutz und die Zuverlässigkeit der Infrastruktur erforderlich sind, ohne dass Ihre VMs unterbrochen werden.
Importtool für virtuelle Laufwerke
Mit dem Importtool für virtuelle Laufwerke lassen sich Dateiformate wie VMDK, VHD und RAW importieren, um neue Compute Engine-VMs zu erstellen. Sie können damit Compute Engine-VMs mit der gleichen Konfiguration wie Ihre lokalen virtuellen Maschinen erstellen. Dies ist hilfreich, wenn Sie bei Software, die in den Images bereits installiert ist, keine Compute Engine-Images von den Binärdateien konfigurieren können.
Automatische Sicherungen
Sie können Sicherungen Ihrer Compute Engine-Instanzen mithilfe von Tags automatisieren. Sie können beispielsweise eine Sicherungsplanvorlage mit dem Backup- und DR-Dienst erstellen und die Vorlage automatisch auf Ihre Compute Engine-Instanzen anwenden.
Weitere Informationen finden Sie unter Schutz neuer Compute Engine-Instanzen automatisieren.
Cloud Storage
Cloud Storage ist ein hervorragender Objektspeicher für Sicherungsdateien. Sie können damit je nach Anwendungsfall gemäß dem folgenden Diagramm unterschiedliche Speicherklassen nutzen.

In DR-Szenarien sind speziell Nearline Storage, Coldline Storage und Archive Storage von Bedeutung. Mit diesen Speicherklassen können Sie die Speicherkosten gegenüber Standard Storage reduzieren. Für das Abrufen der in diesen Klassen gespeicherten Daten oder Metadaten fallen jedoch zusätzliche Gebühren an. Außerdem wird grundsätzlich eine Mindestspeicherdauer berechnet. Nearline wurde für Sicherungsszenarien entwickelt, in denen der Zugriff maximal einmal pro Monat erfolgt. Die Klasse eignet sich optimal, um regelmäßige DR-Belastungstests durchzuführen und gleichzeitig die Kosten niedrig zu halten.
Nearline, Coldline und Archive sind für einen seltenen Zugriff optimiert, was bei der Entwicklung des Preismodells entsprechend berücksichtigt wurde. In diesen Klassen wird grundsätzlich eine Mindestspeicherdauer berechnet. Zusätzliche Gebühren fallen an, wenn Daten oder Metadaten vor Ablauf der Mindestspeicherdauer abgerufen werden.
Um Ihre Daten in einem Cloud Storage-Bucket vor versehentlichem oder böswilligem Löschen zu schützen, können Sie die Funktion Vorläufiges Löschen verwenden, um gelöschte und überschriebene Objekte für einen bestimmten Zeitraum beizubehalten, und die Funktion Objektsperren, um das Löschen oder Aktualisieren von Objekten zu verhindern.
Mit dem Storage Transfer Service können Sie Daten aus Amazon S3, Azure Blob Storage oder lokalen Datenquellen in Cloud Storage importieren. In DR-Szenarien bietet Ihnen der Storage Transfer Service folgende Möglichkeiten:
- Sichern der Daten anderer Speicheranbieter in einem Cloud Storage-Bucket
- Verschieben der Daten aus einem Bucket in einer Dual- oder Multi-Region in einen Bucket in einer einzelnen Region, um die Kosten für das Speichern von Sicherungen zu senken.
Filestore
Filestore-Instanzen sind vollständig verwaltete NFS-Dateiserver zur Verwendung mit Anwendungen, die auf Compute Engine-Instanzen oder GKE-Clustern ausgeführt werden.
Filestore-Instanzen der Basic- und Zonal-Stufe sind zonale Ressourcen und unterstützen keine zonenübergreifende Replikation, während Instanzen der Enterprise-Stufe regionale Ressourcen sind. Um die Resilienz Ihrer Filestore-Umgebung zu erhöhen, empfehlen wir die Verwendung von Instanzen der Unternehmensstufe.
Google Kubernetes Engine
GKE ist eine verwaltete, produktionsfertige Umgebung für die Bereitstellung von Containeranwendungen. Sie können mit GKE hochverfügbare Systeme orchestrieren und folgende Funktionen nutzen:
- Automatische Knotenreparatur: Wenn aufeinanderfolgende Systemdiagnosen eines Knotens etwa 10 Minuten lang fehlschlagen, wird in GKE ein Reparaturvorgang für den Knoten initiiert.
- Aktivitäts- und Bereitschaftsprüfungen: Sie können eine Aktivitätsprüfung festlegen, die regelmäßig an GKE meldet, dass der Pod ausgeführt wird. Wenn der Pod die Prüfung nicht besteht, kann er neu gestartet werden.
- Mehrzonen- und regionale Cluster: Sie können Kubernetes-Ressourcen wahlweise auf mehrere Zonen innerhalb einer Region verteilen.
- Mit Multi-Cluster-Gateway können Sie gemeinsame Load-Balancing-Ressourcen für mehrere GKE-Cluster in verschiedenen Regionen konfigurieren.
- Mit Backup for GKE können Sie Arbeitslasten in GKE-Clustern sichern und wiederherstellen.
Netzwerke und Datenübertragung
In der folgenden Tabelle finden Sie eine Zusammenfassung der Funktionen in Google Cloud Netzwerk- und Datenübertragungsdiensten, die als Bausteine für DR dienen:
| Produkt | Funktion |
|---|---|
Cloud Load Balancing |
|
| Cloud Service Mesh |
|
| Cloud DNS |
|
| Cloud Interconnect |
|
Cloud Load Balancing
Cloud Load Balancing sorgt durch die Verteilung des Nutzertraffics auf mehrere Instanzen Ihrer Anwendungen für eine hohe Verfügbarkeit von Google Cloud Computing-Produkten. Sie können Cloud Load Balancing mit Systemdiagnosen konfigurieren, um die Verfügbarkeit von Instanzen zu prüfen und Trafficweiterleitungen an fehlerhafte Instanzen zu vermeiden.
Mit Cloud Load Balancing benötigen Sie nur eine Anycast-IP-Adresse für Ihre Anwendungen. Die Instanzen Ihrer Anwendungen können in verschiedenen Regionen (z. B. in Europa und in den USA) ausgeführt werden. Endnutzer werden zur nächstgelegenen Instanz weitergeleitet. Neben dem Lastenausgleich für im Internet verfügbare Dienste können Sie auch einen internen Lastenausgleich für Dienste hinter einer privaten IP-Adresse konfigurieren. Diese IP-Adresse ist nur für VM-Instanzen innerhalb Ihrer Virtual Private Cloud (VPC) zugänglich.
Weitere Informationen finden Sie unter Cloud Load Balancing.
Cloud Service Mesh
Cloud Service Mesh ist ein von Google verwaltetes Service Mesh, das auf Google Cloudverfügbar ist. Cloud Service Mesh bietet detaillierte Telemetriedaten, mit denen Sie detaillierte Informationen zu Ihren Anwendungen erhalten. Es unterstützt Dienste, die auf einer Reihe von Computing-Infrastrukturen ausgeführt werden.
Cloud Service Mesh unterstützt auch erweiterte Funktionen zur Trafficverwaltung und zum Routing, z. B. Schutzschaltungen und Fehlerinjektion. Bei Schutzschaltungen werden Limits für Anfragen an einen bestimmten Dienst erzwungen. Wenn die Grenzwerte für die Schutzschaltung erreicht werden, wird verhindert, dass Anfragen den Dienst erreichen, um den Dienst vor einer weiteren Verschlechterung zu schützen. Mithilfe der Fehlerinjektion kann Cloud Service Mesh Verzögerungen verursachen oder einen Teil der Anfragen an einen Dienst abbrechen. Mithilfe der Fehlerinjektion können Sie testen, wie gut Ihr Dienst mit Anfrageverzögerungen oder abgebrochenen Anfragen umgehen kann.
Weitere Informationen finden Sie unter Cloud Service Mesh – Übersicht
Cloud DNS
Cloud DNS ermöglicht die programmatische Verwaltung von DNS-Einträgen im Rahmen eines automatisierten Wiederherstellungsprozesses. Cloud DNS nutzt das globale Google-Netzwerk aus Anycast-Nameservern, um DNS-Zonen über redundante Standorte auf der ganzen Welt bereitzustellen. Nutzer profitieren dadurch von Hochverfügbarkeit und geringer Latenz.
Wenn Sie DNS-Einträge lokal verwalten, können Sie VMs inGoogle Cloud aktivieren, um diese Adressen über die Weiterleitung von Cloud DNS aufzulösen.
Cloud DNS unterstützt Richtlinien, um zu konfigurieren, wie auf DNS-Anfragen reagiert wird. Sie können beispielsweise DNS-Routingrichtlinien konfigurieren, um Traffic anhand bestimmter Kriterien zu steuern, z. B. um Failover auf eine Sicherungskonfiguration zu ermöglichen, um eine hohe Verfügbarkeit zu gewährleisten, oder um DNS-Anfragen basierend auf ihrem geografischen Standort weiterzuleiten.
Cloud Interconnect
Mit Cloud Interconnect können Sie Daten aus anderen Quellen nach Google Cloudübertragen. Dieses Produkt wird später im Abschnitt Daten an und von Google Cloud übertragen erläutert.
Verwaltung und Monitoring
In der folgenden Tabelle finden Sie eine Zusammenfassung der Funktionen in Google Cloud Verwaltungs- und Überwachungsdiensten, die als Bausteine für DR dienen:
| Produkt | Funktion |
|---|---|
| Cloud Status Dashboard |
|
| Google Cloud Observability |
|
| Google Cloud Managed Service for Prometheus |
|
Cloud Status Dashboard
Das Cloud-Status-Dashboard zeigt die aktuelle Verfügbarkeit von Google Cloud -Diensten an. Sie können auf der Seite den Status prüfen und einen RSS-Feed abonnieren, um über Neuigkeiten zu einem Dienst informiert zu werden.
Cloud Monitoring
Cloud Monitoring erfasst Messwerte, Ereignisse und Metadaten von Google Cloud, AWS, gehosteten Betriebszeittests, der Anwendungsinstrumentierung und diversen weiteren Anwendungskomponenten. Sie können Benachrichtigungen an Drittanbietertools wie Slack oder PagerDuty konfigurieren, um Administratoren Aktualisierungen zeitnah zur Verfügung zu stellen.
Mit Cloud Monitoring können Sie Verfügbarkeitsdiagnosen für öffentlich verfügbare Endpunkte und für Endpunkte in Ihren VPCs erstellen. Sie können z. B. URLs, Compute Engine-Instanzen, Cloud Run-Überarbeitungen und Ressourcen von Drittanbietern wie Amazon Elastic Compute Cloud (EC2)-Instanzen überwachen.
Google Cloud Managed Service for Prometheus
Google Cloud Managed Service for Prometheus ist eine von Google verwaltete Multi-Cloud-Lösung für Prometheus-Messwerte, die projektübergreifend eingesetzt werden kann. Damit können Sie Ihre Arbeitslasten global mit Prometheus überwachen und melden, ohne Prometheus manuell in großem Umfang verwalten und betreiben zu müssen.
Weitere Informationen finden Sie unter Google Cloud Managed Service for Prometheus.
Plattformübergreifende DR-Bausteine
Wenn Sie Arbeitslasten auf mehreren Plattformen ausführen, können Sie den operativen Aufwand unter anderem durch die Auswahl von Tools reduzieren, die mit allen Plattformen kompatibel sind. In diesem Abschnitt werden verschiedene plattformunabhängige Tools und Dienste erläutert, die sich für plattformübergreifende DR-Szenarien eignen.
Infrastruktur als Code
Wenn Sie Ihre Infrastruktur mit Code statt mit grafischen Schnittstellen oder Skripts definieren, können Sie deklarative Vorlagentools verwenden und die Bereitstellung und Konfiguration von Infrastruktur plattformübergreifend automatisieren. Sie können beispielsweise Terraform und Infrastructure Manager verwenden, um Ihre deklarative Infrastrukturkonfiguration zu aktivieren.
Tools zur Konfigurationsverwaltung
Für große oder komplexe DR-Infrastrukturen empfehlen wir plattformunabhängige Softwareverwaltungstools wie Chef und Ansible. Mit diesen Tools lassen sich reproduzierbare Konfigurationen unabhängig davon anwenden, wo Rechenarbeitslasten ausgeführt werden.
Orchestrator-Tools
Auch Container können als DR-Bausteine betrachtet werden. Sie können darin Dienste verpacken und eine plattformübergreifende Konsistenz implementieren.
Für die Arbeit mit Containern verwenden Sie in der Regel einen Orchestrator. Kubernetes dient nicht nur zur Verwaltung von Containern in Google Cloud (mithilfe von GKE). Sie können damit auch containerbasierte Arbeitslasten auf mehreren Plattformen orchestrieren. Google Cloud, AWS und Microsoft Azure bieten verwaltete Versionen von Kubernetes.
Die Trafficverteilung auf Kubernetes-Cluster, die auf verschiedenen Cloudplattformen ausgeführt werden, ist mit einem DNS-Dienst möglich, der gewichtete Datensätze unterstützt und Systemdiagnosen durchführt.
Wichtig ist außerdem, dass Sie das Image in die Zielumgebung ziehen können. Daher ist wichtig, dass Sie im Notfall Zugriff auf Ihre Image-Registry haben. Als plattformunabhängige Lösung bietet sich hierfür Artifact Registry an.
Datenübertragung
Die Datenübertragung ist in plattformübergreifenden DR-Szenarien eine wichtige Komponente. Zum Entwerfen, Implementieren und Testen plattformübergreifender DR-Szenarien sollten Sie daher unbedingt realistische Datenübertragungsmodelle verwenden. Datenübertragungsszenarien werden im nächsten Abschnitt behandelt.
Sicherung und Notfallwiederherstellung
Der Backup- und DR-Dienst ist eine Sicherungs- und Notfallwiederherstellungslösung für Cloud-Arbeitslasten. Sie können damit Daten wiederherstellen und wichtige Geschäftsabläufe fortsetzen. Außerdem werden mehrereGoogle Cloud Produkte und DrittanbieterdatenbankenGoogle Cloud sowie Datenspeichersysteme unterstützt.
Weitere Informationen finden Sie unter Backup and DR Service – Übersicht.
DR-Muster
In diesem Bereich werden basierend auf den bereits erläuterten Bausteinen einige der gängigsten Muster für DR-Architekturen beschrieben.
Datenübertragung zur und von Google Cloud
Ein wichtiger Aspekt des DR-Plans ist die Datenübertragungsgeschwindigkeit für Übertragungen an und von Google Cloud. Dies ist besonders wichtig, wenn Sie Daten im Rahmen des DR-Plans von einer lokalen Plattform oder von einem anderen Cloud-Anbieter an Google Cloud übertragen möchten. Google CloudIn diesem Abschnitt werden Netzwerk- undGoogle Cloud -Dienste beschrieben, die einen guten Durchsatz gewährleisten.
Wenn Sie Google Cloud als Wiederherstellungsstandort für lokal oder in einer anderen Cloudumgebung ausgeführte Arbeitslasten verwenden, sind folgende Aspekte zu berücksichtigen:
- Wie verbindest du dich mit Google Cloud?
- Die zum Interconnect-Anbieter verfügbare Bandbreite
- Welche Bandbreite stellt der Anbieter direkt für Google Cloudbereit?
- Die Art der sonstigen über diese Verbindung zu übertragenen Daten
Weitere Informationen zum Übertragen von Daten zu Google Cloudfinden Sie unter Zu Google Cloudmigrieren: Große Datasets übertragen.
Image-Konfiguration und Bereitstellungsgeschwindigkeit ausbalancieren
Beim Konfigurieren eines Maschinen-Images für die Bereitstellung neuer Instanzen sollten Sie berücksichtigen, wie sich die Konfiguration auf die Bereitstellungsgeschwindigkeit auswirkt. Es gilt, einen Kompromiss zwischen dem Umfang der Image-Vorkonfiguration, den Kosten für die Image-Pflege und der Bereitstellungsgeschwindigkeit zu finden. Bei einer minimalen Konfiguration eines Maschinen-Images verlängert sich die Startzeit der Instanzen, die das Image verwenden. Dies liegt daran, dass dafür Abhängigkeiten heruntergeladen und installiert werden müssen. Bei einem umfassend konfigurierten Maschinen-Image verkürzt sich hingegen die Startzeit, aber das Image muss häufiger aktualisiert werden. Die Startdauer einer voll funktionsfähigen Instanz steht in direktem Zusammenhang mit dem RTO.
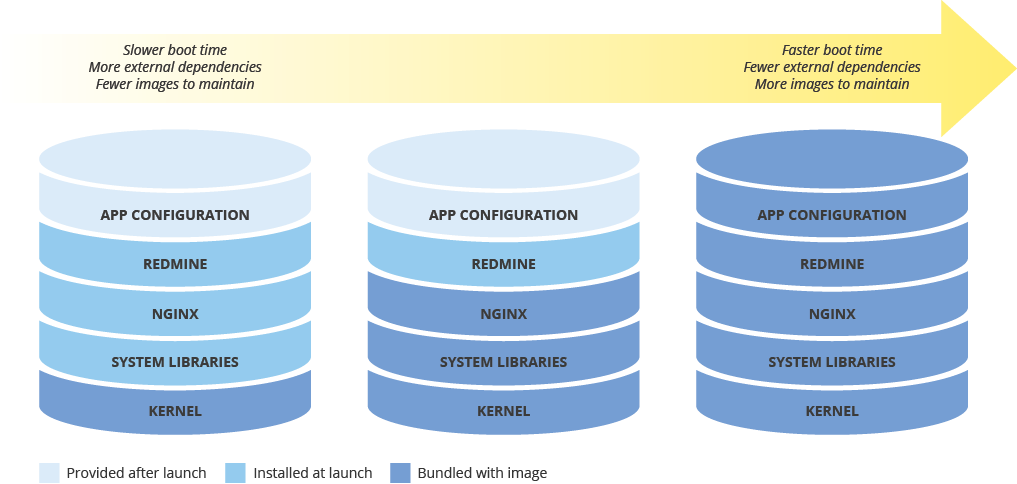
Konsistentes Maschinen-Image in Hybridumgebungen
Wenn Sie eine Hybridlösung wie Lokal-zu-Cloud oder Cloud-zu-Cloud implementieren, ist es wichtig, dass Sie die Image-Konsistenz zwischen Produktumgebungen wahren.
Wenn ein vollständig konfiguriertes Image erforderlich ist, erwägen Sie beispielsweise Packer, um identische Maschinen-Images für mehrere Plattformen zu erstellen. Sie können dieselben Skripts mit plattformspezifischen Konfigurationsdateien verwenden. Mit Packer können Sie die Version der Konfigurationsdatei prüfen und dadurch die in der Produktionsumgebung bereitgestellte Version verfolgen.
Sie können auch Konfigurationsverwaltungstools wie Chef, Puppet, Ansible oder Saltstack verwenden, um detailliertere Instanzen zu konfigurieren. Erstellen Sie je nach Bedarf Basis-Images bzw. minimal oder vollständig konfigurierte Images.
Sie können auch vorhandene Images wie etwa Amazon AMI-, Virtualbox- und RAW-Laufwerk-Images manuell konvertieren und in Compute Engine importieren.
Mehrstufigen Speicher implementieren
Mehrstufiger Speicher wird in der Regel verwendet, um die letzte Sicherung in einem schneller abrufbaren Speicher abzulegen und ältere Sicherungen nach und nach zu einem kostengünstigeren, langsamer abrufbaren Speicher zu migrieren. Wenn Sie dieses Muster anwenden, migrieren Sie Sicherungen zwischen Buckets verschiedener Speicherklassen, in der Regel von Standard- zu kostengünstigeren Speicherklassen wie Nearline und Coldline.
Um dieses Muster zu implementieren, können Sie die Verwaltung des Objektlebenszyklus verwenden. Sie können beispielsweise die Speicherklasse von Objekten, die älter als ein bestimmter Zeitraum sind, automatisch in „Coldline“ ändern.
Nächste Schritte
- Google Cloud Geografie und Regionen
Weitere Artikel dieser DR-Reihe:
- Leitfaden zur Planung der Notfallwiederherstellung
- Szenarien der Notfallwiederherstellung für Daten
- Szenarien der Notfallwiederherstellung von Anwendungen
- Architektur der Notfallwiederherstellung von Arbeitslasten mit Standortbeschränkung entwickeln
- Anwendungsfälle für die Notfallwiederherstellung: Datenanalyseanwendungen mit Standortbeschränkung
- Architektonische Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur
Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.
Beitragende
Autoren:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Cloud Solutions Architect