Dieses Dokument ist der erste Teil einer Reihe, in der die Notfallwiederherstellung (Disaster Recovery, DR) in Google Cloudbehandelt wird. Dieser Teil bietet einen Überblick über den DR-Planungsprozess und vermittelt, was Sie wissen müssen, um einen DR-Plan zu entwerfen und zu implementieren. In den folgenden Abschnitten werden spezifische Anwendungsfälle von DR mit Beispiel-Implementierungen für Google Clouderörtert.
Die Reihe besteht aus folgenden Teilen:
- Leitfaden zur Planung der Notfallwiederherstellung (dieses Dokument)
- Bausteine der Notfallwiederherstellung
- Szenarien der Notfallwiederherstellung von Daten
- Szenarien der Notfallwiederherstellung von Anwendungen
- Architektur der Notfallwiederherstellung von Arbeitslasten mit Standortbeschränkung entwickeln
- Anwendungsfälle für die Notfallwiederherstellung: Datenanalyseanwendungen mit Standortbeschränkung
- Architektonische Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur
Vorfälle, die den Dienst unterbrechen, können jederzeit geschehen. Ihr Netzwerk könnte von einem Ausfall betroffen sein, mit Ihrem letzten Anwendungs-Push könnte ein kritischer Fehler eingeführt worden sein oder Sie könnten mit einer Naturkatastrophe konfrontiert werden. Für alle möglichen Zwischenfälle es wichtig, einen soliden, zielgerichteten und erprobten DR-Plan zu haben.
Mit einem gut konzipierten und getesteten DR-Plan können Sie gewährleisten, dass im Notfall die Auswirkungen auf das Geschäftsergebnis Ihres Unternehmens minimal sind. Unabhängig von Ihren DR-Anforderungen bietet Google Cloud eine solide, flexible und kostengünstige Auswahl an Produkten und Funktionen, mit denen Sie die für Sie passende Lösung entwickeln oder erweitern können.
Grundlagen der DR-Planung
DR ist ein Teilbereich der Geschäftskontinuitätsplanung. Die DR-Planung beginnt mit einer Geschäftsauswirkungsanalyse, die zwei Schlüsselmesswerte definiert:
- Recovery Time Objective (RTO) gibt an, wie lange die Anwendung höchstens ausfallen darf. In der Regel wird dieser Wert im Rahmen eines erweiterten Service Level Agreement (SLA) definiert.
- Recovery Point Objective (RPO) ist die maximal zulässige Dauer, während der Daten aufgrund eines größeren Zwischenfalls bei der Anwendung verloren gehen können. Dieser Messwert variiert je nach Verwendungszweck der Daten. Beispielsweise können häufig geänderte Nutzerdaten ein RPO von nur wenigen Minuten haben. Im Gegensatz dazu könnten weniger kritische, selten geänderte Daten ein RPO von mehreren Stunden haben. Dieser Messwert beschreibt nur die Dauer und nicht die Menge oder Qualität der verlorenen Daten.
In der Regel gilt: Je kleiner die RTO- und RPO-Werte sind (d. h. je schneller die Anwendung nach einer Unterbrechung wiederhergestellt werden muss), desto höher sind die Kosten für die Ausführung der Anwendung. Die folgende Grafik zeigt das Verhältnis zwischen den Kosten und den Messwerten RTO/RPO.
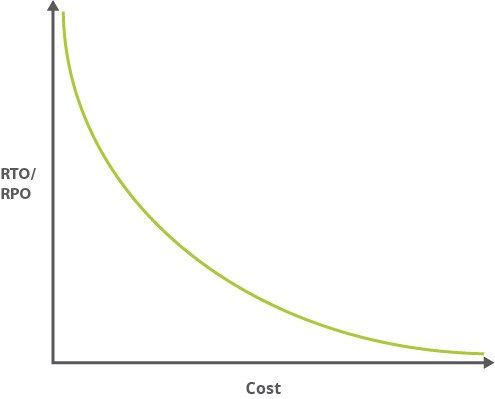
Da kleinere RTO- und RPO-Werte oft mit einer größeren Komplexität einhergehen, folgt der damit verbundene Verwaltungsaufwand einer ähnlichen Kurve. Bei einer Anwendung mit hoher Verfügbarkeit müssen Sie unter Umständen die Verteilung zwischen zwei räumlich voneinander getrennten Rechenzentren, die Replikation und vieles mehr verwalten.
RTO- und RPO-Werte werden im Allgemeinen zu einem weiteren Messwert zusammengefasst, dem Service Level Objective (SLO). Dies ist ein messbares Schlüsselelement eines SLA. SLAs und SLOs werden häufig nicht richtig voneinander unterschieden. Ein SLA ist die gesamte Vereinbarung. Sie regelt, welche Dienste erbracht werden sollen, wie sie unterstützt werden, die Zeiten, Orte, Kosten, Leistungen, Strafen sowie die Verantwortlichkeiten der beteiligten Parteien. SLOs hingegen sind spezifische, messbare Eigenschaften des SLA, wie Verfügbarkeit, Durchsatz, Häufigkeit, Reaktionszeit oder Qualität. Ein SLA kann viele SLOs enthalten. RTOs und RPOs sind messbar und sollten als SLOs betrachtet werden.
Weitere Informationen zu SLOs und SLAs finden Sie im Buch über Google Site Reliability Engineering.
Möglicherweise planen Sie auch eine Architektur für hohe Verfügbarkeit (high availability – HA). HA überschneidet sich nicht vollständig mit DR, muss aber häufig in Überlegungen zu RTO- und RPO-Werten einbezogen werden. HA hilft dabei, eine vereinbarte Betriebsleistung zu gewährleisten, die in der Regel länger als die Standardverfügbarkeit ist. Wenn Sie Produktionsarbeitslasten aufGoogle Cloudausführen, können Sie ein global verteiltes System verwenden, sodass die Anwendung im Falle eines Fehlers in einer Region weiterhin Dienste bereitstellt, auch wenn sie allgemein weniger verfügbar ist. Im Wesentlichen ruft diese Anwendung hier ihren DR-Plan auf.
Warum Google Cloud?
Google Cloud kann die mit RTO und RPO verbundenen Kosten im Vergleich zur lokalen Erfüllung der RTO- und RPO-Anforderungen erheblich reduzieren. Bei der DR-Planung müssen Sie beispielsweise eine Reihe von Anforderungen berücksichtigen, darunter:
- Kapazität: Bereitstellung von ausreichenden Ressourcen für die bedarfsgerechte Skalierung
- Sicherheit: physische Sicherheit zum Schutz von Assets
- Netzwerkinfrastruktur: Softwarekomponenten wie Firewalls und Load-Balancer
- Support: Einsatz qualifizierter Ingenieure für Wartungsarbeiten und zur Problembehebung
- Bandbreite: Angemessene Bandbreite für Spitzenlasten
- Anlagen: Physische Infrastruktur wie Ausrüstung und Stromversorgung
MitGoogle Cloud können Sie durch die Bereitstellung einer vollständig verwalteten Lösung auf einer erstklassigen Produktionsplattform die meisten oder alle diese Anforderungen umgehen und so Ihre Geschäftskosten senken. Dank der administrativen Einfachheit von Google Cloudlassen sich außerdem die Kosten für die Verwaltung einer komplexen Anwendung senken.
Google Cloud bietet mehrere Funktionen, die für die DR-Planung relevant sind, darunter:
- Ein globales Netzwerk. Google hat eines der größten und fortschrittlichsten Computernetzwerke der Welt. Das Backbonenetzwerk von Google nutzt ein modernes softwarebasiertes Netzwerk und Edge-Caching-Dienste, um eine hohe, konsistente und skalierbare Leistung zu bieten.
- Redundanz. Zahlreiche Points of Presence (POPs) auf der ganzen Welt sorgen für hohe Redundanz. Ihre Daten werden automatisch auf Speichergeräten an mehreren Standorten gespiegelt.
- Skalierbarkeit: Google Cloud lässt sich wie andere Google-Produkte (z. B. die Google Suche oder Gmail) skalieren, selbst dann, wenn enorme Trafficspitzen auftreten. Verwaltete Dienste wie Cloud Run, Compute Engine und Firestore ermöglichen eine automatische Skalierung, daher kann eine Anwendung nach Bedarf vergrößert und verkleinert werden.
- Sicherheit. Das Sicherheitsmodell von Google basiert auf jahrzehntelanger Erfahrung im Bestreben, die Sicherheit der Nutzer von Google-Anwendungen wie Gmail und Google Workspace zu schützen. Darüber hinaus gewährleisten die Site Reliability Engineering-Teams von Google eine hohe Verfügbarkeit und den Schutz vor Missbrauch von Plattformressourcen.
- Compliance. Google lässt regelmäßig unabhängige Überprüfungen von Drittanbietern vornehmen, um festzustellen, ob Google Cloud mit Sicherheits-, Datenschutz- und Compliancebestimmungen und den entsprechenden Best Practices im Einklang steht. Google Cloud erfüllt Zertifizierungsstandards wie etwa ISO 27001, SOC 2/3 und PCI DSS 3.0.
DR-Muster
Bei DR-Mustern wird zwischen sogenannten kalten, warmen und heißen Mustern unterschieden. Diese Mustertypen geben an, wie schnell das System nach einem Fehler wiederhergestellt werden kann. Dies wäre beispielsweise mit dem vergleichbar, was Sie zur Behebung einer Reifenpanne tun würden.
Wie Sie eine solche Reifenpanne beheben, hängt davon ab, wie gut Sie darauf vorbereitet sind:
- Kalt: Sie haben kein Reserverad, Sie müssen also jemanden anrufen, der mit einem neuen Rad kommt und dieses montiert. Ihre Fahrt ist unterbrochen, bis Hilfe für die Reparatur eintrifft.
- Warm: Sie haben ein Reserverad und ein Werkzeugset, können also das Rad selbst wechseln und danach weiterfahren. Sie müssen jedoch Ihre Fahrt unterbrechen, um das Problem zu beheben.
- Heiß: Sie haben Notlaufreifen. Möglicherweise müssen Sie etwas langsamer fahren, aber es hat keine unmittelbaren Auswirkungen auf die Fahrt. Ihre Reifen laufen gut genug, um weiterfahren zu können (obwohl Sie das Problem später beheben müssen).
Detaillierten DR-Plan erstellen
Dieser Abschnitt enthält Empfehlungen zur Erstellung eines DR-Plans.
Entwicklung im Hinblick auf die Wiederherstellungsziele
Beim Entwurf eines DR-Plans müssen Sie Ihre Techniken für die Anwendungs- und Datenwiederherstellung kombinieren und das Gesamtbild betrachten. Als Best Practice gilt im Allgemeinen, hierbei von den RTO- und RPO-Werten sowie dem DR-Muster auszugehen, das Sie verwenden können, um diese Werte zu erreichen. Bei Compliance-relevanten Verlaufsdaten benötigen Sie beispielsweise wahrscheinlich keinen schnellen Zugriff auf die Daten. Daher sind ein hoher RTO-Wert und ein kaltes DR-Muster angemessen. Bei einer Unterbrechung Ihres Onlinedienstes sollten Sie jedoch in der Lage sein, sowohl die Daten als auch den für den Nutzer relevanten Teil der Anwendung so schnell wie möglich wiederherzustellen. In diesem Fall wäre daher ein heißes Muster geeigneter. Für Ihr E-Mail-Benachrichtigungssystem, das normalerweise nicht geschäftskritisch ist, reicht wahrscheinlich ein warmes Muster aus.
Anleitungen zur Verwendung von Google Cloud für allgemeine DR-Szenarien finden Sie in den Szenarien der Anwendungswiederherstellung. Diese Szenarien veranschaulichen gezielte DR-Strategien für eine Vielzahl von Anwendungsfällen und enthalten entsprechende Beispiel-Implementierungen fürGoogle Cloud .
Entwicklung im Hinblick auf eine durchgängige Wiederherstellung
Ein Plan für die Sicherung oder Archivierung der Daten allein reicht nicht aus. Der DR-Plan muss den vollständigen Wiederherstellungsprozess abdecken, von der Sicherung über die Wiederherstellung bis zur Bereinigung. Dies wird in den verwandten Dokumenten zu DR-Daten und zur Wiederherstellung noch näher erläutert.
Spezifische Aufgaben gestalten
Wenn der DR-Plan zum Einsatz kommen muss, haben Sie keine Zeit, darüber nachzudenken, was jeder einzelne Schritt bedeutet. Gliedern Sie daher jeden Schritt des DR-Plans im Vorfeld in konkrete, unmissverständliche Befehle oder Aktionen. Die Aktion "Wiederherstellungsskript ausführen" ist beispielsweise zu allgemein formuliert. Im Gegensatz dazu ist „Öffne eine Shell und führe /home/example/restore.sh aus“ präzise und konkret.
Kontrollmaßnahmen umsetzen
Setzen Sie Steuerelemente ein, um Notfällen vorzubeugen und Probleme zu erkennen, bevor sie auftreten. Implementieren Sie beispielsweise ein Überwachungsobjekt, das bei unerwarteten Spitzen oder ungewöhnlicher Aktivität eines datenzerstörenden Flusses, wie etwa einer Lösch-Pipeline, eine Warnmeldung ausgibt. Diese Überwachungsfunktion könnte auch Pipeline-Prozesse beenden, wenn beim Löschen ein bestimmter Grenzwert erreicht wird, um so möglichen Schäden vorzubeugen.
Software vorbereiten
Als weiterer Bestandteil der DR-Planung müssen Sie gewährleisten, dass die Software Ihrer Wahl für ein Wiederherstellungsereignis bereit ist.
Prüfen, ob die Software installiert werden kann
Achten Sie darauf, dass die Anwendungssoftware von der Quelle oder von einem vorkonfigurierten Image installiert werden kann. Außerdem müssen Sie für jede Software, die Sie auf Google Cloudbereitstellen, eine entsprechende Lizenz haben. Erfragen Sie dies gegebenenfalls beim Lieferanten der Software.
Achten Sie darauf, dass in der Wiederherstellungsumgebung die erforderlichen Compute Engine-Ressourcen verfügbar sind. Dazu müssen möglicherweise vorab Instanzen zugewiesen oder reserviert werden.
Kontinuierliche Bereitstellung für die Wiederherstellung entwerfen
Das Toolset für die kontinuierliche Bereitstellung (Continuous Deployment – CD) ist für die Bereitstellung von Anwendungen eine wichtige Komponente. Berücksichtigen Sie als Teil Ihres Wiederherstellungsplans, wo in der wiederhergestellten Umgebung Artefakte bereitgestellt werden. Planen Sie, wo Sie die CD-Umgebung und Artefakte hosten möchten, diese müssen im Notfall verfügbar und einsatzbereit sein.
Sicherheits- und Compliancekontrollen einrichten
Wenn Sie einen DR-Plan erstellen, ist Sicherheit wichtig. Die Kontrollen, die Sie in Ihrer Produktionsumgebung haben, müssen auch für die wiederhergestellte Umgebung gelten. Compliancevorschriften gelten auch für wiederhergestellte Umgebungen.
Sicherheit für DR- und Produktionsumgebungen identisch konfigurieren
Achten Sie darauf, dass die Netzwerkkontrollen dieselben Trenn- und Sperrfunktionen bieten wie die der Quellproduktionsumgebung. Informieren Sie sich, wie Sie eine freigegebene VPC und Firewalls konfigurieren, um eine zentrale Netzwerk- und Sicherheitskontrolle für die Bereitstellung einzurichten, Subnetze zu konfigurieren und eingehenden und ausgehenden Traffic zu steuern. Informieren Sie sich, wie Sie Dienstkonten nutzen, um die jeweils nur geringsten Berechtigungen für Anwendungen zu implementieren, die auf Google Cloud APIs zugreifen. Achten Sie auch darauf, die Dienstkonten als Teil der Firewallregeln zu verwenden.
Gewähren Sie Nutzern den gleichen Zugriff auf die DR-Umgebung, den sie auch in der Quellproduktionsumgebung haben. In der folgenden Liste werden Möglichkeiten zum Synchronisieren von Berechtigungen zwischen Umgebungen beschrieben:
Wenn Ihre Produktionsumgebung Google Cloudist, ist das Replizieren von IAM-Richtlinien in der DR-Umgebung unkompliziert. Sie können Infrastruktur als Code (IaC)-Tools wie Terraform verwenden, um IAM-Richtlinien für die Produktion bereitzustellen. Dieselben Tools verwenden Sie, um die Richtlinien mit den entsprechenden Ressourcen beim Aufbau der DR-Umgebung zu verknüpfen.
Bei einer lokalen Produktionsumgebung ordnen Sie die funktionalen Rollen, wie die des Netzwerkadministrators und Prüfers, den IAM-Richtlinien mit den entsprechenden IAM-Rollen zu. In der IAM-Dokumentation finden Sie einige Beispielkonfigurationen für funktionale Rollen, beispielsweise in der Dokumentation zur Erstellung von funktionalen Netzwerkrollen und für das Audit-Logging.
Sie müssen IAM-Richtlinien konfigurieren, um den Produkten die korrekten Berechtigungen zu gewähren. Beispielsweise möchten Sie möglicherweise den Zugriff auf bestimmte Cloud Storage-Buckets beschränken.
Wenn Ihre Produktionsumgebung von einem anderen Cloud-Anbieter gehostet wird, ordnen Sie die IAM-Berechtigungen des Anbieters den Google Cloud IAM-Richtlinien zu.
DR-Sicherheit prüfen
Testen Sie alles, nachdem Sie die Berechtigungen für die DR-Umgebung konfiguriert haben. Erstellen Sie eine Testumgebung. Achten Sie darauf, dass die Berechtigungen, die Sie Nutzern gewähren, mit den Berechtigungen übereinstimmen, die die Nutzer lokal haben.
Zugriff von Nutzern auf DR-Umgebung sicherstellen
Warten Sie nicht, bis ein Notfall tatsächlich eintritt, sondern prüfen Sie vorher, ob Nutzer auf die DR-Umgebung zugreifen können. Achten Sie darauf, dass Sie Nutzern, Entwicklern, Betreibern, Data Scientists, Sicherheitsadministratoren, Netzwerkadministratoren und anderen Rollen in Ihrer Organisation die entsprechenden Zugriffsrechte erteilt haben. Wenn Sie ein alternatives Identitätssystem verwenden, müssen die Konten mit Ihrem Cloud Identity-Konto synchronisiert werden. Da die DR-Umgebung vorübergehend Ihre Produktionsumgebung sein könnte, fordern Sie Nutzer, die Zugriff auf die DR-Umgebung benötigen, auf, sich anzumelden und eventuelle Authentifizierungsprobleme zu lösen. Beziehen Sie Nutzer, die sich in der DR-Umgebung anmelden müssen, in Ihre DR-Tests ein.
Für eine zentrale Verwaltung der Administratorzugriffe auf die virtuellen Maschinen (VMs), die gestartet werden, aktivieren Sie das OS Login in den Google Cloud Projekten, die Ihre DR-Umgebung bilden.
Nutzer schulen
Nutzer müssen wissen, wie Vorgänge, die sie in der Produktionsumgebung ausführen, wie Anmeldung und Zugriff auf VMs, in Google Cloud funktionieren. Schulen Sie die Nutzer in der Testumgebung, um ihnen zu vermitteln, wie sie diese Aufgaben unter Gewährleistung der Systemsicherheit ausführen.
Prüfen, ob die DR-Umgebung die Complianceanforderungen erfüllt
Achten Sie darauf, dass nur die Personen Zugriff auf die DR-Umgebung erhalten, die ihn effektiv benötigen. Die PII-Daten müssen geändert und verschlüsselt werden. Wenn Sie in Ihrer Produktionsumgebung regelmäßig Penetrationstests durchführen, sollten Sie auch die DR-Umgebung in dieses Verfahren einbeziehen und während des Aufbaus der DR-Umgebung regelmäßige Tests machen.
Achten Sie darauf, dass Logs, die während des Betriebs der DR-Umgebung erstellt werden, auch in das Log-Archiv Ihrer Produktionsumgebung übertragen werden. Ebenso können Sie mit Cloud Logging erfasste Audit-Logs aus der DR-Umgebung in das Hauptarchiv der Logsenke exportieren. Verwenden Sie hierzu die Funktionen für Exportsenken. Spiegeln Sie die Anwendungs-Logs aus der lokalen Logging- und Überwachungsumgebung. Wenn Ihre Produktionsumgebung von einem anderen Cloudanbieter gehostet wird, ordnen Sie die das Logging und die Überwachung dieses Anbieters den entsprechenden Google Cloud -Diensten zu. Implementieren Sie ein Verfahren zum Formatieren von Eingaben in der Produktionsumgebung.
Wiederhergestellte Daten wie Produktionsdaten behandeln
Die Sicherheitskontrollen, die Sie an Produktionsdaten vornehmen, müssen auch auf die wiederhergestellten Daten angewendet werden. Für Berechtigungen, Verschlüsselung und Überwachung gelten die gleichen Berechtigungen.
Ermitteln Sie, wo sich Ihre Sicherungskopien befinden und wer berechtigt ist, Daten wiederherzustellen. Der Wiederherstellungsprozess muss überprüfbar sein. Nach einer Notfallwiederherstellung müssen Sie sehen können, wer auf die Sicherungsdaten zugreifen konnte und wer die Wiederherstellung durchgeführt hat.
DR-Plan auf korrekte Funktion prüfen
Achten Sie darauf, dass der DR-Plan wie vorgesehen funktioniert.
Mehr als einen Datenwiederherstellungspfad pflegen
Im Notfall ist die Methode für den Verbindungsaufbau zu Google Cloud möglicherweise nicht mehr verfügbar. Implementieren Sie eine Alternative für den Zugriff aufGoogle Cloud , damit Sie auch im Notfall Daten inGoogle Cloudübertragen können. Testen Sie regelmäßig, ob der Sicherungspfad funktioniert.
Plan regelmäßig testen
Nachdem Sie einen DR-Plan erstellt haben, sollten Sie diesen regelmäßig testen, eventuell aufgetretene Probleme beachten und den Plan entsprechend anpassen. Mit Google Cloudkönnen Sie Wiederherstellungsszenarien sehr kostengünstig testen. Folgende empfohlene Maßnahmen unterstützen Sie beim Testen:
- Infrastrukturbereitstellung automatisieren. Sie können IaC-Tools wie Terraform verwenden, um die Bereitstellung Ihrer Google Cloud-Infrastruktur zu automatisieren. Bei einer lokalen Produktionsumgebung benötigen Sie ein Überwachungsverfahren, das bei Erkennung eines Fehlers den DR-Prozess starten und die entsprechenden Wiederherstellungsaktionen auslösen kann.
- Umgebungen mit Google Cloud Observability überwachen:Google Cloud bietet hervorragende Logging- und Überwachungstools, auf die Sie per API-Aufruf zugreifen können. Damit können Sie die Bereitstellung bestimmter Wiederherstellungsszenarien auf der Grundlage von Messwerten automatisieren. Achten Sie auch beim Entwurf der Tests darauf, dass Überwachungs- und Benachrichtigungsfunktionen verfügbar sind, die geeignete Wiederherstellungsaktionen auslösen können.
Den zuvor beschriebenen Test machen:
- Testen Sie, ob Berechtigungen und Nutzerzugriff in der DR-Umgebung wie in der Produktionsumgebung funktionieren.
- Führen Sie Penetrationstests in der DR-Umgebung durch.
- Testen Sie den Fall, in dem Ihr gewöhnlicher Zugriffspfad für Google Cloudnicht mehr funktioniert.
Nächste Schritte
- Google Cloud Geografie und Regionen
- Weitere Dokumente in dieser DR-Reihe:
- Bausteine der Notfallwiederherstellung
- Szenarien der Notfallwiederherstellung von Daten
- Szenarien der Notfallwiederherstellung von Anwendungen
- Architektur der Notfallwiederherstellung von Arbeitslasten mit Standortbeschränkung entwickeln
- Anwendungsfälle für die Notfallwiederherstellung: Datenanalyseanwendungen mit Standortbeschränkung
- Architektonische Notfallwiederherstellung bei Ausfällen der Cloud-Infrastruktur
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.
Beitragende
Autoren:
- Grace Mollison | Solutions Lead
- Marco Ferrari | Cloud Solutions Architect