In diesem Dokument werden für Datenanalysten, Data Scientists und Business-Analysten die Prozesse und Aspekte der Analyse von Fast Healthcare Interoperability Resources (FHIR)-Daten in BigQuery erläutert.
Es geht in diesem Dokument insbesondere um Ressourcendaten von Patienten, die aus dem FHIR-Speicher in der Cloud Healthcare API exportiert werden. In diesem Dokument wird auch eine Reihe von Abfragen schrittweise behandelt, in denen die Funktionsweise von FHIR-Schemadaten in einem relationalen Format gezeigt wird. Außerdem erfahren Sie, wie Sie zur Wiederverwendung dieser Abfragen mithilfe von Ansichten auf sie zugreifen können.
FHIR-Daten mit BigQuery analysieren
Die FHIR-spezifische API der Cloud Healthcare API ist für die transaktionale Interaktion mit FHIR-Daten in Echtzeit auf der Ebene einer einzelnen FHIR-Ressource oder einer Sammlung von FHIR-Ressourcen konzipiert. Die FHIR API ist jedoch nicht für Analytics-Anwendungsfälle vorgesehen. Für diese Anwendungsfälle empfehlen wir, Ihre Daten aus der FHIR API in BigQuery zu exportieren. BigQuery ist ein serverloses, skalierbares Data Warehouse, mit dem Sie große Datenmengen rückblickend oder vorausschauend analysieren können.
Außerdem entspricht BigQuery dem Standard ANSI:2011 SQL. Dadurch können Data Scientists und Business-Analysten über Tools, die sie üblicherweise verwenden, wie Tableau, Looker oder Vertex AI Workbench, auf Daten zugreifen.
In einigen Anwendungen wie Vertex AI Workbench erhalten Sie Zugriff über integrierte Clients wie die Python-Clientbibliothek für BigQuery. In diesen Fällen sind die an die Anwendung zurückgegebenen Daten über integrierte Sprachdatenstrukturen verfügbar.
Auf BigQuery zugreifen
Sie können auf BigQuery über die BigQuery-Web-UI in der Google Cloud Console sowie mit den folgenden Tools zugreifen:
- Das Befehlszeilentool von BigQuery
- Die REST API oder die Clientbibliotheken von BigQuery
- ODBC- und JDBC-Treiber
Mithilfe dieser Tools können Sie BigQuery in fast jede Anwendung integrieren.
Mit der FHIR-Datenstruktur arbeiten
Die integrierte FHIR-Standarddatenstruktur ist komplex und umfasst verschachtelte und eingebettete FHIR-Datentypen in jeder FHIR-Ressource. Diese einzubettenden FHIR-Datentypen werden als komplexe Datentypen bezeichnet.
Arrays und Strukturen werden in relationalen Datenbanken auch als komplexe Datentypen bezeichnet. Die integrierte FHIR-Standarddatenstruktur funktioniert gut als serialisierte XML- oder JSON-Dateien in einem dokumentenbasierten System, kann aber bei der Übersetzung in relationale Datenbanken eine Herausforderung darstellen.
Der folgende Screenshot zeigt eine Teilansicht eines FHIR-Datentyps patient resource, der die komplexe Natur der integrierten FHIR-Standarddatenstruktur veranschaulicht.
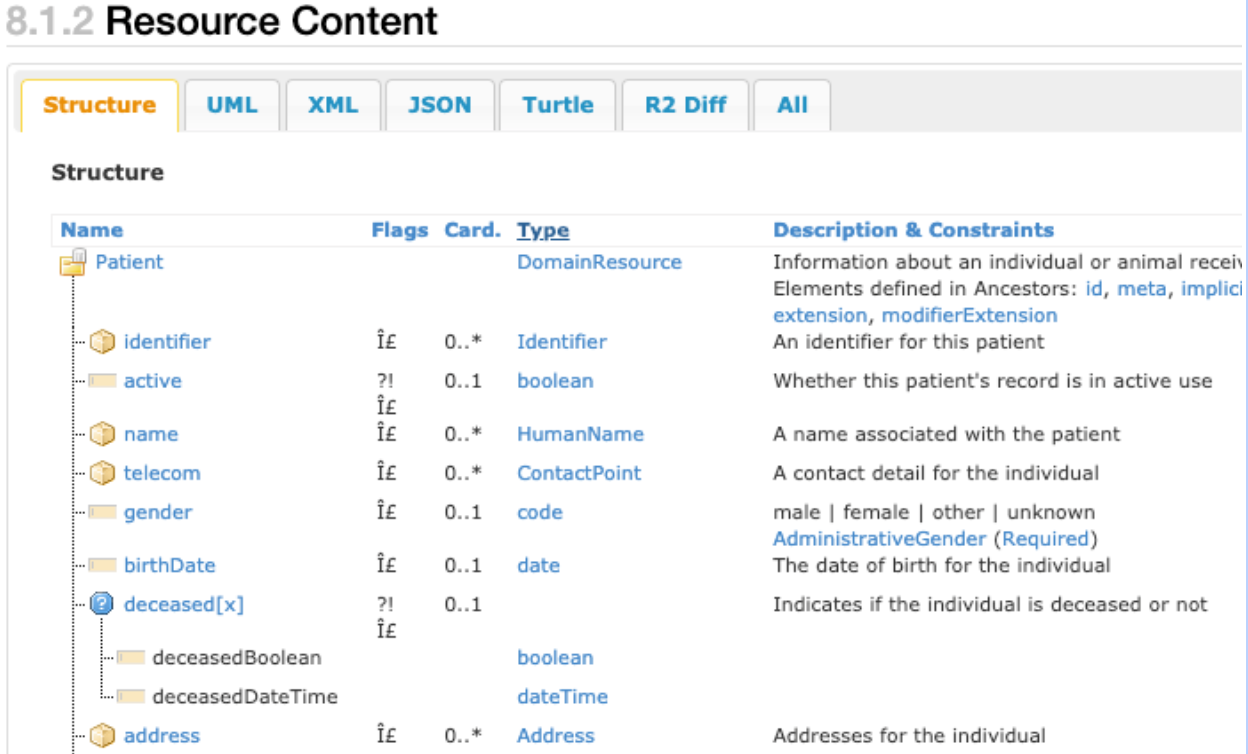
Der vorherige Screenshot zeigt die primären Komponenten eines FHIR-Datentyps patient
resource. Die Spalte Cardinality (in der Tabelle als Card. angegeben) enthält beispielsweise mehrere Elemente, die null, einen oder mehrere Einträge haben können. Die Spalte Typ enthält die Datentypen Identifier, HumanName und Address. Dies sind Beispiele für komplexe Datentypen, die den Datentyp patient
resource umfassen. Jede dieser Zeilen kann mehrmals als Array von Strukturen erfasst werden.
Arrays und Strukturen verwenden
BigQuery unterstützt Arrays und STRUCT-Datentypen, also verschachtelte, sich wiederholende Datenstrukturen, wie sie in FHIR-Ressourcen dargestellt werden. Dadurch wird die Datenumwandlung von FHIR zu BigQuery ermöglicht.
In BigQuery ist ein Array eine geordnete Liste, die aus null oder mehr Werten desselben Datentyps besteht. Sie können Arrays mit einfachen Datentypen, wie dem INT64-Datentyp, und komplexen Datentypen, wie dem STRUCT-Datentyp, erstellen. Die Ausnahme ist der Datentyp ARRAY, da Arrays von Arrays derzeit nicht unterstützt werden. In BigQuery wird ein Array von Strukturen als wiederholbarer Datensatz angezeigt.
Sie können verschachtelte oder verschachtelte und wiederkehrende Daten in der BigQuery-Benutzeroberfläche oder in einer JSON-Schemadatei angeben. Um verschachtelte Spalten oder verschachtelte und wiederkehrende Spalten anzugeben, verwenden Sie den Datentyp RECORD (STRUCT).
Die Cloud Healthcare API unterstützt das SQL on FHIR-Schema in BigQuery. Dieses Analyseschema ist das Standardschema für die Methode ExportResources() und wird von der FHIR-Community unterstützt.
BigQuery unterstützt denormalisierte Daten. Das bedeutet, dass Sie beim Speichern Ihrer Daten anstelle eines relationalen Schemas, etwa in Form eines Sterns oder einer Schneeflocke, Ihre Daten denormalisieren und verschachtelte und wiederkehrende Spalten verwenden können. Verschachtelte und wiederkehrende Spalten bewahren Beziehungen zwischen Datenelementen, ohne die Leistung wie bei relationalen bzw. normalisierten Schemas zu beeinträchtigen.
Zugriff auf Ihre Daten über den Operator UNNEST
Jede FHIR-Ressource in der FHIR API wird als eine Datenzeile in BigQuery exportiert. Sie können sich ein Array oder eine Struktur innerhalb einer beliebigen Zeile als eingebettete Tabelle vorstellen. Auf Daten in dieser "Tabelle" können Sie entweder in der SELECT- oder der WHERE-Klausel Ihrer Abfrage zugreifen, indem Sie das Array oder die Struktur mithilfe des Operators UNNEST vereinfachen.
Der Operator UNNEST verwendet ein Array und gibt dann eine Tabelle mit jeweils einer Zeile für jedes Element im Array zurück. Weitere Informationen finden Sie unter Mit Arrays in Standard-SQL arbeiten.
Der UNNEST-Vorgang behält die Reihenfolge der Arrayelemente nicht bei. Sie können die Tabelle jedoch mithilfe der optionalen WITH OFFSET-Klausel neu anordnen. Dadurch wird für jedes Arrayelement eine zusätzliche Spalte mit der OFFSET-Klausel zurückgegeben.
Sie können dann die ORDER BY-Klausel verwenden, um die Zeilen nach deren Versatz zu ordnen.
Beim Zusammenführen nicht verschachtelter Daten verwendet BigQuery einen korrelierten CROSS JOIN-Vorgang, der die Spalte mit den Arrays aus jedem Element im Array mit der Quelltabelle referenziert. Dies ist die Tabelle, die dem UNNEST-Aufruf in der FROM-Klausel direkt vorangestellt ist. Für jede Zeile in der Quelltabelle vereinfacht der UNNEST-Vorgang das Array aus dieser Zeile zu einem Satz von Zeilen, der die Array-Elemente enthält. Der korrelierte CROSS JOIN-Vorgang führt diesen neuen Satz von Zeilen mit der einzelnen Zeile der Quelltabelle zusammen.
Das Schema mit Abfragen untersuchen
Für die Abfrage von FHIR-Daten in BigQuery ist es wichtig, das Schema zu verstehen, das durch den Exportvorgang erstellt wird. In BigQuery können Sie die Spaltenstruktur jeder Tabelle im Dataset mithilfe der Funktion INFORMATION_SCHEMA untersuchen, einer Reihe von Ansichten, die Metadaten anzeigen. Der Rest dieses Dokuments bezieht sich auf das SQL on FHIR-Schema, das für den Abruf von Daten entwickelt wurde.
Mit der folgenden Beispielabfrage werden die Spaltendetails für die Patiententabelle im SQL on FHIR-Schema analysiert. Die Abfrage verweist auf das öffentliche Dataset Synthea-generierte synthetische Daten in FHIR, in dem über 1 Million synthetische Patienteneinträge im Synthea- und FHIR-Format generiert werden.
Wenn Sie die Ansicht INFORMATION_SCHEMA.COLUMNS abfragen, wird in den Abfrageergebnissen jede Spalte (jedes Feld) einer Tabelle in einer eigenen Zeile dargestellt. Die folgende Abfrage gibt alle Spalten in der Patiententabelle zurück:
SELECT * FROM `bigquery-public-data.fhir_synthea.INFORMATION_SCHEMA.COLUMNS` WHERE table_name='patient'
Der folgende Screenshot des Abfrageergebnisses zeigt den Datentyp identifier und das Array innerhalb des Datentyps, das die STRUCT-Datentypen enthält.

FHIR-Patientenressource in BigQuery verwenden
Die Krankenaktennummer von Patienten (Medical Record Number, MRN) ist eine kritische Information, die in Ihren FHIR-Daten gespeichert ist. Sie wird für alle Patienten in sämtlichen klinischen und operativen Datensystemen eines Unternehmens verwendet. Jede Methode für den Zugriff auf Daten eines einzelnen Patienten oder einer Gruppe von Patienten muss nach der MRN filtern oder sie zurückgeben oder beides.
Die folgende Beispielabfrage gibt die interne FHIR-Server-ID an die Patientenressource selbst zurück, einschließlich der MRN und des Geburtsdatums aller Patienten. Der Filter für die Abfrage einer bestimmten MRN ist ebenfalls enthalten, wird in diesem Beispiel jedoch auskommentiert.
In dieser Abfrage heben Sie die Verschachtelung des komplexen Datentyps identifier zweimal auf. Sie verwenden auch korrelierte CROSS JOIN-Vorgänge, um nicht verschachtelte Daten mit ihrer Quelltabelle zusammenzuführen.
Die Tabelle bigquery-public-data.fhir_synthea.patient in der Abfrage wurde mit der SQL on FHIR-Schemaversion des FHIR-zu-BigQuery-Exports erstellt.
SELECT id, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b"
Die Ausgabe sieht in etwa so aus:
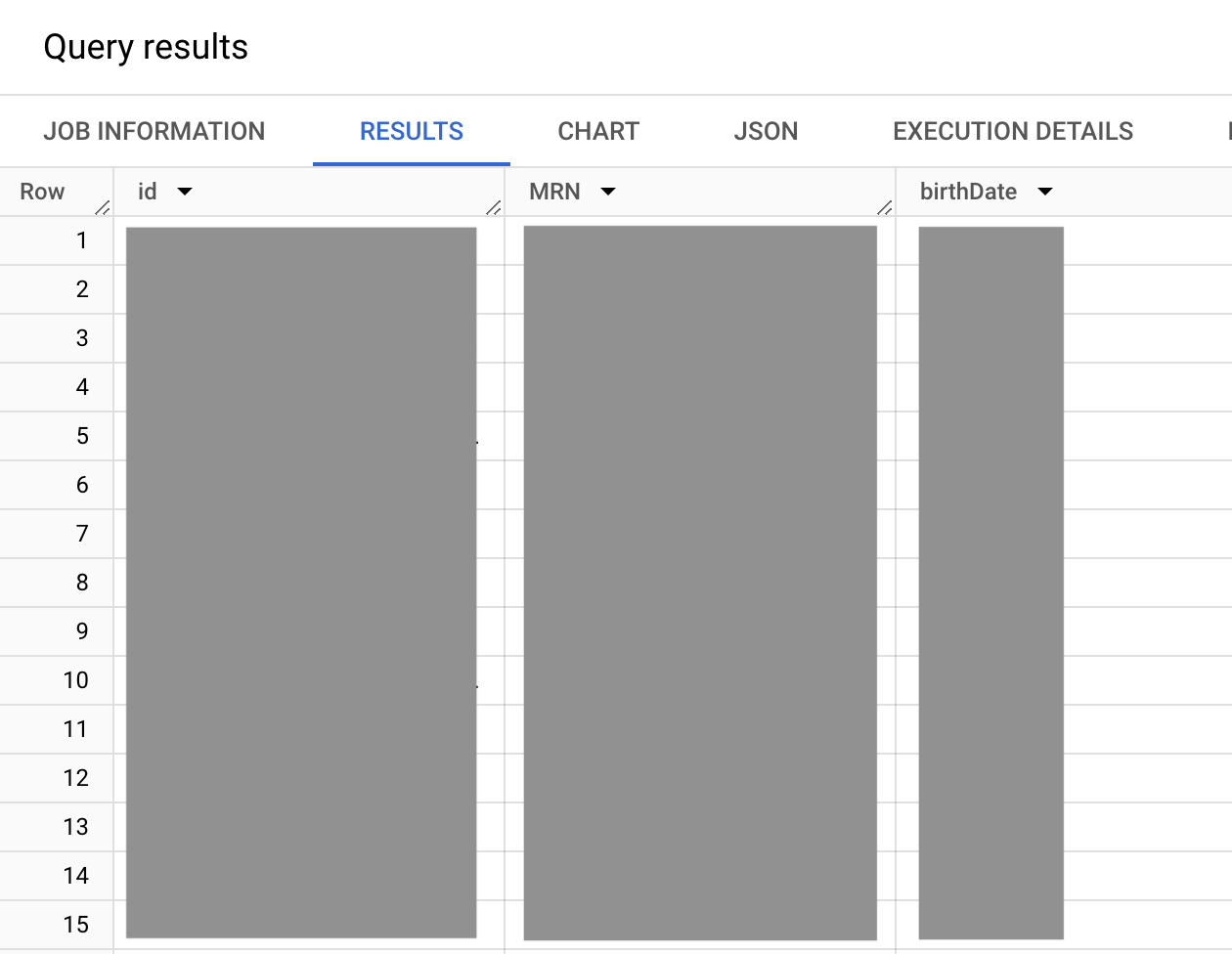
In der vorherigen Abfrage ist der Wertesatz identifier.type.coding.code der FHIR-identifier-Wertesatz, der verfügbare Identitätsdatentypen auflistet, z. B. die MRN (Identitätsdatentyp MR), den Führerschein (Identitätsdatentyp DL) und die Passnummer (Identitätsdatentyp PPN). Da der Wertesatz identifier.type.coding ein Array ist, kann für einen Patienten eine beliebige Anzahl von Identifiern angegeben werden. In diesem Fall sind Sie jedoch an der MRN (Identitätsdatentyp MR) interessiert.
Patiententabelle mit anderen Tabellen zusammenführen
Aufbauend auf der Abfrage der Patiententabelle können Sie die Patiententabelle mit anderen Tabellen in diesem Dataset zusammenführen, z. B. der Krankheitstabelle. Die Krankheitstabelle ist der Ort, an dem die Patientendiagnosen erfasst werden.
Die folgende Beispielabfrage ruft alle Einträge für den Krankheitszustand Bluthochdruck (Hypertension) ab.
SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003'
Die Ausgabe sieht in etwa so aus:
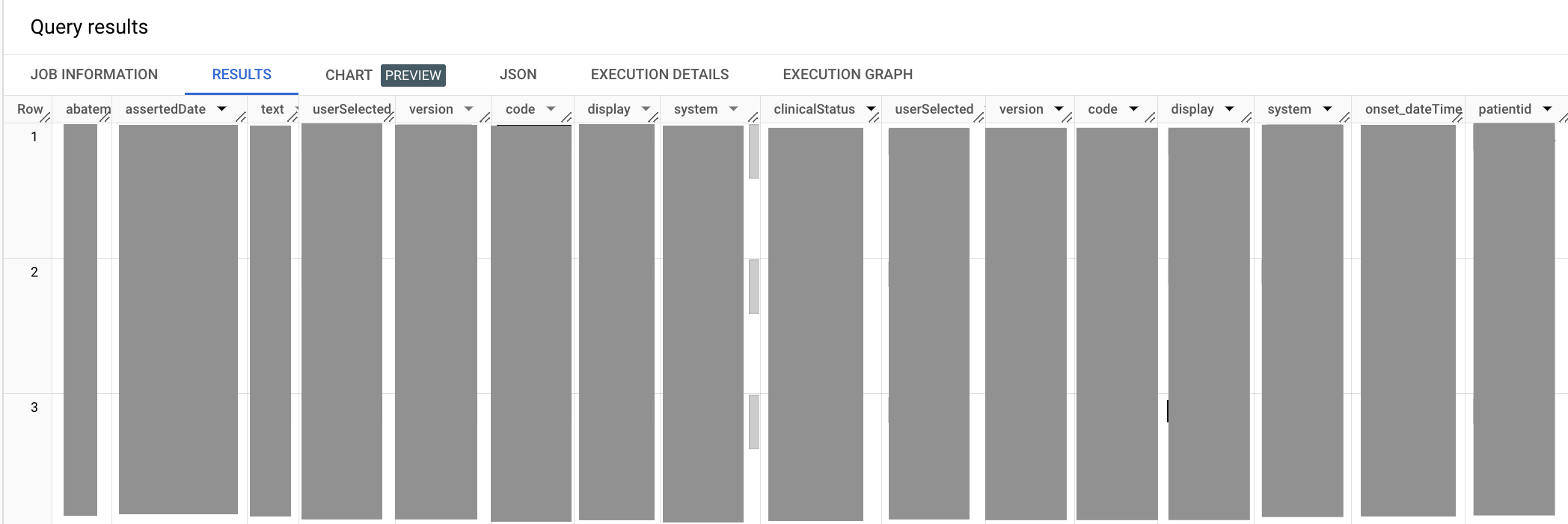
In der vorherigen Abfrage verwenden Sie die Methode UNNEST wieder, um das Feld code.coding zu vereinfachen. Die Codeelemente abatement.dateTime und onset.dateTime in der SELECT-Anweisung werden mit einem Alias versehen, da beide auf dateTime enden, was zu mehrdeutigen Spaltennamen in der Ausgabe einer SELECT-Anweisung führen würde. Wenn Sie den Hypertension-Code auswählen, müssen Sie auch das Terminologiesystem angeben, aus dem der Code stammt, in diesem Fall aus dem klinischen Terminologiesystem SNOMED CT.
Als letzten Schritt verwenden Sie den Schlüssel subject.patientid, um die Krankheitstabelle mit der Patiententabelle zusammenzuführen. Dieser Schlüssel verweist innerhalb des FHIR-Servers auf die Kennung der Patientenressource selbst.
Die Abfragen zusammenführen
In der folgenden Beispielabfrage verwenden Sie die Abfragen aus den beiden vorherigen Abschnitten und führen sie mithilfe der WITH-Klausel zusammen. Dabei führen Sie einige einfache Berechnungen durch.
WITH patient AS ( SELECT id as patientid, i.value as MRN, birthDate FROM `bigquery-public-data.fhir_synthea.patient` #This is a correlated cross join ,UNNEST(identifier) i ,UNNEST(i.type.coding) it WHERE # identifier.type.coding.code it.code = "MR" #uncomment to get data for one patient, this MRN exists #AND i.value = "a55c8c2f-474b-4dbd-9c84-effe5c0aed5b" ), condition AS ( SELECT abatement.dateTime as abatement_dateTime, assertedDate, category, clinicalStatus, code, onset.dateTime as onset_dateTime, subject.patientid FROM `bigquery-public-data.fhir_synthea.condition` ,UNNEST(code.coding) as code WHERE code.system = 'http://snomed.info/sct' #snomed code for Hypertension AND code.code = '38341003' ) SELECT patient.patientid, patient.MRN, patient.birthDate as birthDate_string, #current patient age. now - birthdate CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH)/12 AS INT) as patient_current_age_years, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),MONTH) AS INT) as patient_current_age_months, CAST(DATE_DIFF(CURRENT_DATE(),CAST(patient.birthDate AS DATE),DAY) AS INT) as patient_current_age_days, #age at onset. onset date - birthdate DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset, condition.onset_dateTime, condition.code.code, condition.code.display, condition.code.system FROM patient JOIN condition ON patient.patientid = condition.patientid
Die Ausgabe sieht in etwa so aus:
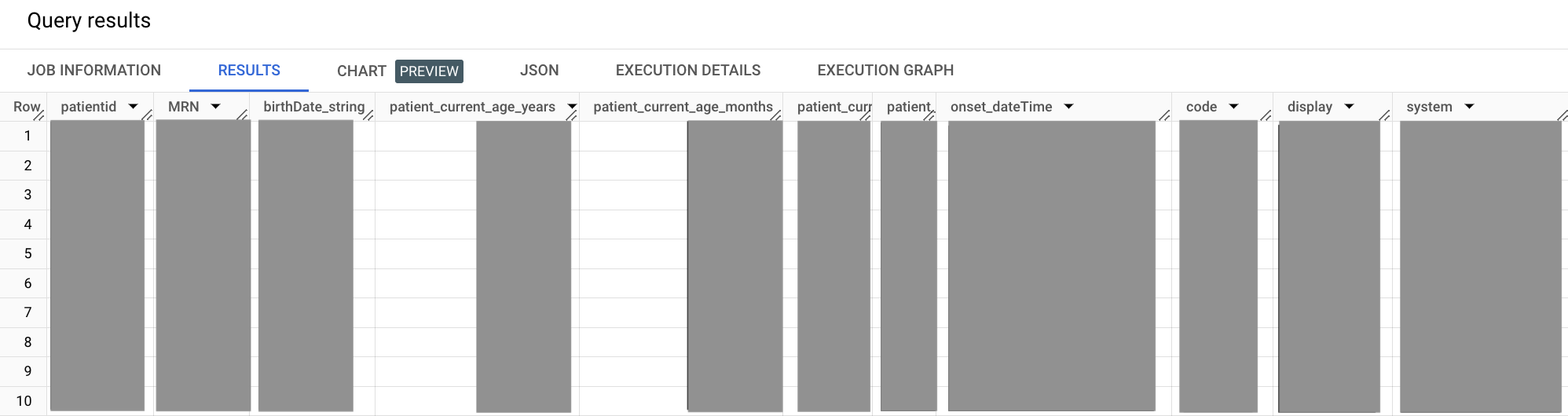
In der vorherigen Beispielabfrage können Sie mit der WITH-Klausel Unterabfragen in ihre jeweiligen definierten Segmente isolieren. Dieser Ansatz kann die Lesbarkeit verbessern, die mit größer werdender Abfrage wichtiger wird. In dieser Abfrage isolieren Sie die Unterabfrage für Patienten und Zustände in ihre eigenen WITH-Segmente und führen sie dann mit dem SELECT-Hauptsegment zusammen.
Sie können auch Berechnungen auf Rohdaten anwenden. Der folgende Beispielcode, eine SELECT-Anweisung, zeigt, wie das Alter des Patienten zu Beginn der Krankheit berechnet wird.
DATE_DIFF(CAST(SUBSTR(condition.onset_dateTime,1,10) AS DATE),CAST(patient.birthDate AS DATE),YEAR)as patient_age_at_onset
Wie im vorherigen Codebeispiel angegeben, können Sie eine Reihe von Vorgängen für den bereitgestellten dateTime-String condition.onset_dateTime ausführen. Wählen Sie zuerst die Datumskomponente des Strings mit dem Wert SUBSTR aus. Anschließend konvertieren Sie den String mithilfe der CAST-Syntax in den Datentyp DATE. Außerdem konvertieren Sie das Feld patient.birthDate in das Feld DATE.
Schließlich berechnen Sie die Differenz zwischen den beiden Daten mithilfe der Funktion DATE_DIFF.
Nächste Schritte
- Mit BigQuery und AI Platform Notebooks klinische Daten analysieren.
- BigQuery-Daten in einem Jupyter-Notebook visualisieren
- Cloud Healthcare API-Sicherheit
- BigQuery-Zugriffssteuerung
- Lösungen für Gesundheit und Biowissenschaften im Google Cloud Marketplace
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center