このドキュメントでは、スケーラブルな TensorFlow 推論システムをデプロイするで作成した TensorFlow 推論システムのパフォーマンスを測定する方法について説明します。また、パラメータ チューニングを適用してシステムのスループットを向上させる方法についても説明します。
このデプロイは、スケーラブルな TensorFlow 推論システムで説明されているリファレンス アーキテクチャに基づいています。
このシリーズは、Google Kubernetes Engine と、TensorFlow、TensorRT などの機械学習(ML)フレームワークに精通しているデベロッパーを対象としています。
このドキュメントは、特定のシステムのパフォーマンス データの提供を目的としていません。パフォーマンス測定プロセスに関する一般的なガイダンスについて説明します。1 秒あたりの合計リクエスト数(RPS)やレスポンス時間(ミリ秒)など、表示されるパフォーマンス指標は、トレーニング済みモデルやソフトウェア、使用するハードウェア構成によって異なります。
アーキテクチャ
TensorFlow 推論システムのアーキテクチャの概要については、スケーラブルな TensorFlow 推論システムをご覧ください。
目標
- パフォーマンス目標と指標を定義する
- ベースライン パフォーマンスを測定する
- グラフを最適化する
- FP16 の変換を測定する
- INT8 の量子化を測定する
- インスタンスの数を調整する
費用
デプロイに関連する費用の詳細については、費用をご覧ください。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
スケーラブルな TensorFlow 推論システムをデプロイするの手順が完了していることを確認します。
このドキュメントでは、次のツールを使用します。
- 作業環境を作成するで準備した作業インスタンスの SSH ターミナル。
- Prometheus と Grafana を使用したモニタリング サーバーをデプロイするで準備した Grafana ダッシュボード。
- 負荷テストツールをデプロイするで準備した Locust コンソール。
ディレクトリを設定する
Google Cloud コンソールで、[Compute Engine] > [VM インスタンス] に移動します。
作成した
working-vmインスタンスが表示されます。インスタンスのターミナル コンソールを開くには、[SSH] をクリックします。
SSH ターミナルで、カレント ディレクトリを
clientサブディレクトリに設定します。cd $HOME/gke-tensorflow-inference-system-tutorial/clientこのドキュメントでは、このディレクトリからすべてのコマンドを実行します。
パフォーマンス目標を定義する
推論システムのパフォーマンスを測定する場合は、システムのユースケースに基づいて、パフォーマンス目標と適切なパフォーマンス指標を定義する必要があります。デモとして、このドキュメントでは次のパフォーマンス目標を使用しています。
- リクエストの少なくとも 95% が 100 ミリ秒以内にレスポンスを受信する。
- 1 秒あたりのリクエスト数(RPS)で表される合計スループットが前の目標を損なうことなく改善される。
この前提に基づいて、次の ResNet-50 モデルのスループットを測定し、さまざまな最適化を行って改善していきます。クライアントが推論リクエストを送信するときに、次の表のモデル名を使用してモデルを指定します。
| モデル名 | 最適化 |
|---|---|
original |
元のモデル(TF-TRT での最適化なし) |
tftrt_fp32 |
グラフの最適化 (バッチサイズ: 64、インスタンス グループ: 1) |
tftrt_fp16 |
グラフの最適化と FP16 への変換 (バッチサイズ: 64、インスタンス グループ: 1) |
tftrt_int8 |
グラフの最適化と INT8 での量子化 (バッチサイズ: 64、インスタンス グループ: 1) |
tftrt_int8_bs16_count4 |
グラフの最適化と INT8 での量子化 (バッチサイズ: 16、インスタンス グループ: 4) |
ベースライン パフォーマンスを測定する
まず、TF-TRT を、最適化されていない元のモデルのパフォーマンスを測定するためのベースラインとして使用します。パフォーマンスの改善を定量的に評価するために、他のモデルのパフォーマンスを元のモデルと比較します。Locust をデプロイしたときに、元のモデルのリクエストを送信するように構成されます。
負荷テストツールをデプロイするで準備した Locust コンソールを開きます。
クライアントの数(スレーブ)が 10 になっていることを確認します。
この数値が 10 未満の場合、クライアントはまだ起動中です。その場合は、10 になるまで数分お待ちください。
パフォーマンスを測定します。
- [Number of users to calls] フィールドに「
3000」と入力します。 - [Hatch rate] フィールドに「
5」と入力します。 - 3,000 に達するまでシミュレートの回数を 1 秒あたり 5 回増やすには、[Start swarming] をクリックします。
- [Number of users to calls] フィールドに「
[Charts] をクリックします。
グラフにパフォーマンスの結果が表示されます。[Total Requests per Second] の値が直線的に増加し、それに応じて [Response Times (ms)] の値が大きくなることを確認します。
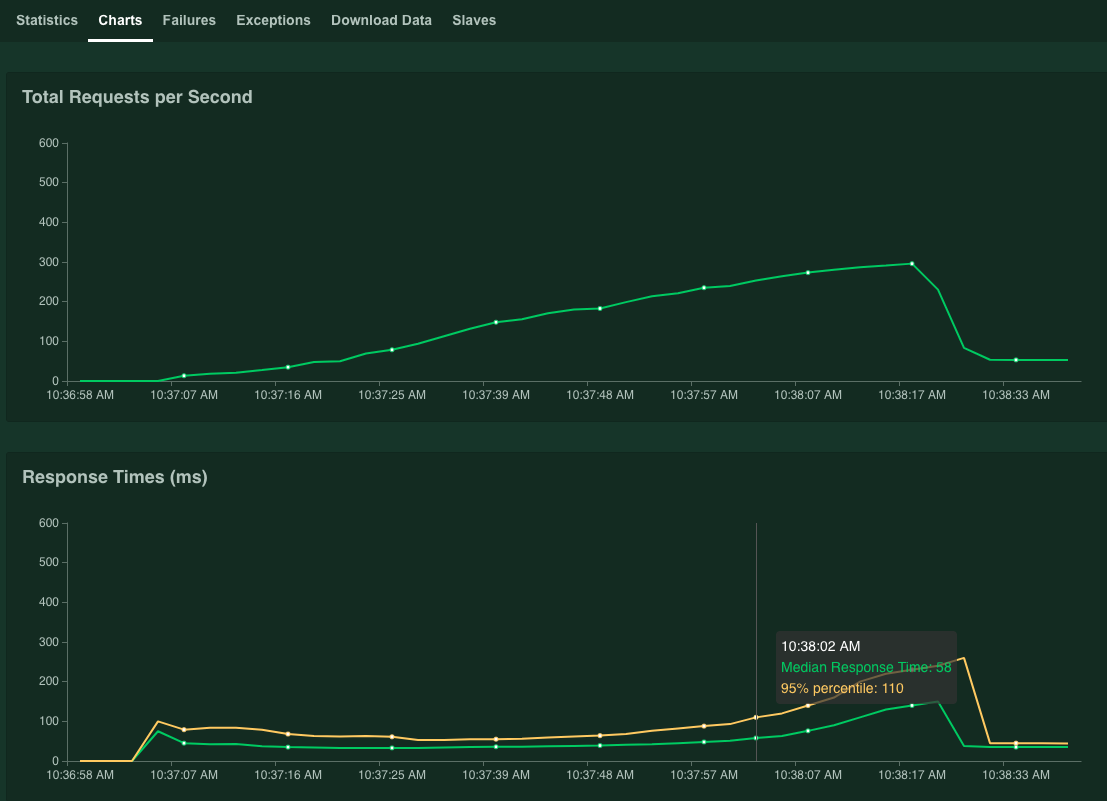
[95% percentile of Response Times] 値が 100 ミリ秒を上回ったら、[Stop] をクリックしてシミュレーションを停止します。
ポインタをグラフの上に置くと、[95% percentile of Response Times] の値が 100 ミリ秒を超えた時点に対応する 1 秒あたりのリクエスト数を確認できます。
たとえば、次のスクリーンショットでは、1 秒あたりのリクエスト数は 253.1 です。
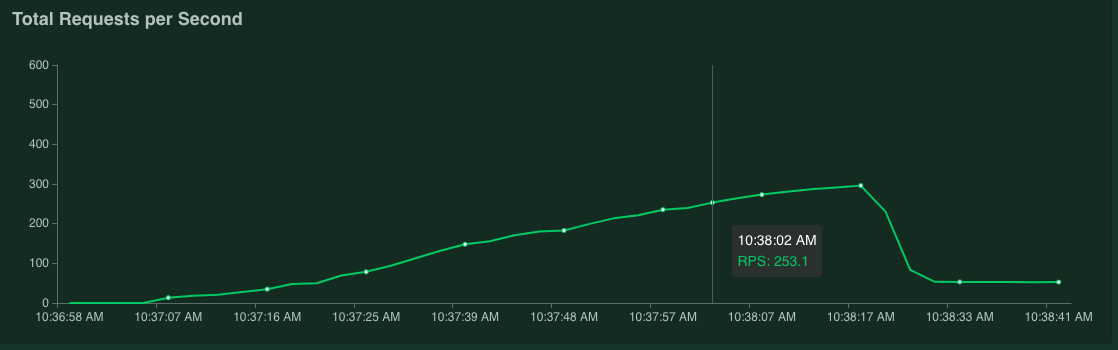
この測定を数回繰り返して、変動を考慮した平均値を取ることをおすすめします。
SSH ターミナルで Locust を再起動します。
kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust測定を繰り返すには、上記の手順を繰り返します。
グラフを最適化する
このセクションでは、グラフの最適化のために TF-TRT で最適化したモデル tftrt_fp32 のパフォーマンスを測定します。これは、ほとんどの NVIDIA GPU カードと互換性のある一般的な最適化です。
SSH ターミナルで、負荷テストツールを再起動します。
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp32 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustconfigmapリソースで、モデルをtftrt_fp32として指定します。Triton サーバーを再起動します。
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1サーバー プロセスの準備が整うまで数分かかります。
サーバーのステータスを確認します。
kubectl get pods出力は次のようになります。
READY列にサーバーのステータスが表示されます。NAME READY STATUS RESTARTS AGE inference-server-74b85c8c84-r5xhm 1/1 Running 0 46sREADY列の値が1/1であれば、サーバーの準備が完了しています。パフォーマンスを測定します。
- [Number of users to calls] フィールドに「
3000」と入力します。 - [Hatch rate] フィールドに「
5」と入力します。 - 3,000 に達するまでシミュレートの回数を 1 秒あたり 5 回増やすには、[Start swarming] をクリックします。
これらのグラフは、TF-TRT グラフの最適化でパフォーマンスが向上したことが示されます。
たとえば、1 秒あたりのリクエスト数が 381、レスポンス時間の中央値が 59 ミリ秒になっています。
- [Number of users to calls] フィールドに「
FP16 に変換する
このセクションでは、グラフの最適化と FP16 変換のために TF-TRT で最適化されたモデル tftrt_fp16 のパフォーマンスを測定します。これは、NVIDIA T4 で利用できる最適化です。
SSH ターミナルで、負荷テストツールを再起動します。
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_fp16 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustTriton サーバーを再起動します。
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1サーバー プロセスの準備が整うまで数分かかります。
パフォーマンスを測定します。
- [Number of users to calls] フィールドに「
3000」と入力します。 - [Hatch rate] フィールドに「
5」と入力します。 - 3,000 に達するまでシミュレートの回数を 1 秒あたり 5 回増やすには、[Start swarming] をクリックします。
これらのグラフは、TF-TRT グラフの最適化に加えて、FP16 変換のパフォーマンスが向上したことを示しています。
たとえば、1 秒あたりのリクエスト数が 1,072.5、レスポンス時間の中央値が 63 ミリ秒になっています。
- [Number of users to calls] フィールドに「
INT8 で量子化する
このセクションでは、グラフ最適化と INT8 量子化のために TF-TRT を使用して最適化されたモデル tftrt_int8 のパフォーマンスを測定します。これは、NVIDIA T4 で利用できる最適化です。
SSH ターミナルで負荷テストツールを再起動します。
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locustTriton サーバーを再起動します。
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1サーバー プロセスの準備が整うまで数分かかります。
パフォーマンスを測定します。
- [Number of users to calls] フィールドに「
3000」と入力します。 - [Hatch rate] フィールドに「
5」と入力します。 - 3,000 に達するまでシミュレートの回数を 1 秒あたり 5 回増やすには、[Start swarming] をクリックします。
グラフにパフォーマンスの結果が表示されます。
たとえば、1 秒あたりのリクエスト数が 1,085.4、レスポンス時間の中央値が 32 ミリ秒になっています。
この例では、FP16 変換と比較して、パフォーマンスが大幅に向上することはありません。理論的には、NVIDIA T4 GPU は、FP16 変換モデルよりも INT8 量子化モデルをすばやく処理できます。この場合、GPU パフォーマンス以外のボトルネックが発生する可能性があります。これは、Grafana ダッシュボードの GPU 使用率データから確認できます。たとえば、使用率が 40% 未満の場合、モデルは GPU のパフォーマンスを十分に活用できていません。
次のセクションで説明するように、インスタンス グループの数を増やすことで、このボトルネックを解消できる場合があります。たとえば、インスタンス グループの数を 1 から 4 に増やし、バッチサイズを 64 から 16 に減らします。このアプローチで、1 つの GPU で処理されるリクエストの合計数が 64 に維持されます。
- [Number of users to calls] フィールドに「
インスタンスの数を調整する
このセクションでは、モデル tftrt_int8_bs16_count4 のパフォーマンスを測定します。このモデルの構造は tftrt_int8 と同じですが、INT8 で量子化するの説明に従ってバッチサイズとインスタンス グループの数を変更します。
SSH ターミナルで Locust を再起動します。
kubectl delete configmap locust-config -n locust kubectl create configmap locust-config \ --from-literal model=tftrt_int8_bs16_count4 \ --from-literal saddr=${TRITON_IP} \ --from-literal rps=10 -n locust kubectl delete -f deployment_master.yaml -n locust kubectl delete -f deployment_slave.yaml -n locust kubectl apply -f deployment_master.yaml -n locust kubectl apply -f deployment_slave.yaml -n locust kubectl scale deployment/locust-slave --replicas=20 -n locustこのコマンドでは、
configmapリソースを使用してモデルをtftrt_int8_bs16_count4として指定します。また、Locust クライアント Pod の数を増やして、モデルのパフォーマンス制限を測定するために十分なワークロードを生成します。Triton サーバーを再起動します。
kubectl scale deployment/inference-server --replicas=0 kubectl scale deployment/inference-server --replicas=1サーバー プロセスの準備が整うまで数分かかります。
パフォーマンスを測定します。
- [Number of users to calls] フィールドに「
3000」と入力します。 - [Hatch rate] フィールドに「
15」と入力します。 このモデルでは、[Hatch rate] が5に設定されている場合、パフォーマンスの上限に達するまでに時間がかかることがあります。 - 3,000 に達するまでシミュレートの回数を 1 秒あたり 5 回増やすには、[Start swarming] をクリックします。
グラフにパフォーマンスの結果が表示されます。
たとえば、1 秒あたりのリクエスト数が 2,236.6、レスポンス時間の中央値が 38 ミリ秒になっています。
インスタンスの数を調整することで、1 秒あたりのリクエスト数をほぼ倍増できます。Grafana ダッシュボードで GPU 使用率が増加していることに注意してください(使用率が 75% に達することもあります)。
- [Number of users to calls] フィールドに「
パフォーマンスと複数のノード
複数のノードを使用してスケーリングする場合、単一 Pod のパフォーマンスを測定します。推論プロセスは、シェアードナッシング方式で異なる Pod 上で独立して実行されるため、合計スループットは Pod の数に比例してスケーリングされるとみなせます。この前提は、クライアントと推論サーバー間のネットワーク帯域幅などのボトルネックがない限り適用されます。
ただし、複数の推論サーバー間で推論リクエストのバランスがどのようにとれているかを理解することが重要です。Triton は gRPC プロトコルを使用して、クライアントとサーバー間の TCP 接続を確立します。Triton は確立された接続を再利用して複数の推論リクエストを送信するため、単一のクライアントからのリクエストは常に同じサーバーに送信されます。リクエストを複数のサーバーで分散するには、複数のクライアントを使用する必要があります。
クリーンアップ
このシリーズで使用したリソースに対する Google Cloud アカウントへの課金を回避するには、プロジェクトを削除します。
プロジェクトを削除する
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- 予測用のコンピューティング リソースの構成について確認する。
- Google Kubernetes Engine(GKE)の詳細を確認する。
- Cloud Load Balancing の詳細を確認する。
- Cloud Architecture Center で、リファレンス アーキテクチャ、図、ベスト プラクティスを確認する。