In questo tutorial utilizzerai Striim per eseguire la migrazione di Oracle® Database Enterprise Edition 18c o versioni successive da un ambiente on-premise o cloud a un'istanza Cloud SQL per PostgreSQL su Google Cloud. Il tutorial utilizza le tabelle nello schema di esempio HR Oracle.
Questo tutorial è rivolto ad architetti di database aziendali, database engineer e proprietari di dati che intendono utilizzare Striim per eseguire la migrazione o replicare i database Oracle in Cloud SQL per PostgreSQL. Avere conoscenze di base su come usare Striim per creare pipeline. Dovresti anche conoscere l'interfaccia utente web di Striim, i concetti chiave di Striim e come creare un'applicazione utilizzando Flow Designer di Sttriim.
Striim è un partner tecnologico per la migrazione dei database Google Cloud. Striim semplifica le migrazioni online utilizzando un'interfaccia a trascinamento per impostare uno spostamento continuo dei dati tra i database. Per le migrazioni a Google Cloud, Striim offre una piattaforma di flussi di dati non invasivi per l'estrazione, la trasformazione e il caricamento (ETL) efficiente di deployment e semplice da iterare. Per creare la pipeline di migrazione, usa Flow Designer di Striim in questo tutorial.
Se non conosci bene la migrazione dei database, vedi questo discorso tecnico di Cloud Next '19.
Architettura
La migrazione del database mediante Striim prevede due fasi dello spostamento sequenziale dei dati:
- Fase 1: una replica iniziale una tantum del database Oracle.
- Fase 2: la replica continua di ogni modifica apportata al sistema di database di origine successivamente utilizzando la tecnologia Change Data Capture (CDC).
Il seguente diagramma illustra un'architettura di deployment di base:

Questa architettura prevede l'esecuzione dell'applicazione Striim su un'istanza di Compute Engine. Si connette a un database Oracle ospitato on-premise o nel cloud e scrive i dati in un'istanza Cloud SQL per PostgreSQL su Google Cloud.
Per evitare problemi di rete o di connettività tra le istanze Striim e Cloud SQL, utilizza la stessa rete per entrambe le istanze. Puoi eseguire il deployment di Striim da Google Cloud Marketplace su un'istanza Compute Engine oppure, se hai bisogno di elevata disponibilità, puoi eseguire il deployment di Striim come cluster.
Per questo tutorial, esegui il deployment da Cloud Marketplace.
Il vantaggio del deployment di Striim da Cloud Marketplace è che consente di connettersi a vari database e origini dati utilizzando gli adattatori integrati. Puoi collegare gli adattatori utilizzando Flow Designer, l'interfaccia interattiva con trascinamento di Striim, per formare un grafico aciclico. Questo grafico è anche noto come pipeline Striim o applicazione Striim.
Il caso d'uso della migrazione in questo tutorial utilizza tre adattatori Striim:
- Lettore database: legge i dati dal database di origine Oracle durante la fase di caricamento iniziale.
- Oracle Reader: Legge i dati utilizzando LogMiner dal database di origine Oracle durante la fase di replica continua dei dati.
- Writer database: scrive i dati nel database Cloud SQL per PostgreSQL durante il caricamento iniziale e durante la replica continua dei dati.
Obiettivi
Prepara il database Oracle come database di origine per la migrazione o la replica.
Prepara un database Cloud SQL per PostgreSQL come database di destinazione per la migrazione o la replica.
Soddisfa i prerequisiti per l'installazione e l'esecuzione di Striim.
Converti lo schema del database Oracle nello schema corrispondente in PostgreSQL.
Esegui il caricamento iniziale dal database Oracle a Cloud SQL per PostgreSQL.
Configura la replica continua dal tuo database Oracle a Cloud SQL per PostgreSQL.
Costi
In questo documento, utilizzi i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto, utilizza il Calcolatore prezzi.
La soluzione Striim in Cloud Marketplace offre una licenza di prova gratuita a tempo limitato. Alla scadenza della prova, i costi per l'utilizzo vengono fatturati al tuo account Google Cloud. Puoi anche ottenere le licenze Striim direttamente da Striim per il deployment on-premise e in una macchina virtuale (VM) Compute Engine. Inoltre, potrebbero esserti addebitati costi associati all'esecuzione di un database Oracle all'esterno di Google Cloud.
Prima di iniziare
- Accedi al tuo account Google Cloud. Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti gratuiti per l'esecuzione, il test e il deployment dei carichi di lavoro.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
Questo tutorial presuppone che tu abbia già quanto segue:
- Un Oracle Database Enterprise Edition 18c o versioni successive per Linux x86-64 di cui vuoi eseguire la migrazione.
- Un Compute Engine su cui è installato CentOS in cui è installato Striim. Puoi eseguire il deployment di Striim tramite la soluzione Google Cloud Marketplace.
Preparazione del database Oracle
Le sezioni seguenti descrivono le modifiche alla configurazione che potrebbero essere necessarie per connetterti al tuo database Oracle ed eseguirne la migrazione con Striim. Per i dettagli sulla configurazione, vedi Attività di configurazione Oracle di base.
Scegli l'origine per Oracle CDC
Anche se esistono diverse origini Oracle CDC, questo tutorial utilizza LogMiner. Per informazioni sulle opzioni alternative, consulta Origini Oracle CDC alternative.
prepara Oracle Database Enterprise Edition 18c (o versioni successive)
Per preparare il database Oracle, segui le istruzioni nella pagina della documentazione di Striim per i seguenti passaggi:
- Attiva
archivelogdi Striim. - Attiva dati di log supplementari di Striim.
- Abilita il logging della chiave primaria Striim.
Crea un utente Oracle con privilegi di LogMiner per Striim.
Per eseguire questi passaggi, devi disporre della connessione al database dei container (CDB), indipendentemente dal fatto che tu stia eseguendo la migrazione di un CDB o di un database modulare (PDB). Ti consigliamo di installare e utilizzare SQL*Plus per interagire con il database Oracle.
Crea una tabella
quiescemarkerStriim.L'adattatore Oracle Reader di Striim per CDC ha bisogno di una tabella per l'archiviazione dei metadati quando arresta un'applicazione. Se utilizzi LogMiner come origine per CDC (come fa questo tutorial), è necessaria la tabella quiescemarker. Devi essere collegato alla rete CDB quando segui i passaggi per creare la tabella.
Stabilisci la connettività di rete tra il database Oracle e l'istanza di Striim.
Per impostazione predefinita, il Listener Oracle si trova sulla porta
1521. Assicurati che l'indirizzo IP per l'istanza Striim possa connettersi alla porta del listener Oracle e che nessuna regola firewall lo blocchi. La porta su cui è configurato il listener Oracle è nel file$ORACLE_HOME/network/admin/tnsnames.ora.Prendi nota del System Change Number (SCN) per il database Oracle.
L'SCN è un timestamp interno utilizzato per fare riferimento alle modifiche apportate a un database.
Nel tuo database Oracle, ottieni l'SCN meno recente:
SELECT MIN(start_scn) FROM gv$transaction;Copia questo numero. Ti servirà in un secondo momento nei passaggi della pipeline di replica continua.
Preparazione dell'istanza Striim
Per informazioni sui sistemi operativi supportati da Striim, consulta i requisiti di sistema. Per utilizzare Oracle Reader con LogMiner, inserisci il driver JDBC di Oracle nel classpath di Java nella tua istanza Striim. Svolgi i seguenti passaggi su ogni server Striim che esegue un adattatore Oracle Reader:
- Accedi al tuo account Oracle, quindi scarica il file
ojdbc8.jarsulla macchina locale.- Se non hai un account Oracle, creane uno.
Fai clic sul link Scarica relativo al file
ojdbc8.jar.- Se accetti i termini di licenza, fai clic su Ho esaminato e accetto il contratto di licenza Oracle per scaricare il file.
In Cloud Shell, crea un bucket Cloud Storage e carica al suo interno il file
.jar:gsutil mb -b on -l REGION gs://BUCKET_NAME gsutil cp PATH/ojdbc8.jar gs://BUCKET_NAMESostituisci quanto segue:
- REGION: la regione in cui vuoi creare il bucket Cloud Storage
- BUCKET_NAME: il nome del bucket Cloud Storage in cui vuoi archiviare il file
ojdbc8.jar - PATH: il percorso da cui hai scaricato il file
ojdbc8.jar
Dopo aver salvato il file sulla macchina locale, ti consigliamo di caricare il file
.jarin un bucket Cloud Storage in modo da poterlo scaricare in qualsiasi istanza.Apri una sessione SSH con la tua istanza Striim, quindi scarica il file
.jarnell'istanza Striim e posizionalo nella directory/opt/striim/lib:sudo su - striim gsutil cp gs://BUCKET_NAME/ojdbc8.jar /opt/striim/libVerifica che le autorizzazioni del file per il file
ojdbc8.jarsiano corrette:sudo ls -l /opt/striim/lib/ojdbc8.jarL'output dovrebbe essere simile al seguente:
-rwxrwx--- striim striim(Facoltativo) Se il file
.jarnon dispone delle autorizzazioni precedenti, imposta le autorizzazioni corrette:sudo chmod 770 /opt/striim/lib/ojdbc8.jar sudo chown striim /opt/striim/lib/ojdbc8.jar sudo chgrp striim /opt/striim/lib/ojdbc8.jarInterrompi e riavvia Striim.
Dopo aver apportato modifiche alla configurazione, ad esempio le precedenti modifiche alle autorizzazioni, devi riavviare Striim.
Se utilizzi la distribuzione Linux di CentOS 7, interrompi Striim:
sudo systemctl stop striim-node sudo systemctl stop striim-dbmsSe utilizzi la distribuzione Linux di CentOS 7, avvia Striim:
sudo systemctl start striim-dbms sudo systemctl start striim-node
Per ulteriori informazioni su come arrestare e riavviare Striim per un altro sistema operativo, consulta Avviare e arrestare Striim
Installa il client psql sull'istanza Striim.
Userai questo client per connetterti all'istanza Cloud SQL e creare schemi più avanti in questo tutorial.
Preparazione dello schema di Cloud SQL per PostgreSQL
Quando copi o replichi continuamente i dati tabulari da un database all'altro, Striim richiede in genere che il database di destinazione contenga tabelle corrispondenti con lo schema corretto. Google Cloud non ha un'utilità per preparare lo schema, ma puoi utilizzare l'utilità di conversione dello schema di Striim o un'utilità open source come ora2pg.
Mantieni le chiavi esterne durante il caricamento iniziale
Durante la fase di caricamento iniziale, presta attenzione al trattamento delle chiavi esterne. Le chiavi esterne stabiliscono la relazione tra le tabelle in un database relazionale. La creazione o l'inserimento fuori ordine di una chiave esterna nel database di destinazione potrebbe eliminare la relazione tra le due tabelle. Se l'integrità tra i due database viene compromessa, potrebbero verificarsi errori. Di conseguenza, durante l'esportazione dello schema più avanti in questa sezione è importante generare tutte le dichiarazioni della chiave esterna in un file separato.
Durante la replica continua nelle pipeline CDC, gli eventi del database di origine vengono propagati al database di destinazione nell'ordine in cui si verificano. Se gestisci correttamente le chiavi esterne nell'origine, le operazioni con chiave esterna vengono replicate dall'origine al database di destinazione nello stesso ordine.
Al contrario, la pipeline di caricamento iniziale carica per impostazione predefinita le tabelle in ordine alfabetico. Se non disabiliti le chiavi esterne prima del caricamento iniziale, si verificano errori di violazione delle chiave esterna. Per replicare i dati durante il caricamento iniziale dalle tabelle del database di origine alle tabelle di destinazione su Cloud SQL per PostgreSQL, devi disabilitare i vincoli della chiave esterna nelle tabelle. In caso contrario, i vincoli potrebbero essere violati durante il processo di replica.
A partire da giugno 2021, Cloud SQL per PostgreSQL non supporta le opzioni di configurazione per disabilitare i vincoli di chiave esterna.
Per gestire i vincoli di chiave esterna:
- Restituisci come output tutte le dichiarazioni di chiave esterna in un file separato durante l'esportazione dello schema.
- Creare schemi di tabella nel database Cloud SQL per PostgreSQL senza i vincoli di chiave esterna.
- Completa la replica iniziale dei dati.
- Applica i vincoli di chiave esterna alle tabelle.
- Creare la pipeline di replica continua.
Questo tutorial offre due opzioni per la conversione dello schema, spiegate nelle sezioni seguenti:
- L'utilità di conversione dello schema Striim (consigliata)
- Il convertitore di schema dei database Oracle a PostgreSQL (Ora2Pg)
Converti lo schema utilizzando l'utilità di conversione dello schema di Striim
Utilizza l'utilità di conversione dello schema di Striim per preparare Cloud SQL per PostgreSQL in modo da integrare i dati con lo schema di destinazione e creare tabelle che riflettono il database Oracle di origine.
Lo strumento di conversione dello schema Striim converte i seguenti oggetti di origine in oggetti di destinazione equivalenti:
- Tabelle
- Chiavi primarie
- Tipi di dati
- Vincoli unici
NOT NULLvincoli- Chiavi esterne
Con l'utilità di conversione dello schema di Striim, puoi analizzare il database di origine e generare script DDL per creare schemi equivalenti nel database di destinazione.
Ti consigliamo di creare manualmente lo schema nel database di destinazione utilizzando gli script DDL generati. È più facile selezionare un sottoinsieme delle tabelle, esportare lo schema e quindi importare lo schema nel database Cloud SQL per PostgreSQL di destinazione.
L'esempio seguente mostra come preparare il database Cloud SQL per PostgreSQL di destinazione per il caricamento iniziale importando lo schema con l'utilità di conversione dello schema di Striim:
Apri una connessione SSH alla tua istanza Striim.
Vai alla directory
/opt/striim:cd /opt/striimElenca tutti gli argomenti:
bin/schemaConversionUtility.sh --helpEsegui l'utilità di conversione dello schema e includi i flag appropriati per il tuo caso d'uso:
bin/schemaConversionUtility.sh \ -s=oracle \ -d=SOURCE_DATABASE_CONNECTION_URL \ -u=SOURCE_DATABASE_USERNAME \ -p=SOURCE_DATABASE_PASSWORD \ -b=SOURCE_TABLES_TO_CONVERT \ -t=postgres \ -f=falseSostituisci quanto segue:
- SOURCE_DATABASE_CONNECTION_URL: URL di connessione per il database Oracle, ad esempio
"jdbc:oracle:thin:@12.123.123.12:1521/APPSPDB.WORLD"o"jdbc:oracle:thin:@12.123.123.12:1521:XE" - SOURCE_DATABASE_USERNAME: il nome utente Oracle da utilizzare per la connessione al database Oracle
- SOURCE_DATABASE_PASSWORD: password Oracle da utilizzare per la connessione al database Oracle
- SOURCE_TABLES_TO_CONVERT: nomi delle tabelle del database di origine utilizzati per convertire gli schemi
Assicurati di utilizzare l'argomento
-f=false. Questo argomento esporta le dichiarazioni di chiave esterna in un file separato.La cartella di output potrebbe contenere alcuni o tutti i seguenti file. Per maggiori dettagli su questi file, consulta la documentazione sull'utilità di conversione schema di Sttriim.
Nome file di output Descrizione converted_tables.sqlContiene tutte le tabelle convertite che non richiedono alcuna coercizione. converted_tables_with_striim_intelligence.sqlContiene tutte le tabelle convertite che sono state convertite con una certa coercizione. conversion_failed_tables.sqlContiene le tabelle in cui è stata tentata la conversione, ma non è stata ottenuta una mappatura converted_foreignkey.sqlContiene tutte le dichiarazioni dei vincoli di chiave esterna conversion_failed_foreignkey.sqlContiene tutte le conversioni di chiave esterna non riuscite conversion_report.txtContiene un report dettagliato della conversione dello schema In questo tutorial utilizzerai il file
converted_tables.sqlper creare tabelle equivalenti nel database Cloud SQL per PostgreSQL senza vincoli di chiave esterna. Dopo la replica iniziale, utilizzerai il fileconverted_foreignkey.sqlper applicare i vincoli della chiave esterna.- SOURCE_DATABASE_CONNECTION_URL: URL di connessione per il database Oracle, ad esempio
Converti lo schema utilizzando Ora2Pg
Un'altra opzione per convertire gli schemi delle tabelle Oracle in schemi PostgreSQL equivalenti è l'utilità Ora2Pg. Puoi installare l'utilità su una VM Google Cloud separata.
L'utilità Ora2Pg converte lo schema Oracle ed esporta le istruzioni DDL necessarie per creare tabelle equivalenti nel database PostgreSQL. Queste istruzioni DDL vengono esportate in un file di output denominato output.sql.
Per impostazione predefinita, l'utilità Ora2Pg esporta le tabelle Oracle con l'attributo NOLOGGING impostato su UNLOGGED. Per evitare di perdere dati da tabelle non registrate in caso di arresto anomalo del database, ti consigliamo di disattivare questa funzionalità.
Se hai scelto di utilizzare questa funzionalità, per esportare tutte le tabelle come tabelle NORMAL, imposta il valore per questo attributo su 1.
Durante l'esportazione dello schema, esporti e salvi tutte le dichiarazioni di chiave esterna in un file separato utilizzando il seguente flag nel file di configurazione Ora2Pg:
FILE_PER_FKEYS 1
Per impostazione predefinita, le chiavi esterne vengono esportate nel file di output principale (output.sql).
Quando attivi il flag FILE_PER_FKEYS (1), le chiavi esterne vengono esportate in
un file separato denominato FKEYS_output.sql.
In questo tutorial utilizzerai il file output.sql per creare tabelle equivalenti nel database Cloud SQL per PostgreSQL senza vincoli di chiave esterna.
Dopo la replica iniziale, utilizzerai il file FKEY_output.sql per applicare i vincoli della chiave esterna.
Preparazione dell'istanza Cloud SQL per PostgreSQL
Per abilitare Striim a scrivere dati in un'istanza Cloud SQL per PostgreSQL, devi creare un'istanza Cloud SQL. Devi anche creare le tabelle del database e lo schema in cui scrive Striim:
In Cloud Shell, crea un'istanza Cloud SQL per PostgreSQL. Ti consigliamo di configurare Cloud SQL in modo che utilizzi un indirizzo IP privato. Utilizza il parametro
--networkper configurare questo indirizzo:$INSTANCE_NAME=INSTANCE_NAME gcloud beta sql instances create INSTANCE_NAME \ --database-version=POSTGRES_12 \ --network=NETWORK \ --cpu=NUMBER_CPUS \ --memory=MEMORY_SIZE \ --region=REGIONSostituisci quanto segue:
- INSTANCE_NAME: il nome dell'istanza
- NETWORK: il nome della rete VPC che utilizzi per questa istanza
- NUMBER_CPUS: numero di vCPU nell'istanza
- MEMORY_SIZE: quantità di memoria per l'istanza. ad esempio 3072 MiB o 9GiB. Se non specifichi l'unità, si presume il valore GiB.
- REGION: la regione in cui hai creato il bucket Cloud Storage
Crea un nome utente e una password per l'istanza Cloud SQL:
CLOUD_SQL_USERNAME=CLOUD_SQL_USERNAME gcloud sql users create $CLOUD_SQL_USERNAME \ --instance=$INSTANCE_NAME \ --password=CLOUD_SQL_PASSWORDSostituisci quanto segue:
- CLOUD_SQL_USERNAME: un nome utente per l'istanza Cloud SQL
- CLOUD_SQL_PASSWORD: la password per il nome utente Cloud SQL
A questo utente è concessa la proprietà delle tabelle PostgreSQL. Striim utilizza le credenziali dell'utente anche per connettersi al database Cloud SQL per PostgreSQL.
I file di schema esportati durante il passaggio di conversione dello schema potrebbero avere un'istruzione DDL che concede la proprietà a un utente, come nell'esempio seguente:
CREATE SCHEMA <SCHEMA_NAME>; ALTER SCHEMA <SCHEMA_NAME> OWNER TO <USER>;
Potresti dover sostituire
SCHEMA_NAMEconCLOUD_SQL_SCHEMAeUSERcon ilCLOUD_SQL_USERNAMEcreato in precedenza.crea un database PostgreSQL
CLOUD_SQL_DATABASE_NAME=CLOUD_SQL_DATABASE_NAME gcloud sql databases create $CLOUD_SQL_DATABASE_NAME \ --instance=$INSTANCE_NAMESostituisci quanto segue:
- CLOUD_SQL_DATABASE_NAME: nome del database PostgreSQL
Configurare il database Cloud SQL per PostgreSQL per consentire l'accesso dall'istanza Striim. Le opzioni di connettività dipendono dal fatto che l'istanza Cloud SQL sia configurata in modo da utilizzare un indirizzo IP pubblico o privato.
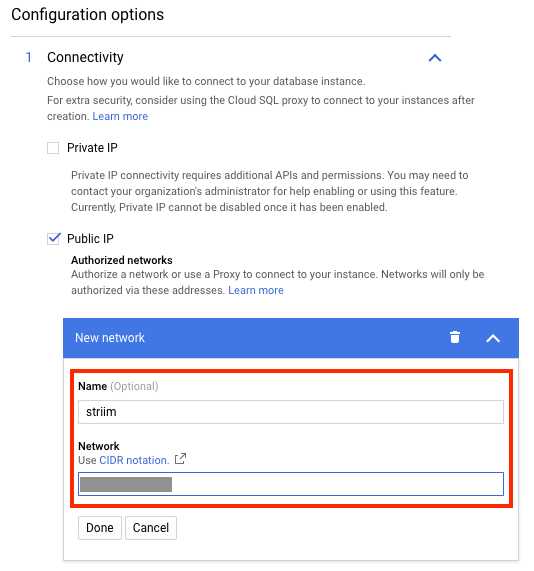
Se hai configurato un indirizzo IP pubblico, aggiungi l'indirizzo IP dell'istanza di Striim come indirizzo autorizzato sull'istanza Cloud SQL. Il seguente screenshot mostra come eseguire questa operazione dalla console Google Cloud:
Se hai configurato un indirizzo IP privato, le opzioni di connettività disponibili dipendono dal fatto che l'istanza Cloud SQL e l'istanza Striim si trovino o meno sulla stessa rete VPC.
Se l'istanza Striim si trova nella stessa rete VPC dell'istanza Cloud SQL, può stabilire la connessione con l'istanza Cloud SQL.
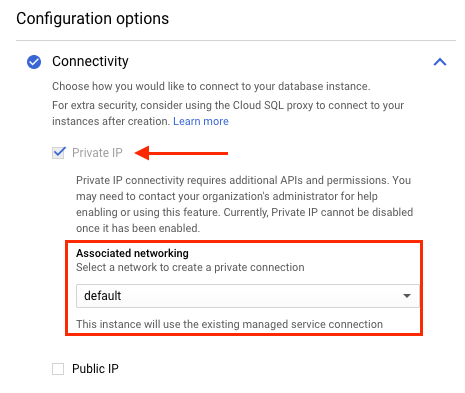
Il seguente screenshot mostra che l'istanza Cloud SQL è associata alla rete VPC predefinita. Se l'istanza Striim è stata creata anche sulla rete VPC predefinita, può connettersi privatamente all'istanza Cloud SQL.
Se l'istanza Striim si trova su una rete VPC diversa da quella dell'istanza Cloud SQL, configura l'accesso privato ai servizi sulla rete VPC dell'istanza Striim.
Creare schemi di tabella senza vincoli di chiave esterna nel database Cloud SQL per PostgreSQL.
Per esportare
output.sqldurante il passaggio di conversione dello schema, utilizza il fileoutput.sqlper creare gli schemi.Per esportare
converted_tables.sqldurante il passaggio di conversione dello schema, utilizza il fileconverted_tables.sqlper creare gli schemi.Puoi eseguire entrambi gli script utilizzando qualsiasi client PostgreSQL con connettività all'istanza Cloud SQL per PostgreSQL. Tuttavia, ti consigliamo di utilizzare il client PostgreSQL che hai installato in precedenza sull'istanza di Striim.
Crea gli schemi:
psql -h HOSTNAME -p CLOUD_SQL_PORT -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -f PATH_TO_MAIN_SQL_FILESostituisci quanto segue:
- HOSTNAME: indirizzo IP dell'istanza Cloud SQL
- CLOUD_SQL_PORT: porta dell'istanza Cloud SQL a cui connetterti
. Per impostazione predefinita, questa porta è
5432 - PATH_TO_MAIN_SQL_FILE: percorso dello script principale nell'istanza di Striim
Ad esempio:
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
Verifica che le tabelle siano state create:
Connettiti al database Cloud SQL per PostgreSQL:
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMEElenca le tabelle presenti in questo database:
\dtL'output è un elenco delle tabelle create dallo script di conversione dello schema della tabella nel passaggio precedente.
Crea una tabella di checkpoint nel database Cloud SQL per PostgreSQL:
Connettiti al database Cloud SQL per PostgreSQL:
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMECrea la tabella:
CREATE TABLE chkpoint ( id character varying(100) primary key, sourceposition bytea, pendingddl numeric(1), ddl text);Striim ha bisogno di questa tabella per mantenere i checkpoint durante il processo di replica continuo.
Caricamento del database Oracle nel database Cloud SQL per PostgreSQL
Questa sezione descrive la replica iniziale una tantum del database Oracle nel database Cloud SQL per PostgreSQL.
Stabilire una connessione a Oracle da Striim
Segui le indicazioni in Esecuzione di Striim in Google Cloud. Per il caricamento iniziale, utilizza l'adattatore Lettore database Striim per connetterti a Oracle da Striim. Puoi anche utilizzare la procedura guidata CDC di Sttriim.
Nell'adattatore Lettore database Striim, vai a Origini, quindi cerca e seleziona Database dall'elenco.
Imposta le seguenti proprietà nella finestra Database:
- Nome: identifica questo componente della pipeline di migrazione.
- Alimentatore:
DatabaseReader URL di connessione: inserisci una stringa univoca per connetterti al database Oracle:
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT:SIDOR
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT/PDB_OR_CDB_SERVICE_NAMESostituisci quanto segue:
- ORACLE_PORT: porta del database Oracle (
1521per impostazione predefinita) - SID: SID database Oracle
- PDB_OR_CDB_SERVICE_NAME: nome del servizio Oracle PDB o CDB. Se le tabelle si trovano in un PDB, utilizza
PDB_SERVICE_NAME; se sono in un CDB, utilizzaCDB_SERVICE_NAME.
Puoi trovare la porta e il nome del servizio nel file
tnsnames.orache si trova in$ORACLE_HOME/network/admin/tnsnames.oranell'istanza Oracle.- ORACLE_PORT: porta del database Oracle (
Nome utente e password:utilizza l'utente Oracle (
c##striimutente) che hai creato nei passaggi preliminari. Striim usa questo nome utente e questa password per connettersi al tuo database Oracle e leggere le tabelle.Tables: per Oracle, il lettore di database richiede anche un elenco di nomi di tabella da replicare. Questa proprietà viene specificata nel campo Tabelle in Mostra proprietà facoltative. Il formato di questa proprietà è il seguente:
ORACLE_SCHEMA.ORACLE_TABLE_NAMESostituisci quanto segue:
- ORACLE_SCHEMA: nome dello schema Oracle
- ORACLE_TABLE_NAME: nomi delle tabelle Oracle nello schema
Puoi anche specificare più tabelle e viste materializzate come elenco separato da punti e virgola o con i seguenti caratteri jolly:
%: qualsiasi serie di caratteri_: qualsiasi carattere singoloAd esempio,
HR.%legge tutte le tabelle nello schema RU. Almeno una tabella deve corrispondere al carattere jolly. In caso contrario, il lettore di database ha esito negativo e restituisce il seguente errore:Could not find tables specified in the databaseSilenziose al completamento di IL: imposta questo campo in verde facendolo scorrere verso destra per mettere in pausa la pipeline al termine del caricamento iniziale.
Output in: assegna un nome all'output di questo adattatore. Utilizza una stringa sensibile alle maiuscole, senza caratteri speciali o spazi.
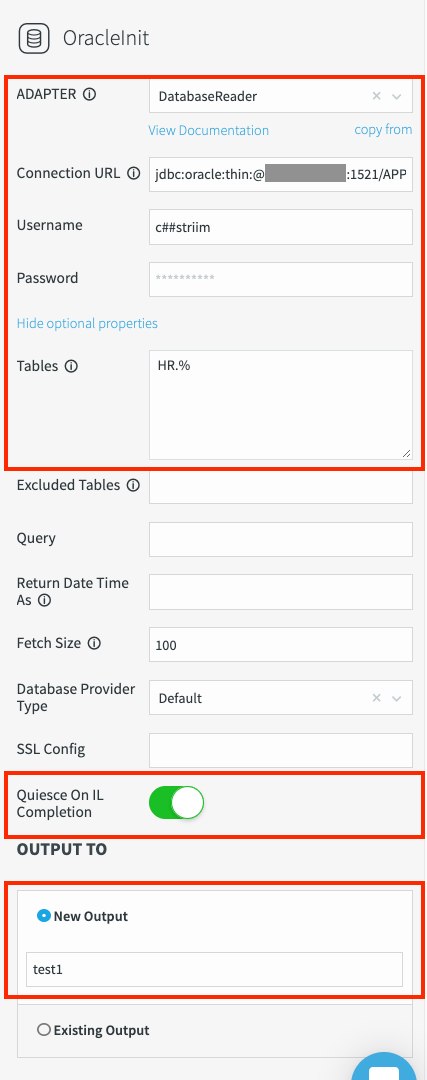
Fai clic su Salva. Vengono visualizzate le proprietà dell'adattatore:
Testa la connessione
Ora che hai effettuato la connessione a Oracle da Striim, testa la connessione.
Fai clic sull'elenco a discesa Created (Creato) per testare la connettività Striim al database Oracle.
Fai clic su Deploy App.
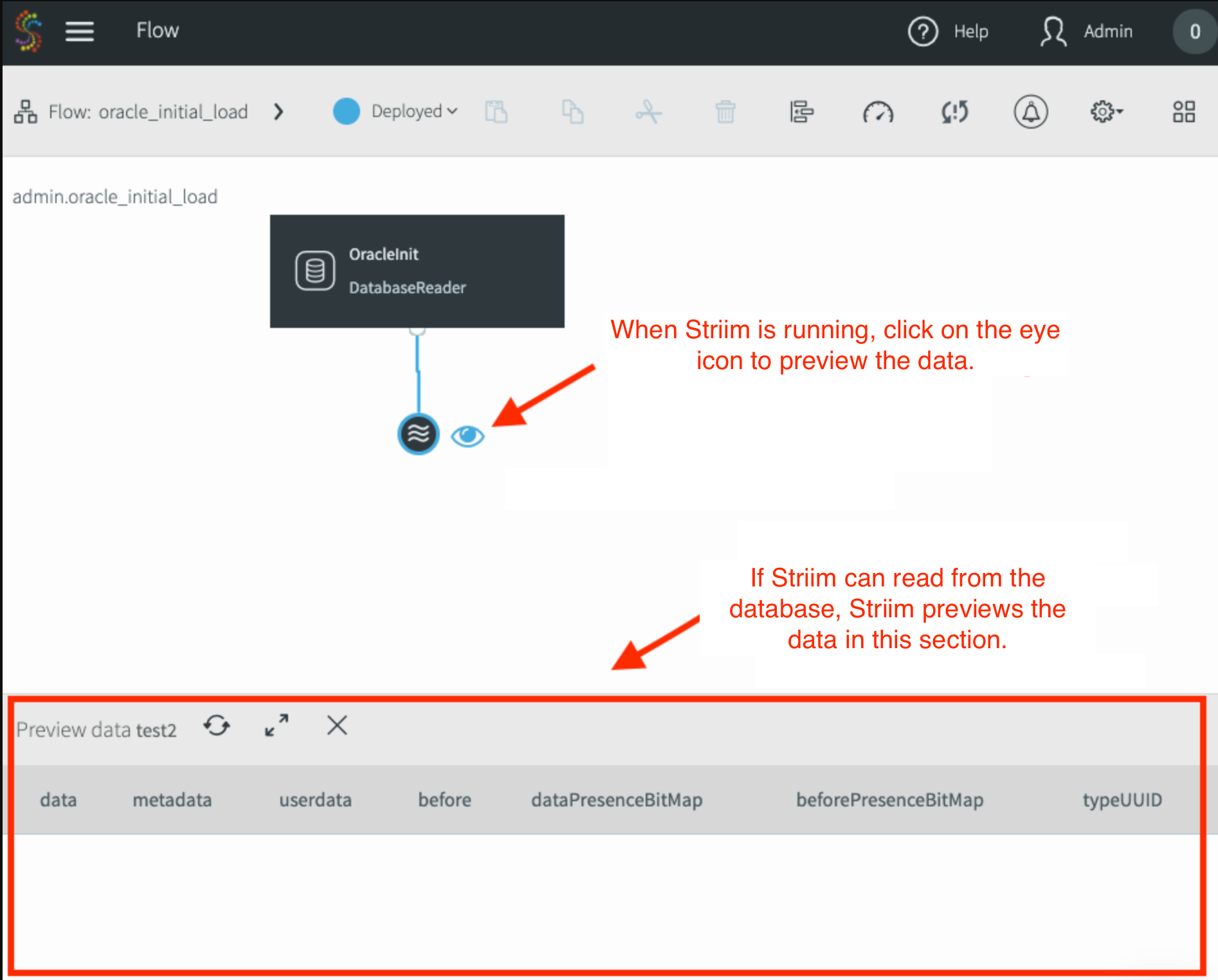
Seleziona l'output di questo adattatore e fai clic su Anteprima per visualizzare i dati in tempo reale mentre Striim li legge dall'origine.
Fai clic sull'elenco a discesa Deployment eseguito e quindi su Avvia app.
(Facoltativo) Fai clic sull'elenco a discesa Deployment eseguito e quindi su Annulla deployment app per correggere eventuali errori che si verificano.
(Facoltativo) Fai clic su Riprendi app dopo aver corretto tutti gli errori per riavviare l'app.
Fai clic sul gruppo di deployment predefinito.
Verifica che l'opzione Convalida mappature delle tabelle sia attivata, quindi fai clic su Esegui il deployment.
Il riquadro dei dati di anteprima e lo stato della pipeline cambiano in Quiesced.
A questo punto del tutorial hai verificato che Striim è in grado di stabilire una connessione al tuo database Oracle e di leggere i dati al suo interno.
Aggiungi un database Cloud SQL per PostgreSQL come destinazione
Per questa migrazione, scriverai dati nell'istanza Cloud SQL per PostgreSQL. Striim fornisce un adattatore per scrittore di database generico, chiamato Writer database, che puoi utilizzare per la migrazione.
- In Striim Flow Designer, vai a Destinazioni. Cerca e seleziona Cloud SQL Postgres dall'elenco.
- Trascina Writer database sulla pipeline.
Imposta le seguenti proprietà:
Alimentatore:
DatabaseWriterURL di connessione: inserisci una stringa univoca per stabilire una connessione all'istanza Cloud SQL:
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecifiedSostituisci quanto segue:
- CLOUD_SQL_IP_ADDRESS: indirizzo IP dell'istanza Cloud SQL
Ad esempio:
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedNome utente e password: inserisci il nome utente e la password di Cloud SQL che hai creato in precedenza.
Tabelle: crea un mapping dai nomi delle tabelle del database Oracle ai nomi delle tabelle Cloud SQL. Specifica la tabella di database Oracle in quale tabella Cloud SQL è scritta. Questa mappatura utilizza il formato seguente:
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAMESostituisci quanto segue:
- CLOUD_SQL_SCHEMA: nome dello schema PostgreSQL
- CLOUD_SQL_TABLE_NAME: nome tabella PostgreSQL
Per mappare più tabelle, puoi utilizzare il carattere jolly (%) nel campo Tabelle, ad esempio:
HR.%,hr.%I campi obbligatori per Writer database sono contrassegnati nel seguente screenshot:
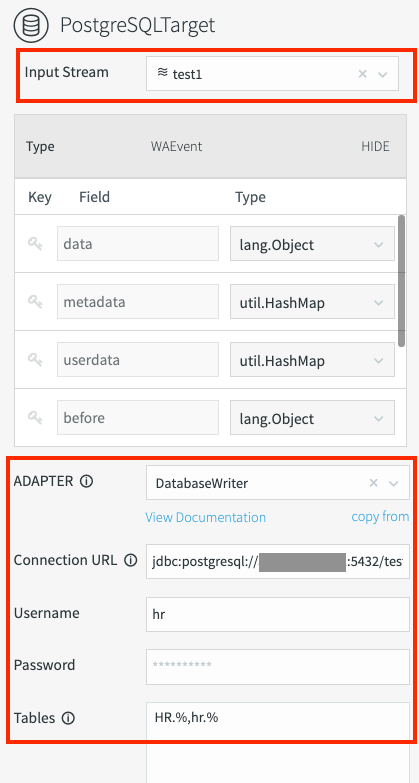
esegui il deployment della pipeline di migrazione
Quando la pipeline di migrazione è pronta, esegui il deployment da Striim Flow Designer e avvia l'applicazione. Puoi anche visualizzare l'anteprima dei dati replicati in tempo reale. Utilizza Monitora i report per monitorare l'avanzamento della replica. Per monitorare l'avanzamento, seleziona l'icona Avanzamento dell'applicazione.
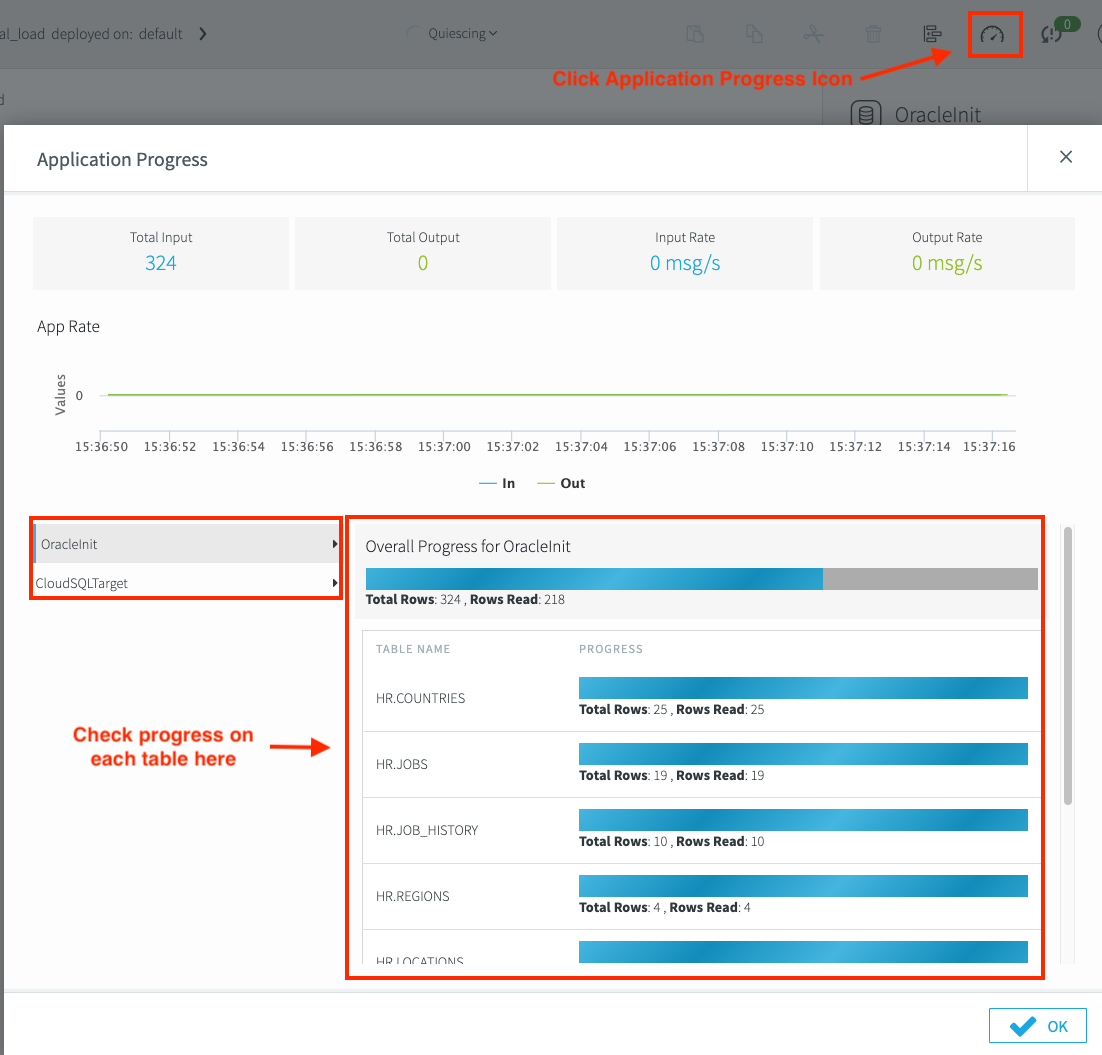
In Striim Flow Designer, esegui il deployment della pipeline di migrazione. Fai clic sull'elenco a discesa Created, quindi fai clic su Deploy App. Al termine del caricamento iniziale, lo stato della pipeline diventa
Quiesced.Fai clic su Annulla il deployment dell'app per eseguire il rollback del deployment.
Verifica che il caricamento dei dati sia riuscito controllando il conteggio delle righe:
SELECT COUNT(*) FROM <TARGET CLOUD SQL TABLE>;Dovresti vedere un output diverso da zero. In caso contrario, il caricamento dei dati non è riuscito.
Il caricamento iniziale dei dati dal database Oracle a Cloud SQL per PostgreSQL è atomico. Il caricamento dei dati ha esito positivo oppure l'intero caricamento dei dati ha esito negativo. Se il caricamento iniziale non va a buon fine, devi caricare di nuovo i dati.
Abilitazione dei vincoli di chiave esterna nelle tabelle Cloud SQL per PostgreSQL
Al termine del caricamento iniziale, abilita i vincoli della chiave esterna nelle tabelle di destinazione. Utilizza il file con le dichiarazioni di chiave esterna (FKEY_output.sql o
converted_foreignkey.sql) che hai creato durante la
conversione dello schema.
In Striim, apri una sessione SSH.
Crea vincoli di chiave esterna nelle tabelle:
psql -h HOSTNAME -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -p CLOUD_SQL_PORT -f PATH_TO_FOREIGN_KEY_FILESostituisci quanto segue:
- CLOUD_SQL_USERNAME: nome utente Cloud SQL per PostgreSQL
PATH_TO_FOREIGN_KEY_FILE: : percorso dello script con vincoli di chiave esterna sull'istanza Striim
Ad esempio:
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
Replica continua del database Oracle in Cloud SQL per PostgreSQL
Dopo aver completato il caricamento iniziale dei dati, crea una pipeline separata per replicare le modifiche al database Oracle. Finché rimane in esecuzione, questa pipeline mantiene sincronizzato anche il database di origine con il database di destinazione.
Stabilire una connessione a Oracle da Striim
Per la replica continua, utilizza l'adattatore Oracle Reader Striim per connetterti da Striim al database Oracle. Questo adattatore Striim può leggere i dati CDC da Oracle.
- Nell'adattatore Oracle Reader Striim, vai a Origini.
Cerca Oracle e seleziona Oracle CDC dall'elenco visualizzato.
Imposta le seguenti proprietà:
URL di connessione:
HOSTNAME:ORACLE_PORT/SIDOR
HOSTNAME:ORACLE_PORT/CDB_SERVICE_NAMESostituisci quanto segue:
- CDB_SERVICE_NAME: nome del servizio CDB di Oracle
L'URL di connessione è una stringa univoca utilizzata per la connessione al database Oracle. A differenza dell'adattatore lettore database utilizzato per il caricamento iniziale, viene utilizzato il nome del servizio CDB, indipendentemente dal fatto che le tabelle del database siano in un PDB o CDB.
Ad esempio:
12.123.123.12:1521/ORCLCDB.WORLD.Nome utente/password: utilizza il nome utente Oracle (
c##striimutente) che hai creato nei passaggi prerequisiti.Questo utente Oracle deve disporre dei privilegi per leggere le tabelle.
Tabelle: è necessario anche un elenco di nomi di tabella da replicare. Il nome viene specificato nel seguente formato, a seconda che le tabelle siano in CDB o PDB.
Per la tabella CDB:
ORACLE_SCHEMA.ORACLE_TABLE_NAMEPer la tabella PDB:
PDB_NAME.ORACLE_SCHEMA.ORACLE_TABLE_NAMESostituisci quanto segue:
- PDB_NAME: nome PDB Oracle
Questo comando replica le tabelle CDB o PDB. Puoi trovare
PDB_NAMEnel filetnsnames.orache si trova all'indirizzo$ORACLE_HOME/network/admin/tnsnames.orasull'istanza Oracle.Ricorda,
PDB_NAMEePDB_SERVICE_NAMEsono due cose diverse. Hai utilizzatoPDB_SERVICE_NAMEin precedenza nella sezione. Visualizza il filetnsnames.oraper recuperare il nome del PDB:sudo su - oracle // Login as oracle user cat ORACLE_HOME/network/admin/tnsnames.oraDi seguito è riportato un esempio di
PDB_NAME(APPSPDB) nel filetnsnames.ora:APPSPDB = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP) (HOST = orainst) (PORT = 1521)) ) (CONNECT_DATA = (SERVICE NAME = APPSPDB.WORLD) ) )Per specificare più tabelle e viste materializzate come elenco, separa i nomi delle tabelle o delle viste con punti e virgola o caratteri jolly. Almeno una tabella deve corrispondere al carattere jolly; in caso contrario, Oracle Reader restituisce un errore
Could not find tables specified in the database.Avvia SCN: per la pipeline continua, devi fornire l'SCN del database Oracle. Striim lo ha bisogno per iniziare a replicare tutte le transazioni. Inserisci il valore SCN generato in precedenza.
Supporto di PDB e CDB: puoi utilizzare un CDB o un PDB; espandi Mostra proprietà facoltative e sposta l'opzione verso destra.
Tabella con indicatori molto chiari: utilizza il nome della tabella che hai creato in precedenza.
Lo screenshot seguente fornisce una panoramica dei campi obbligatori per l'adattatore Oracle Reader:
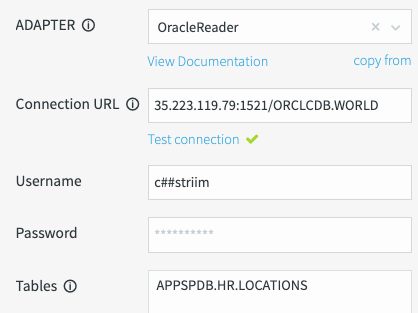
Verifica connessione: fai clic su Verifica connessione. L'URL di connessione, il nome utente e la password sono necessari per testare la connettività del database. Se Striim riesce a stabilire una connessione, viene visualizzato un segno di spunta verde.
Verifica la capacità di Striim di leggere le tabelle del database Oracle:
- Nell'adattatore Oracle Reader, seleziona Deploy app (Esegui il deployment dell'app).
- Seleziona il gruppo di deployment predefinito.
- Fai clic su Esegui il deployment.
Fai clic sull'icona a forma di onda (Output) per questo adattatore. L'icona a forma di occhio (Anteprima) che viene visualizzata viene utilizzata per visualizzare l'anteprima dei dati in tempo reale mentre Striim li legge dall'origine.
Fai clic su Avvia app nel menu a discesa Deployment eseguito.
Se si verificano errori, seleziona Annulla il deployment dell'app dallo stesso menu a discesa e correggi gli errori. Dopo aver corretto gli errori, fai clic su Riprendi app per riavviare l'applicazione.
All'avvio della pipeline, il suo stato viene aggiornato in Running. Eventuali nuove modifiche alla tabella di origine vengono visualizzate nella finestra di anteprima. Poiché l'adattatore Oracle Reader utilizza CDC, le uniche modifiche alla tabella visualizzate nel riquadro dei dati di anteprima sono quelle che si verificano dopo l'avvio dell'applicazione.
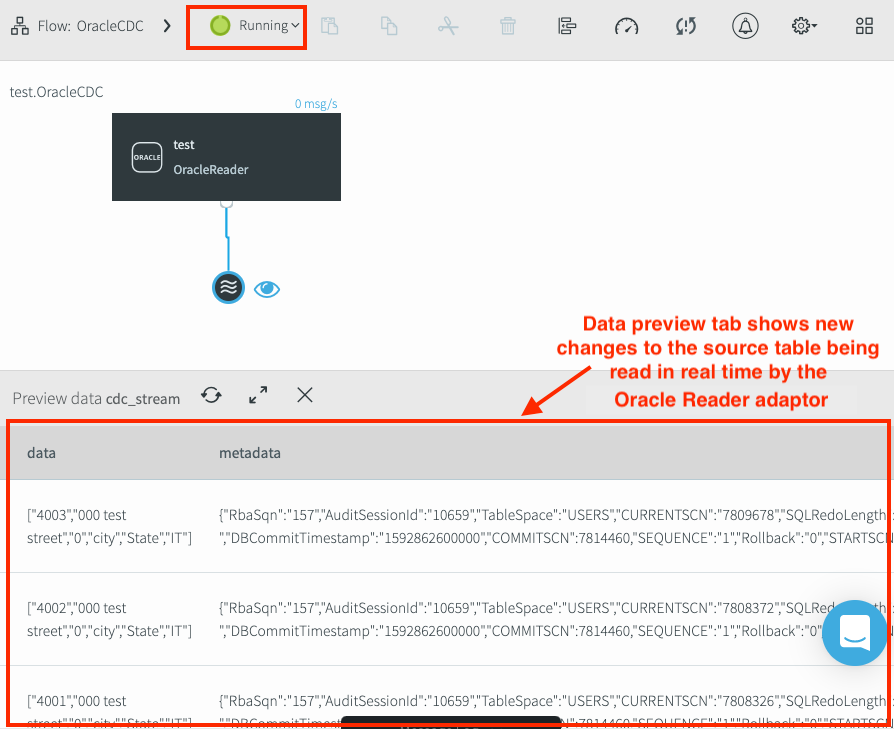
Verifica la capacità di leggere i dati CDC da Oracle
Per verificare se l'adattatore è in grado di leggere le nuove modifiche, segui queste istruzioni:
- Utilizza le istruzioni SQL per inserire nuove transazioni nelle tabelle di origine Oracle.
- Verifica che le nuove transazioni vengano visualizzate nella scheda Anteprima dati dell'adattatore Oracle Reader.
- Arresta l'applicazione e fai clic su Annulla deployment. Ora sei pronto ad andare al passaggio successivo.
Fino a questo punto non hai aggiunto un adattatore di destinazione alla pipeline. I dati non vengono copiati se non aggiungi un adattatore di destinazione. Nella sezione successiva aggiungerai un adattatore di destinazione.
Aggiungi un database Cloud SQL per PostgreSQL come destinazione
Per scrivere dati nel database Cloud SQL per PostgreSQL, devi aggiungere un adattatore Writer database alla tua pipeline. Per la pipeline di replica continua, utilizza lo stesso adattatore utilizzato nella pipeline di caricamento iniziale.
- In Striim Flow Designer, vai a Destinazioni, quindi cerca e seleziona Cloud SQL Postgres dall'elenco.
- Trascina Writer database sulla pipeline.
Imposta le seguenti proprietà:
Alimentatore:
DatabaseWriter.URL di connessione: inserisci l'URL di connessione inserito per stabilire una connessione all'istanza Cloud SQL.
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecifiedAd esempio:
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedNome utente e password: inserisci il nome utente e la password di Cloud SQL che hai creato in precedenza.
Tabelle: crea un mapping dai nomi delle tabelle del database Oracle ai nomi delle tabelle Cloud SQL. Specifica quale tabella di database Oracle è scritta in una quale tabella Cloud SQL. Questa mappatura utilizza il seguente formato:
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAMEPer mappare più tabelle, puoi utilizzare il carattere jolly (%) nel campo Tabelle. Ad esempio:
HR.%,hr.%Oltre a queste proprietà, devi impostare anche le seguenti proprietà per la pipeline di replica continua:
Fai clic su Mostra proprietà facoltative.
Seleziona il seguente valore per il campo Ignorable Eccezioni Code:
23505,NO_OP_UPDATE,NO_OP_DELETEPoiché stai avviando la pipeline CDC da un punto storico, potrebbero esserci duplicati. Striim deduplica sul target utilizzando le precedenti proprietà del codice di eccezione ignorabile. I dettagli sui codici di eccezione sono disponibili nella seguente tabella:
Codice eccezione Dettagli 23505Il valore della chiave primaria duplicata viola un vincolo univoco NO_OP_UPDATEImpossibile aggiornare una riga nel target (in genere perché non c'era una chiave primaria corrispondente) NO_OP_DELETEImpossibile eliminare una riga nella destinazione (in genere perché non c'era una chiave primaria corrispondente) Inserisci
chkpointnel campo Check Point Table (Tabella dei punti di controllo). Striim utilizza questa tabella per archiviare i metadati associati al checkpoint della pipeline di replica continua.
Attivazione del recupero e della crittografia
Prima di eseguire il deployment della pipeline CDC, ti consigliamo vivamente di abilitare il ripristino. Se l'applicazione o la VM Striim smette di funzionare, abilitare il ripristino aiuta a garantire che Striim possa continuare a elaborare. Questo passaggio aiuta anche a garantire l'elaborazione "exactly-once" della semantica. Queste semantiche monitorano il checkpoint di lettura dell'ultimo buon livello noto sul database di origine e l'ultimo checkpoint di scrittura noto sul database di destinazione. In caso di errore di un'applicazione o di una VM, Striim coordina i due checkpoint per garantire che nessun dato sia stato perso o duplicato. Il ripristino non si applica alle applicazioni al caricamento iniziale.
Abilita recupero
- In Striim Flow Designer, fai clic sull'icona Configurazione, quindi seleziona Impostazioni app.
- Fai clic su Intervallo di recupero.
- Digita
5e seleziona Secondo dall'elenco a discesa. - Fai clic su Attiva la crittografia. Striim cripta tutti i flussi che trasferiscono dati tra i server Striim o da un agente di forwarding a un server Striim.
Attiva crittografia
- In Striim Flow Designer, fai clic sull'icona Configurazione, seleziona Impostazioni app e seleziona la casella di controllo in Crittografia.
Visita il sito web di Striim per scoprire di più sui metodi di recupero di Striim.
Abilita eccezioni di logging
Prima di eseguire il deployment della pipeline di replica continua, ti consigliamo di abilitare l'archivio di eccezione in Striim. Nell'ambito dell'applicazione CDC, potrebbero essere presenti duplicati scritti dall'applicazione di caricamento iniziale. L'applicazione Striim ignora questi errori, li scrive in un archivio (per consentirti di esaminarli ed elaborarli) e continuare a elaborare.
- In Striim Flow Designer, seleziona l'icona Eccezioni. L'icona mostra un punto esclamativo tra due frecce curve.
- Fai clic su Attiva.
esegui il deployment della pipeline
Quando la pipeline è pronta, puoi eseguirne il deployment e avviare l'applicazione. Puoi anche visualizzare l'anteprima dei dati mentre vengono replicati in tempo reale e visualizzare i report di monitoraggio. Quando la pipeline avvia correttamente la replica continua, lo stato della pipeline diventa In esecuzione.
- Nell'adattatore Oracle Reader, seleziona Deploy app (Esegui il deployment dell'app).
- Seleziona il gruppo di deployment predefinito.
- Fai clic su Esegui il deployment.
Puoi mantenere la pipeline in esecuzione per tutto il tempo in cui vuoi mantenere le tabelle Oracle sincronizzate con le tabelle Cloud SQL.
Hai terminato il tutorial. Se ti interessa saperne di più su altre origini CDC di Oracle, queste vengono descritte nella sezione seguente.
Origini CDC Oracle alternative
Oltre a LogMiner, l'adattatore di Striim può leggere i database Oracle da XStream o file di trail di Oracle Golden Gate.
Per leggere da XStream, utilizza l'adattatore Oracle Reader di Striim. XStream potrebbe avere prestazioni migliori, ma richiede una licenza Golden Gate ed è supportato solo per Oracle Database 11.2.0.4.
Per leggere i file di prova Golden Gate, utilizza l'adattatore GG Trail Reader di Striim.
Nella tabella seguente vengono descritte le differenze tra LogMiner e XStream:
| Funzionalità CDC del database Oracle |
Supportato da LogMiner? |
Supportato da XStream Out? |
|---|---|---|
Lettura di Data Definition Language (DDL), ROLLBACK e
transazioni non impegnate |
Sì | No |
Utilizzare le funzioni DATA() e BEFORE() |
Sì | No |
Utilizzo di QUIESCE (vedi Comandi della console)
|
Sì | No |
| Ricezione di eventi CDC | Riceve gli eventi in batch come definito dalla proprietà FetchSize di Oracle Reader |
Ricezione continua di eventi di modifica relativi ai dati |
| Lettura da tabelle contenenti tipi non supportati | Impossibile leggere la tabella | Legge le colonne dei tipi supportati |
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID del progetto e fai clic su Chiudi per eliminare il progetto.
Passaggi successivi
- Consulta la documentazione di Striim: Guida alla migrazione da Oracle a Google Cloud PostgreSQL
- Guarda il video sulla migrazione dei database Oracle a Cloud SQL PostgreSQL.
- Per altre architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.
Oracle, Java e MySQL sono marchi registrati di Oracle e/o delle sue società consociate. Altri nomi possono essere marchi dei rispettivi proprietari.