Tutorial ini merupakan bagian kedua dari seri yang menunjukkan kepada Anda cara membangun solusi end-to-end untuk memberi analis data akses yang aman ke data saat menggunakan alat business intelligence (BI).
Tutorial ini ditujukan untuk operator dan admin IT yang menyiapkan lingkungan yang menyediakan data dan kemampuan pemrosesan data untuk alat business intelligence (BI) yang digunakan analis data.
Tableau digunakan sebagai alat BI dalam tutorial ini. Untuk mengikuti tutorial ini, Anda harus menginstal Tableau Desktop di workstation Anda.
Seri ini terdiri dari bagian-bagian berikut:
- Bagian pertama dari seri ini, Arsitektur untuk menghubungkan software visualisasi ke Hadoop di Google Cloud, mendefinisikan arsitektur solusi, komponennya, dan cara komponen tersebut berinteraksi.
- Bagian kedua dari seri ini memberi tahu Anda cara menyiapkan komponen arsitektur yang membentuk topologi Hive end-to-end di Google Cloud. Tutorial ini menggunakan alat open source dari ekosistem Hadoop, dengan Tableau sebagai alat BI-nya.
Cuplikan kode dalam tutorial ini tersedia di repositori GitHub. Repositori GitHub juga menyertakan file konfigurasi Terraform untuk membantu Anda menyiapkan prototipe yang berfungsi.
Selama tutorial, Anda akan menggunakan nama sara sebagai identitas pengguna fiktif
dari seorang data analis. Identitas pengguna ini ada di direktori LDAP yang
digunakan Apache Knox dan Apache Ranger. Anda juga dapat memilih untuk mengonfigurasi grup LDAP, tetapi prosedur ini
berada di luar cakupan tutorial ini.
Tujuan
- Buat penyiapan end-to-end yang memungkinkan alat BI menggunakan data dari lingkungan Hadoop.
- Mengautentikasi dan memberi otorisasi kepada permintaan pengguna.
- Siapkan dan gunakan saluran komunikasi yang aman antara alat BI dan clusternya.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) APIs.
Melakukan inisialisasi lingkungan Anda
-
In the Google Cloud console, activate Cloud Shell.
Di Cloud Shell, tetapkan variabel lingkungan dengan project ID Anda, serta region dan zona cluster Dataproc:
export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bAnda dapat memilih region dan zona apa pun, asalkan tetap konsisten menggunakannya selama mengikuti tutorial ini.
Menyiapkan akun layanan
Di Cloud Shell, buat akun layanan.
gcloud iam service-accounts create cluster-service-account \ --description="The service account for the cluster to be authenticated as." \ --display-name="Cluster service account"Cluster menggunakan akun ini untuk mengakses resource Google Cloud .
Tambahkan peran berikut ke akun layanan:
- Dataproc Worker: untuk membuat dan mengelola cluster Dataproc.
- Editor Cloud SQL: untuk Ranger untuk terhubung ke database-nya menggunakan Proxy Cloud SQL.
Pendekripsi Cloud KMS CryptoKey: untuk mendekripsi sandi yang dienkripsi dengan Cloud KMS.
bash -c 'array=( dataproc.worker cloudsql.editor cloudkms.cryptoKeyDecrypter ) for i in "${array[@]}" do gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "serviceAccount:cluster-service-account@${PROJECT_ID}." \ --role roles/$i done'
Membuat cluster backend
Di bagian ini, Anda akan membuat cluster backend tempat Ranger berada. Anda juga membuat database Ranger untuk menyimpan aturan kebijakan, dan tabel sampel di Hive untuk menerapkan kebijakan Ranger.
Membuat instance database Ranger
Buat instance MySQL untuk menyimpan kebijakan Apache Ranger:
export CLOUD_SQL_NAME=cloudsql-mysql gcloud sql instances create ${CLOUD_SQL_NAME} \ --tier=db-n1-standard-1 --region=${REGION}Perintah ini membuat instance yang disebut
cloudsql-mysqldengan jenis mesindb-n1-standard-1yang berada di region yang ditentukan oleh variabel${REGION}. Untuk informasi selengkapnya, lihat dokumentasi Cloud SQL.Tetapkan sandi instance untuk pengguna
rootyang terhubung dari host mana pun. Anda dapat menggunakan contoh sandi untuk kebutuhan demo, atau membuat sandi Anda sendiri. Jika Anda membuat sandi sendiri, gunakan minimal delapan karakter yang terdiri dari setidaknya satu huruf dan satu angka.gcloud sql users set-password root \ --host=% --instance ${CLOUD_SQL_NAME} --password mysql-root-password-99
Mengenkripsi sandi
Di bagian ini, Anda akan membuat kunci kriptografis untuk mengenkripsi sandi Ranger dan MySQL. Untuk mencegah pemindahan yang tidak sah, simpan kunci kriptografis di Cloud KMS. Demi tujuan keamanan, Anda tidak dapat melihat, mengekstrak, atau mengekspor bit kunci.
Gunakan kunci kriptografis untuk mengenkripsi sandi dan menulisnya ke dalam file.
Upload file ini ke bucket Cloud Storage agar dapat
diakses oleh akun layanan yang bertindak mewakili cluster.
Akun layanan dapat mendekripsi file ini karena memiliki
peran cloudkms.cryptoKeyDecrypter dan akses ke file serta kunci
kriptografis. Meskipun file dipindah secara tidak sah, file tidak akan dapat didekripsi tanpa peran
dan kuncinya.
Sebagai langkah keamanan tambahan, Anda perlu membuat file sandi terpisah untuk setiap layanan. Tindakan ini meminimalkan potensi area yang terdampak jika sandi dipindah secara tidak sah.
Untuk informasi selengkapnya tentang pengelolaan kunci, lihat dokumentasi Cloud KMS.
Di Cloud Shell, buat key ring Cloud KMS untuk menyimpan kunci Anda:
gcloud kms keyrings create my-keyring --location globalUntuk mengenkripsi sandi Anda, buat kunci kriptografis Cloud KMS:
gcloud kms keys create my-key \ --location global \ --keyring my-keyring \ --purpose encryptionEnkripsi sandi pengguna admin Ranger Anda menggunakan kunci tersebut. Anda dapat menggunakan contoh sandi atau membuatnya sendiri. Sandi Anda minimal harus memiliki delapan karakter, setidaknya satu huruf dan satu angka.
echo "ranger-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-admin-password.encryptedEnkripsi sandi pengguna admin database Ranger Anda dengan kunci:
echo "ranger-db-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-db-admin-password.encryptedEnkripsi sandi root MySQL Anda dengan kunci:
echo "mysql-root-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=mysql-root-password.encryptedBuat bucket Cloud Storage untuk menyimpan file sandi terenkripsi:
gcloud storage buckets create gs://${PROJECT_ID}-ranger --location=${REGION}Upload file sandi terenkripsi ke bucket Cloud Storage:
gcloud storage cp *.encrypted gs://${PROJECT_ID}-ranger
Membuat cluster
Di bagian ini, Anda akan membuat cluster backend dengan dukungan Ranger. Untuk informasi selengkapnya tentang komponen opsional Ranger di Dataproc, lihat halaman dokumentasi Komponen Dataproc Ranger.
Di Cloud Shell, buat bucket Cloud Storage untuk menyimpan log audit Apache Solr:
gcloud storage buckets create gs://${PROJECT_ID}-solr --location=${REGION}Ekspor semua variabel yang diperlukan untuk membuat cluster:
export BACKEND_CLUSTER=backend-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b export CLOUD_SQL_NAME=cloudsql-mysql export RANGER_KMS_KEY_URI=\ projects/${PROJECT_ID}/locations/global/keyRings/my-keyring/cryptoKeys/my-key export RANGER_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-admin-password.encrypted export RANGER_DB_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-db-admin-password.encrypted export MYSQL_ROOT_PWD_URI=\ gs://${PROJECT_ID}-ranger/mysql-root-password.encryptedAgar lebih mudah, beberapa variabel yang Anda tetapkan sebelumnya diulang dalam perintah ini sehingga Anda dapat mengubahnya sesuai kebutuhan.
Variabel baru ini berisi:
- Nama cluster backend.
- URI kunci kriptografis agar akun layanan dapat mendekripsi sandi.
- URI file yang berisi sandi terenkripsi.
Jika Anda menggunakan key ring atau kunci yang berbeda, atau nama file yang berbeda, gunakan nilai yang sesuai dalam perintah Anda.
Buat cluster Dataproc backend:
gcloud beta dataproc clusters create ${BACKEND_CLUSTER} \ --optional-components=SOLR,RANGER \ --region ${REGION} \ --zone ${ZONE} \ --enable-component-gateway \ --scopes=default,sql-admin \ --service-account=cluster-service-account@${PROJECT_ID}. \ --properties="\ dataproc:ranger.kms.key.uri=${RANGER_KMS_KEY_URI},\ dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PWD_URI},\ dataproc:ranger.db.admin.password.uri=${RANGER_DB_ADMIN_PWD_URI},\ dataproc:ranger.cloud-sql.instance.connection.name=${PROJECT_ID}:${REGION}:${CLOUD_SQL_NAME},\ dataproc:ranger.cloud-sql.root.password.uri=${MYSQL_ROOT_PWD_URI},\ dataproc:solr.gcs.path=gs://${PROJECT_ID}-solr,\ hive:hive.server2.thrift.http.port=10000,\ hive:hive.server2.thrift.http.path=cliservice,\ hive:hive.server2.transport.mode=http"Perintah ini memiliki properti berikut:
- Tiga baris terakhir dalam perintah ini adalah properti Hive untuk mengonfigurasi HiveServer2 dalam mode HTTP, sehingga Apache Knox dapat memanggil Apache Hive melalui HTTP.
- Parameter lain dalam perintah ini beroperasi sebagai berikut:
- Parameter
--optional-components=SOLR,RANGERmengaktifkan Apache Ranger dan dependensi Solr-nya. - Parameter
--enable-component-gatewaymengaktifkan Komponen Gateway Dataproc yang membuat Ranger dan antarmuka pengguna Hadoop lainnya tersedia langsung dari halaman cluster di konsol Google Cloud. Saat menetapkan parameter ini, Anda tidak perlu melakukan tunneling SSH ke node master backend. - Parameter
--scopes=default,sql-adminmemberikan otorisasi kepada Apache Ranger untuk mengakses database Cloud SQL-nya.
- Parameter
Jika Anda perlu membuat metastore Hive eksternal yang melampaui umur
cluster apa pun dan dapat digunakan di beberapa cluster, lihat Menggunakan Apache Hive di Dataproc.
Untuk menjalankan prosedur ini, Anda harus menjalankan contoh pembuatan tabel secara langsung
di Beeline. Meskipun perintah gcloud dataproc jobs submit hive menggunakan transport biner, perintah ini
tidak kompatibel dengan HiveServer2 saat dikonfigurasi dalam mode HTTP.
Membuat contoh tabel Hive
Di Cloud Shell, buat bucket Cloud Storage untuk menyimpan contoh file Apache Parquet:
gcloud buckets create gs://${PROJECT_ID}-hive --location=${REGION}Salin contoh file Parquet yang tersedia secara publik ke bucket Anda:
gcloud storage cp gs://hive-solution/part-00000.parquet \ gs://${PROJECT_ID}-hive/dataset/transactions/part-00000.parquetHubungkan ke node master cluster backend yang Anda buat di bagian sebelumnya menggunakan SSH:
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mNama node master cluster Anda adalah nama cluster yang diikuti dengan
-m.Nama node master cluster HA memiliki akhiran tambahan.Jika ini adalah pertama kalinya Anda terhubung ke node master dari Cloud Shell, Anda akan diminta untuk membuat kunci SSH.
Di terminal yang Anda buka dengan SSH, hubungkan ke HiveServer2 lokal menggunakan Apache Beeline, yang telah terinstal di node master:
beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice admin admin-password"\ --hivevar PROJECT_ID=$(gcloud info --format='value(config.project)')Perintah ini memulai alat command-line Beeline dan meneruskan nama project Google Cloud Anda dalam variabel lingkungan.
Hive tidak melakukan autentikasi pengguna apa pun, tetapi membutuhkan identitas pengguna untuk melakukan sebagian besar tugasnya. Pengguna
admindi sini adalah pengguna default yang dikonfigurasi di Hive. Penyedia identitas yang nanti Anda konfigurasikan dengan Apache Knox dalam tutorial ini menangani autentikasi pengguna untuk setiap permintaan yang berasal dari alat BI.Pada perintah Beeline, buat tabel menggunakan file Parquet yang sebelumnya Anda salin ke bucket Hive Anda:
CREATE EXTERNAL TABLE transactions (SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) STORED AS PARQUET LOCATION 'gs://${PROJECT_ID}-hive/dataset/transactions';Pastikan bahwa tabel telah dibuat dengan benar:
SELECT * FROM transactions LIMIT 10; SELECT TransactionType, AVG(TransactionAmount) AS AverageAmount FROM transactions WHERE SubmissionDate = '2017-12-22' GROUP BY TransactionType;Hasil dari kedua kueri muncul di perintah Beeline.
Keluar dari alat command-line Beeline:
!quitSalin nama DNS internal dari master backend:
hostname -A | tr -d '[:space:]'; echoGunakan nama ini di bagian berikutnya sebagai
backend-master-internal-dns-nameuntuk mengonfigurasi topologi Apache Knox. Anda juga akan menggunakan nama tersebut untuk mengonfigurasi layanan di Ranger.Keluar dari terminal pada node:
exit
Membuat cluster proxy
Di bagian ini, Anda akan membuat cluster proxy yang memiliki tindakan inisialisasi Apache Knox.
Membuat topologi
Di Cloud Shell, clone tindakan inisialisasi repositori GitHub Dataproc:
git clone https://github.com/GoogleCloudDataproc/initialization-actions.gitBuat topologi untuk cluster backend:
export KNOX_INIT_FOLDER=`pwd`/initialization-actions/knox cd ${KNOX_INIT_FOLDER}/topologies/ mv example-hive-nonpii.xml hive-us-transactions.xmlApache Knox menggunakan nama file sebagai jalur URL untuk topologi. Pada langkah ini, Anda mengubah nama untuk mewakili topologi yang disebut
hive-us-transactions. Selanjutnya, Anda dapat mengakses data transaksi fiktif yang Anda muat ke Hive di Membuat contoh tabel HiveEdit file topologi:
vi hive-us-transactions.xmlUntuk melihat cara layanan backend dikonfigurasi, lihat file deskriptor topologi. File ini menentukan topologi yang mengarah ke satu atau beberapa layanan backend. Dua layanan dikonfigurasi dengan nilai sampel: WebHDFS dan HIVE. File ini juga menentukan penyedia autentikasi untuk layanan dalam topologi dan ACL otorisasi.
Tambahkan contoh identitas pengguna LDAP analis data
sara.<param> <name>hive.acl</name> <value>admin,sara;*;*</value> </param>Menambahkan contoh identitas memungkinkan pengguna mengakses layanan backend Hive melalui Apache Knox.
Ubah URL HIVE untuk mengarah ke layanan Hive cluster backend. Anda dapat menemukan definisi layanan HIVE di bagian bawah file, di WebHDFS.
<service> <role>HIVE</role> <url>http://<backend-master-internal-dns-name> :10000/cliservice</url> </service>Ganti placeholder
<backend-master-internal-dns-name>dengan nama DNS internal cluster backend yang Anda peroleh di Membuat contoh tabel Hive.Simpan file dan tutup editor.
Untuk membuat topologi tambahan, ulangi langkah-langkah di bagian ini. Buat satu deskriptor XML independen untuk setiap topologi.
Di bagian Membuat cluster proxy, salin file ini ke dalam bucket Cloud Storage. Untuk membuat topologi baru atau mengubahnya setelah Anda membuat cluster proxy, ubah file lalu upload lagi ke bucket. Tindakan inisialisasi Apache Knox membuat cron job yang menyalin perubahan dari bucket ke cluster proxy secara rutin.
Mengonfigurasi sertifikat SSL/TLS
Klien menggunakan sertifikat SSL/TLS saat berkomunikasi dengan Apache Knox. Tindakan inisialisasi dapat menghasilkan sertifikat yang ditandatangani sendiri, atau Anda dapat menyediakan sertifikat yang ditandatangani CA.
Di Cloud Shell, edit file konfigurasi umum Apache Knox:
vi ${KNOX_INIT_FOLDER}/knox-config.yamlGanti
HOSTNAMEdengan nama DNS eksternal dari node master proxy Anda sebagai nilai untuk atributcertificate_hostname. Untuk tutorial ini, gunakanlocalhost.certificate_hostname: localhostNantinya, dalam tutorial ini Anda akan membuat tunnel SSH dan cluster proxy untuk nilai
localhost.File konfigurasi umum Apache Knox juga berisi
master_keyyang mengenkripsi sertifikat yang digunakan alat BI untuk berkomunikasi dengan cluster proxy. Secara default, kunci ini adalah katasecret.Jika Anda menyediakan sertifikat sendiri, ubah dua properti berikut:
generate_cert:false custom_cert_name:<filename-of-your-custom-certificate> Simpan file dan tutup editor.
Jika menyediakan sertifikat sendiri, Anda dapat menentukannya dalam properti
custom_cert_name.
Membuat cluster proxy
Di Cloud Shell, buat bucket Cloud Storage:
gcloud storage buckets create gs://${PROJECT_ID}-knox --location=${REGION}Bucket ini menyediakan konfigurasi yang Anda buat di bagian sebelumnya untuk tindakan inisialisasi Apache Knox.
Salin semua file dari folder tindakan inisialisasi Apache Knox ke bucket tersebut:
gcloud storage cp ${KNOX_INIT_FOLDER}/* gs://${PROJECT_ID}-knox --recursiveEkspor semua variabel yang diperlukan untuk membuat cluster:
export PROXY_CLUSTER=proxy-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bPada langkah ini, beberapa variabel yang ditetapkan sebelumnya akan diulang sehingga Anda dapat mengubahnya sesuai kebutuhan.
Buat cluster proxy:
gcloud dataproc clusters create ${PROXY_CLUSTER} \ --region ${REGION} \ --zone ${ZONE} \ --service-account=cluster-service-account@${PROJECT_ID}. \ --initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/knox/knox.sh \ --metadata knox-gw-config=gs://${PROJECT_ID}-knox
Memverifikasi koneksi melalui proxy
Setelah cluster proxy dibuat, gunakan SSH untuk terhubung ke node master dari Cloud Shell:
gcloud compute ssh --zone ${ZONE} ${PROXY_CLUSTER}-mDari terminal node master cluster proxy, jalankan kueri berikut:
beeline -u "jdbc:hive2://localhost:8443/;\ ssl=true;sslTrustStore=/usr/lib/knox/data/security/keystores/gateway-client.jks;trustStorePassword=secret;\ transportMode=http;httpPath=gateway/hive-us-transactions/hive"\ -e "SELECT SubmissionDate, TransactionType FROM transactions LIMIT 10;"\ -n admin -p admin-password
Perintah ini memiliki properti berikut:
- Perintah
beelinemenggunakanlocalhostalih-alih nama internal DNS, karena sertifikat yang Anda buat saat mengonfigurasi Apache Knox menetapkanlocalhostsebagai nama host. Jika menggunakan nama DNS atau sertifikat Anda sendiri, gunakan nama host yang sesuai. - Port-nya adalah
8443, yang sesuai dengan port SSL default Apache Knox. - Baris yang memulai
ssl=trueakan mengaktifkan SSL dan memberikan jalur dan sandi untuk SSL Trust Store untuk digunakan oleh aplikasi klien seperti Beeline. - Baris
transportModemenunjukkan bahwa permintaan harus dikirim melalui HTTP dan menyediakan jalur untuk layanan HiveServer2. Jalur tersebut terdiri dari kata kuncigateway, nama topologi yang Anda tentukan di bagian sebelumnya, dan nama layanan yang dikonfigurasi dalam topologi yang sama, dalam hal inihive. - Parameter
-emenyediakan kueri untuk dijalankan di Hive. Jika menghapus parameter ini, Anda akan membuka sesi interaktif dalam alat command line Beeline. - Parameter
-nmenyediakan identitas dan sandi pengguna. Dalam langkah ini, Anda menggunakan pengguna Hiveadmindefault. Di bagian selanjutnya, Anda membuat identitas pengguna analis dan menyiapkan kredensial serta kebijakan otorisasi untuk pengguna ini.
Menambahkan pengguna ke penyimpanan autentikasi
Secara default, Apache Knox menyertakan penyedia autentikasi yang didasarkan pada
Apache Shiro.
Penyedia autentikasi ini dikonfigurasi dengan autentikasi BASIC terhadap
penyimpanan LDAP ApacheDS. Di bagian ini, Anda menambahkan contoh identitas pengguna
analis data sara ke penyimpanan autentikasi.
Dari terminal node master proxy, instal utilitas LDAP :
sudo apt-get install ldap-utilsBuat file LDAP Data Interchange Format (LDIF) untuk pengguna baru
sara:export USER_ID=sara printf '%s\n'\ "# entry for user ${USER_ID}"\ "dn: uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org"\ "objectclass:top"\ "objectclass:person"\ "objectclass:organizationalPerson"\ "objectclass:inetOrgPerson"\ "cn: ${USER_ID}"\ "sn: ${USER_ID}"\ "uid: ${USER_ID}"\ "userPassword:${USER_ID}-password"\ > new-user.ldifTambahkan ID pengguna ke direktori LDAP:
ldapadd -f new-user.ldif \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389Parameter
-Dmenentukan nama yang dibedakan (DN) yang digunakan untuk mengikat saat pengguna yang direpresentasikan olehldapaddmengakses direktori. DN harus berupa identitas pengguna yang telah ada dalam direktori, dalam kasus ini penggunaadmin.Verifikasi bahwa pengguna baru ada di penyimpanan autentikasi:
ldapsearch -b "uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org" \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389Detail pengguna akan muncul di terminal.
Salin dan simpan nama DNS internal node master proxy:
hostname -A | tr -d '[:space:]'; echoGunakan nama ini di bagian berikutnya sebagai
<proxy-master-internal-dns-name>untuk mengonfigurasi sinkronisasi LDAP.Keluar dari terminal pada node:
exit
Menyiapkan otorisasi
Di bagian ini, Anda akan mengonfigurasi sinkronisasi identitas antara layanan LDAP dan Ranger.
Menyinkronkan identitas pengguna ke Ranger
Untuk memastikan kebijakan Ranger berlaku untuk identitas pengguna yang sama dengan Apache Knox, konfigurasikan daemon Ranger UserSync untuk menyinkronkan identitas dari direktori yang sama.
Dalam contoh ini, Anda terhubung ke direktori LDAP lokal yang tersedia secara default dengan Apache Knox. Namun, dalam lingkungan produksi sebaiknya Anda menyiapkan direktori identitas eksternal. Untuk informasi selengkapnya, lihat Panduan Pengguna Apache Knox dan dokumentasi Google Cloud Cloud Identity, Active Directory Terkelola, dan Federated AD.
Hubungkan ke node master cluster backend yang Anda buat menggunakan SSH:
export BACKEND_CLUSTER=backend-cluster gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mDi terminal, edit file konfigurasi
UserSync:sudo vi /etc/ranger/usersync/conf/ranger-ugsync-site.xmlTetapkan nilai properti LDAP berikut. Pastikan Anda mengubah properti
user, bukan propertigroupyang memiliki kemiripan nama.<property> <name>ranger.usersync.sync.source</name> <value>ldap</value> </property> <property> <name>ranger.usersync.ldap.url</name> <value>ldap://<proxy-master-internal-dns-name> :33389</value> </property> <property> <name>ranger.usersync.ldap.binddn</name> <value>uid=admin,ou=people,dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.ldap.ldapbindpassword</name> <value>admin-password</value> </property> <property> <name>ranger.usersync.ldap.user.searchbase</name> <value>dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.source.impl.class</name> <value>org.apache.ranger.ldapusersync.process.LdapUserGroupBuilder</value> </property>Ganti placeholder
<proxy-master-internal-dns-name>dengan nama DNS internal server proxy, yang Anda ambil di bagian terakhir.Properti ini adalah bagian dari konfigurasi lengkap LDAP yang menyinkronkan pengguna dan grup. Untuk informasi selengkapnya, lihat Cara mengintegrasikan Ranger dengan LDAP.
Simpan file dan tutup editor.
Mulai ulang daemon
ranger-usersync:sudo service ranger-usersync restartJalankan perintah berikut:
grep sara /var/log/ranger-usersync/*Jika identitas disinkronkan, Anda akan melihat setidaknya satu baris log untuk pengguna
sara.
Membuat kebijakan Ranger
Di bagian ini, Anda akan mengonfigurasi layanan Hive baru di Ranger. Anda juga menyiapkan dan menguji kebijakan Ranger untuk membatasi akses ke data Hive untuk identitas tertentu.
Mengonfigurasi layanan Ranger
Dari terminal node master, edit konfigurasi Ranger Hive:
sudo vi /etc/hive/conf/ranger-hive-security.xmlEdit properti
<value>dari propertiranger.plugin.hive.service.name:<property> <name>ranger.plugin.hive.service.name</name> <value>ranger-hive-service-01</value> <description> Name of the Ranger service containing policies for this YARN instance </description> </property>Simpan file dan tutup editor.
Mulai ulang layanan Admin HiveServer2:
sudo service hive-server2 restartAnda siap membuat kebijakan Ranger.
Menyiapkan layanan di konsol Admin Ranger
Di konsol Google Cloud, buka halaman Dataproc.
Klik nama cluster backend Anda, lalu klik Antarmuka Web.
Setelah membuat cluster dengan Komponen Gateway, Anda akan melihat daftar komponen Hadoop yang terinstal di cluster Anda.
Klik link Ranger untuk membuka konsol Ranger.
Login ke Ranger dengan pengguna
admindan sandi admin Ranger Anda. Konsol Ranger menampilkan halaman Pengelola Layanan dengan daftar layanan.Klik tanda plus di grup HIVE untuk membuat layanan Hive baru.
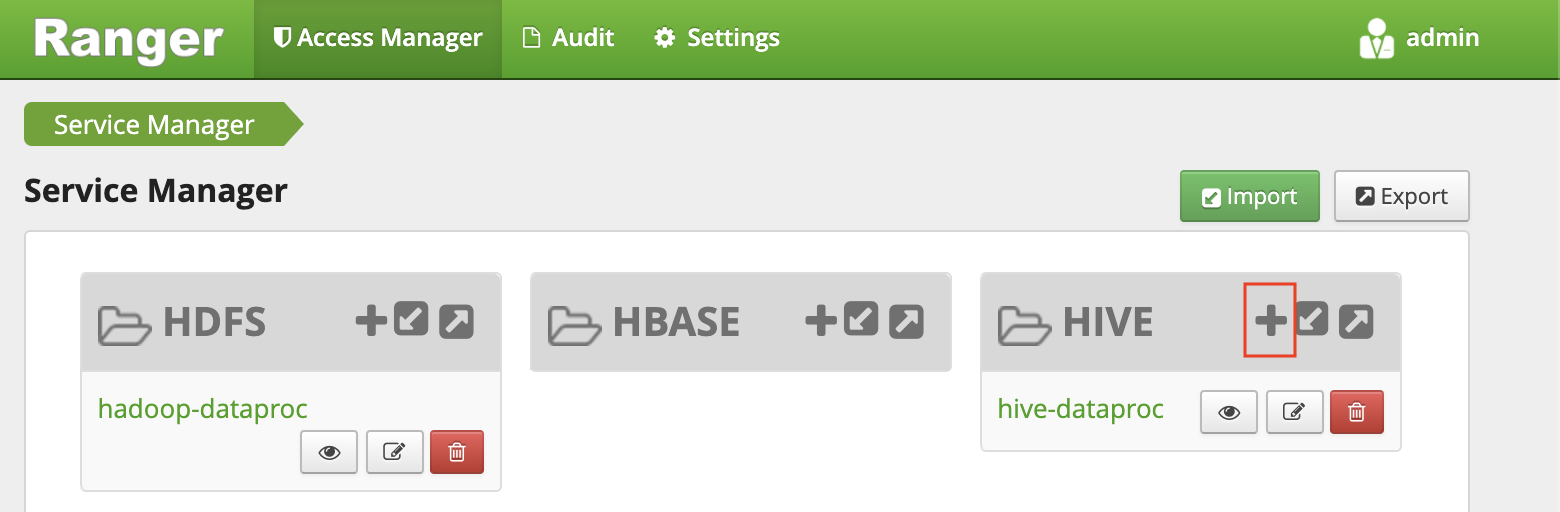
Tetapkan nilai berikut di formulir:
- Nama layanan:
ranger-hive-service-01. Anda sebelumnya menentukan nama ini dalam file konfigurasiranger-hive-security.xml. - Nama pengguna:
admin - Sandi:
admin-password jdbc.driverClassName: biarkan nama default sebagaiorg.apache.hive.jdbc.HiveDriverjdbc.url:jdbc:hive2:<backend-master-internal-dns-name>:10000/;transportMode=http;httpPath=cliservice- Ganti placeholder
<backend-master-internal-dns-name>dengan nama yang Anda ambil di bagian sebelumnya.
- Nama layanan:
Klik Tambahkan.
Setiap penginstalan plugin Ranger mendukung satu layanan Hive. Cara mudah untuk mengonfigurasi layanan Hive tambahan adalah dengan memulai cluster backend tambahan. Setiap cluster memiliki plugin Ranger-nya sendiri. Cluster ini dapat menggunakan Ranger DB yang sama, sehingga Anda dapat memiliki tampilan terpadu dari semua layanan setiap kali Anda mengakses konsol Ranger Admin dari cluster mana pun.
Menyiapkan kebijakan Ranger dengan izin terbatas
Kebijakan ini memberikan contoh analis LDAP pengguna sara akses ke kolom
tertentu dari tabel Hive.
Di jendela Pengelola Layanan, klik nama layanan yang Anda buat.
Konsol Admin Ranger akan menampilkan jendela Kebijakan.
Klik Tambahkan Kebijakan Baru
Dengan kebijakan ini, Anda memberikan izin kepada
sarauntuk hanya melihat kolomsubmissionDatedantransactionTypedari transaksi tabel.Tetapkan nilai berikut di formulir:
- Nama kebijakan: nama apa pun, misalnya
allow-tx-columns - Database:
default - Table:
transactions - Kolom Hive:
submissionDate, transactionType - Izinkan kondisi:
- Pilih pengguna:
sara - Izin:
select
- Pilih pengguna:
- Nama kebijakan: nama apa pun, misalnya
Di bagian bawah layar, klik Tambahkan.
Uji kebijakan dengan Beeline
Di terminal node master, mulai alat command-line Beeline dengan pengguna
sara.beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice sara user-password"Meskipun alat command-line Beeline tidak menerapkan sandi, Anda harus memberikan sandi untuk menjalankan perintah sebelumnya.
Jalankan kueri berikut untuk memverifikasi bahwa Ranger memblokirnya.
SELECT * FROM transactions LIMIT 10;Kueri ini menyertakan kolom
transactionAmount, yang izin pilihnya tidak dimiliki olehsara.Error
Permission deniedditampilkan.Verifikasi bahwa Ranger mengizinkan kueri berikut:
SELECT submissionDate, transactionType FROM transactions LIMIT 10;Keluar dari alat command-line Beeline:
!quitKeluar dari terminal:
exitDi konsol Ranger, klik tab Audit. Peristiwa yang ditolak dan diizinkan akan ditampilkan. Anda dapat memfilter peristiwa berdasarkan nama layanan yang telah Anda tetapkan sebelumnya, misalnya,
ranger-hive-service-01.
Menghubungkan dari alat BI
Langkah terakhir dalam tutorial ini adalah melakukan kueri data Hive dari Tableau Desktop.
Membuat aturan firewall
- Salin dan simpan alamat IP publik Anda.
Di Cloud Shell, buat aturan firewall yang membuka port TCP
8443untuk masuk dari workstation Anda:gcloud compute firewall-rules create allow-knox\ --project=${PROJECT_ID} --direction=INGRESS --priority=1000 \ --network=default --action=ALLOW --rules=tcp:8443 \ --target-tags=knox-gateway \ --source-ranges=<your-public-ip> /32Ganti placeholder
<your-public-ip>dengan alamat IP publik Anda.Terapkan tag network dari aturan firewall untuk node master proxy cluster:
gcloud compute instances add-tags ${PROXY_CLUSTER}-m --zone=${ZONE} \ --tags=knox-gateway
Membuat tunnel SSH
Prosedur ini hanya diperlukan jika Anda menggunakan sertifikat yang ditandatangani sendiri
yang valid untuk localhost. Jika menggunakan sertifikat sendiri, atau node master
proxy memiliki nama DNS eksternal sendiri, Anda dapat langsung menuju ke Hubungkan ke Hive.
Di Cloud Shell, buat perintah untuk membuat tunnel:
echo "gcloud compute ssh ${PROXY_CLUSTER}-m \ --project ${PROJECT_ID} \ --zone ${ZONE} \ -- -L 8443:localhost:8443"Jalankan
gcloud inituntuk mengautentikasi dan memberikan akun pengguna Anda izin akses.Buka terminal di workstation Anda.
Buat tunnel SSH untuk meneruskan port
8443. Salin perintah yang dibuat di langkah pertama dan tempelkan ke terminal workstation, lalu jalankan perintahnya.Biarkan terminal tetap terbuka sehingga tunnel tetap aktif.
Hubungkan ke Hive
- Di workstation Anda, instal driver Hive ODBC.
- Buka Tableau Desktop, atau mulai ulang jika sudah terbuka.
- Di halaman beranda, pada bagian Hubungkan / Ke Server, pilih Lainnya.
- Telusuri, lalu pilih Cloudera Hadoop.
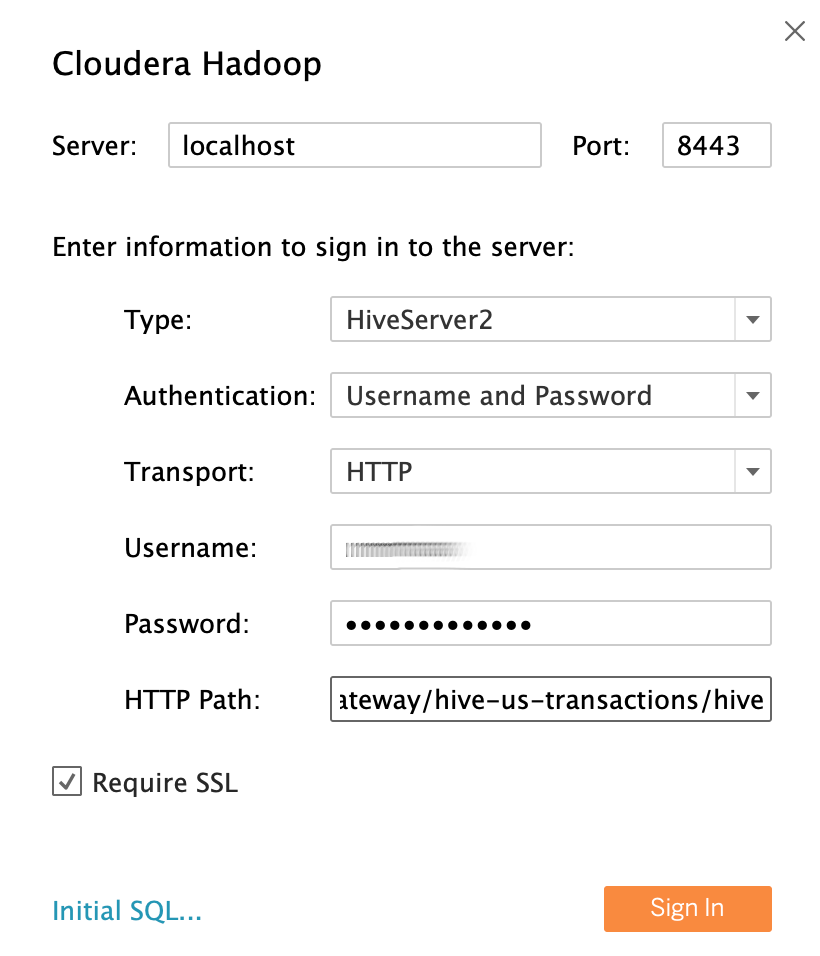
Dengan menggunakan contoh pengguna LDAP analis data
sarasebagai identitas pengguna, isi kolom sebagai berikut:- Server: Jika Anda membuat tunnel, gunakan
localhost. Jika Anda tidak membuat tunnel, gunakan nama DNS eksternal node master proxy Anda. - Port:
8443 - Jenis:
HiveServer2 - Autentikasi:
UsernamedanPassword - Nama pengguna:
sara - Sandi:
sara-password - Jalur HTTP:
gateway/hive-us-transactions/hive - Membutuhkan SSL:
yes
- Server: Jika Anda membuat tunnel, gunakan
Klik Login.
Data Hive kueri
- Di layar Sumber Data, klik Pilih Skema, lalu telusuri
default. Klik dua kali nama skema
default.Panel Tabel dimuat.
Di panel Tabel, klik dua kali SQL Kustom Baru.
Jendela Edit SQL Kustom terbuka.
Masukkan kueri berikut, yang memilih tanggal dan tipe transaksi dari tabel transaksi:
SELECT `submissiondate`, `transactiontype` FROM `default`.`transactions`Klik Oke.
Metadata untuk kueri diambil dari Hive.
Klik Update Sekarang.
Tableau mengambil data dari Hive karena
saradiberi otorisasi untuk membaca dua kolom ini dari tabeltransactions.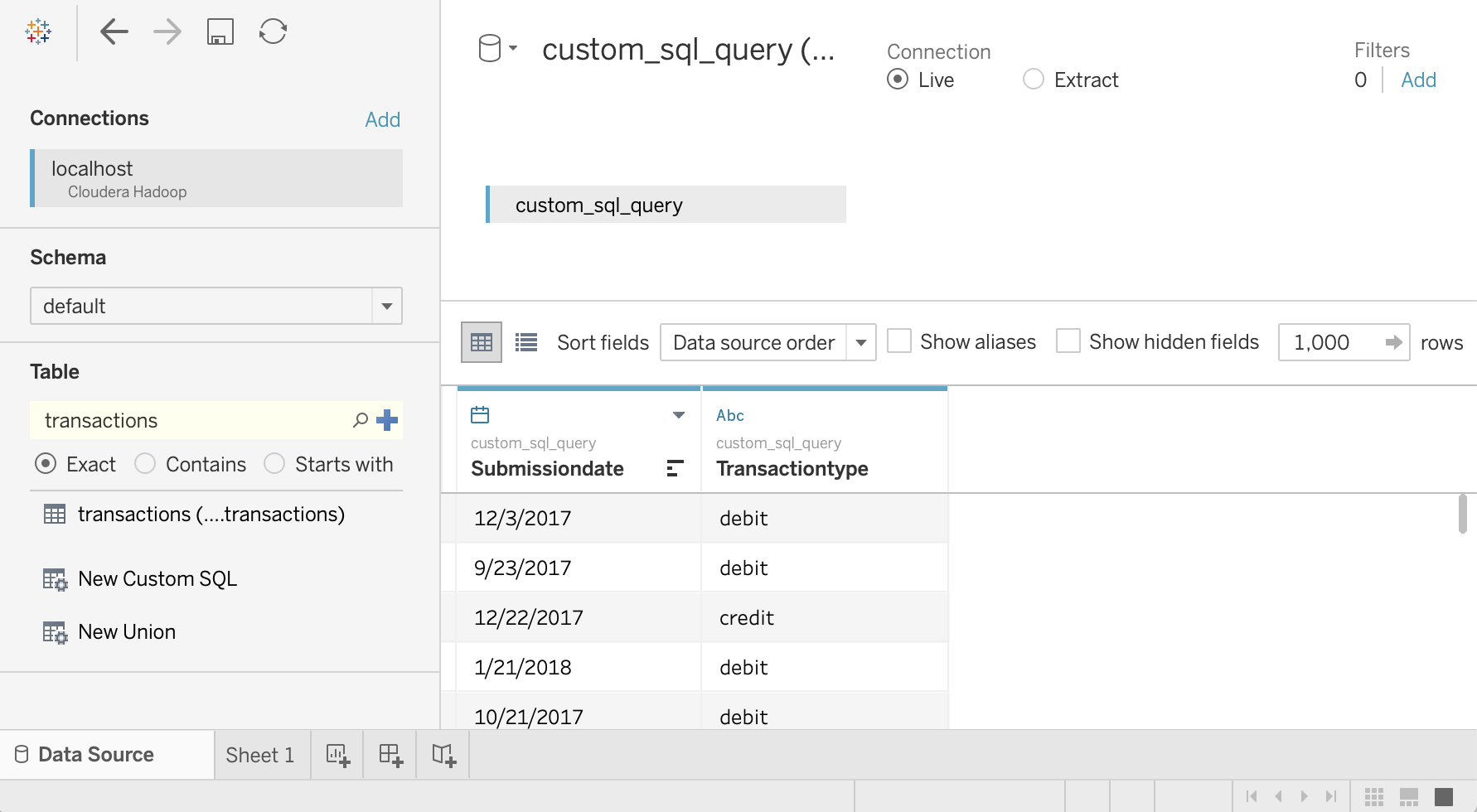
Untuk mencoba memilih semua kolom dari tabel
transactions, klik dua kali lagi SQL Kustom Baru pada panel Tabel. Jendela Edit SQL Kustom akan terbuka.Masukkan kueri berikut:
SELECT * FROM `default`.`transactions`Klik Oke. Pesan error berikut akan muncul:
Permission denied: user [sara] does not have [SELECT] privilege on [default/transactions/*].Karena
saratidak memiliki otorisasi dari Ranger untuk membaca kolomtransactionAmount, pesan ini sudah diantisipasi. Contoh ini menunjukkan bagaimana Anda dapat membatasi data apa saja yang dapat diakses pengguna Tableau.Untuk melihat semua kolom, ulangi langkah-langkah menggunakan pengguna
admin.Tutup Tableau dan jendela terminal Anda.
Pembersihan
Agar tidak perlu membayar biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
Menghapus project
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Langkah berikutnya
- Baca bagian pertama seri ini: Arsitektur untuk menghubungkan Software Visualisasi Anda ke Hadoop di Google Cloud.
- Baca Panduan Keamanan migrasi Hadoop.
- Pelajari cara memigrasikan infrastruktur Hadoop lokal ke Google Cloud.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.