Diese Anleitung ist der zweite Teil einer Reihe, in der erläutert wird, wie Sie eine End-to-End-Lösung erstellen, damit Sie Datenanalysten bei Verwendung von Business Intelligence-Tools (BI) sicheren Zugriff auf Daten gewähren.
Diese Anleitung richtet sich an Operatoren und IT-Administratoren, die Umgebungen einrichten, welche von Datenanalysten verwendete Daten- und Verarbeitungsfunktionen für die BI-Tools (Business Intelligence) bereitstellen.
Tableau wird in dieser Anleitung als BI-Tool verwendet. Damit Sie mit dieser Anleitung arbeiten können, muss Tableau Desktop auf Ihrer Workstation installiert sein.
Die Reihe besteht aus folgenden Teilen:
- Im ersten Teil der Reihe Architektur zum Verbinden der Visualisierungssoftware mit Hadoop in Google Cloud wird die Architektur der Lösung, die zugehörigen Komponenten und die Interaktion der Komponenten definiert.
- In diesem zweiten Teil der Reihe erfahren Sie, wie Sie die Architekturkomponenten einrichten, aus denen die durchgängige Hive-Topologie in Google Cloudbesteht. In dieser Anleitung werden Open-Source-Tools aus dem Hadoop-System mit Tableau als BI-Tool verwendet.
Die Code-Snippets in dieser Anleitung sind in einem GitHub-Repository verfügbar. Das GitHub-Repository enthält auch Terraform-Konfigurationsdateien, mit denen Sie einen funktionierenden Prototyp einrichten können.
In der gesamten Anleitung verwenden Sie den Namen sara als fiktive Nutzeridentität eines Datenanalysten. Diese Nutzeridentität befindet sich im LDAP-Verzeichnis, das Apache Knox und Apache Ranger verwendet. Sie können auch LDAP-Gruppen konfigurieren. Dieser Vorgang wird in dieser Anleitung jedoch nicht behandelt.
Ziele
- Erstellen Sie eine End-to-End-Einrichtung, die einem BI-Tool ermöglicht, Daten aus einer Hadoop-Umgebung zu verwenden.
- Authentifizieren und autorisieren Sie Nutzeranfragen.
- Richten Sie sichere Kommunikationskanäle zwischen dem BI-Tool und dem Cluster ein und verwenden Sie diese.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Vorbereitung
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) APIs.
Umgebung initialisieren
-
In the Google Cloud console, activate Cloud Shell.
Legen Sie in Cloud Shell Umgebungsvariablen mit Ihrer Projekt-ID sowie der Region und den Zonen der Dataproc-Cluster fest:
export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bSie können eine beliebige Region und Zone auswählen, aber diese sollten bei Befolgen dieser Anleitung konsistent bleiben.
Dienstkonto einrichten
Erstellen Sie in Cloud Shell ein Dienstkonto:
gcloud iam service-accounts create cluster-service-account \ --description="The service account for the cluster to be authenticated as." \ --display-name="Cluster service account"Der Cluster verwendet dieses Konto, um auf Google Cloud -Ressourcen zuzugreifen.
Fügen Sie dem Dienstkonto die folgenden Rollen hinzu:
- Dataproc-Worker: Zum Erstellen und Verwalten von Dataproc-Clustern.
- Cloud SQL-Bearbeiter: Für Ranger zum Herstellen einer Verbindung zur Datenbank über Cloud SQL Proxy.
Cloud KMS CryptoKey-Entschlüsseler: Mit Cloud KMS verschlüsselte Passwörter entschlüsseln.
bash -c 'array=( dataproc.worker cloudsql.editor cloudkms.cryptoKeyDecrypter ) for i in "${array[@]}" do gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "serviceAccount:cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \ --role roles/$i done'
Back-End-Cluster erstellen
In diesem Abschnitt erstellen Sie den Back-End-Cluster, in dem sich Ranger befindet. Sie erstellen auch die Ranger-Datenbank, um die Richtlinienregeln zu speichern, und eine Beispieltabelle in Hive, um die Ranger-Richtlinien anzuwenden.
Ranger-Datenbankinstanz erstellen
Erstellen Sie eine MySQL-Instanz, um die Apache Ranger-Richtlinien zu speichern:
export CLOUD_SQL_NAME=cloudsql-mysql gcloud sql instances create ${CLOUD_SQL_NAME} \ --tier=db-n1-standard-1 --region=${REGION}Mit diesem Befehl wird eine Instanz namens
cloudsql-mysqlmit dem Maschinentypdb-n1-standard-1in der Region erstellt, die durch die Variable${REGION}festgelegt ist. Weitere Informationen finden Sie in der Cloud SQL-Dokumentation.Legen Sie das Instanzpasswort für den Nutzer
rootfest, der eine Verbindung von einem beliebigen Host aus herstellt. Sie können das Beispielpasswort zu Demonstrationszwecken verwenden oder Ihr eigenes Passwort erstellen. Wenn Sie ein eigenes Passwort erstellen, verwenden Sie mindestens acht Zeichen, darunter wenigstens einen Buchstaben und eine Zahl.gcloud sql users set-password root \ --host=% --instance ${CLOUD_SQL_NAME} --password mysql-root-password-99
Passwörter verschlüsseln
In diesem Abschnitt erstellen Sie einen kryptografischen Schlüssel zum Verschlüsseln der Passwörter für Ranger und MySQL. Zur Vermeidung einer Exfiltration speichern Sie den kryptografischen Schlüssel in Cloud KMS. Aus Sicherheitsgründen können Sie die Schlüsselbits nicht anzeigen, extrahieren oder exportieren.
Mit einem kryptografischen Schlüssel können Sie die Passwörter verschlüsseln und in Dateien schreiben.
Sie laden diese Dateien in einen Cloud Storage-Bucket hoch, sodass sie für das Dienstkonto zugänglich sind, das im Namen der Cluster agiert.
Das Dienstkonto kann diese Dateien entschlüsseln, da es die Rolle cloudkms.cryptoKeyDecrypter und den Zugriff auf die Dateien und den kryptografischen Schlüssel hat. Selbst wenn eine Datei exfiltriert ist, kann die Datei ohne die Rolle und den Schlüssel nicht entschlüsselt werden.
Als zusätzliche Sicherheitsmaßnahme erstellen Sie für jeden Dienst separate Passwortdateien. Durch diese Maßnahme wird der potenziell betroffene Bereich minimiert, wenn ein Passwort exfiltriert wird.
Weitere Informationen zur Schlüsselverwaltung finden Sie in der Cloud KMS-Dokumentation.
Erstellen Sie in Cloud Shell einen Cloud KMS-Schlüsselbund, der Ihre Schlüssel enthält:
gcloud kms keyrings create my-keyring --location globalErstellen Sie zum Verschlüsseln Ihrer Passwörter einen kryptografischen Cloud KMS-Schlüssel:
gcloud kms keys create my-key \ --location global \ --keyring my-keyring \ --purpose encryptionVerschlüsseln Sie das Passwort für Ihren Ranger-Administrator mit dem Schlüssel. Sie können das Beispielpasswort verwenden oder ein eigenes erstellen. Ihr Passwort muss mindestens acht Zeichen lang sein, darunter wenigstens einen Buchstaben und eine Zahl.
echo "ranger-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-admin-password.encryptedVerschlüsseln Sie das Administratorpasswort für Ihre Ranger-Datenbank mit dem folgenden Schlüssel:
echo "ranger-db-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-db-admin-password.encryptedVerschlüsseln Sie Ihr MySQL-Root-Passwort mit dem Schlüssel:
echo "mysql-root-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=mysql-root-password.encryptedErstellen Sie einen Cloud Storage-Bucket zum Speichern verschlüsselter Passwortdateien:
gcloud storage buckets create gs://${PROJECT_ID}-ranger --location=${REGION}Laden Sie die verschlüsselten Passwortdateien in den Cloud Storage-Bucket hoch:
gcloud storage cp *.encrypted gs://${PROJECT_ID}-ranger
Cluster erstellen
In diesem Abschnitt erstellen Sie einen Back-End-Cluster mit Unterstützung für Ranger. Weitere Informationen zur optionalen Komponente „Ranger“ in Dataproc finden Sie auf der Dokumentationsseite zu Dataproc Ranger.
Erstellen Sie in Cloud Shell einen Cloud Storage-Bucket zum Speichern der Apache Solr-Audit-Logs:
gcloud storage buckets create gs://${PROJECT_ID}-solr --location=${REGION}Exportieren Sie alle Variablen, die zum Erstellen des Clusters erforderlich sind:
export BACKEND_CLUSTER=backend-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b export CLOUD_SQL_NAME=cloudsql-mysql export RANGER_KMS_KEY_URI=\ projects/${PROJECT_ID}/locations/global/keyRings/my-keyring/cryptoKeys/my-key export RANGER_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-admin-password.encrypted export RANGER_DB_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-db-admin-password.encrypted export MYSQL_ROOT_PWD_URI=\ gs://${PROJECT_ID}-ranger/mysql-root-password.encryptedDer Einfachheit halber werden einige der zuvor festgelegten Variablen in diesem Befehl wiederholt, sodass Sie sie nach Bedarf ändern können.
Die neuen Variablen enthalten:
- Den Namen des Back-End-Clusters.
- Den URI des kryptografischen Schlüssels, sodass das Dienstkonto die Passwörter entschlüsseln kann
- Den URI der Dateien mit den verschlüsselten Passwörtern.
Wenn Sie einen anderen Schlüsselbund oder Schlüssel oder andere Dateinamen genutzt haben, verwenden Sie die entsprechenden Werte in Ihrem Befehl.
Erstellen Sie den Back-End-Dataproc-Cluster:
gcloud beta dataproc clusters create ${BACKEND_CLUSTER} \ --optional-components=SOLR,RANGER \ --region ${REGION} \ --zone ${ZONE} \ --enable-component-gateway \ --scopes=default,sql-admin \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --properties="\ dataproc:ranger.kms.key.uri=${RANGER_KMS_KEY_URI},\ dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PWD_URI},\ dataproc:ranger.db.admin.password.uri=${RANGER_DB_ADMIN_PWD_URI},\ dataproc:ranger.cloud-sql.instance.connection.name=${PROJECT_ID}:${REGION}:${CLOUD_SQL_NAME},\ dataproc:ranger.cloud-sql.root.password.uri=${MYSQL_ROOT_PWD_URI},\ dataproc:solr.gcs.path=gs://${PROJECT_ID}-solr,\ hive:hive.server2.thrift.http.port=10000,\ hive:hive.server2.thrift.http.path=cliservice,\ hive:hive.server2.transport.mode=http"Dieser Befehl hat folgende Attribute:
- Die letzten drei Zeilen des Befehls sind die Hive-Attribute zum Konfigurieren von HiveServer2 im HTTP-Modus, damit Apache Knox Apache über HTTP aufrufen kann.
- Die anderen Parameter im Befehl funktionieren so:
- Der Parameter
--optional-components=SOLR,RANGERaktiviert Apache Ranger und seine Solr-Abhängigkeit. - Mit dem Parameter
--enable-component-gatewaykann das Dataproc Component Gateway direkt auf der Clusterseite in der Google Cloud Console den Ranger und andere Hadoop-Benutzeroberflächen bereitstellen. Wenn Sie diesen Parameter festlegen, ist keine SSH-Tunnel-Authentifizierung zum Backend-Master-Knoten erforderlich. - Der Parameter
--scopes=default,sql-adminautorisiert Apache Ranger für den Zugriff auf seine Cloud SQL-Datenbank.
- Der Parameter
Wenn Sie einen externen Hive-Metaspeicher erstellen müssen, der über die Lebensdauer eines Clusters hinausgeht und in mehreren Clustern verwendet werden kann, finden Sie weitere Informationen unter Apache Hive in Dataproc verwenden.
Für die Ausführung müssen Sie die Beispiele für die Tabellenerstellung direkt in Beeline ausführen. Während die gcloud dataproc jobs submit hive-Befehle die Hive-Transportübertragung verwenden, sind diese Befehle nicht mit HiveServer2 kompatibel, wenn sie im HTTP-Modus konfiguriert sind.
Hive-Beispieltabelle erstellen
Erstellen Sie in Cloud Shell einen Cloud Storage-Bucket zum Speichern einer Apache Parquet-Beispieldatei:
gcloud buckets create gs://${PROJECT_ID}-hive --location=${REGION}Kopieren Sie eine öffentlich verfügbare Parquet-Beispieldatei in Ihren Bucket:
gcloud storage cp gs://hive-solution/part-00000.parquet \ gs://${PROJECT_ID}-hive/dataset/transactions/part-00000.parquetStellen Sie mit SSH eine Verbindung zum Masterknoten des Back-End-Clusters her, den Sie im vorherigen Abschnitt erstellt haben:
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mDer Name des Clustermasterknotens ist der Name des Clusters, gefolgt von
-m.. Die Namen des HA-Clustermasterknotens haben ein zusätzliches Suffix.Wenn Sie zum ersten Mal über Cloud Shell eine Verbindung zum Masterknoten herstellen, werden Sie aufgefordert, SSH-Schlüssel zu generieren.
Stellen Sie in dem über SSH geöffneten Terminal eine Verbindung zum lokalen HiveServer2 mit Apache Beeline her, das auf dem Masterknoten vorinstalliert ist:
beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice admin admin-password"\ --hivevar PROJECT_ID=$(gcloud info --format='value(config.project)')Dieser Befehl startet das Beeline-Befehlszeilentool und übergibt den Namen Ihres Google Cloud-Projekts in einer Umgebungsvariablen.
Hive führt keine Nutzerauthentifizierung durch, für die meisten Aufgaben ist jedoch eine Nutzeridentität erforderlich. Der
admin-Nutzer ist hier ein Standardnutzer, der in Hive konfiguriert ist. Der Identitätsanbieter, den Sie später in dieser Anleitung mit Apache Knox konfigurieren, übernimmt die Nutzerauthentifizierung für alle Anfragen, die von BI-Tools stammen.Erstellen Sie in der Beeline-Eingabeaufforderung eine Tabelle mit der Parquet-Datei, die Sie zuvor in Ihren Hive-Bucket kopiert haben:
CREATE EXTERNAL TABLE transactions (SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) STORED AS PARQUET LOCATION 'gs://${PROJECT_ID}-hive/dataset/transactions';Prüfen Sie, ob die Tabelle korrekt erstellt wurde.
SELECT * FROM transactions LIMIT 10; SELECT TransactionType, AVG(TransactionAmount) AS AverageAmount FROM transactions WHERE SubmissionDate = '2017-12-22' GROUP BY TransactionType;Die Ergebnisse dieser beiden Abfragen werden in der Beeline-Eingabeaufforderung angezeigt.
Beenden Sie das Beeline-Befehlszeilentool:
!quitKopieren Sie den internen DNS-Namen des Back-End-Masters:
hostname -A | tr -d '[:space:]'; echoSie verwenden diesen Namen im nächsten Abschnitt als
backend-master-internal-dns-name, um die Apache Knox-Topologie zu konfigurieren. Sie verwenden den Namen auch, um einen Dienst in Ranger zu konfigurieren.Beenden Sie das Terminal auf dem Knoten:
exit
Proxycluster erstellen
In diesem Abschnitt erstellen Sie den Proxycluster mit der Apache Knox-Initialisierungsaktion.
Topologie erstellen
Klonen Sie in Cloud Shell das Dataproc-GitHub-Repository initialization-actions:
git clone https://github.com/GoogleCloudDataproc/initialization-actions.gitErstellen Sie eine Topologie für den Back-End-Cluster:
export KNOX_INIT_FOLDER=`pwd`/initialization-actions/knox cd ${KNOX_INIT_FOLDER}/topologies/ mv example-hive-nonpii.xml hive-us-transactions.xmlApache Knox verwendet den Namen der Datei als URL-Pfad für die Topologie. In diesem Schritt ändern Sie den Namen für die Topologie
hive-us-transactions. Sie können dann auf die fiktiven Transaktionsdaten zugreifen, die Sie in Hive unter Beispiel-Hive-Tabelle erstellen geladen haben.Bearbeiten Sie die Topologiedatei:
vi hive-us-transactions.xmlInformationen zur Konfiguration von Backend-Diensten finden Sie in der Datei Topologie-Schlagwort. Diese Datei definiert eine Topologie, die auf einen oder mehrere Back-End-Dienste verweist. Zwei Dienste werden mit Beispielwerten konfiguriert: WebHDFS und HIVE. Die Datei definiert auch den Authentifizierungsanbieter für die Dienste in dieser Topologie und die Autorisierungs-ACLs.
Fügen Sie die LDAP-Nutzeridentität
sarazum Datenanalystenbeispiel hinzu.<param> <name>hive.acl</name> <value>admin,sara;*;*</value> </param>Wenn Sie die Beispielidentität hinzufügen, kann der Nutzer über Apache Knox auf den Hive-Back-End-Dienst zugreifen.
Ändern Sie die HIVE-URL, sodass sie auf den Hive-Dienst des Back-End-Clusters verweist. Sie finden die Definition des HIVE-Dienstes unten in der Datei unter „WebHDFS”.
<service> <role>HIVE</role> <url>http://<backend-master-internal-dns-name>:10000/cliservice</url> </service>Ersetzen Sie den Platzhalter
<backend-master-internal-dns-name>durch den internen DNS-Namen des Back-End-Clusters, den Sie unter Hive-Beispieltabelle erstellen erhalten haben.Speichern Sie die Datei und schließen Sie den Editor.
Wiederholen Sie die Schritte in diesem Abschnitt, um weitere Topologien zu erstellen. Erstellen Sie einen unabhängigen XML-Deskriptor für jede Topologie.
Kopieren Sie diese Dateien unter Proxycluster erstellen in einen Cloud Storage-Bucket. Sie können neue Topologien erstellen oder sie nach dem Erstellen des Proxy-Clusters ändern. Ändern Sie die Dateien dazu und laden Sie sie wieder in den Bucket hoch. Die Apache Knox-Initialisierungsaktion erstellt einen Cronjob, der regelmäßig Änderungen aus dem Bucket in den Proxy-Cluster kopiert.
SSL/TLS-Zertifikat konfigurieren
Ein Client verwendet ein SSL/TLS-Zertifikat, wenn er mit Apache Knox kommuniziert. Die Initialisierungsaktion kann ein selbst signiertes Zertifikat generieren oder Sie Ihr von einer Zertifizierungsstelle signiertes Zertifikat bereitstellen.
Bearbeiten Sie in Cloud Shell die allgemeine Konfigurationsdatei für Apache Knox:
vi ${KNOX_INIT_FOLDER}/knox-config.yamlErsetzen Sie
HOSTNAMEdurch den externen DNS-Namen Ihres Proxy-Masterknotens als Wert für das Attributcertificate_hostname. Verwenden Sie für diese Anleitunglocalhost:certificate_hostname: localhostSpäter in dieser Anleitung erstellen Sie einen SSH-Tunnel und den Proxcluster für den Wert
localhost.Die allgemeine Konfigurationsdatei für Apache Knox enthält außerdem den
master_key, mit dem die BI-Tools verschlüsselt werden, die für die Kommunikation mit dem Proxycluster verwendet werden. Standardmäßig ist dieser Schlüssel das Wortsecret.Ändern Sie bei der Bereitstellung eines eigenen Zertifikats die beiden folgenden Attribute:
generate_cert: false custom_cert_name: <filename-of-your-custom-certificate>Speichern Sie die Datei und schließen Sie den Editor.
Wenn Sie ein eigenes Zertifikat bereitstellen, können Sie es im Attribut
custom_cert_nameangeben.
Erstellen Sie den Proxycluster
Erstellen Sie in Cloud Shell einen Cloud Storage-Bucket.
gcloud storage buckets create gs://${PROJECT_ID}-knox --location=${REGION}Dieser Bucket stellt die Konfigurationen, die Sie im vorherigen Abschnitt erstellt haben, für die Apache Knox-Initialisierungsaktion bereit.
Kopieren Sie alle Dateien aus dem Apache Knox-Initialisierungsaktionsordner in den Bucket:
gcloud storage cp ${KNOX_INIT_FOLDER}/* gs://${PROJECT_ID}-knox --recursiveExportieren Sie alle Variablen, die zum Erstellen des Clusters erforderlich sind:
export PROXY_CLUSTER=proxy-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bIn diesem Schritt werden einige der Variablen, die Sie zuvor festgelegt haben, wiederholt, damit Sie nach Bedarf Änderungen vornehmen können.
Erstellen Sie den Proxycluster:
gcloud dataproc clusters create ${PROXY_CLUSTER} \ --region ${REGION} \ --zone ${ZONE} \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/knox/knox.sh \ --metadata knox-gw-config=gs://${PROJECT_ID}-knox
Verbindung über Proxy prüfen
Nachdem der Proxycluster erstellt wurde, stellen Sie in Cloud Shell eine SSH-Verbindung zu seinem Masterknoten her:
gcloud compute ssh --zone ${ZONE} ${PROXY_CLUSTER}-mFühren Sie vom Masterknotenterminal des Proxyclusters folgende Abfrage aus:
beeline -u "jdbc:hive2://localhost:8443/;\ ssl=true;sslTrustStore=/usr/lib/knox/data/security/keystores/gateway-client.jks;trustStorePassword=secret;\ transportMode=http;httpPath=gateway/hive-us-transactions/hive"\ -e "SELECT SubmissionDate, TransactionType FROM transactions LIMIT 10;"\ -n admin -p admin-password
Dieser Befehl hat folgende Attribute:
- Der Befehl
beelineverwendetlocalhostanstelle des internen DNS-Namens, da das Zertifikat, das Sie bei der Konfiguration von Apache Knox generiert haben,localhostals Hostnamen angibt. Wenn Sie einen eigenen DNS-Namen oder ein eigenes Zertifikat nutzen, verwenden Sie den entsprechenden Hostnamen. - Der Port ist
8443, der dem Standard-SSL-Port von Apache Knox entspricht. - In der Zeile, die mit
ssl=truebeginnt, wird SSL aktiviert. Außerdem werden der Pfad und das Passwort für den SSL Trust Store von Clientanwendungen wie Beeline bereitgestellt. - Die Zeile
transportModegibt an, dass die Anfrage über HTTP gesendet werden soll, und geben den Pfad für den HiveServer2-Dienst an. Der Pfad besteht aus dem Keywordgateway, dem in einem vorherigen Abschnitt definierten Topologienamen und dem Dienstnamen, der in derselben Topologie konfiguriert wurde, in diesem Fallhive. - Der Parameter
-estellt die Abfrage bereit, die auf Hive ausgeführt werden soll. Wenn Sie diesen Parameter weglassen, öffnen Sie eine interaktive Sitzung im Beeline-Befehlszeilentool. - Der Parameter
-ngibt eine Nutzeridentität und ein Passwort an. In diesem Schritt verwenden Sie den Hive-admin-Standardnutzer. In den nächsten Abschnitten erstellen Sie eine Analyst-Nutzeridentität und richten Anmeldedaten und Autorisierungsrichtlinien für diesen Nutzer ein.
Einen Nutzer zum Authentifizierungsspeicher hinzufügen
Apache Knox enthält standardmäßig einen Authentifizierungsanbieter, der auf Apache Shiro basiert.
Dieser Authentifizierungsanbieter ist mit einer BASIC-Authentifizierung für einen LDAP-Speicher von ApacheDS konfiguriert. In diesem Abschnitt fügen Sie dem Authentifizierungsspeicher eine Beispielnutzer-Nutzeridentität sara hinzu.
Installieren Sie über das Terminal im Masterknoten des Proxys die LDAP-Dienstprogramme:
sudo apt-get install ldap-utilsErstellen Sie eine LDIF-Datei (LDAP Data Interchange Format) für den neuen Nutzer
sara:export USER_ID=sara printf '%s\n'\ "# entry for user ${USER_ID}"\ "dn: uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org"\ "objectclass:top"\ "objectclass:person"\ "objectclass:organizationalPerson"\ "objectclass:inetOrgPerson"\ "cn: ${USER_ID}"\ "sn: ${USER_ID}"\ "uid: ${USER_ID}"\ "userPassword:${USER_ID}-password"\ > new-user.ldifFügen Sie dem LDAP-Verzeichnis die Nutzer-ID hinzu:
ldapadd -f new-user.ldif \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389Der Parameter
-Dgibt den Distinguished Name (DN) an, der gebunden werden soll, wenn der Nutzer, der durchldapadddargestellt wird, auf das Verzeichnis zugreift. Der DN muss eine Nutzeridentität sein, die sich bereits im Verzeichnis befindet, in diesem Fall der Nutzeradmin.Prüfen Sie, ob sich der neue Nutzer im Authentifizierungsspeicher befindet:
ldapsearch -b "uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org" \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389Die Nutzerdetails werden im Terminal angezeigt.
Kopieren und speichern Sie den internen DNS-Namen des Proxy-Masterknotens:
hostname -A | tr -d '[:space:]'; echoVerwenden Sie diesen Namen im nächsten Abschnitt als
<proxy-master-internal-dns-name>, um die LDAP-Synchronisierung zu konfigurieren.Beenden Sie das Terminal auf dem Knoten:
exit
Autorisierung einrichten
In diesem Abschnitt konfigurieren Sie die Identitätssynchronisierung zwischen dem LDAP-Dienst und Ranger.
Nutzeridentitäten in Ranger synchronisieren
Damit Ranger-Richtlinien für dieselben Nutzeridentitäten wie Apache Knox gelten, müssen Sie den Ranger UserSync-Daemon so konfigurieren, dass die Identitäten aus demselben Verzeichnis synchronisiert werden.
In diesem Beispiel stellen Sie eine Verbindung zum lokalen LDAP-Verzeichnis her, das standardmäßig mit Apache Knox verfügbar ist. In einer Produktionsumgebung empfehlen wir jedoch, ein externes Identitätsverzeichnis einzurichten. Weitere Informationen finden Sie im Apache Knox-Nutzerhandbuch und in der Dokumentation zu Google Cloud Cloud Identity, Managed Active Directory und Federated AD.
Stellen Sie mit SSH eine Verbindung zum Masterknoten des von Ihnen erstellten Back-End-Clusters her:
export BACKEND_CLUSTER=backend-cluster gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mBearbeiten Sie im Terminal die Konfigurationsdatei
UserSync:sudo vi /etc/ranger/usersync/conf/ranger-ugsync-site.xmlLegen Sie die Werte der folgenden LDAP-Attribute fest. Ändern Sie die Attribute
userund nicht diegroup-Properties, die ähnliche Namen haben.<property> <name>ranger.usersync.sync.source</name> <value>ldap</value> </property> <property> <name>ranger.usersync.ldap.url</name> <value>ldap://<proxy-master-internal-dns-name>:33389</value> </property> <property> <name>ranger.usersync.ldap.binddn</name> <value>uid=admin,ou=people,dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.ldap.ldapbindpassword</name> <value>admin-password</value> </property> <property> <name>ranger.usersync.ldap.user.searchbase</name> <value>dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.source.impl.class</name> <value>org.apache.ranger.ldapusersync.process.LdapUserGroupBuilder</value> </property>Ersetzen Sie den Platzhalter
<proxy-master-internal-dns-name>durch den internen DNS-Namen des Proxyservers, den Sie im letzten Abschnitt abgerufen haben.Diese Attribute sind eine Teilmenge einer vollständigen LDAP-Konfiguration, mit der Nutzer und Gruppen synchronisiert werden. Weitere Informationen finden Sie unter Ranger in LDAP integrieren.
Speichern Sie die Datei und schließen Sie den Editor.
Starten Sie den Daemon
ranger-usersyncneu:sudo service ranger-usersync restartFühren Sie dazu diesen Befehl aus:
grep sara /var/log/ranger-usersync/*Wenn die Identitäten synchronisiert wurden, wird für den Nutzer
saramindestens eine Logzeile angezeigt.
Ranger-Richtlinien erstellen
In diesem Abschnitt konfigurieren Sie einen neuen Hive-Dienst in Ranger. Außerdem richten Sie eine Ranger-Richtlinie ein und testen sie, um den Zugriff auf die Hive-Daten für eine bestimmte Identität zu beschränken.
Ranger-Dienst konfigurieren
Bearbeiten Sie im Terminal des Masterknotens die Ranger-Hive-Konfiguration:
sudo vi /etc/hive/conf/ranger-hive-security.xmlBearbeiten Sie das Attribut
<value>des Attributsranger.plugin.hive.service.name:<property> <name>ranger.plugin.hive.service.name</name> <value>ranger-hive-service-01</value> <description> Name of the Ranger service containing policies for this YARN instance </description> </property>Speichern Sie die Datei und schließen Sie den Editor.
Starten Sie den HiveServer2-Administratordienst neu:
sudo service hive-server2 restartSie können jetzt Ranger-Richtlinien erstellen.
Dienst in der Ranger-Admin-Konsole einrichten
Öffnen Sie in der Google Cloud Console die Seite Dataproc.
Klicken Sie auf den Namen des Backend-Clusters und dann auf Weboberflächen.
Da Sie Ihren Cluster mit Component Gateway erstellt haben, sehen Sie eine Liste der Hadoop-Komponenten, die in Ihrem Cluster installiert sind.
Klicken Sie auf den Link Ranger, um die Ranger-Konsole zu öffnen.
Melden Sie sich mit dem Nutzer
adminund Ihrem Ranger-Administratorpasswort in Ranger an. Die Ranger-Konsole zeigt die Service Manager-Seite mit einer Liste der Dienste an.Klicken Sie auf das Pluszeichen in der HIVE-Gruppe, um einen neuen Hive-Dienst zu erstellen.

Legen Sie im Formular die folgenden Werte fest:
- Dienstname:
ranger-hive-service-01. Sie haben diesen Namen zuvor in der Konfigurationsdateiranger-hive-security.xmldefiniert. - Nutzername:
admin - Passwort:
admin-password jdbc.driverClassName: Behalten Sie den Standardnamenorg.apache.hive.jdbc.HiveDriverbeijdbc.url:jdbc:hive2:<backend-master-internal-dns-name>:10000/;transportMode=http;httpPath=cliservice- Ersetzen Sie den Platzhalter
<backend-master-internal-dns-name>durch den Namen, den Sie in einem vorherigen Abschnitt abgerufen haben.
- Dienstname:
Klicken Sie auf Hinzufügen.
Jede Installation des Ranger-Plug-ins unterstützt einen einzelnen Hive-Dienst. Eine einfache Möglichkeit, zusätzliche Hive-Dienste zu konfigurieren, ist das Starten zusätzlicher Back-End-Cluster. Jeder Cluster hat ein eigenes Ranger-Plug-in. Diese Cluster können dieselbe Ranger-DB nutzen, sodass Sie eine einheitliche Ansicht aller Dienste haben, wenn Sie von einem dieser Cluster aus auf die Ranger Admin-Konsole zugreifen.
Ranger-Richtlinie mit eingeschränkten Berechtigungen einrichten
Die Richtlinie ermöglicht dem Beispielanalysten-LDAP-Nutzer sara-Zugriff auf bestimmte Spalten der Hive-Tabelle.
Klicken Sie im Fenster „Service Manager” auf den Namen des Dienstes, den Sie erstellt haben.
Die Ranger-Admin-Konsole zeigt das Fenster Richtlinien an.
Klicken Sie auf Neue Richtlinie hinzufügen.
Mit dieser Richtlinie erteilen Sie
saradie Berechtigung, nur die SpaltensubmissionDateundtransactionTypeaus Tabellentransaktionen aufzurufen.Legen Sie im Formular die folgenden Werte fest:
- Richtlinienname: Beliebiger Name, z. B.
allow-tx-columns - Datenbank:
default - Tabelle:
transactions - Hive-Spalte:
submissionDate, transactionType - Bedingungen zulassen:
- Nutzer auswählen:
sara - Berechtigungen:
select
- Nutzer auswählen:
- Richtlinienname: Beliebiger Name, z. B.
Klicken Sie am unteren Bildschirmrand auf Hinzufügen.
Richtlinie mit Beeline testen
Starten Sie im Masterknoten-Terminal das Beeline-Befehlszeilentool mit dem Nutzer
sara.beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice sara user-password"Obwohl das Beeline-Befehlszeilentool das Passwort nicht erzwingt, müssen Sie zum Ausführen des vorherigen Befehls ein Passwort angeben.
Führen Sie die folgende Abfrage aus, um zu prüfen, ob Ranger sie blockiert.
SELECT * FROM transactions LIMIT 10;Die Abfrage enthält die Spalte
transactionAmount, für diesarakeine Berechtigung zur Auswahl hat.Ein
Permission denied-Fehler wird angezeigt.Prüfen Sie, ob Ranger die folgende Abfrage zulässt:
SELECT submissionDate, transactionType FROM transactions LIMIT 10;Beenden Sie das Beeline-Befehlszeilentool:
!quitBeenden Sie das Terminal:
exitKlicken Sie in der Ranger-Konsole auf den Tab Audit. Es werden sowohl abgelehnte als auch zugelassene Ereignisse angezeigt. Sie können die Ereignisse nach dem zuvor definierten Dienstnamen filtern, z. B.
ranger-hive-service-01.
Verbindung von einem BI-Tool herstellen
Im letzten Schritt in dieser Anleitung werden die Hive-Daten von Tableau Desktop abgefragt.
Firewallregel erstellen
- Kopieren und speichern Sie Ihre öffentliche IP-Adresse.
Erstellen Sie in Cloud Shell eine Firewallregel, die den TCP-Port
8443für eingehenden Traffic von Ihrer Workstation öffnet:gcloud compute firewall-rules create allow-knox\ --project=${PROJECT_ID} --direction=INGRESS --priority=1000 \ --network=default --action=ALLOW --rules=tcp:8443 \ --target-tags=knox-gateway \ --source-ranges=<your-public-ip>/32Ersetzen Sie den Platzhalter
<your-public-ip>durch Ihre öffentliche IP-Adresse.Wenden Sie das Netzwerk-Tag aus der Firewallregel auf den Masterknoten des Proxyclusters an:
gcloud compute instances add-tags ${PROXY_CLUSTER}-m --zone=${ZONE} \ --tags=knox-gateway
SSH-Tunnel erstellen
Dieser Vorgang ist nur erforderlich, wenn Sie ein selbst signiertes Zertifikat verwenden, das für localhost gültig ist. Wenn Sie ein eigenes Zertifikat verwenden oder der Proxy-Master-Knoten einen eigenen externen DNS-Namen hat, können Sie mit Mit Hive verbinden fortfahren.
Führen Sie in Cloud Shell den Befehl zum Erstellen des Tunnels aus:
echo "gcloud compute ssh ${PROXY_CLUSTER}-m \ --project ${PROJECT_ID} \ --zone ${ZONE} \ -- -L 8443:localhost:8443"Führen Sie
gcloud initaus, um Ihr Nutzerkonto zu authentifizieren und Zugriffsberechtigungen zu erteilen.Öffnen Sie ein Terminal auf der Workstation.
Erstellen Sie einen SSH-Tunnel zum Weiterleiten von Port
8443. Kopieren Sie den im ersten Schritt generierten Befehl, fügen Sie ihn in das Workstation-Terminal ein und führen Sie den Befehl aus.Lassen Sie das Terminal geöffnet, damit der Tunnel aktiv bleibt.
Mit Hive verbinden
- Installieren Sie auf Ihrer Workstation den Hive ODBC-Treiber.
- Öffnen Sie Tableau Desktop oder starten Sie es neu, falls es geöffnet war.
- Wählen Sie auf der Startseite unter Verbinden / Mit einem Server die Option Mehr aus.
- Suchen Sie Cloudera Hadoop und wählen Sie es aus.
Füllen Sie mit dem Beispiel-Datennalyst-LDAP-Nutzer
saraals Nutzeridentität die Felder so aus:- Server: Wenn Sie einen Tunnel erstellt haben, verwenden Sie
localhost. Wenn Sie keinen Tunnel erstellt haben, verwenden Sie den externen DNS-Namen Ihres Proxy-Masterknotens. - Port:
8443 - Typ:
HiveServer2 - Authentifizierung:
UsernameundPassword - Nutzername:
sara - Passwort:
sara-password - HTTP-Pfad:
gateway/hive-us-transactions/hive - SSL als erforderlich festlegen:
yes
- Server: Wenn Sie einen Tunnel erstellt haben, verwenden Sie
Klicken Sie auf Anmelden.

Hive-Daten abfragen
- Klicken Sie auf dem Bildschirm Datenquelle auf Schema auswählen und suchen Sie nach
default. Klicken Sie doppelt auf den Schemanamen
default.Der Bereich Tabelle wird geladen.
Doppelklicken Sie im Bereich Tabelle auf Neue benutzerdefinierte SQL.
Das Fenster Benutzerdefinierte SQL bearbeiten wird geöffnet.
Geben Sie die folgende Abfrage ein, um das Datum und den Transaktionstyp aus der Transaktionstabelle auszuwählen:
SELECT `submissiondate`, `transactiontype` FROM `default`.`transactions`Klicken Sie auf OK.
Die Metadaten für die Abfrage werden von Hive abgerufen.
Klicken Sie auf Jetzt aktualisieren.
Tableau ruft die Daten aus Hive ab, da
saraberechtigt ist, diese beiden Spalten aus der Tabelletransactionszu lesen.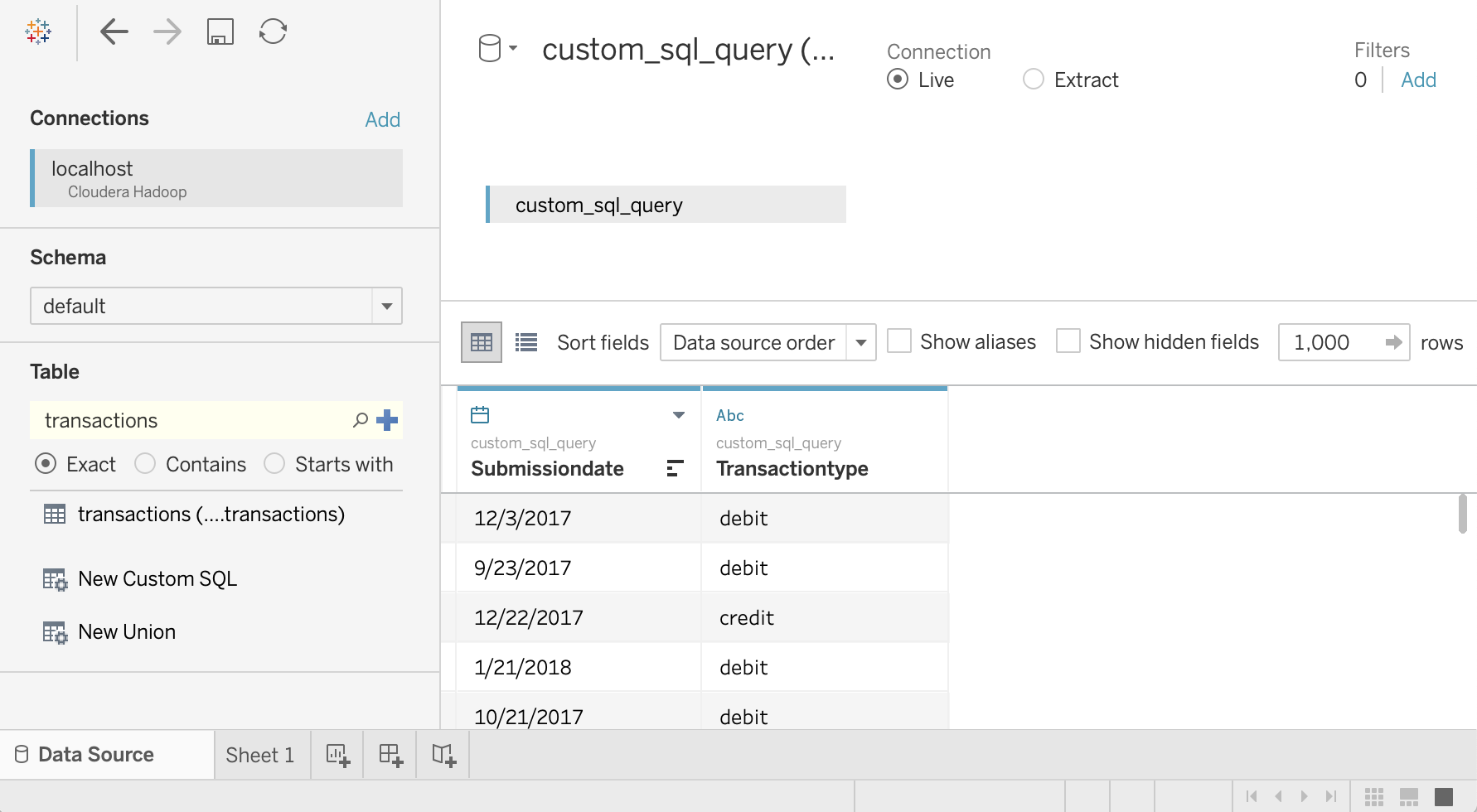
Klicken Sie im Feld Tabelle noch einmal auf Neue benutzerdefinierte SQL, um alle Spalten aus der Tabelle
transactionsauszuwählen. Das Fenster Benutzerdefinierte SQL bearbeiten wird geöffnet.Geben Sie die folgende Abfrage ein:
SELECT * FROM `default`.`transactions`Klicken Sie auf OK. Die folgende Fehlermeldung wird angezeigt:
Permission denied: user [sara] does not have [SELECT] privilege on [default/transactions/*].Da
sarakeine Autorisierung von Ranger zum Lesen der SpaltetransactionAmounthat, wird diese Nachricht erwartet. In diesem Beispiel wird gezeigt, wie Sie den Zugriff auf Daten von Tableau-Nutzern einschränken können.Wiederholen Sie die Schritte mit dem Nutzer
admin, um alle Spalten anzuzeigen.Schließen Sie Tableau und das Terminalfenster.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Lesen Sie den ersten Teil dieser Reihe: Architektur zum Verbinden Ihrer Visualisierungssoftware mit Hadoop in Google Cloud.
- Lesen Sie den Sicherheitsleitfaden für die Hadoop-Migration.
- Informationen zum Migrieren der lokalen Hadoop-Infrastruktur zu Google Cloud
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center