이 가이드는 비즈니스 인텔리전스(BI) 도구를 사용할 때 데이터 분석가가 데이터에 안전하게 액세스할 수 있는 엔드 투 엔드 솔루션을 빌드하는 방법을 설명하는 시리즈 중 두 번째 부분입니다.
이 가이드는 데이터 분석가가 사용하는 비즈니스 인텔리전스(BI) 도구에 데이터 및 처리 기능을 제공하는 환경을 설정하는 운영자와 IT 관리자를 대상으로 합니다.
Tableau는 이 가이드에서 BI 도구로 사용됩니다. 이 가이드를 따르려면 워크스테이션에 Tableau 데스크톱이 설치되어 있어야 합니다.
이 시리즈는 다음 부분으로 구성됩니다.
- 시리즈의 첫 번째 문서인 Google Cloud의 Hadoop에 시각화 소프트웨어를 연결하기 위한 아키텍처에서는 솔루션의 아키텍처, 구성요소, 구성요소가 상호작용하는 방식을 정의합니다.
- 이 시리즈의 두 번째 부분에서는 Google Cloud에서 엔드 투 엔드 Hive 토폴로지를 구성하는 아키텍처 구성요소 설정 방법을 설명합니다. 이 가이드에서는 Tableau를 BI 도구로 사용하는 Hadoop 생태계의 오픈소스 도구를 사용합니다.
이 가이드의 코드 스니펫은 GitHub 저장소에서 사용할 수 있습니다. GitHub 저장소에는 Terraform 구성 파일도 포함되어 있어 작동 중인 프로토타입을 설정하는데 도움을 줄 수 있습니다.
이 가이드에서는 데이터 분석가의 가상 사용자 ID로 sara라는 이름을 사용합니다. 이 사용자 ID는 Apache Knox 및 Apache Ranger 둘 다 사용하는 LDAP 디렉터리에 있습니다. LDAP 그룹을 구성하도록 선택할 수도 있지만 이 절차는 이 가이드에서 다루지 않습니다.
목표
- BI 도구가 Hadoop 환경의 데이터를 사용할 수 있도록 하는 엔드 투 엔드 설정을 만듭니다.
- 사용자 요청을 인증하고 승인합니다.
- BI 도구와 클러스터 간에 보안 통신 채널을 설정하고 사용합니다.
비용
이 문서에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud 구성요소를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용하세요.
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
API Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) 사용 설정
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
API Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS) 사용 설정
환경 초기화
-
Google Cloud 콘솔에서 Cloud Shell을 활성화합니다.
Cloud Shell에서 프로젝트 ID, Dataproc 클러스터의 리전 및 영역으로 환경 변수를 설정합니다.
export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b리전과 영역을 선택할 수 있지만 이 가이드를 따르는 동안 일관성을 유지합니다.
서비스 계정 설정
Cloud Shell에서 서비스 계정을 만듭니다.
gcloud iam service-accounts create cluster-service-account \ --description="The service account for the cluster to be authenticated as." \ --display-name="Cluster service account"클러스터는 이 계정을 사용하여 Google Cloud 리소스에 액세스합니다.
서비스 계정에 다음 역할을 추가합니다.
- Dataproc 작업자: Dataproc 클러스터를 만들고 관리합니다.
- Cloud SQL 편집자: Ranger의 경우 Cloud SQL 프록시를 사용하여 해당 데이터베이스에 연결합니다.
Cloud KMS CryptoKey 복호화: Cloud KMS로 암호화된 비밀번호를 복호화합니다.
bash -c 'array=( dataproc.worker cloudsql.editor cloudkms.cryptoKeyDecrypter ) for i in "${array[@]}" do gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "serviceAccount:cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \ --role roles/$i done'
백엔드 클러스터 만들기
이 섹션에서는 Ranger가 있는 백엔드 클러스터를 만듭니다. 또한 Ranger 데이터베이스를 만들어 정책 규칙을 저장하고 Hive에서 Ranger 정책을 적용하기 위한 샘플 테이블을 만듭니다.
Ranger 데이터베이스 인스턴스 만들기 \
Apache Ranger 정책을 저장할 MySQL 인스턴스를 만듭니다.
export CLOUD_SQL_NAME=cloudsql-mysql gcloud sql instances create ${CLOUD_SQL_NAME} \ --tier=db-n1-standard-1 --region=${REGION}이 명령어는
${REGION}변수로 지정한 리전에 위치한 머신 유형db-n1-standard-1로cloudsql-mysql라는 인스턴스를 만듭니다. 자세한 내용은 Cloud SQL 문서를 참조하세요.호스트에서 연결하는 사용자
root의 인스턴스 비밀번호를 설정합니다. 예시 비밀번호를 시연용으로 사용하거나 혹은 자체적으로 만들 수 있습니다. 사용자 비밀번호를 직접 만들 경우 문자 1개와 숫자 1개 이상이 포함하여 최소 8자를 사용하세요.gcloud sql users set-password root \ --host=% --instance ${CLOUD_SQL_NAME} --password mysql-root-password-99
비밀번호 암호화
이 섹션에서는 암호화 키를 만들어 Ranger 및 MySQL의 비밀번호를 암호화합니다. 유출을 방지하기 위해 암호화 키를 Cloud KMS에 저장합니다. 보안상의 이유로 키 비트를 보거나 추출하거나 내보낼 수 없습니다.
암호화 키를 사용하여 비밀번호를 암호화하고 파일에 작성합니다.
이러한 파일은 Cloud Storage 버킷에 업로드하므로 클러스터를 대신하여 작동하는 서비스 계정에 액세스할 수 있습니다.
서비스 계정에 cloudkms.cryptoKeyDecrypter 역할과 파일 및 암호화 키에 대한 액세스 권한이 있으므로 이러한 파일을 복호화할 수 있습니다. 파일이 유출된 경우에도 역할과 키가 없으면 파일을 복호화할 수 없습니다.
별도의 보안 조치로 서비스마다 별도의 비밀번호 파일을 만듭니다. 이 작업은 비밀번호가 유출될 경우 영향을 받을 가능성이 있는 영역을 최소화합니다.
키 관리에 대한 자세한 내용은 Cloud KMS 문서를 참조하세요.
Cloud Shell에서 키를 보존할 Cloud KMS 키링을 만듭니다.
gcloud kms keyrings create my-keyring --location global비밀번호를 암호화하려면 Cloud KMS 암호화 키를 만듭니다.
gcloud kms keys create my-key \ --location global \ --keyring my-keyring \ --purpose encryption키를 사용하여 Ranger 관리자 비밀번호를 암호화합니다. 예시 비밀번호를 사용하거나 직접 만들 수도 있습니다. 비밀번호는 최소 8자 이상이어야 하며 문자, 숫자를 각각 최소 한 개 이상 포함해야 합니다.
echo "ranger-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-admin-password.encrypted키를 사용하여 Ranger 데이터베이스 관리자 비밀번호를 암호화합니다.
echo "ranger-db-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-db-admin-password.encrypted키를 사용하여 MySQL 루트 비밀번호를 암호화합니다.
echo "mysql-root-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=mysql-root-password.encrypted암호화된 비밀번호 파일을 저장할 Cloud Storage 버킷을 만듭니다.
gsutil mb -l ${REGION} gs://${PROJECT_ID}-ranger암호화된 비밀번호 파일을 Cloud Storage 버킷에 업로드합니다.
gsutil -m cp *.encrypted gs://${PROJECT_ID}-ranger
클러스터 만들기
이 섹션에서는 Ranger를 지원하는 백엔드 클러스터를 만듭니다. Dataproc의 Ranger 선택적 구성요소에 대한 자세한 내용은 Dataproc Ranger 구성요소 문서 페이지를 참조하세요.
Cloud Shell에서 Apache Solr 감사 로그를 저장할 Cloud Storage 버킷을 만듭니다.
gsutil mb -l ${REGION} gs://${PROJECT_ID}-solr클러스터를 만드는 데 필요한 모든 변수를 내보냅니다.
export BACKEND_CLUSTER=backend-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b export CLOUD_SQL_NAME=cloudsql-mysql export RANGER_KMS_KEY_URI=\ projects/${PROJECT_ID}/locations/global/keyRings/my-keyring/cryptoKeys/my-key export RANGER_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-admin-password.encrypted export RANGER_DB_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-db-admin-password.encrypted export MYSQL_ROOT_PWD_URI=\ gs://${PROJECT_ID}-ranger/mysql-root-password.encrypted편의를 위해 이전에 설정한 일부 변수가 이 명령어에서 반복되므로 필요에 따라 수정할 수 있습니다.
새 변수에는 다음이 포함됩니다.
- 백엔드 클러스터의 이름.
- 서비스 계정이 비밀번호를 복호화할 수 있도록 하는 암호화 키의 URI.
- 암호화된 비밀번호가 포함된 파일의 URI.
다른 키링이나 키 또는 다른 파일 이름을 사용한 경우 명령어에서 해당하는 값을 사용합니다.
백엔드 Dataproc 클러스터를 만듭니다.
gcloud beta dataproc clusters create ${BACKEND_CLUSTER} \ --optional-components=SOLR,RANGER \ --region ${REGION} \ --zone ${ZONE} \ --enable-component-gateway \ --scopes=default,sql-admin \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --properties="\ dataproc:ranger.kms.key.uri=${RANGER_KMS_KEY_URI},\ dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PWD_URI},\ dataproc:ranger.db.admin.password.uri=${RANGER_DB_ADMIN_PWD_URI},\ dataproc:ranger.cloud-sql.instance.connection.name=${PROJECT_ID}:${REGION}:${CLOUD_SQL_NAME},\ dataproc:ranger.cloud-sql.root.password.uri=${MYSQL_ROOT_PWD_URI},\ dataproc:solr.gcs.path=gs://${PROJECT_ID}-solr,\ hive:hive.server2.thrift.http.port=10000,\ hive:hive.server2.thrift.http.path=cliservice,\ hive:hive.server2.transport.mode=http"이 명령어의 속성은 다음과 같습니다.
- 명령어의 마지막 세 줄은 HTTP 모드에서 HiveServer2를 구성하는 Hive 속성으로, Apache Knox가 HTTP를 통해 Apache Hive를 호출할 수 있습니다.
- 명령어의 다른 매개변수는 다음과 같이 작동합니다.
--optional-components=SOLR,RANGER매개변수는 Apache Ranger 및 Solr 종속 항목을 사용 설정합니다.--enable-component-gateway매개변수는 Dataproc 구성요소 게이트웨이를 사용 설정하여 Google Cloud Console의 클러스터 페이지에서 Ranger 및 기타 Hadoop 사용자 인터페이스를 직접 사용할 수 있도록 합니다. 이 매개변수를 설정하면 백엔드 마스터 노드에 SSH 터널링할 필요가 없습니다.--scopes=default,sql-admin매개변수는 Apache Ranger가 Cloud SQL 데이터베이스에 액세스하도록 승인합니다.
모든 클러스터의 수명 기간 이상으로 지속되고 여러 클러스터에서 사용할 수 있는 외부 Hive 메타저장소를 만들어야 한다면 Dataproc에서 Apache Hive 사용을 참조하세요.
이 절차를 실행하려면 Beeline에서 테이블 만들기 예시를 직접 실행해야 합니다. gcloud dataproc jobs submit hive 명령어는 Hive 바이너리 전송을 사용하지만 이러한 명령어는 HTTP 모드로 구성된 경우 HiveServer2와 호환되지 않습니다.
샘플 Hive 테이블 만들기
Cloud Shell에서 샘플 Apache Parquet 파일을 저장할 Cloud Storage 버킷을 만듭니다.
gsutil mb -l ${REGION} gs://${PROJECT_ID}-hive공개적으로 사용 가능한 샘플 Parquet 파일을 버킷에 복사합니다.
gsutil cp gs://hive-solution/part-00000.parquet \ gs://${PROJECT_ID}-hive/dataset/transactions/part-00000.parquetSSH를 사용하여 이전 섹션에서 만든 백엔드 클러스터의 마스터 노드에 연결합니다.
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-m클러스터 마스터 노드의 이름은 클러스터의 이름 뒤에
-m.이 붙습니다. HA 클러스터 마스터 노드 이름에는 추가 서픽스가 있습니다.Cloud Shell에서 마스터 노드에 처음 연결하는 경우 SSH 키를 생성하라는 메시지가 표시됩니다.
SSH를 사용하여 연 터미널에서 마스터 노드에 사전 설치된 Apache Beeline을 사용하여 로컬 HiveServer2에 연결합니다.
beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice admin admin-password"\ --hivevar PROJECT_ID=$(gcloud info --format='value(config.project)')이 명령어는 Beeline 명령줄 도구를 시작하고 환경 변수에 Google Cloud 프로젝트 이름을 전달합니다.
Hive는 사용자 인증을 수행하지 않지만 대부분의 작업을 수행하려면 사용자 ID가 필요합니다. 여기에서
admin사용자는 Hive에서 구성된 기본 사용자입니다. 이 가이드의 뒷부분에서 Apache Knox를 통해 구성하는 ID 제공업체는 BI 도구에서 오는 요청에 대한 사용자 인증을 처리합니다.Beeline 프롬프트에서 이전에 Hive 버킷에 복사한 Parquet 파일을 사용하여 테이블을 만듭니다.
CREATE EXTERNAL TABLE transactions (SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) STORED AS PARQUET LOCATION 'gs://${PROJECT_ID}-hive/dataset/transactions';테이블이 제대로 생성되었는지 확인합니다.
SELECT * FROM transactions LIMIT 10; SELECT TransactionType, AVG(TransactionAmount) AS AverageAmount FROM transactions WHERE SubmissionDate = '2017-12-22' GROUP BY TransactionType;Beeline 프롬프트에 두 개의 쿼리 결과가 나타납니다.
Beeline 명령줄 도구를 종료합니다.
!quit백엔드 마스터의 내부 DNS 이름을 복사합니다.
hostname -A | tr -d '[:space:]'; echo다음 섹션에서 이 이름을
backend-master-internal-dns-name로 사용하여 Apache Knox 토폴로지를 구성합니다. 또한 이 이름을 사용하여 Ranger에서 서비스를 구성할 수도 있습니다.노드에서 터미널을 종료합니다.
exit
프록시 클러스터 만들기
이 섹션에서는 Apache Knox 초기화 작업이 있는 프록시 클러스터를 만듭니다.
토폴로지 만들기
Cloud Shell에서 Dataproc initialization-actions GitHub 저장소를 클론합니다.
git clone https://github.com/GoogleCloudDataproc/initialization-actions.git백엔드 클러스터의 토폴로지를 만듭니다.
export KNOX_INIT_FOLDER=`pwd`/initialization-actions/knox cd ${KNOX_INIT_FOLDER}/topologies/ mv example-hive-nonpii.xml hive-us-transactions.xmlApache Knox는 파일 이름을 토폴로지의 URL 경로로 사용합니다. 이 단계에서는
hive-us-transactions이라는 토폴로지를 나타내는 이름을 변경합니다. 그런 다음 샘플 Hive 테이블 만들기에서 Hive에 로드한 가상 트랜잭션 데이터에 액세스할 수 있습니다.토폴로지 파일을 수정합니다.
vi hive-us-transactions.xml백엔드 서비스가 구성된 방식을 확인하려면 토폴로지 설명자 파일을 참조하세요. 이 파일은 하나 이상의 백엔드 서비스를 가리키는 토폴로지를 정의합니다. WebHDFS 및 HIVE의 두 가지 서비스가 샘플 값으로 구성됩니다. 이 파일은 또한 이 토폴로지와 인증 ACL의 서비스에 대한 인증 공급자를 정의합니다.
데이터 분석가 샘플 LDAP 사용자 ID
sara를 추가합니다.<param> <name>hive.acl</name> <value>admin,sara;*;*</value> </param>샘플 ID를 추가하면 사용자가 Apache Knox를 통해 Hive 백엔드 서비스에 액세스할 수 있습니다.
백엔드 클러스터 Hive 서비스를 가리키도록 HIVE URL을 변경합니다. HIVE 서비스 정의는 파일 하단의 WebHDFS 아래에 있습니다.
<service> <role>HIVE</role> <url>http://<backend-master-internal-dns-name>:10000/cliservice</url> </service><backend-master-internal-dns-name>자리표시자를 샘플 Hive 테이블 만들기에서 획득한 백엔드 클러스터의 내부 DNS 이름으로 바꿉니다.파일을 저장하고 편집기를 닫습니다.
토폴로지를 더 만들려면 이 섹션의 단계를 반복하세요. 각 토폴로지에 대해 독립적인 XML 설명자를 하나씩 만듭니다.
프록시 클러스터 만들기에서 이러한 파일을 Cloud Storage 버킷에 복사합니다. 새 토폴로지를 만들거나 프록시 클러스터를 만든 후 변경하려면 파일을 수정하고 버킷에 다시 업로드하세요. Apache Knox 초기화 작업은 버킷에서 변경사항을 프록시 클러스터로 정기적으로 복사하는 크론 작업을 만듭니다.
SSL/TLS 인증서 구성
클라이언트는 Apache Knox와 통신할 때 SSL/TLS 인증서를 사용합니다. 초기화 작업은 자체 서명 인증서를 생성하거나 CA 서명 인증서를 제공할 수 있습니다.
Cloud Shell에서 Apache Knox 일반 구성 파일을 수정합니다.
vi ${KNOX_INIT_FOLDER}/knox-config.yamlHOSTNAME을certificate_hostname속성 값으로 프록시 마스터 노드의 외부 DNS 이름으로 바꿉니다. 이 가이드에서는localhost를 사용합니다.certificate_hostname: localhost이 가이드의 뒷부분에서
localhost값에 대한 SSH 터널과 프록시 클러스터를 만듭니다.Apache Knox 일반 구성 파일에는 BI 도구가 프록시 클러스터와 통신하는 데 사용하는 인증서를 암호화하는
master_key도 포함됩니다. 기본적으로 이 키는 단어secret입니다.자체 인증서를 제공하는 경우 다음 두 속성을 변경합니다.
generate_cert: false custom_cert_name: <filename-of-your-custom-certificate>파일을 저장하고 편집기를 닫습니다.
자체 인증서를 제공하는 경우
custom_cert_name속성에서 지정할 수 있습니다.
프록시 클러스터 만들기
Cloud Shell에서 Cloud Storage 버킷을 만듭니다.
gsutil mb -l ${REGION} gs://${PROJECT_ID}-knox이 버킷은 이전 섹션에서 만든 구성을 Apache Knox 초기화 작업에 제공합니다.
Apache Knox 초기화 작업 폴더의 모든 파일을 버킷으로 복사합니다.
gsutil -m cp -r ${KNOX_INIT_FOLDER}/* gs://${PROJECT_ID}-knox클러스터를 만드는 데 필요한 모든 변수를 내보냅니다.
export PROXY_CLUSTER=proxy-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b이 단계에서는 이전에 설정한 일부 변수가 반복되므로 필요에 따라 수정할 수 있습니다.
프록시 클러스터 만들기
gcloud dataproc clusters create ${PROXY_CLUSTER} \ --region ${REGION} \ --zone ${ZONE} \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/knox/knox.sh \ --metadata knox-gw-config=gs://${PROJECT_ID}-knox
프록시를 통해 연결 확인
프록시 클러스터가 생성되면 SSH를 사용하여 Cloud Shell에서 마스터 노드에 연결합니다.
gcloud compute ssh --zone ${ZONE} ${PROXY_CLUSTER}-m프록시 클러스터의 마스터 노드 터미널에서 다음 쿼리를 실행합니다.
beeline -u "jdbc:hive2://localhost:8443/;\ ssl=true;sslTrustStore=/usr/lib/knox/data/security/keystores/gateway-client.jks;trustStorePassword=secret;\ transportMode=http;httpPath=gateway/hive-us-transactions/hive"\ -e "SELECT SubmissionDate, TransactionType FROM transactions LIMIT 10;"\ -n admin -p admin-password
이 명령어의 속성은 다음과 같습니다.
- Apache Knox를 구성할 때 생성한 인증서가 호스트 이름으로
localhost을 지정하기 때문에beeline명령어는 DNS 내부 이름 대신localhost을 사용합니다. 자체 DNS 이름 또는 인증서를 사용하는 경우 해당 호스트 이름을 사용합니다. - 이 포트는 Apache Knox 기본 SSL 포트에 해당하는
8443입니다. ssl=true를 시작하는 행은 SSL을 사용 설정하며 Beeline과 같은 클라이언트 애플리케이션에서 사용할 SSL Trust Store의 경로와 비밀번호를 제공합니다.transportMode행은 요청이 HTTP를 통해 전송되어야 함을 나타내며 HiveServer2 서비스 경로를 제공합니다. 경로는 키워드gateway, 이전 섹션에서 정의한 토폴로지 이름, 동일한 토폴로지에서 구성된 서비스 이름(이 경우hive)으로 구성됩니다.-e매개변수는 Hive에서 실행할 쿼리를 제공합니다. 이 매개변수를 생략하면 Beeline 명령줄 도구에서 대화형 세션을 엽니다.-n매개변수는 사용자 ID와 비밀번호를 제공합니다. 이 단계에서는 기본 Hiveadmin사용자를 사용하고 있습니다. 다음 섹션에서는 분석가 사용자 ID를 만들고 이 사용자에 대한 사용자 인증 정보 및 승인 정책을 설정합니다.
인증 저장소에 사용자 추가
기본적으로 Apache Knox에는 Apache Shiro를 기반으로 하는 인증 제공업체가 포함되어 있습니다.
이 인증 제공업체는 ApacheDS LDAP 저장소에 대한 BASIC 인증을 통해 구성됩니다. 이 섹션에서는 샘플 데이터 분석 사용자 ID sara을 인증 저장소에 추가합니다.
프록시의 마스터 노드에 있는 터미널에서 LDAP 유틸리티를 설치합니다.
sudo apt-get install ldap-utils새 사용자
sara의 LDAP 데이터 교환 형식(LDIF) 파일을 만듭니다.export USER_ID=sara printf '%s\n'\ "# entry for user ${USER_ID}"\ "dn: uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org"\ "objectclass:top"\ "objectclass:person"\ "objectclass:organizationalPerson"\ "objectclass:inetOrgPerson"\ "cn: ${USER_ID}"\ "sn: ${USER_ID}"\ "uid: ${USER_ID}"\ "userPassword:${USER_ID}-password"\ > new-user.ldifLDAP 디렉터리에 사용자 ID를 추가합니다.
ldapadd -f new-user.ldif \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389-D매개변수는ldapadd로 표현되는 사용자가 디렉터리에 액세스할 때 바인딩할 고유 이름 (DN)을 지정합니다. DN은 이미 디렉터리에 있는 사용자 ID(이 경우 사용자admin)여야 합니다.새 사용자가 인증 저장소에 있는지 확인합니다.
ldapsearch -b "uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org" \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389사용자 세부정보가 터미널에 표시됩니다.
프록시 마스터 노드의 내부 DNS 이름을 복사하여 저장합니다.
hostname -A | tr -d '[:space:]'; echo다음 섹션에서 이 이름을
<proxy-master-internal-dns-name>로 사용하여 LDAP 동기화를 구성합니다.노드에서 터미널을 종료합니다.
exit
승인 설정
이 섹션에서는 LDAP 서비스와 Ranger 간에 ID 동기화를 구성합니다.
사용자 ID를 Ranger에 동기화
Ranger 정책이 Apache Knox와 동일한 사용자 ID에 적용되도록 하려면 Ranger UserSync 데몬을 구성하여 동일한 디렉터리의 ID를 동기화합니다.
이 예시에서는 기본적으로 Apache Knox를 사용할 수 있는 로컬 LDAP 디렉터리에 연결합니다. 하지만 프로덕션 환경에서는 외부 ID 디렉터리를 설정하는 것이 좋습니다. 자세한 내용은 Apache Knox 사용자 가이드 및 Google Cloud Cloud ID, 관리형 Active Directory 및 Federated AD문서를 참조하세요.
SSH를 사용하여 생성한 백엔드 클러스터의 마스터 노드에 연결합니다.
export BACKEND_CLUSTER=backend-cluster gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-m터미널에서
UserSync구성 파일을 수정합니다.sudo vi /etc/ranger/usersync/conf/ranger-ugsync-site.xml다음 LDAP 속성 값을 설정합니다. 이름이 비슷한
group속성이 아닌user속성을 수정해야 합니다.<property> <name>ranger.usersync.sync.source</name> <value>ldap</value> </property> <property> <name>ranger.usersync.ldap.url</name> <value>ldap://<proxy-master-internal-dns-name>:33389</value> </property> <property> <name>ranger.usersync.ldap.binddn</name> <value>uid=admin,ou=people,dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.ldap.ldapbindpassword</name> <value>admin-password</value> </property> <property> <name>ranger.usersync.ldap.user.searchbase</name> <value>dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.source.impl.class</name> <value>org.apache.ranger.ldapusersync.process.LdapUserGroupBuilder</value> </property><proxy-master-internal-dns-name>자리표시자를 마지막 섹션에서 검색한 프록시 서버의 내부 DNS 이름으로 바꿉니다.이러한 속성은 사용자와 그룹을 모두 동기화하는 전체 LDAP 구성의 하위 집합입니다. 자세한 내용은 Ranger를 LDAP와 통합하는 방법을 참조하세요.
파일을 저장하고 편집기를 닫습니다.
ranger-usersync데몬을 다시 시작합니다.sudo service ranger-usersync restart다음 명령어를 실행합니다.
grep sara /var/log/ranger-usersync/*ID가 동기화되면 사용자
sara에 대한 로그 줄이 하나 이상 표시됩니다.
Ranger 정책 만들기
이 섹션에서는 Ranger에서 새 Hive 서비스를 구성합니다. 또한 특정 ID의 Hive 데이터에 대한 액세스를 제한하기 위해 Ranger 정책을 설정 및 테스트합니다.
Ranger 서비스 구성
마스터 노드의 터미널에서 Ranger Hive 구성을 수정합니다.
sudo vi /etc/hive/conf/ranger-hive-security.xmlranger.plugin.hive.service.name속성에서<value>속성을 수정합니다.<property> <name>ranger.plugin.hive.service.name</name> <value>ranger-hive-service-01</value> <description> Name of the Ranger service containing policies for this YARN instance </description> </property>파일을 저장하고 편집기를 닫습니다.
HiveServer2 관리자 서비스를 다시 시작합니다.
sudo service hive-server2 restartRanger 정책을 만들 준비가 되었습니다.
Ranger 관리 콘솔에서 서비스 설정
Google Cloud Console에서 Dataproc 페이지로 이동합니다.
백엔드 클러스터 이름을 클릭한 후 웹 인터페이스를 클릭합니다.
구성요소 게이트웨이로 클러스터를 만들었으므로 클러스터에 설치된 Hadoop 구성요소 목록이 표시됩니다.
Ranger 링크를 클릭하여 Ranger 콘솔을 엽니다.
사용자
admin및 Ranger 관리자 비밀번호로 Ranger에 로그인합니다. Ranger 콘솔에 서비스 목록이 포함된 Service Manager 페이지가 표시됩니다.HIVE 그룹에서 더하기 기호를 클릭하여 새 Hive 서비스를 만듭니다.

양식에서 다음 값을 설정합니다.
- 서비스 이름:
ranger-hive-service-01이전에ranger-hive-security.xml구성 파일에 이 이름을 정의했습니다. - 사용자 이름:
admin - 비밀번호:
admin-password jdbc.driverClassName: 기본 이름을org.apache.hive.jdbc.HiveDriver으로 유지jdbc.url:jdbc:hive2:<backend-master-internal-dns-name>:10000/;transportMode=http;httpPath=cliservice<backend-master-internal-dns-name>자리표시자를 이전 섹션에서 검색한 이름으로 바꿉니다.
- 서비스 이름:
추가를 클릭합니다.
각 Ranger 플러그인 설치는 단일 Hive 서비스를 지원합니다. 추가 Hive 서비스를 구성하는 간단한 방법은 추가 백엔드 클러스터를 시작하는 것입니다. 각 클러스터에는 고유의 Ranger 플러그인이 있습니다. 이러한 클러스터는 동일한 Ranger DB를 공유할 수 있으므로, 이러한 클러스터에서 Ranger 관리 콘솔에 액세스할 때마다 모든 서비스에 대한 통합뷰를 가지게 됩니다.
제한된 권한으로 Ranger 정책 설정
이 정책은 샘플 분석가 LDAP 사용자 sara가 Hive 테이블의 특정 열에 액세스할 수 있도록 허용합니다.
서비스 관리자 창에서 사용자가 만든 서비스의 이름을 클릭합니다.
Ranger 관리 콘솔에 정책 창이 표시됩니다.
새 정책 추가를 클릭합니다.
이 정책을 사용하면
sara에 테이블 트랜잭션의submissionDate및transactionType열만 볼 수 있는 권한이 부여됩니다.양식에서 다음 값을 설정합니다.
- 정책 이름: 임의의 이름(예:
allow-tx-columns) - 데이터베이스:
default - 테이블:
transactions - Hive 열:
submissionDate, transactionType - 허용 조건:
- 사용자 필드:
sara - 권한:
select
- 사용자 필드:
- 정책 이름: 임의의 이름(예:
화면 하단에서 추가를 클릭합니다.
Beeline으로 정책 테스트
마스터 노드 터미널에서 사용자
sara로 Beeline 명령줄 도구를 시작합니다.beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice sara user-password"Beeline 명령줄 도구는 비밀번호를 적용하지 않지만 이전 명령어를 실행하려면 비밀번호를 제공해야 합니다.
다음 쿼리를 실행하여 Ranger가 차단하는지 확인합니다.
SELECT * FROM transactions LIMIT 10;쿼리에
transactionAmount열이 포함되어 있으며,sara는 선택할 수 있는 권한이 없습니다.Permission denied오류가 표시됩니다.Ranger가 다음 쿼리를 허용하는지 확인합니다.
SELECT submissionDate, transactionType FROM transactions LIMIT 10;Beeline 명령줄 도구를 종료합니다.
!quit터미널을 종료합니다.
exitRanger 콘솔에서 Audit(감사) 탭을 클릭합니다. 거부되거나 허용된 이벤트가 모두 표시됩니다. 이전에 정의한 서비스 이름(예:
ranger-hive-service-01)으로 이벤트를 필터링할 수 있습니다.
BI 도구에서 연결
이 가이드의 마지막 단계는 Tableau 데스크톱에서 Hive 데이터를 쿼리하는 것입니다.
방화벽 규칙 만들기
- 공개 IP 주소를 복사하여 저장합니다.
Cloud Shell에서 워크스테이션의 인그레스에 대해 TCP 포트
8443을 여는 방화벽 규칙을 만듭니다.gcloud compute firewall-rules create allow-knox\ --project=${PROJECT_ID} --direction=INGRESS --priority=1000 \ --network=default --action=ALLOW --rules=tcp:8443 \ --target-tags=knox-gateway \ --source-ranges=<your-public-ip>/32<your-public-ip>자리표시자를 공개 IP 주소로 바꿉니다.방화벽 규칙의 네트워크 태그를 프록시 클러스터의 마스터 노드에 적용합니다.
gcloud compute instances add-tags ${PROXY_CLUSTER}-m --zone=${ZONE} \ --tags=knox-gateway
SSH 터널 만들기
이 절차는 localhost에 유효한 자체 서명 인증서를 사용하는 경우에만 필요합니다. 자체 인증서를 사용하거나 프록시 마스터 노드에 자체 외부 DNS 이름이 있는 경우 Hive에 연결하기로 건너뛸 수 있습니다.
Cloud Shell에서 터널을 만들기 위한 명령어를 생성합니다.
echo "gcloud compute ssh ${PROXY_CLUSTER}-m \ --project ${PROJECT_ID} \ --zone ${ZONE} \ -- -L 8443:localhost:8443"gcloud init을 실행하여 사용자 계정을 인증하고 액세스 권한을 부여합니다.워크스테이션에서 터미널을 엽니다.
포트
8443을 전달할 SSH 터널을 만듭니다. 첫 번째 단계에서 생성된 명령어를 복사하여 워크스테이션 터미널에 붙여넣은 다음 명령어를 실행합니다.터널이 활성 상태로 유지되도록 터미널을 열린 상태로 둡니다.
Hive에 연결
- 워크스테이션에서 Hive ODBC 드라이버를 설치합니다.
- Tableau 데스크톱을 열거나 열린 경우 다시 시작합니다.
- 홈페이지에서 연결/서버에 연결 아래에 있는 더보기를 선택합니다.
- Cloudera Hadoop을 검색하여 선택합니다.
샘플 데이터 분석가 LDAP 사용자
sara를 사용자 ID로 사용하여 필드를 다음과 같이 작성합니다.- 서버: 터널을 만든 경우
localhost을 사용합니다. 터널을 만들지 않은 경우 프록시 마스터 노드의 외부 DNS 이름을 사용합니다. - 포트:
8443 - 유형:
HiveServer2 - 인증:
Username및Password - 사용자 이름:
sara - 비밀번호:
sara-password - HTTP 경로:
gateway/hive-us-transactions/hive - 필수 SSL:
yes
- 서버: 터널을 만든 경우
로그인을 클릭합니다.

Hive 데이터 쿼리
- 데이터 소스 화면에서 스키마 선택을 클릭하고
default를 검색합니다. default스키마 이름을 더블클릭합니다.테이블 패널이 로드됩니다.
테이블 패널에서 새 커스텀 SQL을 더블클릭합니다.
커스텀 SQL 편집 창이 열립니다.
트랜잭션 테이블에서 날짜 및 트랜잭션 유형을 선택하는 다음 쿼리를 입력합니다.
SELECT `submissiondate`, `transactiontype` FROM `default`.`transactions`확인을 클릭합니다.
쿼리의 메타데이터는 Hive에서 검색됩니다.
지금 업데이트를 클릭합니다.
sara는transactions테이블에서 이러한 두 열을 읽을 수 있는 권한이 있으므로 Tableau는 Hive에서 데이터를 검색합니다.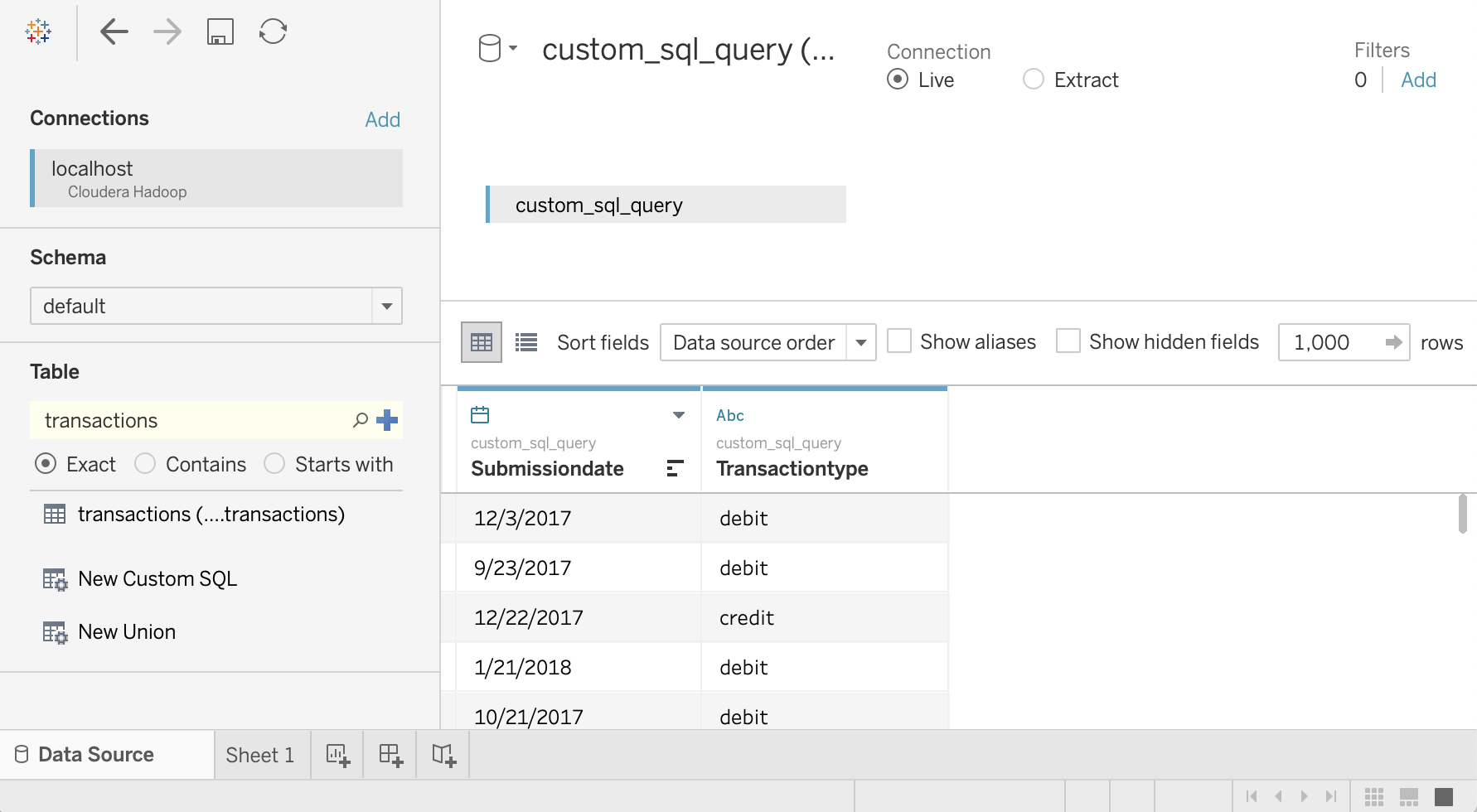
transactions테이블의 모든 열을 선택하려면 테이블 패널에서 새 커스텀 SQL을 다시 더블클릭합니다. 커스텀 SQL 편집 창이 열립니다.다음 쿼리를 입력합니다.
SELECT * FROM `default`.`transactions`확인을 클릭합니다. 다음 오류 메시지가 표시됩니다.
Permission denied: user [sara] does not have [SELECT] privilege on [default/transactions/*].sara는 Ranger로부터transactionAmount열을 읽을 수 있는 권한이 없으므로 이 메시지가 예상됩니다. 이 예시에서는 Tableau 사용자가 액세스할 수 있는 데이터를 제한하는 방법을 보여줍니다.모든 열을 보려면 사용자
admin를 사용하여 단계를 반복합니다.Tableau와 터미널 창을 닫습니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
프로젝트 삭제
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
다음 단계
- 이 시리즈의 첫 번째 부분인 Google Cloud의 Hadoop에 시각화 소프트웨어를 연결하는 아키텍처를 숙지합니다.
- Hadoop 마이그레이션 보안 가이드를 숙지합니다.
- Apache Spark 작업을 Dataproc으로 마이그레이션 하는 방법을 알아봅니다.
- 온프레미스 Hadoop 인프라를 Google Cloud로 마이그레이션하는 방법을 알아봅니다.
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항을 살펴봅니다. Cloud 아키텍처 센터 살펴보기