Questo tutorial è la seconda parte di una serie che mostra come creare un soluzione end-to-end per consentire agli analisti di dati di accedere in modo sicuro ai dati di business intelligence (BI).
Questo tutorial è rivolto agli operatori e agli amministratori IT che configurano ambienti che forniscono all'azienda funzionalità di dati ed elaborazione di intelligence (BI) utilizzati dagli analisti di dati.
Tabella è usato come strumento BI in questo tutorial. Per seguire questo tutorial, devi avere Tableau Desktop installato sulla workstation.
La serie è composta dai seguenti componenti:
- La prima parte della serie, Architecture for connectview software to Hadoop on Google Cloud, definisce l'architettura della soluzione, i suoi componenti e il modo in cui interagire.
- Questa seconda parte della serie spiega come configurare l'architettura che costituiscono la topologia Hive end-to-end su Google Cloud. Il tutorial utilizza strumenti open source dell'ecosistema Hadoop, con Tableau come strumento BI.
Gli snippet di codice in questo tutorial sono disponibili in un repository GitHub. Il repository GitHub include anche i file di configurazione Terraform per aiutarti per creare un prototipo funzionante.
Durante il tutorial, il nome sara viene utilizzato come identità utente fittizia.
di un analista di dati. L'identità utente si trova nella directory LDAP
utilizzati sia da Apache Knox che da Apache Ranger. Puoi anche scegliere di configurare i gruppi LDAP, ma questa procedura
nell'ambito di questo tutorial.
Obiettivi
- Creare una configurazione end-to-end che consenta a uno strumento BI di utilizzare i dati di un Hadoop completamente gestito di Google Cloud.
- Autenticare e autorizzare le richieste degli utenti.
- Configura e utilizza canali di comunicazione sicuri tra lo strumento BI e il in un cluster Kubernetes.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi basata sull'utilizzo previsto,
utilizza il Calcolatore prezzi.
Prima di iniziare
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Assicurati che la fatturazione sia attivata per il tuo progetto Google Cloud.
-
Abilita le API Dataproc, Cloud SQL, and Cloud Key Management Service (Cloud KMS).
Inizializzazione dell'ambiente
-
In the Google Cloud console, activate Cloud Shell.
In Cloud Shell, imposta le variabili di ambiente con il tuo progetto e la regione e le zone dei cluster Dataproc:
export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bPuoi scegliere qualsiasi regione e zona, ma mantienile coerenti man mano che segui questo tutorial.
Configurazione di un account di servizio
In Cloud Shell, crea un'istanza account di servizio.
gcloud iam service-accounts create cluster-service-account \ --description="The service account for the cluster to be authenticated as." \ --display-name="Cluster service account"Il cluster utilizza questo account per accedere alle risorse Google Cloud.
Aggiungi i seguenti ruoli all'account di servizio:
- Worker Dataproc: per creare e gestire i cluster Dataproc.
- Editor Cloud SQL: affinché il ranger si connetta al suo database usando Proxy Cloud SQL.
Autore crittografia CryptoKey Cloud KMS: per decriptare le password criptate con Cloud KMS.
bash -c 'array=( dataproc.worker cloudsql.editor cloudkms.cryptoKeyDecrypter ) for i in "${array[@]}" do gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "serviceAccount:cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com" \ --role roles/$i done'
Creazione del cluster di backend
In questa sezione creerai il cluster di backend in cui si trova il ranger. Inoltre crea il database Ranger per archiviare le regole dei criteri e una tabella di esempio in Hive per applicare le norme dei ranger.
Crea l'istanza del database Ranger
Crea un'istanza MySQL per archiviare i criteri Apache Ranger:
export CLOUD_SQL_NAME=cloudsql-mysql gcloud sql instances create ${CLOUD_SQL_NAME} \ --tier=db-n1-standard-1 --region=${REGION}Questo comando crea un'istanza denominata
cloudsql-mysqlcon tipo di macchinadb-n1-standard-1situato nella regione specificato dalla variabile${REGION}. Per ulteriori informazioni, consulta documentazione di Cloud SQL.Imposta la password dell'istanza per l'utente
rootche si connette da qualsiasi host. Puoi utilizzare la password di esempio a scopo dimostrativo oppure creare un personali. Se crei la tua password, utilizza almeno otto caratteri, inclusi almeno una lettera e un numero.gcloud sql users set-password root \ --host=% --instance ${CLOUD_SQL_NAME} --password mysql-root-password-99
Cripta le password
In questa sezione, creerai una chiave di crittografia per criptare le password per Ranger e MySQL. Per prevenire l'esfiltrazione, memorizzi la chiave di crittografia in Cloud KMS. Per motivi di sicurezza, non puoi visualizzare, estrarre o esportare i bit delle chiavi.
Puoi utilizzare la chiave di crittografia per crittografare le password e scriverle su file.
Carica questi file in un bucket Cloud Storage in modo che vengano
accessibile all'account di servizio che agisce per conto dei cluster.
L'account di servizio può decriptare questi file perché ha
il ruolo cloudkms.cryptoKeyDecrypter e l'accesso ai file e alla crittografia
chiave. Anche se un file viene esfiltrato, non può essere decriptato senza il ruolo
e la chiave.
Come ulteriore misura di sicurezza, crei file di password separati per ogni completamente gestito di Google Cloud. Questa azione riduce al minimo la potenziale area colpita se una password viene esfiltrata.
Per saperne di più sulla gestione delle chiavi, consulta la documentazione di Cloud KMS.
In Cloud Shell, crea un keyring di Cloud KMS in cui inserire le tue chiavi:
gcloud kms keyrings create my-keyring --location globalPer criptare le password, crea una chiave di crittografia Cloud KMS:
gcloud kms keys create my-key \ --location global \ --keyring my-keyring \ --purpose encryptionCripta la password dell'utente amministratore di Ranger utilizzando la chiave. Puoi utilizzare lo esempio di password o crearne una personalizzata. La password deve essere costituita da almeno otto inclusi almeno una lettera e un numero.
echo "ranger-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-admin-password.encryptedCripta la password dell'utente dell'amministratore del database Ranger con la chiave:
echo "ranger-db-admin-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=ranger-db-admin-password.encryptedCripta la password root MySQL con la chiave:
echo "mysql-root-password-99" | \ gcloud kms encrypt \ --location=global \ --keyring=my-keyring \ --key=my-key \ --plaintext-file=- \ --ciphertext-file=mysql-root-password.encryptedCrea un bucket Cloud Storage in cui archiviare i file delle password criptati:
gcloud storage buckets create gs://${PROJECT_ID}-ranger --location=${REGION}Carica i file delle password criptati nel bucket Cloud Storage:
gcloud storage cp *.encrypted gs://${PROJECT_ID}-ranger
Crea il cluster
In questa sezione creerai un cluster di backend con il supporto di Ranger. Per maggiori informazioni informazioni sul componente facoltativo Ranger in Dataproc, consulta la pagina della documentazione del componente Dataproc Ranger.
In Cloud Shell, crea un bucket Cloud Storage per archiviare Apache Solr Audit log:
gcloud storage buckets create gs://${PROJECT_ID}-solr --location=${REGION}Esporta tutte le variabili necessarie per creare il cluster:
export BACKEND_CLUSTER=backend-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-b export CLOUD_SQL_NAME=cloudsql-mysql export RANGER_KMS_KEY_URI=\ projects/${PROJECT_ID}/locations/global/keyRings/my-keyring/cryptoKeys/my-key export RANGER_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-admin-password.encrypted export RANGER_DB_ADMIN_PWD_URI=\ gs://${PROJECT_ID}-ranger/ranger-db-admin-password.encrypted export MYSQL_ROOT_PWD_URI=\ gs://${PROJECT_ID}-ranger/mysql-root-password.encryptedPer praticità, alcune delle variabili impostate in precedenza vengono ripetute questo comando per poterli modificare in base alle tue esigenze.
Le nuove variabili contengono:
- Il nome del cluster di backend.
- L'URI della chiave di crittografia in modo che l'account di servizio possa decriptare le password.
- L'URI dei file contenenti le password criptate.
Se hai utilizzato una chiave o un keyring diversi oppure nomi file diversi, utilizza i valori corrispondenti nel comando.
Crea il cluster Dataproc di backend:
gcloud beta dataproc clusters create ${BACKEND_CLUSTER} \ --optional-components=SOLR,RANGER \ --region ${REGION} \ --zone ${ZONE} \ --enable-component-gateway \ --scopes=default,sql-admin \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --properties="\ dataproc:ranger.kms.key.uri=${RANGER_KMS_KEY_URI},\ dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PWD_URI},\ dataproc:ranger.db.admin.password.uri=${RANGER_DB_ADMIN_PWD_URI},\ dataproc:ranger.cloud-sql.instance.connection.name=${PROJECT_ID}:${REGION}:${CLOUD_SQL_NAME},\ dataproc:ranger.cloud-sql.root.password.uri=${MYSQL_ROOT_PWD_URI},\ dataproc:solr.gcs.path=gs://${PROJECT_ID}-solr,\ hive:hive.server2.thrift.http.port=10000,\ hive:hive.server2.thrift.http.path=cliservice,\ hive:hive.server2.transport.mode=http"Questo comando ha le seguenti proprietà:
- Le ultime tre righe del comando corrispondono alle proprietà Hive configurare HiveServer2 in modalità HTTP, in modo che Apache Knox possa chiamare Apache Hive tramite HTTP.
- Gli altri parametri nel comando funzionano come segue:
- Il parametro
--optional-components=SOLR,RANGERabilita Apache Il ranger e la sua dipendenza da Solr. - Il parametro
--enable-component-gatewayconsente Gateway del componente Dataproc per rendere disponibili Ranger e altre interfacce utente Hadoop direttamente dalla pagina del cluster nella console Google Cloud. Quando parametro, non è necessario il tunneling SSH dal nodo master di backend. - Il parametro
--scopes=default,sql-adminautorizza Apache Ranger per accedere al suo database Cloud SQL.
- Il parametro
Se devi creare un metastore Hive esterno che persiste oltre la durata
di qualsiasi cluster e possono essere utilizzati in più cluster, consulta Utilizzo di Apache Hive su Dataproc.
Per eseguire la procedura, devi eseguire direttamente gli esempi di creazione della tabella
su Beeline. Mentre i comandi gcloud dataproc jobs submit hive utilizzano il trasporto binario Hive, questi comandi
non sono compatibili con HiveServer2 se è configurato in modalità HTTP.
Crea una tabella Hive di esempio
In Cloud Shell, crea un bucket Cloud Storage per archiviare esempio di file Apache Parquet:
gcloud buckets create gs://${PROJECT_ID}-hive --location=${REGION}Copia un file Parquet di esempio disponibile pubblicamente nel tuo bucket:
gcloud storage cp gs://hive-solution/part-00000.parquet \ gs://${PROJECT_ID}-hive/dataset/transactions/part-00000.parquetConnettiti al nodo master del cluster di backend che hai creato nella precedente utilizzando SSH:
gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mIl nome del nodo master del cluster è il nome del cluster seguito di
-m.I nomi dei nodi master del cluster ad alta disponibilità hanno un suffisso aggiuntivo.Se è la prima volta che ti connetti al nodo master da Cloud Shell, ti verrà chiesto di generare chiavi SSH.
Nel terminale che hai aperto con SSH, connettiti all'HiveServer2 locale utilizzando Apache Beeline, preinstallato sul nodo master:
beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice admin admin-password"\ --hivevar PROJECT_ID=$(gcloud info --format='value(config.project)')Questo comando avvia lo strumento a riga di comando Beeline e trasmette il nome progetto Google Cloud in una variabile di ambiente.
Hive non sta eseguendo alcuna autenticazione utente, ma può eseguire la maggior parte delle attività richiede un'identità utente. L'utente
adminqui è un valore predefinito configurato in Hive. Il provider di identità con cui configuri Apache Knox più avanti in questo tutorial gestisce l'autenticazione utente per da strumenti di BI.Nel prompt di Beeline, crea una tabella utilizzando il file Parquet che hai precedentemente copiato nel bucket Hive:
CREATE EXTERNAL TABLE transactions (SubmissionDate DATE, TransactionAmount DOUBLE, TransactionType STRING) STORED AS PARQUET LOCATION 'gs://${PROJECT_ID}-hive/dataset/transactions';Verifica che la tabella sia stata creata correttamente:
SELECT * FROM transactions LIMIT 10; SELECT TransactionType, AVG(TransactionAmount) AS AverageAmount FROM transactions WHERE SubmissionDate = '2017-12-22' GROUP BY TransactionType;I risultati delle due query vengono visualizzati nel prompt di Beeline.
Esci dallo strumento a riga di comando Beeline:
!quitCopia il nome DNS interno del master di backend:
hostname -A | tr -d '[:space:]'; echoQuesto nome verrà utilizzato nella sezione successiva come
backend-master-internal-dns-nameper configurare la topologia Apache Knox. Utilizzerai il nome anche per configurare in servizio presso il ranger.Esci dal terminale sul nodo:
exit
Creazione del cluster proxy in corso...
In questa sezione creerai il cluster proxy con Azione di inizializzazione di Apache Knox.
Crea una topologia
In Cloud Shell, clona il repository GitHub delle azioni di inizializzazione di Dataproc:
git clone https://github.com/GoogleCloudDataproc/initialization-actions.gitCrea una topologia per il cluster di backend:
export KNOX_INIT_FOLDER=`pwd`/initialization-actions/knox cd ${KNOX_INIT_FOLDER}/topologies/ mv example-hive-nonpii.xml hive-us-transactions.xmlApache Knox utilizza il nome del file come percorso dell'URL per la topologia. In questo passaggio modificherai il nome per rappresentare una topologia chiamata
hive-us-transactions. Dopodiché puoi accedere ai dati sulle transazioni fittizie caricato in Hive in Creare una tabella Hive di esempioModifica il file di topologia:
vi hive-us-transactions.xmlPer vedere come sono configurati i servizi di backend, consulta il descrittore della topologia . Questo file definisce una topologia che punta a uno o più backend i servizi di machine learning. Due servizi sono configurati con valori di esempio: WebHDFS e HIVE. Il file definisce anche il provider di autenticazione per i servizi in questa topologia e gli ACL di autorizzazione.
Aggiungi l'identità utente LDAP di esempio per l'analista di dati
sara.<param> <name>hive.acl</name> <value>admin,sara;*;*</value> </param>L'aggiunta dell'identità di esempio consente all'utente di accedere al servizio di backend Hive tramite Apache Knox.
Modifica l'URL HIVE in modo che punti al servizio Hive del cluster di backend. Puoi trovare la definizione del servizio HIVE nella parte inferiore del file, in WebHDFS.
<service> <role>HIVE</role> <url>http://<backend-master-internal-dns-name>:10000/cliservice</url> </service>Sostituisci
<backend-master-internal-dns-name>segnaposto con il nome DNS interno del cluster di backend che acquisito in Creare una tabella Hive di esempio.Salva il file e chiudi l'editor.
Per creare altre topologie, ripeti i passaggi di questa sezione. Creane uno descrittore XML indipendente per ogni topologia.
In Crea il cluster proxy che copi in un bucket Cloud Storage. Per creare nuove topologie modificali dopo aver creato il cluster proxy, modificato i file e caricati di nuovo nel bucket. L'azione di inizializzazione di Apache Knox crea un cron job che copia regolarmente le modifiche dal bucket al cluster proxy.
Configura il certificato SSL/TLS
Un client utilizza un certificato SSL/TLS quando comunica con Apache Knox. La di inizializzazione può generare un certificato autofirmato oppure puoi fornire del certificato firmato dalla CA.
In Cloud Shell, modifica il file di configurazione generale di Apache Knox:
vi ${KNOX_INIT_FOLDER}/knox-config.yamlSostituisci
HOSTNAMEcon il nome DNS esterno del nodo master del proxy come il valore dell'attributocertificate_hostname. Per questo tutorial, usalocalhost.certificate_hostname: localhostPiù avanti in questo tutorial creerai un tunnel SSH e il cluster proxy per il valore
localhost.Il file di configurazione generale di Apache Knox contiene anche
master_keyche cripta i certificati usati dagli strumenti BI per comunicare con il proxy in un cluster Kubernetes. Per impostazione predefinita, questa chiave è la parolasecret.Se fornisci un certificato personale, modifica le due proprietà seguenti:
generate_cert: false custom_cert_name: <filename-of-your-custom-certificate>Salva il file e chiudi l'editor.
Se fornisci un certificato personale, puoi specificarlo nella proprietà
custom_cert_name.
Crea il cluster proxy
In Cloud Shell, crea un bucket Cloud Storage:
gcloud storage buckets create gs://${PROJECT_ID}-knox --location=${REGION}Questo bucket fornisce le configurazioni che hai creato nella sezione precedente all'azione di inizializzazione di Apache Knox.
Copia tutti i file dalla cartella delle azioni di inizializzazione di Apache Knox su il bucket:
gcloud storage cp ${KNOX_INIT_FOLDER}/* gs://${PROJECT_ID}-knox --recursiveEsporta tutte le variabili necessarie per creare il cluster:
export PROXY_CLUSTER=proxy-cluster export PROJECT_ID=$(gcloud info --format='value(config.project)') export REGION=us-central1 export ZONE=us-central1-bIn questo passaggio, alcune delle variabili impostate in precedenza vengono ripetute di poter apportare le modifiche necessarie.
Crea il cluster proxy:
gcloud dataproc clusters create ${PROXY_CLUSTER} \ --region ${REGION} \ --zone ${ZONE} \ --service-account=cluster-service-account@${PROJECT_ID}.iam.gserviceaccount.com \ --initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/knox/knox.sh \ --metadata knox-gw-config=gs://${PROJECT_ID}-knox
Verifica la connessione tramite proxy
Dopo aver creato il cluster proxy, utilizza SSH per connetterti al relativo nodo master da Cloud Shell:
gcloud compute ssh --zone ${ZONE} ${PROXY_CLUSTER}-mDal terminale del nodo master del cluster proxy, esegui seguente query:
beeline -u "jdbc:hive2://localhost:8443/;\ ssl=true;sslTrustStore=/usr/lib/knox/data/security/keystores/gateway-client.jks;trustStorePassword=secret;\ transportMode=http;httpPath=gateway/hive-us-transactions/hive"\ -e "SELECT SubmissionDate, TransactionType FROM transactions LIMIT 10;"\ -n admin -p admin-password
Questo comando ha le seguenti proprietà:
- Il comando
beelineutilizzalocalhostanziché il nome interno del DNS perché il certificato che hai generato quando hai configurato Apache Knox specificalocalhostcome nome host. Se utilizzi il tuo nome DNS o certificato, utilizza il nome host corrispondente. - La porta è
8443, che corrisponde alla porta SSL predefinita di Apache Knox. - La riga che inizia con
ssl=trueabilita SSL e fornisce il percorso password per SSL Trust Store per applicazioni client come Beeline. - La riga
transportModeindica che la richiesta deve essere inviata tramite HTTP e fornisce il percorso per il servizio HiveServer2. Il percorso è composto la parola chiavegateway, il nome della topologia che hai definito in una e il nome del servizio configurato nella stessa topologia, in questo casohive. - Il parametro
-efornisce la query da eseguire su Hive. Se ometti questo parametro, apri una sessione interattiva nella riga di comando di Beeline lo strumento a riga di comando gcloud. - Il parametro
-nfornisce un'identità utente e una password. In questo passaggio, stai utilizzando l'utente Hive predefinito diadmin. Nelle sezioni successive, Creare un'identità utente "analista" e configurare le credenziali e l'autorizzazione criteri per questo utente.
Aggiungi un utente all'archivio di autenticazione
Per impostazione predefinita, Apache Knox include un provider di autenticazione basato su
Apache Shiro.
Questo provider di autenticazione è configurato con l'autenticazione BASIC su un
Archivio LDAP ApacheDS. In questa sezione aggiungi un analista di dati di esempio
l'identità utente sara nell'archivio di autenticazione.
Dal terminale nel nodo master del proxy, installa Utilità LDAP:
sudo apt-get install ldap-utilsCrea un file LDIF (LDAP Data Interchange Format) per il nuovo utente
sara:export USER_ID=sara printf '%s\n'\ "# entry for user ${USER_ID}"\ "dn: uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org"\ "objectclass:top"\ "objectclass:person"\ "objectclass:organizationalPerson"\ "objectclass:inetOrgPerson"\ "cn: ${USER_ID}"\ "sn: ${USER_ID}"\ "uid: ${USER_ID}"\ "userPassword:${USER_ID}-password"\ > new-user.ldifAggiungi l'ID utente alla directory LDAP:
ldapadd -f new-user.ldif \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389Il parametro
-Dspecifica il nome distinto (DN) da associare quando l'utente rappresentato daldapaddaccede alla directory. DN deve essere un'identità utente già presente nella directory. In questo caso utenteadmin.Verifica che il nuovo utente si trovi nell'archivio di autenticazione:
ldapsearch -b "uid=${USER_ID},ou=people,dc=hadoop,dc=apache,dc=org" \ -D 'uid=admin,ou=people,dc=hadoop,dc=apache,dc=org' \ -w 'admin-password' \ -H ldap://localhost:33389I dettagli dell'utente vengono visualizzati nel terminale.
Copia e salva il nome DNS interno del nodo master del proxy:
hostname -A | tr -d '[:space:]'; echoQuesto nome verrà utilizzato nella sezione successiva come
<proxy-master-internal-dns-name>per configurare la sincronizzazione LDAP.Esci dal terminale sul nodo:
exit
Configurazione delle autorizzazioni
In questa sezione configurerai la sincronizzazione delle identità tra il servizio LDAP e Ranger.
Sincronizzare le identità degli utenti in Ranger
Per assicurarti che i criteri dei ranger si applichino alle stesse identità utente di Apache Knox, devi configurare il daemon Ranger UserSync per sincronizzare le identità dalla stessa directory.
In questo esempio, ti connetti alla directory LDAP locale disponibile per impostazione predefinita con Apache Knox. Tuttavia, in un ambiente di produzione, consigliamo devi configurare una directory delle identità esterna. Per ulteriori informazioni, consulta Guida dell'utente di Apache Knox e Google Cloud Cloud Identity, Active Directory gestita, e Annuncio federato documentazione.
Tramite SSH, connettiti al nodo master del cluster di backend che desideri creato:
export BACKEND_CLUSTER=backend-cluster gcloud compute ssh --zone ${ZONE} ${BACKEND_CLUSTER}-mNel terminale, modifica il file di configurazione
UserSync:sudo vi /etc/ranger/usersync/conf/ranger-ugsync-site.xmlImposta i valori delle seguenti proprietà LDAP. Assicurati di modificare le proprietà
usere non le proprietàgroup, che hanno valori simili i nomi degli utenti.<property> <name>ranger.usersync.sync.source</name> <value>ldap</value> </property> <property> <name>ranger.usersync.ldap.url</name> <value>ldap://<proxy-master-internal-dns-name>:33389</value> </property> <property> <name>ranger.usersync.ldap.binddn</name> <value>uid=admin,ou=people,dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.ldap.ldapbindpassword</name> <value>admin-password</value> </property> <property> <name>ranger.usersync.ldap.user.searchbase</name> <value>dc=hadoop,dc=apache,dc=org</value> </property> <property> <name>ranger.usersync.source.impl.class</name> <value>org.apache.ranger.ldapusersync.process.LdapUserGroupBuilder</value> </property>Sostituisci
<proxy-master-internal-dns-name>segnaposto con il nome DNS interno del server proxy, che potrai recuperate nell'ultima sezione.Queste proprietà sono un sottoinsieme di una configurazione LDAP completa che sincronizza sia gli utenti che i gruppi. Per ulteriori informazioni, vedi Come integrare Ranger con LDAP.
Salva il file e chiudi l'editor.
Riavvia il daemon
ranger-usersync:sudo service ranger-usersync restartEsegui questo comando:
grep sara /var/log/ranger-usersync/*Se le identità sono sincronizzate, vedrai almeno una riga di log per l'utente.
sara.
Creazione dei criteri dei ranger
In questa sezione configurerai un nuovo servizio Hive in Ranger. Hai anche configurato e testare un criterio Ranger per limitare l'accesso ai dati Hive per una e identità di base.
Configurare il servizio Ranger
Dal terminale del nodo master, modifica l'elemento Ranger Hive configurazione:
sudo vi /etc/hive/conf/ranger-hive-security.xmlModifica la proprietà
<value>della proprietàranger.plugin.hive.service.name:<property> <name>ranger.plugin.hive.service.name</name> <value>ranger-hive-service-01</value> <description> Name of the Ranger service containing policies for this YARN instance </description> </property>Salva il file e chiudi l'editor.
Riavvia il servizio HiveServer2 Admin:
sudo service hive-server2 restartOra puoi creare le norme dei ranger.
Configurare il servizio nella Console di amministrazione Ranger
Nella console Google Cloud, vai alla pagina di Dataproc.
Fai clic sul nome del cluster di backend e poi su Interfacce web.
Poiché hai creato il cluster con Gateway dei componenti, viene visualizzato un elenco dei componenti Hadoop che sono installato nel cluster.
Fai clic sul link Ranger per aprire la console del ranger.
Accedi al ranger con l'utente
admine la tua password amministratore del ranger. La console Ranger mostra la pagina Service Manager con un elenco dei servizi.Fai clic sul segno più nel gruppo HIVE per creare un nuovo servizio Hive.

Nel modulo, imposta i seguenti valori:
- Nome servizio:
ranger-hive-service-01. In precedenza ha definito questo nome nel file di configurazioneranger-hive-security.xml. - Nome utente:
admin - Password:
admin-password jdbc.driverClassName: mantieni il nome predefinito impostato suorg.apache.hive.jdbc.HiveDriverjdbc.url:jdbc:hive2:<backend-master-internal-dns-name>:10000/;transportMode=http;httpPath=cliservice- Sostituisci il segnaposto
<backend-master-internal-dns-name>con il nome recuperato in una sezione precedente.
- Nome servizio:
Fai clic su Aggiungi.
Ogni installazione di plug-in Ranger supporta un singolo servizio Hive. Un modo semplice per configurare servizi Hive aggiuntivi è avviare cluster di backend. Ogni cluster ha il proprio plug-in Ranger. Questi cluster possono condividono lo stesso database Ranger, in modo da avere una vista unificata di tutti i servizi ogni volta che accedi alla Console di amministrazione Ranger da uno qualsiasi di questi cluster.
Configura un criterio dei ranger con autorizzazioni limitate
Il criterio consente all'utente LDAP degli analisti di esempio sara di accedere a specifiche
colonne della tabella Hive.
Nella finestra Gestore servizi, fai clic sul nome del servizio che hai creato.
Nella Console di amministrazione Ranger viene visualizzata la finestra Criteri.
Fai clic su Aggiungi nuova norma.
Con questo criterio, concedi a
saral'autorizzazione a visualizzare solo le colonnesubmissionDateetransactionTypedalle transazioni della tabella.Nel modulo, imposta i seguenti valori:
- Nome del criterio: qualsiasi nome, ad esempio
allow-tx-columns - Database:
default - Tabella:
transactions - Colonna Hive:
submissionDate, transactionType - Condizioni di autorizzazione:
- Seleziona utente:
sara - Autorizzazioni:
select
- Seleziona utente:
- Nome del criterio: qualsiasi nome, ad esempio
Nella parte inferiore dello schermo, fai clic su Aggiungi.
Testa il criterio con Beeline
Nel terminale del nodo master, avvia lo strumento a riga di comando Beeline con l'utente
sara.beeline -u "jdbc:hive2://localhost:10000/;transportMode=http;httpPath=cliservice sara user-password"Anche se lo strumento a riga di comando Beeline non applica la password, devi inserisci una password per eseguire il comando precedente.
Esegui questa query per verificare che il ranger la blocchi.
SELECT * FROM transactions LIMIT 10;La query include la colonna
transactionAmount, chesaranon disponi dell'autorizzazione necessaria per selezionarlo.Viene visualizzato un errore
Permission denied.Verifica che il ranger consenta la seguente query:
SELECT submissionDate, transactionType FROM transactions LIMIT 10;Esci dallo strumento a riga di comando Beeline:
!quitEsci dal terminale:
exitNella console Ranger, fai clic sulla scheda Controllo. Sia rifiutato che vengono visualizzati gli eventi consentiti. Puoi filtrare gli eventi in base al nome del servizio definito in precedenza, ad esempio
ranger-hive-service-01.
Connessione da uno strumento BI
Il passaggio finale di questo tutorial consiste nell'eseguire una query sui dati Hive da Tableau Desktop.
Crea una regola firewall
- Copia e salva il tuo indirizzo IP pubblico.
In Cloud Shell, crea una regola firewall che apra la porta TCP
8443per il traffico in entrata dalla workstation:gcloud compute firewall-rules create allow-knox\ --project=${PROJECT_ID} --direction=INGRESS --priority=1000 \ --network=default --action=ALLOW --rules=tcp:8443 \ --target-tags=knox-gateway \ --source-ranges=<your-public-ip>/32Sostituisci il segnaposto
<your-public-ip>con il tuo all'indirizzo IP pubblico.Applica il tag di rete dalla regola firewall al master del cluster proxy nodo:
gcloud compute instances add-tags ${PROXY_CLUSTER}-m --zone=${ZONE} \ --tags=knox-gateway
Crea un tunnel SSH
Questa procedura è necessaria solo se utilizzi un certificato autofirmato
valido per localhost. Se utilizzi il tuo certificato o il master proxy
ha il proprio nome DNS esterno, puoi passare direttamente a Connect to Hive (Connetti a Hive).
In Cloud Shell, genera il comando per creare il tunnel:
echo "gcloud compute ssh ${PROXY_CLUSTER}-m \ --project ${PROJECT_ID} \ --zone ${ZONE} \ -- -L 8443:localhost:8443"Esegui
gcloud initper autenticare il tuo account utente e concedere l'accesso autorizzazioni aggiuntive.Apri un terminale sulla workstation.
Crea un tunnel SSH per inoltrare la porta
8443. Copia il comando generato in nel primo passaggio e incollalo nel terminale di workstation, quindi esegui .Lascia aperto il terminale in modo che il tunnel rimanga attivo.
Connetti a Hive
- Sulla workstation, installa il driver ODBC Hive.
- Apri Tableau Desktop o riavvialo se era aperto.
- Nella home page, in Connetti a un server, seleziona Altro.
- Cerca e seleziona Cloudera Hadoop.
Utilizza l'utente LDAP dell'analista di dati di esempio
saracome identità utente, compila i campi nel seguente modo:- Server: se hai creato un tunnel, usa
localhost. Se non lo hai fatto per creare un tunnel, utilizza il nome DNS esterno del nodo master del proxy. - Porta:
8443 - Tipo:
HiveServer2 - Autenticazione:
UsernameePassword - Nome utente:
sara - Password:
sara-password - Percorso HTTP:
gateway/hive-us-transactions/hive - SSL richiesto:
yes
- Server: se hai creato un tunnel, usa
Fai clic su Accedi.

Esegui query su dati Hive
- Nella schermata Origine dati, fai clic su Seleziona schema e cerca
default. Fai doppio clic sul nome dello schema
default.Viene caricato il riquadro Tabella.
Nel riquadro Tabella, fai doppio clic su Nuovo SQL personalizzato.
Si apre la finestra Modifica SQL personalizzato.
Inserisci la query seguente, che seleziona la data e il tipo di transazione da nella tabella delle transazioni:
SELECT `submissiondate`, `transactiontype` FROM `default`.`transactions`Fai clic su OK.
I metadati della query vengono recuperati da Hive.
Fai clic su Aggiorna ora.
Tableau recupera i dati da Hive perché
saraè autorizzato a leggi queste due colonne dalla tabellatransactions.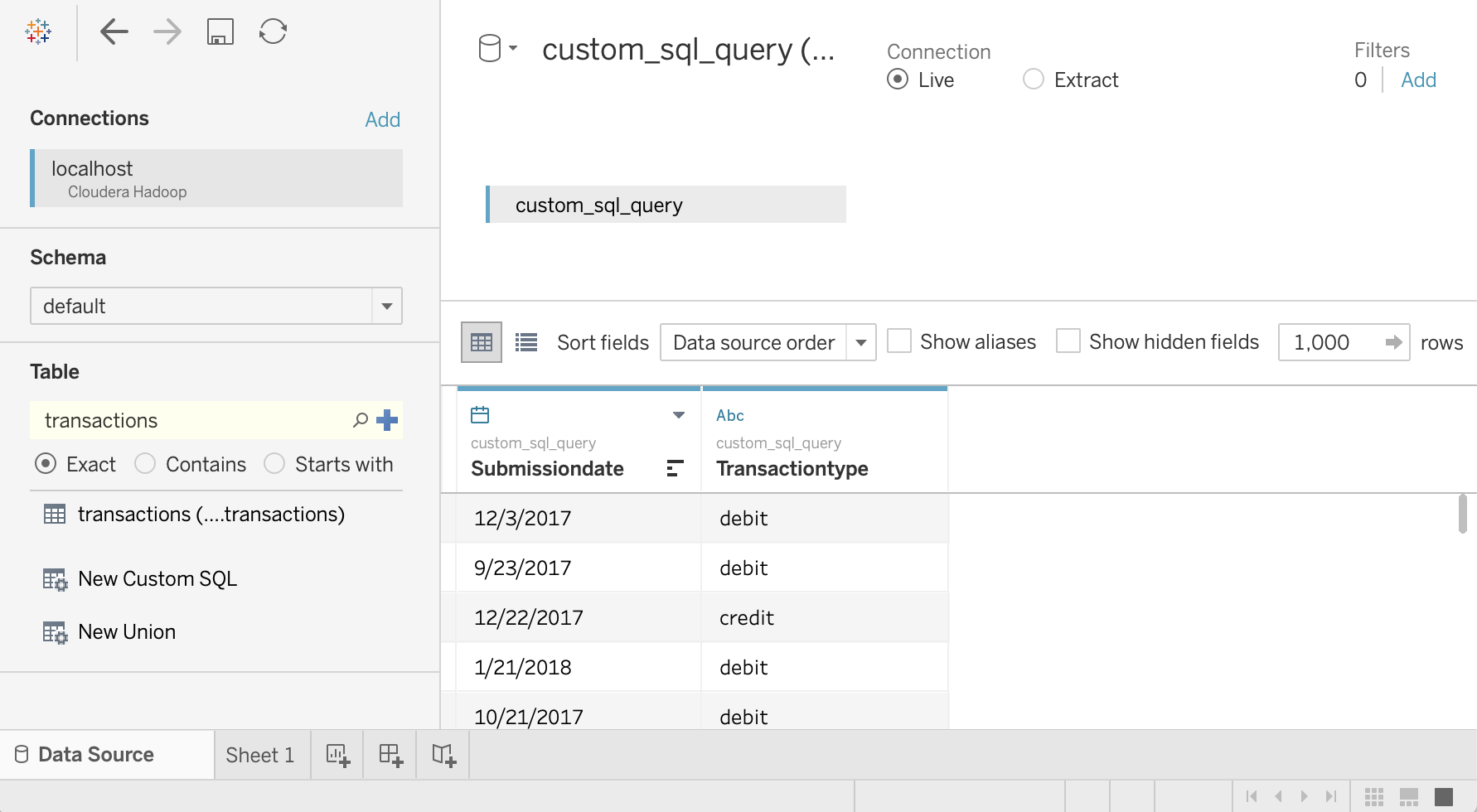
Per provare a selezionare tutte le colonne della tabella
transactions, in Nel riquadro Tabella, fai di nuovo clic due volte su Nuovo SQL personalizzato. La Si apre la finestra Modifica SQL personalizzato.Inserisci la seguente query:
SELECT * FROM `default`.`transactions`Fai clic su OK. Viene visualizzato il seguente messaggio di errore:
Permission denied: user [sara] does not have [SELECT] privilege on [default/transactions/*].Poiché
saranon ha l'autorizzazione del ranger a leggere itransactionAmount, questo messaggio è previsto. Questo esempio mostra come limitare i dati a cui gli utenti di Tableau possono accedere.Per visualizzare tutte le colonne, ripeti i passaggi utilizzando l'utente
admin.Chiudi Tableau e la finestra del terminale.
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID del progetto e fai clic su Chiudi per eliminare il progetto.
Passaggi successivi
- Leggi la prima parte di questa serie: Architettura per connettere il tuo software di visualizzazione a Hadoop su Google Cloud.
- Leggi la Guida alla sicurezza per la migrazione di Hadoop.
- Scopri come eseguire la migrazione dei job Apache Spark in Dataproc.
- Scopri come eseguire la migrazione dell'infrastruttura Hadoop on-premise a Google Cloud.
- Esplora le architetture di riferimento, i diagrammi e le best practice su Google Cloud. Dai un'occhiata al nostro Centro architetture cloud.